网络视频流量分类的特征选择方法研究
2018-03-19吴争董育宁
吴争,董育宁
南京邮电大学通信与信息工程学院,南京210003
网络视频流量分类的特征选择方法研究
吴争,董育宁
南京邮电大学通信与信息工程学院,南京210003
1 引言
近年来,随着互联网和流媒体技术的迅速发展,网络视频业务的增长非常迅速。在2016年互联网流量中,视频流量的比例已达到73%,根据思科[1]的预测,到2021年将达到82%,并且每秒钟将有1 000 000 min的视频内容通过网络。通过网络视频业务流的分类,可以为互联网提供商(ISP)更好地依据不同视频业务的服务质量(QoS)要求提供不同等级的服务。由于动态端口,地址伪装等技术的使用,使得基于机器学习的视频流分类方法成为研究的热点。
而如此庞大体量的网络视频流量,无疑对于分类器的负担是巨大的,更何况是要求实时、准确的网络流量的分类业务,这对网络视频流量的分类提出了巨大的挑战。为了解决这一问题,在分类之前,进行特征选择,可以提高分类器的分类效率,同时将与分类无关的特征筛除,提高分类器的准确率。
在近几十年里,有很多文献对特征选择算法进行研究。Peng[2]较早地对信息度量准则下的特征选择算法进行了汇总,并进行了实验对比。Chandrashekar[3]对三类特征选择算法进行综述,但因为时间较早,并没有对特征选择算法进行系统的汇总,且没有系统的实验对比特征选择算法的性能。Aldehim[4]从可靠性和有效性两个方面论证了特征选择算法,并且实验论证了All approach和Part approach两种框架的优劣,但其并没有从三类特征选择算法的角度进行对比分析。
在以往的文献中虽然有特征选择方法的综述,但并没有对特征选择算法进行系统性的实验和性能对比。本文的主要内容及创新点有:第一,本文对特征选择算法进行分类综述,不仅介绍了相关原理并且在性能方面进行了相关对比;第二,使用较新的视频流量数据集进行实验;第三,设计了一种多级分类器,使用特征选择算法对网络视频流进行细分类,从运行时间、特征压缩率,以及总体分类准确率三个维度对特征选择的算法进行了对比实验,并对实验结果进行了分析,得到网络视频分类中较为重要的特征。
本文剩余部分组织如下:第2章,对三类特征选择算法进行综述,介绍算法的大体原理及优势和劣势;第3章说明了实验环境及数据的分布,对七种特征选择算法进行性能评估;第4章,结论。
2 三类特征选择方法
本文按照特征选择方法与后续学习算法的关系以及评价准则分成三类:过滤式(Filter)、包裹式(Wrapper)、嵌入式(Embedding)。
2.1 过滤式(Filter)特征选择算法
Filter特征选择算法通常对特征采用一些特定的标准以此来评估特征的重要程度,对特征排序,设定阈值,就可选出特征子集。由于它与学习算法无关,这就使得它较为高效。在过去几十年里,有多种过滤式特征选择方法的评价标准被提出,大致可分为四类:距离度量、信息度量、相关性度量、一致性度量。
2.1.1 距离度量
距离度量利用距离标准来衡量特征间的相关性,可以认为是一种分离性,差异性,或者辨识能力的一种度量。一些重要且常用的度量方式[5],有欧氏距离、S阶Minkowski测度、Chebychev距离、平方距离等。典型的使用距离度量的算法有Relief[6]算法及其变种ReliefF。以处理多类别问题为例,每次从一个训练样本集中随机抽取一个样本R,然后从R的同类的样本集中找出R的k个近邻样本(near-Hits),从每个R的不同类的的样本集中找出k个近邻样本(near Misses),然后更新每个特征的权重。如下式:
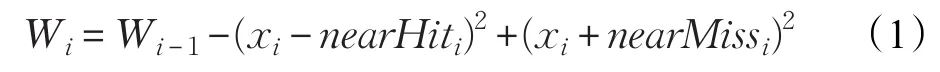
因此,当随机选择的样本的某个特征值与nearMiss相应特征值的距离比nearHit的样本距离小时,这个特征的权重就会被降低。此外,使用距离度量的评价标准的算法还有分支定界法和BFF算法[7]。
2.1.2 信息度量
信息理论的评价标准有很多种,因为它能反映不同变量之间所共有的信息量,使得所选择的特征子集与类别的相关性最大,子集中的特征的相关性最小。
BIF(Best Individual Feature)[8],是一种简单直接的特征选择方法,信息度量函数如下:

I(⋅)表示互信息,C表示类别标签,f为候选特征。它是对每一个特征计算与类别标签的互信息J(f),互信息越大的表示特征中所包含的类别标签的信息量越大。按照值的大小进行排列,选取前k个特征作为特征子集。这种方法计算量小,适于高维数据,但是它没有考虑特征间的冗余量,会带来较多的冗余特征。基于以上缺点,由Battiti[9]提出的一种使用候选特征f与单个已选特征s相关性对f进行惩罚的方法MIFS,其评价函数为:

其中β为调节系数。
由上述MIFS知,β需要设定,Peng[10]提出MRMR算法,从理论上分析了MRMR等价于最大依赖性,取β为已选特征数的倒数。基于最大依赖性,可通过计算不同特征子集与类别的互信息来选取最优化子集。但是,在高维空间中,估计多维概率密度是一个难点。另一个缺点是计算速度慢,所以文中就提出与其等价的最小冗余和最大相关,给出了一种互信息的评价准则。Lin和Tang[11]不仅考虑了特征间的冗余度最小,还考虑了已知类标签的情况下已选特征和候选特征的条件冗余度最大,即在已知已选特征集S的情况下通过候选特征f与类别C的依赖程度来确定f的重要性,其中条件互信息I(C;f|S)越大,f所能提供的新信息越多。因为I(C;f|S)的计算费用较大,样本的多维性导致了其估值的不准确,Fleuret[12]提出的条件互信息最大化算法中采取一种变通的形式CMIM算法,即使用单个子特征s来代替整个已选子集S来估算I(C;f|S),其中s是使得I(C;f|S)值最大的已选特征。
2.1.3 相关性度量
相关性度量的评价标准可以反应两变量之间的相关性,这样在特征选择中就可以去除特征间冗余的特征,而保留与分类结果相关性较大的特征。这类算法中分为有监督和无监督算法。
其中最简单的标准是Pearson相关系数[13],它可以反应特征与标签的线性相关性。除了简单的Pearson系数外,还有常用的Fisher系数、卡方系数、Gini系数。Laplacian系数也是一种相关性特征选择方法,但它最大的不同在于它是无监督的特征选择,这也使得它能够较好地保留数据的结构,这个算法比较有效地衡量了各个特征的权重,但是它没有衡量各个特征之间相互的冗余度,有可能会选取冗余特征。
CFS(Correlated Feature Selection)算法[14]是一种较常用的利用相关性度量的特征选择方法,CFS的基本思想是使用启发式搜索,搜索特征子集,然后利用相关性对特征子集进行打分,选出较好的特征子集。
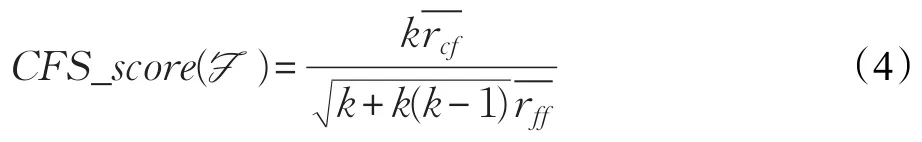
这里CFS_score(F)是有k个特征的特征子集F的启发性值。-rcf为特征与类标签的平均相关系数,-rff为特征与特征之间的平均相关系数。式中分子代表特征子集的预测能力,分母代表特征间的冗余度。Nie提出的迹比准则(Trace Ratio Criterion)[15]直接选出全局最优的特征子集,特征的重要性由迹比准则的值来衡量,此外它还为一类特征选择算法提供了大体框架,不同的亲和度矩阵,会产生不同的特征选择算法,如批处理的Laplacian Scores和批处理的Fisher Scores。
2.1.4 一致性度量
不一致率作为一致性的度量,可以衡量特征集合的优劣。不一致率的定义[16]如下:

式中,P为总的样本数;Nin表示不一致数。不一致率是一种单调的度量方式,并且相较于其他度量方式,它是对子集进行评价,计算简单,能够快速去除冗余和不相关的特征,从而获得一个较小的特征子集,但它对噪声数据敏感,且只适合离散数据,连续数据需要提前离散化。典型的利用一致性度量的算法有:LVF[17]、FOCUS[18]。
2.2 包裹式(Wrapper)特征选择算法
Wrapper模型将学习算法作为特征选择算法的一部分,并且直接使用分类性能作为特征重要性程度的评价标准,最终将选择的子集用于构造分类模型。该方法所选特征子集较为准确,但所用时间较长。
此类特征选择方法常使用快速的搜索算法,选出特征子集并输入分类器中。如Hsu等人[19]使用遗传算法搜索特征子集,并用决策树的分类准确率作为评价指标,选取准确率最高的特征子集。Dai等人[20]将SVM分类器与PSO算法结合,提出了一种快速特征选择的方法。
为了更快的特征选择同时保证特征选择的准确,往往将Filter方法和Wrapper方法相结合,先使用Filter方法在原始特征集中选出特征子集,然后输入到Wrapper方法中,从而选出满足分类器的最好的特征子集。如Alamedine等[21]提出的将ReliefF算法和PSO算法结合,得到了一种快速的Wrapper算法。
2.3 嵌入式(Embedded)特征选择算法
Embedded类特征算法结合了Filter和Wrapper类的优点,利用分类器内部的参数对特征进行排序,这样就有效地结合了分类器的性能同时提高了运算效率。大体将嵌入式算法(Embedded)分为三类。
2.3.1 Pruning方法
初始使用全部特征进行训练,然后将相关系数为小的特征缩减,同时能够保证分类器的性能。典型的应用就是SVM-RFE。SVM-RFE算法就是根据SVM在训练时生成的权向量来构造排序系数,每次迭代去掉一个排序系数最小的特征属性,最终得到所有特征属性的排序。对于SVM-RFE算法,也有诸多缺点,该方法能够有效选择特征但缺乏对冗余特征的考虑,文献[22]给出了SVM-RFE with MRMR算法。每次迭代删除一个特征,为加快算法效率,每次循环可删除多个特征,如Ding提出的RFE-Annealing[23]算法。此外,Zhou等[24]提出了多分类问题的MSVM-RFE算法。
2.3.2 树结构模型的特征选择算法
对于树结构的学习算法来说,在搭建节点之前,需要先判断特征的好坏,以选择特征作为根节点,子节点,进而搭建整个树的结构。特征优劣大多以信息度量的方式评估,如信息增益率,基尼指数等。此外,对于树结构的学习算法,还有剪枝处理,就是在搭建树结构之前或之后剔除无关或对分类无益的特征。
2.3.3 正则化特征选择算法
其中常用的是利用Lasso进行特征选择。Lasso方法下解出的参数常常具有稀疏性,根据参数的稀疏性可将无用特征去掉。为了解决存在奇异解和最终得到的是局部最优特征子集的情况,Zou[25]提出动态的Lasso正则化,将正则项改写:

bi是给定的权重系数用来控制每个特征的贡献,可以看出它是一个带有权重的Lasso。此外,还有ElasticNet Regularization[26]解决了在特征数远远大于样本数的问题,它将l1和l2范数结合构成惩罚函数。另外还有多聚类特征选择方法(Multi-Cluster Feature Selection,MCFS)[27],它是一种无监督利用稀疏学习技术的特征选择方法,还有利用l2,1范式进行正则化的特征选择方法[28],它用来解决多分类情况下的特征选择算法。
3 实验
本文实验平台采用英特尔酷睿i5处理器,Win10操作系统,8 GB内存,视频流的特征提取使用Linux Shell脚本完成,数据处理及算法使用Python进行编程。
本文对网络视频流业务进行研究,选取具有代表性业务标清、高清、超清的Web视频流(YOUKU,iQIYI等网站),即时视频通讯(QQ视频),网络直播视频(CBox,SopCast等),P2P客户端视频(Kankan)以及Http下载视频共七种业务流进行分析。实验中采取真实网络中的流量,用Wireshark在不同时间段提取网络流,时间跨度从2013年11月到2016年7月,提取的报文样本以五元组(时间,源IP地址,目的IP地址,协议,报文大小)组成,每条视频流持续30 min,总共统计840条流,数据量有266 GB。从中筛选出有效的27个特征,作为候选特征。数据集的分布如图1所示,每个应用类中流的条数所占的比例。

图1 数据集分布
本文对前面所谈及的七种典型的特征选择方法进行比较来分析不同特征选择方法对于视频流识别的影响,以下是对七种特征选择算法的介绍,如表1所示。

表1 七种特征选择方法描述
3.1 评价指标
以下是本文实验采取的评价指标,对七种特征选择算法进行对比实验。
采用分类器准确率(Overall Accuracy,OA)来评判特征选择算法选择效果的好坏。

采用特征压缩率(Feature Compression Rate,FCR)来衡量算法对特征提取的效率。
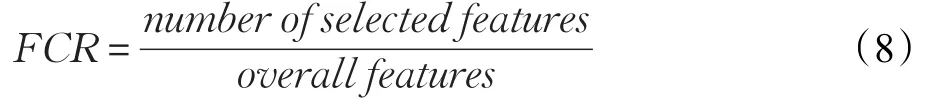
时间(Time):每种特征选择方法所运行的时间,使用每种算法的运行时间来考察其运行速度。
将实验分为两部分,首先对在线直播视频、在线非直播视频、P2P类视频、即时通信视频和Http视频下载流量5类流量进行分类作为实验1。然后将采用两级分类器分类方案对在线非直播视频流业务进行细分类,识别出标清(CD)、高清(SD)、超高清(HD)三种业务流,作为实验2。
3.2 实验1及结果分析
3.2.1 特征选择方法对比
首先使用七种特征选择方法对在线直播视频业务,在线非直播视频业务,即时视频通信业务,Http视频下载业务,P2P视频业务五种业务流进行分类。
由图2可以看出,CFS算法性能起伏较大,所选出的特征并不适用于所有分类器。但同为相关性评价指标的Laplacian算法的整体选择效果与其他特征选择算法大体相同,准确率都在95%以上。SVM-forward算法为Wrapper类算法,其选出的特征极大提高了SVM的准确率,属于Embedded类的Lasso算法的选择效果介于Filter类和Wrapper类之间。
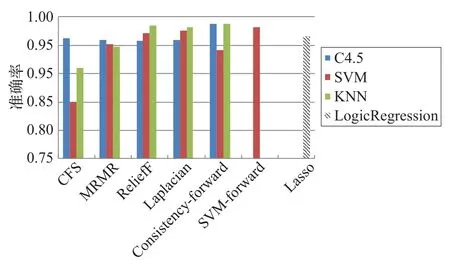
图2 七种特征选择算法准确率
由表2可以看出总体的Filter类别的特征选择算法的时间消耗最小,尤其对于Consistency-forward特征选择算法所用时间最小,因其复杂度较低,另外作为无监督的特征选择方法Laplacian算法运算时间也较低。对于Wrapper类的SVM-forward算法所用时间最大,相较于其他算法差了2~3数量级的时间。Embedded类的Lasso算法结合了Wrapper和Filter的思想,所用时间居中。
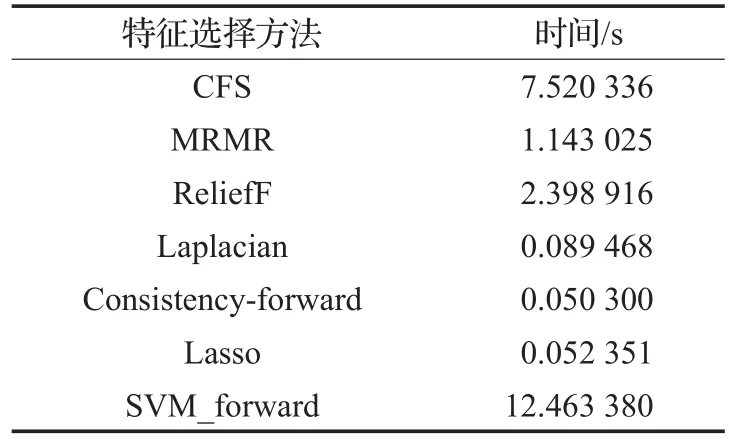
表2 七种特征选择算法运行时间
3.2.2 有特征选择和无特征选择分类对比
综合以上各个特征选择的分类准确率结果取平均,与无特征选择算法的分类准确率进行对比,如图3。
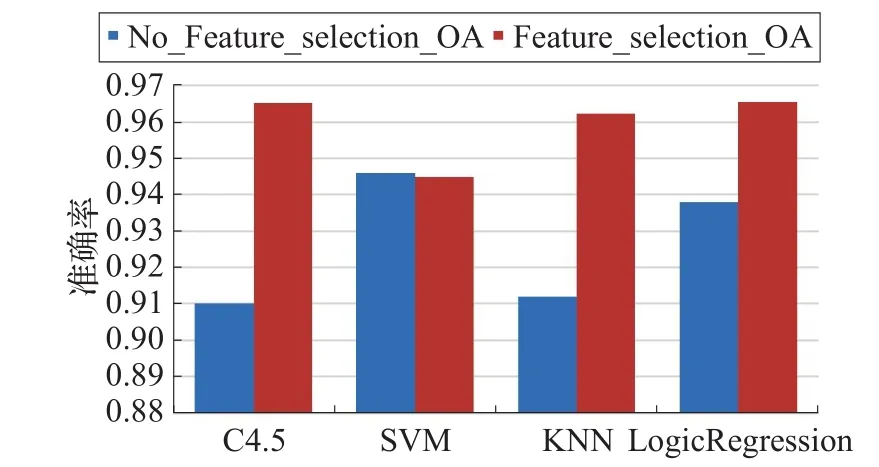
图3 无特征选择与特征选择的准确率对比
可以看出在特征选择后,C4.5、KNN、LogicRegression分类器的准确率都大幅度提高,而SVM的平均准确率与无特征选择的准确率相接近。
接下来进行时间对比,分类器分类时间包括训练时间(training time)和测试时间(testing time)。对七种特征选择算法在四种分类器所用的训练时间和测试时间分别取平均,从而得到每种分类器的平均训练时间和测试时间,与无特征选择的分类器进行比较,得到各个分类器训练时间和测试时间的缩减率,如图4。
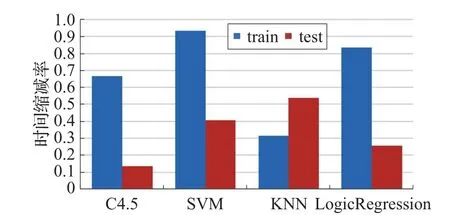
图4 训练时间和测试时间缩减率
可以看出,各个分类器在特征选择后,其训练时间还是测试时间都得到大幅地缩减,SVM的训练时间缩减了93%,而KNN的测试时间缩减了50%以上。
综合以上结果可以看出,特征选择算法不仅可以提高分类器的准确率,而且可以大幅降低分类器的负担,提高其运行效率。
3.3 实验2及结果分析
对在线非直播视频业务进行细粒度的划分,分为标清、高清、超高清视频。因为标清、高清,以及超清视频同属在线非直播视频,拥有相似的数据特征,直接将分类器对数据的所有类别分类并不容易,因此先将标清、高清、超清视频作为一大类,与其他视频流进行分类,然后再将在线非直播视频这一大类进行细分类,所以本文采用两级分类方案能够提高视频流分类的准确率。具体分类方案如图5。
首先在第一级分类中有:在线非直播视频、在线直播视频、即时视频通话、Http视频下载。第二级分类将在线非直播视频进行细分类,分成标清(SD)、高清(HD)、超高清(CD)。
实验中使用的两级分类器设计如图6。
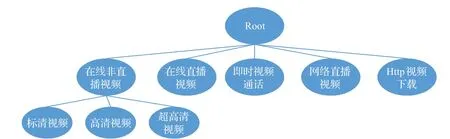
图5 两级分类方案

图6 两级分类器设计结构
将整个训练集的50%分为训练集,50%分为测试集,然后将训练集用于特征选择和分类器学习,随后将选择出的特征用于测试集,形成新的测试集输入到分类器1中,然后将分类器1预测出的待分类集——在线非直播数据集进行细分类,最后将分类结果汇总,统计出准确率。
首先将两级分类方案与不分级分类进行对比,在对比中不使用特征选择方法,可得如图7的各个分类器的对比图。

图7 分级方案与不分级方案对比
分级分类的好处在于先将边界特征明显的大类分出确保其准确率,再使用专门的分类器将小类分出。可以看出分级分类方案在各个分类器中的准确率均好于不分级分类方案。
图8是两级分类各个特征选择算法在四种分类器的准确率。
由图8可以看出,ReliefF算法、Laplacian算法在三种分类器中的表现均好,因此其选择稳定性较好。CFS在三类分类器中表现不稳定,且性能略差。Consistencyforward算法在三个分类器中的表现并不稳定,在C4.5和KNN算法中性能较好,而在SVM算法中性能略差。在所有特征选择算法中,SVM-forward算法得到的准确率最高。而Lasso达到的准确率相较于SVM-forward低了3个百分点,而相较于Filter类算法的平均值高了2.2个百分点。
图9是各个特征选择算法在各个分类器上的特征压缩率。
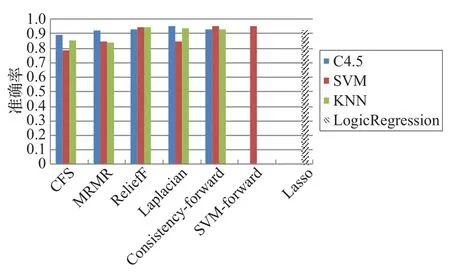
图8 七种特征选择方法两级分类准确率
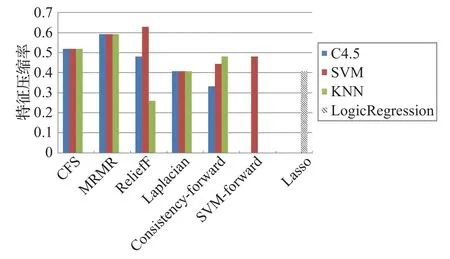
图9 七种特征选择算法特征压缩率
由于CFS和Consistency-forward直接选出特征子集并与分类器无关,因此其在每种分类算法下,选出的特征子集相同,可以看出它们在三类分类器中特征提取率相同。而其他算法均给出所有特征的排名,通过网格搜索算法,以准确率OA为指标,选择出最佳准确率的前m项特征作为特征子集。通过图9可以看出,ReliefF算法的特征压缩率随着分类器的不同变化较大,而MRMR的特征压缩率FCR较为稳定,说明其选出的特征具有普适性。而Laplacian算法的特征压缩率的平均值最小,因此它可以选出较小的特征子集。
4 结论
网络流细分类是QoS分级的关键,而对于要求高并发、低延时的网络流分类任务来说,特征选择是必不可少的环节,它能够提高分类效率以及分类的准确性。在以往的文献中虽然有特征选择方法方面的综述,但并没有对特征选择算法进行实验方面的性能对比。在本文中,介绍了特征选择的过程,并且对三类特征选择算法的发展及其优缺点进行了总结,最后通过实验分别在分类准确率、运算时间,以及特征压缩率上对比了七种三类特征选择算法的性能,并且对视频流量采用分级结构进行了细分类。此外,在特征选择方面,还有很多未确定的因素影响着特征选择的稳定性、可靠性;另外在参数选择方面例如选择特征数的确定还有待进一步研究。
[1] White paper:Cisco VNI forecast and methodology,2016—2021[EB/OL].(2017-09-15).http://www.cisco.com/c/en/us/solutions/collateral/service-provider/ip-ngn-ip-next-generationnetwork/white_paper_c11-481360.html.
[2] Peng H,Long F,Ding C.Feature selection based on mutual information criteria of max-dependency,max-relevance,and min-redundancy[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,2005,27(8):1226-1238.
[3] Chandrashekar G,Sahin F.A survey on feature selection methods[M].[S.l.]:Pergamon Press Inc,2014.
[4] Aldehim G,Wang W.Determining appropriate approaches for using data in feature selection[J].International Journal of Machine Learning&Cybernetics,2017,8(3):915-928.
[5] 姚旭,王晓丹,张玉玺,等.特征选择方法综述[J].控制与决策,2012,27(2):161-166.
[6] Robnikšikonja M,Kononenko I.Theoretical and empirical analysis of ReliefF and RReliefF[J].Machine Learning,2003,53(1/2):23-69.
[7] Xu L,Yan P,Chang T.Best first strategy for feature selection[C]//International Conference on Pattern Recognition,1988,2:706-708.
[8] Jain A K,Duin R P W,Mao J.Statistical pattern recognition:A review[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,2000,22(1):4-37.
[9] Battiti R.Using mutual information for selecting features in supervised neural net learning[J].IEEE Transactions on Neural Networks,1994,5(4):537-550.
[10] Peng H,Long F,Ding C.Feature selection based on mutual information:Criteria of max-dependency,maxrelevance,and min-redundancy[M].[S.l.]:IEEE Computer Society,2005.
[11] Lin D,Tang X.Conditional infomax learning:An integrated framework for feature extraction and fusion[C]//European Conference on Computer Vision(ECCV 2006).Berlin Heidelberg:Springer,2006:68-82.
[12] Fleuret F.Fast binary feature selection with conditional mutualinformation[J].JournalofMachineLearning Research,2004,5(3):1531-1555.
[13] Coelho F,Braga A P,Verleysen M.Multi-objective semi-supervised feature selection and model selection based on Pearson’s correlation coefficient[C]//Iberoamerican Congress Conference on Progress in Pattern Recognition,Image Analysis,Computer Vision,and Applications.[S.l.]:Springer-Verlag,2010:509-516.
[14] Hall M A,Smith L A.Feature selection for machine learning:Comparing a correlation-based filter approach to the wrapper[C]//FLAIRS Conference,1999:235-239.
[15] Nie F,Xiang S,Jia Y,et al.Trace ratio criterion for feature selection[C]//National Conference on Artificial Intelligence,2008,2:671-676.
[16] Dash M,Liu H.Consistency-based search in feature selection[J].Artificial Intelligence,2003,151(1):155-176.
[17] Liu H,Setiono R.A probabilistic approach to feature selection—A filter solution[C]//International Conference on Machine Learning,1996:319-327.
[18] Almuallim H,Dietterich T G.Learning with many irrelevant features[C]//National Conference on Artificial Intelligence.[S.l.]:AAAI Press,1991:547-552.
[19] Hsu W H.Genetic wrappers for feature selection in decision tree induction and variable ordering in Bayesian network structure learning[M].[S.l.]:Elsevier Science Inc,2004.
[20] Dai P,Ning L I.A fast SVM-based feature selection method[J].Journal of Shandong University,2010,40(5):60-65.
[21] Alamedine D,Marque C,Khalil M.Channel selection for monovariate analysis on EHG[C]//International Conference on Advances in Biomedical Engineering,2015:85-88.
[22] Zhang Junying,Liu Shenliang,Wang Yue.Gene association study with SVM,MLP and cross-validation for the diagnosis of diseases[J].Progress in Natural Science:Materials International,2008,18(6):741-750.
[23] Ding Y,Wilkins D.Improving the performance of SVMRFE to select genes in microarray data[J].BMC Bioinformatics,2006,7(S2):S12.
[24] Zhou X,Tuck D P.MSVM-RFE[J].Bioinformatics,2007,23.
[25] Zou Hui.The adaptive lasso and its oracle properties[J].Journal of the American statistical association,2006,101(476):1418-1429.
[26] Zou Hui,Hastie T.Regularization and variable selection via the elastic net[J].Journal of The Royal Statistical Society Series B-statistical Methodology,2005,67(5):301-320.
[27] Deng Cai,Zhang Chiyuan,He Xiaofei.Unsupervised feature selection for multi-cluster data[J].Knowledge Discovery and Data Mining,2010:333-342.
[28] Liu Jun,Ji Shuiwang,Ye Jieping.Multi-task feature learning via efficient L2,1-norm minimization[J].Uncertainty in Artificial Intelligence,2009:339-348.
WU Zheng,DONG Yuning.Contrastive analysis of features selection on network video traffic classification.Computer Engineering andApplications,2018,54(6):7-13.
WU Zheng,DONG Yuning
College of Telecommunications and Information Engineering,Nanjing University of Posts and Telecommunications,Nanjing 210003,China
Accurate identification and categorization of multimedia traffic is the premise of end to end QoS(Quality of Service)guarantees.Today,the dramatic growth of data volume takes challenge to network traffic classification.Therefore,using feature selection methods for multimedia flow identification and classification is particularly important in the big data era.This paper introduces related works on feature selection using identification and categorization of multimedia traffic,which is divided into three categories:Filter,Wrapper,Embedded and analyzes the performance of these methods.Then,this paper compares the performance of various feature selection algorithms using latest dataset from three aspects:The running speed,the feature compression rate and the feature selection accuracy.Besides,to improve classification accuracy,this paper proposes a hierarchical structure to reach fine-grained classification,according to the dataset.
features selection;video traffic classification;hierarchical classifier
准确,高效的业务流识别与分类是保障多媒体通信端到端QoS(Quality of Service),执行相关网络操作的前提。如今数据规模的剧烈增加为业务流的分类提出了挑战,而特征选择能够尽可能地减少特征维数,去除冗余特征,为大数据时代下的业务流分类提供解决办法。对现有的特征选择方法分成Filter、Wrapper、Embedded三类,分析了各类算法的性能原理。采用最新数据集对不同特征选择算法性能对比,从算法的运行时间、特征压缩率、准确率三个方面评估了特征选择算法的性能。另外,针对现有数据集分类情况进行分级分类以达到视频流的细分类,从而提高分类的准确率。
特征选择;视频流分类;多级分类器
2017-11-01
2018-01-24
1002-8331(2018)06-0007-07
A
TP391
10.3778/j.issn.1002-8331.1710-0342
国家自然科学基金(No.61271233)。
吴争(1994—),男,博士研究生,研究领域为多媒体通信,E-mail:1015010406@njupt.edu.cn;董育宁(1955—),男,博士,教授,研究领域为多媒体通信,网络流识别。
