生存分析、宏观经济变量与违约概率
2018-03-16莫易娴
莫易娴
(华南农业大学,广东广州 510642)
一、问题提出
宏观经济状态与违约概率之间有某种联系(Fridson;Garman,1997;莫易娴,2006)[1]。目前,贷款的系统性风险在企业的信用风险模型中有所体现,国内外个人信贷的违约风险评估主要探讨在某一固定时点是否会发生违约 (如判别分析)或发生违约概率的大小(如Logit模型以及Probit模型),无法将个人信用的动态变化在违约概率中表现出来。在研究网络贷款违约风险中,传统往往只单纯地将宏观经济指标作为协变量,并未考虑宏观经济指标的时变交互特征(vandell,1993;Zandi,1998)。 国外研究达成共识的是以 Logistic 回归的传统模型不能给出违约概率的动态预测值,且反映经济形势的宏观经济变量也不能纳入模型中。
国内外个人信贷的违约风险评估主要探讨在某一固定时点是否会发生违约(如判别分析)或发生违约概率的大小,无法将个人信用的动态变化在违约概率中表现出来(李曙光(2003)、崔媛媛(2005)、莫茜(2008)、郑星(2009) 帅理(2012))。生存分析模型能够将不同的宏观经济变量以时变相依的协变量的形式引入生存分析模型,提高了模型的拟合优度以及测试样本集违约概率预测的精度 (Thomas,2001)[2]。
二、理论机理
(一)生存分析理论机理
生存分析现已成为热门的统计分支。它是一种动态的分析方法,生存分析以“时间—事件(Time-to-Event)”资料为研究对象,将时间维度纳入了因变量或自变量中,定义因变量为个体持续处于“非失败”的时间,该理论方法主要是通过构建生存模型(生存函数、概率密度函数等),计算出各个时间点上的危险率即所研究的对象的生存时间和它发生状态转变的可能性,分析各个不同因素对两者的影响程度。在生存分析中,主要有三类生存模型:参数法、非参数法和半参数法。
生存分析方法最早用在生物医学方面,后来渗透到其他各个行业。生存分析在信用评分领域应用的历史比较短,但由于其自身的优点,近年来得到业内学者的广泛关注。生存分析在金融研究中的应用起源于Lane,Looney et al(1986)。近二十年越来越多的学者使用这种方法,最广泛运用的领域是在金融风险和 IPO。 LeClere(2000)做了一个述评,还包括 Lane et al(1986),Whalen(1991),Chen and Lee(1993),Abdel-Khalik(1993)Ongena and Smith(2001),Manigart et al (2002),Cameron and Hall (2003),Audretsch and Lehmann(2005),Jain and Martin (2005),Wheelock and Wilson (2005)and Yang and Sheu(2006)。
Narain(1992)首次将生存分析方法应用于消费信贷领域。Narain指出生存分析方法不仅适用于消费信贷,对于其他的贷款领域都具有一定适用性。Banasik(1999)[3]等用Cox模型来预测借款人违约或提前还款的时间。Thomas等(1999)[4]作了进一步研究,将指数模型、Weibull模型、Cox非参数模型与Logistic回归方法进行了比较,发现生存分析方法完全可以与传统Logistic回归方法相比,有时甚至优于Logistic回归。作者认为weibull模型、指数模型、Cox比例风险模型改进了最简单的生存分析模型。
Stepanova 和 Thomas(2001,2002)[5]利用 PHAB(Proportional Hazards Analysis Behavior Scorings)模型进行行为评分研究,结果显示PHAB模型不仅可以预测风险还可以预测利润。2002年Stepanova和Thomas又研究了用于个人信用评分的Cox模型的三种扩展形式,再次证明Cox模型在预测风险和预测利润方面的有效性。在利用生存分析方法进行信用评分上,他们提出了三个改进:对变量属性分类的Coarse-classifying分类方法;提出了多个检验模型拟合度的方法;强调反映贷款者信息的数据,不管是贷前信息还是贷中信息,都是在不断变化的。
Baesens,Stepanova 和 Vanthienen(2005)[6]认为神经网络生存模型克服了比例风险模型要求输入函数形式是线性的缺点,将神经网络生存模型与比例风险模型两种方法的性能进行了比较。Samuel Glasson(2007)利用生存分析方法构建了 Buckley-James模型,该模型具有非线性方法和多元自适应回归方法的优点,在实证研究中显示了很好的预测能力和解释能力。J-KIm,DWApley,C Qi和X Shan(2012)认为现有信用评分模型未能考虑随时间变化的动态经济数据,因此引入了一个含有时间依存机制的修正的比例风险生存模型,通过对大样本的实证分析证明了包含有时间依存机制的生存模型能够提供更准确的信用风险。Edward N.C.Tong等(2012)利用英国个人贷款投资组合数据建立了混合生存模型,并且和Cox比例风险模型和logistic回归模型的判别能力进行了对比,结果表明三种方法的判别精度都是不错的,但混合生存模型对于固定观察期的客户违约时间预测准确性更好。此外,混合生存模型还可以估计出不同时间违约的借款人的参数特征。
相对于国外来说,国内将生存分析运用在风险管理上的历史还比较短。顾银宽,林钟高(2004)分析了生存分析方法在企业信用风险分析中的可行性。宋雪枫,杨朝军,徐任重(2006)[7]将杜邦分析法与生存分析方法结合使用,对我国上市公司建立了信用评分模型。宋雪枫等人将生存分析信用评分模型与Altaian模型和Ohlson模型的预测效果进行对比,结果表明生存分析模型具有时间序列、无需样本配对、中远期预测能力强等优点。吴俊(2008)研究结果表明生存分析方法可以有效预测客户发生违约的概率。白鹏飞,段倩倩,李金林(2012)[8]构建了混合分布下的信贷生存模型,该模型能够及时有效的管理该类信贷风险。
总结:相对于传统的信用风险管理模型,生存分析是研究生存时间和生存状态与各影响因素之间关系的方法,由于其对样本分布假设要求较少,能够很好的处理定性指标等优点,所以逐渐将其应用于信用风险评估的领域。生存分析方法相对于其他信用评分方法来说,不仅可以估算贷款申请人的信用得分,而且可以预测贷款人的违约时间,为银行提供了贷前贷中双重风险控制手段,使银行能够提前采取预防性措施,降低贷款风险,而且能够对违约的时间进行预测,相对于目前己有的金融机构信用评分模型,生存分析具有一定的预警能力。
(二)Logistic模型的理论分析
从图1中可看出,银行可以预测申请人是否对银行的广告邮件有所反映,是否使用贷款的设施,经过一段时间后是否转到其它银行,或者从其它银行购买金融产品,可以在发邮件之前预测或者在提供金融产品前预测。当借方接受贷款设施,所有的不确定因素之前都要涉及到。
1.银行贷款决策图
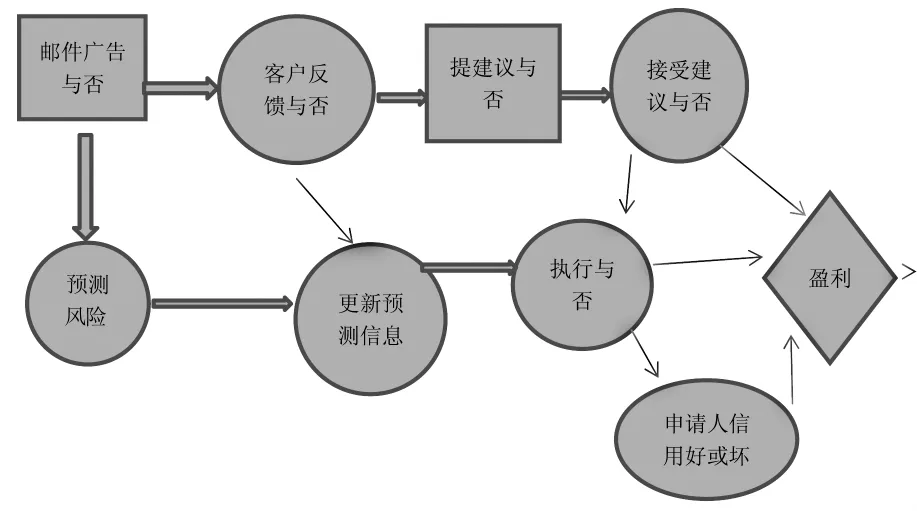
图1 银行贷款决策图
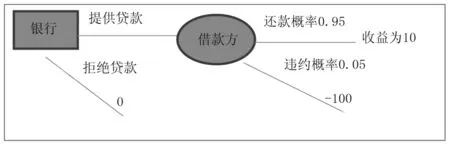
图2 银行贷款分析
如果借方按时还款收益为10,如果不还款损失为100,设违约概率为5%,则还款概率为95%
0.95 ×10+0.05×(-100)=4.5
4.5 大于0,所以银行贷款是正确选择。
又假设违约概率为10%,则还款概率为90%
0.90 ×10+0.10×(-100)=-1
此时,银行应该拒绝贷款。
如果把问题一般化,假设银行贷款给借方利润为g,l为违约的损失,P是按时还款的概率,1-p就是违约概率。
当 pg+(1-P)(-l)>0,银行就愿意贷款给借方。 即 p/(1-p)>l/g
2.Logit回归模型原理及优点
信用评分模型的特征取决于信贷类型、信贷金额和信用目的。通常用于不同的信用评分模型因素如下:现在的住址、家庭状态、申请人的年收入、信用卡、银行账户类型;年龄、职业类型、贷款目的、婚姻状况、银行卡开卡时间、目前单位就业时间、每月债务 (Hand,Henley,1997;Henley,1997;Caouette,Altman,Narayanan,1998;Caouette,Altman,Narayanan,1998;Desai et al.Desai et al,1996;1996;Koch,Koch,MacDonald,2000).MacDonald,2000)。
有学者认为把经济状态融入信用评分模型中,一种方法是通过开发不同经济状态对应不同的信用评分模型或者开发融入经济状态的信用评分模型(托马斯 2000)。Avery,Calem,Canner(2004)说未考虑信用评分中的经济情况可能会影响信用评分模型的准确性,并导致相应的风险。他们建议模型应该包括经济和个人环境的信息,他们的研究结果表明失业率与违约概率有关,高收入地区与低收入地区的违约概率不同。
对于信用的两分类问题,Logistic回归对训练样本只要求表述成好坏两类客户人群,而结果却能得到精确的分值,实际上这个分值被认为是属于好或坏的概率(杨静2008)。而其他的方法则很难给出分值,即使勉强给出也会由于带有较强的主观性以及过分依赖专家经验而导致较低的可信度(Preqibon 1981)。相对于其他方法而言,Logistic回归的分布假设比较少,是一种部分分布法,具有一定的稳健性,对变量分布的要求也比较宽松,适用的范围广泛。在处理定性数据上有一定的优越性,对于离散指标和连续指标在处理方法上是一样的,这是 Logistic回归最为突出的优点(Landwehr 1984)。
假设 p(s)是还款的概率,违约率就是 1-p(s),g0是无违约率时的收益,客户不违约,则银行增加收益为g1,l0是违约时的损失,L1是违约时增加的损失,银行贷款的条件是:
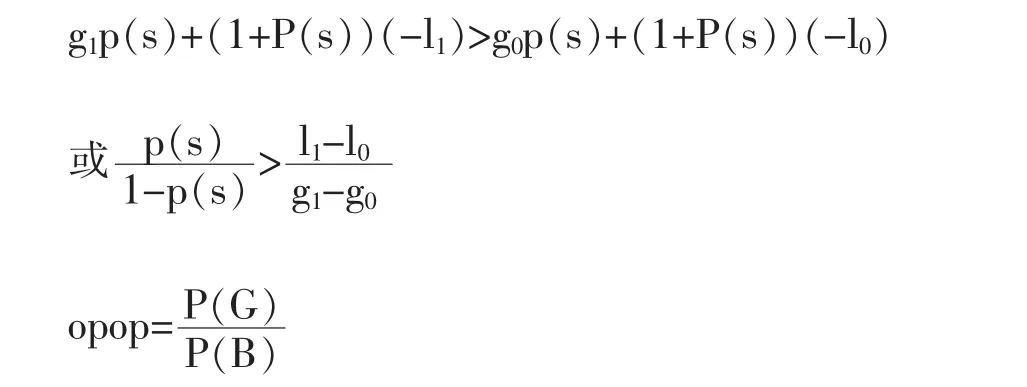
这个指标体现的是按时还款的概率,是当借款未发生之前得知的信息。
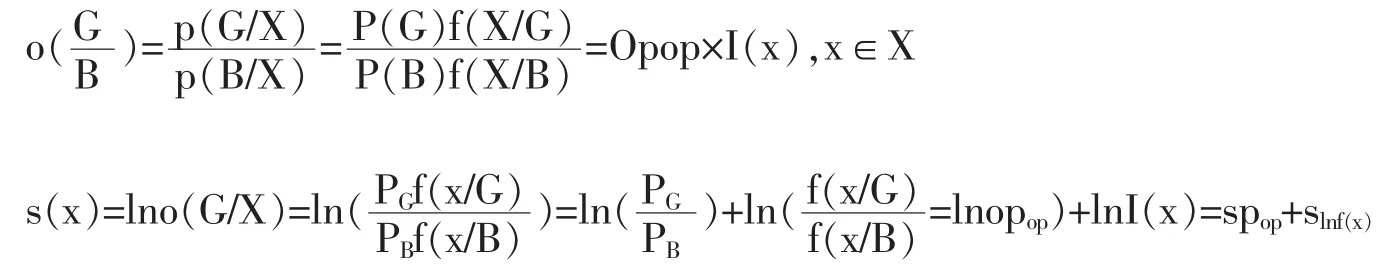
如果只有两个变量,假设它们是相互独立的,那么
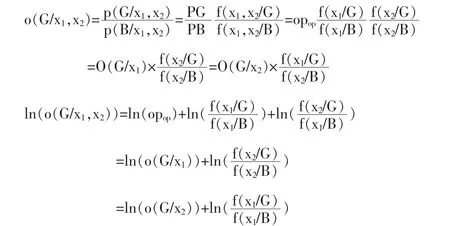
如果有 n个独立的特征变量 x1,x2,x3....有:
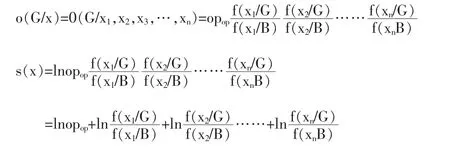
3.基于Logit回归方法的个人信用评分模型构建(1)Logit回归模型介绍——建立一般线性模型

对于0-1变量Y(此处为Y取0或者1)

(2)为简化模型,对P进行Logit变换
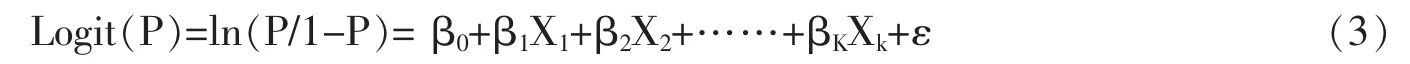
本文用W=P/1-P表示事件发生与不发生的概率,我们将客户发生逾期还款的情况定义为事件的发生。
(3)假设有10个X变量,用以下Logit模型进行回归
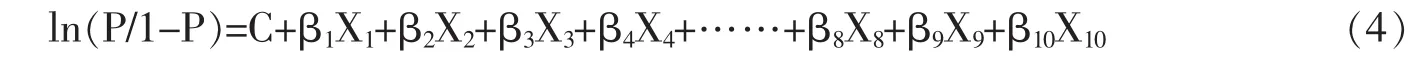
三、P2P网络贷款违约风险实证研究
1.指标的选取及预处理
影响偿还贷款的因素有很多,本文数据来源于广东肇庆、梅州、河源某县当地农村金融机构获取的农户个人小额贷款数据。以一年贷款为例,如果她违约超过2个月60天,客户是“坏”,否则是“好”用这种标准选取以下个人信用状况密切相关的个人基本信息作为特征变量,建立Logistic模型,为了与生存分析相对比,如果账户取消了或者超过观察期,被认为是审查。无法还款可能有各种原因,有些可能确实无力偿还,而有些可能是想要扩大生产等等。明确区分的话将十分复杂,因此,本文统一将到期没有还款的贷款个人定为劣质客户。
选取以下与信用状况密切相关的个人基本信息作为特征变量:性别(x1),年龄(x2),学历(x3),年度收入(x4),赡养人口数(x5),工作年限(x6),健康状况(x7),保险情况(x8),贷款用途(x9)、信用卡(x10)10 个变量作为自变量进入模型,客户质量(y)作为因变量。整个数据样本由620个组成,经数据清理后有效样本减少到600个。有效样本中坏账率为26%,好账率为74%。输入变量分为三个主要维度:(i)人口维度;(ii)社会经济维度;(iii)行为维度。
同时,为了在模型建立后能够对模型进行检验,另外抽取150户作为检验样本,其中劣质客户的比例占20%。
下面对特征变量进行分组。表1列出了所有10个变量的可能取值状况,利用统计学分析,可以得到各特征变量的特征项内优劣客户的分布状况,并计算出优质客户的发生比,对客户信用行为进行初步分析。

表1 特征变量的取值定义
(1)性别
在总计600个样本中,女性共计198个,其中优质客户占86.9%,优质客户发生比为6.61/1;男性有402名,优质客户发生比为1.11/1,女性对男性的优质客户发生比率=6.61/1.11=5.95。这说明,女性的违约风险要远低于男性。

表2 性别各特征项频率及发生比
(2)年龄
将年龄相邻的进行分组,初步分为30岁以下,31~35岁,36~40岁,41~45岁,46~50岁,51~55岁,56~60岁。根据样本特征一些年龄组所包含样本数量较小,将其合并在相邻组。最终得到表3。
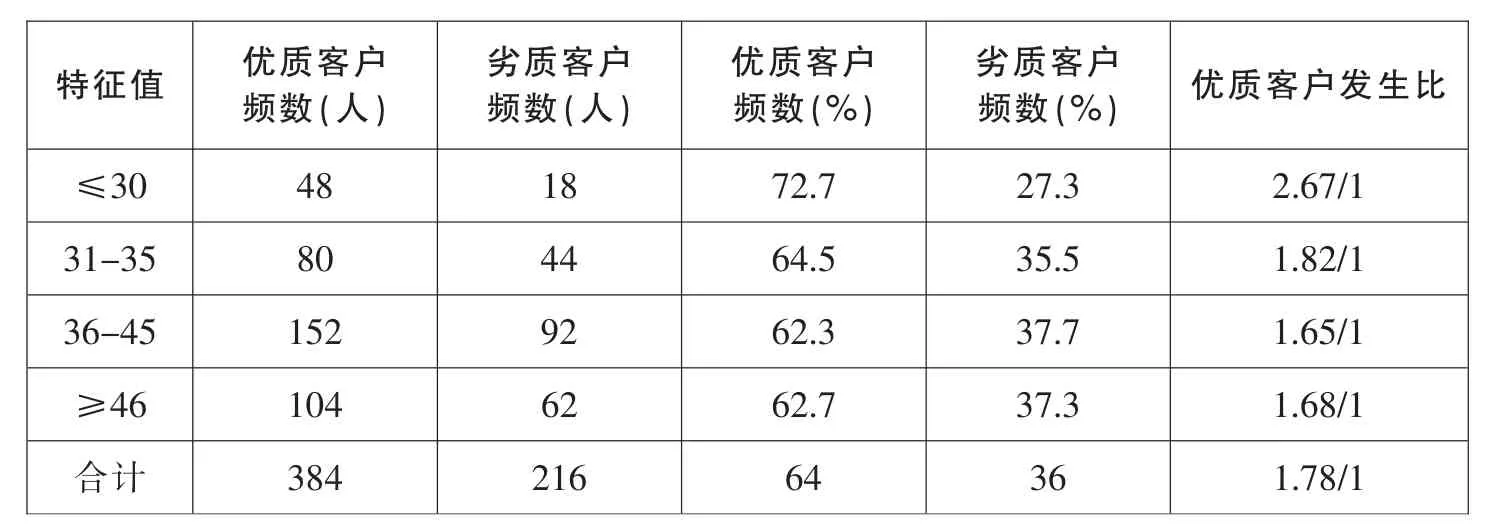
表3 年龄各特征项及发生比
(3)学历
通过对学历进行分组,划分为高中以上,初中,小学以下。具体各特征项数据见表4,从表中可以看出,学历高的个人明显违约风险比学历低的个人要低。
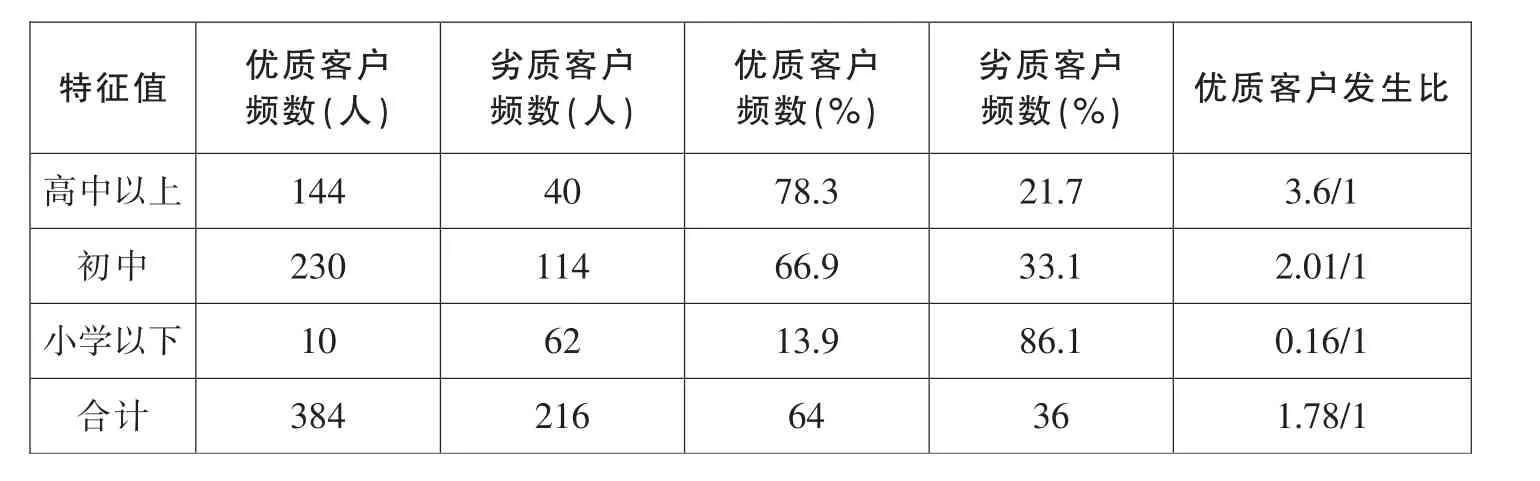
表4 学历各特征项及发生比
(4)年度收入
收入是一个连续变量,由于1万~2万(不含2万)部分人数过少(仅16人,优质客户发生比 0.45/1),因此将其并入1万以下(52人,优质客户发生比0.73/1)部分。这样最终分为3类。分析的结果见表5。从中可以看出,收入和个人的违约风险基本呈反向变化关系。
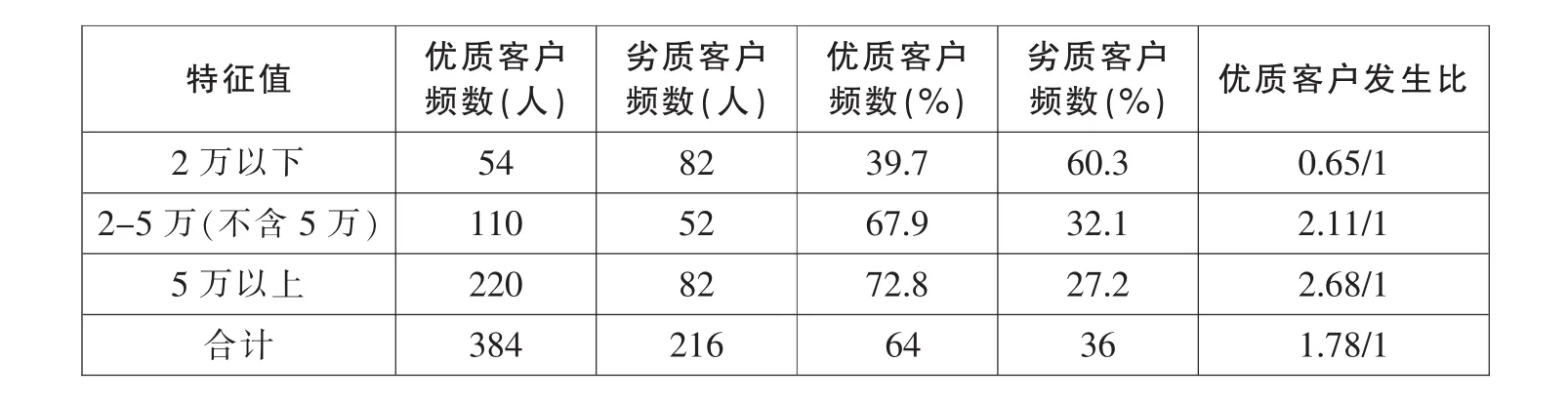
表5 年度收入各特征项及发生比
(5)赡养人口
从表6可以发现,赡养人口越多,个人负担越重,还款压力也就越大,然而无赡养人口的发生比却较小,也许太年轻,还款信用意识不强,导致其发生比反而没有赡养1~3人的个人发生比高。
(6)连续工作年限
连续工作年限指的是个人即将进入行业的工作年限。分析结果见表7,个人从事行业时间越长,则其对本行业相应的也会越熟悉,优质客户的比例也越高。
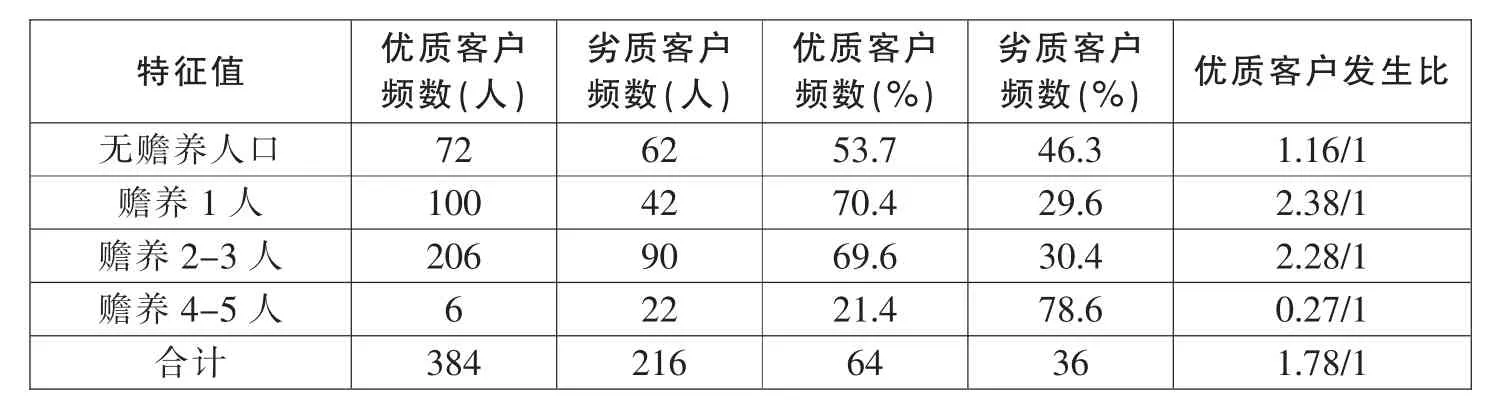
表6 赡养人口各特征项及发生比

表7 连续工作年限各特征项及发生比
(7)健康状况
从表8中看到健康良好的个人,好客户比例要高于健康一般的客户。
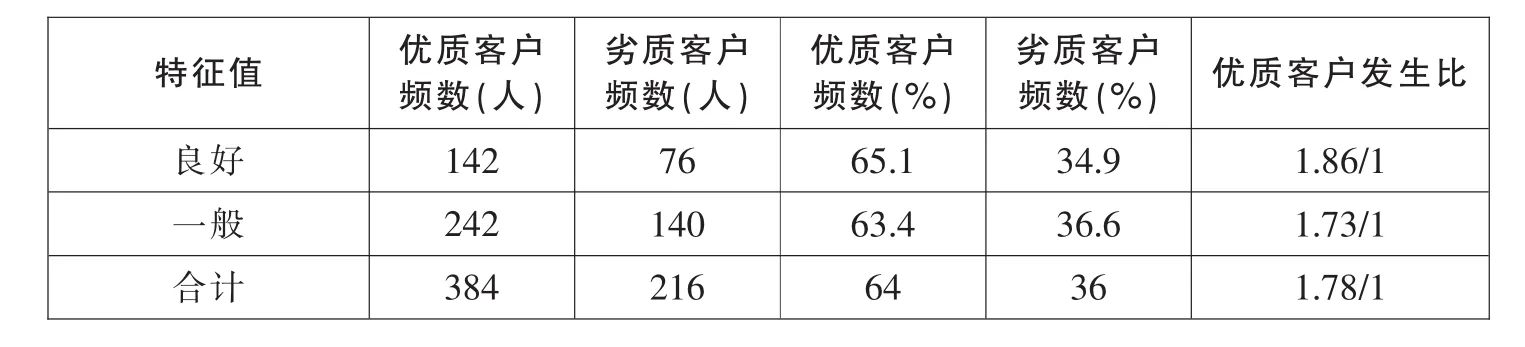
表8 健康状况各特征项及发生比
(8)保险情况
分为有保险和无保险两类,其结果如表9。
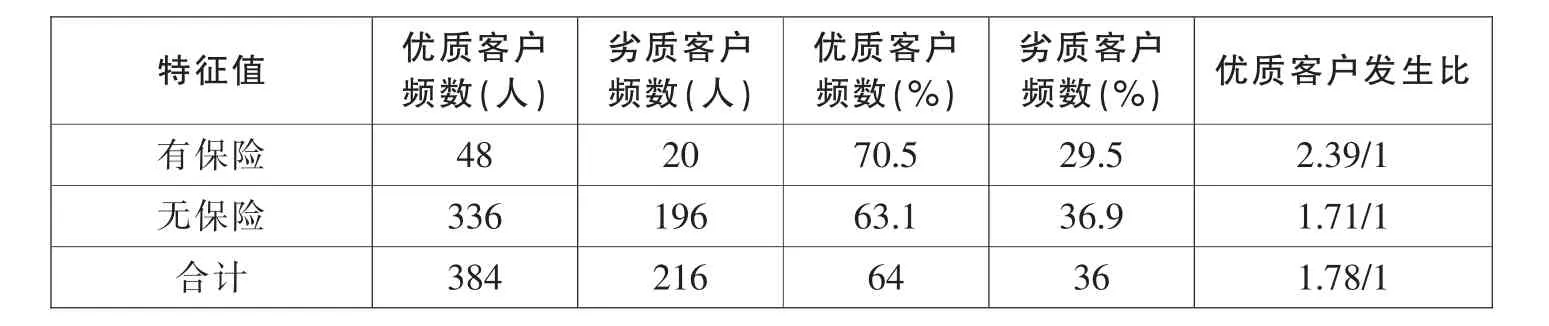
表9 保险状况各特征项及发生比
(9)贷款用途
主要包括种养业贷款,购农业机械贷款,餐饮服务贷款,其他贷款。其结果如表10。从中我们可以看出,传统的种植养殖业个人贷款最多,同时好客户比例也最大,而其他的各行业则相对较少。
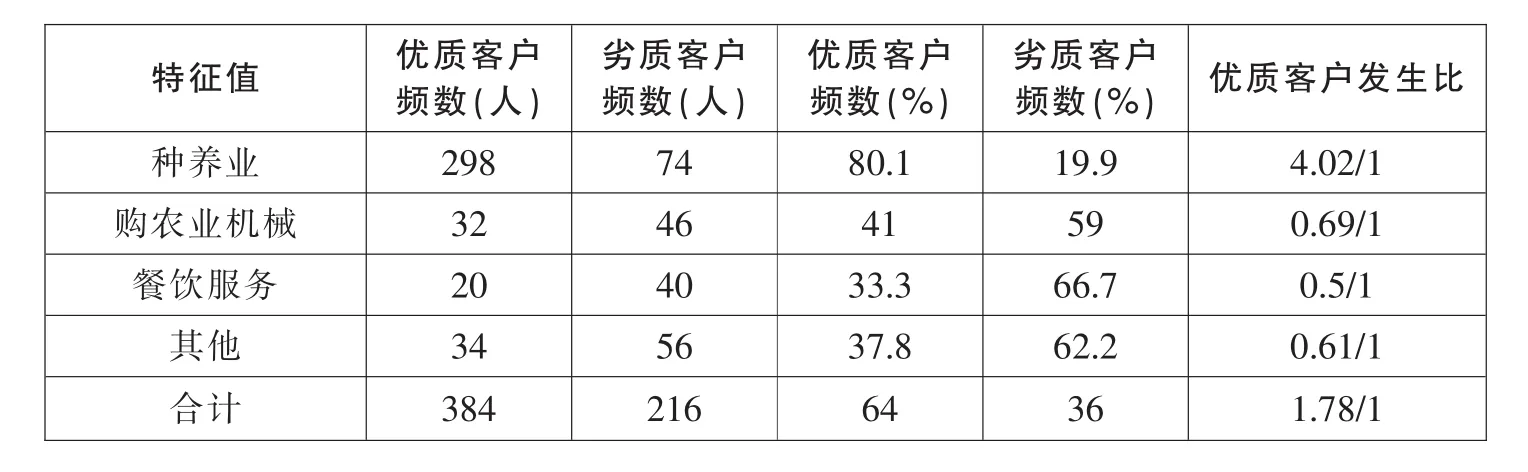
表10 贷款用途各特征项及发生比
(10)信用卡
根据样本数据统计计算信用卡各特征项及发生比如表11所示。
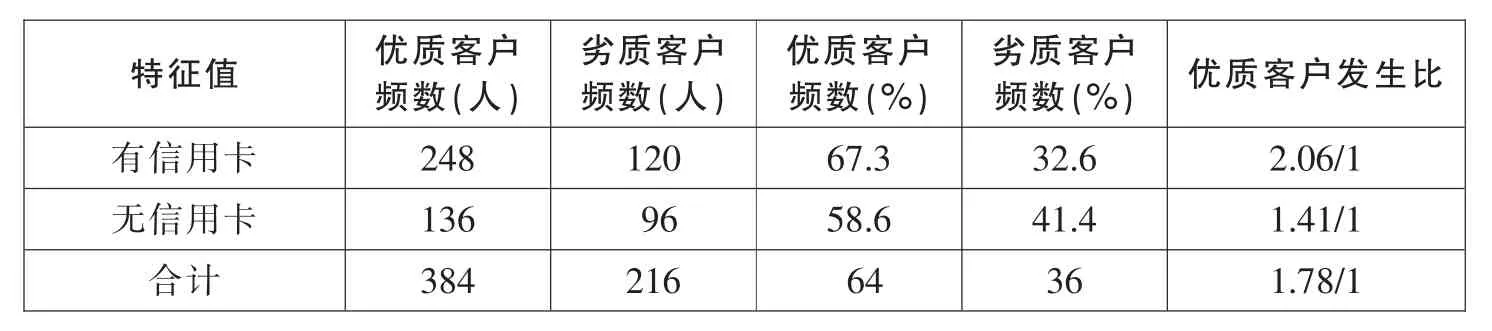
表11 信用卡各特征项及发生比
2.Logistic模型的构建
借助SPSS统计分析软件,利用logistic回归模型对信用指标进行回归分析,筛选出对模型有显著贡献的6个指标作为建模的初始变量,这几个变量的显著性均小于0.05,显著性比较强。其中的Wald统计量越大表明该自变量的作用越显著,最终保留的六个特征变量的Wald值都比较大,因此都通过显著性检验。Logistic回归模型的最终表达式为:
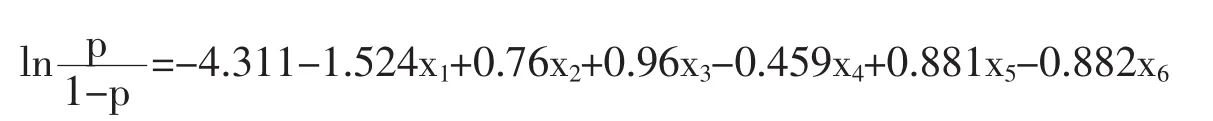

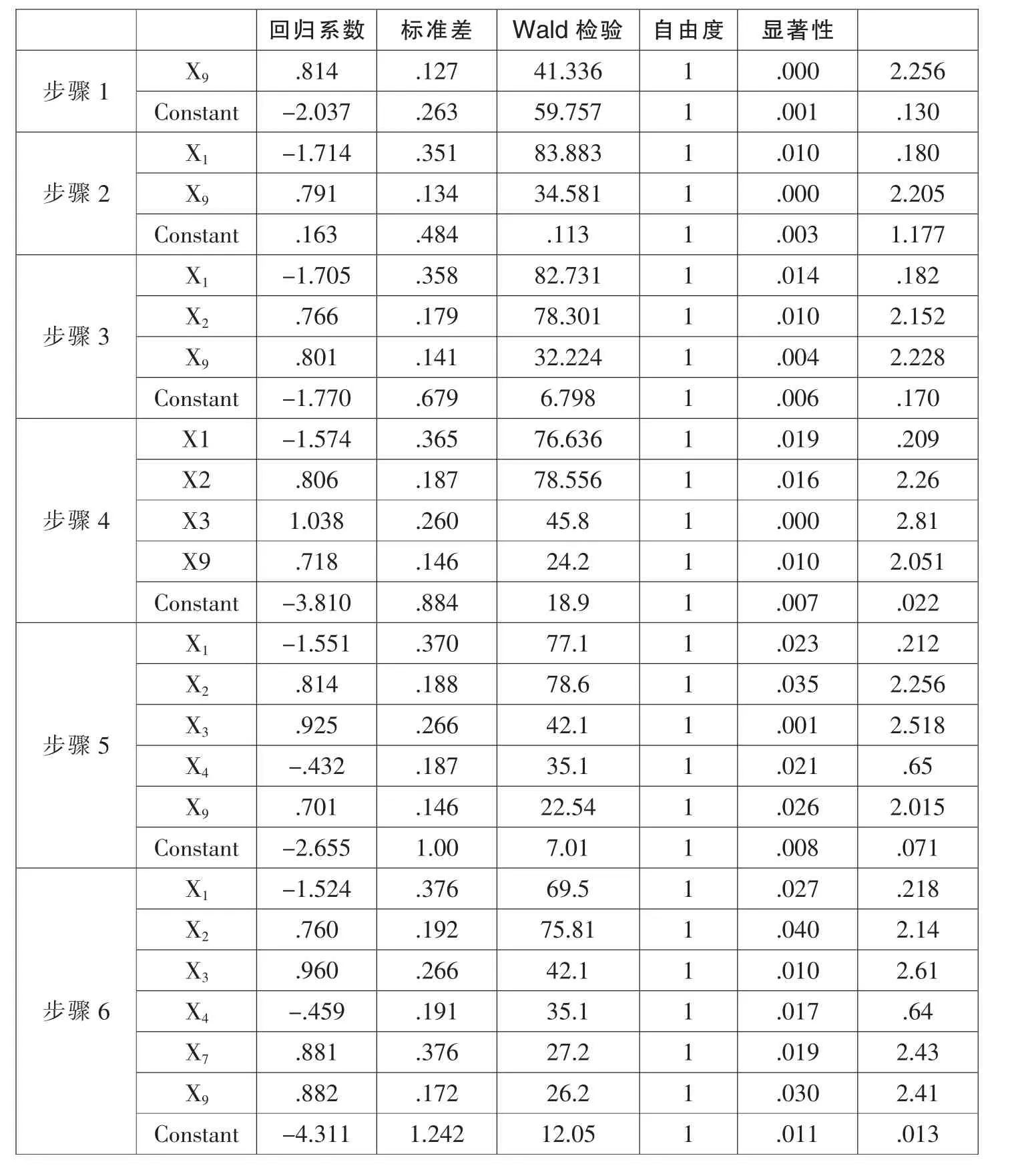
表12 方程中的变量
采用0.5的概率界限,对训练样本检测。总准确率为88.7%,将优质客户判断为优质客户的准确率为90.1%,而将劣质客户判断为劣质客户的准确率为86.1%,拟合效果较为理想。
本文利用另外的135户的数据进行检验。将这135户检验样本带入上述方程(公式3),以0.5为界判别,得出信用程度预测结果如表13所示:
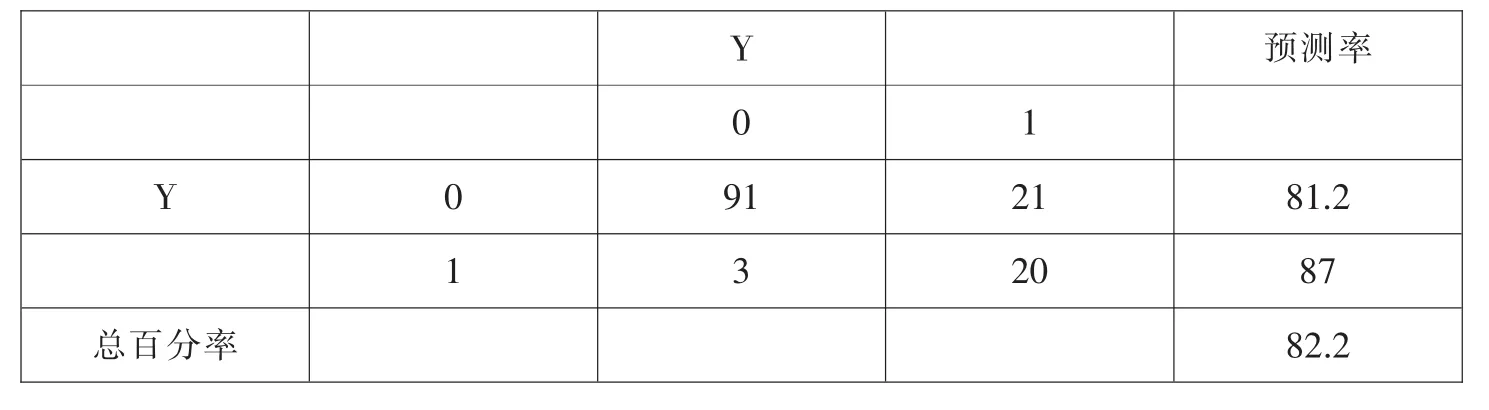
表13 模型预测检验结果
从上述结果可知,模型总判别准确率达82.2%,将优质客户判断为优质客户准确率为81.2%,将劣质客户判断为劣质客户的准确率为87%。因此,模型的实际应用效果较好,具有一定的应用价值。
3.生存分析实证
使用COX模型采用基于偏极大似然估计,经过后向回归剔除不显著的变量,剩余通过显著性建议的变量是性别、年龄、学历、年度收入、健康状况、贷款用途、信用卡。其中,危险率Exp(B)小于1的仅有信用卡1个变量,其余的危险率均大于1。
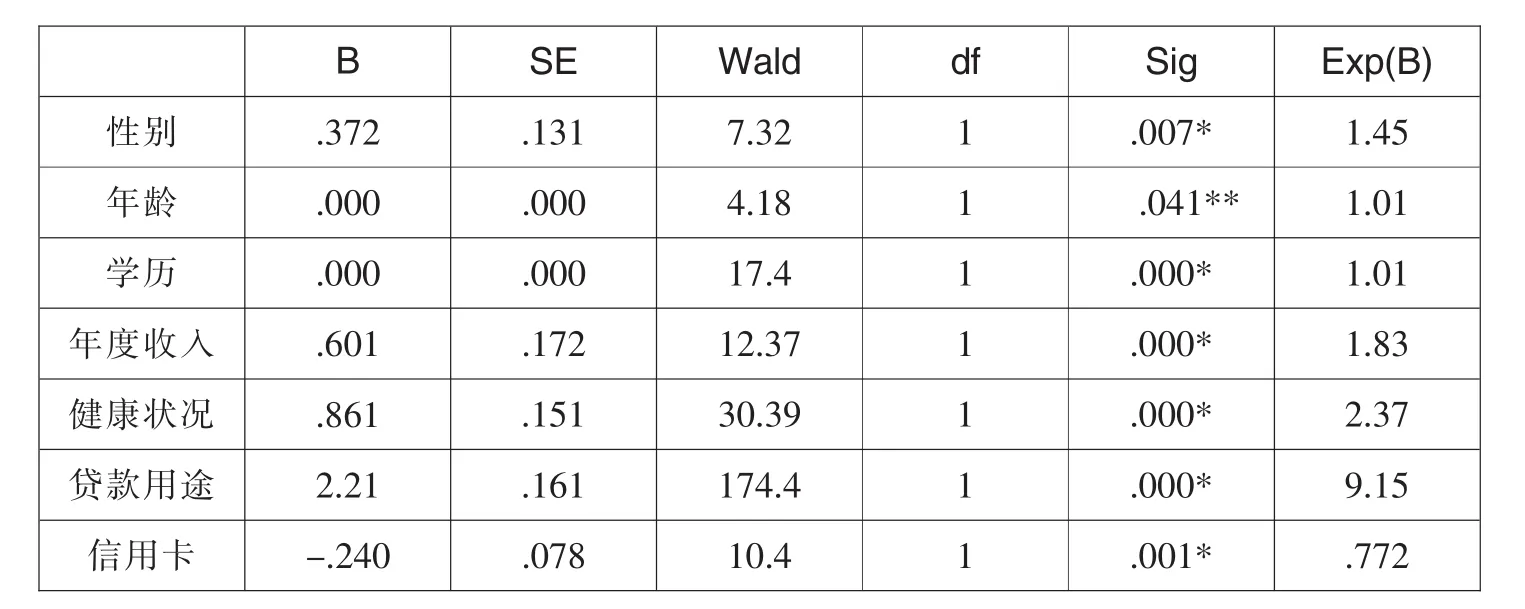
表14 协变量参数估计的结果
将所有样本随机抽取为训练样本和测试样本集,对训练样本集,第1类误判指的是将“坏”人错分为“好”人,即拒真,第2类误判指的是将“好”人错分为“坏”人,即纳伪。
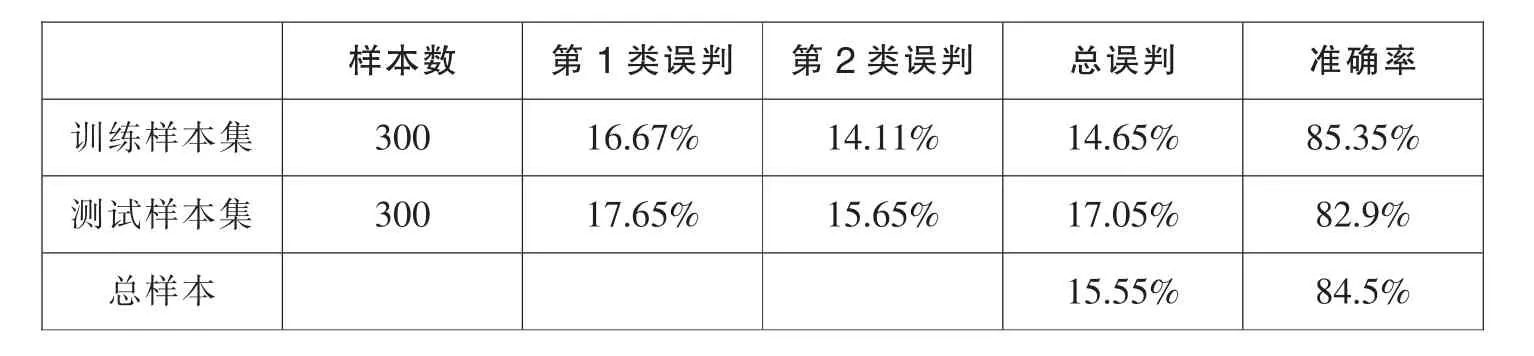
表15 分类准确率
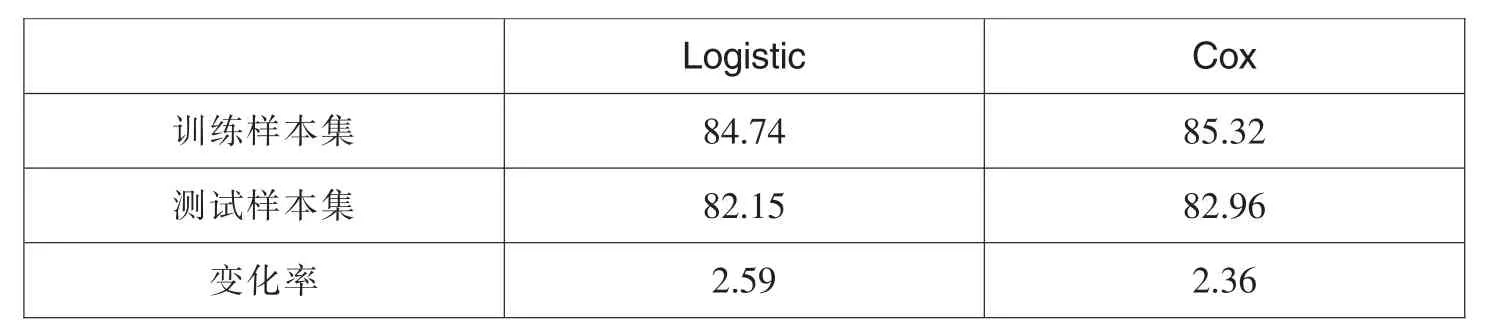
表16 Cox模型与Logistic模型回归方法准确率比较
稳健性较好的模型在对训练样本以外的样本进行预测时,其预测精度不应该有较大幅度的下降(石庆众等,2004)。观察表16的数据,可以对模型的稳健性做一个比较,Cox模型的稳健性比Logistic模型回归更好,并且准确率也更高。
本论文分析为研究个人贷款风险提供理论分析的依据,根据相应的定量分析可以为信贷决策提供支持,并且得到以下的结论:性别、年龄、学历、年度收入、健康状况、贷款用途、信用卡几个指标能较好地反映个人的信用级别状况,个人的年度收入在一定程度上可以反映网贷个人的违约风险。
4.加入宏观经济变量的COX比例危险模型
宏观经济变量作为时变变量加入到COX比例危险模型,考察网贷信用水平受宏观经济的影响。 依据文献(Bellotti&Crook,2007),时间函数 g(t)的选取采用常用的经验形式,即时间对数的函数形式ln(t)。此时,有公式:
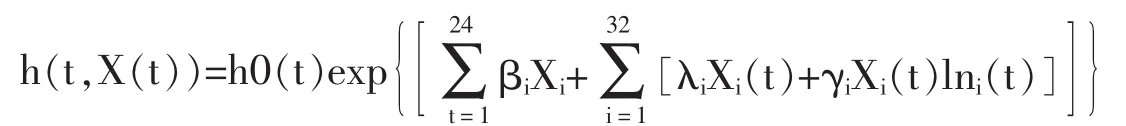
模型中加入宏观经济变量选用GDP、上证综指、CPI和PPI、基准利率、汇率、房地产产业指数和全国消费者信心指数等指标的数据,用偏极大似然估计的后向法选择自变量进入回归方程,得到通过显著性检验的协变量参数估计结果如表17所示。

表17 协变量参数估计的结果
由此我们可以看出性别、年龄、学历、年度收入、健康状况、贷款用途和汇率、储蓄率和CPI通过显著性检验。分类准确率提高情况见表18。
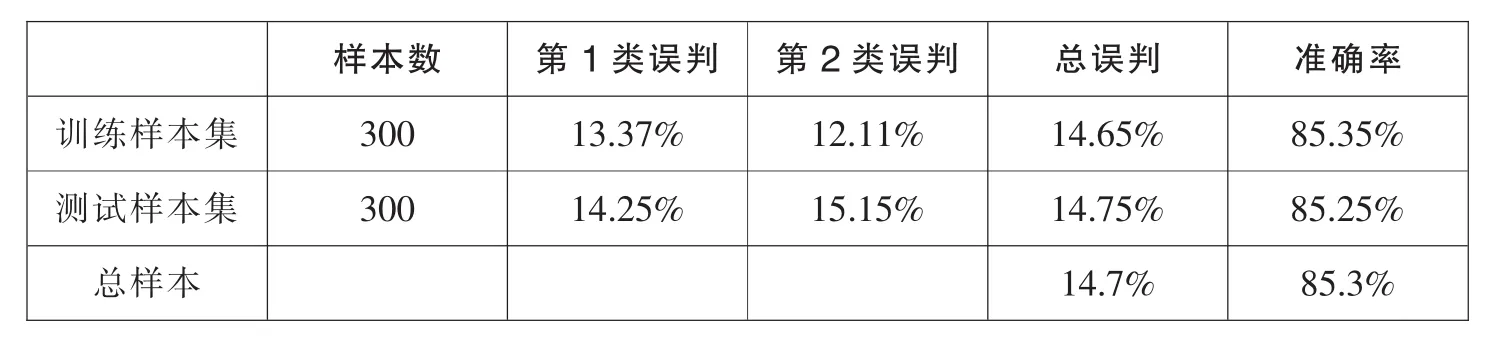
表18 分类准确率
与不考虑宏观经济因素对违约概率的影响模型相比明显提高了分类准确率。可见,宏观经济变量确实对违约风险有影响。
五、结 论
本文利用信用风险理论建立了基于Logistic函数下的网贷信用评估模型,寻找P2P网贷违约有影响的变量,然后与COX模型相比较,COX模型的稳健性比Logistic模型回归更好,并且准确率也更高。然后用没有加入宏观经济变量与加入宏观经济变量后的COX模型比较,发现降低了判误率,并且明显提高了总体模型分类准确率,说明宏观经济变量确实对违约风险有影响。对网贷违约风险来说,COX模型更优于Logistic函数。时变相依比例危险方法构建了信贷违约概率度量模型,可以克服在度量信贷违约概率时仅考虑个体非系统性风险的局限。
后续的研究还可以考虑选用更多的宏观经济指标,反映某一地区经济发展状况的区域性经济指标。根据群体特征,制定特定的群体指标,根据群体特征确定相应的模型可以进一步提高模型的准确度和稳健性。
[1]莫易娴,宏观经济总指数的一种新研究方法[J].统计与决策,2006(2):30-35.
[2]Thomas,L.C.,Banasik,.&Crook,J.N.Not if but when will borrowers default,Journa of the Operational Research Society,1999,50 :1185-1190.
[3]Narain,B.,Survival analysis and the credit granting decision.In L.C.Thomas,J.N.Crook.D.B.Edelman,editors.[M]Credit Scoring and Credit Control,Oxford,U.K.1999,109-121.
[4]Stepanova,M.,&Thomas.Phab scores:proportional hazards analysis behavioralscores,Journal of the Operational Research Society,2001,9:1007-1016.
[5]Stepnova,M.,&Thomas,L.,Survival analysis methods for personal loan data,Operations Research,2002,(50)2:277-289.
[6]Baesens,B.,Gestel,T.V.,Viaene,S.,etal,Benchmarking state-of-the-artclassification gorithms for credit scoring,Journal of Operational Research Society,2005,54:627-635.
[7]宋雪枫,杨朝军,商业银行信用风险评估的生存分析模型及实证研究[J].金融论坛,2006(11):26-29.
[8]白鹏飞,段倩倩,李金林个人住房信贷风险度量——基于生存分析方法,北京理工大学学报(社会科学版)2012(8):10-15.
