基于MapReduce的并行CCBF大流识别算法
2018-03-14张惠民冯林生
张惠民,冯林生
(陆军装甲兵学院, 北京 100072)
网络行为监控是网络安全管理的基础性工作,将具有相同五元组的数据包进行归类就得到了流(flow)数据,基于流(flow)数据的测量为网络监控提供了新的途径。流对象分布呈现出显著的重尾分布特征,少部分的大流量对象形成了大部分的网络流量[8,10];在OC-768链路上,40 B大小的分组仅需8 ns的传输时间,集中式的处理方式难以满足大规模网络流量数据(以下简称“大流”)的处理需求。流对象之间在计算上不存在相关关系,非常适合于分布式并行计算。
MapReduce是Google提出的一种分布式的并行计算框架,Hadoop对MapReduce进行了开源实现,将复杂的计算任务抽象成多路的Map过程和Reduce过程[6],便于并行化计算任务的实现。
本文在CCBF算法[1]的基础上,设计了在Hadoop平台运行的并行CCBF算法,并通过实验验证了算法的性能。
1 MapReduce模型的并行特性
在Hadoop框架中,MapReduce分布式处理框架由Map过程、Partition过程以及Reduce过程构成,如图1所示。主函数负责完成对MapReduce作业正确运行所需参数配置,并显式指定作业执行流程。Map函数定义为一个类(称为Mapper类)。在Mapper类中可以定义setup、map和cleanup等方法。相应地,Reduce函数定义为一个称为Reducer的类,在Reducer类中可以定义setup、reduce和cleanup等方法。map、reduce方法的一般形式表示如下:
map:( K1,V1)→list( K2,V2)
reduce:(K2,list( V2)) →list( K3,V3)
其中,(K1,V1)是数据节点存储的数据分片中的记录经过Hadoop框架解析后提供的键/值对表示,list( K2,V2)、list(K3,V3)分别是map和reduce方法输出的键/值对列表。Combine函数和Map函数运行于TaskTracker节点,partition函数将map过程输出的键值对定位到相应的reduce过程。
2 CCBF算法的并行化策略
2.1 CCBF算法思想
吴桦等[1]提出利用计数型布鲁姆计数器[2,9]进行大流的识别记录以及小流量对象的过滤,提出了CCBF算法,在数据量较大的情况下,该算法具有较小的错误率。
2.1.1 描述
CCBF算法采用计数型布鲁姆过滤器对流(flow)进行计数,只有每个Hash表项的计数都超过阈值时,该流(flow)才被判断为大流,并建立流的记录,同时采用布鲁姆过滤器进行大流存在的记录,CCBF算法的结构如图2所示。
2.1.2 算法
CCBF算法的具体描述如下:
while packet arrives
calculate H = h(1),h(2),…,h(K)
if H exist in Longflow_BF
{
Increase Longflow records
}
else
{
increase corresponding counters in Filter_CBF;
if min_counter>DemandValue{
decrease corresponding counters in Filter_CBF;
increase corresponding counters in Longflow_BF;
add new Long flow records;
}
}
end while
export flow record;
2.1.3 特性分析
令n为已经处理的报文的个数,k为Hash函数的个数,m为计数型布鲁姆过滤器(CBF)结构中计数器的数目,j为大流的阈值,从而CCBF算法的误判率为
(1)
CCBF大流识别算法以较低的时间和空间复杂度实现了高速链路大流的高精度识别,在数据量较大的情况下,该算法具有较小的平均错误率,在排除输入、输出影响的情况下,该算法可以应用于大规模主干网的流量分析。
2.2 基于MapReduce的并行化改造
2.2.1 描述
在基于流(flow)的网络数据测量中,流对象之间在流的大小统计上不存在相关性;本文基于MapReduce的并行CCBF大流识别,在map过程中完成数据报基于流的特征提取,在partition过程中完成数据报基于流的分发,在reduce过程中完成长流的识别以及流长的计算。
2.2.2 map过程的设计
在MapReduce框架中,Map函数的输入为p,p表示报文序列pi(i=1,2,…)。从报文序列中提取出五元组信息作为value,为实现良好的并行性,降低算法在各节点的耦合度,对五元组进行Hash操作,并将结果作为key,之后输出〈key,value〉。
map函数的伪代码如下所示:
input:p
output:〈key,value〉
key = hash(p.info);
value=p.info;
2.2.3 partition过程的设计
在MapReduce分布式运行框架中,Partition过程用来完成对Map过程输出的分区处理,Partition过程根据Reduce节点的个数完成对Map输出的分区。因为在map过程中已经完成了hash操作,所以为提高算法的运行效率,在本文的算法中定制的Partition函数为
getpartition(K key,V value,int numReduceTasks)
{
return new long key;
}
2.2.4 reduce过程的设计
Reduce函数的输入是〈key,[value]〉键值对。输出为〈key′,value′〉键值对,其中key′为数据流的五元组标识符;value′数据流的长度,单位为数据包。Reduce函数首先通过Filter_CBF过滤掉小流,提取超过阈值的数据流存入链表,并用Longflow_BF结构标识长流是否存在,之后将链表中各节点存储的五元组以及流长作为键值对输出。
reduce函数的伪代码如下所示:
input:〈key,[value]〉
output:〈key′,value′〉
while(value exist)
{
H = h1(value),h2(value),…hk(value);
if(H exist in Longflow_List)
{
update Longflow_List;
}
else
{
increase Filter_CBF;
if(Filter_CBFmin>threshold)
{
insert Longflow_BF;
insert Longflow_List;
decrease Filter_CBF;
}
}
}
node= Longflow_List->node;
key′=Longflow_Listi.info;
value′=Longflow_Listi.num;
context.write(key′,value′);
while(node->next != null){
node=node->next;
key′=node.info;
value′=node.num;
context.write(key′,value′);
}
3 算法分析
评价大流识别算法存在严格的标准,需要从算法运行的时间效率以及算法结果的正确性这两个方面进行评价,在大流识别算法中这两个方面是相互联系互相制约的。其中算法的时间效率是主要方面,时间效率高的算法才可能被应用于大规模主干网上进行网络流分析,时间效率将在后面的实验中进行分析;算法的正确性决定了算法应用质量,从而决定了算法是否会被采用,下面从误判率来分析算法的正确性。
算法的主体结构是使用计数型布鲁姆过滤器进行大流识别判断的,结合算法流程以及哈希冲突可知算法存在错误增加流长的误判,使流长错误增加一次的误判率为
(2)
这个概率是误判一次的概率,根据计数型布鲁姆过滤器的功能存在误判两次以上的概率,误判两次以上的概率远远低于误判一次的概率,因而算法的误判率取误判一次的概率。分析误判率公式,可以看出影响算法误判率的4个参数:
N为布鲁姆过滤器表示的元素个数,在Longflow_CBF中表示长流的总数,在Filter_CBF中表示网络流的总数。随着n的增大,算法的误差增大,减小n的值就能相应地降低误差,因此在固定的时间间隔内将布鲁姆过滤器初始化,能够降低误判率。
K为Hash函数的个数。在n和m确定的情况下,为使算法的误判率达到最小,k值为:
(3)
N表示在MapReduce运行框架中,reduce任务的个数。
M为布鲁姆过滤器中表示集合元素的单元个数,m取值越大,误判率越小,但是内存消耗也越大,因此需要在内存消耗和误判率之间找一个平衡点。
将式(2)代入式(1)得:

(4)
从以上的分析可知算法的误判率受硬件资源和被处理报文数量的影响。
4 实验结果及分析
4.1 实验环境与实验数据
在实验室搭建的Hadoop平台上运行所有实验。Hadoop实验平台由6台机器组成,其中1台为主节点,另外5台为从节点。6台机器的配置是:CPU的主频频率为8核2.40 GHz、32 GB内存和100 M网卡。操作系统为CentOS7。Hadoop版本是2.7.3,因为数据节点的采用的是8核CPU,所以reduce任务个数参数设置为8的倍数。6台机器通过交换机和网线搭建一个局域网。
应用JAVA编程语言完成了文献[1]中提出的CCBF算法以及本文提出的基于MapReduce的并行CCBF长流识别算法和不采用基于MapReduce的并行CCBF表流识别算法[1]。并进行了3组数据集实验,分别测试了算法的运行时间、可扩展性以及加速比。实验选取的数据源CAIDA-OC48数据集是在美国西海岸的一个OC48对等链路上采集的,采集于2012年9月,仅包括匿名的数据报头部信息;CAIDA-OC192数据集是在CAIDA组织所监控的一个OC192链路上采集的,采集于2012年6月,仅包括匿名的数据报头部信息,如表1所示,分别从中获取2.9亿个数据报文,使用从中获得五元组(源地址、源端口、目的地址、目的端口、协议类型)[10]和二元组(源地址、目的地址)得到了4个数据集(CAIDA-OC48-5、CAIDA-OC48-2、CAIDA-OC192-5、CAIDA-OC192-2)。

表1 算法使用的数据源
4.2 采用与不采用基于MapReduce的并行CCBF大流识别算法性能对比
使用单机伪分布式方法搭建了一个Hadoop集群运行本文提出的算法,与运行CCBF算法的主机进行运行时间计算,结果如表2所示。
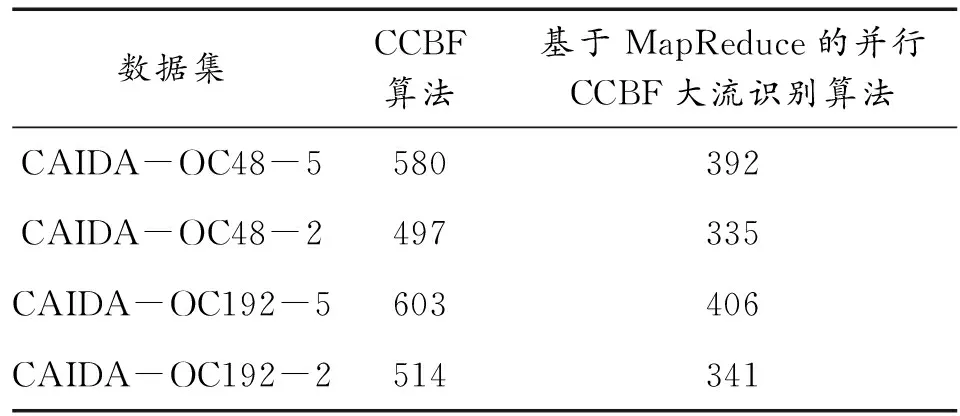
表2 算法执行时间 s
从表2可以看出,不采用基于MapReduce的并行CCBF大流识别算法的执行时间长于基于MapReduce的并行CCBF大流识别算法的执行时间,这是因为本文提出的算法是并行执行的,对多核CPU的利用率比串行执行的CCBF算法要高。
4.3 基于MapReduce的并行CCBF大流识别算法的加速比测试
文献[4-6]给出了评价算法性能的重要指标加速比的公式,公式如下:
(5)
其中,t1、tn分别表示在1个节点和n个节点上的执行时间。
使用表1列出的OC48数据集验证并行CCBF算法的加速比,取得的实验结果如图3所示。从图3可以得出,算法具有较高的加速比。
4.4 基于MapReduce的并行CCBF大流识别算法的可扩展性测试
文献[7]给出了评价算法性能的重要指标可扩展性的计算公式如下:
(6)
其中,w、p表示问题规模和集群规模,w′、p′表示扩展后的问题规模和集群规模。
为了便于测试算法的可扩展性,从表1选取OC192作为实验数据集,实验结果如图4所示。实验结果表明:并行CCBF算法能够取得较好的可扩展性。
5 结论
CCBF算法是一种高效的大流识别算法,受单机计算性能的限制,CCBF算法对大数据环境下的大流识别存在执行时间过长、效率不高的问题。针对该问题,本文在MapReduce并行编程环境下提出了基于MapReduce的并行CCBF大流识别算法,并对算法进行了实验分析,在多个数据集上的测试表明:基于MapReduce的并行CCBF大流识别算法具有较高的加速比和可扩展性。
:
[1] 吴桦,龚俭,杨望.一种基于双重Counter Bloom Filter的长流识别算法[J].软件学报,2010,21(5):1115-1126.
[2] BURTON H.Bloom.Space/time trade-offs in hash coding with allowable errors[J].Communications of the ACM,1970,13(7):422-426.
[3] FAN L,CAO P,ALMEIDA J,et al.Summary cache:A scalable Wide-area Web cache sharing Protocol[J].IEEE/ACM Trans.on Networking,2000,8(3):281-293.
[4] 周丽娟,王慧,王文伯,等.面向海量数据的并行KMeans算法[J].华中科技大学学报(自然科学版),2012,12(40):150-152.
[5] ZHAO Weizhong,Ma Huifang,He Qing.Parallel KMeans Clustering based on MapReduce[J].Lecture Notes in Computer Science.2009,5931:674-679.
[6] 陈兴蜀,张帅,童浩,等.基于布尔矩阵和MapReduce的FP-Growth算法[J].华南理工大学学报(自然科学版),2014,42(1):135-141.
[7] 陈军,莫则尧,李晓梅,等.大规模并行应用程序的可扩展性研究[J].计算机研究与发展,2000,37(11):1382-1388.
[8] 王风宇,郭山清,李亮雄,云晓春.一种高效率的大流提取方法[J].计算机研究与发展,2013,50(4):731-740.
[9] 田小梅,张大方,谢鲲,等.计数布鲁姆过滤器代数运算[J].计算机学报,2012,35(12):2598-2617.
[10]朱应武,杨家海,张金祥.基于流量信息结构的异常检测[J].软件学报,2010,21(10):2573-2583.
