域间F-范数正则化迁移谱聚类方法*
2018-03-12魏彩娜钱鹏江
魏彩娜,钱鹏江,奚 臣
江南大学 数字媒体技术学院,江苏 无锡 214122
1 引言
聚类分析是机器学习、模式识别等领域的主要课题之一,致力于将一组未标记的数据样本按照它们内在本质上的亲疏程度划分到多个组(group)中,且同一组内样本间的相似程度应足够大,不同组间的相似程度应足够小[1-3]。然而现实中往往遇到由于信号干扰或环境噪声等因素的影响,使得采集的数据样本受到很大程度污染,不能理想反映数据内在的分布特征的情况,此时,传统聚类分析算法的聚类性能常常面临很大挑战。
针对上述挑战,近年来机器学习领域出现了迁移学习研究热潮[4-7]。迁移学习可以很好地解决数据受干扰或噪声影响时聚类效果差的问题,当前在聚类、分类问题中引入迁移学习机制已引起了学者们的广泛研究。Zhao等人将迁移学习运用到在线任务上[4];Yang等人提出应用于图像聚类的异构迁移学习方法[5];Dai等人提出自学习无监督迁移聚类算法(selftaught clustering,STC),在大量的辅助未标记数据的帮助下对目标未标注数据进行聚类[6];Jiang等人提出迁移谱聚类算法(transfer spectral clustering,TSC),主要利用协同聚类来实现和控制任务之间的知识转移[7];Qian等人提出的两种基于多样性测量和知识迁移的跨域软分区聚类算法TI-KT-CM(type-I knowledgetransfer-oriented C-means)和TII-KT-CM(type-II knowledge-transfer-oriented C-means),主要解决数据不充分或由于大量的噪音干扰带来异常值的问题[8]。
谱聚类方法作为聚类方法的一个研究分支,以图论为理论基础,利用数据样本间的相似度矩阵构建(广义)特征系统,再基于此特征系统的特征矩阵进行K-means或谱扰动聚类[9]。其本质是将聚类问题转化为图论中的无向加权图的最优分割问题。与现有的其他典型的聚类分析方法(如K-means[10]和模糊C均值[11])相比,谱聚类具有(近似)全局最优解,且同时适用于凸形和非凸形数据集[9]。
本文以谱聚类为基础,利用迁移学习机制,提出域间F-范数正则化迁移谱聚类算法(transfer spectral clustering based on inter-domain F-norm regularization,TSC-IDFR)。TSC-IDFR的主旨是利用源域的历史谱聚类知识,即部分历史特征向量来辅助目标域的谱聚类过程。为此本文基于K近邻(Knearest neighbor)策略[12]为目标域每一数据样本从源域挑选一可用来迁移历史聚类知识的历史样本,利用这些历史数据样本的历史特征向量组成历史特征矩阵,结合F-范数正则化机制[13]构造目标域最优谱聚类目标函数完成聚类。本文算法具有三大特点:
(1)通过迁移历史特征矩阵,TSC-IDFR实现了对历史知识的有效学习和利用,很大程度上提高了目标算法在受干扰或噪声影响的目标数据集上的聚类效果。
(2)TSC-IDFR从源域迁移的是历史特征矩阵这一高级历史知识,而非原始数据样本,这在一定程度上可以满足源域隐私保护的要求。
(3)通过第K近邻点策略和为F-范数正则化项引入正则化系数λ(λ≥0),结合有效的聚类有效性验证指标,TSC-IDFR可以较灵活地决定关于源域历史知识的借鉴程度,最终服务于目标域的谱聚类过程。
2 相关工作
2.1 谱聚类算法
谱聚类是模式识别中聚类学习的重要技术之一[14-17],是一种基于图论的聚类算法,它可以聚类并收敛于任意形状样本空间的全局最优解,且能够同时适用于凸形和非凸形的数据集。
给定样本空间X={xi|xi∈Rd,i=1,2,…,N},d表示数据集的维度,N表示数据集样本容量。G=(V,E,W)表示无向加权图,其中数据集X中的每个数据对应于图G中的一个顶点V,每两个顶点vi、vj的连线构成边集合E,每条边上的两个顶点相似度wij作为边的权重,所有边的权重构成了相似度矩阵W。两个顶点间的相似度wij由采用的亲和度函数计算而得,如高斯径向基函数:
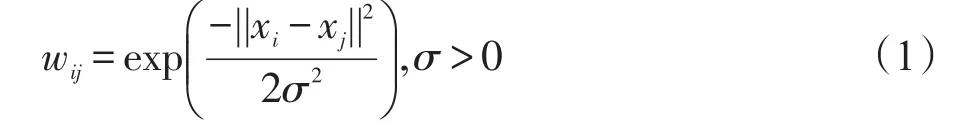
L=称为拉普拉斯矩阵(Laplacian matrix),其中D称为度矩阵(degree matrix)且有D=diag(d11,
谱聚类的最优化模型可以表示为:

其中,tr()表示矩阵的迹;U是由拉普拉斯矩阵L特征分解后的前k个特征向量归一化以后组成的特征矩阵;k对应聚类的类别数。
归一化谱聚类算法(normalized spectral clustering)的具体执行步骤如下:
步骤1根据式(1)计算相似度矩阵W,进而计算度矩阵D和拉普拉斯矩阵L;
步骤2通过对L的特征分解得到前k个特征向量,对每一行进行归一化操作得到特征矩阵U;
步骤3通过k-means聚类或谱扰动[9]算法对特征矩阵U的每一行进行聚类。
2.2 迁移学习
迁移学习引起了广泛的关注和研究,它是运用已有的知识对不同但相关的领域问题进行求解的一种机器学习方法的统称。迁移学习也称知识迁移,是从历史场景(称作源域)获取有益信息(数据或知识),用于指导现有场景(称作目标域)的数据分析过程。迁移学习的目标是将从一个环境中学到的知识用来帮助新环境中的学习任务,即目标域上的新的学习处理过程。关于迁移学习的整体介绍可参见文献[18-23]。
迁移学习场景中,源域和目标域的数据分布规律通常表象不同但内在存在一定联系。鉴于此特点,目标域如何有效地从源域发现有用的可借鉴知识,并如何适度地借鉴学习此知识是知识迁移的关键问题之一。
3 基于域间F-范数正则化迁移的谱聚类算法
为了解决受噪声或干扰信息影响的目标域数据集的有效聚类问题,本文引入迁移学习机制,在F-范数正则化的基础上构建了迁移谱聚类算法TSC-IDFR。
介绍TSC-IDFR算法之前,首先介绍谱聚类方法中什么知识可以用来进行源域到目标域的知识迁移。如第2.1节所介绍,谱聚类最终将进行基于拉普拉斯矩阵L的特征分解操作,得到由前k个特征向量(对应于前k个最小的特征值)构成的特征矩阵。也就是说谱聚类可以理解为将数据信息从原数据集X(N×d)变换成特征矩阵U(N×k),如图1所示。
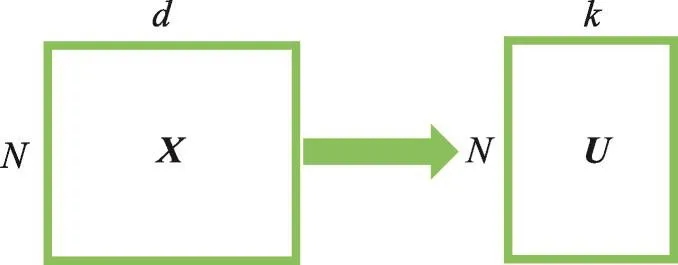
Fig.1 Transformation from data setXto eigenvector matrixUin spectral clustering图1 谱聚类中原数据集X与特征矩阵U的转换
谱聚类中这种从原数据集X到特征矩阵U的转换过程给了人们很大的启示。认为U可被视作一种源域中的高级知识,是对源域数据分布规律的一种高级知识表示形式,且这种知识表示可被目标域的聚类过程借鉴学习。这正是本文最大的研究创新。如此,可以从两方面受益:
(1)从源域获得一种可用于目标域知识借鉴的高级知识表示机制;
(2)基于特征矩阵进行知识迁移而非源域数据样本本身,这可满足数据隐私保护环境下的迁移学习过程。
接着分析如何从源域获取适用的特征矩阵用于目标域的知识借鉴学习。这里需要强调一点:本文重点关注一个经典的迁移学习场景,即目标域数据样本由于受到一定程度的环境噪声或干扰信息的影响,以至于数据样本本身并不能准确反映潜在的数据分布真相的场景。在此场景下,为目标域的任意数据样本从源域找到适宜的可从其借鉴知识的参照样本是本文需要首先解决的问题(假设源域的数据量远大于目标域的数据量)。为此,本文提出第K近邻机制:对于目标域中的任意样本,从源域找距离它第K个最近的样本作为它的可参照样本(注意,这里不是选前K个最近的样本,而是仅第K个最近样本,即前面K-1个最近样本都不被采用)。通过这种机制,本文旨在提出一种源域与目标域之间的较具有灵活性的知识借鉴机制(本文K的最佳取值将通过网格寻优策略决定)。这样,基于目标域的N个数据样本可从源域找出由相应N个样本构成的历史被参照样本子集,这些历史被参照样本在源域特征矩阵中的相应行就构成了最终用以目标域知识借鉴的特征子矩阵(记作U(O))。
基于上述思想,在经典谱聚类的最优化架构上融入对源域知识的借鉴学习项,参考文献[24-28]本文提出TSC-IDFR的最优化目标表达式。
根据迁移学习理论,源域数据(历史被参照数据)与目标域数据(当前待处理数据)应具有一定程度的相似性。本文用D(U(C),U(O))来度量目标域数据上的谱聚类知识和源域数据上的谱聚类知识之间的不相似程度,其中U(C)和U(O)分别表示目标域数据和源域数据的特征矩阵。为定义D(U(C),U(O)),本文引入线性核函数和F-范数的相关知识。用符号KU(C)和分别表示目标域特征矩阵U(C)和源域特征矩阵U(O)对应的相似度矩阵(由线性核函数计算而得),||*||F表示相似度矩阵的F范数。这样本文D(U(C),U(O))可以定义为:

由于采用线性核函数,将得到两个性质:

式(4)等号右边的式子等于F范数的平方,对于n×m矩阵A,其F范数为:
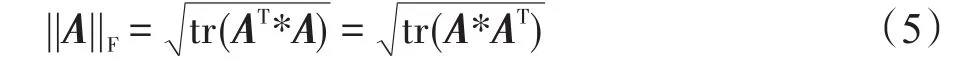
设B、C均为n矩阵,矩阵的迹具有以下性质:

为了找到目标域数据上的谱聚类知识和源域数据上的谱聚类知识之间的不相似程度,按照F范数和矩阵迹的性质和公式,式(4)改变为:
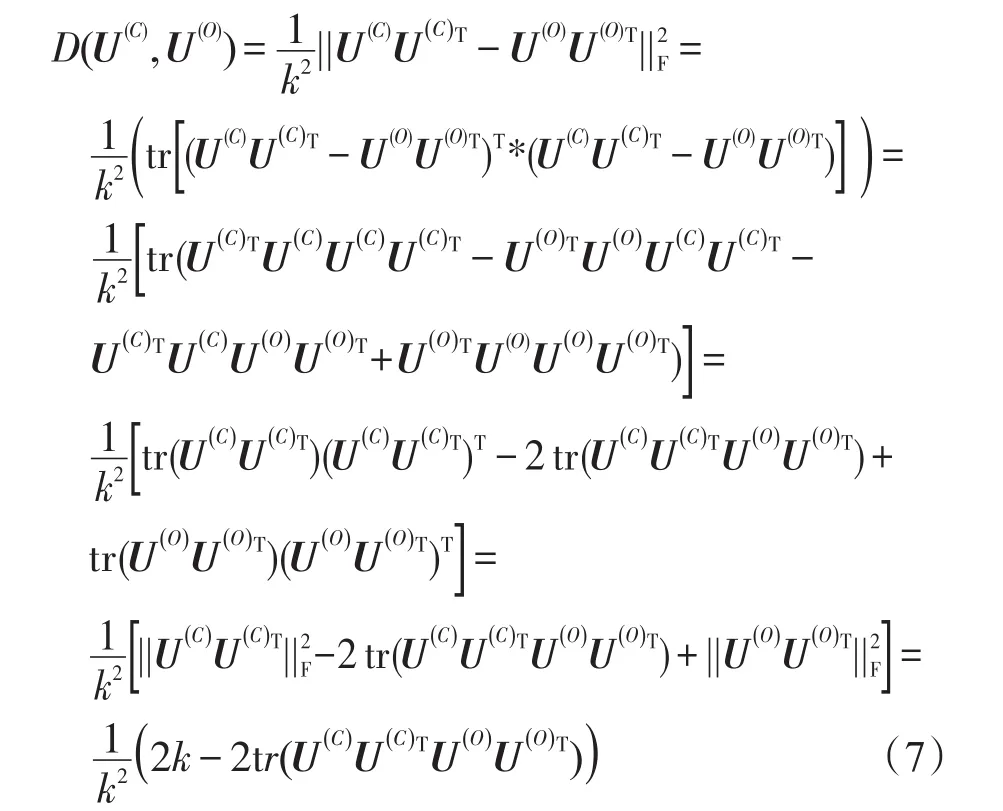
经过以上公式最终得到:
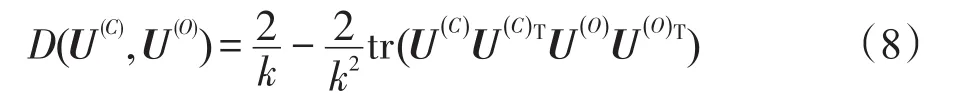
本文希望最小化不相似度D(U(C),U(O)),即最大化tr(U(C)U(C)TU(O)U(O)T)。这样省略常数项因子,基于谱聚类目标函数,可以提出TSC-IDFR的最优化目标函数:
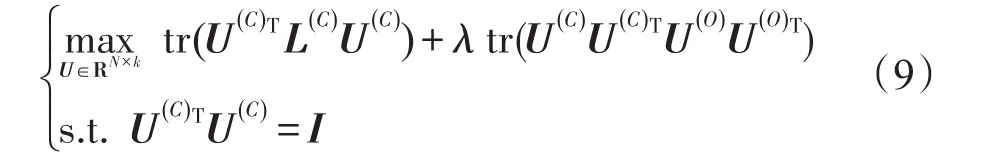
其中,tr(U(C)TL(C)U(C))是原谱聚类最优化项;U(O)U(O)T)是基于F-范数的知识迁移正则化项;λ(λ≥0)是迁移正则化项的系数。

适当合并处理后式(9)可写成:目标表达式中的L(C)+λU(O)U(O)T等同于经典谱聚类里面的拉普拉斯矩阵L,区别在于前者加入了供目标域知识借鉴的特征子矩阵的相关信息。这里将历史信息以特征矩阵的形式给出,通过调整正则化系数λ的值来调整目标域关于源域知识的迁移学习程度,成功地将历史相关知识融入到目标函数中实现了迁移谱聚类的思想。
TSC-IDFR算法的整体设计思想如图2所示。
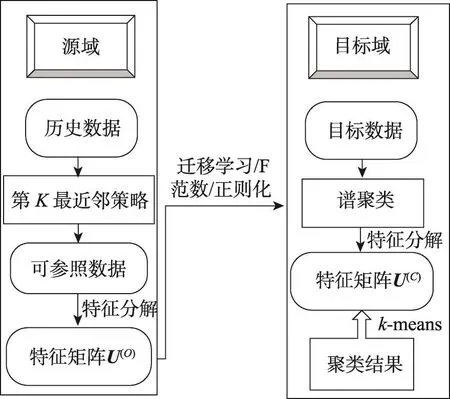
Fig.2 Design idea of TSC-IDFR图2 TSC-IDFR算法设计架构
TSC-IDFR算法的具体执行步骤为:
阶段1数据处理阶段
步骤1输入目标域数据集和源域数据集,根据第K最近邻策略为目标域任一样本从源域数据集挑选出一可参照数据样本,如此获得目标域在源域的可参照数据子集。
阶段2迁移谱聚类算法阶段
步骤2输入相似度参数σ,经由式(1)分别计算出目标域数据和源域的可参照数据子集上的拉普拉斯矩阵L(C)和L(O)L(O);
步骤3对L(O)进行特征分解,取前k个最小特征值对应的特征向量,并对每一行进行归一化操作得到特征矩阵U(O);
步骤4根据式(10),输入正则化系数λ,新的谱聚类的拉普拉斯矩阵等于L(C)+λU(O)U(O)T;
步骤5对步骤4得到的新拉普拉斯矩阵做特征分解,最后通过k-means聚类算法或谱扰动方法对特征矩阵的每一行进行聚类;
步骤6输出聚类实验结果。
4 实验研究
为验证本文提出的TSC-IDFR算法的聚类有效性,以下将基于一组模拟数据集和5个真实数据集进行实验。本文除了与经典谱聚类算法(spectral clustering,SC)对比,还将在对比实验中加入现有的几种典型的相关算法进行比较评价,包括共享学习子空间的多任务聚类算法(learning the shared subspace for multi-task clustering,LSSMTC)[29]、自学习聚类算法(STC)[6]、迁移谱聚类算法(TSC)[7]和两种基于分歧度度量知识迁移的跨域软划分聚类算法(TI-KT-CM/TII-KT-CM)[8]。需要说明的是,TSC算法要求数据维度大于聚类的类目数,因此对于不满足该条件的数据集,以“—”表示无法获得其上的聚类结果。本实验采用归一化互信息(normalized mutual information,NMI[30])和芮氏指标(rand index,RI[31])两种外部评价指标对实验结果进行评价。两种评价指标的取值范围均为[0,1],值越大表明算法的聚类性能越好。
本文算法涉及对径向基参数σ、正则化系数λ和第K近邻机制中的参数K的取值问题,为此本文采用了广为熟知的网格搜索法来进行参数遍历寻优。表1给出了本文TSC-IDFR算法关于径向基参数σ和正则化系数λ在各个数据集上的推荐寻优区间;第K近邻参数K的值则从1到7在各个数据集上遍历获得。其他几种被比较算法均采用原文献推荐的参数区间设置。实验结果统计中NMI-meanNMI-std(RI-meanRI-std)分别表示在最优参数下运行10次后NMI的均值与方差(RI的均值与方差)。

Table 1 Recommended parameter settings to TSC-IDFR表1 TSC-IDFR算法推荐参数寻优区间
实验环境:i3 3.7 GHz CPU,12 GB RAM(根据自己电脑实际修改),Matlab R2014a等。
4.1 模拟数据集实验与结果分析
鉴于迁移学习的场景是源域和目标域数据分布通常表象不同但存在内在关联性,为此本文特设计满足此特点的两种模拟迁移数据场景如下。
(1)月牙型迁移数据场景L1-M1。构造如图3(a)、(b)所示的二维月牙型数据集L1和M1。其中L1不含噪声,2类分布清晰共含1 210个数据点;M1则较明显不同于L1的数据分布,即所含2类形状与L1明显不同且类间部分重叠相交(模拟受噪声干扰场景),且共有460个数据点。
(2)簇状迁移数据场景L2-M2。构造如图3(c)、(d)所示的二维人造簇状数据集。首先采用高斯概率分布函数生成4类共1 200个数据点的源域数据集L2(每类300个点),其中4类满足如下分布规律:第一类均值m=[10 8],方差s=[8 0;0 8];第二类均值m=[25 10],方差s=[14 0;0 16];第三类均值m=[40 18],方差s=[20 0;0 20];第四类均值m=[-1 8],方差s=[12 0;0 12]。类似地采用高斯概率分布函数生成目标域数据集M2,它包含3类共600个数据点(每类200个点)。这3类满足如下分布:第一类均值m=[10 20],方差s=[10 0;0 10];第二类均值m=[15 10],方差s=[12 0;0 14];第 3 类均值m=[20 25],方差s=[15 0;0 15]。这三类彼此部分重叠,用于模拟受噪声干扰目标域类簇较难区分的场景。
本实验的目的是检验迁移聚类算法是否能通过来自源域的知识借鉴以有效提升其在目标域数据集(受到较大程度噪声影响)上的聚类有效性。这里L1-M1场景属于迁移学习中任务相同(都要求划分出2类)但数据域不同(源域和目标域数据分布明显不同)的情形;L2-M2场景则属于任务和数据域均不相同的迁移学习场景,因为源域和目标域不仅数据分布不同,所含类簇数也不同。

Fig.3 Artificial transfer data scenarios图3 人造迁移数据场景
注意:TSC算法要求数据维度大于聚类的类目数,这里的模拟数据集显然不满足该条件,因此本文模拟数据集上的实验未使用TSC算法。
表2给出了各算法在L1-M1和L2-M2迁移数据场景下的最终聚类性能情况。基于表2可以给出如下实验结果分析。
(1)从源域是L1目标域是M1组成的迁移场景L1-M1可以看出,在如图3(b)所示的非凸形目标数据集上,基于谱聚类的TSC-IDFR、SC和STC算法的性能明显优于LSSMTC、TI-KT-CM和TII-KT-CM算法。这是因为谱聚类可以适应任意形状(凸形或非凸形)数据集且拥有全局(近似)最优解。TI-KT-CM和TII-KT-CM虽然也属于时兴知识迁移聚类算法,但对于非凸形数据集聚类效果不佳。就TSC-IDFR、SC和STC三者而言,基于历史谱聚类知识迁移的TSC-IFR算法明显优于SC和STC算法。原因有二:一方面是TSC-IDFR学习的是历史特征矩阵这一高级历史谱聚类知识,而非来自源域的原始数据样本,这使其具备了避免由于参照数据选择不当而造成负迁移的能力,从而实现在目标数据集上的相对有效聚类;另一方面通过灵活调整正则化系数λ的值,在源域与目标域数据分布区别明显的情况下,TSC-IDFR仍然实现了对源域历史谱聚类知识的较合理利用,从而在目标域聚类中获益。
(2)从源域是L2目标域是M2组成的迁移场景L2-M2可以看出,TSC-IDFR、STC、TI-KT-CM和TIIKT-CM算法的聚类性能都优于LSSMTC算法。这是因为LSSMTC算法是一种多任务聚类算法。其目的是同时完成多个聚类任务且任务之间会有一些交互信息。由于源域与目标域间数据分布的差异,导致源域聚类任务和目标域聚类任务之间的交互有效性降低,从而得不到理想的双赢结果。迁移聚类算法TSC-IDFR、STC、TI-KT-CM和TII-KT-CM在此迁移场景中均可获得来自源域的有用信息来提高其在目标域中的聚类有效性。
(3)较之经典谱聚类SC算法,TSC-IDFR的实际性能提升取决于其从源域获取的知识对其在目标域上聚类的实际指导价值。总体而言,目标域与源域相似度越大,从源域获取的知识对目标域的指导价值就越大。比如L1-M1场景较之L2-M2场景源域跟目标域更相似,因此较之SC,TSC-IDFR算法在M1数据集上获得了约11%的聚类性能提升,而在M2上仅4%左右。
4.2 真实数据集实验及结果分析
为了进一步验证本文算法的有效性,选择了5个真实数据源用于构造迁移学习场景。
(1)来自新闻文本数据库20NG(http://www.cs.nyu.edu/?roweis/data.html)的rec VS talk数据集。本文从原数据库选择其中rec和talk两个大类涉及的相关子类的数据记录构成该迁移学习数据集,其中源域数据由rec.autos和talk.politics.guns的1 500条数据组成,目标域由rec.sports.baseball和talk.politics.mideast的500条记录构成。
(2)来自电子邮件垃圾邮件过滤资源库的ESF数据库(http://www.ecmlpkdd2006.org/challenge.html)。其中源域数据来自公共可用消息资源的4 000条记录,目标域则来自用户1的私人消息资源共2 500条记录。

Table 2 Clustering results of each algorithm in simulated data sets表2 模拟数据集的各算法聚类结果
(3)来自UCI的人类活动时间序列(human motion time series,HMTS)数据集(http://archive.ics.uci.edu/ml/datasets/)。该数据集的原始数据由每个志愿者进行各类日常活动时,包括爬楼梯、坐下、走路等,其佩戴在手腕的3个传感器记录的3条时间序列组成。本文首先经3到6层的Haar离散小波变换处理将每一原始时间序列统一降维到17维,接着把每个志愿者的3条17维的新序列拼接为统一的51维特征向量[8]。本文将女性志愿者的共494条记录用作源域,男性志愿者的共312条记录构成目标域数据。
(4)来自人脸数据库的ORL数据集(http://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html)。本文选择其中8个不同人的各10幅人脸图像用以构成实验图像。把每人的任意8幅图像放入源域,剩余的2幅图像放入目标域。为了使源域与目标域数据差异尽可能大,对源域每幅人脸分别按10°和20°进行正时针绕转,对目标域图像则按10°和20°进行反时针绕转,由此形成实验用的所有人脸图像。对每一图像的像素灰度特征用PCA方法降维后获得最终239维的ORL数据集。
(5)来自Brodatz纹理数据库(http://www.ee.oulu.fi/research/imag/texture/image_data/Brodatz32.html)的TIS数据集。本文从中选择了3种不同纹理用以分别构造源域和目标域纹理图像。如图4(a)为源域纹理图像(无噪声),图4(b)为目标域图像(与源域分布不同且受到一定程度的噪声干扰)。通过Gabor滤波方法提取纹理特征构成了最终数据集TIS。

Fig.4 Texture images of TIS data sets图4 TIS数据集涉及的纹理图像
上述5个真实迁移数据场景的源域和目标域数据记录数、数据维度及所含类别数情况详见表3。表4给出了各算法在这些数据集上的聚类结果。此外,为了验证本文TSC-IDFR算法关于参数的鲁棒性,也评估了TSC-IDFR算法中的3个参数,第K近邻机制参数K、正则化系数λ和径向基函数参数σ,对其实际性能的具体影响情况。如图5~图7所示,以其中4个数据集为例示意了TSC-IDFR关于核心算法参数的性能变化情景。
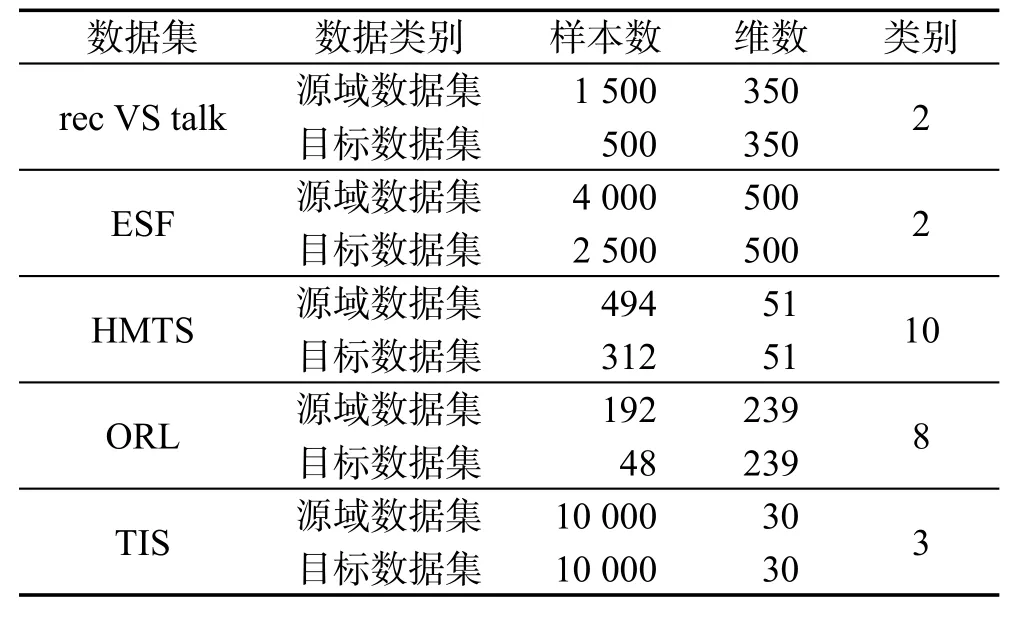
Table 3 Characteristics of real-world transfer data sets表3 真实迁移数据集数据特征
通过观察表4及图5~图7,可以得到如下结论:
(1)无论是高维数据(如ORL和rec VS talk)还是较低维情景(如TIS),TSC-IDFR算法的聚类性能都优于其他算法。这是因为TSC-IDFR算法通过第K近邻点策略为目标数据集找到适宜的可从其借鉴知识的参照样本,通过迁移历史特征矩阵,实现了对历史知识的有效学习和利用。具体说就是通过第K近邻点策略和F-范数正则化系数λ的调节,TSC-IDFR算法可以较灵活地决定关于源域历史知识的借鉴程度,最终服务于目标域的谱聚类过程。此外,TSCIDFR迁移的是历史特征矩阵,这还可以满足源域隐私保护的特定需求。这些结论与在人造数据场景中所得结论是一致的。
(2)TII-KT-CM算法的实际性能始终优于TI-KTCM算法,这是因为TI-KT-CM仅依赖于源域历史类中心这一高级知识,而TII-KT-CM同时借鉴了源域历史类中心和关于历史类中心的模糊隶属度知识,即TII-KT-CM具有更强的历史知识借鉴学习能力,因此总体上比TI-KT-CM更有效。而在这些数据集上本文TSC-IDFR算法更优于TII-KT-CM算法,这进一步佐证了本文同时结合迁移学习、谱聚类和F范数正则化等机制提出的迁移谱聚类方法的有效性。

Table 4 Clustering results of all algorithms on real-world data sets表4 真实数据集的各算法聚类结果

Fig.5 Relationships between parameterKand clustering performance in TSC-IDFR图5 TSC-IDFR算法性能与参数K关系曲线

Fig.6 Relationships between parameterλand clustering performance in TSC-IDFR图6 TSC-IDFR算法性能与参数λ关系曲线

Fig.7 Relationships between parameterσand clustering performance in TSC-IDFR图7 TSC-IDFR算法性能与参数σ关系曲线
(3)图5示意了参数K对TSC-IDFR算法的性能影响情况。结合给定的聚类有效性指标,可以为每个数据集找到一个最优K值。图6、图7示意了参数λ和σ对TSC-IDFR算法的聚类性能影响情况,总体上看,取最佳参数设置时,TSC-IDFR算法对正则化参数λ相对稳定,对高斯径向基窗宽参数σ相对敏感,但在合适区间范围内,其聚类性能总体上波动不大。
5 结束语
为了解决受噪声或干扰信息影响的目标域数据集的有效聚类问题,本文引入迁移学习机制,在F-范数正则化的基础上构建了迁移谱聚类算法TSC-IDFR。通过迁移历史特征矩阵,TSC-IDFR实现了对历史知识的有效学习和利用,很大程度上提高了目标算法在受干扰或噪声影响的目标数据集上的聚类效果。本文在人造数据集和真实数据集聚类中较充分地验证了TSC-IDFR算法的有效性。关于该研究的进一步工作:一是将此算法进一步应用到某些领域,如面向大尺度医学图像的有效分割问题。二是在此算法基础上加入半监督知识,如加入成对约束信息等,以更好地解决数据缺失等问题。
[1]Tzortzis G,Likas A,Tzortzis G.The MinMaxk-means clustering algorithm[J].Pattern Recognition,2014,47(7):2505-2516.
[2]Deng Zhaohong,Zhang Jiangbin,Jiang Yizhang,et al.Fuzzy subspace clustering based zero-order L2-norm TSK fuzzy system[J].Journal of Electronics&Information Technology,2015,37(9):2082-2088.
[3]Jiang Yizhang,Deng Zhaohong,Wang Jun,et al.Transfer generalized fuzzy C-means clustering algorithm with improved fuzzy partitions by leveraging knowledge[J].Pattern Recognition andArtificial Intelligence,2013,26(10):975-984.
[4]Zhao Peilin,Hoi S C H,Wang Jialei,et al.Online transfer learning[J].Artificial Intelligence,2014,216:76-102.
[5]Yang Qiang,Chen Yuqiang,Xue Guirong,et al.Heterogeneous transfer learning for image clustering via the socialweb[C]//Proceedings of the 47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference on Natural Language Processing of the AFNLP,Singapore,Aug 2-7,2009.Stroudsburg:ACL,2009:1-9.
[6]Dai Wenyuan,Yang Qiang,Xue Guirong,et al.Self-taught clustering[C]//Proceedings of the 25th International Conference on Machine Learning,Helsinki,Jun 5-9,2008.New York:ACM,2008:200-207.
[7]Jiang Wenhao,Chung F L.Transfer spectral clustering[C]//LNCS 7524:Proceedings of the 2012 European Conference on Machine Learning and Knowledge Discovery in Databases,Bristol,Sep 24-28,2012.Berlin,Heidelberg:Springer,2012:789-803.
[8]Qian Pengjiang,Sun Shouwei,Jiang Yizhang,et al.Crossdomain,soft-partition clustering with diversity measure and knowledge reference[J].Pattern Recognition,2016,50:155-177.
[9]Qian Pengjiang,Jiang Yizhang,Wang Shitong,et al.Affinity and penalty jointly constrained spectral clustering with allcompatibility,flexibility,and robustness[J].IEEE Transactions on Neural Networks and Learning Systems,2016,28(5):1123-1138.
[10]Kanungo T,Mount D M,Netanyahu N S,et al.An efficientk-means clustering algorithm:analysis and implementation[J].IEEE Transactions on PatternAnalysis and Machine Intelligence,2002,24(7):881-892.
[11]Zhu Lin,Chung F L,Wang Shitong.Generalized fuzzy C-means clustering algorithm with improved fuzzy partitions[J].IEEE Transactions on Systems,Man and Cybernetics:Part B Cybernetics,2009,39(3):578-591.
[12]Samadpour M M,Parvin H,Rad F.Diminishing prototype size fork-nearest neighbors classification[C]//Proceedings of the 14th Mexican International Conference on Artificial Intelligence,Cuernavaca,Oct 25-31,2015.Washington:IEEE Computer Society,2015:139-144.
[13]Fang Jianbin,Chen Zhengxu.An approximation method of positive semi-definite matrix based on weighted F-norm[J].Statistics&Information Forum,2007,22(2):44-48.
[14]Kamvar S D,Klein D,Manning C D.Spectral learning[C]//Proceedings of the 18th International Joint Conference on Artificial Intelligence,Acapulco,Aug 9-15,2003.San Francisco:Morgan Kaufmann Publishers Inc,2003:561-566.
[15]Fan R K C.Spectral graph theory[M]//Conference Board of the Mathematical Sciences Regional Conference Series in Mathematics.Providence:American Mathematical Society,1997:149-180.
[16]Zhou Dengyong,Burges C J C.Spectral clustering and transductive learning with multiple views[C]//Proceedings of the 24th International Conference on Machine Learning,Corvallis,Jun 20-24,2007.New York:ACM,2007:1159-1166.
[17]Luxburg U V.A tutorial on spectral clustering[J].Statistics and Computing,2007,17(4):395-416.
[18]Ling Xiao,Dai Wenyuan,Xue Guirong,et al.Spectral domaintransfer learning[C]//Proceedings of the 14th International Conference on Knowledge Discovery and Data Mining,Las Vegas,Aug 24-27,2008.New York:ACM,2008:488-496.
[19]Weiss K,Khoshgoftaar T M,Wang Dingding.A survey of transfer learning[J].Journal of Big Data,2016,3(1):9.
[20]Pan S J,Yang Qiang.A survey on transfer learning[J].IEEE Transactions on Knowledge and Data Engineering,2010,22(10):1345-1359.
[21]Saha B,Gupta S K,Phung D Q,et al.Multiple task transfer learning with small sample sizes[J].Knowledge and Information Systems,2016,46(2):315-342.
[22]Liu Zhen,Yang Junan,Liu Hui,et al.Transfer learning by fuzzy neighborhood density-based clustering and re-sampling[C]//Proceedings of the 2015 International Conference on Computer Science and Applications,Wuhan,Nov 20-22,2015.Washington:IEEE Computer Society,2015:232-236.
[23]Zhuang Fuzhen,Luo Ping,He Qing,et al.Survey on transfer learning research[J].Journal of Software,2015,26(1):26-39.
[24]Kumar A,Rai P,Daumé H.Co-regularized multi-view spectral clustering[C]//Proceedings of the 2011 International Conference on Neural Information Processing Systems,Granada,Dec 12-14,2011:1413-1421.
[25]Huang Likun,Lu Jiwen,Tan Y P.Co-learned multi-view spectral clustering for face recognition based on image sets[J].IEEE Signal Processing Letters,2014,21(7):875-879.
[26]Sun Shouwei,Qian Pengjiang,Chen Aiguo,et al.Clustercenter-distance maximization clustering with knowledge transfer[J].Computer Engineering and Applications,2016,52(16):149-155.
[27]Chen Aiguo,Wang Shitong.Knowledge transfer clustering algorithm with privacy protection[J].Journal of Electronics&Information Technology,2016,38(3):523-531.
[28]Qian Pengjiang,Sun Shouwei,Jiang Yizhang,et al.Knowledge transfer based maximum entropy clustering[J].Control and Decision,2015,30(6):1000-1006.
[29]Gu Quanquan,Zhou Jie.Learning the shared subspace for multi-task clustering and transductive transfer classification[C]//Proceedings of the 9th IEEE International Conference on Data Mining,Miami,Dec 6-9,2009.Washington:IEEE Computer Society,2009:159-168.
[30]Jing Liping,Ng M K,Huang J Z.An entropy weightingkmeans algorithm for subspace clustering of high-dimensional sparse data[J].IEEE Transactions on Knowledge and Data Engineering,2007,19(8):1026-1041.
[31]Liu Jun,Mohammed J,Carter J,et al.Distance-based clustering of CGH data[J].Bioinformatics,2006,22(16):1971-1978.
附中文参考文献:
[2]邓赵红,张江滨,蒋亦樟,等.基于模糊子空间聚类的〇阶L2型TSK模糊系统[J].电子与信息学报,2015,37(9):2082-2088.
[3]蒋亦樟,邓赵红,王骏,等.基于知识利用的迁移学习一般化增强模糊划分聚类算法[J].模式识别与人工智能,2013,26(10):975-984.
[13]方建斌,陈正旭.一种基于加权F-范数的半正定矩阵的逼近方法[J].统计与信息论坛,2007,22(2):44-48.
[23]庄福振,罗平,何清,等.迁移学习研究进展[J].软件学报,2015,26(1):26-39.
[26]孙寿伟,钱鹏江,陈爱国,等.具备迁移能力的类中心距离极大化聚类算法[J].计算机工程与应用,2016,52(16):149-155.
[27]陈爱国,王士同.具有隐私保护功能的知识迁移聚类算法[J].电子与信息学报,2016,38(3):523-531.
[28]钱鹏江,孙寿伟,蒋亦樟,等.知识迁移极大熵聚类算法[J].控制与决策,2015,30(6):1000-1006.
