中文产品评论的维度挖掘及情感分析技术研究*
2018-03-12赵志滨
赵志滨,刘 欢,姚 兰,于 戈
东北大学 计算机科学与工程学院,沈阳 110819
1 引言
近些年,电子商务迅猛发展,消费者可以通过电商平台完成在线购物和支付,这一方面提高了交易效率,同时也减少了商品流通环节和仓储费用,降低了交易成本。为了提升服务质量和吸引消费者,绝大多数电商平台都鼓励消费者发表购物评论,以表达消费者对产品各个属性维度上的意见。这些包含了消费者购物和产品使用体验的评论成为一种重要的市场信息资源。消费者可以将他人的评论作为指引,了解目标商品在各个属性维度上的指标或者优缺点,从而最大可能地实现理性消费和科学消费。对于商家或者生产者来说,这些消费者评论是最为直接和重要的市场反馈信息,据此可以了解市场需求,从而有的放矢地改进服务,提升产品质量,指导新产品研发,或者实现精准营销。
一个商品会包含众多的属性维度,消费者的评论谈及其中的某些维度,并包含针对具体属性维度的评价,即维度情感。消费者综合考虑不同维度的情感,潜在地为产品评论赋予整体情感。例如,表1中列举了3条来自于京东商城洗衣液商品的评论。表2则是表1中3条评论所描述的属性维度、维度情感和整体情感。
评论r1谈到了商品的“香味”和“物流/送货速度”两个维度,且维度情感都为正面。显然,评论r1的整体情感为正面。
评论r2谈到了“物流/送货速度”、“浓度”、“清洁效果”三方面,其中对于“物流/送货速度”评价为正面,而对于“浓度”和“清洁效果”的评价为负面。显然,r2的整体情感为负面。

Table 1 Examples of product's reviews表1 产品评论举例

Table 2 Dimensions,dimensional sentiments and overall sentiments of reviews in Table 1表2 表1中评论的维度、维度的情感、整体情感
评论r3谈到了“物流/送货速度”、“易漂洗性”和“产品价格”3个属性维度。同r2一样,评论在不同属性维度上所表达的情感有正有负。如果依靠传统的情感标注方法,即整体情感是各个维度情感的简单累加,那么r3的情感值将会被判定为负面。这显然是错误的,因为评论中明确地表达了消费者继续购买这款洗衣液的意愿。这也就意味着,消费者对于该产品的整体情感应为正。
从上面的例子中可以看出:(1)一条评论的整体情感是该评论所包含的属性维度及其对应情感的综合结果;(2)对于同一种商品,消费者对于商品的不同属性的重视程度也不相同。反映到评论中,商品的不同属性应有不同的权重,权重大的维度上的情感对于整体情感的影响也更大。换句话说,评论的整体情感不仅依赖于所包含的维度情感,也与属性维度对于商品的重要性程度,或者说与消费者对于商品不同维度的关注度有关。
本文使用规则匹配的方法抽取评论维度,然后使用决策树算法计算评论维度情感。虽然消费者对于不同产品维度的重视程度具有个体差异,但从群体来讲,具有统计规律。因此,本文通过对人工标注数据集中的维度被提及的概率以及维度情感和总体情感的一致性分析计算维度权重。评论的整体情感是维度情感的加权累加。本文主要贡献如下:
(1)构造了包括词语搭配关系的维度词典,并实现了基于词典的评论维度挖掘;使用卡方统计对维度词典进行扩充。实验结果表明,基于词表的规则匹配方法在维度挖掘方面具有很好的准确性,结果的可解释性也更好。
(2)使用监督学习的决策树算法进行维度情感分类,其中使用最小Gini系数选择分裂属性。实验表明,这种方法可以得到较好的维度情感分类准确性。
(3)用户对产品各个属性的重视度不同,因此评论中各个维度的权重对于评论整体情感的影响也不同。本文提出了维度权重计算方法,其中考虑了维度在评论中的提及概率以及维度情感与整体情感的一致性,最后综合维度情感和维度权重来计算评论的整体情感。
在此需要特别指出的是,本文在评论有效性判定、评论维度抽取方面采用的是规则匹配的方法,其基础是维度词典,因此只适用于中文评论文本。但是,本文所提出的处理思想可适用于其他语言的评论文本挖掘工作。
本文组织结构如下:第2章是相关工作,介绍了维度抽取和文本情感分析方面已有的最新研究成果;第3章给出了本文工作的相关概念以及符号定义,包括问题的形式化描述;第4章详细介绍了维度抽取、维度情感分析、维度权重计算以及评论整体情感计算方法;第5章介绍了实验细节,并分析了实验结果;第6章总结全文,并提出后续的研究计划。
2 相关工作
本文工作的核心是评论维度抽取和评论情感分析。现就这两方面的最新研究成果进行总结。
如果把每一个产品维度都看作是一个标签,那么一条评论包含多个产品维度,也就应被分配多个标签。因此,评论文本的产品维度抽取,本质上是一个多标签分类问题,这是学术界关注的一个热点问题。大体上,解决多标签分类问题可以有三种方法:传统的机器学习算法、深度学习算法和基于词表的规则匹配算法。Zhang等人[1]系统地总结了多标签机器学习算法:(1)一阶算法,假设标签之间相互独立,那么就可以把多标签分类问题转换为一系列独立的传统分类问题。典型的一阶算法有BR(binary relevance)[2]、ML-kNN(multi-labelk-nearest neighbor)[3]和ML-DT(multi-label decision tree)[4]。(2)二阶算法,考虑了标签之间的两两相关性,这也导致了二阶算法较一阶算法的计算复杂度有显著的增加。典型的二阶算法有Calibrated Label Ranking[5]、Rank-SVM(ranking support vector machine)[6]和 CML(collective multi-label classifier)[7]。(3)高阶算法,考虑多个标签之间的相关性,自然计算复杂度会更高。典型的高阶 算 法 有 Classifier Chains[8]和 Randomk-labelsets[9]。Zhang等人[10]研究了维度抽取和实体抽取两大核心问题,分析了维度抽取的3种主要方法,并提出了基于半监督的实体抽取方法。近些年,深度学习技术被应用到了解决多标签分类问题上。例如,Read等人[11]使用Restricted Boltzmann Machine构建隐含层,既提高了分类的准确性,也降低了分类时间。
无论是机器学习方法,还是深度学习方法,在解决多标签问题时,都存在着两个棘手的问题:第一,高质量训练数据的获取问题。这里高质量的含义是既要准确,又要充分。但是当标签数量很多时,数据倾斜现象会非常严重,某些标签下很难获得充足的训练数据。这就导致了机器学习算法,或者深度学习算法对这些标签的分类结果准确性下降。第二,结果缺乏可解释性,难于进行调试。上述两个缺点是机器学习算法和深度学习算法工程应用的巨大阻碍。
文本情感分析又称文本倾向性分析、意见挖掘,它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。文本情感分析的方法主要分为两类:一是基于情感词典的文本情感分类方法;二是基于机器学习的文本情感分类方法。
基于情感词典的文本情感分类方法的基础是准确而且全面的情感词典。Tong等人[12]人工抽取影评领域的词语,并进行极性(position/negative)的标注,从而建立了专门的情感词典。Hu等人[13]通过使用已标注极性的形容词,结合WordNet中词间的近义、同义关系来判断新词的情感极性,以计算主观文本的情感极性。为了计算微博数据传达的情感,Shen等人[14]对情感词进行了细分,建立了态度权重词典(weight dictionary,WD)、消极词典(negative words dictionary,NWD)、程度词典(degree words dictionary,DWD)和感叹词典(interjection words dictionary,IWD),如此计算的微博情感指数更加精确。在假定具有了完善的情感词典后,另一项核心工作是确定具体语境中各个细分词典词语之间的搭配关系,如使用句法分析技术,这样才能尽可能地保证分析结果的准确性。
机器学习分类算法如决策树、支持向量机、朴素贝叶斯等,其核心思想是通过训练集构造分类模型,从而对新数据进行预测。Pang等人[15]使用朴素贝叶斯、支持向量机和最大熵分类器进行文本情感分类,他们尝试用不同的特征选择方法进行实验,并比较实验结果。Hassan等人[16]采用监督型马尔科夫模型,使用词性信息和依存关系来确定消息极性。刘志明等人[17]使用3种机器学习算法、3种特征选取算法以及3种特征项权重计算方法对微博进行情感分类研究。实验结果表明,针对不同的特征权重计算方法,支持向量机和朴素贝叶斯分类算法各有优势,信息增益特征选取方法相比于其他方法效果明显要好。Basari等人[18]使用支持向量机模型结合粒子群优化算法计算文本情感,实验结果的准确率达到77%。
文献[19-20]的工作与本文的工作比较相似。文献[19]提出了LARAM(latent aspect rating analysis model)模型,在已知评论整体情感的情况下,挖掘评论中的潜在维度、维度情感和个性化的维度权重。针对旅馆的评论数据集和MP3播放器数据集进行实验验证,证明了算法的有效性。文献[20]通过统一框架CARW(collectively estimate aspect ratings and weights)来完成同样的3个任务。上述两个工作和本文工作的主要区别是:
(1)虽然都是对评论所谈及的维度进行挖掘,但本文采用的方法与上述工作不同。本文以维度词典为基础,并确定了维度词的搭配关系,同时引入了句法分析技术,这一方面能够提高维度挖掘的准确性,另一方面也适用于维度数量较多的情况。以电商平台上的洗衣液评论为例,在领域专家的指导下,需要抽取的维度数量为69个。其中关于某些维度的评论非常稀疏,在这种情况下,使用机器学习或者深度学习的方法就会面临训练集标注工作量巨大和数据倾斜问题。此时,词典方式是最为直接有效的方法。
(2)在获取了维度情感的基础上,本文的目标是挖掘消费者整体对于产品各个维度的关注度,从而推导出产品的维度权重,并通过维度情感的线性组合得到整体情感。这与文献[19-20]分析个别用户的维度偏好也是不同的。
3 问题描述
设R={r1,r2,…,rR}表示一组评论集合,S={S1,S2,…,SR}表示R中评论的整体情感的集合,其中Si∈S是评论ri∈R的整体情感。
定义1产品维度,也称产品属性,是产品本身及外延性质的总集,可表示为A={a1,a2,…,aA}。消费者对产品进行评论时会涉及产品的若干维度。例如,洗衣液产品有“价格”、“清洁效果”、“产品质量”等维度。
评论ri所包含的维度可以表示为一个A维向量

定义2维度情感,评论ri中针对某一个具体产品维度ax(ax∈A)的情感倾向称为ax的维度情感,记作本文维度情感的情感等级分为:1-负面,3-中性,5-正面。
显然,评论ri的全部维度情感构成一个A维向量

定义3维度权重,是评论者针对所有产品维度所表现出的群体偏好分布特征,用W=<w1,w2,…,wA>表示。其中,wx是ax属性维度的权重,它与维度ax在全体评论中被谈及的次数以及ax的维度情感与评论整体情感的一致性有关。
根据上述定义,本文研究的问题是:
(1)提出维度挖掘函数F,对于任意评论ri,挖掘ri的产品维度向量,形式化描述为F:ri→Vi;
(2)提出维度情感判定函数G,在(1)的基础上,确定ri的维度情感向量,形式化描述为
(3)确定W=<w1,w2,…,wA> ,根据(2)的维度情感向量,计算评论ri的整体情感值Si。
4 算法描述
下面详细介绍评论维度抽取、维度情感计算、维度权重计算以及评论整体情感计算。首先,给出本文工作的前提条件或假设:
(1)只针对有效评论展开,有效评论是指评论内容中至少涉及到了产品的一个属性维度;
(2)如果评论中涉及到了某一个产品维度,则一定包含相应的维度情感;
(3)评论的整体情感依赖于评论所描述的维度及其情感,以及维度的权重,维度权重越大,对评论的整体情感影响越大。
4.1 维度挖掘
如前所述,本文在维度挖掘方面,采用的是基于词典的规则匹配方法。基本思想是:首先根据人工分析确定产品评论的维度,然后为每一个维度确定维度词典,即描述一个具体产品维度的常用词集合。这里需要注意的是,很多词语可能出现在多个维度词典中,比如说“便宜”,如果评论文本为“东西真便宜”,那么它指的是“产品价格”维度;如果评论文本为“比超市便宜”,那么它指的是“购物渠道价格”维度。为解决这个问题,在维度词典中引入了词与词之间的搭配关系。词语以及词语之间的搭配关系共同构成了维度挖掘词典。
基于词典的维度抽取方法的具体执行过程是:首先,对评论文本根据标点符号分割成子句;然后,针对每个子句,使用包含有词语搭配关系的维度词典进行匹配。评论子句的维度就是与其匹配次数最多的维度[21]。
显然,维度词典的完整性直接影响到维度抽取的准确性。维度词典的构造过程是:首先,为产品的每个维度预先设定种子词语;然后,计算评论子句中的每个词与各维度种子词语的卡方统计值,并将卡方值最大的词语加入到相应的维度词典中,从而实现维度词典的扩充。词语t和维度ax相关性的卡方统计值计算公式如式(3)所示:

其中,F1是t出现在属于维度ax的评论子句中的次数;F2是t出现在不属于维度ax的评论子句中的次数;F3是属于维度ax但不包含t的评论子句的个数;F4是既不属于维度ax,又不包含词t的评论子句的个数;F是词t出现的总次数。
4.2 维度情感计算
维度抽取后已得出每条评论子句的维度,且每个维度对应着一种情感,因此维度情感分析是一个传统的单标签多分类问题。另外,绝大多数评论子句中针对同一维度的情感词具有方向一致性,因此选择使用监督学习方法对评论子句进行情感分类,具体采用决策树分类算法。
决策树是一个树形结构,它从根节点开始对数据样本进行测试,根据不同的结果将数据样本划分成不同的数据样本子集。它是通过一系列规则对数据进行分类的过程。构造决策树的关键性内容是进行属性选择度量。属性选择度量算法有很多,不同的决策树实现方法有不同的选择度量算法。本文采用CART(classification and regression tree)算法实现决策树。CART算法采用最小Gini系数选择分裂属性[22]。Gini系数的定义如式(4)所示:

其中,E表示训练样本的集合;G表示维度情感类别的集合,文中G={1,3,5};pi=|Gi|/|E|为样本集中样本属于Gi的概率。
使用决策树方法判断维度情感的具体步骤是:首先,在评论数据集中随机选择一定量的评论数据,使用维度抽取方法确定有效子句;然后,人工标注每条评论子句的情感,形成训练数据集;使用训练数据集训练分类器;最后,对未标注评论子句进行分类预测,得出维度情感。注意,评论的维度情感是一个向量,向量中的每个元素对应于一个产品维度的情感值。评论中未出现的产品维度,其维度情感标注为0。
4.3 维度权重及整体情感的计算
不同产品的主要功能不同,因此用户对于产品各个属性维度的关注度也不尽相同。用户对于产品的评论的总体情感,既与其对各个维度的维度情感有关,也与各个维度的维度权重有关。如果消费者群体对某个维度关注度较高,那么该维度对评论的整体情感影响也会较大。维度ax对于整体情感的影响权重与两方面因素有关:维度ax在全体评论中被谈及的概率,以及ax的维度情感与评论整体情感的一致性。本文综合考虑了上述两点来计算维度权重,为此随机地选择了评论子集Rˆ⊆R,并人工标注了维度、维度情感和整体情感。
维度ax在评论中被谈及概率由式(5)计算:

维度ax的维度情感和评论的整体情感一致性计算如式(6)和式(7)所示:
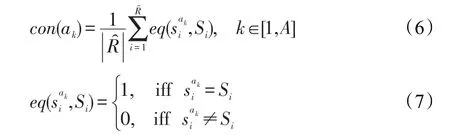
则维度ax的综合权重计算如式(8)所示:

式(8)说明,维度ax在评论中被谈及的概率越大,则消费者对此的关注度就越大。同时,ax的维度情感与评论的整体情感一致性越高,说明ax对整体情感的决定性越强。
到此,已经通过维度挖掘获取了一条评论中谈及的产品维度,并使用决策树算法判定了维度情感。在综合考虑了维度在评论中的出现概率以及维度情感与整体情感一致性的情况下,计算了产品各个维度的维度权重。在此基础上,评论的整体情感则是评论的维度情感向量与维度权重向量的内积,如式(9)所示:

5 实验
5.1 实验数据集及环境介绍
本文选取了32 000条的京东商城洗衣液产品评论作为实验数据集,并对这些评论进行了人工标注作为训练数据和测试数据。标注内容包括产品维度、维度情感和总体情感。领域专家指定了产品维度表,共分为10个大类,分别是“方便性”、“品牌”、“包装”、“产品”、“性价比”、“价格”、“香味”、“快递”、“购物渠道”和“产品功效”。每个大类下又细分为若干个二级维度,总共有69个二级维度。本文的工作,包括实验,都是针对二级维度进行的。
本文均采用Python 3.5语言实现。评论数据采用MongoDB存储。实验物理机硬件配置如表3所示。
Table 3 Hardware environment in experiments表3 实验物理机配置
为提高处理效率,在3台物理机上构建了9个虚拟计算节点,平均分配数据以实现均衡的并行处理。
5.2 实验结果
5.2.1 维度抽取
在维度抽取实验中,以人工标注的32 000条评论数据的维度标注结果作为标准测试数据集。实验过程是:针对一条评论数据,首先使用标点符号对评论进行分割,每条评论都被分割为若干子句;然后,使用维度词表中的词语及其搭配关系对子句进行匹配,并输出该子句的维度挖掘结果。
如前文所述,维度挖掘本质上是一个多标签分类问题,因此挖掘结果的正确性需要通过集合比较来进行评价。本文采用基于样本的评价指标[1]。假设评论ri的事实标签集为Vi,则维度抽取的评价指标定义如式(10)所示:

其中,p为测试样本数量,即32 000条;β取通常值1。维度抽取实验结果如表4所示。

Table 4 Result of dimension mining表4 维度抽取实验结果
实验结果表明,本文维度抽取准确性较高,说明本文方法能够较好地识别评论所谈及的产品属性。实验中使用标点符号把评论文本分隔成子句。一般情况下评论中每个子句谈及的产品维度比较单一,这是维度抽取结果性能较好的基本原因。另外,本文方法的维度词典规模较大,搭配关系超过10万,这也是维度抽取准确性较好的原因。在实验中还发现,有些维度在所有的用户评论中很少涉及,例如“包装开启方便性”、“生产工艺”等,说明消费者对这些产品维度关注度低。
5.2.2 维度情感分析
维度情感分析的本质是传统的单标签分类问题。本文工作的情感分为3类:1-负面,3-中性,5-正面。维度情感分析实验的目的是评估使用决策树分类算法实现评论子句情感分类的效果。人工标注的32 000条数据作为事实数据集,从中随机选取了数据总量的60%作为训练集,其余的40%数据作为测试数据集。实验评价指标与传统的机器学习分类算法评价指标相同。实验发现,使用卡方统计测量特征与类别之间的依赖性来进行特征选取,且特征数为2 000时,决策树分类效果最佳。实验结果如表5所示。

Table 5 Result of dimensional-level sentiment analysis表5 维度情感分析结果
实验结果表明,使用决策树分类算法进行维度情感分析的效果良好。在实验中,把包含维度信息的子句作为情感分析的语料,而子句是通过标点符号切割的,因此实验结果的准确性严重依赖于评论中标点符号使用的规范性。通过实验发现,绝大多数评论中都有标点符号分割,且绝大多数维度情感特征词都和维度信息位于同一个子句中,这是维度情感分类结果较好的原因。
5.2.3 整体情感分析
在整体情感分析实验中,首先使用32 000条人工标注数据集计算维度权重,然后使用式(9)计算评论的整体情感,并与人工标注的评论整体情感进行比较。实验结果如表6所示。

Table 6 Result of overall sentiment analysis表6 整体情感分析结果
实验结果表明,本文的权重计算方法有效。实际上,按权重对维度进行了排序输出,发现权重较高的前5位产品属性依次是“价格”、“购物渠道价格”、“物流/快递速度”、“快递服务态度”、“清洁效果”。这与人们默认的选购洗衣液产品的情感倾向稍微有些差别。一般认为,洗衣液产品最为关键的属性应该是“清洁效果”,但在本文的计算结果中,“清洁效果”仅位于第5位。为此,按照维度标签提取了相应的评论进行了分析,发现了其中的逻辑:网购行为往往带有很强的目的性,即用户已经在线下确定了目标商品,因此网购行为更多关注的是价格和物流速度;很多评论中提到了“快递服务态度”,相应的评价内容主要是快递员是否送货上门。产生这一现象的主要原因是,很多消费者因为电商的促销活动购买了很多洗衣液,重量较大,而且购买者往往是女性,因此她们比较重视快递员是否能够送货上门。通过这些深入观察,也能反映出本文维度权重计算方法是正确的。
6 总结与展望
本文针对电商平台的产品评论信息,完成了维度抽取、维度情感分析和整体情感分析工作。首先,构建维度词典,采用了基于词典的维度抽取方法;然后,使用决策树的方法对维度情感进行分类;通过对评论数据的统计,确定了维度权重,并基于维度情感和维度权重计算评论的整体情感。基于真实的评论数据集的实验结果表明,本文提出的维度挖掘方法、维度情感计算方法、维度权重计算方法,以及评论整体情感分类技术均具有很好的性能。
下一步将针对如下两个问题展开研究:第一,当前的维度信息是领域专家基于经验设定的,缺乏科学性依据,因此计划根据采集的数据,使用聚类算法,自动推荐维度标签;第二,生产企业为了提升产品的竞争力,会经常向产品中添加新功能,这会导致新维度的产生,那么用户评论中一定会有提及,如何自动感知评论中的新维度信息也是一个很有挑战性的问题。
[1]Zhang Minling,Zhou Zhihua.A review on multi-label learning algorithms[J].IEEE Transactions on Knowledge and Data Engineering,2014,26(8):1819-1837.
[2]Boutell M R,Luo Jiebo,Shen Xiping,et al.Learning multilabel scene classification[J].Pattern Recognition,2004,37(9):1757-1771.
[3]Zhang Minling,Zhou Zhihua.ML-KNN:a lazy learning approach to multi-label learning[J].Pattern Recognition,2007,40(7):2038-2048.
[4]Clare A,King R D.Knowledge discovery in multi-label phenotype data[C]//LNCS 2168:Proceedings of the 5th European Conference on Principles of Data Mining and Knowledge Discovery,Freiburg,Sep 3-5,2001.Berlin,Heidelberg:Springer,2001:42-53.
[5]Fürnkranz J,Hüllermeier E,Mencía E L,et al.Multilabel classification via calibrated label ranking[J].Machine Learning,2008,73(2):133-153.
[6]Elisseff A,Weston J.A kernel method for multi-labelled classification[C]//Proceedings of the 14th International Conference on Neural Information Processing Systems:Natural and Synthetic,Vancouver,Dec 3-8,2001.Cambridge:MIT Press,2001:681-687.
[7]Ghamrawi N,McCallum A.Collective multi-label classification[C]//Proceedings of the 14th ACM International Conference on Information and Knowledge Management,Bremen,Oct 31-Nov 5,2005.New York:ACM,2005:195-200.
[8]Read J,Pfahringer B,Holmes G,et al.Classifier chains for multi-label classification[J].Machine Learning,2011,85(3):333-359.
[9]Tsoumakas G,Vlahavas I.Random k-labelsets:an ensemble method for multilabel classification[C]//Proceedings of the 18th European Conference on Machine Learning,Warsaw,Sep 17-21,2007.Berlin,Heidelberg:Springer,2007:406-417.
[10]Zhang Lei,Liu Bing.Aspect and entity extraction for opinion mining[M]//Chu W W.Data Mining and Knowledge Discovery for Big Data.Berlin,Heidelberg:Springer,2014:1-40.
[11]Read J,Perez-Cruz F.Deep learning for multi-label classification[J].Machine Learning,2014,85(3):333-359.
[12]Tong R M.An operational system for detecting and tracking opinions in online discussions[C]//Proceedings of the ACM SIGIR Workshop on Operational Text Classification,New Orleans,2001.New York:ACM,2001:1-6.
[13]Hu Minqing,Liu Bing.Mining and summarizing customer reviews[C]//Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Seattle,Aug 22-25,2004.New York:ACM,2004:168-177.
[14]Shen Yang,Li Shuchen,Zheng Ling,et al.Emotion mining research on micro-blog[C]//Proceedings of the 1st IEEE Symposium on Web Society,Lanzhou,Aug 23-24,2009.Piscataway:IEEE,2009:71-75.
[15]Pang Bo,Lee L,Vaithyanathan S.Thumbs up?:sentiment classification using machine learning techniques[C]//Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing,Philadelphia,Jul 6-12,2002.Stroudsburg:ACL,2002:79-86.
[16]Hassan A,Qazvinian V,Radev D.What's with the attitude?:identifying sentences with attitude in on-line discussions[C]//Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing,Cambridge,Oct 9-11,2010.Stroudsburg:ACL,2010:1245-1255.
[17]Liu Zhiming,Liu Lu.Empirical study of sentiment classification for Chinese microblog based on machine learning[J].Computer Engineering andApplications,2012,48(1):1-4.
[18]Basari A S H,Hussin B,Ananta I G P,et al.Opinion mining of movie review using hybrid method of support vector machine and particle swarm optimization[J].Procedia Engineering,2013,53(7):453-462.
[19]Wang Hongning,Lu Yue,Zhai Chengxiang.Latent aspect rating analysis without aspect keyword supervision[C]//Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,San Diego,Aug 21-24,2011.New York:ACM,2011:618-626.
[20]Wang Feng,Chen Li.Review mining for estimating users'ratings and weights for product aspects[J].Web Intelligence,2015,13(3):137-152.
[21]Wang Hongning,Lu Yue,Zhai Chengxiang.Latent aspect rating analysis on review text data:a rating regression approach[C]//Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Washington,Jul 25-28,2010.New York:ACM,2010:783-792.
[22]Zhang Liang,Ning Qian.Two improvements on CART decision tree and its application[J].Computer Engineering and Design,2015,36(5):1209-1213.
附中文参考文献:
[17]刘志明,刘鲁.基于机器学习的中文微博情感分类实证研究[J].计算机工程与应用,2012,48(1):1-4.
[22]张亮,宁芊.CART决策树的两种改进及应用[J].计算机工程与设计,2015,36(5):1209-1213.
