高光谱成像技术结合遗传算法和BP神经网络的南疆骏枣总糖含量建模分析
2018-03-05李伟伟罗华平孔维楠
李伟伟,罗华平,2,3,孔维楠
(1.塔里木大学机械电气化工程学院,新疆阿拉尔 843300;2.新疆维吾尔自治区普通高等学校现代农业工程重点实验室,新疆阿拉尔 843300;3.南疆农业农机化研究中心,新疆阿拉尔 843300)
南疆骏枣营养价值高,其品质深受人们关注。由于南疆特殊的地理环境和气候条件,特别是昼夜温差大、光照时间长、有效积温高等条件,孕育了南疆骏枣优良的品质,如粒大饱满、营养价值高,深受人们的喜爱。总糖含量是南疆骏枣品质信息的常规性指标,它对红枣进一步分级和销售有重要的影响。传统的检测方法不仅耗时费力,还对样品产生侵入式破坏,且分析速度慢、损害环境,严重影响红枣的分级和销售质量。因此迫切需要一种简单、快速、无损的品质检测方法,保证南疆骏枣的发展。
近年来,高光谱成像技术应用在农产品品质检测方面已成为一个研究热点[1]。传统的光谱技术只能对农产品的光谱信息进行处理,不能获取样品的图像信息。新一代的无损检测技术——高光谱成像技术的诞生,弥补了近红外(near infrared,NIR)光谱技术的弊端,同时获得样品的图像信息和光谱信息,可以综合反映农产品的品质信息[2]。目前,在农产品检测方面,高光谱图像技术应用于鲜枣的损伤、可溶性固形物含量检测[3]、小黄瓜的水分无损检测[4]、苹果的硬度与糖度的检测[5]、马铃薯的淀粉含量检测[6]、柑橘的缺陷检测[7]、长枣表面农药残留检测[8]等内外部品质的检测。研究结果表明,高光谱图像技术在农产品品质检测方面拥有广阔的前景。
1 材料与方法
1.1 仪器设备及软件
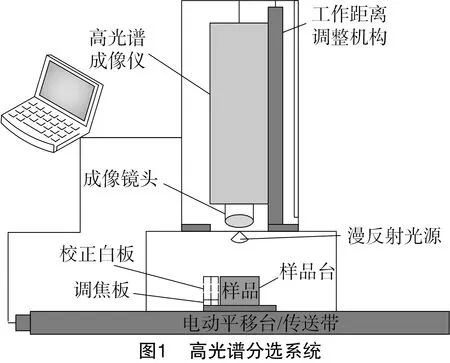
Hyperspectral Sorting System高光谱分选系统(900~1 700 nm,光谱分辨率5 nm,256个波段)。如图1所示,该系统由高光谱成像光谱仪、电荷耦合器件(CCD)相机、探测器(类型InGaAs)、成像镜头、电控位移平台、计算机组成。高光谱图像数据分析软件为ENVI 4.6和Matlab 2013a。
1.2 试验材料与总糖测定
试验材料为2015年9月采集于新疆生产建设兵团阿拉尔市10团的白熟期骏枣,选出大小均匀、无破损的红枣120颗,进行编号及除尘等处理。
红枣总糖含量测定采用国标法,即直接滴定法,按照 GB/T 12456—2008《食品中总糖的测定》执行。
1.3 高光谱图像的采集及反射光谱的获取
1.3.1 高光谱图像的采集 采集南疆骏枣样品的高光谱图像系统设置:光谱扫描范围900~1 700 nm,光谱分辨率 5 nm,扫描速度100张/s,相机像素320×256,CCD相机的曝光时间20 ms,电控位移平台速度17.3 mm/s,相机高度 36 cm,行程25 cm。
由于光源的强度在各个波段下分布不均匀、样品形状不规则及暗电流的存在,需对所获高光谱图像进行黑白校正,消除噪声影响。样品采集相同系统条件下,扫描白色校正板得到的全白图像W,关闭相机镜头进行图像采集得到的全黑图像B,然后再采集样品光谱图像[9]。黑白校正公式如下:
式中:R为校正后高光谱图像;I为原始高光谱图像。
1.3.2 反射光谱的获取 校正后的南疆骏枣高光谱图像在ENVI 4.6中打开,选取表面1个感兴趣区域(简称ROI)(60~100个像素点),计算其平均反射光谱,得到原始反射光谱[10],如图2所示。
1.4 算法及原理
遗传算法(GA)借鉴生物界的自然选择和遗传机制,利用选择、交换和突变等算子操作,随着遗传迭代的不断进行,使得目标函数值较优的变量被保留,较差的变量被淘汰,最终得到最优的结果。遗传算法的实现包括5个基本要素:参数编码、群体的初始化、适应度函数的设计、遗传操作设计、收敛判据和变量的选取[11]。具体的实现流程如图3所示。


反向传播(back propagation,简称BP)神经网络(neural network)是由非线性变换神经单元组成的前馈型多层神经网络,主要由3部分组成:输入层、隐含层和输出层。输入信息按从输入层经隐含层到输出层计算的方向进行,阈值和权值则按照输出到输入的方向进行修正,从而实现了信息的正向传递和误差的反向传播[12]。
2 结果与分析
2.1 反射光谱的预处理
分别采用均值中心化(mean centering,MC)、矢量归一化(vector normalization)、标准正态变量变换(standard normal variate transformation,SNV)、多元散射校正(multiplicative scatter correction,MSC)、导数法对光谱进行预处理。其中多元散射校正处理后的光谱见图4。
2.2 波长变量选择方法
由于高光谱图像波长覆盖范围宽、波段多,每次采集大量光谱信息,而不同的原始光谱数据对待测样品的品质信息贡献不同,通过特定的波长变量的筛选方法对波长变量进行优选,可以减少建模时间,简化建模过程,最重要的是可以剔除无关的信息变量,从而建立鲁棒性强、预测能力好的定量校正模型[13]。

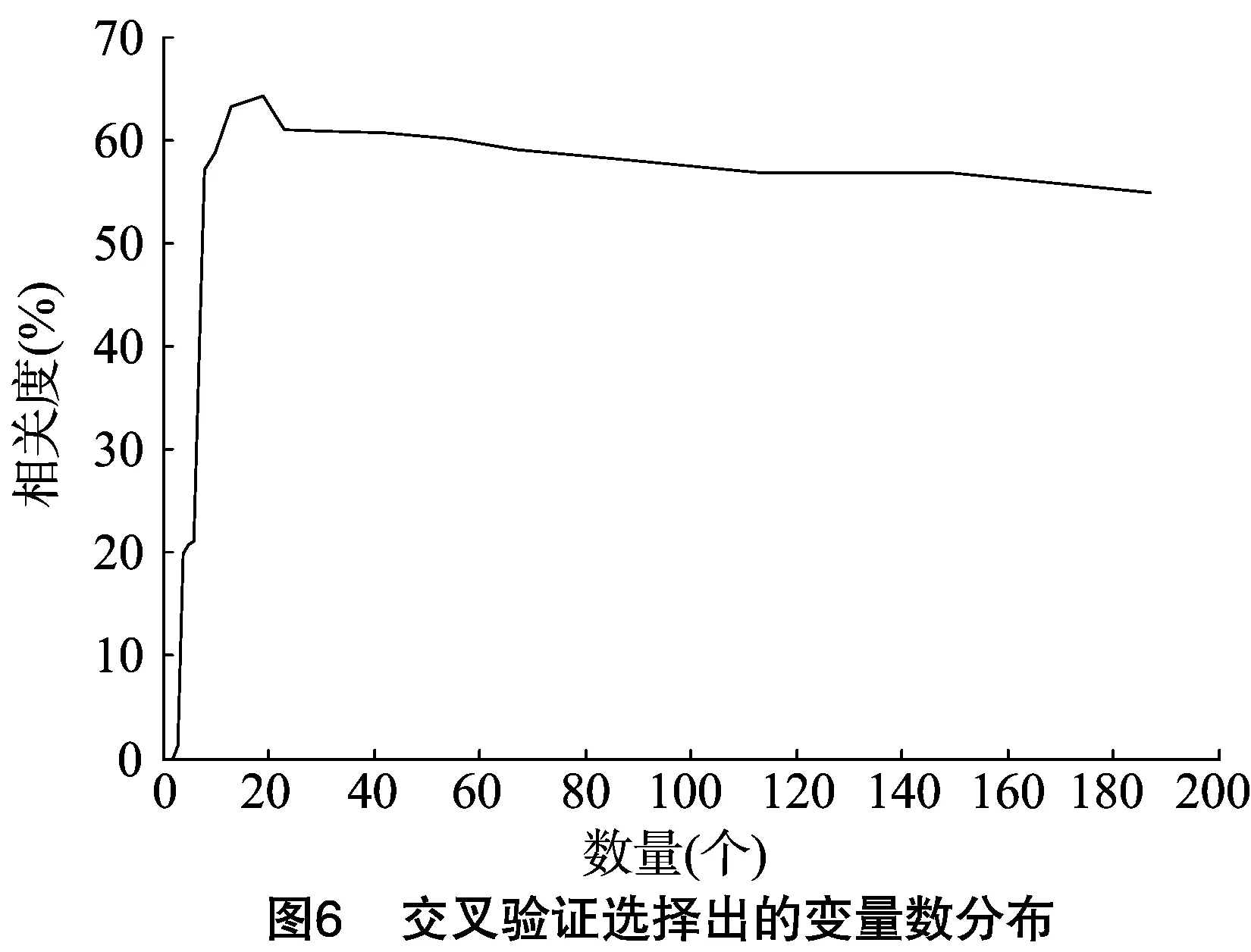
遗传算法参数设定初始种群为100,交叉概率Pc=0.8,变异概率Pm=0.01,遗传迭代次为100次。图5为遗传算法各变量被选用的频次,图6为交叉验证选择出的变量数分布。

2.3 建模方法的选择
目前主要采用的线性校正方法是偏最小二乘法(PLS)、非线性校正方法是BP人工神经网络(BP-ANN)。BP-ANN是一个前向多层网络,它利用误差反向传播算法对网络进行训练。由于其结构简单、可塑性强,包含了神经网络理论中最精华的部分,因此BP-ANN在非线性校正模型中得到了广泛应用[14]。
2.4 界外样本的剔除及样本的总糖信息
120颗待测红枣经过马氏距离(阈值e=2.1)和浓度残差(阈值h=2.8)对骏枣光谱和总糖含量进行剔除。
剔除后样品数为112个,选择校正集与预测集的样本比例为3 ∶1(校正集84个,预测集28个)。南疆骏枣总糖信息如表1所示。

表1 南疆骏枣样本总糖信息
2.5 预处理方法的选择结果
采集的红枣样品信息除了有待测样品的原始化学信息外,还有其他外在的干扰信息和噪声,这些信息导致化学信息与真实信息存在一定差异。为了提高信噪比,尽量减少误差,选择合适的预处理方法至关重要[15]。
经过建模分析,不同预处理方法对南疆骏枣样品的建模精度和预测能力的影响如表2所示。

表2 不同预处理方法南疆骏枣样品的预测能力
2.6 建模分析
运用多元散射校正进行预处理,遗传算法选择特征波长变量。分别用偏最小二乘法和BP神经网络建模,真实值与预测值对比结果如图7、图8所示。
2.7 模型评价
2.7.1 模型的验证参数评价 模型验证评价参数如表3所示。



表3 不同建模方法的验证评价参数

3 结论
(1)运用多元散射校正(MSC)预处理方法好于其他预处理方法。
(2)遗传算法(GA)筛选的特征波长变量作为输入变量的定量校正模型鲁棒性强、预测能力更好。
(3)应用BP神经网络(BP-ANN)建立的校正模型预测能力好于偏最小二乘法(PLS)建立的校正模型。
本试验选取112个样本作为研究对象,试验结果比较理想,但后续工作需要进一步增加样本数量及样本的品种类型,完善南疆红枣的建模预测模型。红枣的外部品质信息也是下一步工作的研究内容,从而实现红枣内外部品质的同时检测。
[1]徐 爽,何建国,易 东,等.基于高光谱图像技术的长枣糖度无损检测[J].食品与机械,2012,28(6):168-170.
[2]吴龙国,何建国,刘贵珊,等.基于近红外高光谱成像技术的长枣含水量无损检测[J].光电子·激光,2014,25(1):135-140.
[3]薛建新,张淑娟,张晶晶.高光谱成像技术对鲜枣内外部品质检测的研究[J].光谱学与光谱分析,2015,35(8):2297-2302.
[4]李 丹,何建国,刘贵珊,等.基于高光谱成像技术的小黄瓜水分无损检测[J].红外与激光工程,2014,43(7):2393-2397.
[5]王 爽.基于高光谱散射图像的苹果内部品质预测建模[D].无锡:江南大学,2012.
[6]吴 晨,何建国,贺晓光,等.基于近红外高光谱成像技术的马铃薯淀粉含量无损检测[J].河南工业大学学报(自然科学版),2014,35(5):11-16.
[7]章海亮,高俊峰,何 勇.基于高光谱成像技术的柑橘缺陷无损检测[J].农业机械学报,2013,44(9):177-181.
[8]刘民法,张令标,何建国,等.基于高光谱成像技术的长枣表面农药残留无损检测[J].食品与机械,2014,30(5):87-92.
[9]黄培贤,姚志湘,粟 晖,等.高光谱图像技术在食品无损检测中的研究进展[J].食品工业科技,2012,33(15):412-417.
[10]徐 爽.基于高光谱图像技术的红枣品质无损检测研究[D].银川:宁夏大学,2013.
[11]褚小立.化学计量学方法与分子光谱分析技术[M].北京:化学工业出版社,2011.
[12]杨 杰,占 君,张继传,等.MATLAB神经网络30例[M].北京:电子工业出版社,2014.
[13]彭云发.近红外光谱技术在南疆红枣品质快速无损检测中的应用[D].阿拉尔:塔里木大学,2015.
[14]葛哲学,孙志强.神经网络理论与MATLAB R2007实现[M].北京:电子工业出版社,2007.
[15]胡晓男.南疆红枣品质数字化快速无损检测技术推广应用[D].阿拉尔:塔里木大学,2015.
