基于3D Res-Inception网络结构的密集人群行为识别
2018-02-20
(上海电力学院电子与信息工程学院,上海200090)
随着现代化进程的加快,人口流动越来越频繁,众多人口涌入经济更发达、城市化水平更高的地区。大量密集人群对当地基础交通设施和公共安全带来巨大挑战,也为人群的监管治理提出更高要求。由于传统的人工视频监控需耗费大量人力,近年来出现了用于跟踪、识别、场景理解的智能监控算法,采用这些算法提取图像序列特定的特征,再建模分析人群行为。光流场的计算最初由Horn等[1]提出,采用光流计算像素级相邻帧之间的瞬时运动,可获取短时间的时空运动特性;Jodoin等[2]将光流法运用于人群运动检测。粒子流是基于流体动力学的光流积分,Wu等[3]将粒子流运用于异常人群行为检测;Yang等[4]提出一种新的特征描述符——多尺度光流直方图(multi-scale histogramsof oriented optical flow,MHOF),能够保留连续的空间信息和运动信息;Wang等提出能够学习语义区的轨迹聚类,从密集的特征点提取轨迹,然后使用特殊的模型来加强轨迹之间的时空相关性,以检测拥挤场景中行人的行为模式;Shao等[6]提出一种基于群体变迁的人群描述子算法,用于人群行为识别和人群运动模式分割。上述算法在一些特定场景,如人群密度较低、监控视角尺度固定等情形有较好效果,对于高密度的人群场景,由于人群流动杂乱、不同的人具有不同运动方式及环境干扰因素等,其智能监控效果并不理想。
近年来,随着深度学习的迅速发展,许多经典且复杂的难题被解决或简化。Krizhevsky等[7]将卷积神经网络用于图像识别并在ImageNet数据集上取得巨大的提升;Szegedy等[8-10]提出的Inception模型组合了不同的卷积核,可提升卷积神经网络的宽度;He等[11]提出残差结构的概念,加深卷积神经网络的深度。在视频分析领域,涌现出一些新颖方法,Du等[12]将二维的卷积池化扩展到三维,从而实现能够提取时空特征的三维卷积神经网络;Simonyan等[13]研究网络分支结构,提出双流卷积神经网络,网络分为两个支路,将分别提取的时间特征和空间特征融合为时空特征;Ng等[14]结合长短期记忆网络(long short term memory,LSTM)和卷积神经网络两种模型,先用卷积神经网络逐帧提取特征,再通过LSTM网络处理时空信息。上述方法主要应用于简单的动作或手势识别,面对复杂的人群场景,如何设计处理时空信息的神经网络,如何提取有益于人群行为分析的特征,需进一步探寻新的识别方法。为此,文中结合深度学习方法与传统的计算机视觉方法,采用数据扩增、时空残差单元等策略及双路Res-Inception深度网络模型对密集人群行为进行识别,以期提高密集人群行为识别的准确率。
1 视频数据扩增
对于数据量有限的数据集,通常有两种增强训练的方法:一种是对原始数据集进行数据扩增;另一种是用更大规模的同类型数据集训练,然后在原数据集上微调。其本质都是扩大训练数据量,让神经网络学习到更多的特征。在图像识别与分类领域,镜像、随机裁剪都是可行的数据扩增技巧。通过数据扩增,扩大训练样本从而增加数据的丰富性,减少过拟合。对于深度神经网络训练来说,密集人群视频数据集的样本数仍偏少,需通过数据扩增的方法对其样本进行扩充。文中以香港中文大学密集人群视频数据集(CUHK Crowd Dataset)为样本(该数据集有474个视频样本,总数据量约6 Gbit),通过数据扩增对其进行扩充,具体扩增步骤如下:
1)将视频数据分解为图像序列,单帧图像如图1(a);
2)将原始图像序列通过镜像扩增为原先的2倍,如图1(b);
3)原始样本的分辨率各不相同,需将所有图像序列调整至同样大小160×240,最后剪裁至128×128,如图1(c)。
2 网络结构
2.1 3D Res-Inception网络模型
3D Res-Inception网络模型如图2,共使用9个时空残差单元,4个最大值池化层和1个平均池化层,网络的开端使用1个3×7×7的大尺度卷积和3×3×3的池化,随后通过两个卷积层和池化层将特征送入时空残差单元,经过多个时空残差单元和最大值池化提取高层语义的时空信息,最后通过全连接层将特征展平,使用Softmax作为分类器输出分类结果。
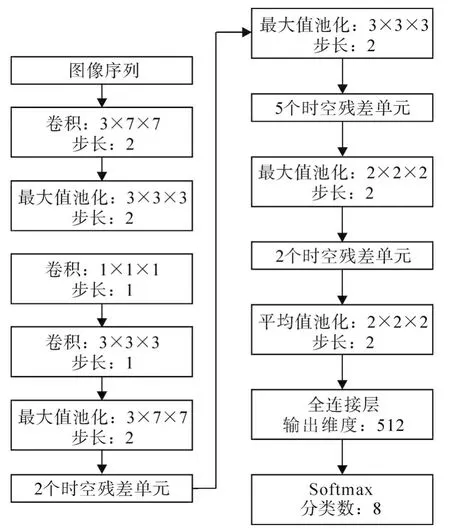
图2 3D Res-Inception网络结构Fig.2 Network structure of 3D Res-Inception
Softmax的定义如式(1)

其中:M为总类别数;a为M维向量;at,ak分别为a中的第t,k个元素。公式分子代表该元素的指数,分母代表所有元素的指数和,两者的比值为该元素的Softmax值,a中Softmax值最大的元素代表的类别即为分类类别。
为将预测的分类类别与真实类别相比较,采用分类交叉熵作为损失函数,定义如(2)。
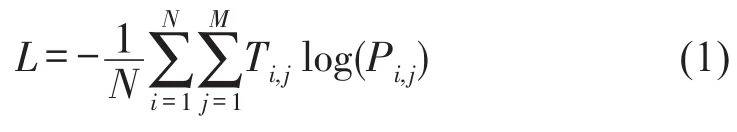
其中:L为损失函数;N为训练样本数;i为样本;j为类别;Ti,j为真实的分类标签;Pi,j为预测的分类结果。
2.2 时空残差单元
针对视频内容,直接将二维网络扩增至三维网络,即将所有的卷积和池化进行维度扩展,如N×N卷积核提升为N×N×N,赋予其第一个维度为时间维度。类似于Inception V2结构,3D Inception主要有4个分支,第一个分支为1×1×1的卷积;第二个分支先经过1×1×1卷积,再经过3×3×3卷积;第三个分支先经过1×1×1卷积,再经过5×5×5卷积;第四个分支先经过3×3×3的最大值池化,再经过1×1×1卷积。此外,每个卷积之后使用修正线性单元(Rectified Linear Units,ReLU)作为非线性激活函数,使用批归一化(Batch Normalization,BN)将前一层的激活值重新规范化从而加速网络收敛。通过不同的卷积组合,扩展网络结构的宽度和深度,提升网络性能,增强网络对不同尺度特征的适应性。
在3D Inception模型中,增加残差连接组成完整的时空残差单元,如图3。残差连接定义如式(3)

其中:xn和xn+1为n层的输入和输出;f为激活函数ReLU;F为残差函数;W为权重。
2.2 双路深度网络
密集人群视频识别问题的难点之一是如何获得较好的时空特征。卷积神经网络能够提取特征,且随着网络的加深,获得的特征更加趋于高层语义。由于原始图像序列为RGB图像序列,通过神经网络获得的高级特征主要包含人群的外观信息,运动信息不够全面。因此,文中在3D IRes-Inception网络结构的基础上,增加网络运动分支结构,构建双路深度网络,运用特征融合的方法,将两条支路获取的运动与外观特征加以融合,扩大总的特征维度,使神经网络获得充分的时空信息。双路深度网络模型如图4。

图3 时空残差单元Fig.3 Spatial-temporal residual unit

图4 双路深度网络模型Fig.4 Deep network model of two branches
分析图4可知,将相同的2个3D Res-Inception网络合并,一个分支网络用于提取外观特征(输入原始RGB图像序列),另一分支网络用于提取运动特征(输入光流图像序列),最后融合外观和运动两种特征,通过Softmax分类器输出人群行为分类结果。光流图像序列包含较长时间内人群的运动变化信息,连续的光流图像可代表图像中密集的轨迹信息,且光流法获得的边缘及位移信息有助于识别人群行为,故文中采用光流图像序列作为运动分支的输入。
3 实验
3.1 实验数据
为验证本文方法应用于人群行为识别的效果,使用香港中文大学的人群行为数据集(CUHK crowd dataset)进行实验。数据库包含215个场景的474个监控视频,根据不同的人群行为,该数据集分为混合行走、方向一致的有序人流、方向一致的无序人流、人群合并、人群分流、反向人群交叉、电梯人流拥堵、电梯人流顺畅等8类,数据集中无重复样本。
3.2 实验过程
数据集的分配按8∶2分为训练集和验证集,训练集中设置20%的随机样本作为训练网络时的测试数据。训练样本中的图像序列长短不一,若取16帧为无重叠划窗的视频帧数,将有大量信息得不到充分利用。此外,分段剪辑的人群运动方式与整段人群运动方式基本保持一致。为此,将训练集中的数据按照25帧为1组,既扩展了训练样本数,且使网络得到充分训练。实验设备为配置TITAN XPascal显卡的Linux系统,框架后端为Tensorflow,前端为Keras。使用Adam优化器,设置学习率为0.001,每批次10组样本。
3.3 实验结果与分析
3.3.1 数据扩增实验
为验证数据扩增的有效性,将训练集进行数据扩增,在相同测试集上测试。原始数据和经过扩增的数据通过单支路3D Res-Inception网络的实验结果如表1。

表1 数据扩增对分类结果的影响Tab.1_ Effect of data augmentation on classification results
从表1可看出,采用扩增后的数据集进行训练,准确率相较原始数据提升3.76%,表明采用视频数据扩增方案可有效提升深度卷积神经网络性能。后续实验均在数据扩增的基础上进行。
3.3.2 单、双支路网络结构实验
为对比单支路结构和双支路结构的网络性能,分别使用RGB图像序列和光流序列作为单分支网络的输入数据进行实验,结果如表2。比较表2中的数据可知:输入RGB图像序列的实验效果更佳,识别准确率达92.16%;对于增加光流支路的双路深度网络,准确率达95.48%,与输入RGB图像序列单支路网络相比,其准确率提升3.32%,与输入光流图像序列单支路网络相比,其准确率提升7.98%,表明外观和运动特性的组合可有效提高人群行为识别的准确性。

表2 单、双支路结构分类结果Tab.2 Classification results of single branch and two branches
3.3.3 密集人群行为识别实验
用于密集人群行为识别的算法有基于群体变迁的人群描述子算法[6]、三维卷积网络(3D CNN)、CNNLSTM、双路3D CNN、双路3D Res-Inception。其中:基于群体变迁的人群描述子算法是非深度学习在人群行为识别中的最佳算法,此算法构建一种群体检测器,系统量化一组描述子,用于群体状态分析和人群行为理解;CNN-LSTM将光流序列和RGB图像序列展平输入CNN提取特征,然后通过LSTM获取时空信息;3D CNN将二维卷积扩展至三维,不仅运用于动作识别,在目标检测、时序检测等领域也取得了较好的成果。3D CNN、双路3D CNN、CNN-LSTM网络模型等与本文提出的双路3D Res-Inception网络模型的实验效果如表3。从表3可看出,与传统计算机视觉方法相比,深度网络模型的识别准确率有很大提升,而本文提出的双路3D Res-Inception网络模型则取得了更好的实验效果,该网络使用的时空残差单元较好地结合时空信息,双路结构融合了人群的外观和运动特征。因此,提出的网络模型更适合于密集人群行为分析。

表3 相近方法的分类结果Tab.3 Classification results of relative methods
4 结 论
构建双路3D Res-Inception卷积网络结构,设计一种残差时空单元用于提取视频中的时空特征,网络的分支一输入原始的RGB数据用于提取人群视频的外观信息,分支二输入光流序列用于提取人群视频的运动信息,且在香港中文大学的人群数据集CUHK crowd dataset进行实验验证。结果表明:该网络结构较好地解决密集人群的行为识别问题,与传统的人群描述子算法、CNN-LSTM以及3D CNN网络相比,其识别准确率有较大提升。
