企业互联网负面信息分析与去噪
2018-02-01蒋鸣珂曾伟红
蒋鸣珂,曾伟红
(湘潭大学 信息工程学院,湖南 湘潭 411105)
1 概述
随着互联网技术的飞速发展,人们能够在互联网中找到各种有用的信息,特别是近年来大数据技术的迅速发展,社会已经进入了大数据时代。在现代社会,企业的负面信息对于我们来说是非常重要的,银行放贷时需要确定该企业是否有负面信息,以此判断该企业是否有能力还贷然后再发放贷款,而我们在寻找合作伙伴时也需要这些信息来帮助我们做个判断。企业在互联网中的负面信息可以通过爬虫来获取,但是,有时通过爬虫获取的数据并不能直接被判断为是负面信息,所以,我们需要对爬虫获取的初步数据进行进一步的分析和去噪,从而精确获取企业负面信息。获取精确的企业负面信息能够便于银行和某些特定用户直观地看到企业状况,从而做出相应的决定。
2 相关工作
文本作为一种重要的信息表达方式,如何分辨一段文本是否是负面信息呢?我们需要对其进行情感分析,研究文本语义和情感倾向。
对于一段文本来说,能够表达其情感倾向的主要是构成文本的词语。所以,判断一段文本是否为负面信息,主要是判断其中某些关键字的语义倾向。张锦明提出了一种基于词汇的语义倾向向量空间模型表示算法(SOVR算法),它结合了语法、语义、语用,将统计测度方法与机器学习方法结合起来,大大提升了判断性能。但是,这种方法还存在侧重统计方法、规则利用较为单一、对特定领域依赖较大等问题。以单词为基础的语义倾向研究是对文章语义倾向研究的基础。Vasileios Hatzivassiloglou和Kathleen R.McKeown依赖于文本语料库对形容词语义进行分析,他们发现,形容词语义会受到连接词的影响,所以,可分析连接词前后2个形容词来判断其是否有相同或者不同的取向。文中提出一种四步走的方法来有效判别一个形容词的语义倾向。Peter D.Turney运用统计方法,使用点互信息(PMI)和潜在语义分析(LSA)对正面和负面样例词汇进行语义倾向分析,从而提高各类词统计的准确率。
机器学习方法在情感分类中发挥着非常重要的作用。Bo Pang和Lillian Lee使用机器学习解决文本情感分类,利用朴素贝叶斯、最大熵分类器和SVM这3种方法分析电影评论数据。经过实验对比,在对相同数据进行文本语义倾向分析时,在这3种方法中,朴素贝叶斯效果相对比较差,而SVM的效果相对比较好。情感倾向研究在互联网中被广泛应用。杨欢在其文章中阐述将文本分类用于微博中情感倾向的研究,解决了以往检索和采集以关键字为基础难以支持情感倾向挖掘的问题。同时,他还提出了一种基于主题情感相关的改进k最近邻算法,这种方法能够对情感进行正面、负面和中性的分类,在处理微博热门中文主题情感时有一定的可行性。从目前情况来看,这个领域还没有一个完整的语料库。因此,杨江等人提出建设汉语语义倾向语料库,以语言主观性多维度描述体系为指导理论,将类别、程度、形式、成分、关联和模式6个维度构成一个体系,每个维度表示一种属性,从而构建一个具有检索统计、结果检查、可视化等特点的语料库工具箱系统,这对于人们理解语言主观性有一定的帮助。朱嫣岚、闵锦等人基于HowNet提出语义相似度和基于语义相关场的2种语义倾向计算方法,通过选择褒贬基准词,计算被测试词与基准词之间的语义紧密程度,从而得到这个词的语义倾向值。这种方法在汉语常用词中效果比较好,具有一定的实用价值。
3 数据描述与分析
基于百度搜索使用爬虫来获取所需要的数据,使用“公司全称或者简称+负面词”的方式搜索,使用420个负面词循环抓取百度搜索结果前10页的数据,最终获取了10万多条数据并对其进行分析。
3.1 数据处理流程
对于获取到的数据,具体处理流程是:①判断是否有简称或全称+负面词。②识别内容中的实体,判断公司名称是否为全称。例如搜索的简称是“国基建设”,全称是“湖北国基建设”,结果内容中实体却是“湖南国基建设”,则这个结果不符合,就要去除。③对包含负面词的句子调用HanLP进行依存句法分析,进一步解析,判断其是否为负面信息。爬虫获取的整个网页的原始数据被存放在一个json中,在处理数据时,会先从这段文本中找出负面关键字所在的句子,将其提取出来,然后调用HanLP对其进行依存句法解析,并根据解析结果得到依存句法树。数据处理流程如图1所示。

图1 数据处理流程图
3.2 依存句法分析
依存句法用来描述词语之间的依存关系,即用来表示词语之间句法上的搭配关系,这种关系与语义相关。在依存句法树中,输入的句子从普通排列模式变成树状结构,可以更加直观地发现句子内部词语之间的远距离搭配或者修饰关系。中文文本词性标注情况如表1所示。
经过依存句法分析后,生成的依存句法树如图2所示。

表1 中文文本词性标注

图2 生成依存句法树的结果
通过依存句法树我们可以清楚看到,负面词“涉案”的主语是“员工”,员工一共3名,而员工是“中联重科”的员工,所以,该语句可以判断为是中联重科的负面信息。
4 负面信息噪声产生因素分析
在本节中,对比、分析获取到的10万多条数据,最终得到了若干可能会造成负面信息噪声的因素,并将其归纳为以下几点。
4.1 负面词否定
在众多影响负面信息去噪的因素中,负面词否定可以说是一种比较直接的影响因素,因为否定修饰词往往直接作用于负面词。在此次实验中,共获取该类语句8 812条,占总数据的8.5%.例如,“从根本上控制污染”中,“污染”是负面词,但是“控制”修饰“污染”构成动宾关系,“控制污染”并不是负面词,所以,该语句不能被列为负面信息;“并不会夸张到有95%的创业公司倒闭”中,“倒闭”是负面词,但是,“夸张”和“有”为并列关系,而“有”修饰“倒闭”,所以,该语句也不能被列为负面信息;“在冲击下坚挺危机逆袭”中,“危机”是负面词,但是,“逆袭”作为定语修饰“危机”,“危机逆袭”不能表达出负面信息,所以,该语句不是负面信息。
4.2 有负面词但不是负面信息
在众多噪声因素中,有很多语句包含负面词但不是负面信息这个问题比较普遍。在本次实验中,共获取该类语句17 353条,占总数据的16.7%.该问题的出现大致可以分为以下几种情况:①负面词可能夹杂在某个专有名词中出现,即负面词只是作为某个名词中的部分出现。例如,“暂停业务”中的“停业”,“遇难题”中的“遇难”,都是负面词作为部分出现,而“青山寨特产店”中的“山寨”也是作为店铺名字中部分出现,它们都不属于负面信息。②有负面词但是并不能体现负面意思。例如,“曝光”“借款”等负面词所表示的内容可能并不是负面的,需要对其作进一步的判断。③负面词可能是某一个产品介绍中的词语。例如,“出现交通事故,车子会马上报警”中的“事故”,“意外伤害保险”中的“伤害”,“举报受理方式”中的“举报”,这些虽然都是负面词,但具体内容均为产品或业务介绍,并不属于负面信息。④负面词体现出正面意思或者是欲扬先抑。例如,“正是这样的困境,构成了创新工场人工智能工程院建设的初衷”中的“困境”,“有很多珠宝企业资金链出现了危机,而该公司却逆市而上”中的“危机”均为负面词,但却体现出了目标公司的正面形象,不属于负面信息。
4.3 负面词主语问题
负面词主语问题在噪声中也算是一个重要问题。在本次实验中,共获取该类语句28 655条,占总数据的27.5%.经过研究,可以将该问题划分成以下3类:①语句中表达的公司不是目标公司,或者是目标公司去举报别的公司。例如,“OKAI公司侵犯了合肥华泰集团的商标权”中的目标公司为“合肥华泰集团”,负面词为“侵犯”,“在梯子网倒闭的同时,在线教育行业遭遇质问关键节点,绩优堂还能受到如此热捧”中目标公司是“绩优堂”,负面词是“倒闭”。这两句话都可被认定为噪声,因为负面词所说的公司并不是目标公司。②语句中负面词的主语不是公司。例如,“有4家规模较小的企业出现了大幅亏损”中负面词“亏损”,“曾伙同他人在梅县维也纳酒店内故意损害酒店财物,涉案金额总计8 850元”中“损害”“涉案”为负面词。虽然此类例子中有负面词,但是,负面词的主语与公司无关,所以也是噪声。③负面词反映了一个行业的问题。例如,“宝怡珠宝这种稳扎稳打、有实力、有准备的珠宝企业,更容易在危机中找到进一步发展的机遇”中“危机”为负面词,但是,该语句说明的是珠宝行业的问题,与目标公司无关,属于噪声。
4.4 简称问题
在搜索阶段使用公司简称搜索可能会获得更多的相关信息,但是,这么搜索在获得更多信息的同时也会出现很多噪声信息。在本次实验中,通过简称搜索到数据36 331条,其中,存在噪声问题的数据有14 323条,占搜索到的额外数据的39.4%,占总数据的13.8%.出现简称问题的原因也有几种,例如目标搜索公司可能有很多分公司,或者有名字相近的公司,但是,使用公司简称搜索后可能会搜到很多分公司信息,或者搜索到了别的公司,而这些信息并不属于你的目标公司,属于噪声;又或者搜索到的内容中的简称关键字可能只是一句话中的某些词语,对于公司来说并没有什么意义,也可列为噪声。
4.5 负面词库设置
负面词库中负面词的设置不仅决定着爬虫抓取信息量,还在负面信息噪声判断方面发挥着重要作用。增加负面词库中的负面词数量,可以使爬虫在抓取信息过程中获得更多负面信息,但是,在去噪过程中,会发现有部分负面词在大多数语句中并不能表现为负面信息,此时就要删减负面词库来提升去噪效果。
4.6 句式
在爬虫获取的大量语句中,除了有以上几种问题外,还有小部分包含负面词的语句可能是疑问句或者是假设句,等等,这类句子也需要对其进行二次判断才能确定是否为噪声。例如,“如果发现有拖欠农民工工资等违法违规行为”是假设句,“是否会产生此类危害”是疑问句,但是这都不能直接将其语句列为负面语句,需要再次判断。
4.7 数据总体分析
获取数据分布情况如图3和图4所示,可以看出,主语问题在噪声中占有较大的比例,有负面词但不是负面信息和简称问题随后,占比最小的是负面词否定问题。
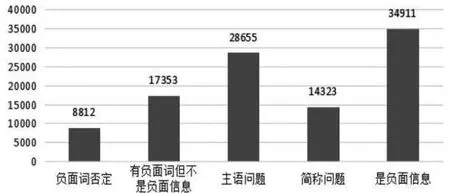
图3 数据分布柱状图
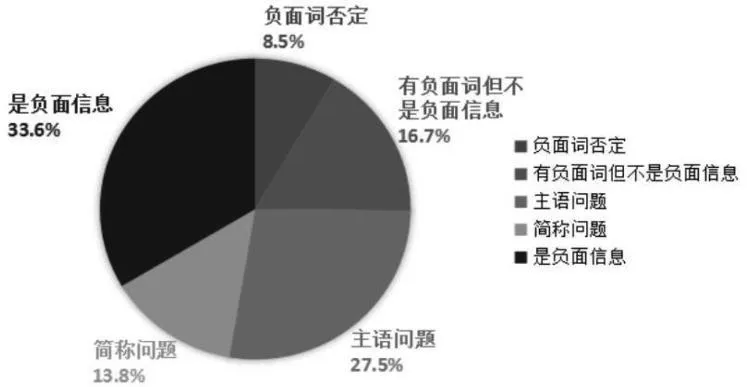
图4 数据分布饼图
5 总结与展望
本文主要考察了爬虫获取的初步文本中噪声产生的因素,并且分析了判断一个语句是否为负面信息时噪声造成的影响。使用HanLP对语句进行依存句法分析,得到依存句法树,然后对其进行解析,能够有效判断一个语句是否为负面信息。
然而本文还有一些地方需要改进,例如,可能还有其他噪声因素等待我们去发现,需要进一步获取更多数据来分析实验。此外,是否还有其他方法可以用来判断一个语句是否为负面信息还需要我们进一步探索,如果有的话,对比现有方法,其在效率、复杂度上是否更有优势等。
[1]张锦明.中文语义倾向识别的关键算法研究[D].北京:北京邮电大学,2008.
[2]Vasileios Hatzivassiloglou,Kathleen R.McKeown.Predicting the Semantic Orientation ofAdjectives[C]//In:Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics and the 8th Conference of the European Chapter of the ACL,1997:174-181.
[3]Peter D.Turney,Michael L.Littman.Measuring Praise and Criticism:Inference of Semantic Orientation from Association[J].ACM Transactions on Information Systems,2003,21(4):315-346.
[4]Bo Pang,Lillian Lee,Shivakumar Vaithyanathan.Thumbs up Sentiment Classification Using Machine Learning Techniques[C]//In:Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing,2002:79-86.
[5]杨欢.基于文本分类的微博情感倾向研究[D].重庆:重庆师范大学,2016.
[6]杨江,李薇,彭石玉.汉语语义倾向语料库的建设[J].中文信息学报,2014,28(05):74-82.
[7]朱嫣岚,闵锦,周雅倩,等.基于HowNet的词汇语义倾向计算[J].中文信息学报,2006(01):14-20.
[8]徐军,丁宇新,王晓龙.使用机器学习方法进行新闻的情感自动分类[J].中文信息学报,2007(06):95-100.
[9]马妍.商品评论情感分析系统的设计与实现[D].北京:北京交通大学,2015.
[10]宋光鹏.文本的情感倾向分析研究[D].北京:北京邮电大学,2008.
[11]马那那.面向产品评论的情感文本分类研究[D].合肥:安徽大学,2017.
[12]李钝,乔保军,曹元大,等.基于语义分析的词汇倾向识别研究[J].模式识别与人工智能,2008,21(04):482-487.
[13]李正华.汉语依存句法分析关键技术研究[D].哈尔滨:哈尔滨工业大学,2013.
