基于可见-近红外光谱及随机森林的鸡蛋产地溯源
2018-01-22巧华
,巧华,,*, ,, ,
(1.华中农业大学工学院,湖北武汉 430070; 2.华中农业大学国家蛋品加工技术研发分中心,湖北武汉 430070)
随着我国鸡蛋产业的快速发展,国家对盒包装的鸡蛋更加规范化,规定必须标明生产地、生产日期等,市场中乱标鸡蛋产地的现象严重,不仅影响市场的健康发展,也侵犯了消费者与生产者的权益,不利于中国名优鸡蛋原品种和品牌的保护。鸡蛋品种及产地的检测在加工、贮藏和销售等方面都非常重要。为保证市场的公平,需要建立一种快速、精确的鸡蛋产地溯源技术。
由于鸡蛋成分复杂,其外观和理化品质比较接近,采用传统的感官和经验方法很难鉴别其产地。可见-近红外光谱是指波长的其中一部分是属于可见光(400~760 nm)的波段范围内,另一部分是属于近红外波段(780~2526 nm)的范围内。可见-近红外光谱的吸收主要是由于含氢基团振动的倍频和合频吸收所造成的。光谱信息能间接的反映出农产品本身的化学构成信息,因此,将该技术应用在农产品内部品质、品种、缺陷等方面的定性和定量研究,有着广泛的前景[1]。可见-近红外光谱分析技术是一种快速简便无损的分析方法,且能够用于在线检测分级,被广泛应用于食品、化工、医药等行业[2]。近年来,国内外学者利用光谱技术在农副产品品质的检测上进行了相关研究[3-7],在蛋品品质检测中,近红外光谱技术也有应用。段宇飞等对鸡蛋新鲜度研究方面,利用近红外光谱结合局部线性嵌入(LLE)、支持向量回归进行无损检测[8];王巧华等利用近红外光谱结合多模式共识法(CUVE)、偏最小二乘判别法(PLS-DA)对鸡蛋新鲜度进行在线检测分级[9];祝志慧等利用光谱技术和多分类器融合对异物蛋无损鉴别[10];孙俊等利用介电特性对鸡蛋品种及产地进行无损鉴别,模型训练集正确率为95.83%,测试集正确率为95.83%[11]。戴祁等利用稳定同位素对鸡蛋鉴别及溯源进行研究,通过测定各地自来水的δ18O值,可以得出鸡蛋的产地[12]。
上述研究中大多是研究鸡蛋内部品质,对鉴别鸡蛋产地溯源的研究较少且方法比较繁琐。本研究利用自行搭建的可见-近红外光谱检测装置,提取不同产地鸡蛋的可见-近红外透射光谱,运用直接正交信号校正结合t分布式随机邻域嵌入(t-SNE)方法来提取光谱特征信息,再将光谱特征信息输入随机森林建立产地溯源模型,为进一步研究与开发鸡蛋产地溯源便携式仪器提供技术支持。
1 材料与方法
1.1 材料与仪器
鸡蛋 共4种,均取自于湖北武汉、孝感、恩施和黄石4个产地的外形、颜色相近鸡蛋,鸡种为罗曼粉,产蛋母鸡觅食品种均为青草、虫子及谷粒等(自然放养),鸡蛋日期相近(1~2 d),其中蛋重分布在45~65 g,蛋形指数分布在1.30~1.35。
USB2000+光纤光谱仪 美国海洋光学公司;L4探测器聚光透镜 美国海洋光学公司;ILX511线阵CCD探测器 日本索尼公司;LS-3000高功率卤素灯 广州标旗电子科技有限公司;EA-01鸡蛋新鲜度测定仪 以色列ORKA公司;MNT150数显卡尺 上海美耐特实业有限公司;JY103B电子天平 上海精平电子仪器有限公司。
1.2 实验方法
1.2.1 鸡蛋样本的挑选 测试前,清除蛋壳表面污渍,使用鸡蛋新鲜度测定仪抽样检测,新鲜度均达AA级。随机挑选4种鸡蛋各60枚(共240个样本)。然后将所有样本按照每种鸡蛋3∶1的比例选取训练集180个样本,测试集60个样本,并对所有的实验样本进行编号并称重。
1.2.2 光谱采集装置的搭建 采集装置包括6大部分,如图1所示。计算机中安装了与USB2000+光纤光谱仪配套的Specsuite光谱采集软件。探测仪为聚光透镜与线阵CCD探测器的组合,透镜被固定在探测器窗片上,将透过信号光聚焦到探测器上,提高了采集信号光的效率。光源有内置风扇,调节温度,保证鸡蛋采集后的新鲜度。

图1 鸡蛋光谱采集装置Fig.1 Egg spectrum collection device注:1:计算机;2:光纤光谱仪;3:光谱采集支架; 4:光纤探测仪;5:鸡蛋;6:光源。
1.2.3 光谱采集 采集光谱前,将光谱仪开机预热30 min。每枚鸡蛋样本水平横放在检测台上,探测仪对准鸡蛋长轴中心位置,重复扫描5次,取5次平均后的光谱曲线。采集参数设置:积分时间60 ms,平均扫描次数5次,平滑宽度设置为3。
1.2.4 光谱数据预处理 在实验的过程中不可避免会伴有高频随机噪音、基线漂移等因素的影响,为了消除这些影响,需对原始光谱数据进行预处理。利用中心化、归一化、标准正态变量(SNV)、直接正交信号校正(DOSC)、Savitzky-Golay平滑滤波(SG)和多元散射校正(MSC)方法进行光谱数据预处理,通过比较建模效果,确定最优预处理方法。
1.2.5 建模算法原理 ELM算法由Huang等提出,它是一种新型单隐层前馈神经网络,已经证明了ELM具有与神经网络相同的全局逼近能力[13-14]。RF具有分析复杂相互作用分类特征的能力,并且具有较快的学习速度,近年来已经被广泛应用于各种分类、预测、特征选择以及异常点检测问题中[15-16]。ELM建模中武汉、孝感、恩施、黄石鸡蛋的标签分别为[1 0 0 0]、[0 1 0 0]、[0 0 1 0]、[0 0 0 1];RF建模中武汉、孝感、恩施、黄石鸡蛋的标签分别为1、2、3、4。
1.2.6 光谱降维方法原理 利用t分布式随机邻域嵌入(t-SNE)对光谱数据进行降维。SNE即Stochastic Neighbor Embedding,是Hinton在2002年提出来的算法,在高维空间相似的数据点,映射到低维空间距离也是相似的[17-18]。t是表示t分布,本文选用t分布的自由度为1。利用t-SNE将经过预处理后的光谱数据分别降到2、3、4、5维,通过建模分析来确定最优维数。

表1 不同产地鸡蛋的基本参数分析Table 1 Analysis of the parameters of egg between different origin
注:同一行数据肩标不同小写字母表示相互间差异显著(p<0.05)。
1.3 数据处理
利用Matlab2010b(Mathworks,美国)软件编写所有算法。Specsuite软件(海洋光学,美国)用于光谱数据采集。
2 结果与分析
2.1 鸡蛋样本原始数据
图2为所有鸡蛋样本的原始吸光度光谱曲线,光谱采集范围500~900 nm。
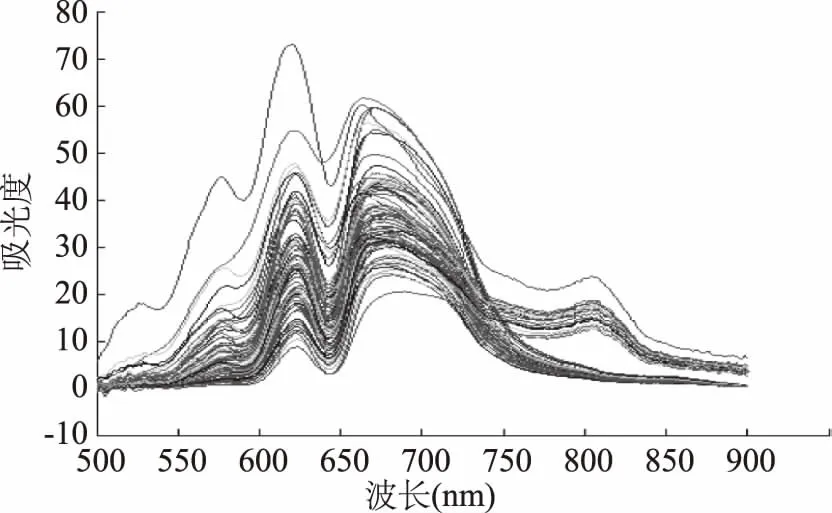
图2 鸡蛋吸收度光谱Fig.2 Original absorbance spectrum of eggs
2.2 各产地鸡蛋基本参数
光谱数据采集完后测量鸡蛋的长轴、短轴与蛋壳厚度。用精度0.01 mm的游标卡尺测量蛋的长轴、短轴和蛋壳厚度,结果见表1。
表1说明4个产地鸡蛋之间长轴、短轴、蛋壳厚度没有显著性差异不能通过这些基本参数来判别产地,且这些参数对光谱数据的影响相差不大,光谱数据可以表征鸡蛋内部信息。
2.3 预处理与建模方法选择
本文采用训练集十字交叉验证的准确率(cross validation Accuracy,CVaccuracy)、训练集准确率(Train Accuracy,TRA)、测试集准确率(Test Accuracy,TEA)来评价模型的好坏。准确率越高,说明模型的精度越高。表2为全波段建模方法比较。由表2可知,RF方法训练集准确率、测试集准确率、交叉验证准确率均高于ELM方法,RF建模方法效果优于ELM建模方法,RF模型鲁棒性好,可以完成隐含特征的选择,并且提供一个很好的特征重要度的选择指标。

表2 建模方法比较Table 2 Comparison of modeling methods
表3为不同预处理的预测结果,可以得出,经过不同预处理的光谱数据得出不同的预测效果,通过比较,利用直接正交信号校正(DOSC)建立的模型效果最好,预测集正确率为96.11%,测试集准确率为95.00%,交叉验证准确率为92.42%。直接正交信号校正能够有效除高频随机噪音、基线漂移[19-20]。
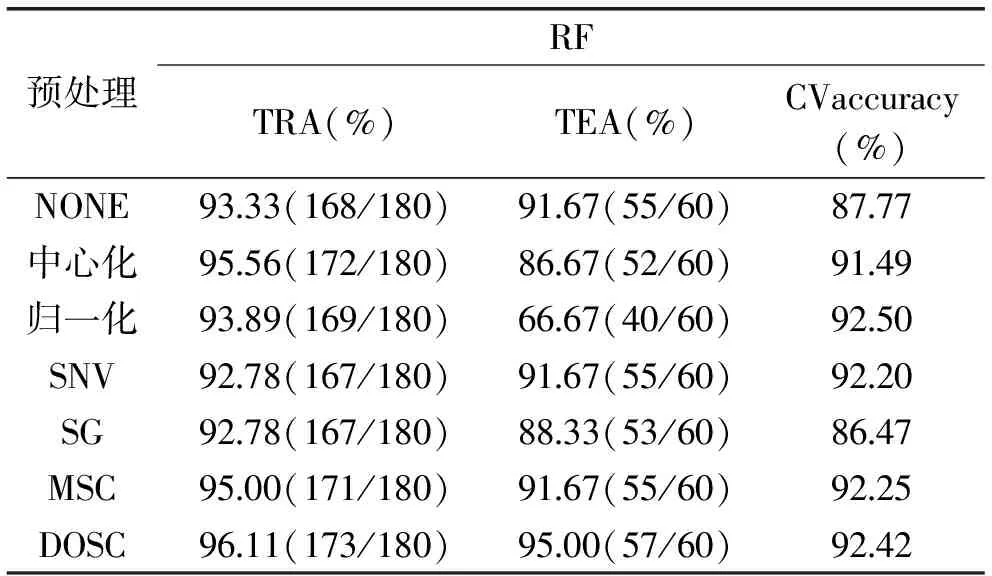
表3 不同预处理的预测结果Table 3 Prediction results based on different pretreatment methods
2.4 降维与建模
图3、图4为t-SNE、PCA降维后的3维可视化效果。

图3 t-SNE降维Fig.3 Dimension reduction of t-SNE
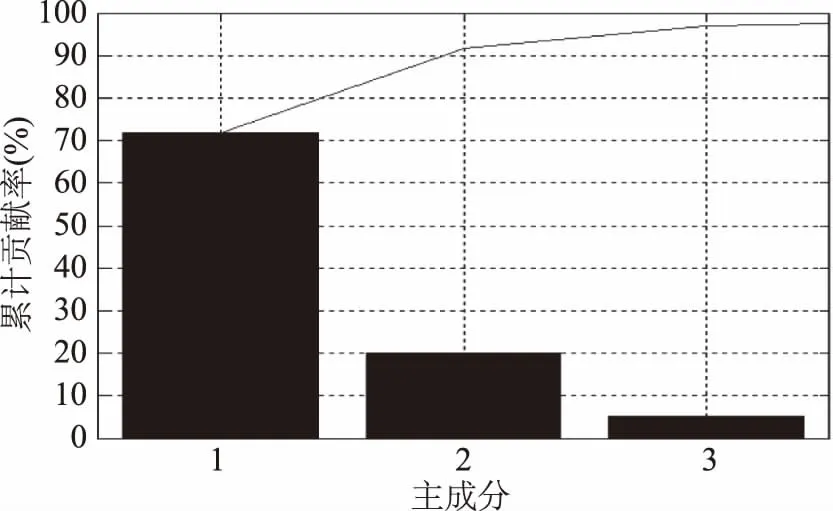
图4 前3个成分对应的累计贡献率Fig.4 Cumulative contribution rate of the first there principal components

表4 降维处理的结果Table 4 Results based on dimension reduction

表5 t-SNE下不同维数的预测结果Table 5 The prediction results of different dimensions based on t-SNE
分别获取降到3维的t-SNE、PCA数据,利用RF进行建模分析。其结果如表4所示。通过比较,利用t-SNE降维优于PCA降维与未降维。通过t-SNE方法不仅较好地保留了有效信息,而且极大地剔除了无效信息,减少了数据维数,进一步优化了模型。
表5显示t-SNE下不同维数的预测结果,通过表5可以得出,降到2、3位的效果低于4、5维,且降到4维和5维效果一样,在效果一样的前提下,优先选择维数小,有利于简化模型。所以选用4维数据来进行建模。
随机森林的起始性能往往相对较差,随着子决策树数目的增加,随机森林通常会收敛到更低的泛化误差(generalization error)。在机器学习中泛化误差是用来衡量一个学习机器推广未知数据的能力,即根据从样本数据中学习到的规则能够应用到新数据的能力。本文以利用袋外数据误差(OOB error)估计作为泛化误差[21]。袋外数据(OOB)误差的计算方法如下:对于随机森林,可以利用袋外数据进行性能测试,假设袋外数据总数为Y,用这Y袋外数据输入生成的随机森林分类器,分类器会给出Y个数据相应的分类,则用已知正确的分类与随机森林分类的结果比对,统计随机森林分类器分类错误的数量,设为X,则袋外数据误差大小为X/Y。图5为RF模型的袋外数据误差率。
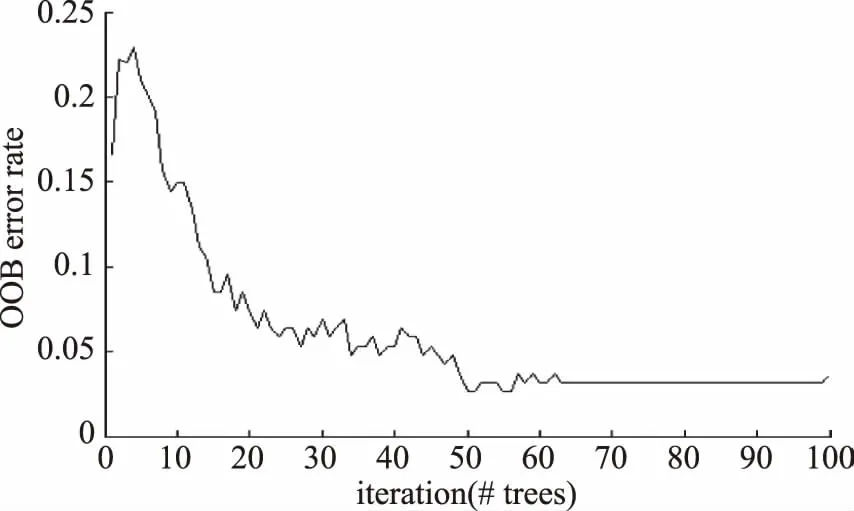
图5 袋外数据误差率Fig.5 Error rate of OOB
由图5可知,当模型生成63个子决策树时达到稳定状态,袋外数据误差率接近于0.03,使得随机森林不易过拟合。图6为预测集分类结果,其中1~15为武汉产地鸡蛋,16~30为孝感产地鸡蛋,31~45为恩施产地鸡蛋,46~60为黄石产地鸡蛋。

图6 预测集分类结果Fig.6 Results of predictive set classification
模型对于训练集和预测集样本的鉴别结果:训练集和预测集正确率为100%、98.33%,交叉验证准确率为93.50%,袋外数据误差率为0.03,单个鸡蛋测试运行时间为30 ms。
3 结论
本文提出了包括直接正交信号校正(DOSC)、t分布式随机邻域嵌入(t-SNE)结合随机森林(RF)的方法对湖北4个地区鸡蛋产地溯源。直接正交信号校正方法能够消除可见-近红外光谱中的高频随机噪音、基线漂移。运用t分布式随机邻域嵌入将光谱数据降维,得到鸡蛋光谱低维空间的特征信息,提取有效信息,剔除无效信息。利用RF算法建模,具有较低的袋外数据误差率,可以避免模型过拟合,提高模型的鲁棒性。
提出的基于可见-近红外光谱技术的鸡蛋产地溯源方法的验证精度高,训练集和预测集正确率为100%、98.33%,说明利用该技术可用于鸡蛋产地溯源,为下一步开发便携式光谱检测设备提供技术支持。
[1]Blanco M,Villarrova I. NIR spectroscopy:a rapid-response analytical tool[J]. Trac Trends in Analytical Chemistry,2002,21(4):240-250.
[2]严衍禄,赵龙莲,韩东海,等.近红外光谱分析基础与应用[M].北京:中国轻工业出版社,2005:15.
[3]王徽蓉,陈新亮,李卫军,等. 玉米品种近红外光谱的特征分析与鉴别方法[J].光光谱学与光谱分析,2010,30(12):3213-3216.
[4]何勇,李晓丽,邵咏妮. 基于主成分分析和神经网络的近红外光谱苹果品种鉴别方法研究[J].光谱学与光谱分析,2006,26(5):850-853.
[5]李晓丽,唐月明,何勇,等. 基于可见/近红外光谱的水稻品种快速鉴别研究[J].光谱学与光谱分析,2008,28(3):578-581.
[6]徐文杰,刘茹,洪响声,等. 基于近红外光谱技术的淡水鱼品种快速鉴别[J].农业工程学报,2014,30(1):253-261.
[7]郝勇,孙旭东,高荣杰,等.基于可见/近红外光谱与SIMCA和PLS-DA的脐橙品种识别[J].农业工程学报,2010,26(12):373-377.
[8]段宇飞,王巧华,马美湖,等. 基于LLE-SVR的鸡蛋新鲜度可见-近红外光谱无损检测方法[J].光谱学与光谱分析,2016,36(4):981-985.
[9]王巧华,李小明,段宇飞. 基于CUVE-PLS-DA的鸡蛋新鲜度在线检测分级[J].食品科学,2016,37(22):187-191.
[10]祝志慧,谢德君,李婉清,等. 基于光谱技术和多分类器融合的异物蛋检测[J].农业工程学报,2015,31(2):312-318.
[11]孙俊,刘彬,毛罕平,等. 基于介电特性的鸡蛋品种无损鉴别[J].食品科学,2017,38(6):282-286.
[12]戴祁,肖冬光,钟其顶.稳定同位素在鸡蛋签别及溯源中的应用研究[D].天津:天津科技大学,2016.
[13]Guang-Bin Huang,Qin-Yu Zhu,Chee-Kheong Siew. Extreme learning machine:a new learning scheme of feed forward neural networks[J]. IEEE International Joint Conference on Neural Networks,2004,2:985-990.
[14]Breiman L. Random Forests[J]. Machine Learning,2001,45(1):5-32.
[15]Strobl Carolin,Boulesteix Anne-Laure,Kneib Thomas,et al. Conditional variable importance for random forests[J].BMC Bioinformatics,2008,9(1):1-11.
[16]Mohammed Khalilia,Sounak Chakraborty,Mihail Popescu.Predicting disease risks form highly imbalance data using random forest[J]. BMC Medical Informatics and Decision Making,2011,11(1):1-13.
[17]L J P van der Maaten. Accelerating t-SNE using tree-based algorithms[J].Journal of Machine Learning Research,2014,15:3221-3245.
[18]L J P van der Maaten,G E Hinton. visualizing high-dimensional data using t-SNE[J]. Journal of Machine Learning Research,2008,9(12):2579-2605.
[19]李玉军,汤晓君,刘君华.直接正交信号校正算法在烷烃类多组分气体定量分析中的应用[J].光谱学与光谱分析,2012,32(4):1038-1042.
[20]胡国田,何东健,Kenneth A Sudduth.基于直接正交信号校正的土壤磷和钾VNIR测定研究[J].农业机械学报,2015,46(7):139-145.
[21]David H Wolpert,William G Macready. An efficient method to estimate bagging’s generalization error[J]. Machine Learning,1997,5(1):1-16.
