基于知识图谱的国外数据科学研究状况分析
2018-01-16叶文豪王东波
叶文豪 王东波
(南京农业大学信息科学技术学院 江苏 南京 210095)
1 引言
当“大数据”一词取代“信息”成为了一个新时代的标志[1],大数据的重要程度就不言而喻了,而数据科学正是应对大数据挑战所必须的一门多学科多技术融合的新兴学科[2]。“数据科学”一词早在20世纪60年代就已经出现[3],但直到20世纪90年代才开始有它准确的名称——“data science”[4]。21世纪以来,随着信息产业的发展,数据开始呈指数增长,体量大、形式多样等一些大数据的特征为大数据的研究和利用带来了很大的挑战,在这样的背景下,各个领域的学者们纷纷将关注点转向了数据科学,促使数据科学成为了近几年来国际上普遍关注的热点领域。目前,我国在数据科学方面的研究方兴未艾。王曰芬等学者在《国外数据科学研究的回顾与展望》一文中对国外数据科学的研究现状进行了计量分析,在此基础上归纳总结了数据科学的内涵界定与应用方向,最后提出了目前国外数据科学研究面临的问题和未来的发展趋势,为我国数据科学研究的发展提供了参考和借鉴[5]。本文尝试基于王曰芬等学者的研究,在Web of Science核心合集数据库中扩充检索式,对下载得到的国外数据科学相关文献进行更深入的可视化分析,并结合对下载到的一些文献的深入阅读,分析数据科学研究目前仍面临的一些问题和挑战以及其未来的发展趋势。
2 数据来源
本文数据来源选取Web of Science核心合集数据库。笔者于2017年2月23日在Web of Science核心合集数据库中设置检索条件如下:检索式为:“主题:(“data science”) OR 主题:(“data scientist*”)OR主题:(“datafication”),数据库选择为:SCI-EXPANDED、 SSCI、 CPCI-S、 CPCI-SSH、 CCR-EXPANDED, IC,时间跨度=所有年份,共得到861条记录,涉及时间范围1994-2017,其中收录的最新一篇跟检索主题相关的文献是Snasel V、Nowakova J等人于2017年2月发表在FUTUREGENERATIONCOMPUTERSYSTEMS-THEINTERNATIONALJOURNALOFESCIENCE期刊上的GeometricalandtopologicalapproachestoBigData一文,汇集了关于大数据的几何和拓扑方法的最先进的研究成果[6]。将检索到的文献导出引文全记录,并进行各年份文献量的统计,得到了图1所示发文量年份分布图(考虑到2017年的文献量还将继续增长,所以本文在绘制发文量年份分布图时去除了2017年的数据)。从图1中可以看到数据科学相关文献数量年份分布情况,2011年以前各年份论文发表数量一直保持在10篇以下,2012年发文数量出现拐点,进入逐年增长趋势,并从2014年开始呈现急剧增长,这表明国外真正对于数据科学的研究是近几年才开始兴起的,伴随着大数据的研究热潮,学者们纷纷开始关注这样一门研究数据的科学,以期能够更好地为迎接大数据时代的挑战提供理论与技术上的支撑[7]。
通过对下载的数据进行文献来源出版物的统计,发现本文所检索到的数据科学主题相关论文来源于577种期刊,这说明目前国外对于数据科学的研究较为零散,尚未形成领域内的核心期刊集。本文选取了其中刊文量最多的前十个刊物绘制了期刊来源分布图(图2所示),从图中可以发现数据科学相关论文主要来源于LECTURENOTESINCOMPUTERSCIENCE、STATISTICALANALYSISANDDATAMINING等期刊,这表明国外对于数据科学的研究主要还是基于以计算机科学、统计学领域为主导的数据处理方法、工具的探索和研究,还没有形成相对独立的数据科学领域的核心理论与应用支撑,这也是由数据科学本身的多学科融合性质所决定的。
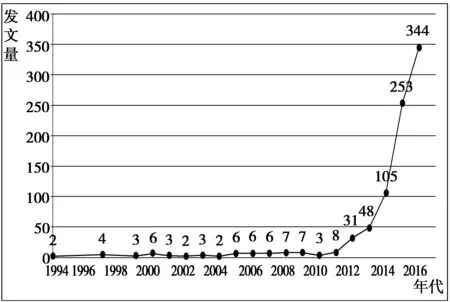
图1 数据科学研究相关文献发文量年份分布图
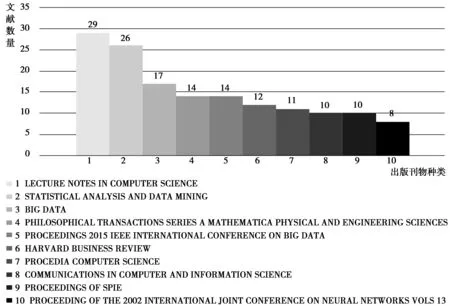
图2 文献期刊分布图
3 可视化分析
笔者在利用CiteSpace软件对从Web of Science核心合集数据库中下载所得数据进行相关知识图谱的绘制之前,对CiteSpace软件的界面进行了如下参数设置:根据笔者检索得到数据的时间覆盖范围,选取时间段为1980-2017,时间切片为1年,LinkStrength选择Cosine算法,数据抽取对象选择Top50,引文数量(c)、共被引频次(cc)和共被引系数(ccv)的阈值选择为(2,3,15)、(3,3,20)、(3,3,20),具体每年分区的阈值由线性内插值来决定。之后再分别选择对应的节点进行作者合作网络图谱、机构合作网络图谱、关键词共现网络图谱以及文献共被引网络图谱的绘制,并对这些图谱进行解读,从而探析数据科学在国外的研究现状。
3.1 作者合作网络分析
首先选择节点类型为“Author”,利用CiteSpace软件绘制出作者合作网络图谱。图谱显示笔者在Web of Science中下载得到的数据科学相关的文献共涉及1 631位作者。但由于作者数量非常多,网络图谱又非常零散,所以为方便呈现,笔者生成了发文数在2篇及以上的作者之间的合作网络(图3),图谱显示生成了138个节点之间的211条连线,其中发文数在4篇及以上的作者共有8位(见表1)。这些作者近年来在数据科学领域开展了一系列的研究,通过对他们的文献进行进一步的阅读,发现其文献产出年份都比较新,基本分布在2015年和2016年,但他们的研究方向各有侧重。文献产出量最高的作者是 Georgia Institute of Technology(乔治亚理工学院)的Kalidindi SR。Kalidindi SR在数据科学方面的研究方向主要是新兴的材料数据科学和信息学学科(MDSI,Materials Data Science and Informatics),其数据科学相关论文中主要探讨了材料数据的存储、管理、处理、分析等问题,以便更好地为材料开发和部署工作提供决策支持[8-11]。另外Leung CK,Vatrapu R,Provost F,Mondal K,Moat HS,Preis T,Hussain A也是产出文献相对较多的学者。Leung CK近几年来的研究主要体现在频繁模式挖掘上,其最近的一篇数据科学相关论文中提出了一种用于频繁模式大数据分析的数据科学模型,在挖掘和分析大数据方面具有较高的效率和实用性[12]。Vatrapu R则主要是对社
会数据分析方法进行了相关的研究,他们提出了一种称为社会集分析的大数据分析方法,来弥补在涉及组织、社会单位的分析时对于其社会媒体影响力的概念化、分析、解释和预测上的局限[13]。其他的作者也分别从理论、方法、应用等角度对数据科学进行了相关的研究。从图3可以看出,作者合作网络整体呈现较为分散的状态,未形成核心的中间节点,一方面可能是由于数据科学的应用领域在不断扩展,彼此之间没有合作关系的学者独立进行各自领域的数据科学研究,本文建议各个不同领域的学者之间加强合作关系,从而促进数据科学在各个领域更好地融合发展;另一方面笔者认为这也进一步证实了国外数据科学的研究尚处在初步发展阶段,还未形成领域内的核心研究团队。
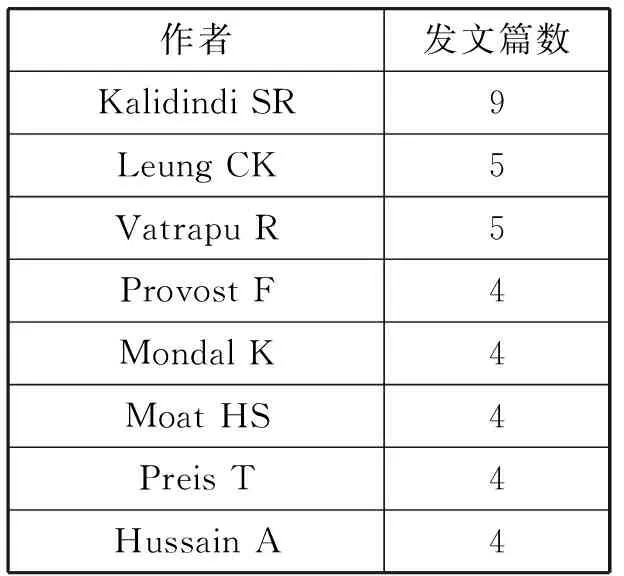
表1 发文数3篇以上的作者
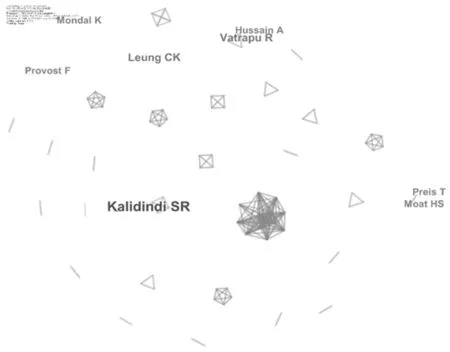
图3 作者合作网络
3.2 机构合作网络分析
选择节点类型为“Institution”,利用CiteSpace软件绘制出机构合作网络图谱(图4)。图谱共生成452个结点之间的778条连线,其中出现频次最高的机构是MIT(16篇),近几年来MIT的计算机科学和人工智能实验室(MIT CSAIL)对数据科学展开了大量的研究,并取得了一系列的研究成果。MIT CSAIL的Max Kanter和他的指导老师Kalyan Veeramachaneni等人在2015年设计出了Data Science Machine,其突破点在于利用深度特征合成算法实现了从原始数据自动导出预测模型[14],为数据科学的自动化做出了重大贡献。另外,以MIT CSAIL的Dong Deng和Raul Castro Fernandez为核心的一支国际化的科研团队近期发布了一个全新的大数据分析系统——Data Civilizer[15],该系统旨在帮助分析人员快速找到组织内包含其所需相关信息的不同数据集,并且将相关数据集合在一起,以创建新的统一数据集,从而整合所需的数据,为数据科学家简化了数据的预处理过程,使其能够将更多的时间和精力用在分析数据上[16],这一项新的研究成果为数据处理工具带来了新的研究方向,将推动数据科学更快速地发展。除MIT之外,Georgia Inst Technol(13篇)、Stanford Univ(13篇)、NYU(13篇)、Univ Washington(13篇)、Harvard Univ(13篇)等高校也较为活跃,笔者在上文提到的文献产出量最高的作者Kalidindi SR就是Georgia Inst Technol高校职员。另外,现任职于Georgia Inst Technol的C.F.Jeff Wu教授是最早推广“data science”这一术语的[17]。近年来,这些高校也都在不断开展数据科学方面的项目和计划,并且也已经开始关注数据科学人才的培养问题,如纽约大学、斯坦福大学等就新开设了数据科学相关的硕士学位[18]。从图4可以看出这些高校之间的合作关系相对来说比较密切,这在一定程度上能够为进一步融合各高校的强势学科、促进数据科学的快速发展带来更广阔的空间。
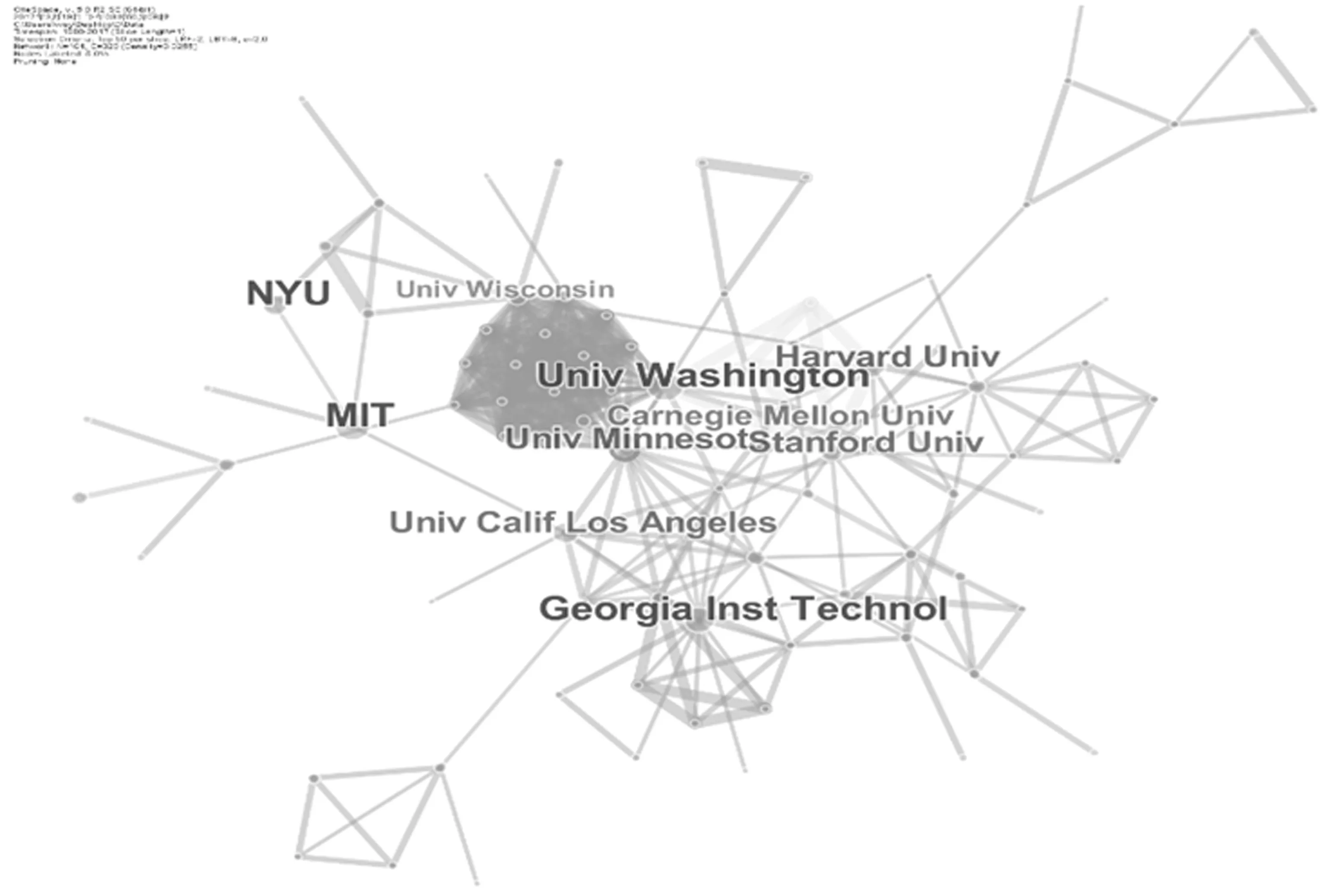
图4 机构合作网络
3.3 关键词共现网络分析
为了对数据科学领域的研究热点进行考察分析[19],本文在CiteSpace软件中选择“Keyword”节点类型,利用CiteSpace软件对下载文献中出现频次大于等于2的关键词进行共词网络分析,得到图5所示关键词共现网络。表2给出了频次统计前十的高频关键词出现的频次以及它们的中心性。通过对这些关键词进行综合分析,从以下几个方面总结国外数据科学的研究热点:从研究对象来看,数据科学的研究对象是大数据,王曰芬、谢清楠、宋小康三位学者在《国外数据科学研究的回顾与展望》一文中给出了“big data”和“data science”相关主题的文献发文量时序分析对比图[5],对比分析发现“data science”和“big data”的发文量年度分布走势基本相似,进一步表明了数据科学和大数据之间的强关联性,数据科学正是基于大数据的出现而成为了研究热点。从研究方法来看,数据科学的研究方法、技术主要集中在“machine learning”“model”“system”“data mining”“network”等方面。“machine learning”体现了机器学习在数据科学领域的应用,机器学习是当今增长最快的技术领域之一,是人工智能和数据科学的核心。数据密集型机器学习方法的采用可以在科学、技术和商业领域得到应用,从而为医疗保健、制造业、教育、金融建模、警务和市场营销等多个领域提供更多决策支持[20]。伴随着计算机技术的发展,数据挖掘的诞生,越来越多的机器学习算法得以开发和实现,并被应用到实际的领域当中。Amparo Alonso-Betanzos等人在他们最新发表的Volume,varietyandvelocityinDataScience一文中总结了近期关于数据科学的算法研究[21]。随着数据科学被应用到越来越多的领域,不同领域的学者也都在不断探索适合本领域数据的特征模型,开发针对特定领域的数据处理和分析系统。“network”则反映出了数据科学在大数据可视化方面的研究。随着数据科学在决策中的价值体现越来越突出,怎样将数据分析得到的结果更好地呈现出来,以便决策者能够更有效地理解和利用信息就成为了关键问题。目前network是一个比较普遍的可视化方式,将数据之间的关联通过网络的形式体现出来。这一方式在表现社交关系时非常方便,但如何根据数据本质特征设计可表达的几何空间,如何建立数据空间与可表达的几何空间
的映照等仍是可视分析的最根本科学问题[7]。近年来,维数降低技术对于数据的可视化起着越来越重要的作用。维度降低技术与视觉大数据之间的联系将为对该领域感兴趣的团队带来巨大的机遇和挑战[6]。从应用的角度来看,“management”反映了数据科学在管理方面的应用,数据科学能够更好地帮助企业进行供应链的管理并且为企业相关决策提供支持[22]。通过图5可以看到,这些关键词与“data science”的关联程度都比较高,反映了目前对于数据科学的研究热点集中体现在数据科学的研究对象、研究方法和其相关的应用方面。
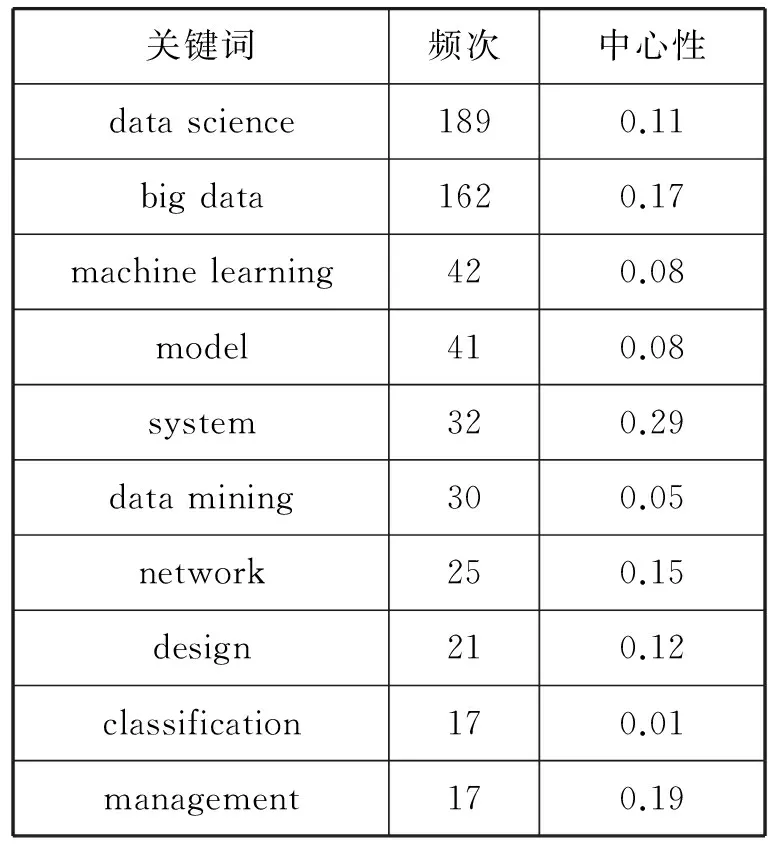
表2 高频关键词
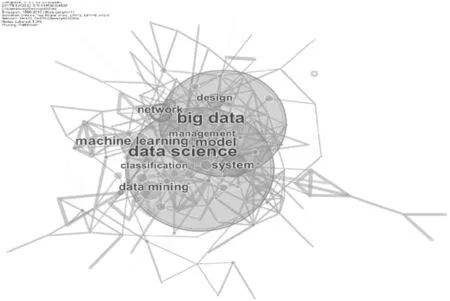
图5 关键词共现网络
3.4 文献共被引分析
CiteSpace软件提供的文献共被引分析可以用来帮助分析相关领域的知识基础及研究前沿[19]。通过CiteSpace软件中的“Cited Reference”节点类型,生成了共被引频次在两次及以上的文献共被引网络,网络中包含192个节点。对生成的共被引网络进行聚类,选择K命名方式(从施引文献中抽取indexing terms命名聚类),使用LLR算法对类标签进行抽取,得到了共被引网络的聚类图,图中共生成了74个聚类,图6截取了其中的一部分。从图6中可以看到“predictive analytics”“social data analysis”“principal component analysis”“financial market”“cloud”等是生成的一些较大聚类的标签词。在这些聚类标识的基础上,总结数据科学领域的研究前沿主要是基于应用和技术方法方面。应用方面近年来主要表现在商业和政府的预测分析以及人文社科方面的社会数据分析上。在Bigdata:Thenextfrontierforinnovation,competition,andproductivity一书中,Manyika J等人主要对大数据在商业和经济上的价值进行了研究,强调商业领袖和政策制定者必须要能够捕捉到大数据带来的价值[23],引发了政府、企业对大数据的关注,从而促进了数据科学在预测分析方面的发展。预测分析正在影响许多不同的领域,从棒球和流行病学到预测和客户关系管理。制造商、零售商、软件公司和顾问正在创造性地发现使用预测分析在供应链管理和物流中的大数据的新应用[24]。预测分析能够帮助决策者更好地预测未来的形势,从而制定出更有效的决策,这一点在政府部门和商业领域有着很大的应用价值,尤其是在企业当中,预测分析已经逐渐成为了企业的核心竞争力,这也是企业越来越关注数据科学的一个重要原因。“social data analysis”这一聚类标签词则反映了近年来数据科学在人文社科方面的应用。社会数据的分析在一定程度上能够为人文社科的研究提供支持。马克思曾说过:一个学科理论的支撑必须建立在数学的基础之上,但对于很多的人文社科问题却没有办法从数学的角度进行解释和论证,随着大量社会数据的产生,越来越多的人文社科问题能够通过数据加以解释[7]。Ouyang Yi等人在其最新的一篇论文中提出了SentiStory,它是一个多粒度情感分析和事件总结系统,通过对微博数据库的相关数据进行处理和分析来研究社交媒体数据,从而从中发现多维和丰富的信息[25]。而在技术方法方面,图6中#5“cloud”聚类的MapReduce:SimpliedDataProcessingonLargeClusters一文中,Dean J等人对MapReduce进行了详细的介绍和说明,包括MapReduce的功能和原理等。MapReduce是一个编程模型,用于处理和生成大型数据集,极大地简化了大型集群的数据处理[26],推动了数据处理工具的快速发展。云计算的主要特点之一就是强调计算资源和空间的使用弹性、较少的管理投入和灵活的
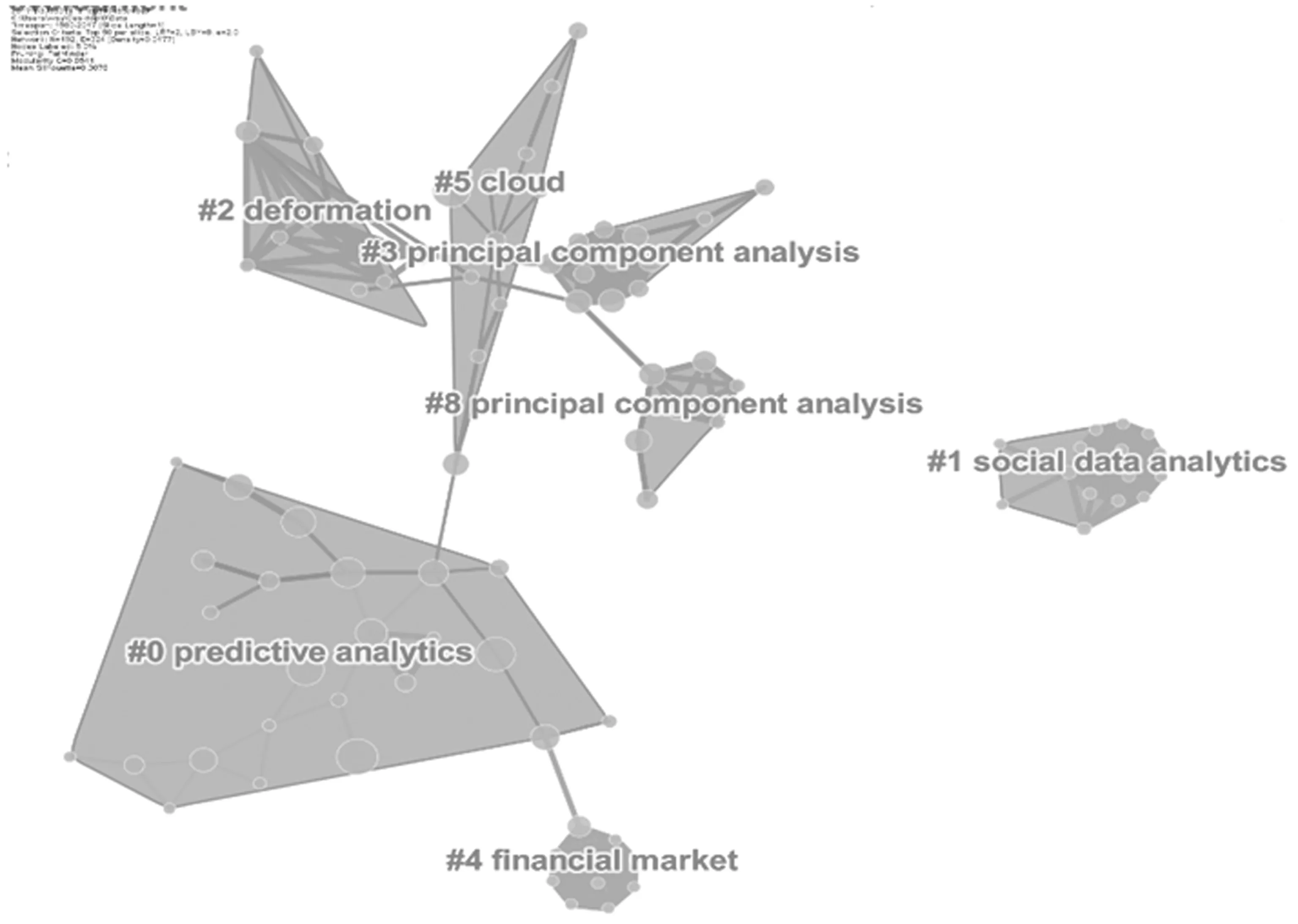
图6文献共被引网络聚类图
成本[27]。云端的出现为算法的实现提供了很好的平台,因此也推动了更多的开发者在数据科学方法(算法)上的创新。这些聚类中的高频次共被引文献在一定程度上可以认为是数据科学领域的知识基础,为数据科学的发展起到了一定的推动作用。而这些聚类的标签词则反映了目前数据科学方面的研究前沿。
4 数据科学研究面临问题及未来发展趋势
新的科学范式诞生于数据密集型科学发现(DISD),也被称为大数据问题。目前许多领域的科学研究都涉及到大数据问题。一方面,海量的数据中隐藏着非常多的有用价值,能够为企业生产力和科学进步的突破做出重大贡献,目前大数据已经引起了政府和企业的极大关注,未来的商业生产力和技术竞争将会融入更多的大数据探索。另一方面,大数据也面临着许多的挑战,随着信息增长的速度超过摩尔定律,过多的数据对人类造成巨大的困扰,在数据收集,数据存储,数据分析和数据可视化等方面仍存在着非常多的挑战与困难[28]。笔者综合对一些相关文献的内容分析,结合大数据的特征,从以下几个方面总结了数据科学研究目前面临的问题和挑战:
4.1 数据的初步处理
大数据的5V特征为数据科学的研究带来了很大的挑战。因此,越来越多的学者开始关注数据的处理方法,以便更好地利用数据。在数据处理方面,首先要面对的问题就是数据的整合、存储和管理等数据的初步处理。
大数据涉及具有多个独立来源的大量、复杂、不断增长的数据集[29],这就使得如何选择最有价值的来源并有效融合信息成为了数据科学领域的核心问题。Xu WH等人在其最新发表的一篇论文中就对这个问题进行了研究,他们首先提出内部信任度和外部信任度来估计多源信息系统中每个信息源的可靠性,然后构建源选择原则,允许选择值得和可靠的信息源。此外,通过将每个对象的原始信息转换为三角形模糊信息颗粒来构建新的信息融合方法,并且研究了该融合过程的一些不确定性度量[30]。整合完数据后就要对数据进行存储和管理。V.Dhar认为传统数据库的规模和功能已经不能满足海量数据的存储和管理[31],于是一些新的数据管理系统如并行数据库、网格数据库、分布式数据库、云平台、可扩展数据库等孕育而生,它们为解决海量数据提供了多种选择[32]。B.Allen等人则提出了服务型软件(SaaS)能够帮助解决大数据体量大这一特征带来的数据量的问题,并且他们还介绍了所研发的一种叫 Globus Online的数据管理系统[5],简化了研究人员的数据传送,简化了研究设施,其未来还将继续扩展该系统在数据共享方面的功能,促进团队之间的协调工作,为大数据的管理带来更大的方便[33]。另外,Mokhtar B等人提出了一种称为NetMem的分布式网络存储管理系统,能够有效地存储互联网数据,并在匹配和预测过程中提取和利用流量语义[34]。
4.2 数据的深度挖掘
大量异构数据,尤其是图片、视频、音频等多样化数据的出现,使得人们开始更多地关注半结构化或非结构化的数据,希望能从中挖掘出更多高价值的信息,但这些数据同时也为数据的深度处理增加了难度。这方面的研究主要基于以下几个方面:
(1)大数据语义理解与分析。大数据语义分析技术将为基于网络大数据的理解提供关键支持, 是众多大数据应用的基础[35]。这方面主要有两个关键的任务:一是大数据自然语言识别,二是非结构化数据的知识发现、集成技术。目前在大数据的自然语言识别方面已经有了较为成熟的发展,例如目前百度地图等在语音识别方面的技术已经取得了非常好的应用效果。而对于非结构化数据的知识发现,则需要对图像、音频等这些非结构化数据进行概念识别,进而从中提取出相关的知识。近年来,随着机器学习在数据科学的应用,越来越多基于机器学习算法的数据处理方法得以实现,为数据的处理带来了很大的帮助。Mokhtar B等人提出了一种综合LDA和HMM的语义推理的混合智能技术,以提取基于语法和语义相关性学习模式和特征的网络语义[34]。另外,很多成熟的理论或技术被用来构建深度学习系统。使用深度网络构建的特征提取和分类算法在图像识别和语音识别中都取得了非常好的成绩。Dean等人采用深度网络在大规模图像识别任务中取得了突破性的进展[35]。
(2)异构数据的关联与融合。随着微信、微博的普及,大量图片、视频、音频等多模数据迅速产生,这就使得实现异构数据之间的关联与融合成为了研究的热点。近年来已经能够将文本、图像、视频等放在一个框架下去进行机器学习[7],但有效性问题仍没有得到解决。目前在信息融合方面的研究主要是基于不同模式特征的统一表示、相似性度量以及异构数据的语义关联分析这几个方面。在特征表示方面的关键问题是如何将不同形式的数据内容通过其语义相关性进行统一表示。目前比较常用的是基于子空间的映射技术。相似度计算方面主要有两类:一类是基于图模型的相似性度量方法;一类是基于学习的相似性度量方法。语义关联分析这方面,Jia等人提出了一种随机场模型,用来挖掘多媒体对象之间的关联关系[35]。C.A.Mattmann则认为数据处理中更重要的是要为数据深度处理和优化发现开发分享工具,因此,在设计分享工具时,需要发现将不同算法无缝集成到大数据架构的方法、软件开发和归档应汇集在一个体系下、数据在不同格式之间的读取可自动实现[5]。
(3)大数据的计算。解决大数据问题是一项具有挑战性和时间要求的任务,需要大量的计算基础设施来确保成功的数据处理和分析[36]。计算首先要有相应的技术支撑,如相适应的硬件技术、存储技术等[7]。GPU的出现为数据的并行计算提供了硬件支持。而MapReduce框架则为大数据的处理提供了较好的平台,但它仍存在着一些问题,因此又有一些新的框架基于其基础之上被设计出,Spark就是其中的一种,可以用来解决MapReduce所不擅长的迭代计算和交互式分析。目前也出现了一些针对分布式处理海量数据的具体任务的计算框架,它们一般以Hadoop平台为基础,提供了许多特定的操作或功能。例如,谷歌开发的Pregel,可以在通用分布式服务器上处理PB级别的图像数据,为海量图数据的查询与匹配提供了支持。研究显示数据挖掘、图遍历、有限状态机是并行化未来的热门方向[35]。
4.3 数据的分析与利用
数据采集、存储、管理与深度处理等最终目的是要挖掘出数据的价值,这也是数据科学兴起与发展的根本[5]。笔者从以下几个方面总结了如何对数据进行更好地分析与利用:
(1)数据的多维分析与可视化呈现。数据科学的研究是为了对大数据进行处理和分析,从而从海量异构数据中获取有价值的知识,为决策服务,而决策是多维的,这就需要相关的分析人员能够从数据的不同维度出发对数据进行分析,然后整合成能够为决策提供服务的信息。但其实每个人对于信息的理解程度和方向都是有所不同的,因此对于大数据问题来说,将全民的智慧集中起来,从不同方面对数据进行理解和分析,将会给大数据的利用带来更大的价值,而要做到这一点,将大量数据以可视化方式呈现出来是必不可少的[7]。实际上“network”的表示就是大数据可视化的一种重要表现,但对于许多数据,靠简单的“network”并不能得到很好的体现。数据可视化的挑战主要来自于数据的大尺寸和高维度。目前的可视化技术受到功能性差,可扩展性和响应时间差等缺陷的影响[34],我们可能需要重新考虑可视化的方式。此外,可视化的有效性可能受到数据源不确定性的挑战。因此,这就需要更多的学者对于数据分析结果的可视化进行更深入的研究。
(2)数据科学的应用。目前的数据科学在互联网、金融等领域有了很好的应用效果,伴随着越来越多领域对大数据的关注,未来数据科学将在更多的领域得到实践应用,比如将数据科学与物联网、人工智能等的结合,将为人们的生活带来更大的便捷,智慧城市的建设理念就是基于此提出来的。Dobre C.等人认为智慧城市不仅需要依靠城市基础设施中的传感器,还需要依靠大量能够自觉感知和整合数据的技术平台。他们提出了一个用于大规模收集和汇总上下文信息的平台——CAPIM,它集成了用于收集位置、用户简档和特征以及环境等的服务,在此基础上,提出了一个在CAPIM上设计的智能交通系统的具体实现。该应用旨在帮助用户和城市官员更好地了解大城市的交通问题[37]。另外,数据科学在医药领域和人文社科领域的应用研究近年来也受到了广泛的关注,临床医疗相关的大数据和数据科学有可能能够为患者提供更多的了解病况的信息,以及定制针对患者特定情况的个性化策略服务[38]。而人文社科方面,则能够对其相关的一些社会问题的研究从数据的角度进行解释。最近对大型复杂网络及其属性的研究激增,社会网络的计算分析已经引起了相当大的关注。越来越多的人工智能和数据挖掘研究人员认为,一个大型组织(例如,一家公司)可以从其成员之间的非正式社交网络的互动中受益[39]。虽然数据科学的应用能够带来这么多的好处,但在对数据科学进行应用时仍需要考虑到一些问题。近年来关于数据科学应用的道德问题开始被一些学者所关注,Boyd D等人在CRITICAL QUESTIONS FOR BIG DATA一文中就对大数据崛起所带来的一系列道德、文化等方面的问题进行了讨论,激发人们对数据科学应用的思考[40]。de Montjoye等人则提出了一种动态保护个人元数据的新方法——openPDS和SafeAnswers,在一定程度上能够为数据科学研究中的数据隐私问题提供解决方案[41]。
(3)数据科学人才的培养。数据的高价值分析与利用离不开数据科学人才的作用。数据、技术和人是数据科学的三大支柱。数据无处不在,技术是为了应付越来越多的大数据问题而积极研发的,而人是远远落后于这两个要素的[42]。公司已经意识到他们需要聘请数据科学家,学术机构正在争相把数据科学计划放在一起,出版物正在将数据科学家推向热门甚至是“性感”的职业选择[43]。虽然数据科学的兴起使得数据科学家成为了近年来最热门的职业,但全球范围内数据科学人才却是十分短缺的。麦肯锡全球研究所的一份报告显示,到2018年,仅美国就面临 14万-19万数据分析专业技术人才以及 150万数据分析管理人才缺口[44]。一方面,数据科学人才本身的稀缺性造成了全球范围内数据科学人才的短缺;另一方面,高校对于数据科学人才的培养与市场对于数据科学人才的需求存在很大的差距[2],使得真正能适应市场需求的数据科学人才十分短缺。不过值得欣慰的是,目前许多高校已经开始关注数据科学人才的培养问题,并且也已经陆续开展了大批数据科学人才培养的计划和项目。
5 结语
通过国外数据科学相关文献的知识图谱研究分析,发现目前国外在数据科学方面的研究还处在初步发展阶段,尚未形成领域内的核心研究团队,并且其在理论、方法、应用等方面还有待更进一步的完善。但随着越来越多领域的学者针对各自所在领域的现实问题提出更多的数据科学需求,并展开相关的研究,可以预测未来数据科学将得到更大的发展,主要体现在对于数据的深度挖掘、可视化呈现及其应用方面。伴随着机器学习算法的实现,目前在数据挖掘方面已经有了很大的突破,未来将得到更成熟的发展。而在可视化方面,目前网络是最常用的一种方式,但网络对于关系的呈现仍然存在一定的缺陷,因此,未来在可视化方面的研究还有很大的发展空间。最后,在数据科学的应用方面,将在更多的领域扩展,结合不同领域数据的特征,挖掘出针对特定领域问题的解决方案。目前国内对于数据科学的关注度也越来越高,一方面越来越多的学者开始关注数据科学的理论和方法研究,另一方面越来越多的学者也开始关注数据科学人才的培养问题,并且一些高校也已经开始设置相关的专业、开设相关的课程,这对于我国的数据科学发展将有很大的推动作用。本文希望通过对国外的发展现状进行分析总结,为我国的数据科学发展提供参考借鉴,从而帮助更多的学者展开对国内数据科学的研究,以解决国内所面临的一些现实问题。
[1] 周傲英,钱卫宁,王长波.数据科学与工程:大数据时代的新兴交叉学科[J].大数据,2015,(2):90-99.
[2] 陈振冲,贺田田.数据科学人才的需求与培养[J].大数据,2016,2(5):95-106.
[3] Data science[EB/OL].[2017-02-25].https://en.wikipedia.org/wiki/Data_Science.
[4] 刘磊.从数据科学到第四范式:大数据研究的科学渊源[J].广告大观:理论版,2016,(2):44-52.
[5] 王曰芬,谢清楠,宋小康,等.国外数据科学研究的回顾与展望[J].图书情报工作,2016,60(14):5-14.
[6] Snasel V,Nowakova J,Xhafa F,et al.Geometrical and topological approaches to Big Data[J].Future Generation Computer Systems,2017,67(2):286-296.
[7] 徐宗本,张维,刘雷,等.“数据科学与大数据的科学原理及发展前景”——香山科学会议第462次学术讨论会专家发言摘登[J].科技促进发展,2014,10(1):66-75.
[8] Kalidindi S R.Data science and cyberinfrastructure: critical enablers for accelerated development of hierarchical materials[J].INTERNATIONAL MATERIALS REVIEWS,2015,60(3):150-168.
[9] Kalidindi S R,Medford A J,Mcdowell DL.Vision for Data and Informatics in the Future Materials Innovation Ecosystem[J].JOM,2016,68(8):2126-2137.
[10] Kalidindi S R,Brough D B,Li SY.Role of materials data science and informatics in accelerated materials innovation[J].MRS BULLETIN,2016,41(8):596-602.
[11] Kalidindi S R,De Graef M. Materials Data Science: Current Status and Future Outlook[J].ANNUAL REVIEW OF MATERIALS RESEARCH,2015,45(2):171-193.
[12] Leung C K,Jiang F,Zhang H,et al.A Data Science Model for Big Data Analytics of Frequent Patterns[C]//2016 IEEE 14TH INTL CONF ON DEPENDABLE, AUTONOMIC AND SECURE COMPUTING, 14TH INTL CONF ON PERVASIVE INTELLIGENCE AND COMPUTING, 2ND INTL CONF ON BIG DATA INTELLIGENCE AND COMPUTING AND CYBER SCIENCE AND TECHNOLOGY CONGRESS(DASC/PICOM/DATACOM/CYBERSC),NEW ZEALAND:Auckland,2016:866-873.
[13] Vatrapu R,Mukkamala RR,Hussain A,et al.Social Set Analysis: A Set Theoretical Approach to Big Data Analytics[J].IEEE ACCESS,2016,(4): 2542-2571.
[14] Kanter J M,Veeramachaneni K.Deep Feature Synthesis: Towards Automating Data Science Endeavors[C]//PROCEEDINGS OF THE 2015 IEEE INTERNATIONAL CONFERENCE ON DATA SCIENCE AND ADVANCED ANALYTICS (IEEE DSAA 2015),FRANCE:PARIS,2015:717-726.
[15] 恒亮.数据整理太繁琐?MIT发布能化零为整的分析系统[EB/OL].[2017-03-08]. http://www.leiphone.com/news/201701/H7Kntnaqe2nbDe0M.html.
[16] Larry.Hardesty.Taming data[EB/OL].[2017-03-08]. http://news.mit.edu/2017/system-finds-links-related-data-digital-files-quer ying-filtering-0119.
[17] Chipman H A,Joseph V R.A Conversation with Jeff Wu[J].STATISTICAL SCIENCE,2016,31(4):624-636.
[18] 赵柯然.数据科学50年(上)[J].情报理论与实践,2017,(1):145.
[19] 李杰,陈超美.CiteSpace科技文本挖掘及可视化[M]. 北京:首都经济贸易大学出版社,2016.
[20] Jordan MI, Mitchell TM.Machine learning: trends, perspectives,and prospects[J]. Science,2015,(2):255-260.
[21] Alonso-Betanzos A,Gamez JA,Herrera F,et al.Volume, variety and velocity in Data Science[J].KNOWLEDGE-BASED SYSTEMS,2017,117(1):1-2.
[22] Hazen B T,Boone C A, Ezell JD,et al.Data quality for data science, predictive analytics, and big data in supply chain management: An introduction to the problem and suggestions for research and applications[J].INTERNATIONAL JOURNAL OF PRODUCTION ECONOMICS,2014,154(2):72-80.
[23] Manyika J,Chui M,Brown B,et al.Big data: the next frontier for innovation, competition,and productivity[EB/OL].[2017-03-08].http://www.mckinsey.com/insights/business_technology/big_data_the_next_frontier_for_innovation.
[24] Waller M A,Fawcett S E.Click Here for a Data Scientist: Big Data, Predictive Analytics, and Theory Development in the Era of a Maker Movement Supply Chain[J].JOURNAL OF BUSINESS LOGISTICS,2013,34(4):249-252.
[25] Ouyang Yi,Guo Bin, Zhang Jiafan,et al.SentiStory: multi-grained sentiment analysis and event summarization with crowdsourced social media data[J].PERSONAL AND UBIQUITOUS COMPUTING,2017,21(01):97-111.
[26] Dean J,Ghemawat S.MapReduce: Simplied Data Processing on Large Clusters[J]. Communications of the ACM,2009,48(04):107-113.
[27] Fernandez A,del Rio S,Lopez V,et al.Fernandez AlbertoBig Data with Cloud Computing:an insight on the computing environment, MapReduce, and programming frameworks[J].WILEY INTERDISCIPLINARY REVIEWS-DATA MINING AND KNOWLEDGE DISCOVERY,2014,4(5):380-409.
[28] Chen CLP,Zhang CY.Data-intensive applications, challenges, techniques and technologies: A survey on Big Data[J].INFORMATION SCIENCES,2014,(3):314-347.
[29] Wu Xin-dong,Zhu Xing-quan,Wu Gong-Qing.Mining with Big Data[J].IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING,2014,26(1):97-107.
[30] Xu W H,Yu J H.A novel approach to information fusion in multi-source datasets: A granular computing viewpoint[J].INFORMATION SCIENCES,2017,(3):410-423.
[31] Dhar V. Data Science and Prediction[J].COMMUNICATIONS OF THE ACM,2013,56(12):64-73.
[32] 陆嘉恒.大数据挑战与NoSQL数据库技术[EB/OL].[2017-03-16]. http://book.51cto.com/art/201303/386849.htm.
[33] ALLEN B,BRESNAHAN J,CHILDERS L,et al.Software as a service for data scientists[J].Communications of the ACM,2012,55(2):81-88.
[34] Mokhtar B,Eltoweissy M.Big data and semantics management system for computer networks[J].AD HOC NETWORKS,2017,57(SI):32-51.
[35] 唐杰,陈文光.面向大社交数据的深度分析与挖掘[J].科学通报,2015,60(5-6):509-519.
[36] Hashem I A T,Yaqoob I,Anuar NB,et al.The rise of “big data”on cloud computing: Review and open research issues[J].INFORMATION SYSTEMS,2015,47(2):98-115.
[37] Dobre C,Xhafa F.Intelligent services for Big Data science[J].FUTURE GENERATION COMPUTER SYSTEMS-THE INTERNATIONAL JOURNAL OF GRID COMPUTING AND ESCIENCE,2014,37(3):267-281.
[38] Brennan P F,Bakken S.Nursing Needs Big Data and Big Data Needs Nursing[J].JOURNAL OF NURSING SCHOLARSHIP,2015,47(05):477-484.
[39] Liben-Nowell D,Kleinberg J.The link prediction problem for social networks[J].Journal of the Association for Information Science and Technology,2007,58(07):1019-1031.
[40] boyd D,Crawford K.Critical questions for Big Data[J].Information, Communication & Society,2012,15(5):662-679.
[41] de Montjoye Y A, Shmueli E, Wang S S,et al.openPDS: Protecting the Privacy of Metadata through SafeAnswers[J].PLOS ONE,2014,9(7): e98790.
[42] 王迪,王东雨.美国数据科学课程设置对信息素养的影响研究[J].商,2016,(14):200.
[43] PROVOST F,FAWCETT T.Data science and its relationship to big data and data-driven decision making[J].Big data,2013,1(1):51-59.
[44] Davenport T H,Patil DJ.Data Scientist: The Sexiest Job of the 21st Century[J].HARVARD BUSINESS REVIEW,2012,90(1):70-76,128.
[45] Chen C. CiteSpaceⅡ: Detecting and visualizing emerging trends and transient patterns in scientific literature[J]. Journal of the AmericanSociety for Information Science and Technology, 2006, 57(3): 359-377.
