深度学习在汽车制造物流规划工作中的应用
2018-01-15梅剑平潘荣胜
钱 丰,梅剑平,潘荣胜
(上汽大众汽车有限公司 计划物流部,上海 201805)
1 引言
近年来,建立在大数据基础上的人工智能取得了爆发式的发展,其影响已经迅速渗透到了我们日常生活中。而此轮发展的核心则是基于神经网络的深度学习在理论和实践上的突破,深度学习的方法具有较强的通用性。本文将结合汽车制造业物流规划中的一个案例,介绍一条将这种方法应用于日常工作的路径。
2 深度学习与神经网络简介
多伦多大学教授Hinton于2006年提出深度学习神经网络,使得神经网络训练性能取得突破性发展。2012年Hinton团队在ImageNet比赛中完胜对手,基于神经网络的深度学习开始被工业界重视,结合工业界的大数据,在各领域特别是在视觉和语音识别上准确率大幅提高,并以此为基础应用于人类日常生活与工作,显著提高了效率。
神经网络的工作原理是模拟人脑神经元的活动过程,在输入的大量数据中自发提取特征、总结规律,自我训练各神经元权重,调整神经网络结构,最终可以对未获取过的信息做出正确判别。其与传统人工智能的本质区别就在于,自发提取特征,调整结构,而不需要人工构建特征,设计算法。
一个神经网络的基本结构如图1,最基本有三层结构。输入层接受数据,其维度由输入数据的结构决定,一般由x表示。输出层为输出结果,其维度由需要获得结果的结构决定,一般由y表示。中间皆为隐藏层,至少有一层隐藏层,当有多个隐藏层时即为深度神经网络。
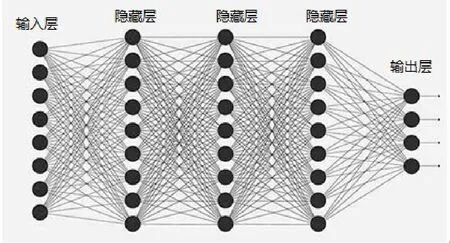
图1 深度神经网络结构示意

图2 单个神经元基本结构
单个神经元的基本结构如图2。一个神经元有多个输入,但只有一个输出。这与人脑神经元有多个树突、一个轴突是一致的。W为各输入的权重,加上偏置b,即为一个神经元获得的总输入g=再经过激活函数得到输出yk=Φ(g).激活函数的意义在于使神经元输出非线性。
所谓深度学习,即对深度神经输入大量样本x,以训练隐藏层的各神经元的输入权重。最终达到输出y与理想输出y'的误差最小。这样训练好的神经网络即可用于对未知的样本x0计算可靠输出y0。
工业实践中积累有大量数据,非常适合神经网络的训练。如汽车业的自动驾驶技术,就是基于大量司机实际的驾驶数据训练驾驶模型的神经网络,最终由车载计算机输出在不同场景下的正确驾驶反应。
获取大量规范化数据的成本很大,而且构建与训练神经网络的难度也较高。那么在物流规划的日常工作中是否也能利用深度学习来解决问题呢?本文将以一个实践的案例对此进行探讨。
3 问题描述
在汽车制造业物流规划工作中,最基本的一个参数就是流量,而流量是由零件数量与零件包装体积构成的。规划工作始于项目的早期阶段,零件的数量有较成熟的体系进行输出,输出偏差有良好控制。而零件包装体积则只能根据工作人员的经验进行预估。一般有以下方法:
(1)参考现有近似零件的包装。在大多数情况下,两个名称相同,零件号差异很小的零件,其外形不会有较大差异。参照类似零件的现有包装可以获得较准确的包装数据。但其中管状零件则较特殊,这些零件有较大的外形差异,即使在名称、零件号、功能与装配位置等基本一致的情况下,其包装体积也存在很大的不同。特别在当今从传动燃油车向混合动力与纯电动车转变的大趋势下,近似零件号、零件名称的零件外形差异很大,经常无法找到可参照的零件。
(2)根据零件三维图纸,使用包装软件模拟包装结果。该方法准确度通常较高,但是同样对于管状零件模拟误差很大。主要原因在于模拟时的限制条件是刚性的,而实际装箱与依靠零件外形的模拟有很大差异。
以下列举用上述方法估计的几个管状零件的结果比较,总体偏差很大,见表1。
用上述方法进行估计输出在一般情况下能满足整体规划的要求,如总体的资源配置等。但实际规划工作中,很多时候需要对个体零件物流体积有一个较准确的估计,如单个零件采购价格中物流成本的估计,生产线边某工位的首轮规划等。在涉及到管状零件时,由于存在估计偏差较大的问题,会对后续规划造成困扰。以下我们将采用深度学习的方法,构造一个估计零件包装体积的神经网络并进行训练。

表1 传统管状零件包装体积估计
4 零件包装体积预估的神经网络构建
我们将依次对深度神经网络的输出层,输入层与隐藏层进行分析与构建
4.1 输出数据层与损失函数
从我们所希望得到的结果出发,首先构筑输出层,可以为之后的工作提供一个明确的目标。而损失函数是训练过程中引导训练向最优化进行的关键函数。在本文的研究过程中,尝试过三种不同的输出结构与损失函数。
(1)直接输出体积。这是我们最直观的需求,即对一个具体样本神经网络输出计算的体积数值。损失函数即为所有参与训练的样本输出相对于标准值的偏差平均值。

虽然这种输出比较直观,但是神经网络的学习机制决定了这种输出并不合适。在后续的训练过程中,极易造成BP计算中的梯度消失。
(2)输出简单的分类。考虑到神经网络最适合进行分类输出,按我们得到的样本数据,将输出依体积分成十类,见表2。
以上是根据已经获取的样本数据的平均分布进行的分类。例如表1中列举的三个零件分别属于6,2,1类。对于每一个样本,输出是一个十维的one-hot向量。如表1中第一个零件属于类6,则输出的onehot向量为y'=(0,0,0,0,0,0,1,0,0,0)。损失函数则是输出向量与样本准确向量的交叉熵Cross-entropy

表2 输出结果分类
这种输出结构与损失函数虽然较易训练,但是由于我们的目标是获取一个体积数值,而非分类,所以这种输出无法满足需求的准确性。而且在训练中只要没有进入分类区,逐步接近准确数值的状态并不会比那些远离的状态更有优势。而一旦进入了分类,也就失去动力进一步靠近准确数值。
(3)输出逼近数值概率的分类。沿用方法(2)的分类。但输出不是one-hot的向量,而是一个考虑邻分类与本分类中数值逼近程度的向量。
v'-准确的体积数值;v'm-准确体积所在分类的中间数值;
v'max-准确体积所在分类的最大值;v'min-准确体积所在分类的最小值;
P1-准确体积所在分类的概率;P2-最邻近分类的概率。

其它分类的输出则仍然是0。
仍以表1中第一个零件为例,输出y'=(0,0,0,0,0,0,0.58,0.42,0,0),对应 0.002 7m3。
这种方式在训练落入分类与分类邻近区域时仍有动力逼近准确值,同时还能在获得输出后,通过对公式(1)的逆运算获得体积数值。这种输出的缺陷在于,与直接输出体积相比,目标还是存在一些偏差,但比常用的one-hot分类有了大幅度优化。损失函数同样是输出向量与样本准确向量的交叉熵
这种输出结构是笔者结合此问题的特殊性创造的,实验中也取得了不错的效果。
4.2 输入数据层与数据增强
输入层为我们能获取到的实际样本的参数结构。与目标有关的参数越多,训练效果越好,但也会造成计算负荷指数级的上升。同时也需要大量的样本数量,样本稀少极易造成过拟合。
具体到本文的问题,考虑与零件包装体积相关的参数主要是零件的外形,虽然零件的各部分材质等也会影响到实际包装,但此类参数较难获取并格式化。所以在本文中我们只取零件外形数据。
将获取的零件3D图纸先转为STL标准格式后再转化为11*11*11的体素图(如图3所示)。同时,大小不同的零件标准化为相同大小的体素图,则必然存在一个大小变化的比例值s,这个值将填入体素矩阵中有实物点的位置中。

图3 单个零件体素矩阵
最终输入x为m*1 331的列表(m为参与训练的样本数量)。
本文的实验中转化了156个管状零件样本的体素矩阵,并以此为基础进行训练。但相比于神经网络的要求,这个数据量还是非常小的。结合本文采用的卷积神经网络框架,笔者使用了数据增强技术(Data Augmentation)。在卷积神经网络中,通过卷积与池化可以实现平移不变性与小幅度旋转的不变性。但对于同一个样本的大幅度旋转或视角变化则会存在结果差异。我们对每一个样本从6个视角分别进行镜像和90度旋转,这样就能产生48个样本,总的样本数量即可增加到7 488个。图4是列举9个衍生样本的示例。
另外,还需要准备一批测试集数据,验证模型训练的效果与精度。测试集数据完全独立于训练样本,不参加训练。在本文中取了10个零件样本做测试集。
4.3 深度神经网络结构
整个神经网络构建如图5所示。
输入层获得的数据为样本的列表数据m*1 331。变形还原为三阶矩阵数据,对应零件的体素图,以供后续卷积处理。
隐藏层分两次卷积,两次池化,一次全连接层和一次Dropout,最终输出体积预测。
图4 单个零件体素矩阵衍生示例

图5 神经网络结构总图
卷积层(Convolutional Layer)本质上是一个滤波器。样本的每一部分与卷积窗口进行点积。通过对共享参数进行训练,最终形成一个能提取到样本区域特征的卷积窗口。每个通道提取一种特征。在复杂的模型中有多层卷积,以提取复杂而隐藏的特征。卷积层输出后将经过激活函数,以实现非线性化。本模型所用为Leakyrelu激活函数。
池化层(Pooling Layer)主要用来降维,将卷积层提取的特征中可能重复的部分剔除。同时实现特征的平移不变性,小旋转不变性。从模型中可以看到,每次池化后维度下降了一半。
全连接层(Densely Connected Layer)起到分类器的作用。卷积层、池化层和激活函数将原始数据映射到隐藏特征空间,全连接层重新将训练学习到的分布式特征映射到样本标记空间。
Dropout层在训练中按50%的概率随机丢弃一些全连接层的神经元。在本文模型中,由于数据样本较少,而模型有一定复杂度,很容易造成训练过拟合。Dropout的方法在实际训练中可以有效降低过拟合概率。
输出层在对Dropout层输出做Softmax操作后,即可得到样本属于各分类的概率。通过对损失函数的不断迭代优化以训练模型中所有参数。
5 深度学习实验结果
本文采用开源人工智能库Tensorflow构造了上述神经网络。训练与测试结果如图6。
Traingning Set Loss指训练过程中损失函数值的变化趋势,该指标用来跟踪神经网络的训练过程,理论上随着训练次数不断降低,最终达到稳定。
Testing Set Loss指训练好的模型用于测试集的损失函数值。实验中每隔100次优化即用测试集测试。从结果看趋势与训练集基本一致,说明不存在过拟合。
Testing Set Value Deviation指测试集在神经网络输出的概率矩阵转化为体积数值之后,与准确的体积数值的偏差率。由于本问题中损失函数与最终输出并不严格对应,偏差率才是最终验证输出质量的指标。从结果看,偏差率与损失函数趋势一致。最终稳定在0.32,即32%的偏差(其中最大偏差为44%,最小为7%)。

图6 训练与测试结果
对照表1中的几个例子,深度学习后的平均偏差率远小于传统方法,并且偏差波动较小,取得了相当明显的效果,具体见表3。
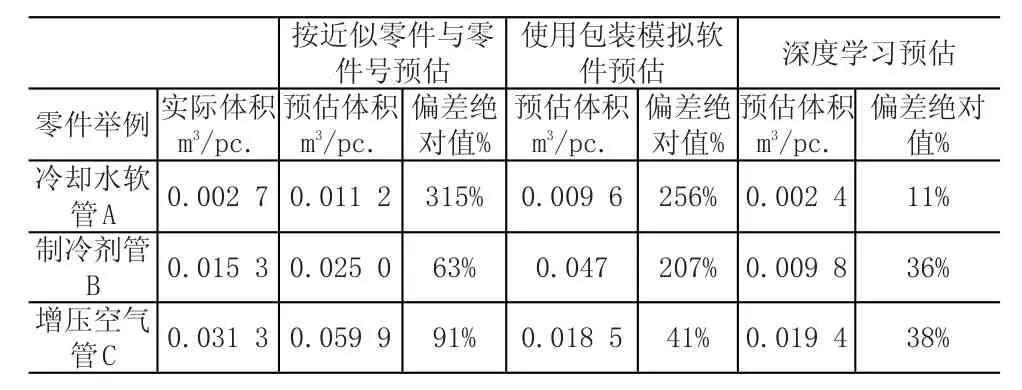
表3 深度学习结果对照
6 进一步的优化方向与展望
本文对深度学习方法在物流规划日常工作中的应用进行了有效地尝试,积累了经验,并已在实践中得到了应用,对工作有明显帮助。基于现有的结果,笔者认为还可以从以下方面进行优化。
(1)提高零件体素化像素精度。本文采用的分辨率为11*11*11,是考虑在不太高的运算负荷下能尽快测试多种建构模型。参考目前流行的手写数字数据集像素为28*28,可以将像素提高到20以上,在此基础上增加卷积层通道,可以进一步提高输出精度。
(2)获取更多的实验样本。本文仅获取了管状零件原始样本156个,后续可以建立完整的零件体素化数据库,范围扩大到所有零件。这样可以将输出结果的适用对象扩大到所有零件。虽然对于规则零件而言,由于参数与结果的映射关系比较简单,深度学习预估的精度不会比人工估计高,但可以为此环节自动化、智能化处理建立基础。
(3)多神经网络联结。零件包装基本参数应为包装箱型与装箱数,通过箱型尺寸计算单件包装体积。可以首先为箱型类别构筑神经网络,而这种分类问题也更适合深度学习方法。然后将零件图与箱型作为下一个神经网络的输入,装箱数作为输出。
7 结语
深度学习技术在近几年中的发展极其迅猛,不断有适合不同场景的新网络模式和训练方法出现。在习以为常的物流工作中也可以抓住前沿科技的发展,促进物流效率不断提升。
