基于卷积神经网络的固定群体中目标人物分类
2018-01-13刘惠彬
刘惠彬,陈 强,吴 飞,赵 毅
随着视频监控的普及,利用计算机技术实现人物分类的方法在社会安全、生产生活等方面发挥了重要的作用.近年来,很多基于图像特征的人物分类方法被提出.例如通过直方图、尺度不变特征变换(scale-invariant feature transform,SIFT)等方法提取图像特征,然后计算图像间的相似度来实现人物的分类[1-2],以及通过人脸识别技术实现对监控视频中人物的分类[3-4].但是,上述方法都需要对分类图像进行大量的前期处理,并且对图像的质量有较高的要求.为了解决上述问题,本工作提出了一种基于卷积神经网络的人物分类方法.
神经网络[5]是一种模仿生物神经网络进行分布式并行信息处理的数学模型,通常用于解决分类和回归问题.反向传播(back propagation,BP)神经网络在1986年被提出,但由于当时没有无监督的预训练,其性能比浅层神经网络差,而且受到当时软硬件条件的限制,隐层的数量被限制在1~2层.2006年加拿大多伦多大学的Hinton教授[6-8]指出:多隐层的人工神经网络具有优异的特征学习能力,学习得到的特征对数据有更本质的刻画,有利于可视化或分类;深度神经网络在训练上的难度可以通过“逐层初始化”来有效地克服,且逐层初始化可通过无监督学习实现.实质上,深度学习就是一种基于无监督特征学习和特征层次结构的机器学习方法,该方法通过构建包含多个隐含层的模型和海量训练数据,来学习更有用的特征,从而最终提升分类或预测的准确性.近年来,大数据技术的飞速发展使深度学习成为研究热点.作为深度学习的重要分支,卷积神经网络在图像识别、图像分类等方面应用广泛,并且取得了重大成功[9].
本工作对固定人物群体中的个体目标进行视频采集,然后利用直方图的归一化互相关方法从视频中截取帧间差超过阈值的图片,并将这些图片作为进入卷积神经网络的训练图片,再用未参加训练的图片与训练模型匹配,得到其与每个人匹配的相似度,其中预训练和目标匹配都在快速特征嵌入卷积神经网络框架Caあe中实现.将人物个体作为分类目标在深度神经网络中进行训练,避免了传统图像处理技术的弊端,这里因为传统技术在分类前需要对原始图像的视觉特征进行采集,而且选取的特征对分类的准确率起关键性作用.没有选择人脸识别技术,则是因为人脸识别需要的训练图片是人脸数据[3],要求将采集到的视频图像进行分割,而且实验用摄像头的性能无法保证人类图像的清晰度.
1 卷积神经网络及其工具
1.1 神经网络与深度学习
一个神经网络由多个神经元连接组成.神经网络的整体功能不仅取决于单个神经元的特征,更取决于神经元之间的相互作用和相互连接.神经元可以表示不同的对象,例如特征、字母、概念等.神经网络的处理单元可以分为3类,其中输入层单元连接外部的信号和数据,输出层单元实现系统处理结果的输出,隐含层单元则处于输入层和输出层之间,系统外部无法观察.神经元之间的连接权重控制单元间的连接强度,而整个系统的信息处理过程就体现在神经网络各处理单元的连接关系中.图1为包含一个隐含层的神经网络示意图.
神经网络是机器学习的一个庞大的分支,有几百种不同的算法,深度学习就是其中的一类算法.深度学习的训练过程分为两个阶段.
(1)自下而上的无监督学习.图2为深度学习的逐层调参过程.由图可以看出,在这一阶段,从输入层开始逐层构建单层神经元,每层采用认知和生成两个阶段对算法进行调优,每次仅调整一层,逐层调整.在认知阶段,通过下层的输入特征和向上的编码器权重初始值产生初始抽象表示,再通过解码器权重的初始值产生一个重建信息,然后计算输入信息和重建信息残差,并使用梯度下降修改层间的解码器权重值.在生成阶段,首先通过初始抽象表示和向下的解码器权重修改值,生成下层的状态,再利用编码器权重初始值产生一个新的抽象表示;然后利用初始抽象表示和新建抽象表示的残差,并利用梯度下降修改层间向上的编码器权重;最后利用修改后的编码器权重得到输入层的抽象表示(即隐含层).由上可知,在深度学习神经网络中每个隐含层可以看作下一个隐含层的输入.
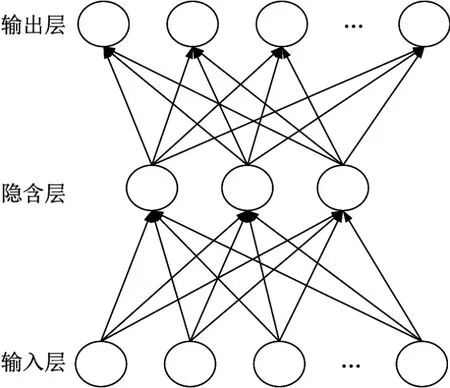
图1 包含一个隐含层的神经网络结构示意图Fig.1 Structure diagram of neural network with one hidden layer
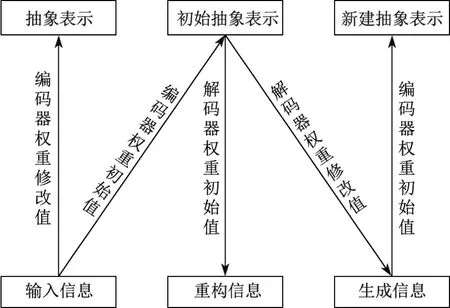
图2 深度学习的逐层调参过程Fig.2 Process of tuning parameters layer by layer for deep learing
(2)自顶向下的监督学习.深度学习的第一阶段实质上是一个网络参数初始化过程.第二个阶段是在第一阶段学习获得各层参数的基础上,在最顶的编码层添加一个分类器,然后通过带标签数据进行有监督的学习,并利用梯度下降法微调整个网络参数,即自顶向下重新调整所有层间的编码器权重.
与传统神经网络初值随机初始化不同,深度学习模型通过无监督学习输入数据的结构得到,因而这个初值更接近全局最优,因而能够取得更好的效果.典型的深度学习结构有卷积神经网络(convolutional neural network,CNN)、递归神经网络(recursive neural network RNN)和长短时记忆单元(long short-term memory,LSTM),其中卷积神经网络在图像识别和目标检测领域中的应用非常成功[10].
1.2 卷积神经网络
卷积神经网络[11]是为识别二维形状而设计的一个多层神经网络,主要有5个特征.
(1)局部感知.在图像的空间联系中,距离较近的像素联系较为紧密,而距离较远的像素相关性比较弱.因此,神经元没有必要对全局图像进行感知,而只需要感知相邻的局部图像,然后在更高层进行全连接得到全局信息.
(2)权值共享.在局部连接中,每个神经元与上一层的连接方式可以看作特征提取的方式,且该方式与位置无关.因此,在某部分学习的方式可以用在该图像所有位置上,实现权值共享,即利用同一个卷积核在图像上做卷积,如图3所示.权值共享和局部感知均可以使CNN模型参数的数量大幅减少.
(3)多卷积核.只用一个卷积核进行特征提取是不充分的,可以通过增加卷积核的个数使网络学习更多的特征,其中每个卷积核都会将图像生成为另一幅图像.
(4)池化.卷积之后得到的卷积特征向量较多,而在一个图像区域有用的特征极有可能同样适用于另一个区域.因此为了描述较大的图像,可以对不同位置的特征进行聚合统计,既可以降低统计特征的维度,又不容易过拟合.池化分为平均池化和最大池化两种方式.
(5)多个卷积层.一个卷积层学到的特征往往是局部的,层数越高学到的特征越全局化,因此,在实际应用中通常采用在网络中添加多个卷积层,然后再使用全连接层进行训练的方法.
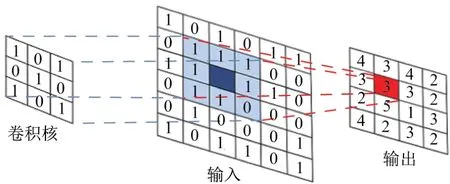
图3 卷积神经网络中的卷积过程Fig.3 Convolution process of convolutional neural network
1.3 Caあe框架
快速特征嵌入卷积神经网络框架(convolutional architecture for fast feature embedding,Caあe)[12]由毕业于加州大学伯克利分校的贾扬清博士开发,具有快速、可扩展、开放性等特征,是目前炙手可热的一个深度学习工具.Caあe是纯粹的C++/CUDA架构,支持命令行、Python和Matlab接口,可以在CPU和GPU之间无缝切换.本工作在进行目标匹配时直接通过Caあe的Python接口实现.在Caあe中,层的定义由层属性与层参数两部分组成.层属性包括层名称、层类型以及层连接结构(输入和输出).层参数的定义非常方便,可以随意设置相应参数,例如调用GPU进行计算时,只需要将solver mode直接设置成GPU.安装Caあe前,需要先安装Cuda,VS以及Opencv,Boost,Protobuf等第三方库.
在Caあe中实现目标匹配需要按以下步骤操作.
第1步 利用convert imageset命令调整图片大小,并生成leveldb格式或lmdb格式训练文件.
第2步 根据模型要求选择是否需要利用computeimage mean命令生成图像的均值文件.
第3步 根据训练图片个数和训练周期的要求,在solver和train val中调整训练参数.
第4步 利用Caあe的train命令进行训练,产生训练模型caあemodel文件.
第5步 利用Caあe的Python或者Matlab接口实现目标图片的匹配,并给出目标图片与每一类图片的相似度.
2 固定群体中的个体目标匹配
本工作的研究对象限定于固定人物群体,首先将某个办公室中的所有人物图片进行训练,产生训练模型,然后将群体中某个人物的图片在模型中进行匹配,并通过匹配结果得出该人物的身份,最后对多次匹配的结果进行统计,得出该人物的出现频率.
2.1 固定群体中训练模型的产生
(1)采集固定群体视频.本工作涉及的实验都是在固定单源摄像头拍摄的情况下获得的固定群体人物的视频,在Python中调用OpenCV的VideoCapture函数获取,并将实时视频写入文件.
(2)构建训练图片集.在视频采集过程中,首先将第一帧图像保存为关键图片,然后以此为基准依次计算新的视频帧与关键图片的帧间差,当帧间差超过一定阈值后将当前帧保存为下一个关键图片.循环计算得到所有满足与当前关键图片帧间差超过阈值的下一个关键图片,直到视频采集结束.
关键图片的帧间差通过比较直方图的相关性得到,其中直方图利用OpenCV的calcHist函数得到.帧间差通过cv2.compareHist(hist1,hist2,cv2.cv.CVCOMP CORREL)实现,其中第三个参数CVCOMP CORREL控制用直方图的归一化互相关方法计算帧间差,且有
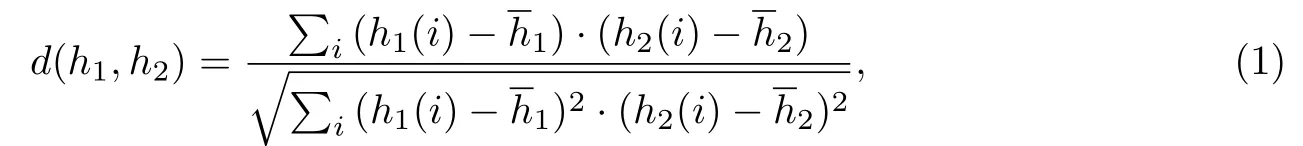

图4 固定群体中目标人物的部分关键图片Fig.4 Key Frames of individual object
(3)产生训练模型.CNN中典型的图像分类模型有AlexNet,GoogleNet等.实验证明,在训练数据有限的情况下,利用GoogleNet模型训练得到的准确率并不优于AlexNet模型,并且当卷积神经网络规模变大时,需要对网络进行压缩以解决参数量大和计算复杂度高等问题[13].因此,本工作采用AlexNet模型产生训练模型.AlexNet模型有5个卷积层和3个全连接层,如图5所示[14].
通过卷积(Conv)和池化(Pool)降低网络参数,并利用激活函数(ReLu)缩小无监督学习和监督学习之间的差距,不仅提高训练速度,也进一步通过局部响应标准化(local response normalization,LRN)和Dropout层提高了网络的泛化能力.为了减少训练时间,本工作利用较少的训练图片快速产生训练模型,同时在调参时将训练网络的最大迭代次数由450 000降低到250 000,在保证训练质量的情况下,缩短训练时长,并根据图片数量和机器配置设置base lr,testiter和batchsize等参数.
2.2 目标分类
(1)选取验证图片.验证图片一部分从参与训练的监控视频截取图片中选取验证图片,另一部分从重新拍摄的监控视频中获得,且在进行验证前将图片尺寸调整为256×256像素.
(2)目标分类.利用Caあe提供的Python接口,调用classify.py将jpg格式的验证图片在前期预训练产生的训练模型中进行匹配,并给出该目标匹配固定群体中每个目标的相似度.
(3)行为统计.目标匹配后,根据需求可在较大的时间周期(以周或月为单位)内给出个体目标的行为统计报告,如每周出勤情况、非工作时间返回办公室的次数及时间、单独进入机要室的次数及时间、黑名单人物进入场景的报警等.
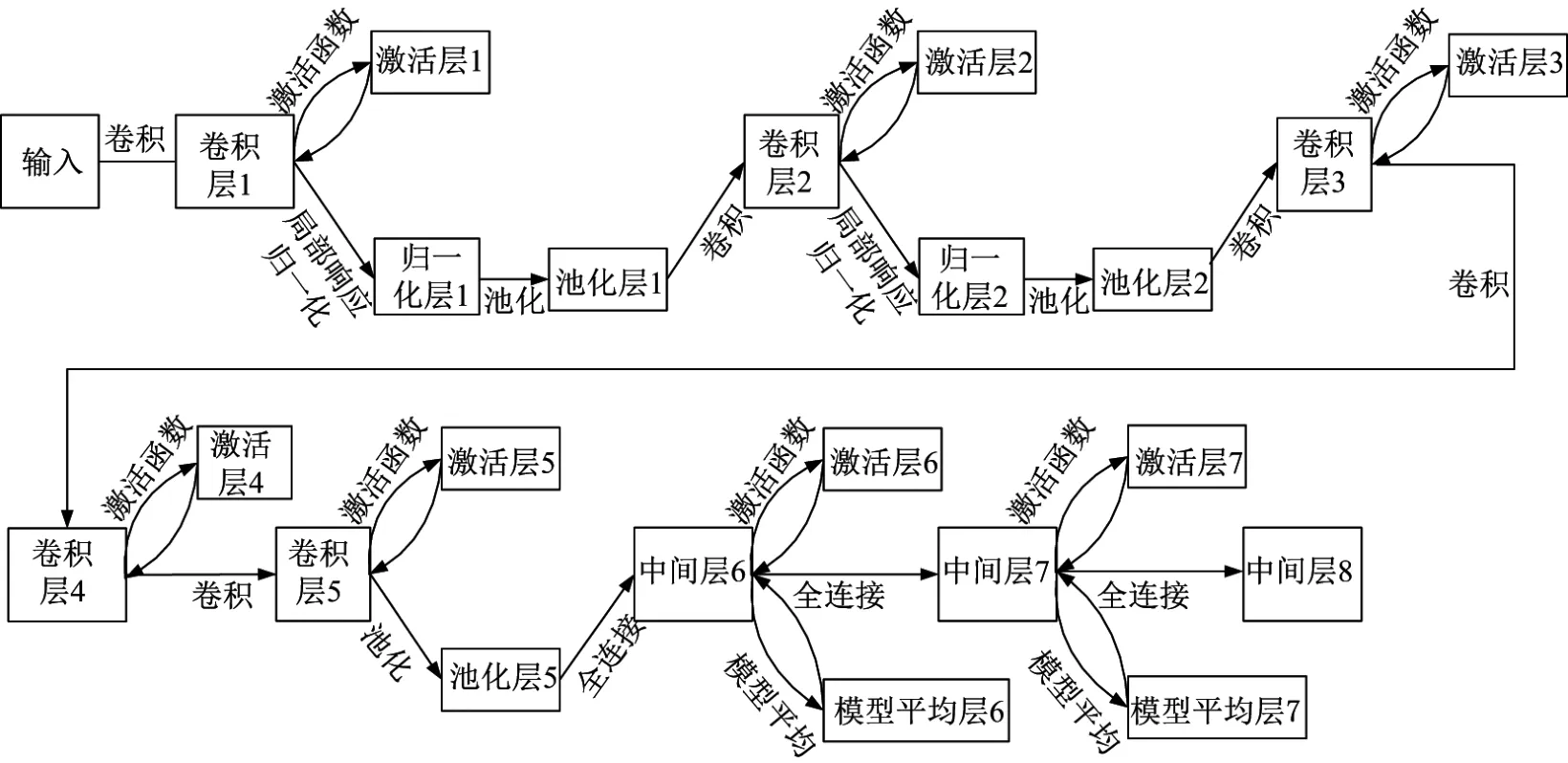
图5 AlexNet模型结构Fig.5 Architecture of AlexNet model
3 实验结果与分析
采用戴尔n5110笔记本电脑(内存8 GB,主频2.10 GHz)进行视频采集和图片分类,在台式机内存4 GB,NVIDIA GTX 960显卡,显存4 GB上进行训练,训练时间为30 h.图片分类时间毫秒级别,而训练时间则主要依赖于显卡显存的容量.固定群体中个人目标为4人,其中成人3人,幼儿1人,每个目标训练图片400张,测试图片50张,验证图片10张.
另外,本工作还构建了其他两种验证图片集:同一环境不同拍摄角度下的目标人物照片(图片集2)和不同环境下不同季节的目标人物照片(图片集3),并将这两种验证图片集与第一种图片集的准确率进行比较,结果如表1所示.
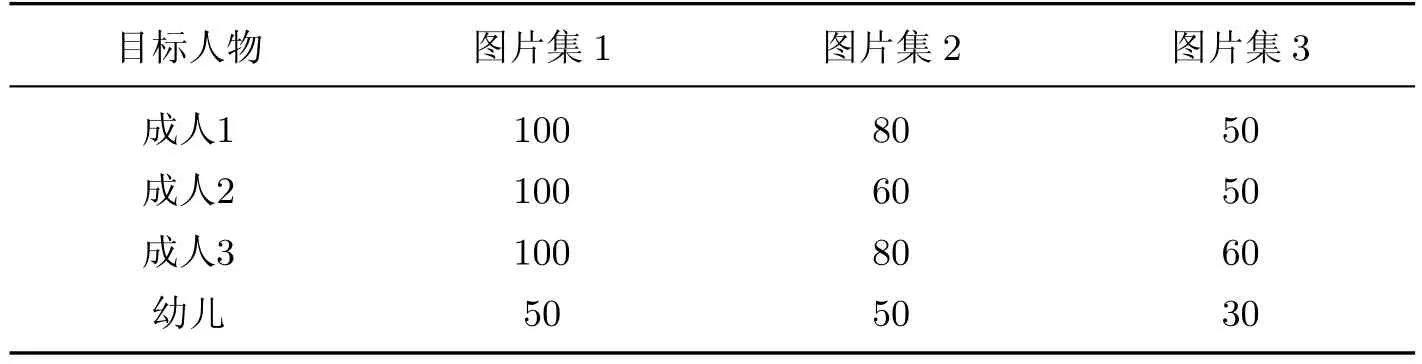
表1 目标人物验证图片集的准确率Table 1 Accuracy of diあerent verif i ed image sets for individual object %
实验结果表明,利用卷积神经网络框架Caあe能够实现固定群体中的目标人物分类.当训练图片和分类图片由同一拍摄源得到时,成人的分类准确率达到100%,而幼儿的准确率仅为50%.究其原因可能有两种:①摄像头固定的情况下,幼儿目标较小,占据图片的比例较小,不能较好地参与训练;②幼儿受控性较差,在拍摄硬件条件不高的情况下,幼儿图片质量不高.为了提高幼儿图片的分类准确率,根据拍摄环境特点,利用imcrop函数从图片的左、上、右3个方向对图片进行裁剪,增大幼儿占整幅图片的比例.经过多次实验发现,当幼儿占图片的比例达到20%以上时,准确率可达到90%.综上可以推断,当目标人物占据图片的比例增大时,准确率将提高.由表1可知,通过扩大训练图片的数量或在训练图片中添加更多环境下的目标人物照片,将大幅提高图片集2和图片集3的准确率.
本工作中的目标人物分类方法在图像预处理、分类时间周期两方面与传统的方法不同,具体如表2表示.

表2 两种目标人物分类方法的比较Table 2 Comparison of two kinds of classif i cation methods for individual object
4 结束语
深度学习在2006年之后得到了非常广泛的应用,包括谷歌、百度、脸书等大型技术公司都成立了相应的研发部门,力求在深度学习领域提高自身的技术性能,并将其应用到实际工作中.特别是在2015年ImageNet计算机识别挑战赛(ImageNet large scale visual recognition competition,ILSVRC)期间,微软亚洲研究院视觉计算组[15]将对象识别分类错误率降低至3.570%,超越了人眼辨识的错误率5.100%,而在ILSVRC 2016期间,对象识别分类错误率又被刷新到2.991%.这预示着深度学习已从理论成熟走向实践成熟,未来几年将会大放异彩.
[1]明安龙,马华东,傅慧源.多摄像机监控中基于贝叶斯因果网的人物角色识别[J].计算机学报,2010,33(12):2378-2386.
[2]宁波,宋砚.基于无监督方法的视频中的人物识别[J].计算机与现代化,2014(12):49-53.
[3]ZHONG Y,SULLIVAN J,LI H B.Face attribute prediction with classif i cation CNN[EB/OL].(2016-02-04)[2017-09-01].https://arxiv.org/abs/1602.01827v2.
[4]尹萍,赵亚丽.视频监控中人脸识别现状与关键技术课题[J].警察技术,2016(3):77-80.
[5]闻新,李新,张兴旺.应用MATLAB实现神经网络[M].北京:国防工业出版社,2015.
[6]HINTON G E,SALAkHUTDINOV R R.Reducing the dimensionality of data with neural networks[J].Science,2006,313(5786):504-507.
[7]BENGIO Y,LAMBLIN P,POPOVICI D,et al.Training of deep networks[M].Massachusetts:MIT Press,2007:153-160.
[8]RANZATO M A,POULTNEY C,CHOPRA S,et al.Eきcient learning of sparse representations with an energy-based model[C]//Advances in Neural Information Processing Systems.2006.
[9]KRIZHEVSkY A,SUTSkEVER I,HINTON G E.ImageNet classif i cation with deep convolutional neural networks[C]//Advances in Neural Information Processing Systems.2012.
[10]LI D,DONG Y.Deep learning:methods and applications[M].Boston:Now Publishers,2014.
[11]LECUN Y,BENGIO Y,HINTON G.Deep learning[J].Nature,2015,521(7553):436-444.
[12]Caあe[EB/OL].(2017-08-30)[2017-10-10].http://caあe.berkeleyvision.org.
[13]LIN S H,JI R R,GUO X W,et al.Towards convolutional neural networks compressing via global error reconstruction[C]//Preceedings of the 25thInternational Joint Conference on Artif i cial Intelligence.2016.
[14]KRIZHEVSkY A,SUTSkEVER I,HINTON G E.Imagenet classif i cation with deep convolutional neural networks[C]//Proceedings of the 25thInternational Conference on Neural Information Processing Systems.2012.
[15]HE K,ZHANG X,REN S,et al.Deep residual learning for image recognition[EB/OL].(2015-12-10)[2017-09-21].https://arxiv.org/abs/1512.03385.
