基于高光谱技术的籼稻霉变程度鉴别模型构建与优化
2017-12-07郑立章龚中良桑孟祥
郑立章 龚中良 文 韬,2 董 帅 桑孟祥
(中南林业科技大学机电工程学院1,长沙 410004) (华南农业大学南方农业机械与装备关键技术教育部重点实验室2,广州 510642)
基于高光谱技术的籼稻霉变程度鉴别模型构建与优化
郑立章1龚中良1文 韬1,2董 帅1桑孟祥1
(中南林业科技大学机电工程学院1,长沙 410004) (华南农业大学南方农业机械与装备关键技术教育部重点实验室2,广州 510642)
为解决快速无损鉴别籼稻霉变程度问题,利用高光谱技术采集200份霉变样本可见/近红外光谱信息,随机选取155份样本作为校正集,剩余45份作为验证集,根据预测浓度残差检验标准对校正集中异常样本进行剔除。以新校正集建立主成分线性判别分析(PCA-LDA)和簇类独立软模式法(SIMCA)模型,选用正确识别率为指标,优选最佳鉴别模型。并采用连续投影算法(SPA)提取特征波长,优化优选的最佳模型构建速度。研究结果表明,PCA-LDA对所有样本的误判总数为15,正确识别率为92.50%;SIMCA和SPA-SIMCA对所有样本的未能正确识别总数分别为6、2,正确识别率分别为97.00%、99.00%,并且经SPA筛选的变量数为20,仅占原始变量数的7.81%,建模时长缩短为原始变量的40.93%。因此,SPA-SIMCA鉴别效果最好,该方法在快速、准确鉴别籼稻霉变程度上具有可行性。
高光谱技术 霉变籼稻 鉴别 簇类独立软模式法 连续投影算法
稻谷的生产具有季节性,储藏时,所含淀粉、蛋白质及碳水化合物等成分在微生物作用下会发生变化,导致其营养价值和品质降低,甚至有可能霉变[1]。霉变稻谷一旦流入市场,必将存在安全隐患,因此,如何快速、准确鉴别稻谷霉变程度显得尤为重要。稻谷霉变过程中会产生一种稳定物质(脂肪酸),该物质会在霉变稻谷内沉积[2-3],因此,稻谷的霉变程度可由脂肪酸含量衡量。
当稻谷的脂肪酸含量超过25 mg/100 g可认为其开始霉变[4],但对霉变程度还鲜见具体量化标准。惠国华等[5]、张红梅等[6]、邹小波等[7]均根据培养时间确定谷物的霉变程度;陈红等[8]根据不同霉变花生的外观和颜色确定其霉变程度。通常将稻谷霉变程度划分为3个等级,即轻度霉变、中度霉变和重度霉变。在轻度霉变时,稻谷开始变色、潮湿;中度霉变时,其胚部开始出现菌落,并伴有霉斑和霉味;重度霉变时,稻谷产生刺鼻的霉味和酸味,出现结块现象[9-10]。目前,主要依赖于人工检测稻谷霉变程度,检测员根据不同霉变稻谷的特点进行分类,这种传统的检测方法比较费时,不适用于快速鉴别。
高光谱分析是一种操作简便、快速、绿色环保的检测技术,该技术用于霉变农作物的理化指标测定[11-15]的研究报道较多,但对其霉变程度的鉴别报道相对较少,近年来,该技术逐步应用于农作物的霉变鉴别,如袁莹等[16]应用近红外对霉变玉米进行了检测;周竹等[17]对霉变板栗进行识别;黄星奕等[18]对霉变出芽花生进行了鉴别,这些研究的鉴别准确率范围为87.8%~98.84%,为本试验提供了可行性技术支持。但上述研究方法很少涉及异常样本对模型精度影响的研究,也很少涉及分析PCA-LDA和SIMCA方法对鉴别结果的影响。因此,本试验选取霉变籼稻作为研究对象,用高光谱分析仪采集4种不同霉变程度籼稻的光谱信息,将样本随机划分为校正集和验证集,对校正集中异常样本进行剔除,采用新校正集构建PCA-LDA和SIMCA鉴别模型,优选最佳模型,并对其建模速度进行优化,以期为快速、准确鉴别籼稻霉变程度提供一种新方法。
1 材料与方法
1.1 材料
试验材料分别为正常籼稻(C两优34156籼稻,为两系杂交一季晚稻,含水量14.2%,千粒重23.1 g,由湖南农业大学选育,主要种植在湖南地区)和不同霉变程度籼稻(实验室培养制得),考虑到试验样本应具有普适性和代表性,结合传统分级方法和参考文献[4-7]所述的样本划分方法,将霉变籼稻划分为3个等级:轻度、中度以及重度霉变。根据霉菌作用籼稻时间不同,使其产生不同程度霉变,故可用培养初始(正常稻谷)、第10、第20、第30天来标记稻谷的4个霉变等级[19],每个等级样本为50份,每份100 g,正常稻谷按实际储藏要求(温度10 ℃,相对湿度15%)进行储存,保证样本不发生霉变。霉变稻谷储藏温度为30 ℃,相对湿度90%,模拟实际储藏条件变化所导致的稻谷不同程度霉变结果。培养过程中借助传统经验观察稻谷色泽和气味的感官变化,并通过随机抽样测定培养霉变籼稻的脂肪酸含量,保证能获得不同霉变程度样本,培养结束后,测定其脂肪酸含量,最终获得正常、轻度、中度和重度霉变籼稻的脂肪酸含量范围分别为18.55~24.40、27.03~80.90、84.44~127.26、101.09~124.88 mg/100 g。
1.2 光谱数据采集及预处理
采用HyperSIS-VNIR-PFH高光谱成像分析仪(北京卓立汉光仪器有限公司)采集样本的光谱信息,该系统内部结构如图1所示。图2为稻谷样本在光谱检测载物台上的分布,通过高光谱相机采集每个稻谷的256个波段图像,利用遥感图像处理平台选取载物台上的稻谷样本作为感兴趣区域,通过计算感兴趣区域的各个像素点的光谱反射率平均值,作为观测稻谷的光谱反射率。其中理想曝光时间20 ms,平台移动速度14.6 mm/s,扫描距离150 mm,光谱范围380~1 000 nm,光谱分辨率2.8 nm。

注:1 高光谱相机;2 光源;3 暗箱;4 载物台;5 线性导轨图。图1 高光谱信息采样系统

图2 稻谷样本在光谱检测载物台上的分布
采用Unscrambler 10.3和Matlab R2013a软件对光谱数据进行处理和分析。由于高光谱分析仪采集的数据在反映样品化学信息的同时,也会受到其物理性质和环境因素的影响,例如由稻谷样本颗粒不均匀产生的散射、仪器和环境噪声以及基线漂移为光谱数据引入了较大误差。故采用Savitzky-Golay平滑(savitzky-golay,SG)、多元散射校正(multiplicative scatter correction,MSC)、一阶导数(first derivation,FD)、二阶导数(second derivation,SD)对光谱进行预处理以提高建模和预测效果,通过对比优选最佳预处理方法。
1.3 建模方法
利用霉变籼稻的可见/近红外光谱信息,分别选用主成分线性判别分析(principal component analysis-linear discriminate analysis,PCA-LDA)和簇类独立软模式法(soft independent modeling of class analogy,SIMCA)构建籼稻霉变程度鉴别模型。其中PCA-LDA算法是对所有类样本的光谱数据进行特征压缩,然后建立数学模型,并将所有未知样本与数学模型进行拟合,从而判断样本所属的类,而SIMCA则是针对每一类样本的光谱数据进行主成分分析,建立每一类主成分分析数学模型,然后分别将未知样品与各类样品的数学模型进行逐一拟合,进而判断未知样品的类别。
鉴别模型的构建如图3所示,对霉变籼稻赋值,即正常为1、轻度为2、中度为3、重度为4,以此作为真实分类变量;随机选取155份样本作校正集(正常、轻度、中度、重度分别为39、39、37、40),脂肪酸含量范围为18.55~127.26 mg/100 g,剩余45份作为验证集(正常、轻度、中度、重度分别为11、11、13、10),脂肪酸含量范围为18.74~116.55 mg/100 g;对校正集样本采用留一交叉验证MLR建模,根据预测浓度残差检验标准[20]剔除校正集中异常样本;采用新校正集建立PCA-LDA和SIMCA模型,并对验证集样本进行预测分类,以正确识别率为评价指标,优选最佳鉴别模型;采用连续投影算法(successive projections algorithm,SPA)筛选特征变量,压缩输入变量,简化最佳鉴别模型。
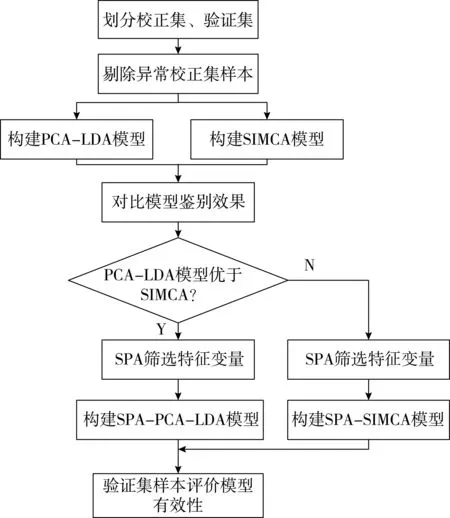
图3 模型的建立与评价
2 结果与分析
2.1 可见/近红外光谱特征分析
4种霉变程度籼稻的光谱数据经SG平滑预处理后的平均光谱图如图4所示。由图4可知,4条光谱反射率曲线整体变化趋势基本相同,呈现霉变籼稻所特有的光谱变化规律:在波长为380~700、850~1 000 nm时,光谱反射率有较明显变化,在波长为700~850 nm时,光谱反射率无明显变化。在波长为420 nm附近时,4条反射率曲线均出现不同程度的低谷,在波长为450~700 nm时,光谱反射率变化趋势随着籼稻霉变程度的加深而减缓,此波长范围内,光谱反射率差异明显,其中正常和重度霉变样本的反射率曲线差异最大,表明在后期鉴别时较容易区分2者。但轻度和中度霉变样本的反射率曲线差异较小,这必定给后期准确鉴别2者带来困难。在波长为850~1 000 nm时,正常、中度和重度霉变样本的反射率曲线差异较大,其反射率值均有所下降,但正常和轻度霉变样本的反射率基本重合。
2.2 剔除异常的校正集样本
当校正集中存在异常样本时,使用该样本集建立模型,会使其可靠性和预测精度降低。因此,必须寻找和剔除异常样本,保证模型的有效性。试验先采用PCA对光谱数据进行压缩,根据主成分累计贡献率确定较佳主成分数,其前1、2、3、4个主成分累计贡献率分别为98.96%、99.57%、99.91%、99.95%,前3个主成分累计贡献率已达99.91%,说明其包含了原始光谱的99.91%的信息。以该较佳主成分作为输入变量,采用留一交叉验证MLR法计算预测值与真实分类变量之间的残差,并对该残差进行显著水平P=0.05的F检验,根据残差置信区间范围筛选异常样本,由图5可知,黑色线条对应样本的残差离零点较远,说明该类样本的预测值与真实值偏离程度较大,并且其残差置信区间不包括零,即该类样本异常。表1为不同校正集的MLR模型预测结果,由表1可知,轻度霉变样本剔除个数为1,中度为5,重度为1,以新校正集建立模型的校正集相关系数RC比未剔除异常样本提高了0.031,但验证集相关系数RP减小了0.004。因此,剔除异常样本虽可提高校正模型精度,但预测精度却存在下降,为了保证模型的预测效果较优,本研究选用的校正集为原始校正样本集。
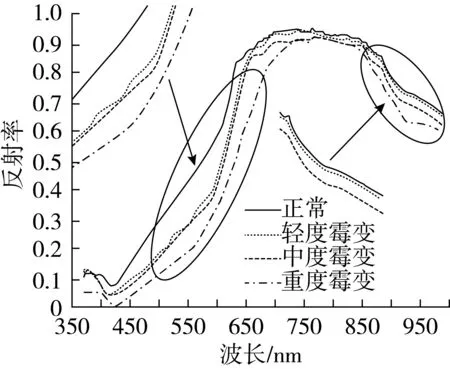
图4 4种霉变稻谷光谱平滑图
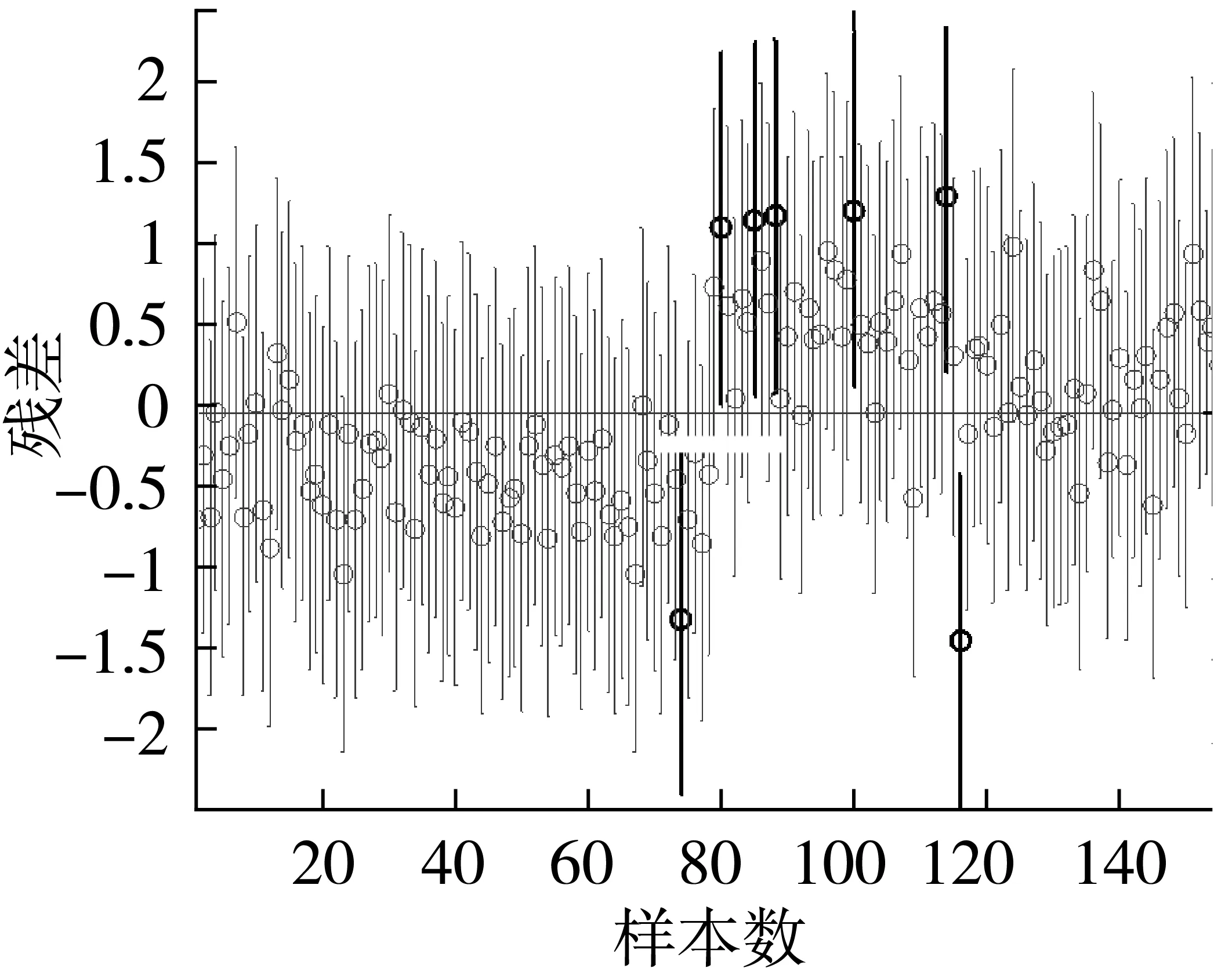
图5 校正集样本的残差
表1 不同校正集的MLR模型预测结果

校正集类型样本数异常样本数正常轻度中度重度校正集RMSECRC验证集RMSEPRP未预处理15500000545087505770850新校正集14801510482090605840846
2.3 PCA-LDA和SIMCA对霉变籼稻的判别分析
2.3.1 PCA-LDA对霉变籼稻的判别分析
对校正集原始光谱数据进行主成分分析,其前3个主成分累计贡献率达到99.91%,包含了绝大部分光谱信息。图6为样本前3个主成分得分图,该3个主成分得分值分别为98.96%、0.61%、0.34%,由图6可知,正常、轻度和中度霉变样本各自的聚合程度较好,其中正常样本同轻度和中度霉变样本之间存在少量重叠,但轻度和中度霉变样本之间重叠部分较多,说明某些轻度霉变样本的光谱与中度霉变样本较为相似,给准确识别带来了困难。重度霉变样本的聚合程度较差,同轻度和中度霉变样本之间存在少量重叠,但重度霉变样本同正常样本之间区分明显,可以准确区分两类样本。因此,通过PCA对不同霉变样本的区分具有可行性,为了提高模型预测精度和定量分析误判情况,对原始光谱数据实施SG、MSC、FD、SD等预处理,并采用PCA分别提取经上述方法处理后的光谱数据的主成分,其主成分数分别为3、3、4、4,对应的累计贡献率分别为99.91%、99.93%、99.95%、99.98%,利用上述主成分的得分对校正集样本进行Fisher判别分析,同时,应用该模型对验证集样本进行预测分类,不同预处理方法的PCA-LDA鉴别结果如表2所示。
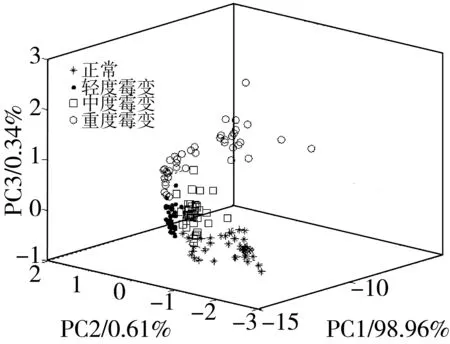
图6 霉变稻谷样本前3个主成分得分图
表2 不同预处理方法的PCA-LDA鉴别结果
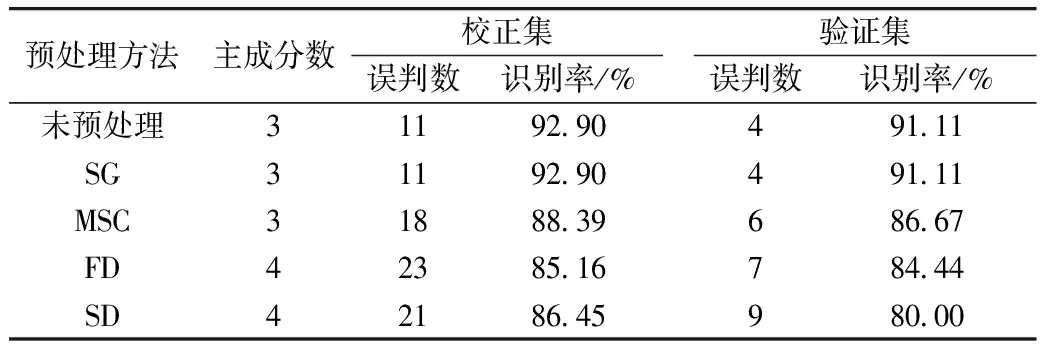
预处理方法主成分数校正集误判数识别率/%验证集误判数识别率/%未预处理311929049111SG311929049111MSC318883968667FD423851678444SD421864598000
由表2可知,光谱数据经MSC、FD、SD等处理后的校正集和验证集的正确识别率均小90%,其中,SD处理的预测效果最差,验证集的正确识别率最小(80%),光谱数据经MSC、FD、SD预处理效果变差,可能因为预处理过程中丢失了一些重要信息。未预处理和SG平滑建模的校正集和验证集的正确识别率相同,均大于90%,因此,本试验选用原始数据建模效果较佳,由原始数据建立的PCA-LDA鉴别结果如表3所示。
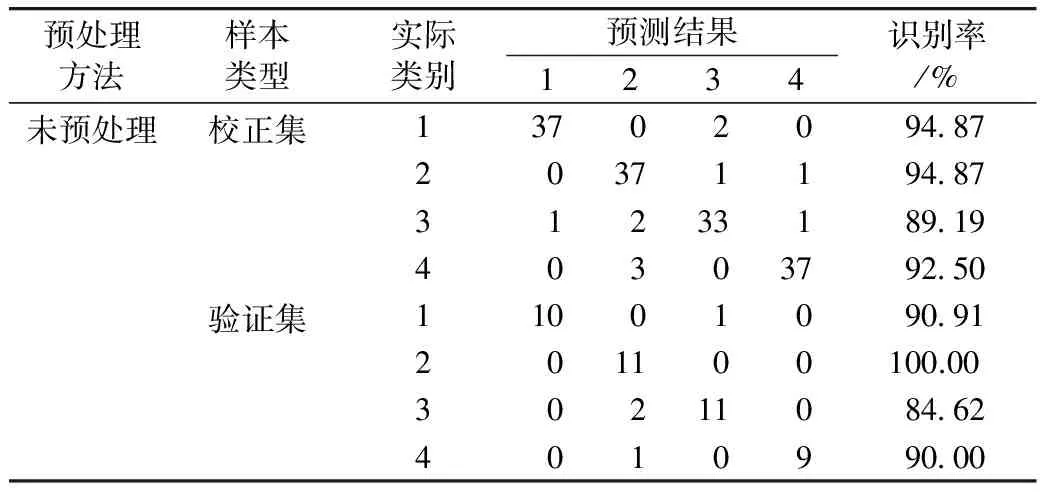
表3 采用原始数据的PCA-LDA鉴别结果
注:1代表正常样本;2代表轻度霉变样本;3代表中度霉变样本;4代表重度霉变样本,下同。
由表3可知,PCA-LDA对校正集中的4类样本均存在误判,正确识别率范围为89.19%~94.87%,将2个正常样本误判为中度霉变;2轻度霉变样本分别误判为中度和重度霉变;4个中度霉变样本分别误判为1个正常、2个轻度和1个重度霉变;3个重度霉变样本误判为轻度霉变。该模型可正确识别验证集中的轻度霉变样本,识别率为100%;将1个正常样本误判为中度霉变;2个中度霉变和1个重度霉变样本均误判为轻度霉变,正确识别率分别为84.62%、90.00%。PCA-LDA对校正集和验证集样本的总体正确识别率分别为92.90%、91.11%,因此,该模型可对霉变稻谷进行粗略鉴别,其识别精度有待提高。
2.3.2 SIMCA对霉变籼稻的判别分析
为解决PCA-LDA精度不高问题,在主成分分析基础上采用SIMCA模式识别方法。利用校正集建立SIMCA鉴别模型,并通过验证集的45份样本对模型可靠性进行检验。先对校正集中的4类样本分别进行主成分分析,通过交叉验证法得出正常、轻度、中度、重度霉变样本的主成分数分别为3、3、5、3,45份样本验证该模型的结果如表4所示。
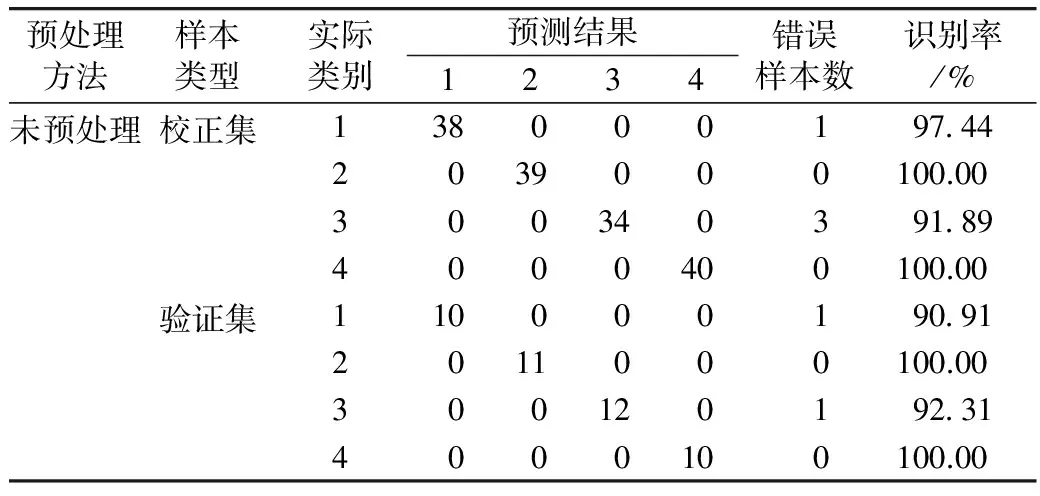
表4 采用原始数据的SIMCA鉴别结果
由表4可知,在显著水平P=0.05下,校正集和验证集中的轻度和重度霉变样本的正确识别率均为100%;校正集和验证集中的正常样本的正确识别率分别为97.44%、90.91%,两类样本集中均有1个样本未能正确识别;校正集和验证集中的中度霉变样本的正确识别率分别为91.89%、92.31%,未能正确识别个数分别为3、1。SIMCA的构建时长为1 488 s,其对校正集和验证集样本的总体正确识别率分别为97.42%、95.56%,因此,该模型对霉变稻谷的鉴别具有可行性。
2.4 SPA优化SIMCA光谱建模
对比PCA-LDA和SIMCA的鉴别结果,可知SIMCA鉴别效果优于前者,其对校正集和验证集样本的总体正确识别率分别提高了4.52%、4.45%。为了进一步提高SIMCA构建速度,同时剔除光谱数据中的冗余信息。采用SPA提取光谱特征波段,指定波段数N范围为10~50,并以该特征波段作为SIMCA的输入变量。图7为不同变量数下的交叉验证均方根误差(RMSECV)的变化情况。由图7可知,变量数在1~20范围内,RMSECV具有较高的下降速率,在变量数为20时,RMSECV值最小(0.299),变量数在20~43范围内,RMSECV变化趋于平缓,说明在变量数为20以后,其预测值与真实值之间的均方根误差无明显差异。故最终优选的变量数为20,仅占原始变量数的7.81%,大大压缩了数据维数,简化了SIMCA模型。将特征波段作为输入变量构建SIMCA模型,并对校正集和验证集样本进行预测分类,具体鉴别结果如表5所示。
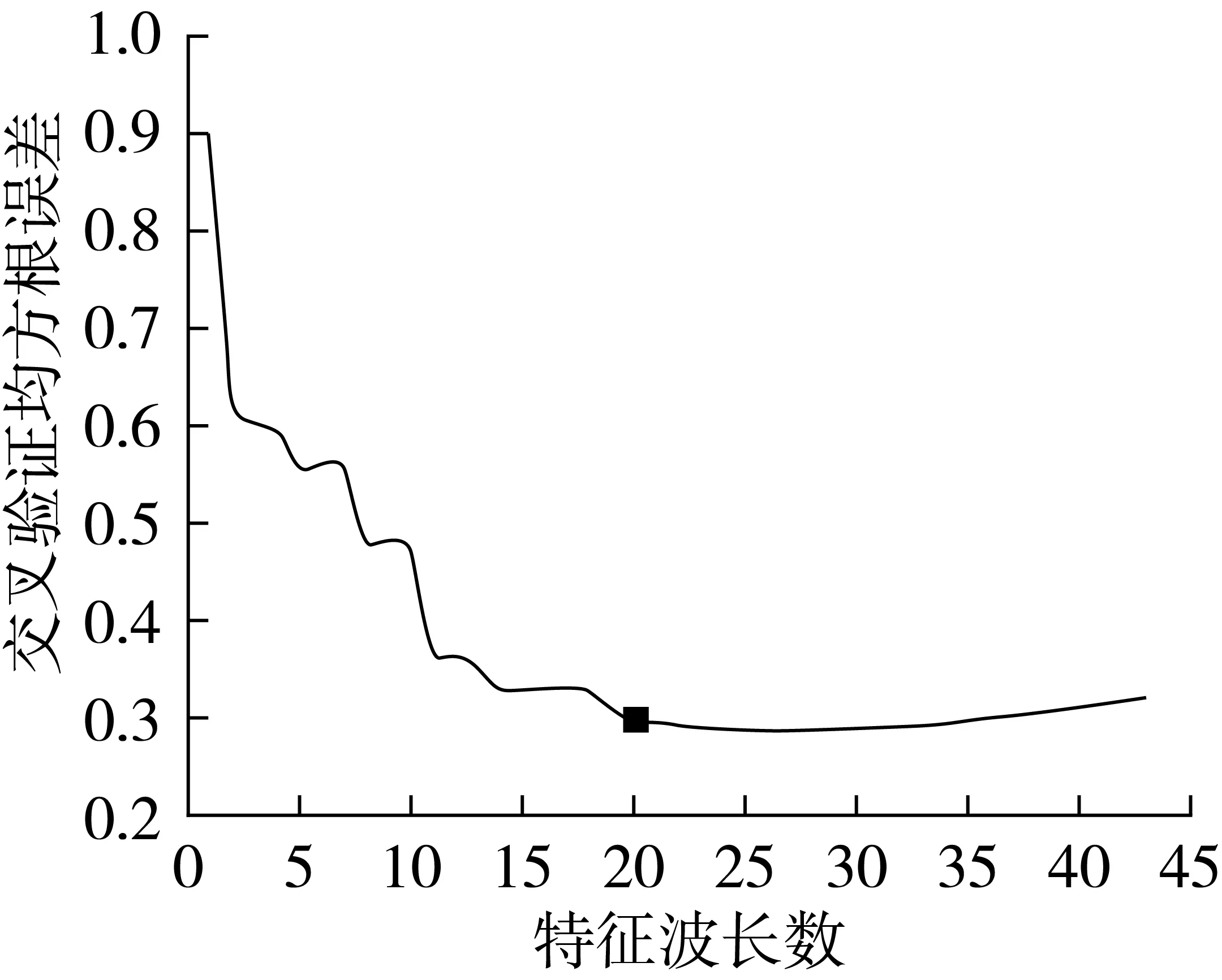
图7 最优特征波长数选取
由表5可知,SPA-SIMCA可准确鉴别校正集中的轻度、中度和重度霉变样本,正确识别率均为100%,正常样本中存在2个样本未能正确识别,正确识别率为94.87%;该模型可准确鉴别验证集中的4类样本。SPA-SIMCA的构建时长为609 s,其对校正集和验证集样本的总体正确识别率分别为98.71%、100%。因此,该模型的鉴别效果优于全波段的SIMCA模型,SPA算法不仅可以压缩光谱数据,节约建模时间,也可提高SIMCA精度。同时,SPA-SIMCA的鉴别效果也优于PCA-LDA,可能因为光谱数据经SPA处理,剔除了一些冗余信息,保留了对籼稻霉变程度贡献率大的特征波段,而PCA进行数据压缩时,一些低敏感波段被保留下来,导致其鉴别效果较差。
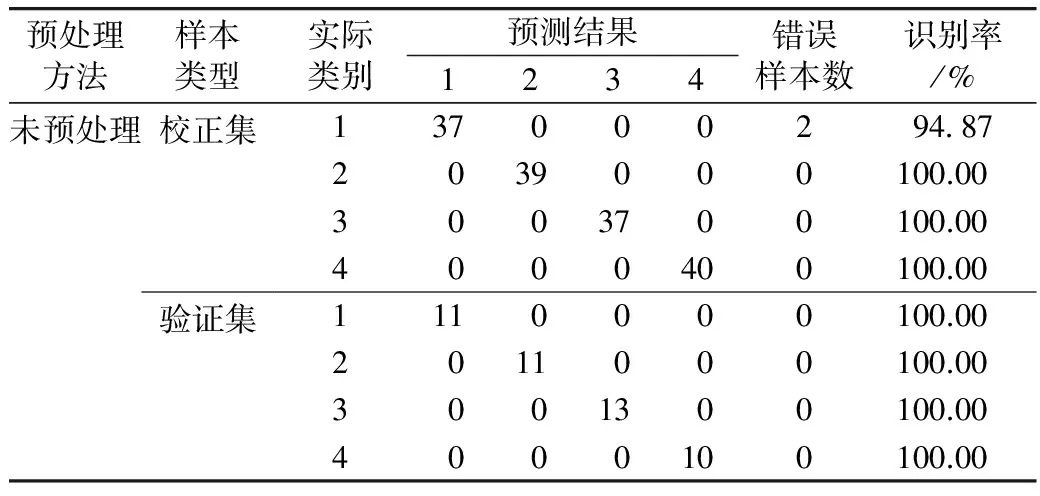
表5 采用原始数据的SPA-SIMCA鉴别结果
3 结论
3.1 霉变籼稻的反射率曲线变化趋势基本一致,呈现其独有的光谱特性:在波长为380~700、850~1 000 nm时,反射率有较明显变化,在波长为700~850 nm时,反射率无明显变化。
3.2 根据预测浓度残差检验标准,得出校正集中存在7个异常样本,剔除该样本后的校正集相关系数比未剔除异常样本提高了0.031,但验证集相关系数RP减小了0.004。
3.3 PCA-LDA对校正集和验证集的误判个数分别为11、4,总体正确识别率分别为92.90%、91.11%;SIMCA对校正集和验证集的未能正确识别个数分别为4、2,总体正确识别率分别为97.42%、95.56%。
3.4 SPA筛选的特征变量数为20,仅占原始变量数的7.81%,建模时长缩短为原始变量的40.93%,同时,采用特征波段建立的SIMCA模型对校正集和验证集的正确识别率比全波段建模分别提高了1.29%、4.44%。SPA-SIMCA对校正集和验证集的未能正确识别个数分别为2、0,总体正确识别率分别为98.71%、100%。
因此,SPA-SIMCA更适于建模,该方法可为快速、无损鉴别籼稻霉变程度提供技术支持,也可以为在线检测流入市场的籼稻是否霉变以及霉变程度提供参考依据。
[1]包清彬,猪谷富雄.储藏条件对糙米理化特性影响的研究[J].农业工程学报,2003,19(6):25-27
Bao Qinbing,Tomio ITANI.Influence of storage conditions on physicochemical characteristic of brown rice[J].Transactions of the Chinese Society of Agricultural Engineering,2003,19(6):25-27
[2]苏永腾,刘强.谷物霉菌毒素的危害及其控制措施的研究[J].中国食物与营养,2010(4):9-12
Su Yongteng,Liu Qiang.Hazards and control measures of grain mycotoxin[J].Food and Nutrition in China,2010(4):9-12
[3]Aibara S,Ismail I A.Changes in rice bran lipids and fatty acids during storage[J].Agriculture Biology Chemistry,1986,50(3):665-673
[4]杨晓蓉,周建新,姚明兰,等.不同储藏条件下稻谷脂肪酸值变化和霉变相关性研究[J].粮食储藏,2006,35(5):49-52
Yang Xiaorong,Zhou Jianxin,Yao Minglan,et al.Study on a correlation between the fatty acid value change and mould of indica rice in different storage conditions[J].Grain Storage,2006,35(5):49-52
[5]惠国华,陈裕泉.基于随机共振的电子鼻系统构建及在谷物霉变程度检测中的应用[J].传感技术学报,2011,24(2):159-164
Hui Guohua,Chen Yuquan,Establishment of an electronic nose system using stochastic resonance and its application in moldy corn status detection[J].Chinese Journal of Sensors and Actuators,2011,24(2):159-164
[6]张红梅,王俊,叶盛,等.电子鼻传感器阵列优化与谷物霉变程度的检测[J].传感技术学报,2007,20(6):1207-1210
Zhang Hongmei,Wang Jun,Ye Sheng,et al.Optimized of sensor array and detection of moldy degree for grain by electronic nose[J].Chinese Journal of Sensors and Actuators,2007,20(6):1207-1210
[7]邹小波,赵杰文.电子鼻快速检测谷物霉变的研究[J].农业工程学报,2004,20(4):121-124
Zou Xiaobo,Zhao Jiewen.Rapid identification of moldy corn by electronic nose[J].Transactions of the Chinese Society of Agricultural Engineering,2004,20(4):121-124
[8]陈红,熊利荣,胡筱波.基于神经网络与图像处理的花生仁霉变识别方法[J].农业工程学报,2007,23(4):158-161
Chen Hong,Xiong Lirong,Hu Xiaobo,et al.Identification method for moldy peanut kernels based on neural network and image processing[J].Transactions of the Chinese Society of Agricultural Engineering,2007,23(4):158-161
[9]周建新.论粮食霉变中的生物化学[J].粮食储藏,2004,32(1):9-12
Zhou Jianxin.The biochemistry during grain mildewing[J].Grain Storage,2004,32(1):9-12
[10]惠国华,倪彧.基于信噪比分析技术的谷物霉变快速检测方法[J].农业工程学报,2011,27(3):336-340
Hui Guohua,Ni Yu.Investigation of moldy corn fast detection based on signal-to-noise ratio spectrum analysis technique[J].Transactions of the Chinese Society of Agricultural Engineering,2011,27(3):336-340
[11]张强,刘成海,孙井坤,等.基于支持向量机稻谷黄曲霉毒素B1近红外无损检测[J].东北农业大学学报,2015,46(5):84-88
Zhang Qiang,Liu Chenghai,Sun Jingkun,et al.Near-infrared spectroscopy nondestructive determination of aflatoxin B1 in indica rice rice based on support vector machine regression[J].Journal of Northeast Agricultural University,2015,46(5):84-88
[12]Pettersson H,Aberg L.Near infrared spectroscopy for deter-mination of mycotoxins in cereals[J].Food Control,2003,14(4):229-232
[13]袁莹,王伟,褚璇,等.基于高光谱成像技术和因子判别分析的玉米黄曲霉毒素检测研究[J].中国粮油学报,2014,29(12):107-110
Yuan Ying,Wang Wei,Chu Xuan,et al.Detection of Corn Aflatoxin Based on Hyperspectral Imaging Technology and Factor Discriminant Analysis[J].Journal of the Chinese Cereals and Oils Association,2014,29(12):107-110
[14]Fernández-Ibanez V,Soldado A,Martínez-Fernández A,et al.Application of near infrared spectroscopy for rapid detection of aflatoxin B1 in maize and barley as analytical quality assessment[J].Food Chemistry,2009,113(2):629-634
[15]文韬,洪添胜,李立君,等.基于高光谱技术的霉变稻谷脂肪酸含量无损检测[J].农业工程学报,2015,31(18):233-239
Wen Tao,Hong Tiansheng,Li Lijun,et al.Non-destructive detection of fatty acid content in mould indica rice based on high-spectral technology[J].Transactions of the Chinese Society of Agricultural Engineering,2015,31(18):233-239
[16]袁莹,王伟,褚璇,等.基于傅里叶变换近红外和支持向量机的霉变玉米检测[J].中国粮油学报,2015,30(5):143-146
Yuan Ying,Wang Wei,Chu Xuan,et al.Detection of moldy corns with FT-NIR spectroscopy based on SVM[J].Journal of the Chinese Cereals and Oils Association,2015,30(5):143-146
[17]周竹,李小昱,李培武,等.基于GA-LSSVM和近红外傅里叶变换的霉变板栗识别[J].农业工程学报,2011,3(3):331-335
Zhou Zhu,Li Xiaoyu,Li Peiwu,et al.Near-infrared spectral detection of moldy chestnut based on GA-LSSVM and FFT[J].Transactions of the Chinese Society of Agricultural Engineering,2011,3(3):331-335
[18]黄星奕,丁然,史嘉辰,等.霉变出芽花生的近红外光谱无损检测研究[J].中国农业科技导报,2015,17(5):27-32
Huang Xingyi,Ding ran,Shi Jiachen.et al.Studies on Non-destructive testing method of moldy and budding peanuts by Near Infrared Spectroscopy[J].Journal of Agricultural Science and Technology,2015,17(5):27-32
[19]张瑛,吴先山,吴敬德,等.稻谷储藏过程中理化特性变化的研究[J].中国粮油学报,2003,18(6):565-566
Zhang Ying,Wu Xianshan,Wu Jingde,et al.Study on physical and chemical characters in rice storage[J].Journal of the Chinese Cereals and Oils Association,2003,18(6):565-566
[20]祝诗平,王一鸣,张小超,等.近红外光谱建模异常样品剔除准则与方法[J].农业机械学报,2004,35(4):115-119
Zhu Shiping,Wang Yiming,Zhang Xiaochao,et al.Outlier sample eliminating criterions and methods for building calibration model of near infrared spectroscopy analysis[J].Transactions of the Chinese Society of Agricultural Machinery,2004,35(4):115-119.
Establishment and Optimization of Identification Model for the Degree of Moldy Indica Rice Based on Hyperspectral Technology
Zheng Lizhang1Gong Zhongliang1Wen Tao1,2Dong Shuai1Sang Mengxiang1
(School of Mechanical and Electrical Engineering,Central South University of Forestry and Technology1,Changsha 410004) (Key Laboratory of Key Technology for South Agricultural Machinery and Equipment, Ministry of Education,South China Agricultural University2,Guangzhou 510642)
In order to solve the problem of fast and nondestructive identification of moldy indica rice,the hyperspectral technique was used to collect the visible/near infrared spectroscopy of 200 moldy paddies,155 samples were randomly chosen as calibration set,and 45 samples were chosen as validation set.According to the criterion of predicted concentration residual,the outlier samples of calibration set were eliminated.Then,the principal component analysis combined with linear discriminate analysis(PCA-LDA)and soft independent modeling of class analogy(SIMCA)were established by using the new calibration set.Further,by comparing the correct recognition rate of the two models,the optimal model was elected.In order to improve the speed of establishing the optimal model,the successive projections algorithm(SPA)was used to extract the characteristic wavelength.The results showed that 15 samples of the all samples were mistakenly identified by using the PCA-LDA,the correct recognition rate was 92.50%.The numbers of wrongly identified samples of the all samples respectively were 6 and 2 by using the SIMCA and SPA-SIMCA;the correct recognition rates were 97.00% and 99.00%,respectively.20 characteristic wavelengths were selected by SPA;the number of variables was dropped to 7.81%,and the time of establishing model was reduced to 40.93% compared with initial variables.Therefore,the identification model established by the SPA-SIMCA was the best.The model is feasible for fast and accurately identifying the moldy degree of the indica rice.
hyperspectral technology,moldy indica rice,identification,soft independent modeling of class analogy,successive projections algorithm
S123;S511
A
1003-0174(2017)11-0151-07
国家自然科学基金(31401281),湖南省科技计划重点研发项目(2016NK2151),湖南省自然科学基金(14JJ3115),湖南省高校科技创新团队支持计划(2014207)
2016-10-06
郑立章,男,1992年出生,硕士,农产品品质与安全无损检测技术应用基础研究
文韬,男,1983年出生,副教授,农产品品质与安全无损检测技术应用基础研究
