基于拉曼和近红外光谱特征层融合的食用油MUFA和PUFA含量检测
2017-12-07俞雅茹何东平
吴 双 王 杰 俞雅茹 涂 斌 郑 晓 何东平
(武汉轻工大学机械工程学院1,武汉 430000) (武汉轻工大学食品科学与工程学院2,武汉 430000)
基于拉曼和近红外光谱特征层融合的食用油MUFA和PUFA含量检测
吴 双1王 杰1俞雅茹1涂 斌1郑 晓1何东平2
(武汉轻工大学机械工程学院1,武汉 430000) (武汉轻工大学食品科学与工程学院2,武汉 430000)
针对食用油中单不饱和脂肪酸(MUFA)和多不饱和脂肪酸(PUFA)含量的快速检测问题,研究探索应用拉曼(Raman)和近红外(NIR)光谱以及特征层数据的融合,结合化学计量学分析,建立食用油MUFA和PUFA含量预测模型。重点研究各种预处理算法对模型预测能力的影响。应用竞争性自适应重加权采样(CARS)提取Raman和NIR光谱的特征波长,应用网格搜索(GS)算法选取支持向量机回归(SVR)模型的参数组合(C,g)值,分别建立基于拉曼和近红外光谱的特征波段的SVR预测模型;建立基于特征层的多源光谱融合的SVR预测模型。试验表明,基于特征层融合建立的Raman-NIR-SVR模型能够实现食用油MUFA和PUFA含量的快速预测,且预测效果更优。其中预测MUFA含量的SG15-ALS-Nor-CARS-MSC-CARS-SVR模型的预测集决定系数R2为0.977 3,与单光谱中最优含量预测模型相比增加了2.43%;而预测PUFA含量的MA11-airPLS-Nor-CARS-MSC-CARS-SVR模型的预测集R2为0.993 0,比较最优单光谱数据建立的SVR模型增加了2.57%。结果表明,采用特征层融合方法建立的含量预测模型的综合性能优于基于单光谱数据建立的模型。
单不饱和脂肪酸 多不饱和脂肪酸 特征层融合 支持向量机回归
食用油不仅可以提高食品的感官性质,增强饱腹能力,而且提供人体所需的植物淄醇、不饱和脂肪酸、谷维素等营养物质,对身体健康和保健作用越来越大[1]。食用油中包含单不饱和脂肪酸(Monounsaturated Fatty Acid,MUFA)和多不饱和脂肪酸(Polyunsaturated Fatty Acid,PUFA),MUFA具有保护心脏、降低血糖和胆固醇、调节血脂、防止记忆下降等功能[2],PUFA不仅有MUFA的功能,还具有通过排除体内多余脂肪实现减肥的作用[3]。然而,一些不法人员为谋取暴利,使用变质原料加工食用油或将劣质油或低价值油掺入高价值油中,使食用油中的不饱和脂肪酸含量减少,损害消费者权益,影响人的身体健康。
现有的检测食用油PUFA和MUFA含量的方法是采用色谱和质谱等方法,此方法需要借助昂贵的仪器及严格的实验条件,远不能满足现场快速准确检测的要求。因此,探索一种能快速、灵敏度高的动态分析检测食用油的技术对提高油脂企业品质监管,保障食用油市场和消费者权益等方面具有重要意义[4]。近年来,拉曼(Raman)光谱和近红外(NIR)光谱技术用于食用油品质检测成为国内外研究的热点。这是由于光谱技术是一种快速、简便、无损分析技术,并且具有测量时间短,不需要对待测样本预处理,易于实现在线分析,已经被广泛应用于医药、食品、烟草、农业和石化等领域[5-6]。Raman光谱的特征峰的位置和强度能够直观的反映待测样品的化学基团、结构及其变化信息[7],而NIR技术主要基于光谱波段范围与含氢基团(O—H、N—H、C—H)振动的合频、倍频的吸收区一致,故其光谱反映待测样品的有机分子O—H、N—H、C—H等基团的特征信息[8]。既然2种光谱都能反映待测样品的信息,那么将2种光谱融合来提高定性定量分析的准确性成为了研究的新方向。
本试验重点研究了特征层数据融合技术对含量预测模型的作用。数据融合技术是对来自多个信息源的数据进行自动检测、估计、相关及组合等处理,一个多层面、多级的数据处理过程,产生新的有意义的信息,对目标识别是一种新的方法,目前数据融合技术已经被应用在自动目标识别、机器人、医疗、石化、食品和水质检测等领域[9-10]。本研究基于近红外、拉曼及两者融合的光谱结合化学计量法建立了食用油MUFA和PUFA含量预测的SVR模型。通过比较单光谱和融合光谱对模型预测能力的影响,为准确建立MUFA和PUFA含量预测的回归模型提供可靠依据。
1 材料与方法
1.1 脂肪酸含量检测样本
按照GB/T 17377—2008,采用Angilent 7890-5975 GC-MS型气相色谱仪对大豆油、菜籽油、茶籽油、花生油等55个正常食用油的脂肪酸含量进行气相色谱测定,所得到的脂肪酸含量为总脂肪酸的质量百分数。采用SPXY(Sample set Portioning based on joint x-y distances)算法按3:1的比例选取油脂肪酸成分含量预测模型的校正集和预测集样品。脂肪酸含量统计如表1所示。
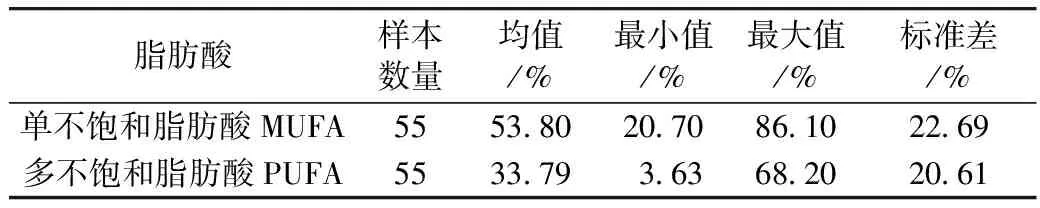
表1 脂肪酸含量统计
1.2 设备及仪器
选用RamTraceer-200激光拉曼光谱仪(欧普图斯,中国)采集拉曼光谱数据,其参数为:激光波长为785 nm,分辨率≤8 cm-1,光谱采集波数范围250~2 340 cm-1,最大激光功率为320 mW,积分时间参数设置为5 s,激光功率为220 mW。同时选用实验室自主研发的激光近红外光谱仪(AXSUN,USA)采集近红外光谱数据。其主机为Axsun XL410,光谱测定范围为1 350~1 800 nm,扫描次数32次,分辨率为3.5 cm-1,波长重复性为0.01 nm,信噪比(250 ms,RMS)>5 500:1。
1.3 拉曼和近红外光谱采集
每个样品装样3次,采集3次稳定的谱图后取其平均图谱作为最终图谱,室温下测定。采集样品的拉曼原始光谱,选取信噪比较高的780~1 800 cm-1示于图1。图2为采集样品的近红外原始图。
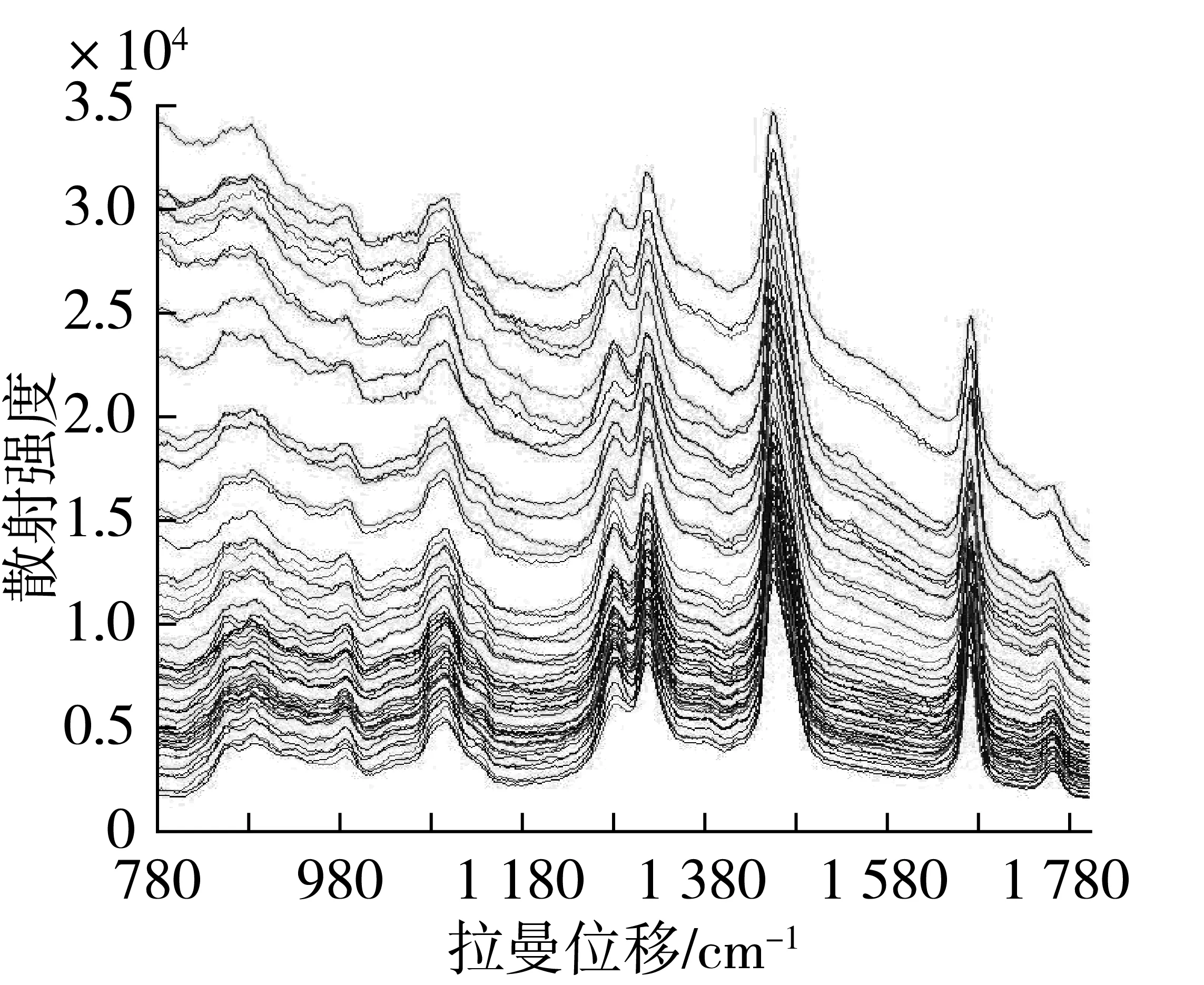
图1 拉曼原始光谱
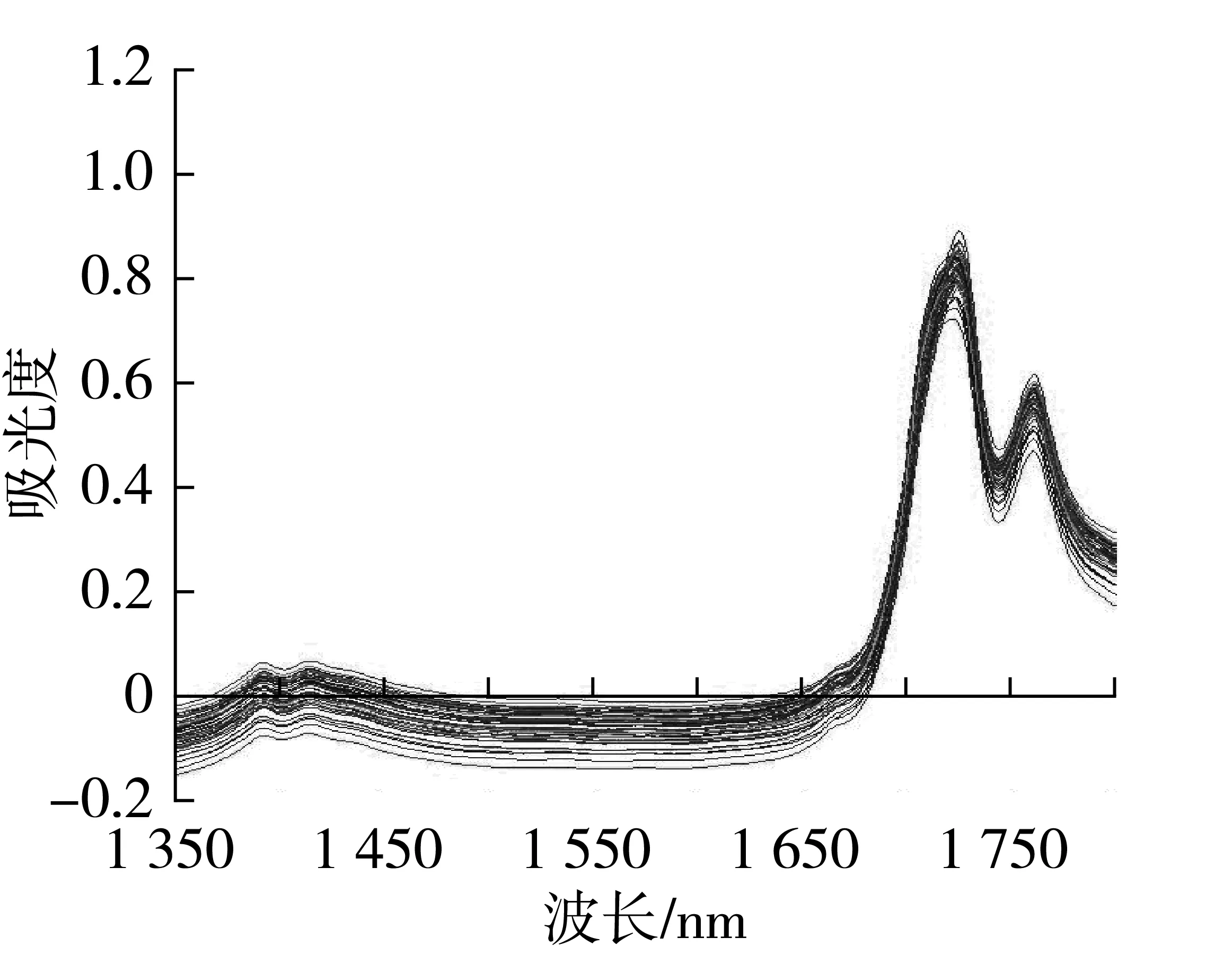
图2 近红外原始光谱
1.4 光谱数据预处理和基线校正
拉曼光谱采用移动平均11点平滑法(MA11)和Savitzky-Golay[11]滤波15点平滑法(SG15)消除光谱噪声,自适应迭代重加权惩罚最小二乘(airPLS)和非对称最小二乘法(ALS)算法进行基线校正,以1 454 cm-1附近的特征峰强度为基准进行归一化(Nor)处理。图3是经SG15-ALS-Nor预处理的拉曼光谱。airPLS[12]是惩罚最小二乘法结合自适应迭代加权而得到的一种易于实现拉曼光谱背景扣除的算法,对拉曼光谱进行基线校正时,只需要设置影响背景平滑程度的参数λ,试验中设置参数λ=105。而ALS则是Boelens等[13]提出的惩罚最小二乘法结合非对称加权而得到的一种易于实现拉曼光谱背景扣除的算法,对拉曼光谱进行基线校正时需要设置平滑(smoothness)和非对称加权(asymmetry)参数组合(smo,asy),试验中设置参数smo=106,asy=10-2。
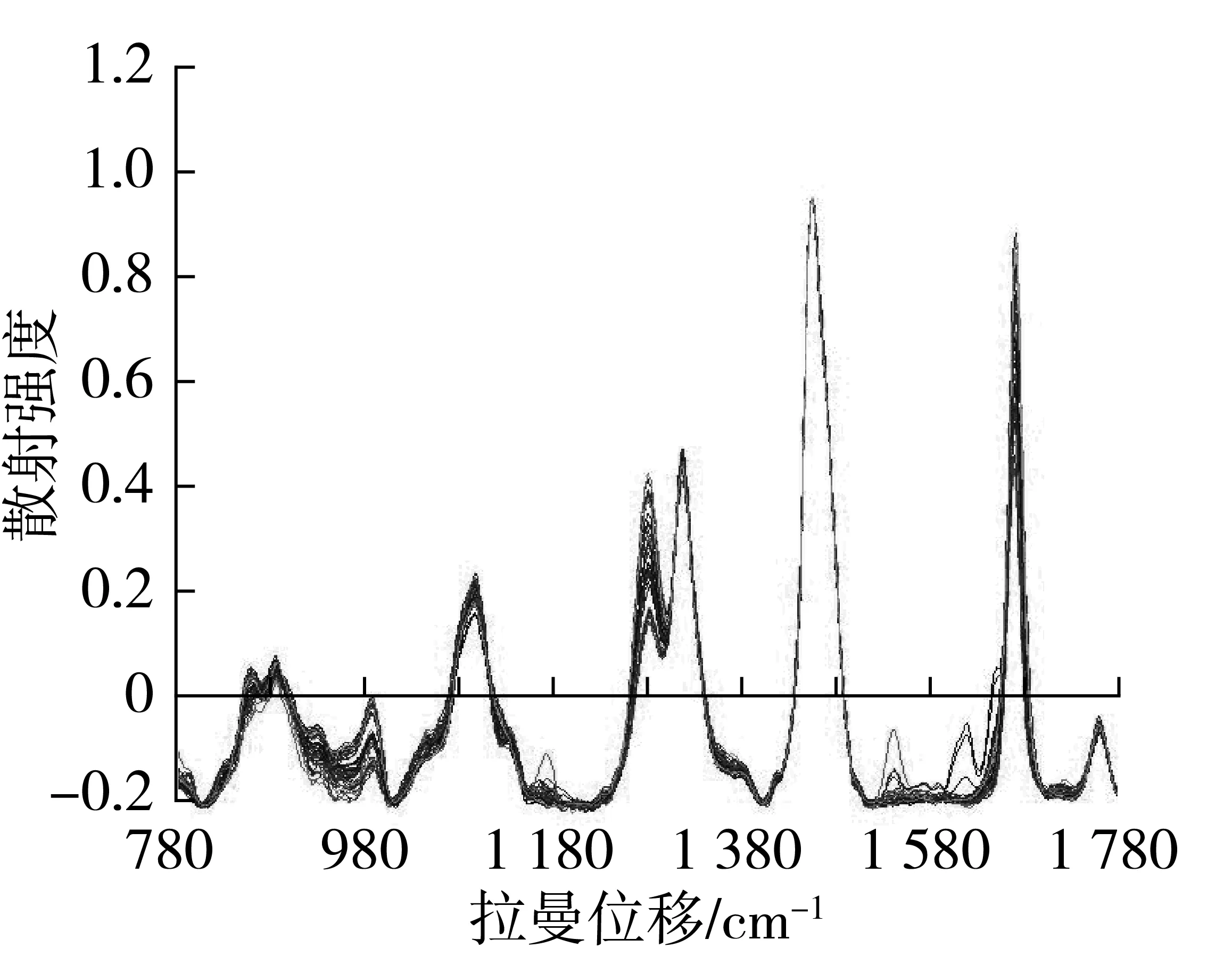
图3 经过SG15-ALS-Nor预处理拉曼光谱
近红外光谱采用的预处理方法有:多元散射校正(MSC)、标准正态变量变换(SNV)、标准正态变量变换和去趋势技术联用算法(SNV_DT)。图4是经过SNV_DT预处理的近红外光谱。
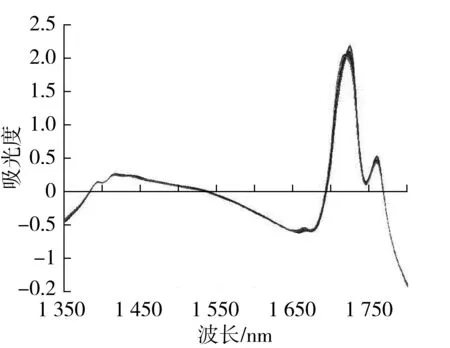
图4 经过SNV_DT预处理近红外光谱
1.5 光谱特征波长提取
竞争性自适应重加权采样方法(CARS)[14]是采用偏最小二乘(PLS)交叉验证建模,结合蒙特卡罗(MC)采样技术,根据PLS模型的交互检验均方差(RMSECV)值选择波长变量子集,RMSECV值最小时选取对应的变量区间作为建模的特征变量。试验中MC采样次数设为100,根据PLS模型的10折交互检验均方差值选择波长变量子集。
将预处理(MA11-ALS-Nor、MA11-airPLS-Nor、SG15-ALS-Nor、SG15-airPLS-Nor)的拉曼和预处理(SNV、MSC、DT、SNV_DT)的近红外光谱应用CARS提取特征变量,将提取后特征波段光谱分别应用于拉曼和近红外光谱、多源光谱特征层融合SVR模型的建立。
1.6 建模方法、参数优化方法及模型评价指标
支持向量机(SVM)在解决小样品、非线性及高维模式识别中表现出许多特有的优势,成为克服“维数灾难”和“过学习”等困难的强有力手段[15]。SVM
方法可细分为支持向量机分类(SVC)和支持向量机回归(SVR)2种方法[16]。而本试验选用支持向量机回归法建立食用油MUFA和PUFA含量的快速预测模型。SVR方法需要设置惩罚因子C和RBF核函数的参数g的输入值,不同的参数组合(C,g)值对SVR模型的检测效果存在较大差异,人为地设置参数,很难确定最佳参数组合,因此本实验采用GS法优化食用油MUFA和PUFA检测模型的参数组合(C,g),建立预测能力较强的SVR模型[17]。试验中以校正集和预测集的决定系数R2和均方误差(MSE)作为模型的评价标准。
2 结果与分析
2.1 食用油MUFA含量预测的SVR模型
2.1.1 食用油MUFA含量预测的拉曼、近红外SVR模型
采用4种不同预处理的拉曼光谱经CARS提取的特征变量作为SVR模型的输入量,选用RBF核函数,采用GS算法对组合参数(C,g)进行寻优,建立特征波段含量预测SVR模型。同理,建立基于4种不同预处理的近红外光谱的CARS-SVR模型。表2为拉曼、近红外光谱结合SVR建模得到的MUFA含量预测结果和模型参数。
从表2中可以看出,拉曼、近红外光谱结合化学计量学方法建立的SVR模型都能够实现食用油MUFA含量的快速预测。采用DT预处理方法的近红外光谱建立的CARS-SVR模型对预测集样品预测效果最好,预测集决定系数R2和均方误差(MSE)为0.953 0、1.29E-3,校正集和预测集的MSE相差较小,预测能力强。基于拉曼光谱建立的CARS-SVR模型的校正集决定系数R2较近红外有一定程度的增加,但是前3个模型的预测集R2最高才0.852 7,远低于NIR-SVR模型,采用预处理方法(SG15-airPLS-Nor)建立的Raman-CARS-SVR模型的预测集R2提升到0.932 0,但校正集和预测集的MSE相差较大,模型预测效果较之NIR-DT-CARS-SVR差。图5为近红外光谱的食用油MUFA的DT-CARS-SVR模型对预测集样品的预测结果图。
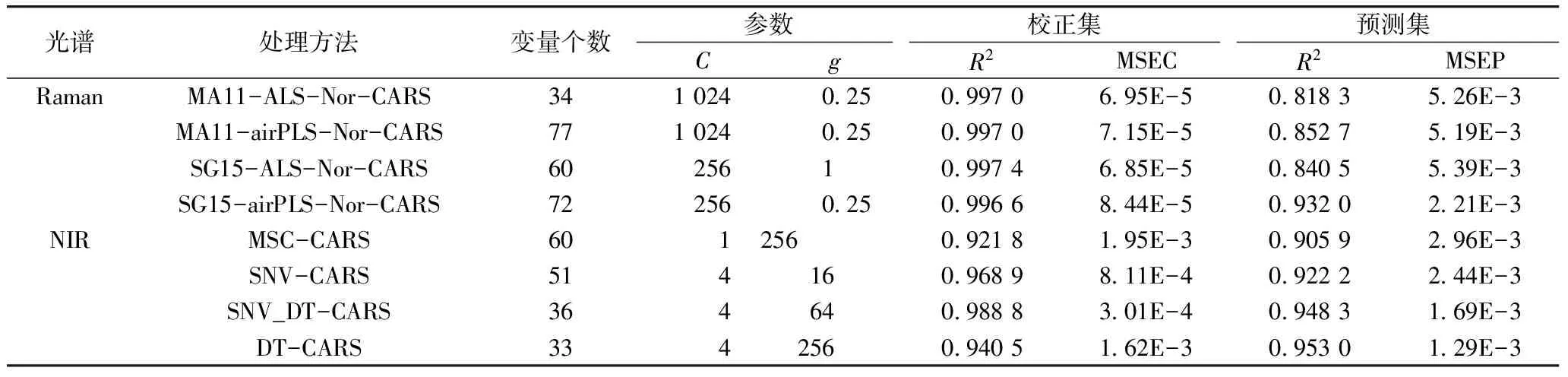
表2 拉曼、近红外光谱结合SVR建模得到的MUFA含量预测结果
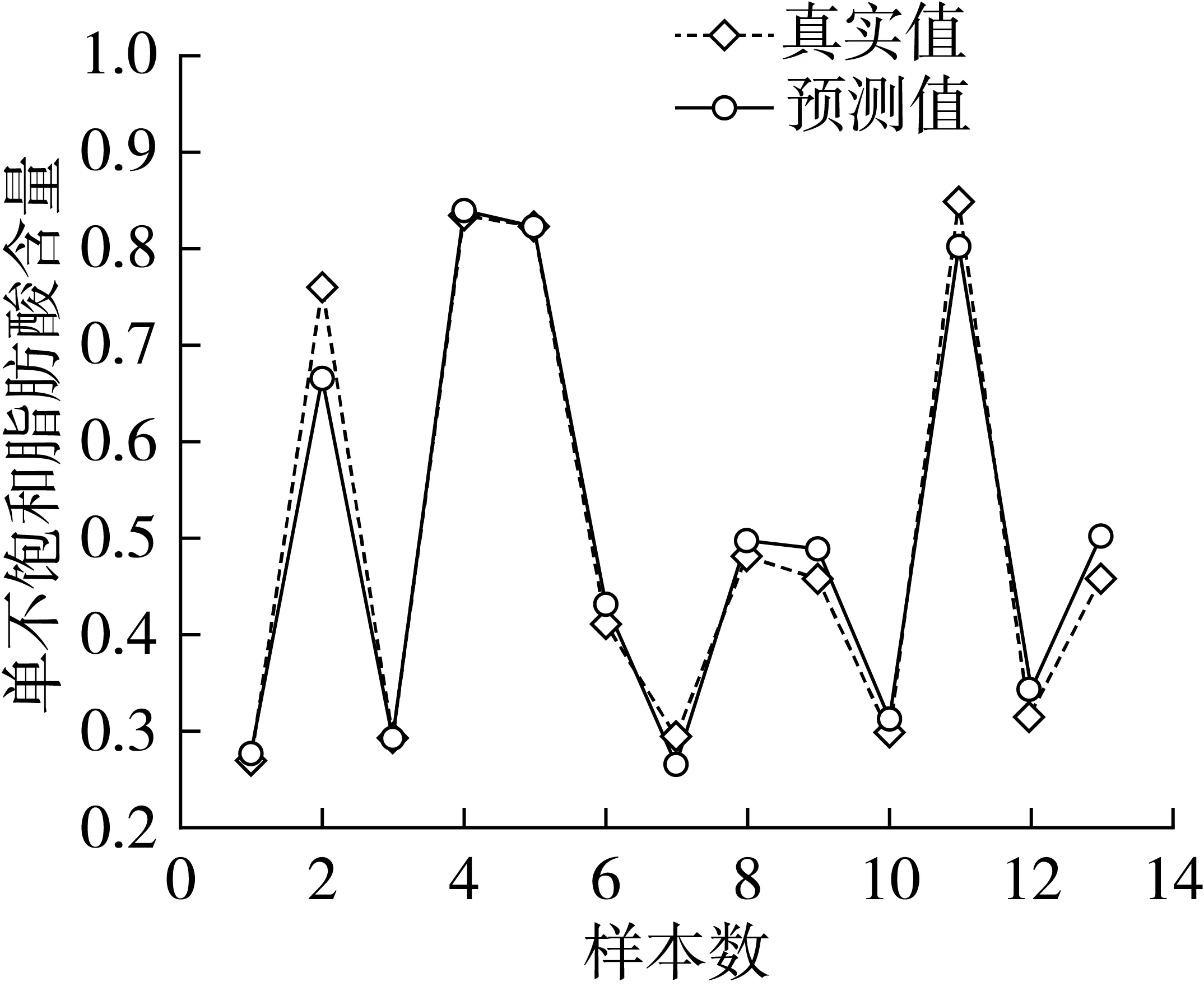
图5 DT-CARS-SVR对预测集样品的预测结果
2.1.2 特征层多源光谱数据融合食用油MUFA含量预测SVR模型
将经过特征波长提取方法优选的拉曼和近红外光谱数据同时作为SVR模型的输入变量,建立特征层多源光谱数据融合的MUFA含量快速预测Raman-NIR-SVC模型;建立的特征层融合SVR模型预测结果和模型参数见表3。
从表3中可以看出,基于特征层融合建立的Raman-NIR-SVR模型能够实现食用油MUFA含量的快速预测。经过特征波长提取的拉曼和近红外2种光谱数据融合建立的Raman-NIR-SVR模型预测集决定系数R2均在0.943 4以上,最高达到0.977 3,模型预测能力强,其中SG15-ALS-Nor-CARS-MSC-CARS-SVR模型的校正集和预测集的R2为0.996 8和0.977 3。与单光谱中最优的NIR-DT-CARS-SVR模型比较,使用特征层融合的SG15-
ALS-Nor-CARS-MSC-CARS-SVR模型的预测集和校正集的R2分别增加了5.63%、2.43%。结果表明使用特征层融合建立的MUFA含量的快速预测的SVR模型的预测效果要好于单独使用Raman和NIR光谱建立的SVR预测模型,说明Raman和NIR 2种光谱具有互补效果。图6为拉曼和近红外光谱的特征层融合的食用油MUFA的SG15-ALS-Nor-CARS-MSC-CARS-SVR模型对预测集样品的预测结果图。
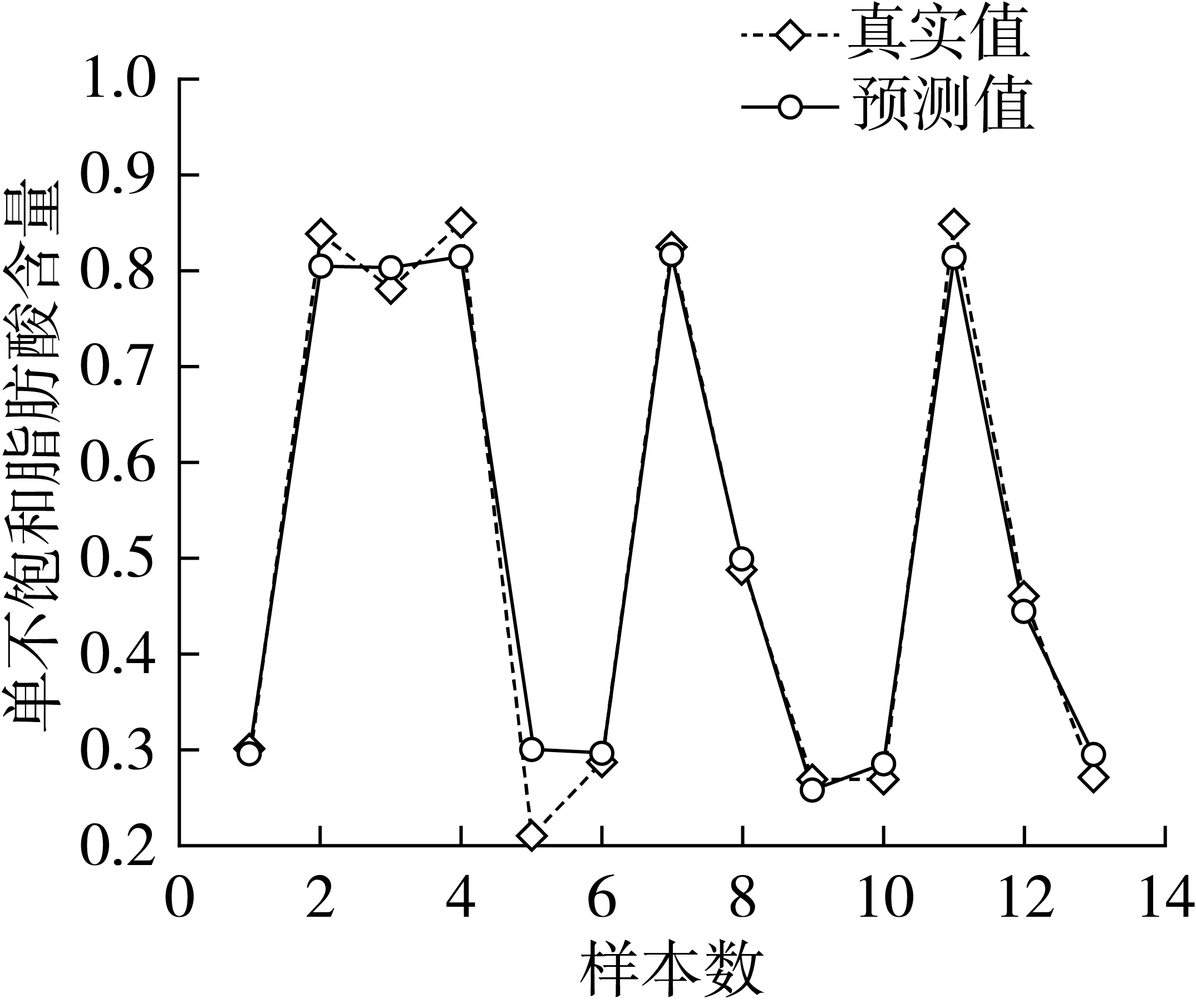
图6 SG15-ALS-Nor-CARS-MSC-CARS-SVR模型对预测集样品的预测结果
2.2 食用油PUFA含量预测SVR模型
2.2.1 食用油PUFA含量预测拉曼、近红外光谱SVR模型
将拉曼光谱经过预处理及CARS特征波长提取后得到的光谱数据作为SVR模型的输入变量;近红外光谱则经过预处理后进行CARS特征波长提取,得到的光谱数据作为SVR模型的输入变量,然后分别建立PUFA含量预测SVR模型。基于拉曼、近红外光谱数据建立的含量预测SVR模型预测结果和模型参数见表4。

表3 基于特征层多源光谱融合的Raman-NIR-SVR模型MUFA预测结果
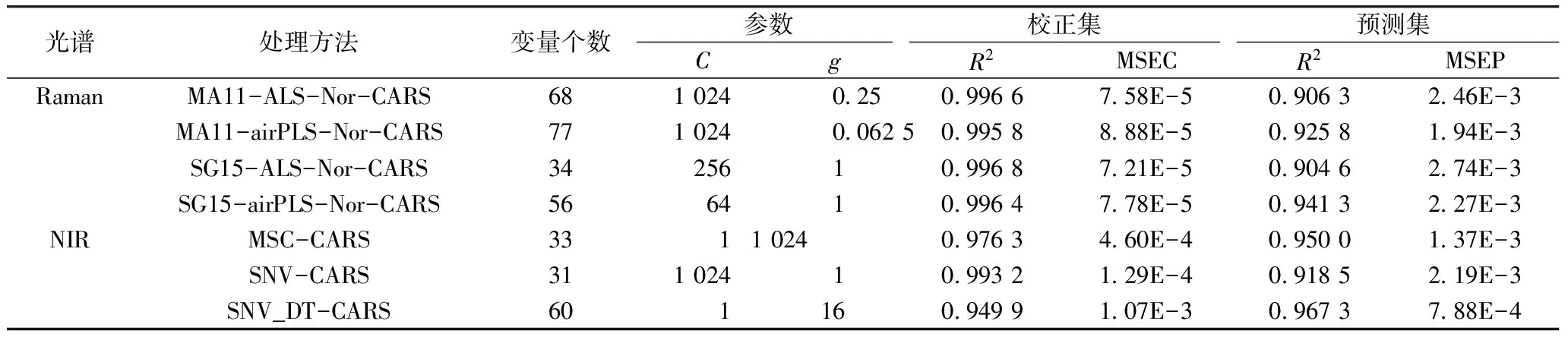
表4 拉曼、近红外光谱结合SVR建模得到的PUFA含量预测结果

表5 基于特征层多源光谱融合的Raman-NIR-SVR模型PUFA预测结果
从表4中可以看出,拉曼、近红外光谱结合化学计量学方法建立的SVR模型能够实现PUFA含量的快速预测。就Raman-SVR模型而言,经过SG15-airPLS-Nor-CARS处理的光谱数据建立的模型对预测集样品预测效果最好,预测集决定系数R2为0.941 3。而对于NIR-SVR模型,采用SNV_DT-CARS处理的光谱建立的模型的预测效果最好,预测集决定系数R2和均方误差(MSE)为0.967 3、7.88E-4,预测能力强,实际应用价值大。对比2种单光谱建立的CARS-SVR模型,NIR-SNV_DT-CARS-SVR模型的含量预测的综合性能最好。图7为近红外光谱的PUFA的SNV_DT-SVR模型对预测集样品的预测结果图。
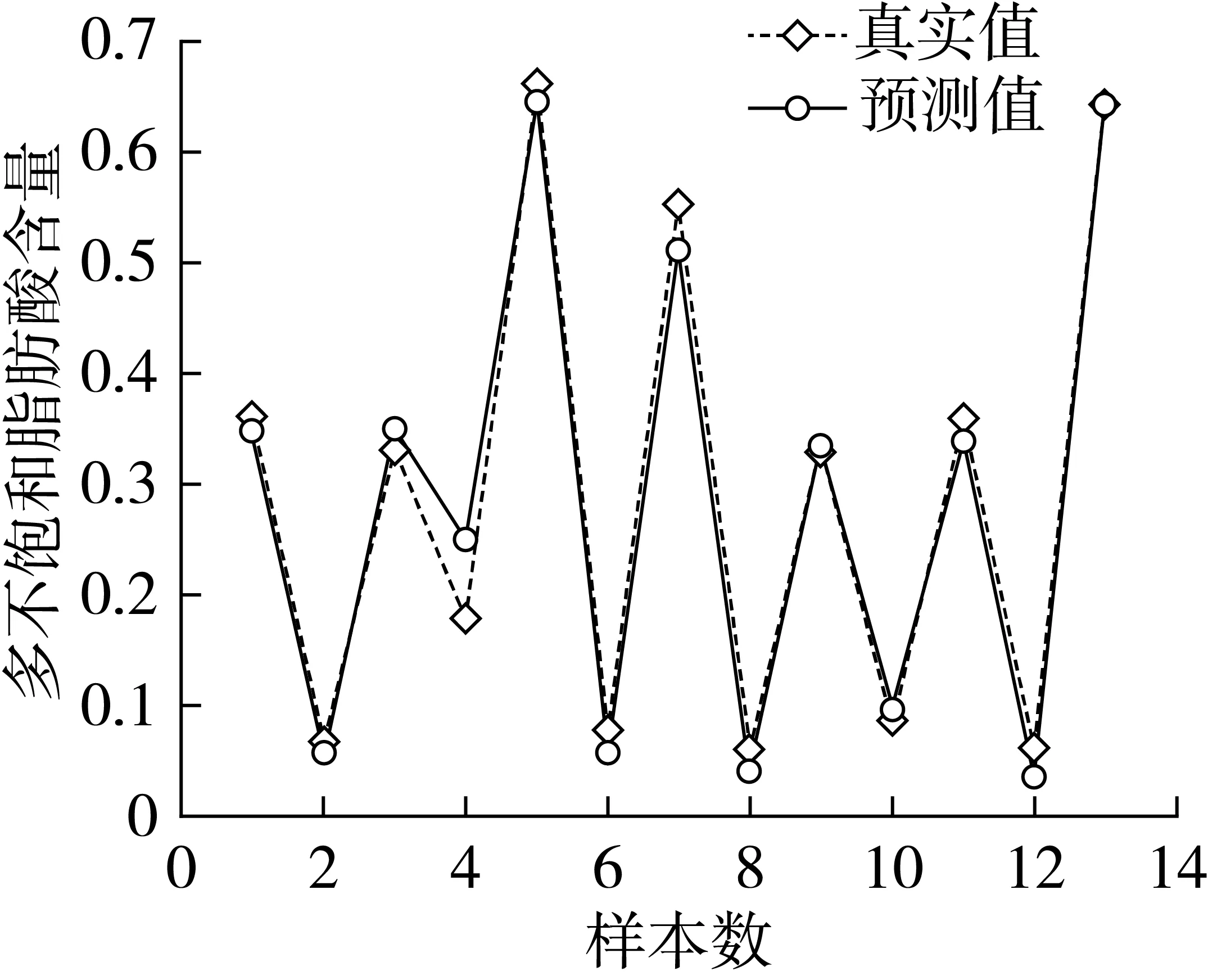
图7 SNV_DT-SVR模型对预测集样品的预测结果
2.2.2 特征层多源光谱数据融合食用油PUFA含量预测SVR模型
将经过特征波长提取方法优选的拉曼和近红外光谱数据同时作为SVR模型的输入变量,建立特征层融合的食用油PUFA含量快速预测Raman-NIR-SVR模型。建立PUFA含量的特征层融合SVR模型预测结果和模型参数见表5。
从表5中可以看出,基于多源光谱的特征层融合建立的Raman-NIR-SVR模型能够实现食用油PUFA含量的快速预测。经过特征波长提取的激光拉曼和近红外两种光谱数据融合建立的Raman-NIR-SVR模型校正集和预测集决定系数R2均在0.983 9以上,且校正集和预测集的均方误差(MSE)相差较小,模型预测能力和稳定性强,其中MA11-airPLS-Nor-CARS-MSC-CARS-SVR模型的校正集和预测集决定系数R2为0.995 8和0.993 0。比较最优单光谱数据建立的NIR-SNV_DT-CARS-SVR模型,校正集和预测集决定系数R2分别增加了4.59%、2.57%,预测效果更好。结果表明使用特征层多源光谱数据融合建立的PUFA含量预测模型的预测效果优于单独使用拉曼光谱和近红外光谱建立的模型。图8为拉曼和近红外光谱的数据层融合的PUFA的MA11-airPLS-Nor-CARS-MSC-CARS-SVR模型对预测集样品的预测结果图。
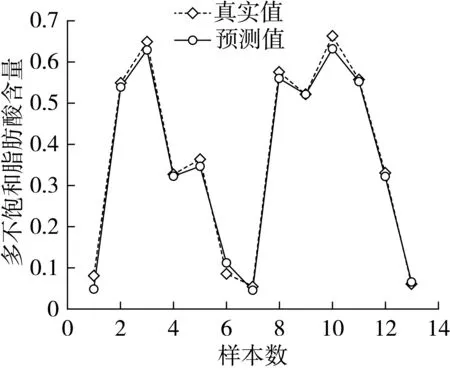
图8 MA11-airPLS-Nor-CARS-MSC-CARS-SVR模型对预测集样品的预测结果
3 结论
应用光谱数据融合技术,在特征层建立融合拉曼和近红外光谱的食用油MUFA和PUFA含量的快速预测模型,实现了基于多源光谱特征层数据融合的食用油MUFA和PUFA含量的快速预测。研究表明,近红外、拉曼光谱法结合SVR建立的NIR-SVR模型能够实现食用油MUFA、PUFA含量的快速预测。使用特征层多源光谱数据融合建立的食用油MUFA、PUFA含量预测模型的预测效果优于单独使用拉曼光谱和近红外光谱建立的含量预测模型。结果表明,本研究提出的技术路线能够实现食用油MUFA和PUFA含量的快速预测,而基于特征层融合建立的定量回归模型提高了预测的准确性,为其他食用植物油品质在快速检测的问题上提供借鉴。
[1]杨帆,薛长勇.常用食用油的营养特点和作用研究进展[J].中国食物与营养,2013,19(6):63-66
Yang F,Xue CY.Research Advancement of Nutritional Characteristics and Functions of Common Edible Oils[J].Food and Nutrition in China.2013,19(6):63-66
[2]张伟敏,钟耕,王炜.单不饱和脂肪酸营养及其生理功能研究概况[J].粮食与油脂,2005(3):13-15
Zhang WM,Zhong G,Wang W.Study Survey of Nutrition and Biological Function of MUFA[J].Cereals and Oils.2005(3):13-15
[3]王萍,张银波,江木兰.多不饱和脂肪酸的研究进展[J].中国油脂.2008,33(12):42-46
Wang P,Zhang YB,Jiang ML.Research advance in polyunsaturated fatty acid[J].China Oils and Fats,2008,33(12):42-46
[4]薛雅琳,王雪莲,张蕊,等.食用植物油掺伪鉴别快速检验方法研究[J].中国粮油学报,2010,25(10):116-118
Xue YL,Wang XL,Zhang R,et al.An Authentication Method of Edible Vegetable Oils[J].Chinese Cereals and Oils Association,2010,25(10):116-118
[5]褚小立,许育鹏,陆婉珍.用于近红外光谱分析的化学计量学方法研究与应用进展[J].分析化学,2008,36(5):702-709
Chu XL,Xu YP,Lu WZ.Research and Application Progress of Chemometrics Methods in Near Infrared Spectroscopic Analysis[J].Chinese J.Anal.Chem.,2008,36(5):702-709
[6]邓之银,张冰,董伟,等.拉曼光谱和 MLS-SVR的食用油脂肪酸含量预测研究[J].光谱学与光谱分析,2013,33(11):2997-3001
Deng ZY,Zhang B,Dong W,et al.Research on Prediction Method of Fatty Acid Content in Edible Oil Based on Raman Spectroscopy and Multi-Output Least Squares Support Vector Regression Machine[J].Spectroscopy and Spectral Analysis,2013,33(11):2997-3001
[7]FAN Ya,LI Shuang,XU Da-peng.Raman Spectra of Oleic Acid and Linoleic Acid[J].Spectroscopy and Spectral Analysis,2013,33(13):3240-3243
[8]陆婉珍,袁洪福,徐广通.现代近红外光谱分析技术[D].北京:中国石化出版社,2000
Lu WZ,Yuan HF,Xu GG.Modern near infrared spectral analysis technology[D].Beijing:Sinopec press,2000
[9]滕召胜,郁文贤.基于数据融合的智能水分快速测定仪[J].电工技术学报,1999,14(5):71-73,80
Teng ZS,Yu WX.An Intelligent Instrument of Quick Measuring Moisture Content Based on Data Fusion[J].Transactions of China Electrotechnical Society,1999,14(5):71-73,80
[10]穆海洋,李艳君,单战虎,等.便携式多源光谱融合水质分析仪的研制[J].光谱学与光谱分析,2010,30(9):2586-2590
Mu HY,Li YJ,Dan ZH,et al.Development of a Multi-Spectra Based Portable Water Quality Analyzer[J].Spectroscopy and Spectral Analysis,2010,30(9):2586-2590
[11]谢军,潘涛,陈洁梅,等.血糖近红外光谱分析的Savitzky-Golay平滑模式与偏最小二乘法因子数的联合优选[J].分析化学,2010,38(3):342-346
Xie J,Pan T,Chen JM,et al.Joint Optimization of Savitzky-Golay Smoothing Models and Partial Least Squares Factors for Near-infrared Spectroscopic Analysis of Serum Glucose[J].Chinese J.Anal.Chem.,2010,38(3):342-346
[12]Zhang Z M,Chen S,Liang Y Z.Baseline correction using adaptive iteratively reweighted penalized least squares[J].Analyst,2010,135(5):1138-1146
[13]H.E.M.Boelens,R.J.Dijkstra,P.H.C Eilers,et a1.New background correction method for liquid chromatography with diode array detection,infrared spectroscopic detection and Raman spectroscopic detection[J].Journal of Chromatography A,2004,1057(1-2):21-30
[14]Li H D,Liang Y Z,Xu Q S,et al.Key wavelengths screening using competitive adaptive reweighted sampling method for multivariate calibration[J].Analytical Chimica Acta,2009,648(1):77-84
[15]Vapnik,Vladimir Naumovich.The Nature of Statistical Learning Theory[M].New York:Springer-Verlag,1999
[16]涂斌,宋志强,郑晓,等.基于激光近红外的稻米油掺伪定性-定量分析[J].光谱学与光谱分析,2015,35(6):1539-1545
Tu B,Song ZQ,Zhang X,et a1.Qualitative-Quantitative Analysis of Rice Bran Oil Adulteration Based on Laser Near Inf rared Spectroscopy[J].Spectroscopy and Spectral Analysis,2015,35(6):1539-1545
[17]Shen Xiong,Zheng Xiao,Song Zhiqiang,et al.Rapid Identification of Waste Cooking Oil with Near Infrared Spectroscopy Based on Support Vector Machine.In:Li D,Chen Y(eds)Computer and computing technologies in agriculture VI,Berlin:Springer,2013,392(1):11-18.
Content Detection of MUFA and PUFA Integrated Based on Characteristic Fusion of Raman and Near Infrared Spectrum
Wu Shuang1Wang Jie1Yu Yaru1Tu Bin1Zheng Xiao1He Dongping2
(School of Mechanical Engineering,Wuhan Polytechnic University1,Wuhan 430000) (College of Food Science and Engineering,Wuhan Polytechnic University2,Wuhan 430000)
It was explored in this paper that characteristic fusion of Raman-NIR was combined with Chemometrics to establish monounsaturated fatty acid(MUFA)and polyunsaturated fatty acids(PUFA)content prediction model to solve the problem of their content rapid prediction.It focused on what effects various pretreatment algorithms had on prediction model.Competitive adaptive reweighted sampling(CARS)was used to extract the characteristic wavelength of Raman and NIR spectra,grid search(GS)algorithm to select the parameter combination(C,g).The author established SVR model based on characteristic wavelength of Raman and NIR spectra respectively,and based on characteristic fusion did SVR model.The experiment showed that based on feature fusion of Raman-NIR the SVR model was better to realize fast prediction.For MUFA content,prediction set determination coefficientR2of SG15-ALS-Nor-CARS-MSC-CARS-SVR model was 0.977 3,compared with the optimal prediction model of the single spectra,which increased by 2.43%;and for MUFA,MA11-airPLS-Nor-CARS-MSC-CARS-SVR modelR2was 0.995 8,comparing the optimal single spectra SVR model increased by 2.57%.Result showed that comprehensive performance of the prediction model established by feature fusion method was better than the model based on single spectral data.
monounsaturated fatty acid,polyunsaturated fatty acids,characteristic fusion,support vector machine
TS225.1
A
1003-0174(2017)11-0158-07
2016湖北省粮食科技创新与成果转化(20165104),武汉市科技攻关计划(2013010501010147),武汉工业学院食品营养与安全重大项目培育专项(2011Z06),武汉轻工大学研究生创新(2014CX005)
2016-10-24
吴双,女,1989年出生,硕士,利用光谱技术检测食用油的成分
郑晓,男,1958年出生,教授,利用光谱技术检测食用油的成分
