基于引导Boosting算法的显著性检测
2017-11-15叶子童范赐恩
叶子童,邹 炼,颜 佳,范赐恩
(武汉大学 电子信息学院,武汉 430072)(*通信作者电子邮箱zoulian@whu.edu.cn)
基于引导Boosting算法的显著性检测
叶子童,邹 炼*,颜 佳,范赐恩
(武汉大学 电子信息学院,武汉 430072)(*通信作者电子邮箱zoulian@whu.edu.cn)
针对现有的基于引导学习的显著性检测模型存在的训练样本不纯净和特征提取方式过于简单的问题,提出一种改进的基于引导(Boosting)的算法来检测显著性,从提升训练样本集的准确度和改进特征提取的方式来达到学习效果的提升。首先,根据显著性检测的自底向上模型产生粗选样本图,并通过元胞自动机对粗选样本图进行快速有效优化来建立可靠的引导样本,完成对原图的标注建立训练样本集;然后,在训练集上对样本进行颜色纹理特征提取;最后,使用不同特征不同核的支持向量机(SVM)弱分类器生成基于Boosting学习一个强分类器,对每幅图像的超像素点进行前景背景分类,得到显著图。在ASD数据库和SED1数据库上的实验结果显示该模型能对复杂和简单的图像生成完备清晰的显著图,并在准确率召回率曲线和曲线下面积(AUC)测评值上有较大提升。由于其准确性,能应用在计算机视觉预处理阶段。
显著性检测;boosting;自底向上模型;粗选样本优化;颜色特征提取
0 引言
显著性检测在计算机视觉中常被作为一种预处理手段,在图像分割[1-2]、目标识别[3]、图像检索[4]、自适应压缩[5]、内容感知[6]等领域有着广泛的应用。显著性检测模型可以分为自底向上的目标驱动模型[7-10]和自顶向下的任务驱动模型[11-13]。前者与人类视觉系统对外界的自下而上、快速的、任务无关的阶段相对应,从底层视觉信息出发,对细节信息的检测比较好;后者与人类视觉系统对外界视觉感知的自上而下、意识驱动、任务相关的阶段相对应,一般从训练样本中获取更典型的特征,通常比较粗糙但能有较好的全局形状。
显著图反映了图像中不同区域的显著程度,而理想的显著性检测模型是得到显著性目标和背景的二值图,在这样的任务驱动下,自顶向下的显著性检测可以是对于图像的有意识带需求的训练学习。采用学习的方法来进行显著性检测能够取得较好的全局表现,但是需要参考样本。对图像进行标记建立参考然后从大量样本中学习特征的方式显然过于复杂,不足以应对实时快速的处理要求。考虑到基于自底向上的显著性检测模型能生成原图的弱显著图,尽管该显著图缺乏全局信息,检测效果具有局限性,但是可以作为原图的粗糙参考,引导学习(Bootstrap Learning, BL)[14]算法提出可以采用自底向上的模型生成的样本来引导特征学习,即采用弱显著图对原图作一次简单的标记(根据图中像素块的显著性值设定正负种子),利用原图中选取的正负样本种子训练一个分类器。这种方法使得监督学习的过程可以变为无监督的,省去了繁琐的人工标注和离线训练。但是用于引导的样本的准确性很大程度上决定了特征学习的效果,在原算法中存在参考过于粗糙导致样本选择不纯净和分类器的特征提取方式过于简单的问题。针对以上问题,本文提出:1)采用优化处理后的样本来进行引导以减少误分类,提升显著性检测的效果;2)改进特征提取的方式。本文将学习的过程限定在每幅图像中,可以适应每幅图像的差异性,且去掉了人工标注的过程,是一种自生成参考的学习模型。
将基于自底向上的检测模型生成的显著图作为粗选样本图,本文提出对于粗选样本图进行快速有效的优化处理得到引导样本图,对每幅图像建立参考。引导样本图是基于底层图像特征生成且演化更新的,虽然缺少完善的形状信息但是在细节上表现优异,其中有部分很准确的前景背景点。同时本文选用了新的颜色特征描述子,并在学习的过程中加上了纹理特征,新的颜色特征描述方式避免了原有的特征选取中由于超像素点内像素值间颜色差异较大时带来的训练效果偏差。利用Boosting算法从多个弱分类器学习一个强分类器对原图的所有超像素点进行分类,对结果加以平滑后得到最终的显著图。
如图1所示,原算法选用粗糙的参考样本进行学习,由于训练样本的不纯净,错误的样本种子可能导致学习效果的下降,最终得不到显著性物体或者误将背景作为前景。

图1 粗选样本图和优化样本图引导Boosting的结果比较
1 研究现状
人类视觉系统的研究表明,显著性有关某一场景的唯一性、稀有程度、惊奇度,而这些是由如色彩、纹理、形状等基本特征表达的[15]。在显著性检测的自底向上模型中常常从图像底层线索出发使用各种先验信息,如对比度先验[15-16]、边界先验、中心先验[17]和暗通道先验[18]、背景先验[19-23]等。Wei等[20]将图像边界作为背景并把每个图像块与背景的最短距离定义为该区域块的显著性值。Zhu等[23]定义了一个有认知几何解释的量,即区域在边界上的周长与该区域面积的平方根之比,称之为边界连接度并用以衡量区域的显著性。Tong等[14]将超像素点与边界区域的颜色纹理对比度作为超像素点的显著性值。
自顶向下的显著性检测模型由任务驱动,文献[23]中根据图像的显著性检测问题建立一个最优化模型。文献[14]中通过从样本集中学习的一个分类器对图像中所有超像素点进行显著性物体和背景的二分类。自底向上模型从底层图像线索出发,缺乏全局形状信息,检测效果有一定的局限性。而基于学习的方法建立自顶向下的模型则具有样本依赖性,粗糙参考会带来学习效果下降,精确标注又需要繁琐的过程,因此本文选择建立一个优化预处理过程来连接两种模型。利用底层图像特征得到的显著图作为粗选样本图,通过优化过程对粗选样本图进行优化,以达到建立可靠参考和选取准确训练样本集的目的,尽量降低了学习前训练样本集建立的复杂度且提高了样本的可靠性。 具体的框架如图2所示。

图2 本文算法的框架
2 改进的基于引导的Boosting算法
本文的自生成参考的学习模型是通过提升训练样本集的准确度和改进特征提取的方式着手来实现学习效果的提升。具体算法为:
步骤1 基于自底向上模型生成粗选样本图,并采用元胞自动机的优化策略得到引导样本图,生成训练样本集;
步骤2 对所有样本使用改进后的颜色及纹理特征提取方式进行特征提取;
步骤3 对提取的特征进行学习,采用Adaboost的方法训练强分类器;
步骤4 利用分类器对原图所有超像素点进行分类,平滑后得到最终的显著图。
2.1 训练样本集生成
生成训练样本集的参照图分为两个过程:建立粗选样本图,粗选样本图是基于自底向上模型得到的显著图,是对原图的粗糙标记;对粗选样本图进行优化处理得到引导样本图,引导样本图是优化后显著性物体与背景趋于分离的较高质量的显著图。最终基于参考图在原图中选取关键超像素点来建立训练样本集。整个过程在每幅图像中单独进行。
2.1.1 粗选样本图
对于一幅300×400的图像,对所有的像素点进行计算的时间复杂度过高,采用超像素可以降低时间复杂度。本文中采用了简单线性迭代聚类(Simple Linear Iterative Clustering, SLIC)[24-25]算法来产生超像素,每幅图像选取N=300个超像素,提高了计算效率同时对于小尺度的显著性目标也能兼容,超像素的颜色为超像素集合内的像素点的颜色均值。
自底向上的显著性检测模型,从图像既有的基本特征——颜色特征出发,基于对比度先验和边界先验来计算显著性值,生成粗选样本图。不同于RGB色彩空间,LAB颜色更接近于人类的生理视觉,L分量能够密切匹配人类的亮度感知,它弥补了RGB色彩模型的色彩分布不均的问题,所以本文中用RGB特征和LAB特征共同描述颜色特征,从而起到相互补充的作用。
超像素点的显著性值为该超像素点和所有边界超像素点的两种颜色对比度之和,计算公式如式(1):

(1)
其中:dk(si,sj)是超像素点si和sj在第k颜色空间的欧氏距离,NB是边界超像素的个数。
以超像素点的显著性值为其像素值,就得到了一幅图像的粗选样本图。粗选样本图的计算从对120 000个像素点的计算降低为对300个像素点的计算,且将全局对比度改为只对边界的对比度,极大地提高了计算效率。从图3中可以看出粗选样本中含有较多的分散的噪点,要对原图有更精确的参考标注,就需要使前景物体和背景各自聚集,将选作训练样本的超像素点的置信度尽可能提高。为了得到一些更准确的超像素点用作训练,下文中提出了训练集建立前从粗选样本图到引导样本图的预处理步骤。为保持计算的统一,本文中的所有显著性值都进行了归一化处理。
2.1.2 引导样本图
粗选样本图中存在部分背景超像素点的显著性值过高,这些超像素容易被当作正样本引入训练样本集,因此对整个粗选样本图进行优化处理是有必要的。
显著性物体总是趋向于聚集的,而元胞自动机[19,26]可以探索邻居间的本质联系,并减少相似区域间的差异性,因此利用元胞自动机来优化粗选样本图是有效的。将粗选样本图中的每个超像素看作一个元胞,对所有元胞的显著性值进行演化和更新。粗选样本图的元胞当前显著性值组成初始向量S0=[Saliency(s1),Saliency(s2),…,Saliency(sN)]。下一状态下的显著性值St+1由周边元胞和自身元胞共同决定。本文算法以影响因子矩阵和置信度矩阵来表征下一状态和当前状态的关系。
影响因子矩阵衡量周边元胞对元胞下一状态的影响。F=[fij]N×N是N维矩阵(N为元胞的个数,矩阵的元素表示元胞sj对元胞si的影响因子),矩阵元素计算公式如式(2):
(2)
其中dlab(si,sj)表示元胞si和sj在CIELAB空间的欧氏距离,σ2是一个可调参数用于控制影响程度,文中设定为σ2=0.1。
置信度矩阵C表征元胞下一状态与当前自身元胞状态的关系权重。置信度越高下一状态越依赖当前状态,置信度矩阵是对角阵,对角元素的计算公式如式(3):
ci=1/max(fij)
(3)
得到置信度矩阵和影响因子矩阵后按照如下规则使元胞自动更新演化。设定更新公式为:
St+1=C·St+(I-C)·F·St
(4)
其中:I为单位矩阵,初始状态S0就是粗选样本中的超像素点的显著性值向量。一般进行N1=15次的更新就可以取得较好的效果。最终状态下SN1的就是优化后的超像素点的显著性值向量。将每个超像素值平均到每个像素点上,就可以得到较为精准的引导样本图。影响因子矩阵的计算复杂度为O(N2),更新过程只需进行15次矩阵运算,整体复杂度很低,因而元胞自动机的优化处理是高效的。
如图3(b)所示,粗选样本图中会在背景点处出现较亮的点,基于一定的样本选取规则,若采用粗选样本图作为参考会导致样本集的不纯净,带来学习效果的下降。因此用优化后的引导样本图建立训练样本集和引导随后的Adaboost学习强分类器更为可靠。

图3 粗选样本图优化的结果
2.1.3 样本选取规则

2.2 特征提取
选取特征是建立学习模型中关键的一步,选取的特征很大程度上决定了学习效果。在显著性检测问题中,颜色特征是必不可少的,一般的提取方式为以超像素的颜色值,也就是超像素内所有像素点在R,G,B各个通道上的平均值作为RGB域的三维特征,以RGB特征为例,超像素点si的特征向量Fsi为:
(5)
其中:Nsi为超像素点si内像素点的个数,j为超像素点内的像素点,rj为像素点的r通道颜色值。LAB特征也是如此。但是通过随机选取多幅图像,对其按照该方式进行特征提取,发现这种方式舍弃了超像素内的颜色分布信息,当超像素内像素颜色相近时可能问题不大,但是如果超像素内像素间颜色变化过大导致平均值并不能代表超像素的颜色特征时就会产生误差,甚至可能出现像素点的颜色误差相互抵消导致正样本和负样本具有相同的特征分布的情况,对于分类器的分类效果产生影响。如图4所示,对于随机选取的一幅图像,根据上文中所述建立参考图基于样本选取规则得到的正样本为前29组,负样本为后216组,以特征的维数作为横坐标,特征值作为纵坐标,绘制为散点图,并用加号点表示正样本,空心点表示负样本,可以明显地看出正负样本的特征区别度不大容易出现交叉,且正样本的特征分布并不具备较好的一致性,如果用于训练则会影响到学习的效果。

图4 三维的RGB特征
2.2.1 颜色特征提取
针对以上问题,在RGB和LAB空间中提取特征时提出新的方式,仍然以RGB域为例:
步骤1 本文首先将原图在RGB空间进行量化。将原图在三个通道上都量化至12个bin,bini,k表示k通道下第i个bin的颜色范围,k∈{r,g,b},i∈{1,2,…,12};
(6)
步骤2 对超像素内的所有像素点分别在三个通道下进行直方图统计,得到表征颜色值落在每个bin上的像素点个数的3组12维向量;
(7)
步骤3 将这三组向量串联成为36维向量作为超像素点在RGB空间的特征向量。
Fsi=[Rsi,Gsi,Bsi]
(8)
为了量化的准确性,并非在各个通道的固有范围上量化,而是计算出每幅图像在各个通道的最大最小值来作为量化的起点和终点,这样能减小不必要的误差,使结果更准确。
特征向量的每一维的值代表了落在固有颜色区间上的像素点个数,既隐式地表征了其颜色值又显式地表明了超像素点内颜色分布情况。可以兼顾到图像的颜色变化,背景的超像素点的颜色集中在某些区间,而正样本往往在多个区间都有颜色分布,缺少颜色的分布信息会带来误分类。采取串联的方式,一是因为本文中的训练是针对每幅图像进行的,训练样本集中样本数较少,如果按照量化后的颜色种类进行统计,例如在RGB空间中量化后的颜色种类为123,会出现维数较大与训练样本数量不匹配的情况;二是实验显示串联得到的特征向量计算复杂度较低且能较好地表明超像素内的颜色及其分布。如图6所示,同样的一幅图像,采取本文的特征提取方式,绘制出正负样本的散点图,加号表示正样本,空心号表示负样本,并拟合出正样本的包络为虚曲线,负样本的包络为实曲线。可以看出正负样基本没有交叉,两者有较大的区分。从图中也可以看出,正样本在各个通道中的颜色值分布并非集中在某个值上,如果单独地采用颜色的均值得到的三维特征,效果就会出现偏差。

图5 36维的RGB特征
在CIELAB空间上则只需量化到更少的bin上[27],本文将其分别在三个通道内都量化至8个bin。采用和RGB空间内同样的方法,将3个8维向量串联成的24维的特征向量作为超像素点在CIELAB空间内的特征向量。相比文献[14]中BL的特征选择方式,本文的方法更能兼顾超像素点内的结构信息和细节,使分类的结果更优。
使用新的颜色特征提取方法和原始的特征提取方法,基于本文算法模型得出的实验结果对比如图6。

图6 颜色特征提取方式不同的结果
2.2.2 纹理特征提取
考虑到显著性物体和背景可能在颜色上相似而存在着纹理上的区别,算法中添加了纹理特征局部二值模式(Local Binary Mode, LBP)用于分类。相较于BL算法中使用的基本的LBP算子,本文算法选用了旋转不变的LBP算子,这样的方式对于图像的旋转表现得更为鲁棒。对每个像素点取其圆形邻域,不断旋转该圆形邻域得到一系列初始定义的LBP值,取最小值作为该邻域的LBP值。将每个超像素内的所有像素点的LBP值赋予0~58的数值;然后统计超像素内的各个像素点的LBP值,这样就可以得到一个59维的特征向量。
对仅采用颜色算子、采用普通LBP算子和采用旋转不变的LBP算子进行对比实验。可以看出当图像具有显著性物体和背景颜色近似,但纹理有差别时,使用旋转不变的LBP算子显然能得到更优的结果。

图7 LBP算子对比实验结果
2.3 Adaboost
考虑到对于不同的特征使用不同核函数的支持向量机(Support Vector Machine, SVM)能使分类的结果更为准确[28],本文算法采用不同特征和不同核的SVM作为弱分类器,然后采用Adaboost的方法训练得到强分类器。文中采用Nf=Nfeature×Nkernel种不同的标准SVM分类器,其中Nfeature是特征的数量,Nkernal是核函数的数量,本文中采用4种不同的核函数:Linear、Polynomial、径向基函数(Radial Basis Function, RBF)和Sigmoid。Nf种标准SVM线性组合后的决策函数如式(9)所示:
(9)

(10)

(11)
为了计算系数βj,采用了Adaboost的方法。J表示增强过程的迭代次数。学习的过程如下:
步骤1 将样本集中每个超像素si的权重初始化为同一个值w0(si)=1/P(i=1,2,…,P),同时为每一个弱分类器设定一组目标函数{zn(s),n=1,2,…,Nf};
步骤2 用弱分类器对样本进行学习,并计算错误率{εn},找到最小的错误率εj和对应的弱分类器目标函数zj(s),根据式(12)计算对应弱分类器的结合系数:

(12)
步骤3 根据式(13)来更新样本权重,并跳转回步骤2进行下一次的迭代直至完成J次迭代:

(13)
J次迭代之后, 即得到了J组βj和zj(s)的值,生成了一个强分类器。用强分类器对所有超像素进行分类得到超像素级别的灰度图,并生成像素级别的显著图。对该显著图进行图割平滑:采用最大流分割算法[29]来得到显著图的二值分割图,加在原显著图上作为最终的显著图。
3 实验结果
将算法在数据集ASD和SED1上进行实验验证。ASD数据集是来自于MASR数据集的1 000张图片,其中多为单一目标且背景比较简单的图像。而SED1数据集中有包含单个目标背景较复杂的100张图片,规模小但是难度比较大。本文采用定量测评的方式,按照[0,255]的所有阈值将显著图进行二值化,计算每个阈值下的平均准确率值和召回率值, 从而得到准确率-召回率曲线和曲线下面积(Area Under Curve, AUC)值。将本文算法(Ours)的结果和其他8种模型,即BL,BSCA (Background Single Cellular Automata)[19]、FT(Frequency-Tuned algorithm)[30]、GC(Global Contrast method)[15]、HC(Histogram Contrast method)[15]、LC方法[31]、RC(Region Contrast method)[15]、SR(Spectral Residual approach)[32]得到的显著性结果进行比较。如图8所示。
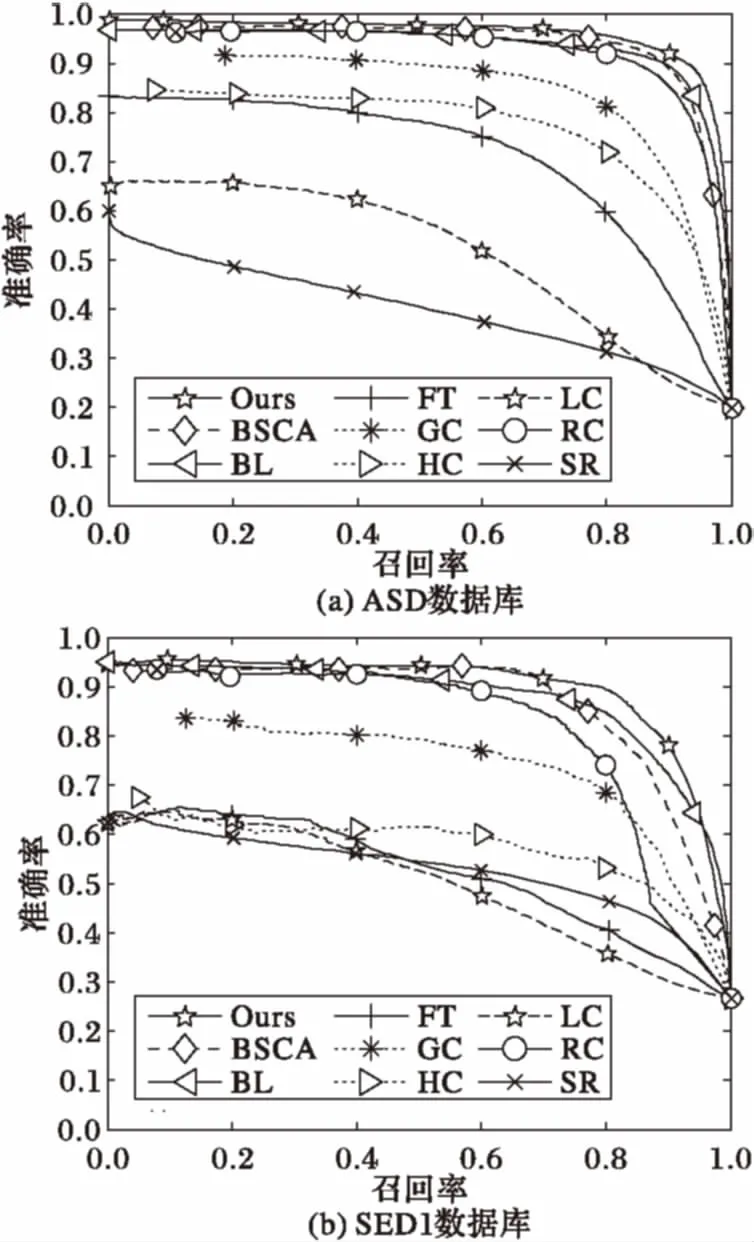
图8 准确率-召回率曲线
从图8(b)中可以看出,本文的模型在准确率-召回率曲线上有很好的表现。如表1所示,通过计算8种不同显著性检测方法的AUC值可以看出对于结构和背景比较简单或者复杂的图像,本文算法都能取得很好的检测效果。
单独采用自底向上的显著性检测模型时间效率都较高但是检测效果较差,如果采用自底向上模型结合自顶向下模型的算法则会耗时更多效果更好。本文中采用的由底至上模型和优化策略都采用了较为高效的算法,力求快速建立可靠参考,而超像素分割和学习的过程则计算开销较大。由于BL算法中采用多尺度显著图融合,本文的算法效率更高。使用配置为i7-6700,3.40 GHz,内存为8 GB的CPU的PC机上进行实验,部分算法平均运行时间如表2所示。

表1 8种方法在ASD和SED1数据库上的AUC测评值

表2 各种方法的运行时间和实现语言
为了进一步展示算法结果的改进,本文还将最终显著图与其他几种算法的显著图进行对比,对比的结果如图9。从图9中可以看出,本文的方法在全局上有很好的效果,得到的显著图的轮廓最接近真值,而且细节部分也比较清晰,具有较为分明的前景和背景区分,能够很好地反映一幅图像的显著性物体。本文的算法能克服原有的基于学习的显著性检测模型的不足,从主观图像和客观评价上显示出本文算法具有一定的优越性。
4 结语
本文中提出了一种改进的基于引导的Boosting算法来构建显著性检测模型。针对基于各种先验的检测模型建立的粗选样本图,对其优化加强来得到引导样本图,为原图建立参考用于学习。本文中还采用了新的特征提取方式,使训练效果得到提升。根据AdaBoost算法训练强分类器能够整合不同的特征和不同的核,避免了使用单一核对不同特征进行学习时的局限性。从原始图像到最终的显著图,本文建立了一种自生成参考的学习模型。粗选样本的优化解决了Boosting时样本选择不纯净带来的误识别,而新的特征选择方式也能更准确地体现出正负样本的区别以提升学习的效果。本文算法的最终结果既具有完善的全局形状又具有准确的局部细节信息,且很接近于真值。在两个数据库上的实验验证了本文算法有一定的优越性。
文中还存在一些待解决的问题,例如对于多目标的显著性检测效果有待提升,对于全背景(无显著性目标)的图像的处理也需要深入研究。

图9 本文算法与8种现有算法的显著图对比
References)
[1] HAN J, NGAN K N, LI M, et al. Unsupervised extraction of visual attention objects in color images [J]. IEEE Transactions on Circuits & Systems for Video Technology, 2006, 16(1): 141-145.
[2] KO B C, NAM J Y. Object-of-interest image segmentation based on human attention and semantic region clustering [J]. Journal of the Optical Society of America A, Optics, Image Science, and Vision , 2006, 23(10): 2462-2470.
[3] RUTISHAUSER U, WALTHER D, KOCH C, et al. Is bottom-up attention useful for object recognition? [C]// Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2004: 37-44.
[4] CHEN T, CHENG M M, TAN P, et al. Sketch2Photo: Internet image montage [J]. ACM Transactions on Graphics, 2009, 28(5): Article No. 124.
[5] CHRISTOPOULOS C, SKODRAS A, EBRAHIMI T. The JPEG2000 still image coding system: an overview [J]. IEEE Transactions on Consumer Electronics, 2000, 46(4): 1103-1127.
[6] ZHANG G, CHENG M, HU S, et al. A shape-preserving approach to image resizing [J]. Computer Graphics Forum, 2009, 28(7): 1897-1906.
[7] HOU X, ZHANG L. Saliency detection: a spectral residual approach [C]// Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2007: 18-23.
[8] JIANG H, WANG J, YUAN Z, et al. Automatic salient object segmentation based on context and shape prior [EB/OL]. [2016- 12- 21]. http://www.bmva.org/bmvc/2011/proceedings/paper110/paper110.pdf.
[9] KLEIN D A, FRINTROP S. Center-surround divergence of feature statistics for salient object detection [C]// Proceedings of the 2011 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2011: 2214-2219.
[10] TONG N, LU H, ZHANG Y, et al. Salient object detection via global and local cues [J]. Pattern Recognition, 2015, 48(10): 3258-3267.
[11] MARCHESOTTI L, CIFARELLI C, CSURKA G. A framework for visual saliency detection with applications to image thumbnailing [C]// Proceedings of the 2009 IEEE 12th International Conference on Computer Vision. Piscataway, NJ: IEEE, 2009: 2232-2239.
[12] NG A Y, JORDAN M I, WEISS Y. On spectral clustering: analysis and an algorithm [EB/OL]. [2017- 01- 12]. http://www.csie.ntu.edu.tw/~mhyang/course/u0030/papers/Ng%20Weiss%20Jordan%20Spectral%20Clustering.pdf.
[13] 桑农,李正龙,张天序.人类视觉注意机制在目标检测中的应用[J].红外与激光工程,2004,33(1):38-42.(SANG N, LI Z L, ZHANG T X. Application of human visual attention mechanisms in object detection [J]. Infrared and Laser Engineering, 2004, 33(1): 38-42.)
[14] TONG N, LU H, XIANG R, et al. Salient object detection via bootstrap learning [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 1884-1892.
[15] CHENG M M, ZHANG G X, MITRA N J, et al. Global contrast based salient region detection [C]// Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2011: 409-416.
[16] CHENG M M, WARRELL J, LIN W Y, et al. Efficient salient region detection with soft image abstraction [C]// Proceedings of the 2013 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2013: 1529-1536.
[17] FENG J. Salient object detection for searched web images via global saliency [C]// Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2012: 3194-3201.
[18] HE K, SUN J, TANG X. Single image haze removal using dark channel prior [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(12): 2341-2353.
[19] QIN Y, LU H, XU Y, et al. Saliency detection via cellular automata [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2015: 110-119.
[20] WEI Y, WEN F, ZHU W, et al. Geodesic saliency using background priors [C]// European Conference on Computer Vision, LNCS 7574. Berlin: Springer, 2012: 29-42.
[21] SUN J, LU H, LI S. Saliency detection based on integration of boundary and soft-segmentation [C]// Proceedings of the 2012 19th IEEE International Conference on Image Processing. Piscataway, NJ: IEEE, 2012: 1085-1088.
[22] JIANG H, WANG J, YUAN Z, et al. Salient object detection: a discriminative regional feature integration approach [C]// Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2013: 2083-2090.
[23] ZHU W, LIANG S, WEI Y, et al. Saliency optimization from robust background detection [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2014: 2814-2821.
[24] YANG F, LU H, CHEN Y W. Human tracking by multiple kernel boosting with locality affinity constraints [C]// Proceedings of the 2010 10th Asian Conference on Computer Vision. Berlin: Springer. 2010: 39-50.
[25] 汪成,陈文兵.基于SLIC超像素分割显著区域检测方法的研究[J].南京邮电大学学报(自然科学版),2016,36(1):89-93.(WANG C, CHEN W B, et al. Salient region detection method based on SLIC superpixel segmentation [J]. Journal of Nanjing University of Posts and Telecommunications (Natural Science Edition), 2016, 36(1): 89-93.)
[26] WOLFRAM S. Statistical mechanics of cellular automata [J]. Reviews of Modern Physics, 1983, 55(3): 601-644.
[27] YILDIRIM G, SÜSSTRUNK S. FASA: fast, accurate, and size-aware salient object detection [C]// Asian Conference on Computer Vision, LNCS 9005. Berlin: Springer, 2014: 514-528.
[28] BACH F R, LANCKRIET G R G, JORDAN M I. Multiple kernel learning, conic duality, and the SMO algorithm [C]// Proceedings of the 21st International Conference on Machine Learning. New York: ACM, 2004: 6.
[29] BOYKOV Y, KOLMOGOROV V. An experimental comparison of min-cut/max-flow algorithms for energy minimization in vision [C]// Proceedings of the 3rd International Workshop on Energy Minimization Methods in Computer Vision and Pattern Recognition. London: Springer, 2001: 359-374.
[30] ACHANTA R, HEMAMI S, ESTRADA F, et al. Frequency-tuned salient region detection [C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2009: 1597-1604.
[31] ZHAI Y, SHAH M. Visual attention detection in video sequences using spatiotemporal cues [C]// Proceedings of the 14th ACM International Conference on Multimedia. New York: ACM, 2006: 815-824.
[32] HOU X, ZHANG L. Saliency detection: a spectral residual approach [C]// Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2007: 1-8.
SaliencydetectionbasedonguidedBoostingmethod
YE Zitong, ZOU Lian*, YAN Jia, FAN Ci’en
(ElectronicInformationSchool,WuhanUniversity,WuhanHubei430072,China)
Aiming at the problem of impure simplicity and too simple feature extraction of training samples in the existing saliency detection model based on guided learning, an improved algorithm based on Boosting was proposed to detect saliency, which improve the accuracy of the training sample set and improve the way of feature extraction to achieve the improvement of learning effect. Firstly, the coarse sample map was generated from the bottom-up model for saliency detection, and the coarse sample map was quickly and effectively optimized by the cellular automata to establish the reliable Boosting samples. The training samples were set up to mark the original images. Then, the color and texture features were extracted from the training set. Finally, Support Vector Machine (SVM) weak classifiers with different feature and different kernel were used to generate a strong classifier based on Boosting, and the foreground and background of each pixel of the image was classified, and a saliency map was obtained. On the ASD database and the SED1 database, the experimental results show that the proposed algorithm can produce complete clear and salient maps for complex and simple images, with good AUC (Area Under Curve) evaluation value for accuracy-recall curve. Because of its accuracy, the proposed algorithm can be applied in pre-processing stage of computer vision.
saliency detection; boosting; bottom-up model; coarse reference optimization; color feature extraction
2017- 03- 15;
2017- 05- 25。
叶子童(1993—),女,湖北襄阳人,硕士研究生,主要研究方向:显著性检测、图像检索; 邹炼(1975—),男,湖北武汉人,副教授,博士,主要研究方向:图像检索、语音识别; 颜佳(1984—),男,湖北天门人,讲师,博士,主要研究方向:图像质量评估、显著性检测; 范赐恩(1975—),女,浙江慈溪人,副教授,博士,主要研究方向:图像修复、图像超分辨率重建。
1001- 9081(2017)09- 2652- 07
10.11772/j.issn.1001- 9081.2017.09.2652
TP391.4
A
YEZitong, born in 1993, M. S. candidate. Her research interests include saliency detection, image retrieval.
ZOULian, born in 1975, Ph. D., associate professor. His research interests include image retrieval, speech recognition.
YANJIA, born in 1984, Ph. D., lecturer. His research interests include image quality assessment, saliency detection.
FANCi’en, born in 1975, Ph. D., associate professor. Her research interests include image restoration, image super-resolution reconstruction.
