基于近红外光谱的食用植物油中反式脂肪酸含量快速定量检测及模型优化研究
2017-11-06莫欣欣刘木华叶振南
莫欣欣 孙 通* 刘木华 叶振南
1(江西农业大学工学院,江西省高校生物光电技术及应用重点实验室, 南昌 330045)2(江西出入境检验检疫局,综合技术中心, 南昌 330038)
基于近红外光谱的食用植物油中反式脂肪酸含量快速定量检测及模型优化研究
莫欣欣1孙 通*1刘木华1叶振南2
1(江西农业大学工学院,江西省高校生物光电技术及应用重点实验室, 南昌 330045)2(江西出入境检验检疫局,综合技术中心, 南昌 330038)
利用近红外光谱技术对食用植物油中反式脂肪酸 (Trans fatty acids, TFA)含量进行快速定量检测,并通过波段选择、预处理方法、变量筛选及建模方法对TFA含量预测模型进行优化。采用Antaris Ⅱ傅里叶变换近红外光谱仪在4000~10000 cm光谱范围采集98个食用植物油样本的近红外透射光谱,然后采用气相色谱法测定TFA的真实含量。首先,对样本原始光谱进行波段、预处理方法优选; 在此基础上,采用竞争自适应重加权法 (Competitive adaptive reweighted sampling, CARS)筛选TFA相关的重要变量,最后应用主成分回归、偏最小二乘和最小二乘支持向量机方法分别建立食用植物油中TFA含量的预测模型。研究结果表明,近红外光谱技术检测食用植物油中的TFA含量是可行的,优化后的最佳预测模型的校正集和预测集R2分别为0.992和0.989,RMSEC和RMSEP分别为0.071%和0.075%。最佳预测模型所用的变量仅26个,占全波段变量的0.854%。此外,与全波段偏最小二乘预测模型相比,其预测集R2由0.904上升为0.989,RMSEP由0.230%下降为0.075%。由此表明,模型优化非常必要,CARS能有效筛选TFA相关的重要变量,极大减少建模变量数,从而简化预测模型,并较大提高预测模型的精度和稳定性。
食用植物油; 近红外光谱; 模型优化; 竞争自适应重加权法变量筛选; 定量检测
2017-05-25收稿; 2017-08-15接受
本文系国家自然科学基金(No.31401278)、江西省自然科学基金(No.20151BAB204025)和江西省教育厅科学研究基金(No.GJJ13254)项目资助
* E-mail: suntong980@163.com.
1 引 言
反式脂肪酸 (Trans fatty acids, TFA) 是具有反式结构双键的一类不饱和脂肪酸的总称,主要来自采用氢化加工工艺后的植物油。由于氢化植物油具有较好的稳定性、口感及加工性能,被广泛应用在食品工业中。近年来的诸多研究表明,TFA不是维持人体生理功能所需要的氨基酸,并且TFA能增加患心血管疾病、糖尿病的危险,导致必需氨基酸缺乏和抑制婴幼儿生长发育等[1]。丹麦、美国、加拿大、巴西、日本和韩国等国家相继出台相关法规控制食品中的TFA含量。我国的国标GB 28050-2011[2]也规定食品中TFA含量。因此,迫切需要建立快速、高效的食品中TFA检测方法。
目前,对于油脂中TFA的检测主要采用色谱法[3,4]、红外光谱法[5~7]、毛细管电泳法[8,9]等。但上述方法前处理过程复杂,分析时间长,且需要破坏样本。近红外光谱技术是一种绿色、快速、无损的检测技术,已应用于食用油掺假、种类鉴别、脂肪酸测定等[10~12]。Li等[13]利用傅里叶变换近红外光谱 (Fourier transformation near infrared spectroscopy, FT-NIR)技术对食用油中TFA含量进行了检测研究,在温控模块 (68±1℃)中采集样本在4000~10000 cm的FT-NIR光谱, 建立食用油中TFA含量的偏最小二乘 (Partial least square, PLS)回归模型,并取得了较好的结果。Azizian等[14]运用FT-NIR对脂肪和植物油中的TFA含量进行定量检测研究,根据特征波段建立TFA的PLS模型,其模型决定系数为0.74~0.93,交互验证均方根误差 (Root mean square error of cross validation, RMSECV)为0.35%~1.13%。Kim等[15]运用近红外光谱技术对谷物食品中TFA含量进行了检测研究, 采用700~2498 nm光谱波段建立TFA的PLS模型,其最优模型决定系数R2为0.97,均方根误差为0.70%。安雪松等[16]对食品 (蛋糕、面包和饼干)中TFA含量进行了定性检测研究,采集近红外漫反射光谱后分别建立含TFA含量的偏最小二乘判别、支持向量机、簇类独立软模式和K-最邻近法模型。结果表明, 以使用与TFA相关波段,结合标准化和二阶导数预处理所建立的偏最小二乘判别识别模型效果最佳,校正集和验证集识别准确率分别达到了96.4%和88.0%。目前,对于TFA的近红外检测研究仅有少数报道,且均采用全波段或部分波段建模,未进行变量筛选等优化,建模所用的变量数较多,预测模型的稳定性和精度受到限制,难以应用于实际样品分析。
竞争自适应重加权法 (Competitive adaptive reweighted sampling, CARS)[17]是最近提出的一种新变量选择方法,可以有效筛选重要的相关变量组合,剔除冗余或噪声变量,从而简化预测模型,提高预测模型的预测精度和稳定性[18]。
为保证预测模型的可靠性和适应性,本研究收集市场上常见的各类及不同品牌的食用植物油样本,利用近红外光谱技术结合CARS等方法对食用植物油中TFA含量进行快速定量检测,并优化其预测模型。首先通过样本光谱分析TFA可能存在的特征波段,并根据建模结果确定较优的波段范围和预处理方法; 在此基础上,采用CARS方法筛选与TFA相关的重要变量组合,极大减少建模所用的变量数; 最后,应用不同建模方法建立TFA含量的预测模型,根据建模结果确定最优的建模方法,最终实现预测模型的整体优化,从而提高预测模型的预测精度和稳定性,以应用于实际样品的分析检测。
2 实验部分
2.1实验仪器
Antaris Ⅱ傅里叶变换近红外光谱仪 (美国Thermo Scientific公司), 配备InGaAs检测器,波数范围为4000~10000 cm,光源为25 W卤素灯。石英比色皿光程为2 mm。GC-2010气相色谱仪 (日本Shimadzu公司), 配有FID检测器和GC SOLUTION数据处理工作站。
2.2实验材料与试剂
本实验中,98个食用植物油样本均购于本地大型超市,种类包含菜籽油、玉米油、葵花籽油、花生油、大豆油、山茶油、稻米油、橄榄油以及调和油,涉及金龙鱼、长康、鲁花、福临门、道道全、西王等39个品牌。为充分考虑校正集样本的代表性,将98个食用植物油样本采用含量梯度法随机分为校正集和预测集,共得到校正集样本74个,预测集样本24个。
顺、反异构的 C18∶1(46902-U, 46903), C18∶2(47791)和 C18∶3(47792)脂肪酸甲酯混合标准品(美国Sigma 公司); KOH-甲醇溶液 (2 mol/L); 异辛烷 (C8H18, 色谱纯); 其它试剂为分析纯。
2.3近红外光谱数据采集
将98个食用植物油样本分别注入2 mm比色皿中, 依次置于Thermo Antaris Ⅱ的透射采集附件中,并在室温下进行近红外光谱采集。采用2 mm空比色皿作为参比。光谱采集软件为RESULT Integration (美国Thermo Scientific公司), 光谱采集参数设置如下:扫描次数为64次, 分辨率为4.0 cm。
2.4反式脂肪酸含量测定
食用植物油中TFA含量参照GB 5009.257-2016方法进行测定。色谱条件及参数如下:选用HP88毛细管色谱柱(100 m×0.25 mm×0.25 μm); 进样口温度240℃; 检测器温度300℃; 色谱柱温度:程序升温,120℃以5℃/min升至170℃,保持10 min; 以2℃/min升至185℃,保持8 min; 以3℃/min升至240℃,保持10 min。载气:氮气,压力360.4 kPa,流速1.99 mL/min; 氢气流速:50 mL/min; 空气流速:500 mL/min; 分流比 20∶1。每个样本平行测定两次,取平均值作为测定结果。
2.5数据处理
竞争自适应重加权法 (CARS)是最近提出的一种变量选择方法,该方法模拟达尔文进化理论“适者生存”进行变量筛选,通过自适应加权采样技术筛选PLS模型中回归系数绝对值大的变量,去除权重值较小的变量,并通过交互验证计算出交互验证均方根误差RMSECV,根据RMSECV最小原则确定最优的变量组合[17]。此算法能够在一定程度上克服变量筛选过程中的组合爆炸问题,筛选出优化的变量子集,提高模型的预测能力和降低预测方差。
本研究中,首先分析TFA在近红外谱区可能存在的特征波段,然后根据建模结果依次确定最优的波段范围及光谱预处理方法。在此基础上,采用CARS进行变量筛选,并应用主成分回归 (Principal component regression, PCR)、PLS和最小二乘支持向量机 (Least square support vector machine, LS-SVM)方法分别建立食用植物油中TFA的预测模型,比较预测模型性能以确定最优的建模方法。在CARS分析中,蒙特卡罗 (Monte carlo, MC)取样次数设置为50次,PLS最大主成分数为20,所选择的变量子集采用5折交互验证建模。
数据处理分析在Unscrambler X10.1 (CAMO, Norway)以及MatlabR2014a (The Math Works,USA)中进行。通过决定系数 (R2)、校正均方根误差 (Root mean square error of calibration, RMSEC)、RMSECV和预测均方根误差 (Root mean square error of prediction, RMSEP)对模型进行评价。RMSEC、RMSECV及RMSEP由公式(1)计算。
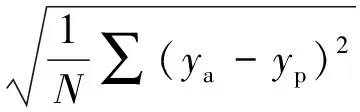
式中,ya和yp为样本的真实值和预测值,N为样品数量。
3 结果与讨论
3.1气相色谱分析反式脂肪酸含量
本研究中,测定的食用植物油样本TFA含量为反式十八碳一烯酸、反式十八碳二烯酸和反式十八碳三烯酸之和。图1为脂肪酸甲酯标准品溶液的气相色谱图,其中十八碳一烯酸甲酯为单标,十八碳二烯酸甲酯和十八碳三烯酸甲酯为混标。由图1可知,脂肪酸甲酯标准品中的顺式和反式均得到了良好的分离,满足检测要求。图2为菜籽油样本气相色谱图的局部放大图,可以看出,顺反脂肪酸均得到了良好的分离。
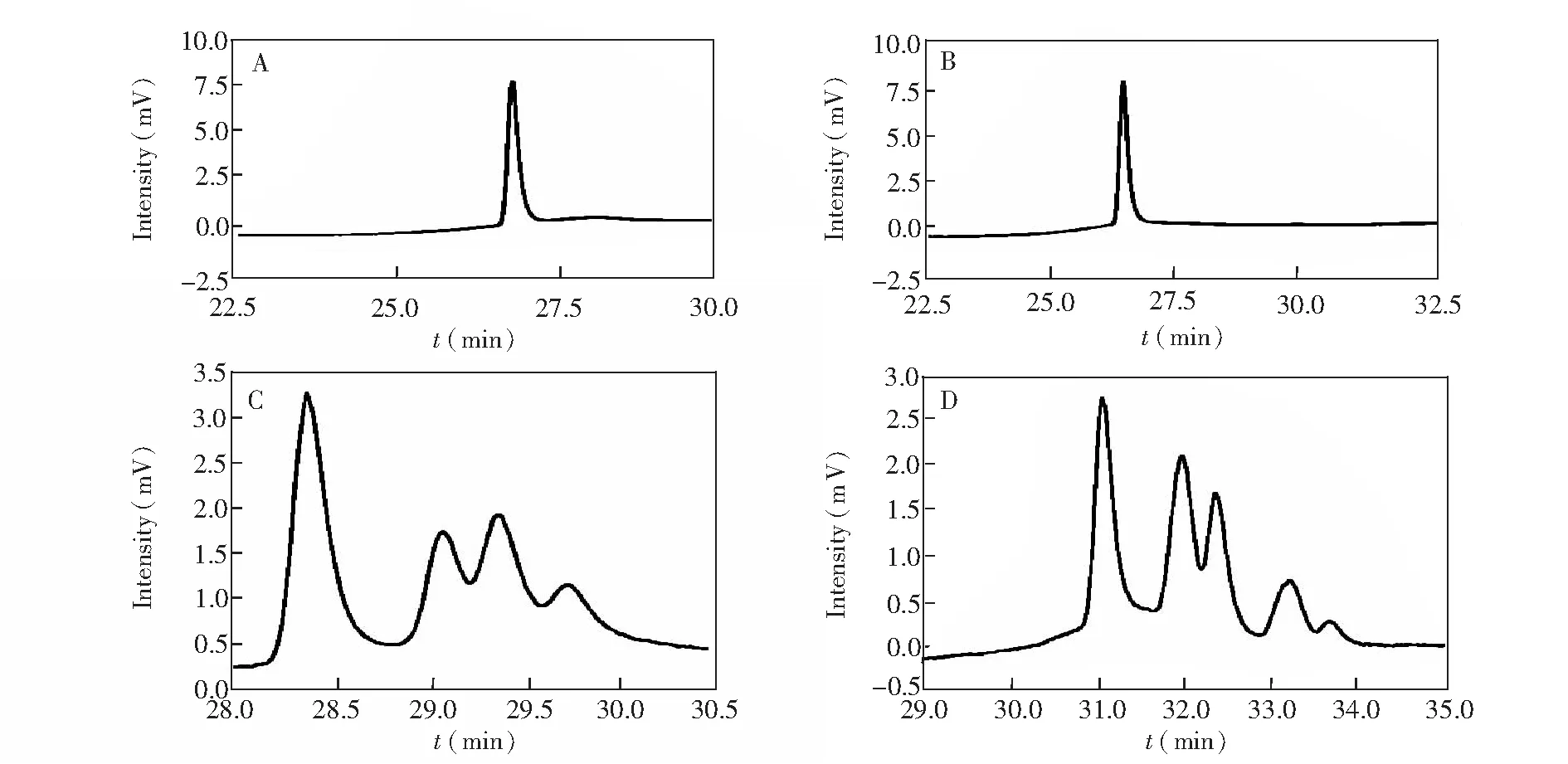
图1 脂肪酸甲酯标准品溶液气相色谱图Fig.1 Gas chromatograms of fatty acid methyl ester standard solution(A):顺式十八碳一烯酸甲酯; (B):反式十八碳一烯酸甲酯; (C):十八碳二烯酸甲酯; (D):十八碳三烯酸甲酯。(A): cis-Vaccenic acid methyl ester; (B): trans-Vaccenic acid methyl ester; (C): Linoleic acid methyl ester; (D): α-Linolenic acid methyl ester
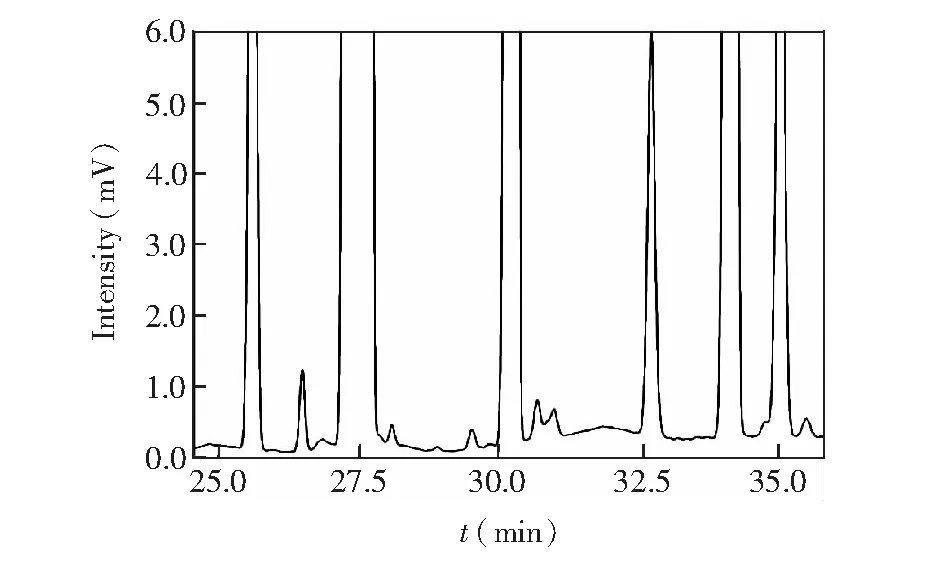
图2 菜籽油样本气相色谱图局部放大图Fig.2 A partial magnification of gas chromatogram of rapeseed oil sample
不同品种的食用植物油TFA的具体含量见表1。由表1可知,菜籽油、玉米油、葵花籽油、花生油、大豆油、山茶油、稻米油、橄榄油和调和油的TFA含量范围和平均值分别为0.019%~1.301%,0.642%~2.280%,0.192%~0.968%,0.053%~0.510%,0.047%~1.538%,0.100%~2.662%,1.048%~3.880%,0.007%~0.051%,0.437%~1.263%和0.667%,1.546%,0.539%,0.205%,0.843%,1.122%,2.203%,0.018%,0.777%。 综上可知, 橄榄油和花生油中TFA含量较低,而玉米油、山茶油和稻米油含量偏高,其中最高含量分别达到了2.270%、2.662%和3.880%。
3.2近红外光谱分析
98个食用植物油样本的近红外原始光谱如图3所示。在近红外光谱分析中,吸光度>3则表明光谱信噪比低。因此,在数据处理时剔除原始光谱中4255~4384 cm波数范围内的数据。由于TFA中含有大量化学键,其在近红外谱区有较强的吸收信息。此外,由于反式双键的存在,使得TFA在分子结构上与饱和脂肪酸、顺式不饱和脂肪酸等存在不同。分子结构的变化会在吸收光谱中表现出来,有相关研究表明,油脂中TFA和顺式脂肪酸的吸收变化虽然出现在同一倍频和合频位置,但吸收强度不同[16,19]。
表1 食用植物油样本的TFA含量
Table 1 Content of trans fatty acids (TFA) in edible vegetable oil samples
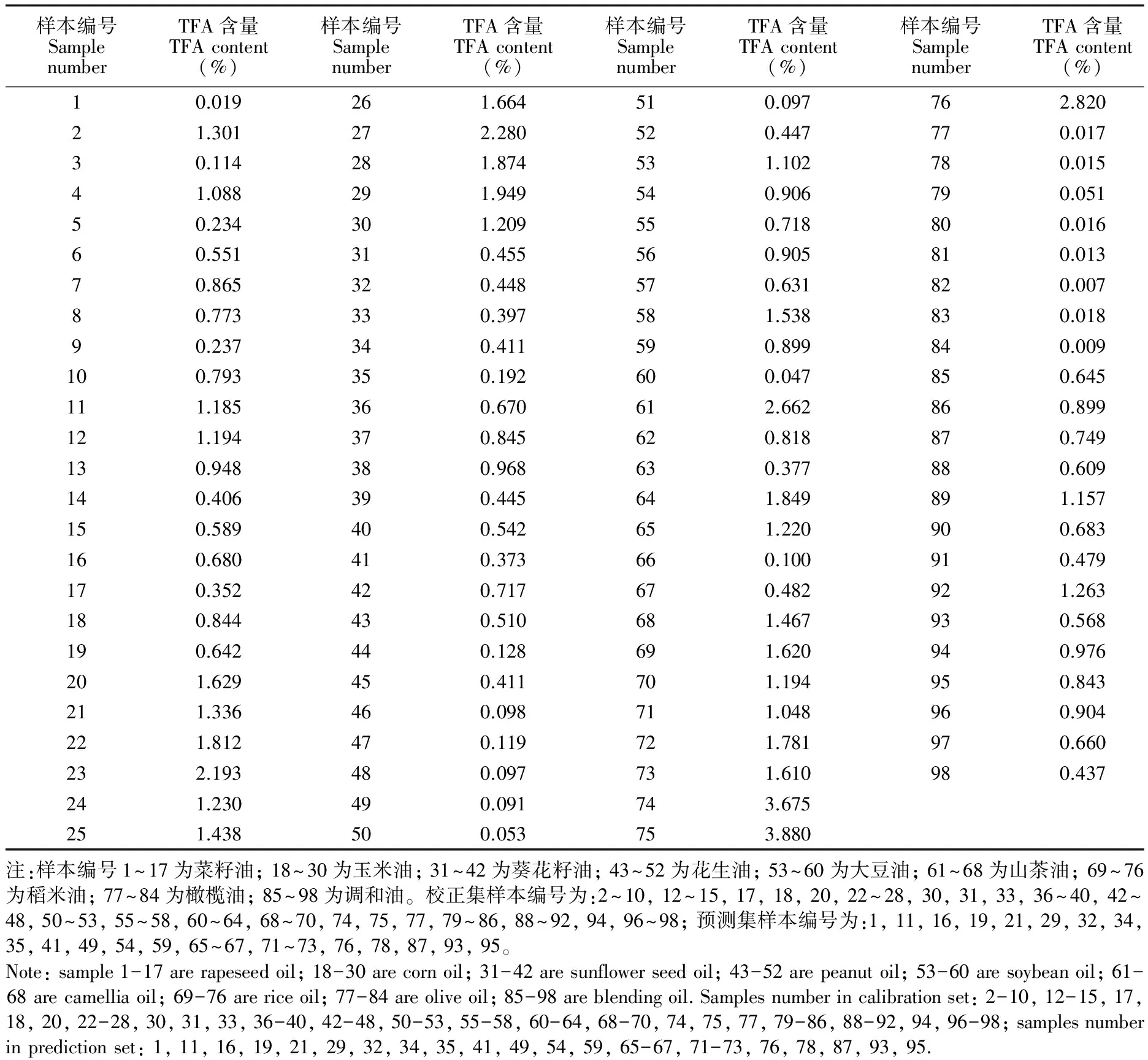
样本编号SamplenumberTFA含量TFAcontent(%)样本编号SamplenumberTFA含量TFAcontent(%)样本编号SamplenumberTFA含量TFAcontent(%)样本编号SamplenumberTFA含量TFAcontent(%)10.019261.664510.097762.82021.301272.280520.447770.01730.114281.874531.102780.01541.088291.949540.906790.05150.234301.209550.718800.01660.551310.455560.905810.01370.865320.448570.631820.00780.773330.397581.538830.01890.237340.411590.899840.009100.793350.192600.047850.645111.185360.670612.662860.899121.194370.845620.818870.749130.948380.968630.377880.609140.406390.445641.849891.157150.589400.542651.220900.683160.680410.373660.100910.479170.352420.717670.482921.263180.844430.510681.467930.568190.642440.128691.620940.976201.629450.411701.194950.843211.336460.098711.048960.904221.812470.119721.781970.660232.193480.097731.610980.437241.230490.091743.675251.438500.053753.880注:样本编号1~17为菜籽油;18~30为玉米油;31~42为葵花籽油;43~52为花生油;53~60为大豆油;61~68为山茶油;69~76为稻米油;77~84为橄榄油;85~98为调和油。校正集样本编号为:2~10,12~15,17,18,20,22~28,30,31,33,36~40,42~48,50~53,55~58,60~64,68~70,74,75,77,79~86,88~92,94,96~98;预测集样本编号为:1,11,16,19,21,29,32,34,35,41,49,54,59,65~67,71~73,76,78,87,93,95。Note:sample1-17arerapeseedoil;18-30arecornoil;31-42aresunflowerseedoil;43-52arepeanutoil;53-60aresoybeanoil;61-68arecamelliaoil;69-76arericeoil;77-84areoliveoil;85-98areblendingoil.Samplesnumberincalibrationset:2-10,12-15,17,18,20,22-28,30,31,33,36-40,42-48,50-53,55-58,60-64,68-70,74,75,77,79-86,88-92,94,96-98;samplesnumberinpredictionset:1,11,16,19,21,29,32,34,35,41,49,54,59,65-67,71-73,76,78,87,93,95.
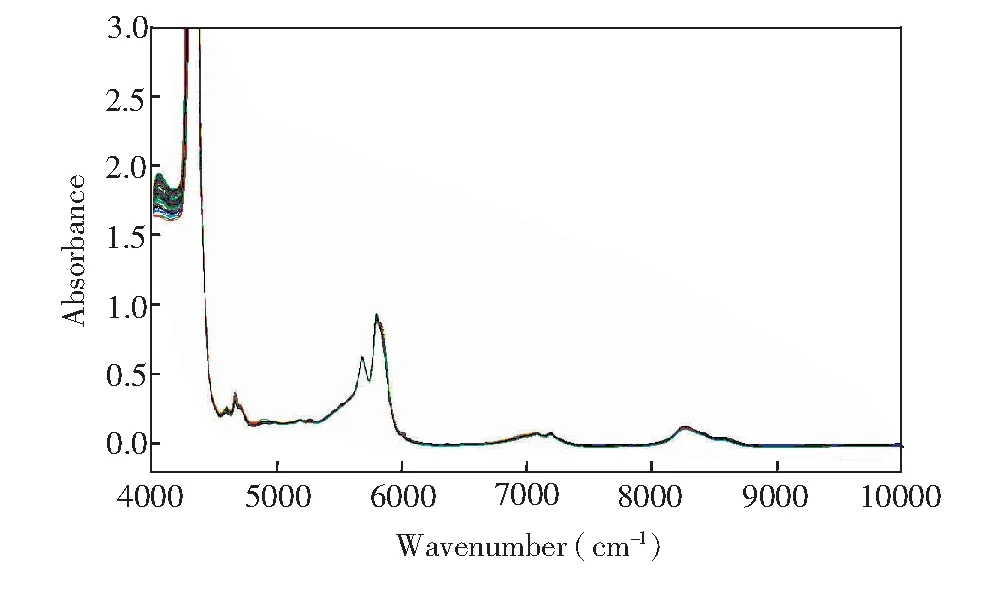
图3 食用植物油样本的近红外原始光谱Fig.3 Near infrared spectra of edible vegetable oil samples
由图3可知,在整个波段范围内,有5处明显的光谱吸收带, 分别约为4000~4200 cm、 4500~ 4800 cm、 5400~6000 cm、 6900~7300 cm及8000~8800 cm波段。这些波段范围可能包含较多的光谱信息,在后续波段初选时应尽量保留。另外,相关研究指出,4263和4329 cm的吸收峰归属于二级倍频合频振动吸收峰,5663和5790 cm处的吸收峰为一级倍频振动吸收峰,8260 cm处的吸收峰为二级倍频振动吸收峰[14~16]。Azizian等[14]提出4547~4794 cm,5423~6013 cm和6974~7290 cm波段为TFA在近红外谱区的特征波段。Kim等[15]指出5347~6097 cm和8000~8695 cm波段范围为键的一级和二级倍频吸收带,4500~4901 cm波段为键的合频吸收带,4651 cm、 4566 cm和5959 cm波数附近为顺式和反式键伸缩振动特征波段等。根据相关报道,以上所列吸收峰均与油脂相关,而脂肪酸是油脂的重要成分。因此,这些吸收峰可能与TFA也相关。根据上述分析,在后续波段初选中,选择了6个波段范围进行优选。6个波段范围分别为B1 (4000~4254 cm, 4385~10000 cm)、 B2 (4000~4254 cm, 4385~6250 cm)、 B3 (4138~4254 cm, 4385~4428 cm, 5508~5963 cm, 7795~8960 cm)、 B4 (4547~4794 cm, 5423~6013 cm, 6975~7290 cm)、 B5(4501~4902 cm, 5346~6098 cm, 7101~7301 cm, 8001~8695 cm)及B6 (4501~4700 cm, 5662~6001 cm, 8263~8279 cm)。为方便叙述,下文中各波段范围均用B1~B6表示 。
3.3预测模型建立及优化
3.3.1波段初选为初步获取TFA较佳的建模波段范围,采用PLS方法在不同波段范围内建立TFA含量的预测模型,其结果见表2。从表2可知,采用B5、B6波段建模时,所用的主成分数最少,校正集和交互验证R2较高且接近,但预测集R2偏低且RMSEC值偏高。采用B1、B2波段建模时,所用的主成分数过多,可能存在过拟合,且交互验证R2偏低以及RMSECV值偏高。对于B3、B4波段,其预测模型所用的主成分数接近,但B3波段的交互验证和预测集R2值低于B4波段的预测模型结果,均方根误差大于B4波段的预测模型结果; 此外,B4波段所建立的预测模型的校正集、交互验证和预测集结果更为接近,模型精度以及稳定性好。综上分析,B4波段为较佳的建模波段,其所建立的预测模型性能较优,后续的模型均在此基础上建立。
表2 不同波数范围下TFA的PLS建模结果
Table 2 Partial least square (PLS) modeling results of TFA with different wave number ranges
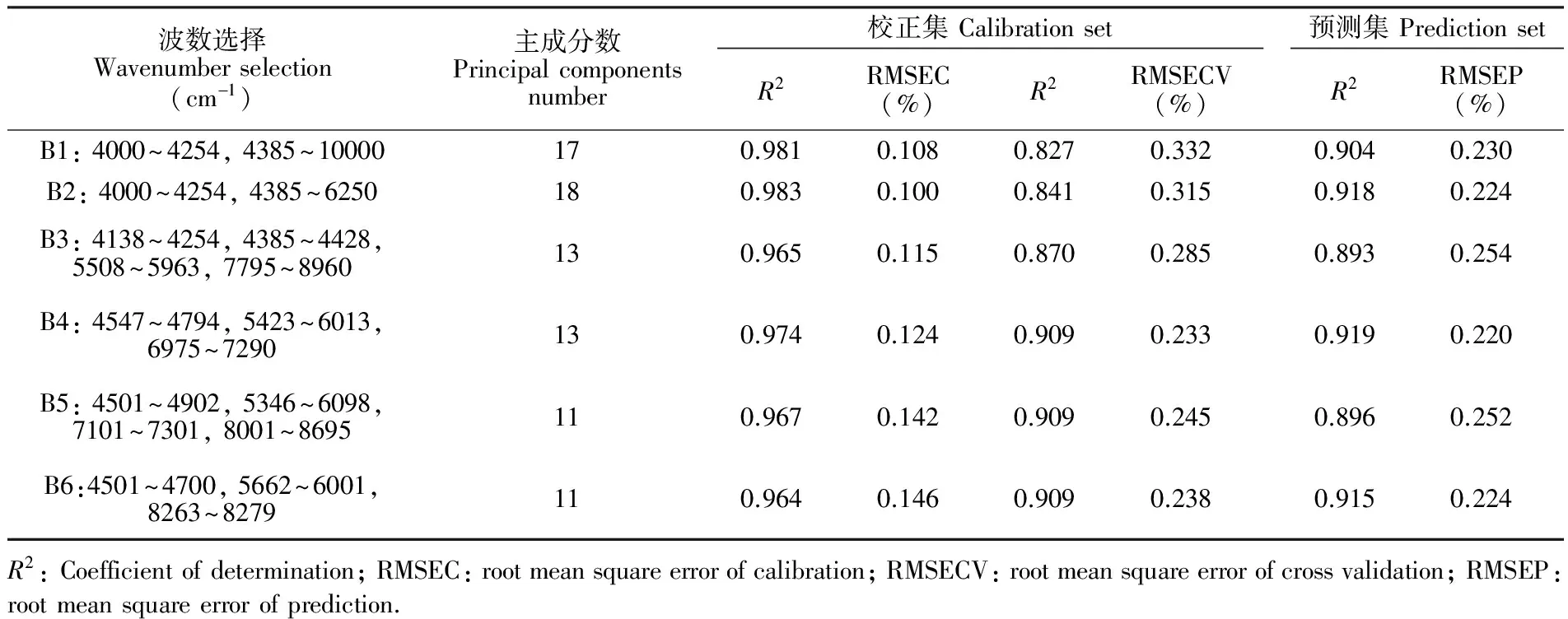
波数选择Wavenumberselection(cm-1)主成分数Principalcomponentsnumber校正集CalibrationsetR2RMSEC(%)R2RMSECV(%)预测集PredictionsetR2RMSEP(%)B1:4000~4254,4385~10000170.9810.1080.8270.3320.9040.230B2:4000~4254,4385~6250180.9830.1000.8410.3150.9180.224B3:4138~4254,4385~4428,5508~5963,7795~8960130.9650.1150.8700.2850.8930.254B4:4547~4794,5423~6013,6975~7290130.9740.1240.9090.2330.9190.220B5:4501~4902,5346~6098,7101~7301,8001~8695110.9670.1420.9090.2450.8960.252B6:4501~4700,5662~6001,8263~8279110.9640.1460.9090.2380.9150.224R2:Coefficientofdetermination;RMSEC:rootmeansquareerrorofcalibration;RMSECV:rootmeansquareerrorofcrossvalidation;RMSEP:rootmeansquareerrorofprediction.
3.3.2预处理方法在B4波段范围,分别采用多元散射校正 (Multiplicative scatter correction, MSC)、标准正态变量变换 (Standard normal variable transformation, SNV)、归一化函数 (Normalization)和基线校正 (Baseline correction)方法进行光谱预处理,再应用PLS方法建立食用植物油中TFA含量的预测模型,其结果见表3。由表3可知,经光谱预处理后,预测模型所用的主成分数较原始光谱预测模型均有降低,说明预测模型稳定性得到了提高。相比于其它3种预处理方法,经MSC预处理后建立的预测模型的校正集和预测集R2均较高,且均方根误差最小,优于其它预处理方法。究其原因,可能是MSC方法能够有效消除散射影响,增强了与TFA成分相关的光谱信息。此外,与原始光谱的预测模型相比,MSC预处理后建立的预测模型的R2和均方根误差均较为接近,但其所用的主成分数少,预测模型稳定性好。综合考虑,选择MSC方法为最佳预处理方法。
表3 不同预处理方法下TFA的PLS模型结果
Table 3 PLS model results of TFA with different pretreatment methods
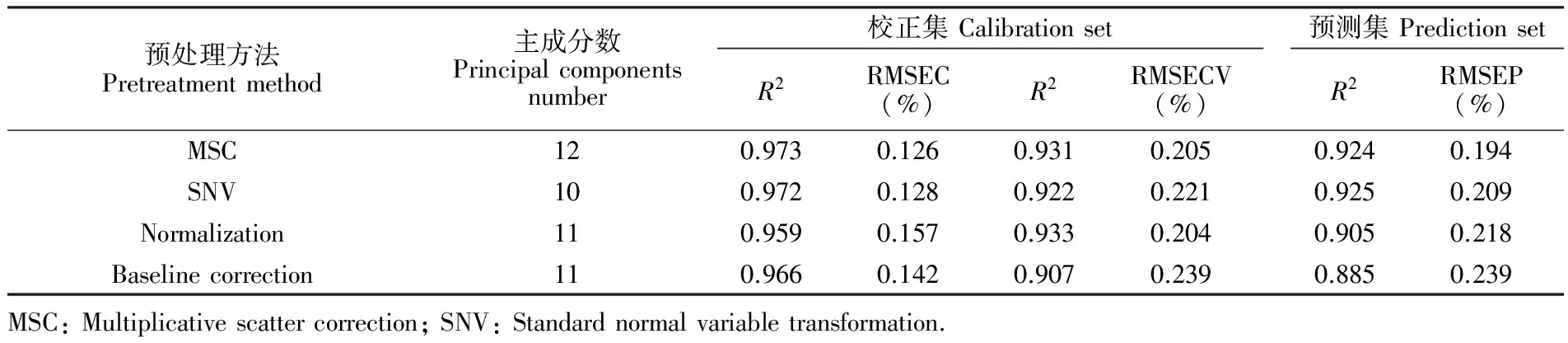
预处理方法Pretreatmentmethod主成分数Principalcomponentsnumber校正集CalibrationsetR2RMSEC(%)R2RMSECV(%)预测集PredictionsetR2RMSEP(%)MSC120.9730.1260.9310.2050.9240.194SNV100.9720.1280.9220.2210.9250.209Normalization110.9590.1570.9330.2040.9050.218Baselinecorrection110.9660.1420.9070.2390.8850.239MSC:Multiplicativescattercorrection;SNV:Standardnormalvariabletransformation.
3.3.3CARS变量筛选为进一步优化预测模型,增加预测模型的稳定性,采用CARS方法对MSC预处理后的B4波段光谱数据进行变量筛选。图4为食用植物油中TFA含量的CARS变量筛选过程。由图4(A)可知,随着MC采样次数的增加,选择的变量数先以指数函数的速率减少, 而后变量减少速率逐渐减慢,体现了变量粗选和精选两个过程。图4B为CARS变量筛选过程中RMSECV的变化曲线。由图4(B)可知,随着MC采样次数的增加,RMSECV值逐渐减小,表明正在剔除与TFA无关或者共线的变量; 当MC采样次数达到28次 (图4C中星号垂线位置)时,RMSECV值最小; 而后,RMSECV值逐渐增大,说明此时有与TFA含量相关的变量被剔除; 而当MC采样次数为30次时,RMSECV值大幅升高,说明此时有与TFA相关的重要变量被剔除,使模型性能大幅降低。图4C为CARS变量筛选过程中各变量回归系数路径的变化趋势,“*”所标注位置为28次MC采样,此时RMSECV值最小。根据RMSECV最小原则,此次采样所获得的变量组合即为CARS变量选择的最优结果。最终,共选择26个与食用植物油中TFA含量相关的特征波数变量。图5为CARS方法优选出的26个波数变量的分布情况。
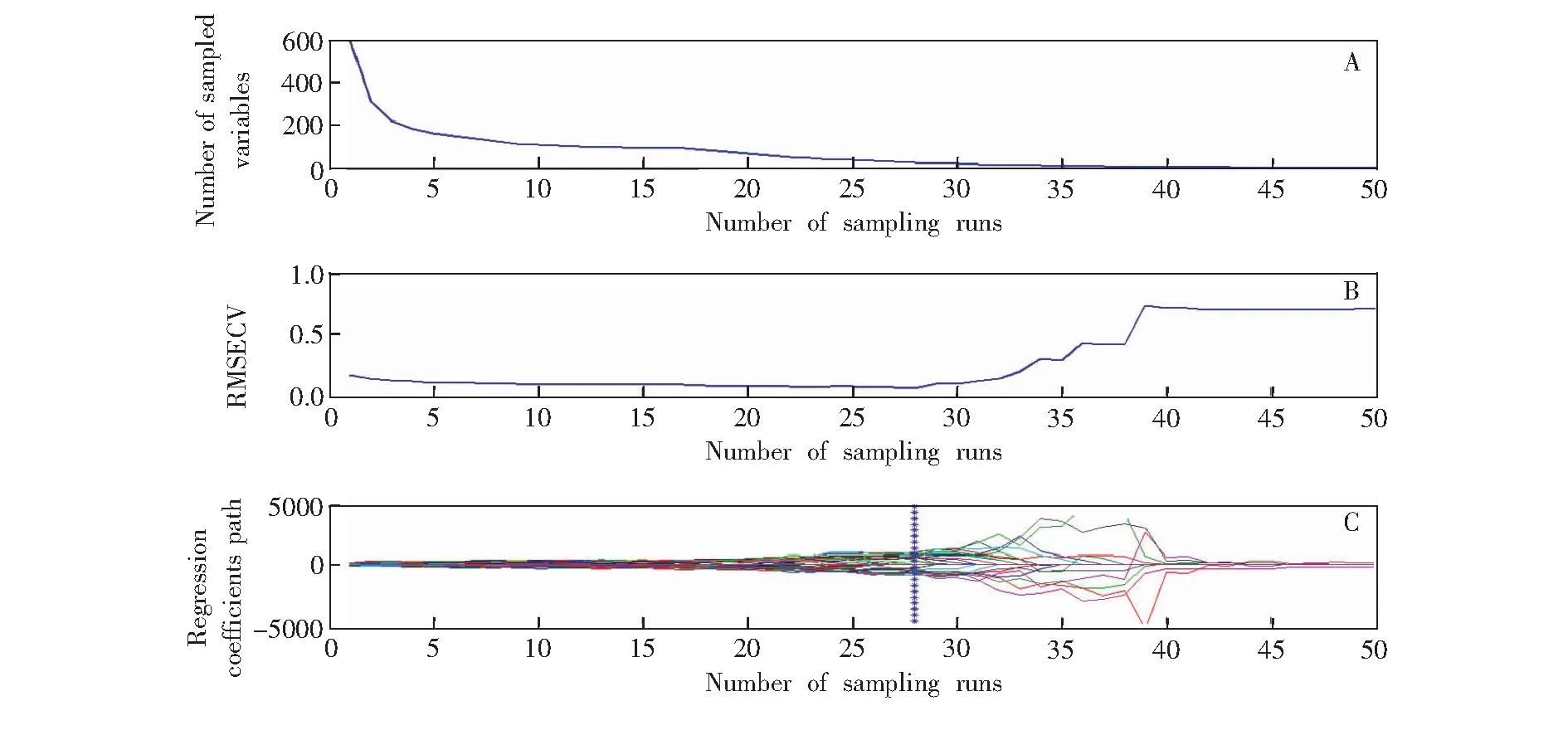
图4 CARS变量筛选过程: (A)波数变量数的变化; (B) 均方根误差的变化; (C) 变量回归系数趋势图Fig.4 Process of competitive adaptive reweighted sampling (CARS) variable selection: (A) variation of wave number number; (B) variation of RMSECV; (C) trend of varible regression coefficients
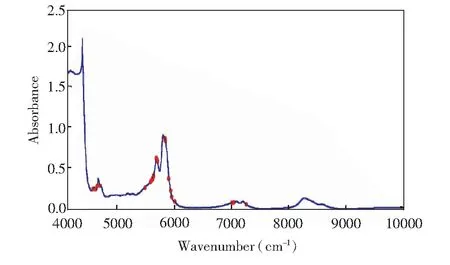
图5 CARS优选变量分布图Fig.5 Distribution of selected CARS variables
3.4预测模型的比较与选择
对于37个特征变量,应用PCR、PLS和LS-SVM方法分别建立食用植物油中TFA含量的预测模型,其结果见表4。由表4可知,与PCR预测模型相比,PLS预测模型的R2更高且RMSEC及RMSEP更低,其预测模型性能优于PCR预测模型。对于LS-SVM预测模型,其预测模型的RMSEC低于PLS预测模型,但RMSEP高于PLS预测模型,RMSEC与RMSEP相差较大,预测模型可能存在过拟合; 而PLS预测模型的RMSEC与RMSEP较为接近,预测模型性能稳定。综合考虑,PLS为最佳建模方法。
表4 PCR、PLS和LS-SVM方法建立的TFA预测模型结果
Table 4 TFA prediction model results with PCR, PLS, and LS-SVM methods

建模方法Modelingmethod主成分数Principalcomponentsnumber校正集CalibrationsetR2RMSEC(%)预测集PredictionsetR2RMSEC(%)PCR180.9840.0980.9620.137PLS130.9920.0710.9890.075LS⁃SVM-0.9960.0480.9770.110PCR:principalcomponentregression;LS⁃SVM:leastsquaresupportvectormachine.
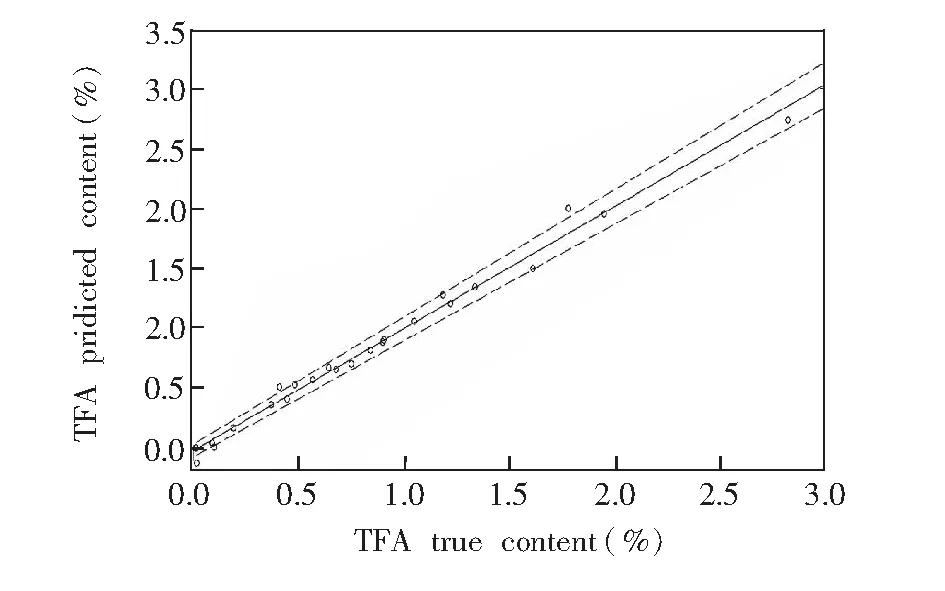
图6 最优预测模型对预测集样本的预测结果Fig.6 Prediction results of optimal set of prediction models
经上述优化后,最优预测模型的预测集R2和RMSEP分别为0.989和0.075%。与未优化的全波段 (B1)PLS预测模型相比,其预测集R2由0.904上升为0.989,RMSEP由0.230%下降为0.075%。全波段 (B1)共有3045个变量,而最优预测模型所用的变量数为26个,仅为全波段的0.854%。此外,与文献[13,14]的结果相比, 本研究的决定系数及均方根误差均有较大的改善。由此可知,模型优化非常必要,能简化预测模型,并较大程度提高预测模型的精度和稳定性。图6为最优预测模型对预测集样本的预测结果。图6中,直线为TFA真实值和预测值的线性拟合结果,两条虚线为其95%置信区间的拟合结果, 对于预测集样品,选取编号为41、71和76 3个具有代表性的样本,其预测值分别为0.366%、1.064%和2.744%,绝对误差分别为-0.007%、0.016%和0.076%。
4 结 论
本研究利用近红外光谱技术对食用植物油中TFA含量进行快速定量检测,并通过波段选择、光谱预处理、变量选择及建模方法对预测模型进行优化。结果表明,近红外光谱技术可以用于食用植物油中TFA含量的快速定量检测,其最优预测模型的校正集和预测集R2分别为0.992和0.989,RMSEC和RMSEP分别为0.071%和0.075%。与全波段 (B1)PLS预测模型相比,最优预测模型的预测集R2由0.904上升为0.989,RMSEP由0.230%下降为0.075%。此外,最优预测模型所用的变量数仅为26个,为全波段的0.854%。由此表明,模型优化非常必要,能简化预测模型,并较大提高预测模型的精度和稳定性。本研究为食用植物油中TFA含量的快速无损定量检测提供了参考。
1 CHEN Yi, ZHANG Qing-Ling, LIN Cong, HUANG Jian-Li.Cereal&FoodIndustry,2009, 16(5): 25-28
陈 宜, 张青龄, 林 丛, 黄建立. 粮食与食品工业,2009, 16(5): 25-28
2 National Food Safety Standard, General Rules for Nutrition Labeling of Prepackaged Foods. National Standards of the People's Republic of China. GB 28050-2011
食品安全国家标准,预包装食品营养标签通则. 中华人民共和国国家标准. GB 28050-2011
3 XU Xiao-Yan, LAN Guo-Dong.GuangdongAgriculturalScience,2010, 37(6): 153-154
徐小艳, 蓝国东. 广东农业科学,2010, 37(6): 153-154
4 SONG Zhi-Hua, SHAN Liang, WANG Xin-Guo.ChinaOilsandFats,2006, 31(12): 37-40
宋志华, 单 良, 王兴国. 中国油脂,2006, 31(12): 37-40
5 YU Xiu-Zhu, DU Shuang-Kui, YUE Tian-Li, WANG Qing-Lin.TransactionsoftheChineseSocietyforAgriculturalMachinery,2009, 40 (1): 114-119
于修烛, 杜双奎, 岳田利, 王青林. 农业机械学报,2009, 40(1): 114-119
6 HE Wen-Xun, HONG Gui-Shui, FANG Run, CAI Xian-Chun, HUANG-Sheng.SpectroscopyandSpectralAnalysis,2015, 35(1): 76-82
何文绚, 洪贵水, 方 润, 蔡仙春, 黄 声. 光谱学院光谱分析,2015, 35(1): 76-82
7 TAO Jian, JIANG Wei-Li, DING Tai-Chun, FENG Bo, JIN Li-Xin, CHENG Hai-Fang.JournalofChineseInstituteofFoodScienceandTechnology,2011, 11(8): 154-158
陶 健, 蒋炜丽, 丁太春, 冯 波, 靳立新, 程海芳. 中国食品学报,2011, 11(8): 154-158
8 ZOU Qing-Qing, TAN Hua-Rong, LU Ning.PackagingandFoodMachinery,2016, 34(2): 57-60, 51
邹晴晴, 檀华蓉, 陆 宁. 包装与食品机械,2016, 34(2): 57-60, 51
9 ZHAO Lei, CHANG Hui, HU Jin-Shan, LI Hong-Xia.AcademicPeriodicalofFarmProductsProcessing,2014, 18(9): 66-68
赵 雷, 常 辉, 胡金山, 李红霞. 农产品加工(学刊),2014, 18(9): 66-68
10 WU Jing-Zhu, XU Yun.TransactionsoftheChineseSocietyforAgriculturalMachinery,2011, 42(10): 162-166
吴静珠, 徐 云. 农业机械学报,2011, 42(10): 162-166
12 SUN Tong, WU Yi-Qing, LI Xiao-Zhen, XU Peng, LIU Mu-Hua.ActaOpticaSinica,2015, 35(6): 350-357
孙 通, 吴宜青, 李晓珍, 许 朋, 刘木华. 光学学报,2015, 35(6): 350-357
12 LIU Cui-Ling, WEI Li-Na, ZHAO Wei, SUN Xiao-Rong.ChinaBrewing,2014, 33(11): 149-151
刘翠玲, 位丽娜, 赵 薇, 孙晓荣. 中国酿造,2014, 33(11): 149-151
13 Li H, Voort F R V D, Ismail A A, Sedman J, Cox R.J.Am.OilChem.Soc.,2000, 77(10): 1061-1067
14 Azizian H, Kramer J K.Lipids,2005, 40 (8): 855-867
15 Kim Y K, Kays S E.J.Agr.Food.Chem.,2009, 57(18): 8187-8193
16 AN Xue-Song, SONG Chun-Feng, YUAN Hong-Fu, XIE Jin-Chun, LI Xiao-Yu.SpectroscopyandSpectralAnalysis,2013, 33(11): 3019-3023
安雪松, 宋春风, 袁洪福, 谢锦春, 李效玉. 光谱学与光谱分析,2013, 33(11): 3019-3023
17 Li H, Liang Y, Xu Q, Cao D.Anal.Chim.Acta,2009, 648(1): 77
18 ZHANG Xiao-Yu, LI Qing-Bo, ZHANG Guang-Jun.SpectroscopyandSpectralAnalysis,2014, 34(5): 1429-1433
张晓羽, 李庆波, 张广军. 光谱学院光谱分析,2014, 34(5): 1429-1433
19 Li H, Sedman J, Ismail A A.J.Am.OilChem.Soc.,1999, 76(4): 491-497
This work was supported by the National Natural Science Foundation of China (No.31401278) and the Natural Science Foundation of Jiangxi Province, China (No.20151BAB204025)
RapidQuantitativeDetectionandModelOptimizationofTrans
FattyAcidsinEdibleVegetableOilsbyNearInfraredSpectroscopy
MO Xin-Xin1, SUN Tong*1, LIU Mu-Hua1, YE Zhen-Nan2
1(KeyLaboratoryofJiangxiUniversityforOptics-ElectronicsApplicationofBiomaterials,
Collegeofengineering,JiangxiAgriculturalUniversity,Nanchang330045,China)
2(ComprehensiveTechnologyCenter,JiangxiEntry-ExitInspectionandQuarantineBureau,Nanchang330038,China)
Near infrared spectroscopy (NIR) was used to detect trans fatty acids (TFA) in edible vegetable oils quantitatively. And prediction model of TFA was optimized through band selection, pretreatment method, variable selection and modeling method. NIR spectra of 98 edible vegetable oil samples were collected in spectral range of 4000-10000 cmusing an Antaris II Fourier transform near infrared spectrometer, and the true content of TFA was measured by gas chromatography. First, optimization of waveband and pretreatment method was conducted on original spectra. On this basis, competitive adaptive reweighted sampling (CARS) was used to select important variables that related to TFA. Finally, the prediction models of TFA content in edible vegetable oils were established using principal component regression (PCR), partial least square (PLS) and least square support vector machine (LS-SVM). The results indicated that NIR spectroscopy was feasible for detecting TFA content in edible vegetable oils,R2of the best prediction model after optimized in calibration and prediction sets were 0.992 and 0.989, and root mean square error of calibration (RMSEC) and root mean square error of prediction (RMSEP) were 0.071% and 0.075%, respectively. Only 26 variables were used in the best prediction model, accounting for 0.854% of the whole waveband variables. In addition, compared with the full waveband PLS prediction model, theR2in prediction set increased from 0.904 to 0.989, and RMSEP decreased from 0.230% to 0.075%. It shows that model optimization is very necessary, CARS method can select important variables related to TFA effectively and immensely reduce the number of modeling variables, so it can simplify the prediction model, and greatly improve the accuracy and stability of prediction model.
Edible vegetable oils; Near infrared spectroscopy; Model optimization; Competitive adaptive reweighted sampling variable selection; Quantitative detection
25 May 2017;accepted 15 August 2017)
10.11895/j.issn.0253-3820.170329
