基于增量关联规则游记挖掘的景点推荐应用研究※
2017-11-06廖旺宇
廖旺宇
(四川旅游学院 ,四川 成都 610100)
基于增量关联规则游记挖掘的景点推荐应用研究※
廖旺宇
(四川旅游学院 ,四川 成都 610100)
文章提出了一种基于旅游文记挖掘的改进增量关联规则景点推荐算法。该算法紧密关注旅行者偏好,基于分类有效降低了算法空间复杂度,使得挖掘结果聚焦度更高;能够高效处理旅游文记数量增长的状况,避免了反复扫描整个数据集,仅需扫描增量数据集并结合已有挖掘结果便可开展高效运算分析,完成相关景点推荐应用。通过使用网络获取旅游文记作为实例对算法进行验证,表明改进算法在候选项集获取个数方面减少明显,推荐结果清晰明了,有较明显的优势。
关联规则;增量更新;旅游文记挖掘;景点推荐
旅游逐渐成为休闲娱乐活动中不可或缺的组成部分。同时,互联网技术和自媒体平台的迅速发展一方面为旅行者分享旅行经历、提供出行建议带来了巨大的便利;另一方面为计划出行者进行景点和线路甄选提供了极具代表性和可靠性的[1]重要参考依据。然而旅行者很难高效、准确地从庞杂多样、质量参差不齐的旅游文记中获取满足其偏好和要求的出行参考信息。设计一种高效算法帮助旅行者处理、分析繁杂的旅游文记,使其在获得了某些旅游景点并安排到自己的旅游行程单之后,可以通过系统智能地推荐符合其喜好的相关联的旅游目的地或者景点,以扩展其旅游景点的选择范围或丰富其行程安排[2]成为亟待解决的需求。
由R·Agraeal等人首先提出的关联规则算法[3]可以解决上述问题。但是经典的关联规则算法,如Apriori算法等,所处理的数据集都相对固定,无法高效应对互联网中旅游文记数量快速增长的情况。在旅游文记集合增长之后只能完全重新执行高花费的整个频繁项目集的发现过程[4],进而重新获取关联规则挖掘,严重降低了运行效率。并且,在传统关联规则挖掘过程中,为了最大限度地获取更多的规则,需要对所有频繁项目集的非空子集进行计算。而事实上,旅行者只关注与其偏好相吻合的、关联性强的景点集合。传统挖掘方式获得的规则中包含了众多用户不关注的规则,这样既不方便用户浏览挖掘结果,又浪费了计算机的资源,降低了效率。
基于上述考虑,本文利用在原有高效更新关联规则算法[5]和增量关联规则更新算法[6]基础上所提出的改进增量关联规则算法,高效地从大容量旅游文记中获取用户关注度高的关联景点集合。依据该关联景点集合便可精确地推荐、选择满足旅行者偏好的景点。同时,当旅游文记集合增长时,无须完全重新扫描整个游记文本集合,只需对增量游记进行扫描处理便可更新相关联的景点集合,为智能、高效的景点推荐提供了极大的便利。
1 基于增量关联规则旅游文记挖掘的旅游景点推荐的算法设计
1.1算法基础
基本思想:设初始数据集为DB,在扫描DB一次之后,记录所有非空项目集及其支持度计数并用于生成初始数据集的频繁项目集。在实验数据集动态增长之后,设增长部分的数据集为db。此时只需对db进行一次扫描,记录所有非空项目集及其支持度计数,并利用该结果与DB中已知的挖掘结果进行合并分析处理,便可生成扩充之后的新数据集DB+db的频繁项目集进而获取强规则。该方法避免了重复扫描整个DB+db数据集,减少数据库I/O次数的同时,降低了算法运行的空间需求,提升了挖掘结果的聚焦度。
设DB中的事务总数为|DB|,db中的事务总数为|db|。若用户设定的最小支持度阈值为minsup,则数据集DB、db及DB+db中频繁项所需满足的最小支持度计数分别为cDB=minsup*|DB|、cdb=minsup*|DB|和cDB+db=minsup*|DB|。且,显然cDB+db=cDB+cdb。
设数据集DB、db、DB+db中候选项的实际支持度计数分别为sDB、sdb、sDB+db,且显然sDB+db=sDB+sdb。
为便于讨论,设fx=sx-cx(x=DB,db,DB+db),显然有:若f≥0,则该候选项集为数据集中的频繁项集;若f<0,则该候选项集为数据集中的非频繁项集,且fDB+db=fDB+fdb。
性质1,若某一候选项集在DB中为频繁项集,且在db中为频繁项集,则该候选项在DB+db中为频繁项集。
证明:若某一候选项集在DB和db中为频繁项集,则fDB≥0,fdb≥0,显然有fDB+db=fDB+fdb≥0。所以,该候选项集在DB+db中为频繁项集。
性质2,若某一候选项集在DB中为非频繁项集,且在db中也为非频繁项集,则该候选项集在DB+db中为非频繁项集。
证明:若某一候选项集在DB和db中为非频繁项集,则fDB<0,fdb<0,显然有fDB+db=fDB+fdb<0。所以,该候选项集在DB+db中为非频繁项集。
性质3,若一个候选项在DB和db中分别为频繁项集、非频繁项集或非频繁项集、频繁项集,则该候选项集在DB+db中是否为频繁项集不确定。
证明:若某一候选项集在DB中频繁,在db中不频繁,则fDB≥0,fdb<0,显然无法确定fDB+db=fDB+fdb的值为正值还是负值。
若某一候选项集在DB中不频繁,在db中频繁,则fDB<0,fdb≥0,显然无法确定fDB+db=fDB+fdb的值为正值还是负值。
所以,以上两种情况无法确定该候选项是否为DB+db中的频繁候选项。
当出现性质3中情况时,只能将该候选项集在DB+db中的实际支持度计数sDB+db与(|DB| + |db|)*minsup比较进行判断。而sDB+db=sDB+sdb,显然可以通过已知的sDB和sdb容易地得到。
因此,根据性质1、性质2、性质3,候选项集是否为频繁项集的判断方式可以归纳为表1:

表1 增量更新候选项频繁状况判定表
1.2算法描述
增量关联规则游记挖掘算法分为两个阶段:首先,高效统计出DB或db中每一非空项集的支持度计数;然后,利用上一阶段的结果和已知的挖掘结果更新具有用户指定的最小支持度阈值的频繁项集。
对于每一个项集都有一个count域来存储其实际支持度计数,算法描述如下。
算法1:统计各项集的实际支持度计数
输入:事务数据集DB或db,项集I={i1,i2,……,in}。
输出:所有实际支持度计数大于零的项集CDB或Cdb,及CDB或Cdb中每一项目所对应的实际支持度计数。
算法描述:
(1)初始化CDB或Cdb,将其置为空值。
(2)设置算法关注的目的地项目。不妨设算法只关注与目的地ix相关的景点。
(3)对事物数据集DB或db中的每一事务中的所有包含ix的项集c进行计数:
若该项集c已经包含于CDB或Cdb中,则将其对应的count值增加1;
否则将该项集c加入CDB或Cdb中,并将其计数count记为1。
(4)对事物数据集DB或db中的每一事务中的所有与ix相关,但不包含ix的项集c进行计数:令c=c-ix,则:
若该项集c已经包含于CDB或Cdb中,则将其对应的count值增加1;
否则将该项集c加入CDB或Cdb中,并将其计数count记为1。
由算法1显然可以产生所有与游客密切关注的目的地ix相关的、项目集合的实际支持度计数非零的项集。
若对数据集DB使用该算法,可以完成对初始数据集中与用户关注景点相关的、实际支持度计数非零的候选项目集合CDB。随后依据CDB便捷地得到频繁项集FDB,并检验其各子项是否满足最小置信度阈值,进而得到初始数据中用户关注度高的关联景点集合。
当游记动态增长时,首先将新增数据集db作为输入执行算法1,即可获得db的所有与用户关注景点相关的、项集的支持度计数非零的候选项目集合Cdb。此时,执行算法2将容易地获取到DB+db的频繁项集FDB+db,进而得到更新后的用户关注度高的相关景点集合。
算法2:
输入:最小支持度阈值minsup,候选项集CDB、Cdb,原数据集DB的频繁项集FDB。
输出:DB+db中具有最小支持度阈值minsup的所有频繁项集的集合FDB+db。
算法描述:
(1)初始化CDB+db,将其值置为CDB+db=CDB+Cdb。
(2)求db的频繁项集:首先将Fdb置为空值,若Cdb中某一项目cdb的实际支持度计数大于等于|db|*minsup,则将cdb加入Fdb中。
(3)依据表1中的方法判断项集在DB+db中是否频繁:
①对于CDB+db中的所有项目fDB+db,若在DB中频繁:
若在db中不频繁:计算fDB+db.count=fDB.count+fdb.count。
如果fDB+db.count≥(|DB| + |db|)*minsup,则将fDB+db加入FDB+db;否则,将其从频繁项集中删除。
若在db中频繁:将fDB+db加入FDB+db,并置其支持度计数为fDB.count+fdb.count。
②对于CDB+db中的所有项目fDB+db,若在DB中不频繁:
若在db中频繁:计算fDB+db.count=fDB.count+fdb.count。
如果fDB+db.count≥(|DB| + |db|)*minsup,则将fDB+db加入FDB+db;否则,将其从频繁项集中删除。
若在db中不频繁,则将其从频繁项集中删除。
(4)将CDB+db置为CDB:
在获取频繁项集FDB+db,并检验其中子项是否满足最小置信度阈值,进而得到更新后的数据集中用户关注度高的关联景点集合。
2 实验与结果分析
2.1基于旅游文记挖掘的旅游景点推荐应用实例
本文以四川省成都市为例,从蚂蜂窝网站上以“成都”作为检索词获取了427篇旅行游记,并随机将其中321篇游记作为初始实验数据集DB,106篇作为增量实验数据集db。随后分别提取了DB和db中每一篇游记中的地理名词。在纠正了错误语义的地理名词之后,对获取到的共208个地理名词进行了数据预处理,将所有地理名词替换为对应的地理名词ID号,形成了由游记ID和地理名词ID集合构成的实验数据表,部分数据表快照如图1所示。
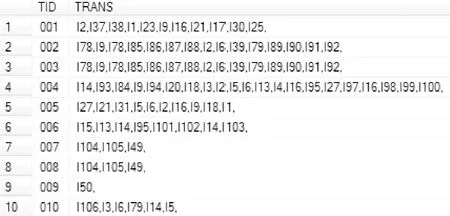
图1 游记地理名词集合部分数据快照
其中,TID为标识符,TRANS为各游记中经过预处理的地理名词集合。DB中单个元组包含的ID个数最小值为1个,最大值为31个;db中单个元组包含的ID个数最小值为1个,最大值为16个。本文随机选取以关注武侯祠对应的项目“I5”为例开展应用实例实验。
首先执行算法1,产生DB中所有支持度计数非零的候选项集合及其支持度计数CDB,得:
CDB={(I1,56),(I2,195),(I3,66),…,(I1I2,47),(I1I3,12),…,(I1I2I3,10),(I1I2I4,22),…,…,(I1I2I3I4I5I6I9I10I11I12I17I27I28I31I32I33I42I44I45I50I110I118I125I127I135I147I150I151I152I161I162,1)}
其中,(x,y)∈CDB,则x表示DB中的地理名词项目集,y表示其对应的支持度计数。不妨设用户给定的最小支持度阈值为minsup=20%,则CDB需满嘴的最小支持度计数为minsup*|DB|=321*20%≈64。
在CDB中进行筛选,即可产生具有用户指定的最小支持度阈值的频繁项集FDB,得:
FDB={(I2,195),(I3,66),(I4,92),(I5,126),(I6,189),(I9,118),(I14,73),(I2I4,70),(I2I5,95),(I2I6,144),(I2I9,88),(I4I6,72),(I5I6,110),(I5I9,67),(I6I9,87),(I2I5I6,88),(I2I6I9,71)}
若仅为针对初始数据集求频繁项集FDB,则至此执行完毕。并可由所得FDB进一步容易地根据公式(1)[7-8]求取。
Confidence(X→Y)=Support(X∪Y)/Support(X)(1)
各候选项集的置信度值如表2所示。
进而根据用户设置的最小支持度阈值、最小置信度阈值得到与旅行者关注的武侯祠相关的、可推荐游览的景点的集合。

表2 DB中各规则的支持度和置信度
若游记数量增长之后需要更新强关联规则,则先对增量集合db执行算法1,产生db中所有支持度计数非零的候选项集合及其支持度计数Cdb,得:
Cdb={(I1,16),(I2,71),(I3,36),…,(I1I2,10),(I1I3,7),…,(I1I2I3,5),(I1I2I4,2),…,…,(I2I5I6I9I13I14I17I18I34I62I66I78I84I85I134I175,1)}
若用户设定的最小支持度阈值仍为minsup=20%,则cdb需满足的最小支持度计数为minsup*|DB|=106*20%≈21。在Cdb中进行筛选,即可产生具有用户指定的最小支持度阈值的频繁项集Fdb,得:
Fdb={(I2,71),(I3,36),(I4,24),(I5,45),(I6,72),(I9,45),(I14,23),(I2I3,31),(I2I5,34),(I2I6,57),(I2I9,35),(I3I6,27),(I5I6,36),(I5I9,23),(I6I9,32),(I2I3I6,24),(I2I5I6,28),(I2I6I9,28)}
随后,根据算法2,设置CDB+db=CDB+Cdb,并对CDB+db中所有子集依据表1中的判断方式进行判断。
例如,在候选项集CDB+db中:
(1)子集I2,在DB和db中均为频繁项集,因此I2属于FDB+db。
(2)子集I1,在DB和db中均为非频繁项集,因此I1不属于FDB+db。
(3)子集I2I4,在DB中为频繁项集,在db中为非频繁项集,需要从全局判断其是否属于FDB+db。此时,候选子集需要满足的最小支持度计数为(|DB|+|db|)*minsup=(321+106)*20%,约为85。而子集I2I4在DB+db中的支持度计数为70+17=87,因此I2I4属于FDB+db。
(4)子集I2I3,在DB中为非频繁项集,在db中为频繁项集,需要从全局判断其是否属于FDB+db。此时,候选子集需要满足的最小支持度计数为(|DB|+|db|)*minsup=(321+106)*20%,约为85。而子集I2I4在DB+db中的支持度计数为50+31=81,因此I2I3不属于FDB+db。
对CDB+db中所有子集均使用上述方法进行判断后,最终可得到所需的更新之后的游记集合DB+db中的频繁地名项集FDB+db:
FDB+db={(I2,266),(I3,102),(I4,116),(I5,171),(I6,261),(I9,119),(I14,87),(I2I4,104),(I2I5,152),(I2I6,147),(I2I9,89),(I5I6,113),(I6I9,88),(I2I5I6,116),(I2I6I9,99)}
根据FDB+db可以简易地根据公式(1)计算出纳入新增游记地名记录之后的新数据集中各候选项集的置信度值如表3所示。
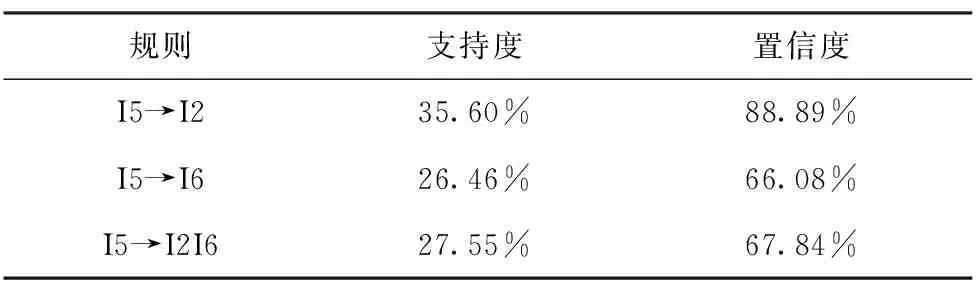
表3 DB+db中各规则的支持度和置信度
进而向旅行者推荐满足最小支持度阈值和最小置信度阈值的与其关注的武侯祠紧密关联的景点的集合。假设,用户设置置信度为65%,则关联规则I5→I2和I5→I6成为强规则。参照地名数据预处理记录,可以还原为规则游览武侯祠的游客还游览了宽窄巷子和锦里。据此,可将宽窄巷子和锦里两景点推荐给游客备选。
2.2应用实例分析及与原算法的比较
应用实例随机选取以关注数据预处理后对应于武侯祠的地名候选项集“I5”为例,对算法的运行过程进行了说明。算法在获取游记地名候选项集的过程中只扫描了两次数据库,并可以在游记数量增长后只扫描增加部分的数据集db。既有效避免了多次扫描数据库而引起多次I/O操作,又可以在处理增量数据时有效利用已有扫描结果,避免反复扫描庞大的数据集。同时,针对旅行者只关注其偏好的游览项目的特点,设置了面向分类的关注项集,大幅度减小了候选项集中的项目个数,有效减小算法运行所需占用的空间的同时,增强了挖掘结果的聚焦度。
实验结果表明,不论是对初始数据集DB还是增量数据集db进行处理,本文算法所求取的候选集C中的项目个数都有明显下降。其中,对初始数据集DB进行处理时,本文算法共获取的支持度计数不为零的候选项集总数为1 216 576 105个,相较于原算法获取总数的2 250 572 195个大幅下降了45.94%;对增量数据集db进行处理时,本文算法共获取的支持度计数不为零的候选项集总数为89 665个,相较于原算法获取总数的151 134个大幅下降了40.67%。DB、db中各支持度计数非零的候选项集个数比较详细情况见图2所示。
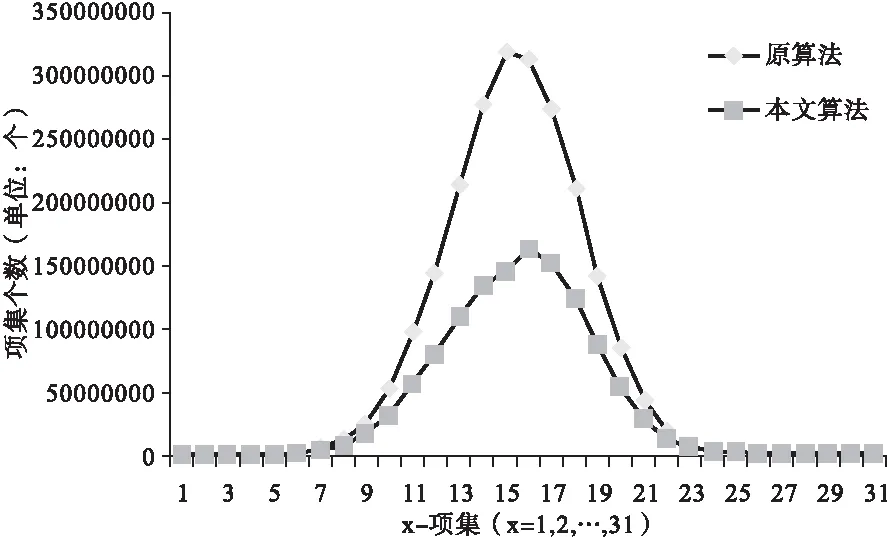
(1)CDB子集数目比较

(2)Cdb子集数目比较图2 候选项集子集个数比较
3 总结
旅游电子商务的快速发展使得越来越多的旅行者借助网络获取出行信息、预订产品[9],针对游客希望依据自己偏好的景点由系统自动向其推荐相关联的旅游景点,以扩展、优化和丰富其旅行选择范围的需求,本文利用改进的高效增量关联规则算法予以实现,并有效降低了原有算法的空间复杂度,提高了挖掘结果的聚焦度。同时,伴随着互联网技术和自媒体的迅速发展,发表旅游评论和游记、分享旅行经历也愈发便捷,因而大量的旅游文记正在不断生成。本文的算法可以高效应对旅游文记数量增长的情况,从大量已有游记或新增游记中挖掘出一系列景点集合推荐给用户,具有一定的应用价值和针对性。
[1]曹新向. 充分利用网络,为旅游研究和决策提供服务[J]. 旅游学刊,2007,22(5):11-12.
[2]胡乔楠. 基于旅游文记的旅游景点推荐及行程路线规划系统[D]. 杭州:浙江大学,2015.
[3]Agrawal R, et al. Mining association rules between sets of items in large databases[C]∥ Proceedings of ACM SIGMOD Conference on Management of Data. Washington DC, 1993: 207-216.
[4]杨君锐. 关联规则增量式快速更新方法的研究[J]. 微电子学与计算机,2004,21(9):120-124.
[5]周海岩. 适合于高效更新的关联规则挖掘算法[J]. 小型微型计算机系统,2004,25(4):634-637.
[6]冯玉才,冯建琳. 关联规则的增量式更新算法[J]. 软件学报,1998,9(4): 301-306.
[7]Jiawei Han, MichelineKamber .数据挖掘概念与技术(第2版)[M]. 范明,孟小峰,译. 北京: 机械工业出版社,2007:147-148.
[8]黄德才. 数据仓库与数据挖掘教程[M]. 北京:清华大学出版社,2016:228-230.
[9]闫海艳. 在线旅游用户数据研究及其关联应用[D]. 上海:华东师范大学,2015.
ApplicationResearchonIncrementalAssociationRulesforTravelogueMining-basedTouristAttractionsRecommending
LIAOWangyu
(Sichuan Tourism University, Chengdu 610100, Sichuan, China)
As the travelers would like the system to automatically recommend relevant scenery spots to optimize their travel plan based on their preferences and selections, an improved incremental updating algorithm of association rules based on tourist attraction recommendation is proposed. The algorithm focuses on the traveler’s preferences and its classification effectively reduces the space complexity of the algorithm, making the mining result more concentrated. It can efficiently handle the growth of travel documents, avoiding scanning the entire data set and only scanning the incremental data set and combining the results with the existing mining results. Through the experimental verification, the improved algorithm can significantly reduce the number of candidates, and the results are clear and have obvious advantages.
association rules; incremental updating; travelogue mining; tourist attractions recommending
F590.7
A
2095-7211(2017)06-0089-05
本文为四川省教育厅自然科学项目 “数据挖掘在餐饮旅游业客户关系管理中的应用研究”的阶段性研究成果,项目编号:13ZB0148。
廖旺宇(1984—),男,四川成都人,四川旅游学院讲师,主要从事数据挖掘研究。
