自动作文评分系统测量性、归纳性和外推性效度研究*
2017-10-31上海交通大学
张 荔 上海交通大学
自动作文评分系统测量性、归纳性和外推性效度研究*
张 荔 上海交通大学
研究人员对常用的自动作文评阅(AWE)系统PEG、IEA、e-rater、IntelliMetric等都开展过大量效度研究,对AWE系统的发展起到了积极作用。然而,针对我国自主研发的AWE系统批改网的效度研究却十分有限。本研究从测量性、归纳性和外推性三方面对批改网效度加以验证,结果显示,批改网的人机评分同一分数档内的完全一致性以及完全加相邻分数档一致性与国外同类AWE系统基本相似,人机评分显著相关,说明其具有一定的测量性,但是相关性略低于国外其它AWE系统。批改网对不同任务作文评分呈现显著相关性,显示出一定的归纳性,但相关性略低于人工评分间的相关性以及国外其它AWE系统的人机评分相关性。批改网作文评分与听力、阅读以及学习档案袋分数显著相关,具有一定的外推性,且相关性高于国外其它多数AWE系统。研究也发现,批改网对不同任务作文评分有显著差异,系统评分与口语成绩未呈现显著相关性。研究者对此进行了解释。本研究较为全面地对批改网系统的效度进行了验证,对于系统的开发、利用和改进有着积极意义。
自动作文评分,效度,测量性,归纳性,外推性
1.引言
效度是测量工具能准确测出所测量事物的程度,简单地说是指测量工具或手段的准确性和有用性。某一AWE系统能够从多大程度上测量学生的写作质量和帮助学生提升写作水平是十分关键的问题。国外研究人员对PEG(Kukich 2000)、IEA(Landauer et al.2000), e-rater(Ramineni et al.2012;Attali Lewis&Steier 2013;Weigle 2010,2011),IntelliMetric(Elliot 2003;Vantage Learning 1999,2001;Powers,Escoffery&Duchnowski 2015)Criterion(Klobucar et al.,2013) 等常用 AWE系统进行了效度研究,并取得了一定的进展。我国研究人员也针对自主研发的批改网AWE系统开展了大量研究,但是这些研究主要集中在系统对写作教学的作用,有关效度的研究比较少,且这些研究往往局限于效度的某一方面,未从效度的多个层面加以探究。因此本研究将着眼于测量性、归纳性和外推性,对批改网进行更为全面的效度检验。
2.研究背景
2.1 理论基础
美国心理协会将效度定义为“证据能够支持基于分数的推论的程度,它是指使用测量做出的某种特定的推论而不是测量本身是否有效”(AERA1985:9)。在测试研究中,效度是指“基于测试分数所做出的推理行为的准确性和合理性的程度” (Messick 1989:13)。从传统观念来看,效度可分为内容效度、关于标准的效度和结构效度。而现代效度的概念又增加了解释性和对分数的使用,换句话说,效度包含对分数的解释所包含的价值的评估和使用测试结果的社会效应(Yang et al.2002)。研究人员提出效度研究的五个方面:测量性(evaluation)、解释性(interpretation)、外推性(extrapolation)、归纳性(generalization) 和实用性 (utilization)(Enright&Quinlan 2010; Williamson et al.2012, Xi 2010; Chapelle Cotos&Lee 2015)。测量性是评分是否能够体现写作能力与分数之间的关系,也就是说,根据评分标准给一篇作文评分,那么这个分数是否真正意义上准确地反映作文的实际水平。在自动作文评阅系统来看,评分标准必须能够抓住写作能力的各个方面,评判必须严格按照评分标准。测量性主要体现在系统评分与人工评分者的评分是否具有一致性和相关性,换句话说就是研究自动作文评分的信度。解释性指的是自动评分系统是否反映写作评分的结构效度,也就是说,评分是否体现写作能力所需包含的各项内容,从某种意义上来说,就是评分标准是否体现写作能力的各个方面。解释性主要体现在评分对写作结构效度的表征性。也就是系统评分要素与人工评分要素是否一致。归纳性是指系统评分可以推测出其它类似的写作任务的得分情况。其依据体现在不同写作任务之间的系统评分一致性和系统评分对其它相似写作任务的代表性。归纳性的另一方面体现在自动作文评分系统究竟在多大程度上可以被认为是另外一个评分员,是否可以推测出人工评分的分数。外推性是指分数是否能够对目标领域的表现加以推导。所谓目标领域,可以指各种不同的写作领域,比如学术写作、实用英语写作、商务英语写作;亦或与写作能力相关的其它内容,例如听力、阅读、自我及教师评价、学习档案袋等等。通过自动作文系统评分与目标领域表现得分的关系可证明其外推性。实用性是一种对语言学习政策和策略的决定作用或是对语言教学实践的预测作用,也就是系统评分结果对政策实施的效应。在自动评分中就体现在对个人学习,教学大纲制定和教学政策实施的影响作用。比如使用自动作文评分对教与学是否产生正面的影响作用,是否对某种教学政策的制定产生积极影响,是否合理地适用于分级教学的决策过程、是否对学生考前准备产生有效推动作用等。限于文章篇幅,且对批改网的解释性(何旭良2013;张荔、盛越2015) 和实用性(杨晓琼、戴运财2015;石晓玲2012) 以往研究已有所涉及,本研究仅对批改网的测量性、归纳性和外推性加以研究。
2.2 相关研究综述
对于测量性的研究主要考察人机评分的相关性和一致性两个指标。从相关性指标来看,PEG的人机评分的相关性为0.72-0.78,高于人工评分者之间0.55-0.75的相关性(Page&Peterson,1995)。Kukich(2000) 则发现PEG的人机评分相关性达0.78,低于人工评分者间0.85的相关性。根据Landauer et al.(2000) 的报告,IEA人机评分的相关性达到0.85,与人工评分在词汇和文本的意义方面有较高的相似性。Landauer et al.(2003)对IEA系统的可靠性分析发现人机评分的相关性为0.81,略低于人工评分者之间0.83的相关性。Folze et al.(2013) 对IEA进行人机评分对比研究后发现相关性达到0.88,高于人工评分者之间0.79的相关性。对IntelliMetric的一系列可靠性评估研究表明,人机评分的相关性为0.50-0.90(Elliot 2003;Vantage Learning 1999,2001)。 对e-rater的一系列研究发现人机评分相关性为0.66-0.95(Attali&Burstein 2004;Burstein,Chodorow&Leacock 2004;Powers,Escoffery&Duchnowski 2015;Valenti et al.2003;Attali 2015)。由此可见,国外多数AWE系统人机评分的相关性高于0.7,但也有个别研究结果显示人机评分相关性在0.5-0.7之间。对于人机评分与人工评分相关性的比较,不同的研究结果也有所不同,人机评分相关性或高于或低于人工评分者间的相关性。从一致性指标来看,一系列IntelliMetric可靠性评估研究表明,人机评分的完全一致性为87%-98%,完全一致性加相邻一致性为94%-100%(Elliot 2003;Vantage Learning1999,2001)。e-rater人机评分的完全一致性为56-61%,完全加相邻一致性都是98%-99%,与人工评分者间的一致性基本持平(Dekli2006)。Dikli(2006) 认为,就满分为6分的作文,若人机评分达到70%的完全一致性和0.70的相关性,且与人工评分者之间的均分差别不大于0.1,则说明系统具有较好的信度或测量性。
对于归纳性的研究主要从系统测量不同写作任务的相关性和差异性来加以评定。Attali(2007) 对5000名两次参加托福考试学生的写作成绩进行效度的归纳性研究发现,使用e-rater对两次作文评分相关性达到0.71,人工两次评分间的相关性为0.54,因此系统对两次作文评分的相关性高于人工评分。次年,Attali(见Enright&Quinlan 2010)) 又针对14,000名学生三个月内的两次托福考试作文分数进行相关性检验,结果发现,人工评分两次作文相关性为0.53,E-rater两次作文评分相关性为0.80。由此可见,从归纳性来看,E-rater系统评分高于人工评分。Weigle(2011) 则分别比较了人工评分和e-rater评分在两次不同写作任务间的差异性,他使用配对样本T检验对e-rater两次作文评分的结果进行比较后发现,无论人工评分(t=0.75,p=0.45)还是系统评分(t=0.24,p=0.79),两次作文的均分都没有显著差异,体现出系统评分具有较好的一致性。因此系统评分体现了较好的归纳性效度。
对于外推性的效度研究主要看系统评分与体现语言能力的其它测试性(如听力、阅读、口语成绩)或非测试性(如师生问卷评定、档案袋评分等) 指标的相关性。Ramineni等(2012) 将系统评分与阅读、听力、口语以及去除写作的其它项目总分进行相关性检验后发现,人工作文评分与以上各项的相关性分别为0.53、0.53、0.58和0.62,而系统评分与以上各项的相关性则分别为0.54、0.52、0.55、0.61,人工评分与系统评分的外推力基本相同。Ramineni(2013) 又将e-rater对学生四篇作文的评分与入学考试阅读题、多项选择题、作文题、学期累积GPA分数、写作课程得分和个人学习记录档案袋进行了相关性检验,结果发现e-rater与以上各项的相关性分别为0.23-0.35、0.29-0.42、0.37-0.46、0.10-0.23、0.17-0.34和0.26-0.41,部分项目显示出一定的相关性,但总体来看相关性不是很强。Weigle(2010)分析了人机评分分别与其它体现写作能力的非测试性指标之间的相关性,包括学生自评、教师评价、课堂作文。结果发现系统评分与这些非测试性指标的相关性在0.30到0.40之间,略低于人工评分与指标的相关性。Weigle(2011)又使用网络问卷收集到学生对自身听、说、读、写的自我评分以及教师对学生的整体学术表现、写作能力、口语能力、英语语言能力的评分,并将这些评分与学生托福网考的e-rater评分之间进行了相关性检验。结果发现e-rater与学生自评的听、说、读、写的相关性分别为0.23、0.26、0.36和0.36,略低于人工作文评分与此的相关(0.29,0.31,0.40,0.41),与教师对学生的整体学术表现、写作能力、口语能力、英语语言能力的评分的相关性分别为0.21、0.28、0.27和0.34,略低于人工作文评分与此的相关性 (0.23、0.31、0.31、0.38)。Klobucar等人(2013)从其它测试或非测试性质的指标与自动作文评分的关系对Criterion的外推性进行了研究,这些内容包括SAT写作测试分数、学习记录档案袋分数以及学科成绩。他们于2009和2010年进行了两次数据采集和分析,结果发现Criterion与SAT的相关性分别为为0.43和0.41,与学习记录档案袋的相关性为0.37和0.39,与学科成绩的相关性为0.22和0.29,高出SAT与学习记录档案袋分数以及学科成绩的相关性。说明从外推性来看,Criterion比SAT的效度更高。
以上研究显示,国外的AWE系统从测量性、归纳性和外推性这几项指标来看显示了一定的效度,尤其在测量性和归纳性方面相关系数都比较高,而从外推性来看相关系数比较低。不同研究显示出高于或者低于人工评分或其它测试成绩的外推性。为了解批改网的测量性、归纳性和外推性效度,本研究提出以下三个问题:
1)同一任务系统评分与人工评分的一致性和相关性如何(测量性)?
2)不同任务系统评分的一致性和相关性如何(归纳性)?
3)系统评分与反应语言能力的其它测试或非测试指标(听、说、读等其它测试项目和学习记录档案袋)的相关性如何(外推性)?
3.研究方法
3.1 研究对象
上海交通大学计算机、数学、物理、化学、生物等专业56名大一学生参与了该研究,其中男生47名、女生9名。他们被分为两个英语教学班,由同一名教师教授大学英语课程。在为期16周的大学英语教学中完成了同样的教学任务和测试任务。
3.2 研究工具
研究工具主要包括写作任务,学期末水平考试、学期末外教口试和学习记录档案袋。学生共完成三次写作任务,题目分别为“My Idea of a Good College Teacher”、“My Expectation about Life in the University”和根据大学是否要晨跑的阅读材料自拟题目的任务,每次作文练习相隔时间一个月左右,字数要求200字以上。学期结束时,所有学生参加了学校统一举行的水平测试,包含听力(长对话、复合式听写、简答题和听译) 阅读(15选10完形填空、四选一完形填空、长篇阅读理解简答)和作文。学期末所有学生还进行了口语考试,由外教就某个题目与学生进行交谈,并根据统一的评分标准给出分数。整个学期英语学习进程都使用电子档案袋进行记录和整理,包括期中/末笔试成绩,期初/末口试成绩、中外教师给出的课堂表现和作业情况平时成绩、并将此记录按期中笔试10%,期末笔试50%,外教口试10%,外教平时成绩10%,中教平时成绩20%的比例得出每个学生教学档案袋的最终得分。
3.3 数据收集和分析过程
学生将三次作文提交至批改网,系统设定为四级打分公式,总分15分,得出相应的批改网得分。学生会根据批改网反馈进行反复修改,但本研究只使用了批改网对作文第一稿的评分,这是因为初稿未经外界因素影响(如根据批改网或教师的反馈进行修改),比较能够真实反映学习者当前的作文水平。两位多次参加四级评分的教师对三次作文的初稿进行了人工评分,然后我们将这56位学生的三次作文分别进行批改网和人工评分的相关性和一致性检验,即系统测量性效度检测。接着我们又进行系统归纳性效度检测,我们将批改网对每次作文初稿的评分进行了两两相关性检验,同时计算每次作文人工评分的两两相关性,将系统归纳性与人工评分归纳性加以比较。我们还使用One-Way ANOVA对三次作文的均分进行了比较,又进行了Post Hoc两两比较,以判断系统对每次作文成绩评分是否一致。最后我们将水平考试成绩的听力、阅读分项分数、外教口试分数和学习档案袋分数与批改网作文评分进行了相关性检验,以检测系统的外推性。
4.研究结果
4.1 测量性
研究结果显示,三次作文人工评分的平均分与批改网的平均分十分接近,尤其是两位人工打分均值的平均分(9.51)与批改网的平均分(9.50)相差仅为0.01,体现出系统评分与人工评分在总体平均分上的一致性(见表1)。CET作文评分标准的同一分数档上的人机评分完全一致性达62.50%~83.93%,完全加相邻一致性达98.21%~100%,与人工评分者之间的完全一致性(64.28%~78.57%) 和完全加相邻一致性(100%)比较一致。此外,无论从三次作文总体来看还是每次作文来看,人机评分都具有显著相关性(0.479~0.741),第二次作文人机评分的相关性(0.741) 高于人工评分者间(0.725)的相关性,其它两次作文人机评分的相关性低于人工评分者间的相关性(见表2)。由此可见,人机评分具有一定的相关性和一致性。

表1 自动评分系统与人工评分的描述统计
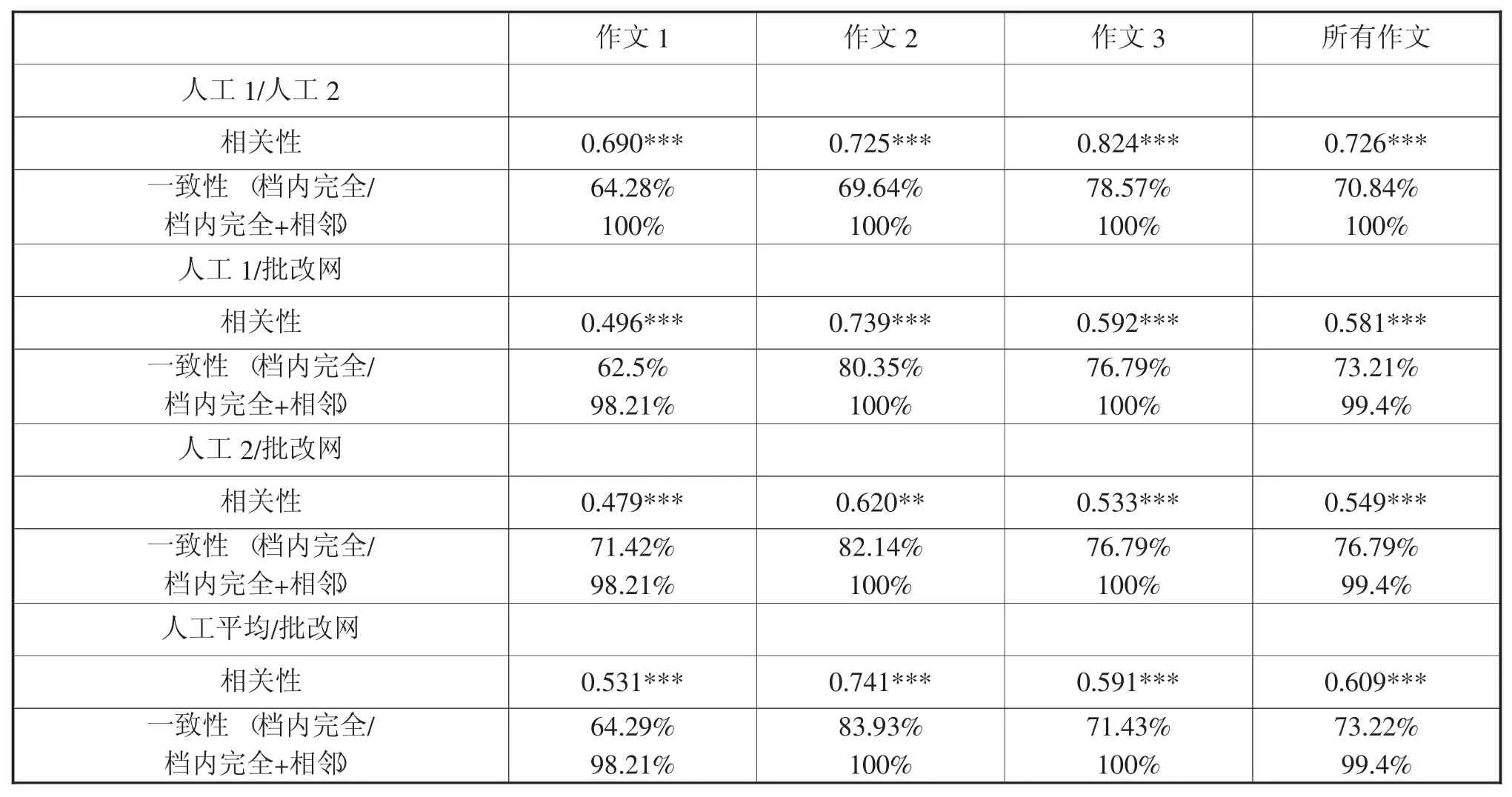
表2 三次作文人工评分与系统评分的相关性和一致性
4.2 归纳性
批改网对三次作文的评分呈现显著相关性,相关系数在0.403到0.498之间,而人工对三次作文评分的相关性在0.457到0.679之间,因此系统评分三次作文相关性略低于人工评分(见表3)。三次作文分数的一致性检验呈现显著差异(F=3.49,P<0.05,见表4),Post-Hoc两两比较发现第一次作文与第二、三两次作文都有显著差异,而后两次作文之间没有显著差异(见表5)。

表3 系统三次作文评分的相关性和人工三次作文评分的相关性比较

表4 系统三次作文评分的差异性(One-way ANOVA)
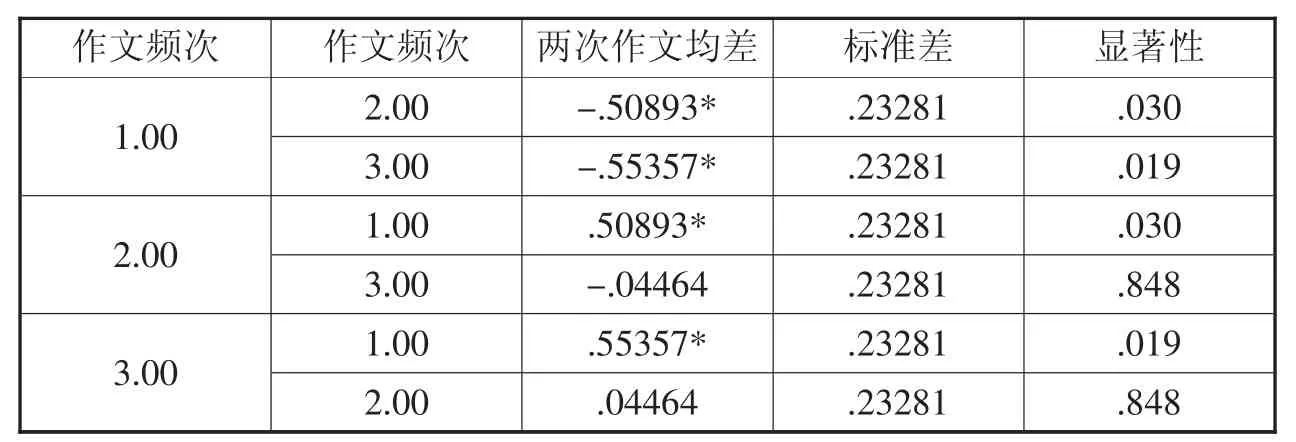
表5 系统三次作文评分差异性两两比较(Post Hoc)
4.3 外推性
将批改网第一次作文的分数与口语、听力、阅读和学习档案袋分数的相关性检验显示,系统与口语没有显著相关性,但与听力(0.446)、阅读(0.352) 以及学习档案袋(0.500) 都显著相关。而人工评分与这几项的相关性分别为0.274~0.325、0.341~0.374、0.276~0.322 和 0.427~0.471。除口语外,系统评分与听力、阅读和学习档案袋的相关性皆高于人工评分与这几项的相关性(见表6)。
5.讨论
5.1 测量性
人机三次作文的平均分之差为0.01,三次作文人机评分的完全一致性达62.50%-83.93%,完全加相邻一致性达98.21%-100%,人机评分的完全一致性虽低于IntelliMetric(87%-98%),但完全加相邻一致性高于 IntelliMetric(94%-100%)(Elliot 2003;Vantage Learning1998,1999,2001),也高于e-rater人机评分的完全一致性(56%-62%)和完全加相邻一致性(98%-99%) (Dekli 2006),因此批改网显示出较好的一致性。但是三次作文人机评分的相关性为 0.479~0.741,低于 PEG(0.72~0.78)(Page&Peterson 1995; Petersen 1997; Kukich 2000)、IEA(0.81~0.88)(Landauer et al.2000,2003;Folze et al.2013)、IntelliMetric(0.50~0.90)(Elliot 2003;Vantage Learning 1998,1999,2001)和 e-rater(0.66-0.95)(Attali&Burstein 2004;Burstein,Chodorow&Leacock 2004;Kelly 2001;Powers,Escoffery&Duchnowski 2015;Valenti et al.2003;Dekli 2006)。根据 Dikli(2006)人机评分70%完全一致性和0.70相关性,且与人机评分差别不大于0.1的标准,批改网从CET作文评分标准的5个分数档来看,其人工评分完全一致性基本达到可靠性要求。从作文的平均分来看,系统与人工评分之间的差别亦小于0.1,体现系统与人工评分有较好的一致性。当然,这也有可能是由于中等水平学生作文偏多,高分和低分段作文比较少,因此无论是人工评分还是系统评分都比较容易集中在8分档和11分档,也比较容易达到档内一致的要求。但是研究发现人机评分的相关性偏低,也就是说系统评分对每个学生分数的排名与人工评分有一定的出入,或者说有可能出现高分评低和低分评高的现象。虽然人机评分的相关性显著,但是离0.7的标准还有一定的距离。由于批改网是网上自动作文反馈系统,该系统强调对教学的辅助作用,而不是对大规模考试的评判作用,其对相关性要求往往低于用于TOFEL和GRE考试评分的e-rater系统。总之从测量性的一致性和相关性指标来看人机评分一致性较好但相关性偏低,系统体现出一定的测量性,但不如用于大规模考试评分的AWE系统。
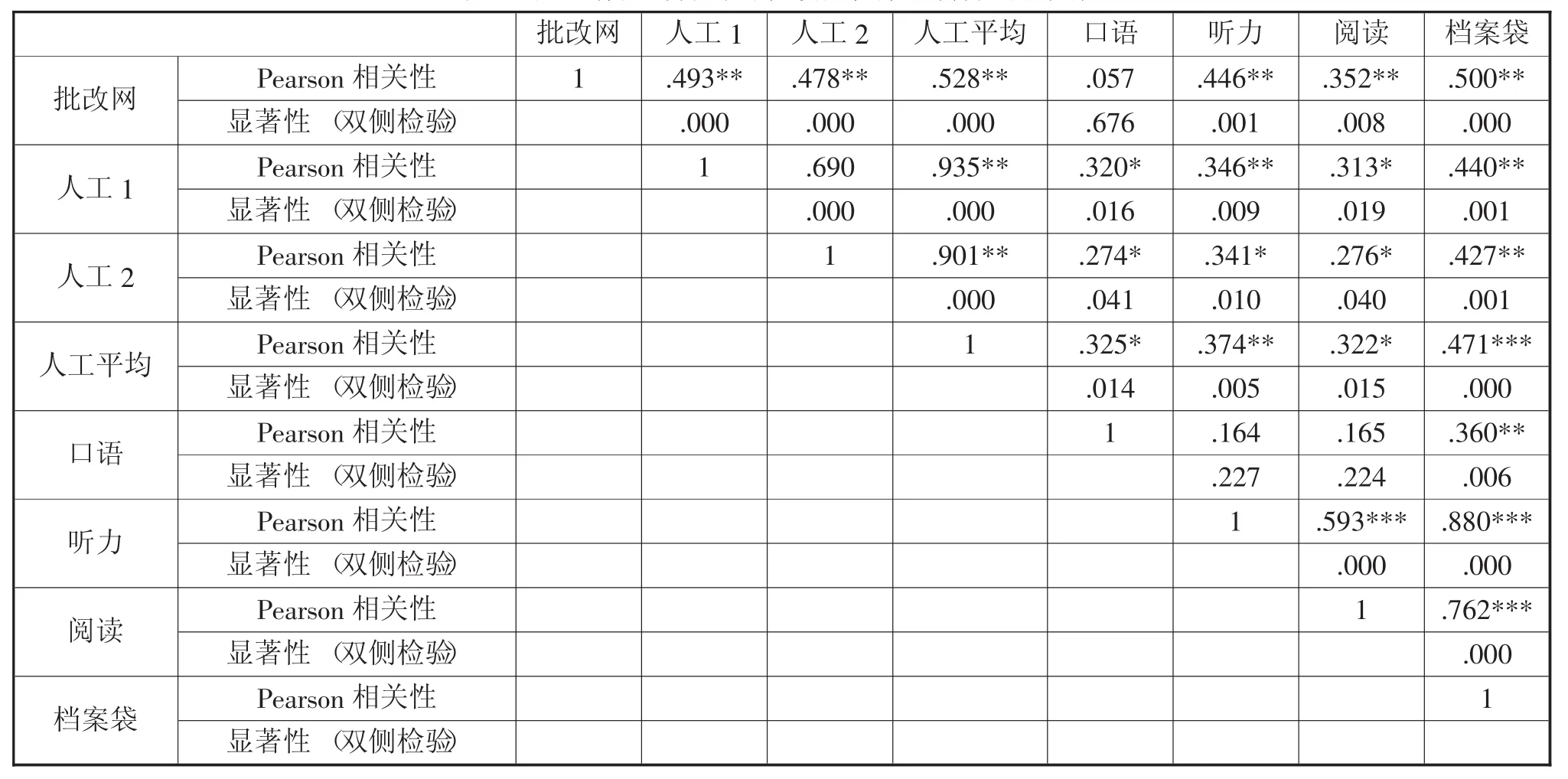
表6 人工作文评分与听说读及档案袋得分的相关性
5.2 归纳性
批改网对三次作文评分呈现显著相关性(0.403-0.498),但低于人工评分三次作文的相关性(0.457-0.679),这与国外同类研究的结果正好相反。Attali(2007) 的研究发现e-rater对两次作文评分相关性达到0.71和0.80,而人工两次评分间的相关性为0.54和0.53,也就是说E-rater的归纳性高于人工评分,而本研究发现批改网的归纳性略低于人工评分。这一方面可能在于批改网比较注重作文反馈,对评分的信度要求有所降低。另一方面国外研究从TOEFL考试中收集大量样本进行比对,而本研究则从教学角度出发,收集的教学样本数比较有限,所显示的相关性有一定局限性。从三次作文分数的一致性检验来看有显著差异(F=3.49,P<0.05),主要体现在第一次作文与后两次作文之间。这与Weigle(2011) 的研究也有所不同。Weigle在分别比较e-rater对两次不同写作任务的评分后发现系统两次评分均值没有差异。本研究第一次作文和后两次作文呈现显著差异可能是由于样本与Weigle的样本有所不同。Weigle使用的是两次TOFEL考试重复测试的样本,而本研究则使用学生在一个学期三次作文的样本。由于学生在每次作文之间有大量的课堂和课后语言输入和关于写作方法的课堂教学,同时学生还有根据批改网提供的反馈进行反复修改以及结合教师反馈进行进一步修改的过程,学生在写作水平上已经获得提升,第二次作文均分与第一次作文产生显著差异。第三次作文与第二次作文之间虽然差异不显著,但也有所提高。总之从多次作文相关性指标来看系统具有一定的归纳性,但不及国外同类AWE系统。
5.3 外推性
系统评分与口语成绩没有显著相关性,但与听力 (0.446)、阅读(0.352) 以及学习档案袋(0.500) 都呈现显著相关。体现出系统评分对听力、阅读以及总体英语学习情况具有一定的推断性。这一结果与Ramineni等(2012) 对e-rater的外推性研究结果比较一致,他们将系统评分与阅读、听力、口语成绩进行相关性检验后发现系统评分与以上各项的相关性分别为0.54、0.52、0.55,高于批改网对这几项指标的外推性。但后来Ramineni(2013)对系统与阅读和个人学习记录档案袋的相关性检验发现e-rater与阅读的相关性为0.23-0.35,与个人学习记录档案袋的相关性为0.26-0.41,低于批改网作文评分与这两项指标的相关性。Klobucar等人(2013) 的两次研究数据采集结果发现Criterion与学习记录档案袋的相关性为0.37和0.39,低于批改网与学习档案袋的相关性。Weigle(2011) 发现e-rater与学生自评的听、说、读的相关性分别为0.23、0.26、0.36,均低于批改网与这些指标的相关性。本研究说明,批改网在听力和阅读方面的外推性比很多同类AWE系统要好,但是与口语成绩不具有相关性,因此对口语指标的外推性则不明显,这可能是由于这些学生分别来自两个班级,由不同的外教实施口语考试,虽然我们要求外教有统一的评分标准,但是口语考试评分毕竟存在主观性,导致口语成绩与批改网评分以及听力(0.164)、阅读(0.165) 成绩之间的相关性都不明显,因此还需要进一步研究系统对口语成绩的外推性。
6.结论
本研究对国内自主研发的AWE系统批改网进行了测量性、归纳性和外推性效度检验,并与国外AWE系统进行了比较。研究结果发现,从测量性来看,批改网的人机评分同一分数档内的完全一致性以及完全加相邻分数档一致性与国外同类AWE系统基本相似,人机评分显著相关,但是相关性低于国外其它AWE系统。从归纳性来看,批改网对三次作文评分呈现显著相关性,但是相关性低于人工评分,也低于国外其它AWE系统。从外推性来看,批改网作文评分与听力和阅读成绩以及学习档案袋分数显著相关,且相关性高于国外其它多数AWE系统。研究也发现,批改网三次作文评分有显著差异,系统评分与口语成绩未呈现显著相关性,研究者对此进行了解释。本研究较为全面地对批改网系统的效度进行了验证,对于系统的开发、利用和改进有着积极意义。但是鉴于所使用的样本量较小,所得出的结论还有一定的局限性,今后可以在更大范围内,使用更多样本对批改网的测量性、归纳性和外推性加以研究。对于效度解释性和实用性的研究虽不是本研究涉及的范围,但相关研究也可进一步深入。
American Educational Research Association(AERA).1985.Standards for Educational and Psychological Testing[M].Washington,DC:American Psychological Association.
AttaliY.2007.Constructvalidityofe-raterinscoringTOEFLessays[R].(ETSRR-07-21).Princeton,NJ:ETS.
Attali,Y.2015.Reliability-based feature weighting for automated essayscoring[J].Applied Psychological Measurement(4):303-313.
Attali,Y.Lewis,W.&Steier,M.2013.Scoringwith the computer:Alternative procedures for improvingthe reliabilityofholistic essayscoring[J].Language Testing(1):125-141.
Attali Y,Burstein,J.2004 Automated essay scoring with e-rater V.2.[R].ETS Research Report(2):i-21.
Burstein,J.,Chodorow,M.,&Leacock,C.2004.Automated essay evaluation:The Criterion online writing service[J].AI Magazine(3):27-35.
Chapelle,C.A.,Cotos,E.&Lee,J.2015.Validity arguments for diagnostic assessment using automated writing evaluation[J].Language Testing(3):385-405.
Dikli,S.2006.An overview of automated scoring of essays[J].Journal of Technology,Learning,and Assessment(1):1-35.
Elliot,S.2003.Howdoes IntelliMetric score essay responses?[R](RB-929).Newtown,PA:Vantage Learning。
Enright,M.,&Quinlan,M.2010,Complementing human judgment ofessays written byEnglish language learners with e-raterscoring[J].Language Testing(3):317-334.
Folze,P.W.,Streeter,L.A.,Lochbaum,K.E.&Landauer,T.2013.Implementation and applications of the Inteligent Essay Assessor[A].Shermis M.D.&J.Bursteineds.Handbook ofAutomated Essay Evaluation:Current Applications and New Directions[C].NewYork,NY:Routledge:68-88.
Klobucar,A.,Elliot,N.,Deess,P.,Rudniy,O.&Joshi,K.2013,Automated scoring in context:Rapid assessment for placed students[J].Assessing Writing(1):62-84.
Kukich,K.2000.Beyond automated essay scoring[J].IEEE Inte lligent systems:The Debate on Automated Essay Grading(5):22-27.
Landauer,T.K.,Laham,D.&Foltz,P.W.2000.The Intelligent Essay Assessor[J].IEEE IntelligentSystems:The Debate on Automated Essay Grading(5):27-31.
Landauer,T.K.,Laham,D.,&Foltz,P.W.2003.Automatic essay assessment[J].Assessment in Education(3):295-308.
Messick,S.1989.Validity[A].Linn,R.L.ed.Educational Measurement(Third edition)[C].New York:American Council on Education and Macmillan,13-103.
Page,E.&N.S.Peterson.1995,The computer moves into essay grading:Updating the ancient test[J].Phi Delta Kappan(76):561-565.
Powers,D.E.,Escoffery,D.S.&Duchnowski,M.P.2015.Validating automated essay scoring:A(modest)refinement of the“Gold Standard”[J].Applied Measurement in Education(2):130-142.
Ramineni,C.,Trapani,C.S.,Williamson,D.M.W.,Davey,T.&Bridgeman,B.2012.Evaluation ofthe e-rater scoring engine for the TOEFL independent and integrated prompts[R](ETSRR-12-06).Princeton,NJ:ETS.
Ramineni,C.&Williamson,D.M.2013.Automated essayscoring:Psychometric guidelines and practices[J].Assessing Writing(18):25-39.
Valenti,S.,Neri,F.,&Cucchiarelli,A.2003.An overview of current research on automated essay grading[J].Journal of Information Technology Education(2):319-330.
Vantage,Learning.1999.Construct validity of intelliMetric with international assessment[R](RB-323).Newtown,PA:Vantage Learning,
Vantage,Learning.2001.About IntelliMetric[R](PB-540).New town,PA:Vantage Learning,
Weigle,S.C.2010.Validation ofautomated scores ofTOEFL iB T tasks against non-test indicators of writing ability[J].Language Testing(3):335-353.
Weigle,S.C.2011.Validation of automated scores of TOEFL iBT tasks against nontest indicators of writing ability[R].ETS Research Report Series(2):i-63.
Williamson,D.M.,Xi,X.,&Breyer,F.J.2012,A framework for evaluation and use of automated scoring[J].Educational Measurement:Issues and Practices(31):2-13.
Xi,X.2010.Automated scoring and feedback systems:Where are we and where are we heading[J]?Language Testing(3):291-300.
Yang,Y.,Buckendahl,C.W.,Juszkiewicz,P.J.,&Bhola,D.S.2002,Areviewofstrategiesforvalidatingcomputer-automated scoring[J].Applied Measurement in Education(4):391-412.
何旭良,2013,句酷批改网英语作文评分的信度和效度研究[J],《现代教育技术》(5):64-67。
石晓玲,2012,在线写作自动评改系统在大学英语写作教学中的应用研究——以批改网为例[J],《现代教育技术》(10):67-71。
杨晓琼、戴运财,2015,基于批改网的大学英语自主写作教学模式实践研究[J],《外语电化教学》(2):17-23。
张荔、盛越,2015,自动作文评阅系统反馈效果个案研究[J],《外语电化教学》(3):38-44。
“一带一路”国家战略背景下话语研究与语言服务高端论坛
为服务国家“一带一路”战略的实施、促进国内话语研究与语言服务水平及相关人才的培养质量,“‘一带一路’国家战略背景下话语研究与语言服务高端论坛”定于2017年12月1日—3日在广州召开。此次论坛由中国英汉语比较研究会话语研究专业委员会主办、广州大学外国语学院承办。
本次论坛主题为:服务国家“一带一路”战略,助力构建当代中国新话语。议题为:1、“一带一路”战略下中国形象的话语建构;2、“一带一路”战略下的语言服务与人才培养;3、“一带一路”沿线国家的语言与文化;4、新媒体与话语研究的新发展。论坛将特邀中国话语研究机构联盟成员代表及学者参会并做大会报告。
论坛时间:2017年12月1日13:00-22:00报到。
论坛地点:广州大学城广州大学学术交流中心。
会务费:800元/人(在读研究生减半)。
会议统一安排食宿,费用自理。与会者请于2017年10月30日前将会议回执连同论文摘要发送到邮箱:3390001548@qq.com
联系人:曾祥薇电话:13632220509贺龙会电话:13424102499 胡安奇电话:15989001498
中国英汉语比较研究会话语研究专业委员会
广州大学外国语学院
H319
A
2095-9648(2017)03-0064-08
*本文系国家社科基金项目“基于语料库和云技术的网络自动作文评阅系统信效度及其辅助教学研究”(项目号:13BYY081)的部分成果。
(张 荔:上海交通大学外国语学院副教授,博士)
2017-05-30
通讯地址:200240上海市闵行区东川路800号上海交通大学外国语学院
