基于用户自然标注的微博文本的消费意图识别
2017-10-11陈毅恒邵艳秋
付 博, 陈毅恒,邵艳秋,刘 挺
(1. 哈尔滨工业大学 计算机科学与技术学院社会计算与信息检索研究中心, 黑龙江 哈尔滨 150001;2. 北京语言大学 信息科学学院,北京 100083)
基于用户自然标注的微博文本的消费意图识别
付 博1, 陈毅恒1,邵艳秋2,刘 挺1
(1. 哈尔滨工业大学 计算机科学与技术学院社会计算与信息检索研究中心, 黑龙江 哈尔滨 150001;2. 北京语言大学 信息科学学院,北京 100083)
消费意图是指用户在文本中明确表达出的购买产品或服务等一些商业消费的意愿,如“想买一部手机”。该文针对微博上的消息文本,提出一种基于用户自然标注的微博消费意图识别方法。该方法将微博消费意图识别看作为领域自适应学习问题,通过自动获取的训练语料基于源域和目标域共同特征设计分类器,抽取置信度高的伪标注消费意图微博,再利用微博特征训练新的分类器对微博进行消费意图识别。实验结果表明该文所采用的方法是有效的,F值达到69%和77%,其中使用的各种特征对于提高消费意图识别的效果皆有帮助。
消费意图;自然标注;社会媒体;领域自适应
Abstract: Consumption Intent refers to an exact indication of an immediate or future purchase in microblog. For example, a post like “I want to buy a mobile phone” indicates a buying intention. The paper proposes to study the problem of identifying consumption intent in microblogs based on user naturally annotated resources. Specifically, the proposed method recasts consumption intent recognition as a domain adaptation problem, and presents an approach utilizing automatic acquisition of large text corpora for classification. First, we look for a set of common features generalizable across domain adaptation, and then we extract the high confidence of pseudo annotation samples. Finally, we pick up useful features specific to the target domain. Experimental results show that the proposed method is effective for consumption intent recognition, achieving 69% and 77% in F-value, respectively. And, the features adopted are all contributive to the performance.
Key words: consumption intent; naturally annotated; social media; domain adaptation
1 引言
随着网络媒体技术的发展和普及,用户乐于在互联网上搜索、发布和分享自身的消费需求,因此互联网上积累了大量的带有消费意图的内容信息。本文着重研究社会媒体(以新浪微博文本为例)中的消费意图识别,来判断用户是否对某一产品产生了购买意愿。消费意图分析是一个多学科综合的研究领域,在众多的应用场景中都有重要的意义。例如在产品推荐研究中,消费意图识别可以为用户提供精准的产品推荐,提高用户对推荐系统的满意度;在社会需求预测研究中,消费意图识别可以对产品市场容量需求及投资前景进行预先判定,以实现社会生产与社会需求之间的平衡;在社会媒体营销的研究中,消费意图识别既可用于电子商务公司挖掘用户当前需求,又有助于针对社会媒体富有价值的用户提供广告宣传,在产品策划、设计和营销过程中做到有的放矢。
图1是微博文本消费意图实例。尽管微博上有类似大量的消费意图文本,但消费意图需求表达隐藏在噪声文本和无关铺垫成分中,给标注带来干扰。幸运的是,互联网上有大量的用户自然标注 的 消 费意图文本可供使用,如查询日志中用户点击电商网站的查询、淘宝问答等基于购物知识的问答平台、电商网站用户的历史购买等,可以看作为用户自然标注的与消费相关的语料。表1为百度*www.baidu.com查询日志中的查询消费意图实例,记录了消费意图查询、点击的电商网站URL链接。

图1 微博消费意图实例

查询查询点击URL雷柏8100怎么样http://www.360buy.com/sales/...html台式机用酷睿i5好吗http://product.it168.com/list/...shtml
在以往的工作中,有学者研究搜索引擎查询日志中的查询商业意图识别[1-3](即本文定义的消费意图识别),进而将其应用到搜索引擎广告投放和竞价排名中[4]。然而查询商业意图识别在应用中也存在着几个明显的局限性。首先,研究者们通常认为热门查询词即是广告关键词,故而将广告关键词定位在热门查询中。但在实际应用中,查询仅记录了用户搜索的关键词信息,无关的噪声信息和缺失的用户信息让大多数的广告资源投入在不相关的用户中。再者是资源获取方面的限制,查询日志、广告点击等用户行为信息只能从搜索引擎公司处获取,难以实现自动抓取。相对于查询商业意图识别研究,本文所研究的微博消费意图具有以下显著的优点: 首先,微博消费意图文本中含有表示消费意图的触发词和消费对象(如图1中“想买”和“空气净化机”),意图表达更明确;其次,微博消费意图文本可以通过分析获得文本信息和用户信息,查询特征更丰富;再者,社会媒体(如新浪微博和Twitter等)提供开放的API接口,可以实时地获取微博和用户信息以供研究。因此,微博中的消费意图识别研究具有很重要的意义。
然而截至目前,国内外对消费意图识别的研究却很少。Goldberg率先提出buy wish的概念[5](即本文定义的消费意图),Chen[6]也提出过相似的概念“intention posts”。早期的一部分研究者将这项任务分为两个步骤,首先获取模板和词袋等特征,继而基于特征分类器来完成消费意图的识别[7]。这种方法大大提高了识别的准确率,但由于模板具有局限性及语料不平衡的限制,召回率不高。近期的一部分研究工作,侧重于对不平衡语料的处理,用弱监督的方法或迁移学习的方法来识别消费意图[8]。此类方法假设在不同的领域下意图表达的方式具有相似性,这种方法可以获取大规模语料或意图词来提高系统识别的性能。然而,前人方法通常需要大规模的标注语料,否则会影响学习到的分类器效果。
鉴于已有方法存在的缺陷,本文提出了一种基于用户自然标注的微博消费意图识别方法。我们将这一问题看作是领域迁移学习问题[9],利用搜索引擎搜索日志,结合伪相关反馈,实现高性能的微博消费意图识别方法。由于查询(源域)与微博(目标域)相关但并不完全相同,如何充分考虑不同领域数据之间的这种共性和特性,是基于用户自然标注的微博消费意图识别研究中需要解决的主要问题。具体来说,本文首先提出了一种自动构建大量源域训练语料的方法,继而把各个领域的数据从原始高维特征空间映射到低维特征空间,再利用大量标记的源域数据训练分类器初始目标域数据;进一步地,选择目标域数据中标记置信度高的样本作为伪标记数据,利用目标域数据特征来对其重新训练,得到新的分类器;最后对各种特征的作用进行了较为详细的分析和比较。实验结果表明,本文 提 出 的 基 于 用 户
自然标注的方法对于微博消费意图的识别是有效的。利用本方法,在微博文本测试集上的F值达到69%和77%。
2 问题描述

2.2 方法描述
本文旨在利用自然标注的搜索引擎查询消费意图语料来指导微博文本的消费意图识别。消费意图查询和微博尽管在表述上相似,但仍有区别。为此我们希望识别出源域与目标域中共有的特征表示,然后利用这些特征进行知识迁移。类似于方法[10],我们把样本类别高度相关的那些文本作为训练样本,方法框架如图2所示。其中,两个椭圆分别表示源域蓝色和目标域大字纹,阴影区域代表实例可以很好地解释分类模型。我们很希望可以由源域训练数据学习到目标域的真实标记(图2中虚线部分),但在实际中很难实现。因而我们把学习过程分成两个阶段,在第一阶段,我们利用源域和目标域共同部分训练初始分类模型;在第二阶段,利用目标域特有特征去学习适应目标域的新模型。
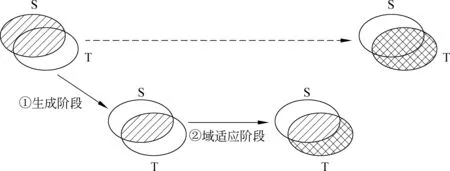
图2 两阶段的领域自适应微博消费意图识别框图
3 基于用户自然标注的微博消费意图识别
3.1 系统框架描述 本文方法的系统框架如图3所示。
在第一阶段中,首先利用源域数据和目标域数据共有部分的特征学习词向量表示,初始化学习一个分类模型,这里共有部分的特征使用了查询和微博的词特征集合,通过词向量表示方法把各个领域的数据从原始高维词特征空间映射到低维词特征空间,并对目标域数据进行初始分类;在第二阶段,从初始分类模型为目标领域标注的数据中,选择置信度高的微博标注文本作为伪标注微博消费意图文本,然后重新训练分类器,以对目标数据再次判别类别,以确定数据的真实标注类别。
3.2 基于自然标注的初始模型训练
自然标注资源,是指不同媒体用户在互联网上生成的各种资源,用户在无意中为这些资源做了一定程度的义务“标注”,如论坛、用户日志、百度百科、微博等[11]。我们主要利用了用户查询日志中的自然标注资源,基本思想是利用用户点击电商网站的查询,获取大量的具有消费意图的查询及点击标题,以此为基础训练查询的消费意图识别分类器。
为构建消费意图识别的初始训练模型,首先收集电商网站链接(URL)。电商网站链接可以从分类网站目录中抽取(为了降低噪声,本文人工定义了八类URL,见4.1.1节)。然后我们对查询以及点击的标题文本进行分词,利用词向量表示将每个词映射成k维实数向量(本文设k的值为200维),即将词表征为实数值向量,然后针对源域和目标域数据中的句子,把句中出现的每个词向量对应相加然后除以词数,得到每句话的向量特征表示。最后基于共同的语义特征在源域上训练初始分类器。
目前,基于神经网络的词向量表示(word embedding)方法在词语语义表示方面表现出很好 的 性 能,
受到广泛关注,包括Word2Vec*http: //word2vec.googlecode.com/svn/trunk,C&W 2008[12]、M&H 2009[13]、Mikolov 2013[14]等。各种词表示方法之间没有绝对的优劣之分,其性能的好坏往往取决于待处理的具体问题及待处理数据的效率要求等。本文选择目前较流行的Word2Vec的训练方法来实现词向量表示。
3.3 基于伪相关反馈的微博文本消费意图识别
基于伪相关反馈的思想,假设将上述初始分类系统返回的置信度高的文本作为消费意图类微博。微博文本一般都含有自己的结构特征,针对其特定的结构,本文在实现伪相关反馈的微博消费意图识别时共使用了四类11个特征,表2详细描述了每类特征。

表2 微博文本消费意图识别的特征描述

(2) 微博影响力特征。可以观察到,用户发布微博文本的内容与用户影响力具有一定的正相关性。认证用户通常很少发布消费意图类微博,而消费意图类微博也很少被用户大量转发和评论。此外,微博上有一些广告用户会关注大量用户,但是被关注数却很少。此外,本文采用文献[11]中提出的用户信誉度概念,作为一维特征。用户信誉度用以描述一个用户的关注行为特征,计算公式如式(1)。

(1)
(3) 微博发布特征。通常情况下,人们发布消费意图类微博时是以普通方式发布在社会媒体平台上的,而广告、活动等非消费意图的微博常利用第三方开发的微博管理应用工具定时发布,实现定时发布微博、定时转发微博等功能,这时微博平台会记录微博发布的来源,我们把微博发布源作为一种特征。
(4) 触发词特征。“触发词(Trigger)”的概念出自于事件抽取等研究领域,它是指能够清楚表达事件发生的词,如“出生”、“爆炸”等。通过分析我们发现,一个消费意图句中通常包含有两个主要元素,分别是触发词和消费对象。其中,触发词表明文本中的消费意图,而消费对象表明消费意图的目标。在本文中,我们利用依存句法工具LTP[5]来获得触发词及对应的消费对象。触发词定义由动词在消费意图句(正例)和非消费意图句(负例)中的相关频率决定。这个动词wv的相关频率的权重得分score(wv)基于式(2)计算。
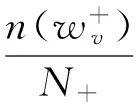
(2)

我们利用文献[11]中的触发词列表,其中包含818个触发词,分别有52个消费意图触发词和766 个非消费意图触发词。表3列出了top-k个触发词,可以看出消费意图触发词中“求购”、“想买”、“推荐”等都是很强烈的购买意愿。在非消费意图触发词中,如“免费”、“参加”、“转发”等与消费意图没有明显的关系。
触发词特征实例如图4所示。

表3 消费意图触发词和非消费意图触发词实例

图4 触发词相关特征实例
4 实验设置
4.1 实验数据 本文在新浪微博用户发布的微博文本内容集合上进行了构建大规模消费意图语料的相关实验。在种子语料集合中,本文使用了百度搜索引擎记录的查询日志数据集合。实验使用的微博语料数据集合和查询日志集合分别来自于利用微博API自动抓取的2012年3月的11 854 002条微博数据和百度2012年3月共1个月1亿条查询。其中,微博数据记录了微博文本相关信息及其对应的用户信息。百度查询日志中包含三部分内容,分别是查询、查询点击的URL及查询点击的标题。
4.1.1 种子数据准备
在本文实验中选取了八个网站作为消费意图查询点击的链接,并从百度查询日志中抽取出点击了相关网站的查询作为消费意图查询(本文仅进行信息类的消费意图研究,因而过滤了导航类和事务类查询),训练集合中的URL列表如表4所示。此外,我们随机抽取60 000条查询作为非消费意图查询。

续表

表4 训练集合中URL列表
4.1.2 微博文本数据预处理
本文对微博语料进行了两方面的数据预处理。一是使用文献[2]中的方法对垃圾微博文本进行过滤。二是为使数据正负比例平衡,我们选取了必须包含本文定义的四类产品名称的微博文本作为处理对象。表5中列出了经过上述数据预处理后,利用四个领域词表抽取出的微博数量。
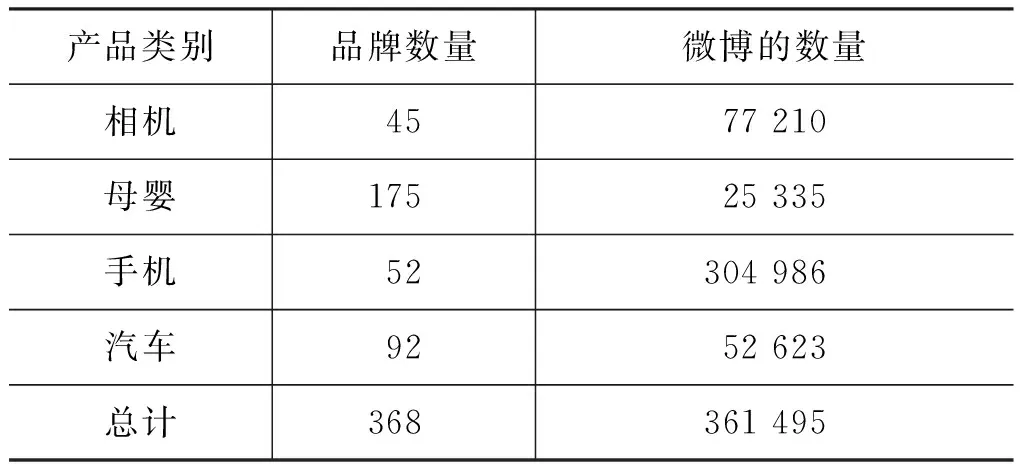
表5 四个领域产品类别对应的微博数量
4.1.3 测试数据集
由于二元分类的方法需要测试语料,而目前国内外并没有公开发布的相关语料,因此,本实验通过人工标注的方法构建测试集。我们从微博语料中随机抽取出5 000条微博,将其交由两名标注者和一名仲裁者进行标注。其标注流程为: (1)由两名标注者分别对抽取出的数据进行独立标注,每一条候选微博消费意图文本被标注为正例(消费意图)或负例(非消费意图); (2)计算两名标注者的标注一致性,我们通过计算得到两组标注结果的Kappa值为0.861,这说明两名标注者的一致性很高; (3)由仲裁者对两名标注者意见不同的数据进行重新标注,并将其标注作为最终标注结果。依照上述过程,我们共从5 000条微博文本中过滤广告后进行标注,得到正例和负例分别是431条和2 530文本。
4.2 评价方法
我们首先利用上述标注数据对本文提出的分类特征进行评价。这里我们采用的评价指标包括准确率P、召回率R以及F值F。具体定义为:P=|A∩B|/|A|;R=|A∩B|/|B|;F=2PR/(P+R)。其中,A表示分类器识别为正例的数据集合,B表示人工标注为正例的数据集合。
4.3 对比实验系统
为证明跨领域消费意图识别中的有效性,我们将其与利用词袋特征训练的SVM分类器进行了对比。本实验所使用的SVM分类器为libsvm-2.82*http: //www.cite.nt.deu.tw/cjlin/libsvm,我们利用词向量(bag-of-words)特征在自动标注的查询日志消费意图数据集上对SVM分类器进行实验,并在微博文本测试集上进行分类。
• SVM-Q(BOW): 利用源域中的查询词项作为训练语料构建分类器。
• SVM-T(BOW): 利用源域中的查询点击标题中的词项作为训练语料构建分类器。
• SVM-QT(BOW): 利用自然标注语料中的查询以及查询点击的标题中的词项作为训练语料构建分类器。
• SVM-QT(BOW-Word2Vec): 利用大规模的查询及查询点击的标题中的词项训练一个词向量表示。这里,我们用Word2Vec将单词转换成向量形式,然后对每一条文本中的词向量加和求平均,来表示每条文本词向量特征。利用查询及点击标题中的词项和词向量表示作为特征构建分类器。
5 实验与分析
5.1 基于用户自然标注的微博消费意图识别方法 的评价 为考察本文所使用的自然标注的语料是否对微博消费意图识别产生作用,我们对在4.3节提出的基准方法进行了对比,其实验结果见表6。从表6中我们可以看到,对于仅利用查询词特征,即表6中的SVM-Q(BOW)基线实验时,系统的性能很低,主要是由于查询是关键词的意图表示方式,与微博文本的自然语言表示方法有着明显区别。而查询点击的标题相当于一种自然语言的表示方式,因而性能会随之提升,当随着查询词项和点击标注词项加入到训练语料中,分类F值达到63.32%。这说明本文所使用的基于自然标注的训练语料对于提高二元分类的性能是有帮助的。也就是说,查询关键词和点击标注关键词均有助于微博消费意图的识别。在此基础上,当加入词表示特征(Word2Vec)后,系统的性能有了进一步的提升,这也证明了本文提出方法的有效性。

表6 基于自然标注的微博消费意图识别
5.2 基于弱指导的微博消费意图识别方法的评价
上面的实验验证了领域自适应学习方法的有效性。接下来,我们通过实验考察在目标域数据标记判别学习时本文使用的四类特征是否对微博消费意图识别都有作用,我们进行了四组实验,每组实验依次加入基于视觉的特征、影响力特征、发布特征、微博触发词特征,其实验结果如表7所示。从表7中可以看到,随着加入每一类特征,分类的F值都有明显提高。尤其是当使用全部四类特征时,分类准确率、召回率和F值均达到最高。这一结果说明本文所采用的四类特征对于提高二元分类的性能都是有帮助的。也就是说,全部四类特征均有助于微博文本消费意图的识别。
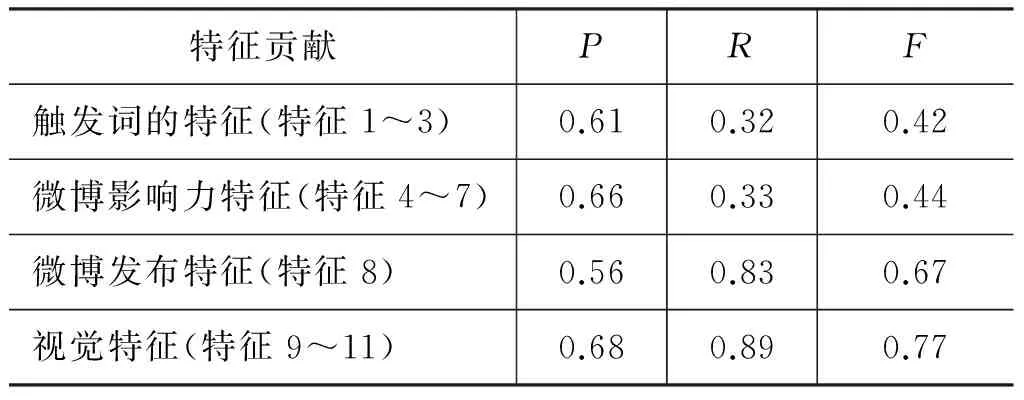
表7 四类特征的贡献
6 结论与展望
本文首次提出基于用户自然标注的消费意图识别方法,并将此方法作为一个领域自学习问题加以研究。具体的,文章的贡献可以总结为以下几个方面: (1)提出一种自动生成查询消费意图识别训练语料的方法,解决了有指导方法需要大量人工标注训练数据的问题,并且通过实验验证了自动获取和标注的训练数据的质量; (2)基于半监督的方法自动标注了大规模无标注数据集,解决了对无标注语料进行自动标注的困难,并且通过实验验证了方法的有效性; (3)在对目标领域的模型构建中,尝试了多种特征,既包括前人使用过的基于文本内容特征,又包括本文提出的基于视觉特征和用户信息特征。本文对多种特征加以融合、比较和分析,希望其结论对后续的研究有所裨益。
[1] Dai H K, Zhao L,Nie Z, et al. Detecting online commercial intention (OCI)[C]//Proceedings of the 15th international conference on World Wide Web. ACM, 2006: 829-837.
[2] Ashkan A, Clarke C L A. Term-based commercial intent analysis[C]//Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval. ACM, 2009: 800-801.
[3] 陈磊, 刘奕群, 茹立云, 等. 基于用户日志挖掘的搜索引擎广告效果分析[J]. 中文信息学报, 2008, 22(6): 92-97.
[4] Jansen B J. The comparative effectiveness of sponsored andnonsponsored links for Web e-commerce queries[J]. ACM Transactions on the Web (TWEB), 2007, 1(1): 3.
[5] Goldberg A B, Fillmore N, Andrzejewski D, et al. May All Your Wishes Come True: A Study of Wishes and How to Recognize Them[C]//Proceedings of Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics. 2009: 263-271.
[6] Z Chen, B Liu, M Hsu, et al. Identifying intention posts in discussion forums[C]//Proceedings of the HLT-NAACL, 2013. 1041-1050.
[7] Yang H, Li Y. Identifying user needs from social media[R]. IBM Tech Report. goo.gl/2XB7NY, 2013.
[8] Fu B, LIU T. Weakly-supervised consumption intent detection in microblogs[J]. Journal of Computational Information Systems, 2013, 6(9): 2423-2431.
[9] 庄福振,罗平,何清,史忠植.迁移学习研究进展[J].软件学报,2015,26(1): 26-39.
[10] Jiang J,Zhai C X. A two-stage approach to domain adaptation for statistical classifiers[C]//Proceedings of the sixteenth ACM conference on Conference on information and knowledge management.ACM, 2007: 401-410.
[11] 孙茂松. 基于互联网自然标注资源的自然语言处理[J]. 中文信息学报, 2011, 25(6): 26-32.
[12] Collobert R, Weston J. A unified architecture for natural language processing: Deep neural networks with multitask learning[C]//Proceedings of the 25th international conference on Machine learning. ACM, 2008: 160-167.
[13] Mnih A, Hinton G E. A scalable hierarchical distributed language model[C]//Advances in neural information processing systems. 2009: 1081-1088.
[14] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv: 1301.3781, 2013.
[15] Q Liu, Y Wang, J Li, et al. Predicting user likes in online media based on conceptualized social network profiles.//Web Technologies and Applications.Springer, 2014: 82-92.

付博(1983—),博士,主要研究领域为社会计算,自然语言处理、信息检索。
E-mail: bfu1983@163.com

陈毅恒(1979—),博士,讲师,主要研究领域为社会计算、自然语言处理、信息检索。
E-mail: yhchen@ii.hit.edu.cn

邵艳秋(1971—),博士,主要研究领域为自然语言处理、语言监测、社会计算。
E-mail: yashao@pku.edu.cn
Consumption Intent Recognition Based on User Natural Annotation
FU Bo1, CHEN Yiheng1, SHAO Yanqiu2, LIU Ting1
(1. Research Center for Social Computing and Information Retrieval, School of Computer Science and Technology, Harbin Institute of Technology, Harbin, Heilongjiang 150001, China;2. School of Information Sciences, Beijing Language and Culture University, Beijing 100083, China)
1003-0077(2017)04-0208-08
TP391
A
2015-10-20 定稿日期: 2016-04-08
国家青年科学基金(61202277);国家自然科学基金(61170144,61472107)
