基于Spark的大规模文本k-means并行聚类算法
2017-10-11滕家雨丁恩杰
刘 鹏, 滕家雨,丁恩杰,孟 磊
(1. 中国矿业大学 物联网(感知矿山)研究中心,江苏 徐州 221008;2. 矿山互联网应用技术国家地方联合工程实验室,江苏 徐州 221008;3. 中国矿业大学 信息与电气工程学院,江苏 徐州 221116)
基于Spark的大规模文本k-means并行聚类算法
刘 鹏1,2, 滕家雨1,3,丁恩杰1,2,孟 磊1,2
(1. 中国矿业大学 物联网(感知矿山)研究中心,江苏 徐州 221008;2. 矿山互联网应用技术国家地方联合工程实验室,江苏 徐州 221008;3. 中国矿业大学 信息与电气工程学院,江苏 徐州 221116)
互联网文本数据量的激增使得对其作聚类运算的处理时间显著加长,虽有研究者利用Hadoop架构进行了k-means并行化研究,但由于很难有效满足k-means需要频繁迭代的特点,因此执行效率仍然不能让人满意。该文研究提出了基于新一代并行计算系统Spark的k-means文本聚类并行化算法,利用RDD编程模型充分满足了k-means频繁迭代运算的需求。实验结果表明,针对同一聚类文本大数据集和同样的计算环境,基于Spark的k-means文本聚类并行算法在加速比、扩展性等主要性能指标上明显优于基于Hadoop的实现,因此能更好地满足大规模文本数据挖掘算法的需求。
k-means;并行化;文本聚类;Spark;RDD;Hadoop;MapReduce
Abstract: Due to sharp increase of internet texts, the processing of k-means on such data is incredibly lengthened. Some classic parallel architectures, such as Hadoop, have not improved the execution efficiency of K-means, because the frequent iteration in such algorithms is hard to be efficiently handled. This paper proposed a parallelization algorithm of k-means based on Spark. It makes full use of in-memory-computing RDD model of Spark so as to well meet the frequent iteration requirement of k-means. Experimental results show that k-means executes much more efficiently in Spark than in Hadoop on the same datasets and the same computing environments.
Key words: k-means;parallelization;text clustering;Spark;RDD;Hadoop;MapReduce
收稿日期: 2015-02-05 定稿日期: 2015-03-30
基金项目: 国家自然科学基金(41302203)
1 引言
随着互联网信息量的迅猛增加,如何对海量网络文本信息进行有效处理及价值挖掘已成为当今中文信息处理的研究热点之一,大规模文本聚类便是其中一个重要的研究领域。由于在互联网信息海洋中,人们不会事先对数据进行类别标注,也无法确定数据应归属的类别总数,这样就很难采用基于类别标注的挖掘算法(如支持向量机)对数据进行处理。而聚类技术[1]不需要知道数据的类别标注,也不需要任何训练数据,便可以直接对目标数据集进行挖掘处理,其应用更加便捷、高效。在互联网大规模信息挖掘处理中,聚类可应用于文本语义分析、文档相似性分析、语料分类分析及主题分析等多个领域[2-4],另外,在很多算法的预处理阶段,例如文本分割及多文档文摘抽取,聚类技术也可以发挥重要的作用。但是目前可用的聚类算法基本都仅适于处理小规模的数据,而在当今互联网信息爆炸的背景下,网络数据文档数量呈指数性增长,文本特征空间的维度也急剧增大,这都会严重降低聚类算法的类别划分能力,同时也大大延长了算法的运行时间,这显然不适合实际应用。因此,如何能够对大规模文本数据进行快速、有效的并行聚类计算,将是一个很有价值的研究方向。
作为传统的并行计算方法,20世纪末出现的MPI(message passing interface)[5]、21世纪初出现的网格计算[6]等,存在开发复杂、扩展性不好等问题,已无法满足日益增长的互联网大规模数据处理的需求。面对挑战,“云计算[7]” 应运而生,Map-Reduce(MR)即是其最受关注的关键技术之一。Map-Reduce是由Google公司开发的一个用于大规模数据处理的分布式计算模型[8-10],具有编程简单、易于扩展、容错性好等特点,极大地简化了集群上的海量数据并行处理实现。除Google外,MapReduce已有多种实现版本,其中最经典的是Hadoop[10],它是一个由Java语言编写的开源分布式计算框架,提供了以MapReduce为核心的编程接口和分布式文件系统HDFS(Hadoop distributed file system),能够处理多至百万个节点和ZB量级的数据。
但是越来越多的研究证明[11-12],Hadoop的MapReduce计算模型比较简单,适合数据量大但核心计算并不复杂的处理作业,而对于较复杂的计算模型,譬如递归、迭代、嵌套调用等,利用MapReduce实现不但编程复杂,而且处理效率也很难让人满意。下面以迭代计算为例说明MapReduce模型的局限性。
目前为止,我们能看到的MapReduce版本实现都没有针对迭代计算进行相应优化,在运行迭代型作业时,存在以下四个主要问题[12]:
(1) 尽管每次迭代所进行的操作都一样,但每一次迭代都是作为独立作业(job)重新进行处理,需要重新初始化和读写、传输数据,这会导致大量不必要的系统开销。
(2) 虽然大量数据在迭代循环时很可能是不变的,但在每次迭代时仍会被重新载入和处理,这将浪费掉大量的I/O、CPU资源和网络带宽。
(3) 每次迭代都需要一个额外的MapReduce Job作业来检测迭代终止条件,这又会消耗掉额外的任务调度、磁盘数据读取和网络传输。
(4) 必须在前一次迭代全部结束,输出数据全部写入分布式文件系统,并完成迭代终止条件检测之后,下一次迭代才可以开始,而下一次迭代又需要先从分布式文件系统读取数据,这使得数据的读写过于集中,而相对应地,空闲时的系统I/O、CPU和网络带宽等资源则被浪费掉了。
因此,MapReduce在进行迭代型数据处理时性能比较低下,而迭代计算在数据处理中是一类非常重要的应用模型,尤其在数据挖掘、信息检索、机器学习等领域,大量算法都是运用多次迭代实现的[13]。作为主要创作动机之一,基于内存计算的新一代并行计算框架Spark[14],力求能很好地解决此类频繁迭代问题。本文提出了基于Spark的k-means本文聚类算法并行设计与实现,并使用相同样本集、计算环境进行实验,对比分析Hadoop和Spark环境下的并行k-means文本聚类算法执行效率及性能差异,对并行聚类技术在大规模文本分类中的作用做了有益的探讨。
本文后续部分安排如下,首先介绍文本聚类整体流程及k-means串行算法,接着分别设计及实现了基于Hadoop和Spark的k-means并行化算法,最后通过实验在加速比、扩展比等主要性能指标上进行比较并得出实验结论。
2 文本聚类整体流程
为了能够对文本信息进行聚类分析,必须首先对非结构化文本进行预处理,包括分词、去停用词、词频统计、特征降维和构建文本表示模型等步骤,需要量化为数值的形式才能便于计算机进行聚类分析,整个文本聚类分析流程如图1所示,这其中由于聚类分析需要频繁迭代,因此会占据大部分处理时间,

图1 文本聚类分析整体流程
所以本文的重点是研究如何通过并行处理提高聚类分析部分的效率。在此之前,先简要介绍下预处理阶段的工作内容(本文文本聚类预处理使用的工具包为中科院计算所研发的ICTCLAS分词系统)。
2.1 文本聚类预处理
文本主要记录和存储文字信息,是非结构化的数据,不能直接对文本信息进行数据挖掘处理,应该对文本信息进行预处理,最终把文本信息转化为一种结构化的形式(便于计算机处理),然后再对预处理数据进行聚类。文本预处理是聚类分析的首要步骤,预处理的质量直接决定着聚类分析的效果。预处理过程的一般步骤包括分词、去停用词、词频统计、特征选择。
预处理的第一个关键步骤就是分词[15]。不同于英文文本,在中文文本中,词与词之间是连续的,没有空格间隔,因此必须对文本进行分词处理。所谓分词,就是将文档按照词的含义进行切分。在文本信息处理的过程中,可以用字、词或者词组作为文本的特征项。但是用字作为特征项会导致特征向量维数庞大,并且字所包含的信息量有限。词组虽然包含信息量多,但是在文本中出现的频率极少,用词组作为特征向量会导致特征向量稀少。因此,选用词作为特征向量既能够包含足够的信息,又能够得到较合适的特征维数。
文本聚类中,从文本得到的单词集还不能作为特征集来表示文本,因为它包含文本集各类文本中普遍出现的通用词和弱词性词,这些停用词几乎出现在任何一个文本中,但是对表达文本内容几乎没有任何贡献,这些词更多的作用是在语法上,被称为停用词。因此,需要建立一个停用词表,并按照此表从单词集中过滤掉所有的停用词,从而降低特征空间维数,减少噪声。
2.2 文本表示
文本是一种无结构的数据,要进行聚类,必须把文本表示成为计算机能够识别和处理的形式。本文采用最常用的向量空间模型(VSM)[16],向量的每一维由特征项及其权重组成,特征项的权重用TF-IDF[17-18]方法来计算:
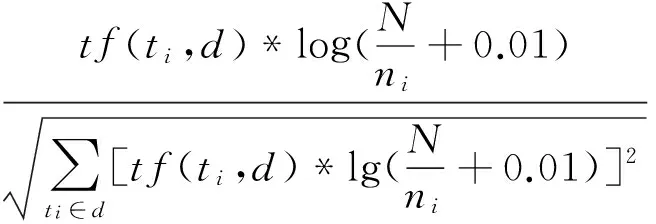
(1)
其中,w(ti,d)为特征项ti在文档d中的权重;tf(ti,d)为特征项ti在文档d中的词频;N为训练文本的总数;ni为训练文本集中出现特征项ti的文本数,分母为归一化因子,即文档dj的向量化表示,为dj=(tj1:wj1,tj2:wj2,…,tji:wji,…,tjm:wjm),即tji表示第j个文档的第i个特征项,wji表示该特征项的权重,m表示向量中特征项的个数。
3 串行k-means文本聚类算法
串行k-means聚类算法[19]基本思想如下: 以空间中的k个点为聚类中心,对最靠近它们的对象归类,具体计算过程通过迭代的方法,逐次更新各聚类中心的值,直到最后收敛得到最优的聚类结果,其目的就是为了使簇内数据对象之间的相似性尽可能大,而簇间数据对象的相似性尽可能小。在每次迭代后需验证聚类的准则函数是否收敛来确定算法是否应该结束,如果不收敛,就继续对数据对象进行聚类;否则,聚类完成,算法结束。
运用k-means算法进行文本聚类,首先需要对文本建立文本表示模型,向量空间模型是一种常用的文本表示模型。VSM模型用向量表示文本,文本转换成向量数据,可以利用k-means算法实现文本聚类。算法具体描述如下:
输入: 文本向量集D={d1,d2,…,dn},聚类个数k
输出:k个聚类
(1) 从文本向量集D中随机选取k个向量作为k个聚类的初始中心;
(2) 在第c次迭代中,对任意一个向量di,求其到k个中心的相似度,将di归到最相似的类;
(3) 利用均值方法更新该类的中心值;
(4) 对所有的k个聚类中心,利用上述两步的迭代更新后,求得式(4)的J值,若不再发生明显变化,则判定收敛,迭代结束;或者达到设定的最大迭代次数,迭代也结束。否则转(2)继续迭代。
k-means算法用来计算文本向量相似度的标准通常是使用欧氏距离,其定义如下:
(2)
其中,x=(x1,x2,…,xp)和y=(y1,y2,…,yp)是数据集中两个p维的数据对象。
更新聚类中心的计算方法,定义如下:
(3)
其中,Ci表示某个簇,m表示属于Ci簇的数据个数。
评价k-means划分聚类效果的聚类准则函数J定义为:
(4)
4 基于Hadoop的k-means文本聚类算法并行化
基于Hadoop的核心就是将串行的k-means任务通过MapReduce模型进行并行化设计,由于Hadoop没有针对迭代计算作特殊优化,在使用MapReduce模型求解问题时,运行一趟MapReduce过程无法完成整个求解过程。将串行算法的每次迭代设计成一趟MapReduce过程,也就是一个k-means作业[20]。每次迭代完成样本数据到聚类中心的计算及聚类中心的更新。聚类整体迭代过程中,需要进行多次MapReduce过程,直到满足迭代条件。
图2描述了MapReduce主程序首先从HDFS读取数据集并进行采样随机生成k个样本作为初始聚类中心,之后启动相应的k-means作业。每次迭代计算过程包括Map和Reduce两部分,Map执行局部操作,进行数据对象的本地局部划分聚类,Reduce接收来自Map的中间结果,汇总操作执行全局的聚类,计算并更新该类的聚类中心,具体实现如算法2-1所示。当一次迭代计算完成后,根据当前输出结果执行收敛条件判断。如果聚类结果未达到收敛条件,Hadoop会再次启动新的k-means作业,把上一次MapReduce任务的输出作为当前任务的输入,重复执行,直到结果满足收敛条件或者达到最大迭代次数为止[21]。
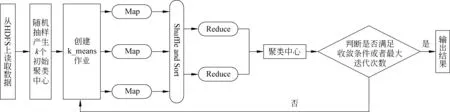
图2 基于Hadoop的k-means并行算法实现总流程图
算法2-1 k-means作业的MapReduce化算法
Map部分
输入: 中心点列表,数据对象的偏移量,数据对象
输出:
FOR每个文本向量i=1,…,ndo:
FOR每个聚类中心j=1,…,kdo:
计算每个文本向量与每个聚类中心相似度;
比较上述相似度;
将此向量归纳到相似度高的那个聚类中心所属的类;
将<所属类别,数据对象>写入中间文件;
Reduce部分
输入:
输出:
FOR对于key相同的所有文本向量(它们属于同一个簇):
求所有文本向量的均值,得出新的聚类中心
输出新的聚类中心
5 基于Spark的k-means文本聚类算法并行化
5.1 Spark架构和弹性分布式数据集RDD Spark由加州大学伯克利分校AMPLab开发,主要目的是用来构建大型的、低延迟的数据分析应用程序,由于引进了弹性分布式数据块RDD(resilient distributed dataset)[22]的概念,Spark可在集群计算中将数据集分布式缓存在各节点内存中,省去大量的磁盘IO操作,从而大大缩短访问延迟。作为Spark架构的核心机制,RDD是一种基于分布式内存的并行数据结构,它能将用户数据存储在内存中,并控制分区划分以优化数据分布。数据存储在内存中,尤其对于需要多次迭代使用的数据,省去了多次载入到内存和存储到磁盘的过程,大大加快了处理速度。Spark支持RDD的显式缓存(cache)及持久化(persistence)存储,即在初次使用RDD时,可以将所需数据对象缓存在本地内存,而且可以将RDD对象持久化到本地文件系统或HDFS中。
Spark运行架构如图3所示,在该图中描述了当一个应用程序在Spark集群上运行时的基本组成部分。驱动程序用来协调集群上任务执行调度,可以与三类集群资源管理器(Standalone、Mesos或YARN)相连接,本文选择的是Standalone模式,集群资源管理器的作用为在不同Spark应用间分配资源。Spark在执行程序时,需要将应用代码发送给工作节点的执行器去执行任务,以尽可能实现数据的本地化计算[23]。
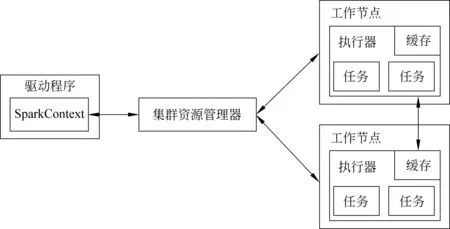
图3 Spark运行架构图
与上文所述的Hadoop处理迭代运算的方式不同,利用新一代并行计算机架构Spark实现k-means,只需将迭代计算的数据块定义为RDD,以分区(partitions)的形式分布存储在不同节点的内存中,再由位于这些节点的任务针对本地内存分区重复完成迭代计算即可,中间完全无需和磁盘进行交互,从而大大加快执行速度,这也是以RDD内存计算为核心的Spark的最大优势。
5.2 基于Spark的k-means文本聚类并行化设计
利用Spark并行实现k-means,总体上也是采用“Map”和“Reduce”的思想,即在每次迭代中,先用“Map”计算所有样本和中心点距离并归类,再用“Reduce”分类求均值算得新的中心点。然而与Hadoop的MapReduce最大的不同是,Spark对所有中心点的所有次迭代运算都在内存中对RDD计算完成,中间不需要与磁盘交互,而Hadoop的这个过程则要与磁盘有(迭代次数×分类数)次的交互[21]。
基于Spark的k-means文本聚类在实现时,先从HDFS上读取所有的数据(已经预处理过的文件)并形成RDD对象,由于这些数据不只使用一次,所以可在本地缓存RDD数据以便下次直接使用。之后进行Map操作,对本地局部数据按类划分,Reduce操作汇总中间结果数据,计算得到全局的聚类中心。聚类算法的并行化执行由Spark框架自动完成,自动将数据集及执行任务分配到不同工作节点,并行执行聚类计算,Spark并行化的核心就是使用RDD,算法在逻辑上与串行算法差不多。算法总流程如图4所示。
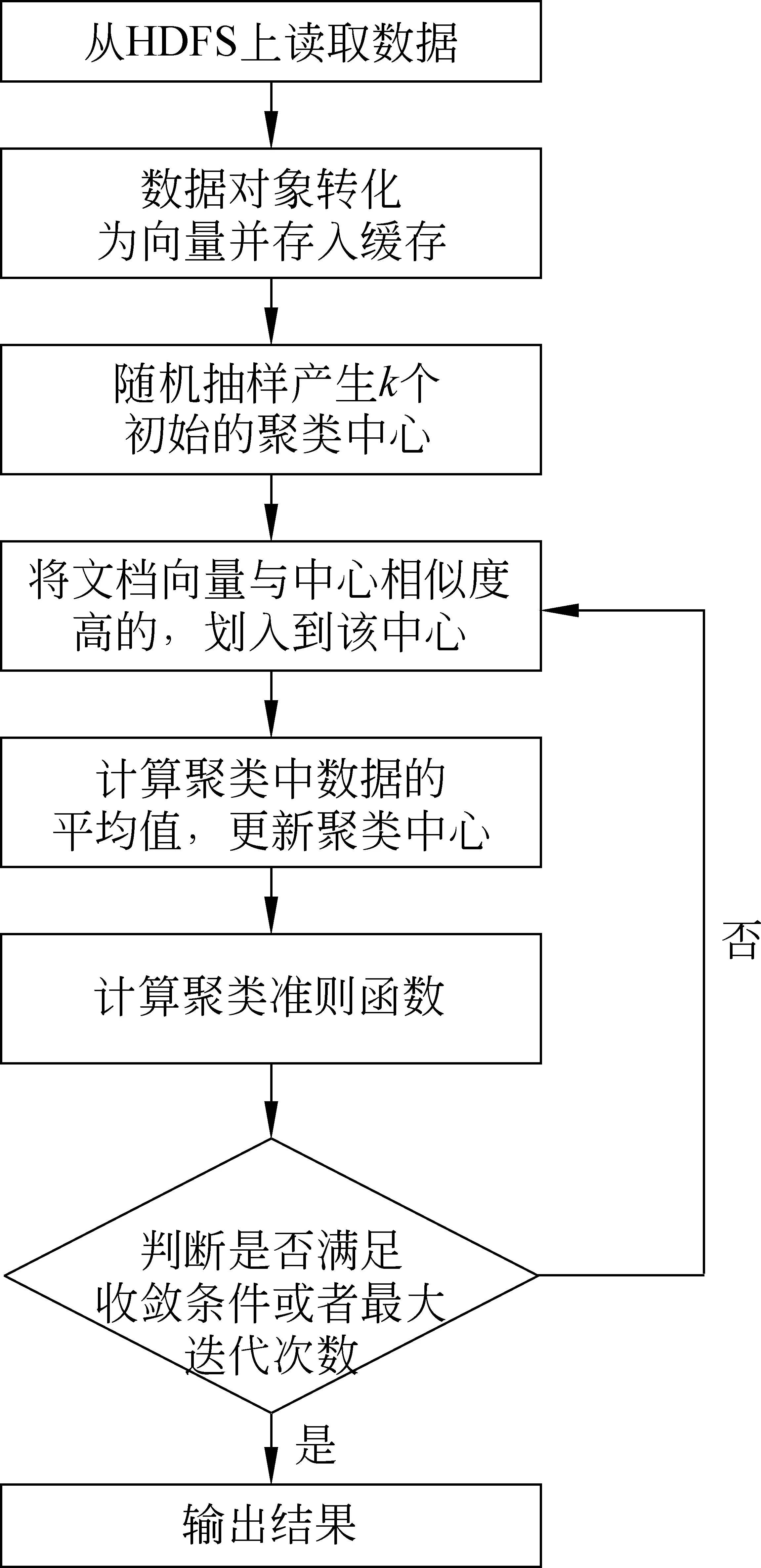
图4 基于Spark的k-means算法总体流程图
5.3 基于Spark的k-means文本聚类算法并行化实现 Spark实现k-means并行化算法如算法3-1所示,首先执行Spark集群环境的初始化;从HDFS中载入原始数据,创建形成Hadoop RDD对象,对RDD进行Map生成新的RDD对象,并用cache操作将其缓存于各worker节点本地内存;而后在各worker节点先执行算法中(1)~(5),完成第一轮迭代,接着重复执行(2)~(5),直到满足收敛条件或者到达最大迭代次数,聚类操作结束。
算法3-1 基于Spark的k-means算法
程序输入: Context(arg0),Input(arg1),numSplits(arg2),k(arg3),convergeDist(arg4),MaxIter(arg5)。其中Context为Spark环境参数,Input为数据集输入路径,numSplits为数据的分片数, K为聚类个数,convergeDist为聚类准则值J,MaxIter为最大迭代次数
程序输出:k个聚类中心。核心步骤如下:
(1) 随机抽样产生k个初始的聚类中心:
o1~ok∈文档向量集D
(2) FOR j=1 tondo:
计算所有的RDD文本向量与k个聚类中心的相似度d(xi,yj),并得出最近的聚类索引号,格式形如(id,(point,1))
(3) FORi=1 tokdo:
(5) untilJ不再发生明显变化或者达到最大迭代次数
Spark实现k-means并行化的代码使用scala语言编写,Scala语言表现力强大,代码相比Java、C#等要简洁许多[24]。算法3-1所用Scala主要代码解释如下:
1. Spark集群环境的初始化
1. val sc=new SparkContext(args(0), "SparkK-Means")
2. 从HDFS读入已处理过的文本向量
2. val lines=sc.sequenceFile[Text,VectorWritable](args(1),args(2).toInt)
3~5. 输入参数赋值给相应变量
3. valK=arg(3)
4. val convergeDist=arg(4)
5. val MaxIter=arg(5)
6. 将每个数据点RDD化
6. val data=lines.map{ case (category,instances)=>
(category.toString.split("/")(1),Vectors.sparse(instances.get.size,instances.get.all.asScala.map(_.get).zipWithIndex.map(e => (e._2,e._1)).filter(_._2!=0.0).toArray))}.cache()
7. 随机抽样产生k个初始聚类中心
7. varkPoints = data.takeSample(false,K, 42).map{ pair => pair._2}.toArray
8~9. 聚类准则比较变量和迭代次数中间变量的初始化
8. vartempDist = 1.0
9. var tempIter=0
10. 实现算法3-1中(2)~(5)部分,为k-means核心代码,具体如下:10.0 当聚类准则比较变量大于聚类准则值,并且迭代次数不到最大迭代次数时,执行循环内容{10.1求数据的局部聚类,通过closestPoint函数求得文本向量p与哪个类中心相似度高,标记所属类别,每个点p映射成(id,(point,1))。10.2 pointStats对相同id的向量p进行归约求和,为(point特征值求和,point数量和)。10.3 newPoints是所求的新聚类中心点,键值对形如(id,point特征值求和/ point数量和)。10.4 tempDist聚类准则变量置零。10.5 新旧中心点的差平方和。10.6 更新聚类中心。10.7 已迭代次数更新。}
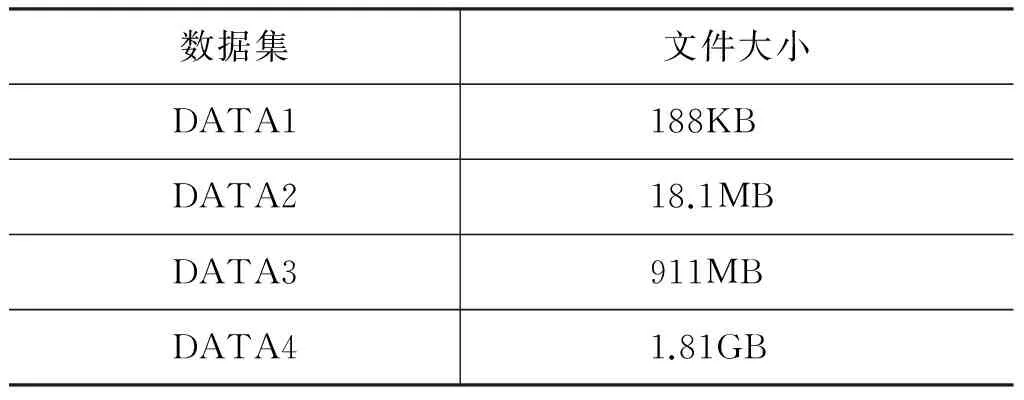
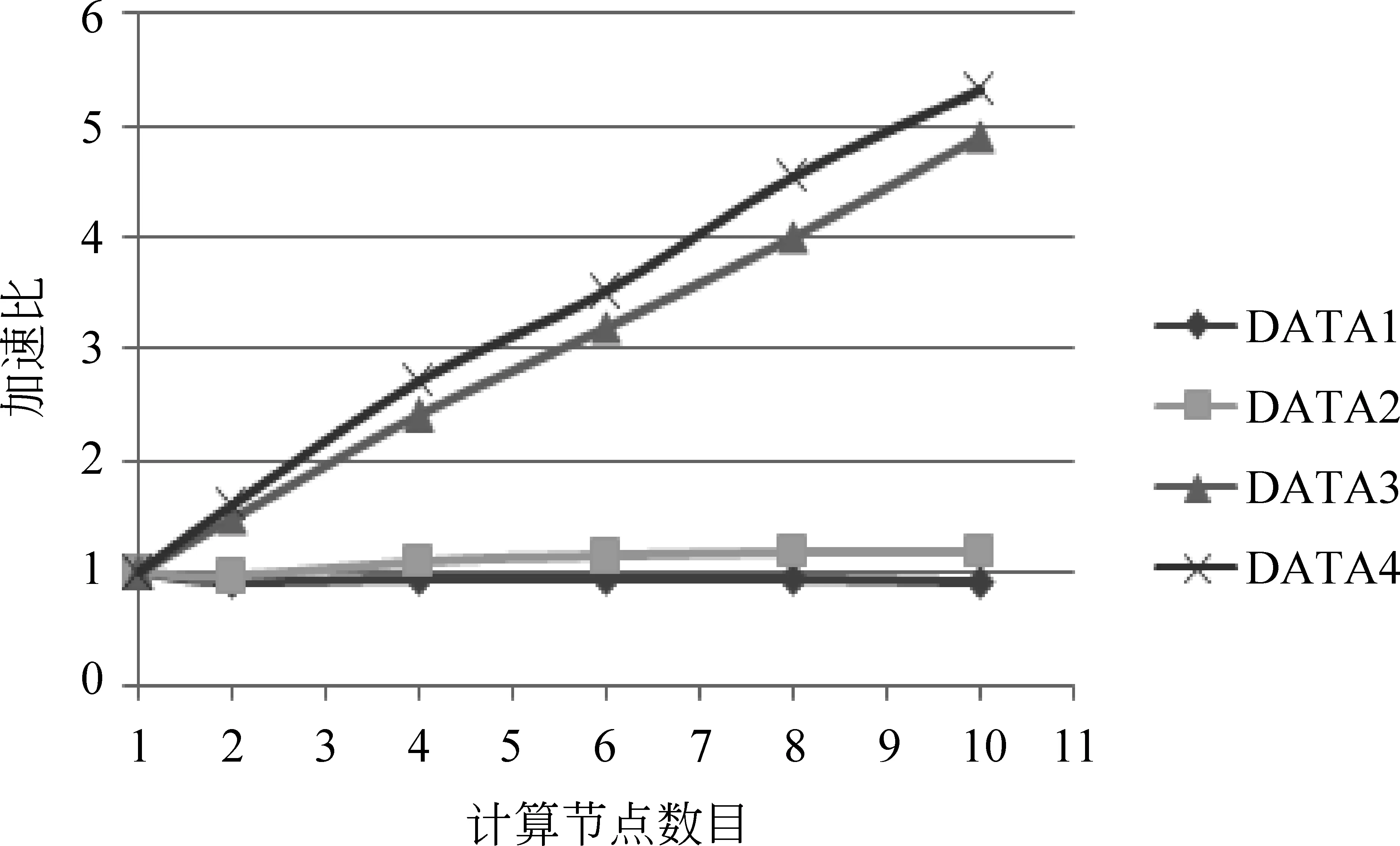
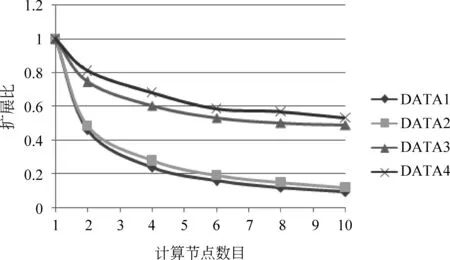
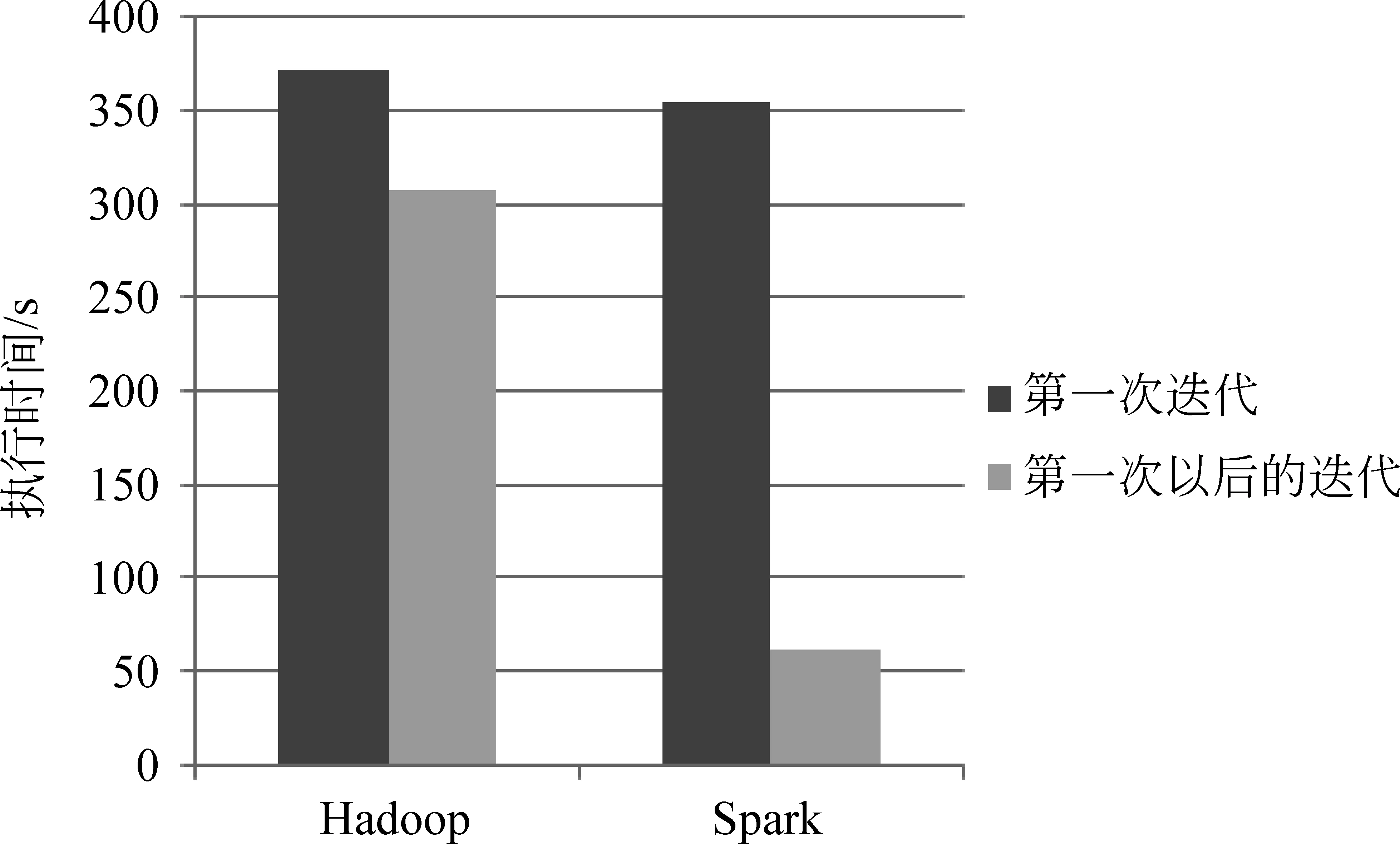
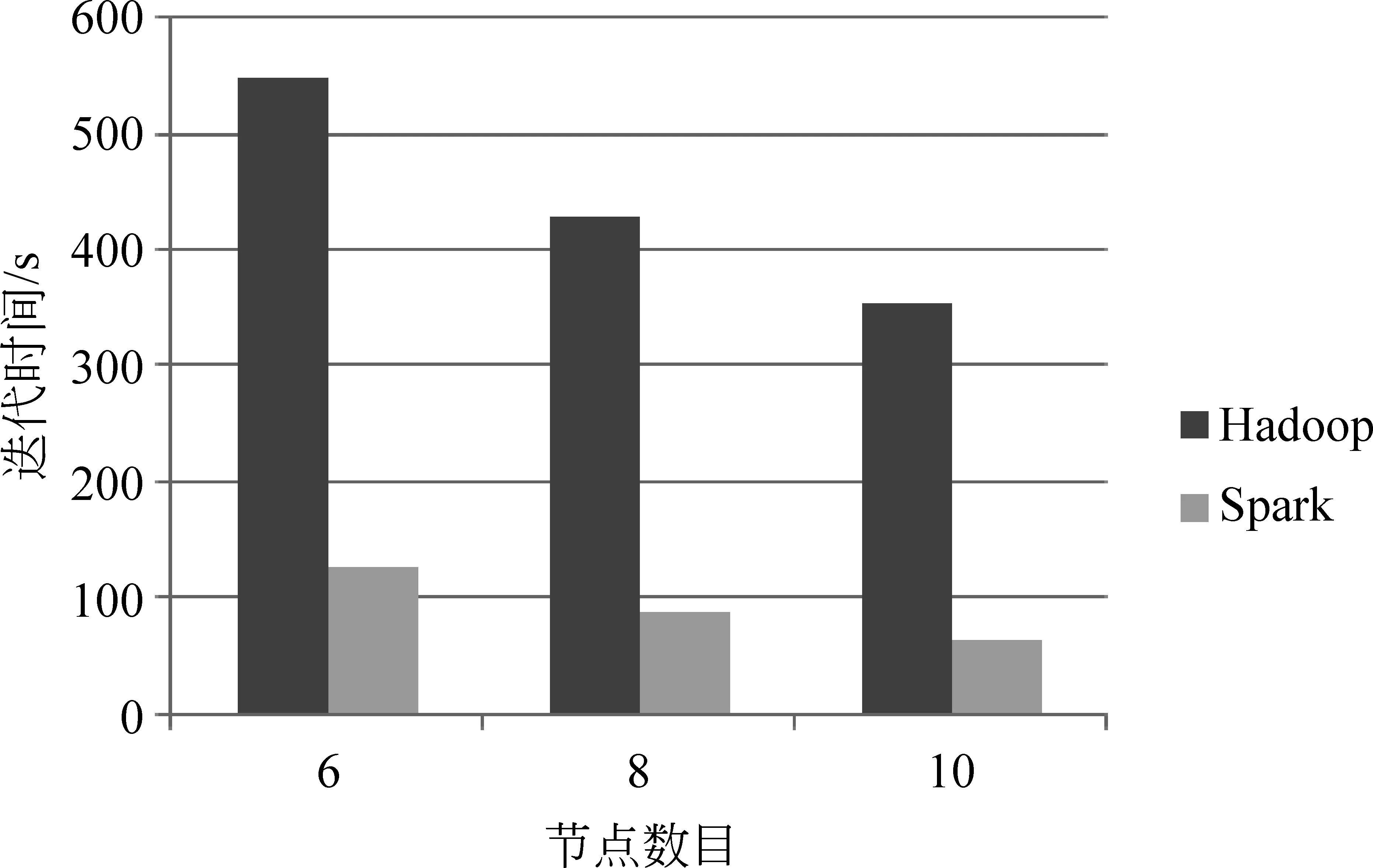
10.0 while(tempDist>convergeDist&&tempIter { 10.1 val closest = data.map (p => (closestPoint(p._2, kPoints), (p._2, 1))) 10.2 val pointStats = closest.reduceByKey{case ((x1, y1), (x2, y2)) => (plus(x1 + x2), y1 + y2)} 10.3 valnewPoints = pointStats.map {pair._1 =>(pair._2._1, scaleDivde(pair._2._1 / pair._2._2))}.collectAsMap() 10.4 tempDist = 0.0 10.5 for (i<- 0 until K){ 10.5.1 tempDist += kPoints(i).squaredDist(newPoints(i))} 10.6 for (newP<- newPoints) { 10.6.1 kPoints(newP._1) = newP._2} 10.7 tempIter=tempIter+1 } 本实验平台的集群由一个控制节点(namenode)和十台计算节点(datanode1~10)组成,所有节点配置都相同,有2核CPU(主频: 1.86GHz)、4GB内存和60GB硬盘,控制节点和计算节点间以千兆以太网互联。Hadoop的版本为1.2.1,Spark的版本为0.8.1,Hadoop程序使用Java编写,Java版本1.7,Spark程序使用Scala编写,版本2.9.3。本文的语料库采用的是搜狗实验室提供的中文语料库SogouC,它包括九个文本类别集合: 财经,IT,健康,体育,旅游,教育,招聘,文化,军事。数据集的规模如表1所示。 表1 实验使用的数据集的规模 实验分别在Hadoop和Spark集群平台上进行,共进行了三类实验: (1) 基于Spark平台的并行k-means算法加速比测试; (2) 基于Spark平台的并行k-means算法扩展比测试; (3) 基于Spark与Hadoop平台,从首次和后续迭代执行时间来比较运行效率。 6.1 k-means算法的加速比分析 加速比是指通过并行计算使运行时间减少所获得的性能提升,它是验证并行计算性能的一个重要指标,其计算公式为Sd=Ts/Td,其中Ts表示串行算法(即在单节点上)计算所消耗的时间,Td表示并行算法(即在d个相同节点上)计算所消耗的时间。加速比越大,表明并行计算消耗的相对时间越少,并行效率和性能提升越高。为了评估在Spark下的加速比,使用表1中DATA1、DATA2、DATA3、DATA4文本集,指定聚类的个数为10,分别测试这些文本集在单机环境下的执行时间及Spark环境下的并行聚类算法的执行时间。根据测试结果绘制如图5所示的加速比曲线图。从图中可以看出,随着计算节点从1增加到10,文本集为DATA1或DATA2的加速比接近于1,曲线持平;当文本集为DATA3或DATA4时,算法的加速比都大于1。在数据量很小的情况下,加速比不明显;但是随着数据量的增加,在相同数据量的情况下加速比曲线随着节点数增加逐渐上升。实验表明Spark下的k-means文本聚类具有较好的加速比[21]。 图5 Spark环境下的加速比 6.2 k-means算法的扩展比分析 当集群中的计算节点的数目不断增加时,并行算法的加速比并不能无限地增大,此时仅用“加速比”已不能反映集群的利用率,因此引入了扩展比的概念,即扩展比表示并行算法执行过程中集群的利用率情况,其公式为J=Sd/d,其中Sd表示算法的加速比,d表示计算节点数。图6描述了在Spark环境下的并行聚类算法执行的扩展比,随着数据量的增大和节点数量的增多,扩展比逐渐下降并趋于稳定,而且文本集DATA1和DATA2较DATA3和DATA4扩展比曲线下降更快。这说明在Spark环境下,k-means文本聚类具有良好的扩展性,相对来说,小数据集的扩展性表现差一些[21]。 图6 Spark环境下的扩展比 6.3 Hadoop和Spark环境下k-means并行算法的比较 在本次实验中,选定聚类样本为DATA4,设置计算节点数为10,指定的聚类个数为10,聚类的阈值J为0.5。我们将分别比较Hadoop和Spark平台下算法执行时每次迭代的执行时间。实验时随机选择10个样本向量作为初始聚类中心。因为k-means聚类是典型的迭代算法,我们将第一次迭代(含从磁盘读数据的开销)和除第一次外所有迭代(在Spark环境下,只从内存读数据;Hadoop下依然每次都要从磁盘读数据)的均值分开描述比较,以更清楚地展现Spark基于内存计算的强大优势,实验结果如图7所示。 图7 每次迭代时间比较 在第一次迭代中,两个系统都是从磁盘文件系统HDFS中读取数据,实验数据显示Spark比Hadoop稍快,原因是Hadoop程序开始和终止的心跳机制开销略大于Spark程序。 除第一次迭代外其他所有迭代运行时间的均值,Spark比第一次迭代执行时间少了一半,而Hadoop与第一次迭代执行时间相差不大。原因是Hadoop不支持数据缓存及作业之间的数据共享,而k-means的每次迭代都以独立作业的形态存在,因此每次迭代都需要访问HDFS,将相关的数据集载入到本地内存中;而Spark支持数据的缓存,在首次迭代时将数据cache到内存,再次迭代时可以直接从缓存中读取数据,从而大幅度减少了磁盘I/O操作的时间,而且节省了执行器启动任务的时间。因此在后续迭代过程中,Spark相比Hadoop环境下的迭代时间得到显著缩减[21]。 图8给出了随着计算节点的增加,Hadoop和Spark完成一次迭代的平均执行时间(不含首次迭代)比较,从图中可以看出,相比Hadoop,Spark的执行效率得到了大幅度的提升。 图8 平均迭代时间比较 基于内存计算的新一代并行计算框架Spark被人寄予厚望,希望能针对Hadoop的弱点,切实提高具有复杂计算模式的大数据文本处理效率。本文以具有频繁迭代计算特点的k-means算法并行化为切入点,基于Spark平台,利用其以RDD为核心的内存计算模型,设计并实现了并行化k-means算法。通过实验验证了基于Spark的应用在处理需频繁迭代的大规模文本数据计算时,具有优良的加速比和扩展比,与传统大数据平台Hadoop相比,处理效率得到显著提升,因此适合未来大规模数据挖掘及其他需要频繁迭代的数据处理工作。 [1] 何婷婷,戴文华,焦翠珍.基于混合并行遗传算法的文本聚类研究[J].中文信息学报, 2007,21(4): 55-60. [2] 陈德华, 韩忠明, 乐嘉锦.基于XML文档相似性的构件聚类分析[J].计算机工程与设计, 2009,30(2): 507-510. [3] 袁冬.基于海量文本的语义构建方法研究[D].中国海洋大学博士学位论文,2012. [4] 石晶,胡明, 戴国忠.基于小世界模型的中文文本主题分析[J].中文信息学报,2007,21(3): 69-74. [5] Quinn M J, 奎因, 文光, 等. MPI与OpenMP并行程序设计: C语言版[M]. 清华大学出版社, 2004. [6] 赵念强, 鞠时光. 网格计算及网格体系结构研究综述[J]. 计算机工程与设计, 2006, 27(5): 728-730. [7] 陈康, 郑纬民. 云计算: 系统实例与研究现状[J]. Journal of Software, 2009, 20(5): 1337-1348. [8] Dean J, Ghemawat S. MapReduce: simplified data processing on large clusters [J]. Communications of the ACM, 2008, 51(1): 107-113. [9] 王凯. MapReduce集群多用户作业调度方法的研究与实现 [D]. 国防科学技术大学硕士学位论文, 2010. [10] 刘鹏. 实战 Hadoop: 开启通向云计算的捷径[M]. 北京: 电子工业出版社, 2011. [11] 李建江, 崔健, 王聃, 等. MapReduce并行编程模型研究综述[J]. 电子学报, 2012, 39(11): 2635-2642. [12] Srirama S N, Batrashev O, Jakovits P, et al. Scalability of parallel scientific applications on the cloud[J]. Scientific Programming, 2011, 19(2): 91-105. [13] Fox G C. Data intensive applications on clouds[C]//Proceedings of the 2nd International Workshop on Data Intensive Computing in the Clouds. ACM, 2011: 1-2. [14] Zaharia M, Chowdhury M, Franklin M J, et al. Spark: cluster computing with working sets[C]//Proceedings of the 2nd USENIX Conference on Hot Topics in Cloud Computing.2010: 10-10. [15] 黄昌宁, 赵海.中文分词十年回顾[J].中文信息学报, 2007,21(3): 8-19. [16] G. Salton, et al.. Vector-space model for automatic indexing [J]. Communications of the Acm, 1975(18): 613-620. [17] 徐建民,王金化,马伟瑜.利用本体关联度改进的TF-IDF特征词提取方法[J].情报科学,2011,29(2): 279-283. [18] 黄承慧,印鉴,侯昉. 一种结合词项语义信息和TF-IDF方法的文本相似度量方法[J].计算机学报,2011,34(5): 856-864. [19] 韩晓红, 胡彧. K-means 聚类算法的研究[J]. 太原理工大学学报, 2009,(3): 236-239. [20] 江小平, 李成华, 向文, 等. K-means聚类算法的MapReduce并行化实现[J]. 华中科技大学学报(自然科学版), 2011, 39(1): 120-124. [21] 滕家雨. 云框架下的文本挖掘算法并行化研究[D].中国矿业大学硕士学位论文, 2015. [22] Zaharia M, Chowdhury M, Das T, et al. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing[C]//Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation. USENIX Association, 2012: 2-2. [23] Apache Spark. Spark [EB/OL]. http://spark.incubator.apache.org.html,2014-02-10. [24] Scala programming language [EB/OL]. http://www.scala-lang.org, 2014. 刘鹏(1972—),博士,副教授,主要研究领域为机器学习及其并行化技术、大数据处理技术及其在矿山物联网的应用等。 E-mail: liupeng@cumt.edu.cn 滕家雨(1988—),硕士研究生,主要研究领域为并行机器学习算法及其在大规模文本处理中的应用。 E-mail: 294315013@qq.com 丁恩杰(1962—),通信作者,博士,教授,博士生导师,主要研究领域为大数据处理技术、矿山物联网等。 E-mail: enjied@cumt.edu.cn Parallel K-means Algorithm for Massive Texts on Spark LIU Peng1,2, TENG Jiayu1,3, DING Enjie1,2, MENG Lei1,2 (1. Internet of Things Perception Mine Research Centre, China University of Mining and Technology, Xuzhou, Jiangsu 221008, China;2. National and Local Joint Engineering Laboratory of Internet Application Technology on Mine, Xuzhou, Jiangsu 221008, China;3. School of Information and Electrical Engineering, China University of Mining and Technology, Xuzhou, Jiangsu 221116,China) 1003-0077(2017)04-0145-09 TP311 A6 实验设计与分析
7 结语



