藏语音节标注研究
2017-10-11龙从军刘汇丹
龙从军,刘汇丹,吴 健
(1. 中国社会科学院 民族学与人类学研究所,北京 100081; 2. 中国科学院 软件研究所,北京 100190)
藏语音节标注研究
龙从军1,2,刘汇丹2,吴 健2
(1. 中国社会科学院 民族学与人类学研究所,北京 100081; 2. 中国科学院 软件研究所,北京 100190)
藏语的“音节”在词汇语法研究和文本信息处理研究中都十分重要,尤其在解决未登录词切分问题和标注中能够发挥积极的作用。然而在现有的研究中,对音节的重视还不够。该文提出在文本标注时,可以先进行音节的性质标注,然后通过音节构词的规律预测复合词的词性,尤其是未登录词的词性。该文作者对藏语音节的定义进行了界定,提出音节的性质分类及标注原则,利用统计模型,在约24万音节的中小学语文教材语料库上进行实验,音节性质标注的正确率为93.520 8%。在此基础上,把音节性质标注信息用到词性标注中。实验结果表明: 即使在音节性质标注存在一定错误的情况下,词性标注的正确率也提高到94.196 7%;如果在保证音节性质标注完全正确的情况下,词性标注的正确率可以提高到97.775 4%,这说明音节性质标注信息对词性标注有帮助。
藏语;藏语音节;音节性质标注;音节性质分类
Abstract: “Syllables” of Tibetan language are very important in vocabulary construction and text information processing, especially for solving the segmentation and annotation of OOVs. This paper proposes to tag the syllables, which can be applied to predict POS of compound words (especially OOVs) according to the rules of words-construction. This paper presents the definition of the Tibetan syllable, outlines and the principles of classification and labeling. The train and test texts are selected from teaching material of Tibetan language of primary and secondary schools, total 240K syllables. Experiments reveals a precision of 93.5208% for syllable tagging, upon which an improved 94.1967% accuracy for POS tagging can be reached. And given the gold-standard of syllable tagging, the accuracy of POS tagging will be improved to 97.775 4%.
Key words: Tibetan language; Tibetan syllable; syllable tagging; syllable classification
收稿日期: 2016-04-18 定稿日期: 2017-03-03
基金项目: 国家语委重点项目(ZDI135-17)
1 引言
词性标注是为给定句子中的每个词确定一个合适的词性的过程。词性标注研究是自然语言处理的基础内容之一,它在语音识别、信息检索等很多领域发挥着重要的作用。在分词和词性标注研究中,未登录词是影响分词或标注正确率的重要因素。文献[1]指出,在Bakeoff2003分词评测中,在给定的四个语料库基础上进行测评,未登录损失词造成的分词精度损失比歧义切分造成的精度至少大10倍。藏语由于存在黏写形式[2],未登录词造成的切分错误还会更多。同样,在词性标注中,未登录词标注错误也占据较大的比例。现有的藏语词性标注模型基本上以词为单位进行标注[3-5],由于用来训练标注模型的语料库比较小,未登录词的比例较高,标注结果并不理想[6-7];而且各标注系统在词边界划分上也有分歧,不同系统的标注结果往往不一致。在统一标注语料库缺失的情况下,各种标注系统难以比较优劣。近几年,基于音节的方法在统计语言模型中发挥着积极的作用。在拼音线性文字研究方面,基于字符(letter)、子词(subword)层级的统计语言模型不管在文本处理还是语音识别、文本语音转换研究中都凸显优越性[8]。在汉、藏语文本处理研究中,研究者也广泛采用了基于字位的统计分词策略,并已经取得了明显的效果。因此,本文采用这种研究思路进行藏语音节(通常指一个非黏写形式的音节)的音节性质标注。文章第二部分着重谈藏语音节的概念、分类,第三部分主要讲藏语音节性质标注的原则,第四部分描述标注策略及结果分析。
2 藏语音节的定义与分类


2.2 藏语音节的性质分类
古代藏语以单音节为主,大部分音节都有实意,这里所说的音节的性质是指音节的语法类别性质,与词的词性类似。藏语的词可以由单个音节构成,也可以由多个音节构成。汉语中把构成合成词的字称为词素或者语素,词素可以分成名词性词素、动词性词素、形容词性词素等。藏语音节的性质同样可以分成名词性音节、动词性音节、形容词性音节等。要标注藏语音节的语法属性,首先需要对它们进行分类,经过标注实践,我们对藏语音节进行了如下分类。







(9) 前缀、后缀音节(f),指没有词汇意义,只有语法意义的音节,如“pa”、“po”、“mo”、“bo”等。根据后缀所依附的音节的不同性质,可以分为nf(名词性音节的缀)、vf(动词性音节的缀)、af(形容词性音节的缀)等。如果是前缀,则分别为fn、fv、fa等,但实际上藏语中的前缀非常少。


除了上述的音节之外,还有一部分表示语义、句法关系的格标记和助词,它们的分类如表1所示[9]。

表1 表示语法意义的音节分类及标注标记表
3 藏语音节性质标注的原则

由此可见,藏语音节性质标注过程实际上是对同形多性进行歧义消解的过程,每一个音节需要放置于合成词、短语或句子中,才能够得以正确标注。根据这些特点,本文作者在音节标注时遵循了以下几个原则。
(1) 考虑合成词中音节的来源,这个原则在前文已经交代。

(3) 遵循上下文原则,音节的标注不是对孤立的音节或者独立的合成词中的音节进行标注,而是把音节置于文本的句子中考虑。尤其是单独成词或者具有某种语法意义的音节,在确认性质的时候要结合上下文语境。例如,在确定格标记时,不但要考虑格标记相关的名词性结构,还要考虑动词的语义特性。
4 藏语音节性质标注策略及结果分析



在现有的研究中,对藏语黏写形式切分的方法主要有两种: 基于规则的方法[11-12]和基于统计的方法[2,12-13]。在统计方法中,有采用分词和黏写切分一体化的四词位和六词位标注方法,以及单独先处理黏写形式然后再进行分词的预处理方法,实验结果表明后者比前者稍好一些[3],因此本实验采用后一种方法处理黏写音节。
4.2 语料选择

4.3 模型选择
音节性质标注实验采用了条件随机场模型工具包。条件随机场模型被广泛使用在自然语言标注研究中,尤其在序列标注任务中表现突出。需要标注的序列与标注标签之间的概率可以采用式(1)计算。
(1)
对于藏语音节来说,X是藏语音节的序列,Y是对应的音节性质标签。fk是特征函数,t是每个音节在当前句子中的索引,Z(X)是归一化因子,它用来保证Pλ(Y|X)满足作为概率值的性质,其计算方法如式(2)所示。
(2)
如果将fk中的X和yt-1视为当前的上下文h,将yt视为在当前上下文环境中当前观察值的标签t,则概率模型和相应的特征函数取自空间H×T,其中H表示所有可能的上下文或者任何预先定义的条件,而T是所有可能的标签集合,则特征函数可由式(3)定义,其中hi∈H,tj∈T。
(3)
条件随机场模型不需要隐马尔科夫模型所要求的严格独立假设,也克服了最大熵模型的标记偏置的缺陷。它是在给定观测序列的条件下定义整个类别标记中单一标记的联合概率,而不是单单定义一个状态分布概率。这个特点更符合自然语言的序列递归特点。
4.4 标注实验及结果分析
在实验中,语料库按照1∶4的比例分配,随机抽取3 983句作为测试语料,其余15 952句作为训练语料,获得模型大小为215MB。测试结果分别采用正确率来度量。本实验语料情况如表 2所示。
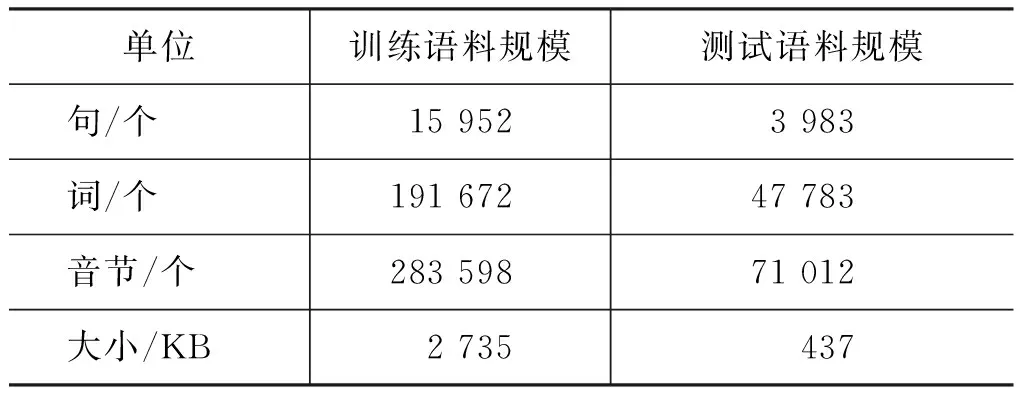
表2 语料情况
我们采用五个上下文窗口进行训练,分别进行词性标注、音节性质标注,以及使用带音节性质信息的词性标注实验,实验的统计数据如表3所示。

表3 实验数据
注: 标准音节性质是指正确标注的音节性质。
从表3中可以看出,单独进行音节性质标注,音节性质标注的正确率为93.520 8%;单独进行词性标注,正确率为93.014 3%;如果利用音节性质标注信息进行词性标注,词性标注的正确率可以提高到94.196 7%,比不利用音节性质信息直接进行词性标注的方法提高了1.18%,在音节性质标注存在较多错误的情况下,仍然能够提高词性标注的正确率,其原因可能是歧义音节的多个音节性质虽然不同,但在构词时却能形成相同的词性,因而仍然有利于词性标注。在保证音节性质标注完全正确的情况下,利用正确的音节性质信息,词性标注的正确率提高到97.78%,正确率提高了4.77%。也就是说,如果音节性质信息完全正确,可以极大地提高词性标注的正确率。
5 结语
本文进行了基于音节的音节性质标注研究,对音节进行了定义、分类,阐述了标注的原则;构建了约24万音节的中小学藏语文教材标注语料库。经过实验得到了音节标注模型,测试结果正确率达到了93.520 8%。经分析错误例子得知,大部分标注错误是由于标注语料的不一致性引起的。由于藏语音节性质标注研究在藏语文本信息处理中还没有报道过,本文的研究对藏语构词法研究、未登录词识别与标注、基于音节的语言模型的构造都具有积极的意义。
[1] 黄昌宁,赵海.中文分词十年回顾[J].中文信息学报,2007,21(3): 8-19.
[2] 康才畯,龙从军,江荻.基于词位的藏文黏写形式的切分[J].计算机工程与应用, 2014(11): 218-222.
[3] 史晓东,卢亚军.央金藏文分词系统[J].中文信息学报,2011,25(4): 54-56.
[4] 于洪志,李亚超,汪昆,等.融合音节特征的最大熵藏文词性标注研究[J].中文信息学报,2013, 27(5): 160-165.
[5] 康才畯.藏语分词与词性标注研究[D].上海师范大学博士学位论文, 2014: 53.
[6] 于洪志,李亚超,汪昆,等.融合音节特征的最大熵藏文词性标注研究[J]. 中文信息学报, 2013, 27(5): 160-165.
[7] 华却才让,刘群,赵海兴,等.判别式藏语文本词性标注研究[J].中文信息学报, 2014, 28(2): 56-60.
[8] TomášMikolov, IlyaSutskever, Hai-Son Leetc. Subword language modeling with neural networks[EB/OL]. www.fit.vutbr.cz /~imikolov/ rnnlm/char.pdf.
[9] 赵小兵,孙媛,龙从军,等.藏文拉丁转写、分词和词性分类规范: 信息处理用现代藏语分词规范(草案)[M].北京: 商务印书馆, 2015: 1-10.
[10] 张济川. 藏语词族研究: 古代藏族如何丰富发展他们的词汇[M].北京: 社会科学文献出版社,2009: 207.
[11] 才智杰.藏文自动分词系统中紧缩词的识别[J].中文信息学报,2009,23(1): 35-37, 43.
[12] 刘汇丹,藏文分词及文本资源挖掘研究[D],中国科学院博士学位论文,2012: 46.
[13] Congjun Long, Caijun Kang, Di Jiang. The comparative research on the segmentation strategies of Tibetan bounded variant forms[C]//Proceedings of the Asian Language Processing(IALP), 2013 International Conference on DOI: 10.1109/IALP,2013 : 243-246.

龙从军(1978—),博士,副研究员, 主要研究领域为藏语计算语言学。
E-mail: longcj@cass.org.cn

刘汇丹(1982—),博士,副研究员,主要研究领域为自然语言处理、多语言信息处理。
E-mail: huidan@iscas.ac.cn

吴健(1962—),研究员,主要研究领域为操作系统中文信息处理、多语言信息处理。
E-mail: wujian@iscas.ac.cn
Research on Tagging of Tibetan Syllables
LONG Congjun1,2, LIU Huidan2, WU Jian2
(1. Institute of Ethnology and Anthropology, Chinese Academy of Social Sciences, Beijing 100081,China;2. Institute of Software, Chinese Academy of Sciences, Beijing 100190, China)
1003-0077(2017)04-0089-05
文献标志码: A
