基于统计和浅层语言分析的维吾尔文语义串快速抽取
2017-10-11吐尔地托合提维尼拉木沙江艾斯卡尔艾木都拉
吐尔地·托合提,维尼拉·木沙江,艾斯卡尔·艾木都拉
(新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046)
基于统计和浅层语言分析的维吾尔文语义串快速抽取
吐尔地·托合提,维尼拉·木沙江,艾斯卡尔·艾木都拉
(新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046)
该文提出了一种基于统计和浅层语言分析的维吾尔文语义串快速抽取方法,采用一种多层动态索引结构为大规模文本建词索引,结合维吾尔文词间关联规则采用一种改进的n元递增算法进行词串扩展并发现文本中的可信频繁模式,最终依次判断频繁模式串结构完整性从而得到语义串。通过在不同规模的语料上实验发现,该方法可行有效, 能够应用到维吾尔文文本挖掘多个领域。
语义串;多层动态索引;词串扩展;可信频繁模式;邻接特征分析
Abstract: A fast Uyghur semantic string extraction method is proposed based on statistical model and shallow linguistic parsing. It employs a multilayered dynamic indexing structure to build word index for large-scale text. Combined with the Uyghur word association rules, an improved n-gram incremental algorithm is designed for word string extension, trying to capture the credible frequent patterns in the text. The final semantic strings are determined after the structural integrity of the frequent pattern is verified. Experiments on different corpus indicate that this method is feasible and effective.
Key words: semantic string; multilayered dynamic indexing; word string extension; credible frequent pattern; context analysis
收稿日期: 2015-9-26 定稿日期: 2015-12-18
基金项目: 国家自然科学基金(61562083,61262062,61262063);新疆维吾尔自治区高校科研计划重点项目(XJEDU2012I11)
1 引言
关于语义串的识别和抽取,国内外很早就有学者开展一些研究工作。如L F Chien的研究工作表明: 一个具有词汇意义和语法意义的模式串是由任意多个连续字符构成的,在一个内容相关的文本集中频繁出现,其语义是完整且独立的[1]。J Zhang等人的研究工作表明: 复合词是在文本集中结构稳定的字符串,复合词内部词语之间紧密程度较强,而它与上下文其他词语之间的紧密程度较弱[2]。Y S Lai等人的研究工作中,提出了PLU(phrase like unit)的概念,并实现了一种基于统计的挖掘算法来抽取文本集中类似于短语的,并且独立于领域的语言单元[3]。胡吉祥的研究工作表明: 文本集中的关键频繁模式应具有极强的文本表征能力,其特点是: 结构稳定不可分割,语义完整,独立于上下文的语言单位[4]。贺敏的研究工作表明: 有意义串突破词语概念的界限,是包含具体语义,并且能够作为一个灵活独立的语言单元在不同语境中使用的字符串[5]。吴庆耀的工作表明: 语义词具有完整的语义和完整的边界,语义词可以是一个名词、形容词、复合词、短语等[6]。
根据以上研究工作,我们可以定义语义串为: 是文本中上下文任意多个连续字符(字或词)的稳定组合,其语义完整且独立,能作为文本中线索词,包括人名、地名、机构名等命名实体,还有实词(科学家)、新词(自贸区)、词组或短语(地方政府阳光举债)、领域术语(人感染H7N9确诊病例)、固定搭配(严格监管)等。
语义串抽取是文本处理中的基础技术,可以直接应用到文本挖掘多个领域中。如应用到分词中,可以提高新词识别效率[7]。应用到搜索引擎中的索引词的抽取、查询词的修正,以及相关搜索分析中,可以达到索引压缩的目的,同时也可以大大提高搜索效率[8]。应用到网络舆情系统中,可以将语义串作为主要的舆情线索进行网络舆情热点的有效发现和跟踪[9]。应用到文本分析中,以语义串作为特征表征文本,可以构造泛化能力更强、更紧凑的文本模型,这就会明显提高聚类和分类准确率[10-11]。除此之外,在专业术语抽取及领域词典编撰等更多的领域[12],语义串的抽取仍能作为有效手段。
随着维吾尔文文本挖掘更多领域研究工作的深入开展,维吾尔文现有分词方法开始暴露出其潜在的不足和缺陷,维吾尔文语义串抽取方法的研究变得尤为必要和迫切[13]。本文从以上中、英文相关研究工作中受到启发,再结合维吾尔文的语言特性,提出了一种基于统计和浅层语言分析的维吾尔文语义串抽取方法,并通过实验验证了其可行性和有效性。
2 文本表示
影响浅层语言分析效率的主要因素是文本表层质量,主要包括文本书写规范性和词法正确性[14]。因此,我们先对待处理文本进行正则化、拼写校对、词干切分等必要的预处理。
词索引是将单词作为词条(term),与单词属性之间建立映射的数据结构,是常见、高效的大规模文本表示方法。本文语义串抽取方法以单词索引为基础,考察单词扩展到串、串扩展到更长的串的可能性,因此新产生的串还需要写入索引中,这就要求索引具有动态特性和更好的规模扩展性[15]。因此,我们设计了如图1所示的索引结构,该结构由三个部分组成。

图1 索引结构
(1) 词典。是每一个词条与它对应的ID之间的管理工具。对于本文研究工作来说,初始索引项是单词(词干),经过词条扩展后会产生长度不同的新串,而这些串都作为新的索引项追加到索引中。显然,这不利于存储和运算。在本文研究中,我们设计了一个基于双数组Trie树优化算法的维吾尔文词典管理工具[16],将不同长度的词条(串)转换成整个索引空间中唯一的词条(串)ID,这样节省了存储空间,同时极大提高了运算效率。
(2) 一级索引。作为索引项的每一个单词或串,经过词典管理工具翻译成全索引空间唯一的ID,然后用这个ID就可以找到该索引项对应的一级索引入口。一级索引包含以下数据: Freq是该索引项在语料中的频次;is_stop是停用词标志;is_adj是形容词标志;Unit_count是该索引项的单词长度(串中包含的单词个数); Pos_pointer,Lv_pointer和Rv_pointer分别是对应二级索引入口的地址偏移量。
(3) 二级索引。二级索引又是一个索引项列表,其入口由一级索引获取。二级索引表中的每一项是该索引项在文本集中的概要描述。其中,第一个索引表是Position,是该索引项的位置倒排;第二个是左邻接列表,是该索引项所有的左邻接及其频次;第三个是右邻接列表,是该索引项所有的右邻接及其频次。
通过这种索引结构,可以描述每一个单词或串尽可能多的属性,其动态性、效率和可扩展性等方面也符合海量文本处理需求。
3 可信频繁模式发现及语义串抽取
语义串作为可独立运用的语言单元,在真实语言环境中有一定的流通度,其内部单词之间存在一定的并发关系(co-occurrence relationships)。在数据挖掘领域中,并发关系也称为关联(association),则文本集中频繁出现的单词关联,我们可以称它为频繁关联模式[17],简称为频繁模式(frequent pattern,FP)。因此,我们可以用关联规则挖掘中的评价指标来衡量频繁模式中相邻单词之间的关联强度。
3.1 文本中的可信频繁模式
根据关联规则的基本概念,一篇文章甚至文章中的一句话我们都可以作为事务来对待[18]。此时,文本中的单词就是一个项目(item),而文本集就是一个项目集(item set)。因此,给定一个文本集或句子集,我们完全可以从中找出单词之间的并发关系(关联)。
假设S=w1w2…wn是一个长度为n的维吾尔文单词串(以空格隔开的n个单词序列),T=S1#S2#…#Sm#是由m个单词串构成的文本语料,#标志文本中的各种标点符号。
定义1 对于单词串S=w1w2…wn,如果文本语料中至少存在两个位置pos1和pos2,并使得T=(wpos1wpos1+1...wpos1+n-1)=T(wpos2wpos2+1...wpos2+n-1)=S,则S称为语料T中的一个模式(pattern),也称为重复串(repeat)。
定义2 根据事先设定的各个参数阈值,如果Support(S)>minsup(minsup为最小支持度)或Frequency(S)>minFreq(minFreq为最小出现频次),则称S为语料T中的频繁模式(frequent pattern: FP),如Confidence(S)>minconf(minconf为最小置信度),则可确定S为可信频繁模式(trusted frequent pattern,TFP)。
设wi-1wi是语料T中维吾尔文词对,wi-1是上文(前件),wi是下文(后件),观察候选频繁模式S=(wi-1wi)是否为可信频繁模式时,我们没有使用支持度指标。因为,Support(wi-1→wi)是语料T中wi-1和wi共现次数的百分比,是对这个单词关联重要性的衡量,说明它在语料T中有多大的代表性。但本文研究是要找出语料中所有重复出现单词关联,而不关心这个单词关联在语料中的重要性。因此,我们将Frequency(S)>2(minFreq=2)的模式都选为频繁模式,再评价wi-1→wi的置信度Confidence(wi-1→wi)来选取可信频繁模式。
置信度Confidence(wi-1→wi)是指上文wi-1出现的情况下,其下文出现wi的后验概率,是对单词关联wi-1→wi的准确度的衡量。当Confidence(wi-1→wi)>minconf时,可确定S=(wi-1wi)是一个可信频繁模式,如式(1)所示。
(1)
假如,对于语料T中频繁模式S=(wi-1wi)有: Freq(wi-1)=100,Freq(wi-1wi)=10,Freq(wi)=10,则由式(1)计算得出Confidence(S)=0.1,因为置信度过小,模式S很可能被过滤掉。但是,我们观察S的下文wi,就发现它与上文wi-1的100%的并发率,很明显S是个可信频繁模式。针对这种情况,我们再引入了一个评价指标,称为逆置信度。
定义3 逆置信度(R-Confidence)是指单词关联wi-1→wi的下文(后件)wi出现的情况下,其上文是wi-1的条件概率,其计算如式(2)所示。
(2)
评价上例中S的逆置信度,由式(2)计算得到R-Confidence(S)=1,因此频繁模式S以极高的准确度被选为可信频繁模式。据此,我们定义可信频繁模式的评价准则。
定义4 对于语料T中的一个频繁模式S,如Confidence(S)>minconf或R-Confidence(S)>minconf,则可确定S为可信频繁模式(TFP)。
3.2 频繁模式发现中的语言规则
本文研究中,我们发现以下语言特性对于文本中关联模式的识别非常有用。
特性2 维吾尔文单词间的结合主要是在名词(N)、形容词(ADJ)和动词(V)之间发生。其中,当形容词与名词或动词结合时,形容词总是作为前驱,而不会出现在后继位置。因此,N+ADJ或V+ADJ关系的相邻单词绝不可能结合成一个语义串。
根据以上语言特性1和特性2,归纳出用于词间关联识别的单词结合规则(word association rule: WAR)并定义如下:
定义5(单词结合规则: WAR) 对于文本中的相邻词对“A B”,如成立条件: A∈{IW} or B∈{IW} or B∈{ ADJ } ,则判断A与B不能结合成为关联模式。
3.3 频繁模式发现过程
本文频繁模式发现是对n元递增算法的改进,根据主要思路及所采取的文本表示模型,大规模文本中维吾尔文频繁模式发现,是按照以下步骤进行的。
(1) 建索引。对于经过预处理的文本集,首先按单词在文本中出现的顺序建立词典,然后对于生成的单词ID序列建词索引。对于只有六个单词的文本“ABCF#EFCEABCFD#EFCADFECDABCFACD#”(#是标点符号),建词索引示例如图2所示。

图2 索引示例
(2) 串扩展及频繁模式发现。一开始,让所有单词(ID)进入一个队列中,然后根据每个单词的索引信息从每个单词扩展得到其二词串或三词串,让该单词出队并将新产生的扩展串入队,继续从n词串扩展到n+1词串或n+2词串,反复迭代,直到队列为空。串扩展候选单词索引及队列初始状态如图3所示。
假定X、Y是文本中相邻的两个单词(或串),X是Y的右邻接词(上文),Y是X的左邻接词(下文),要进行X→XY的扩展,则要满足以下条件 :
①X不是停用词,即is_stop(X)=0;
②X是频繁模式,即Freq(X)≥2;
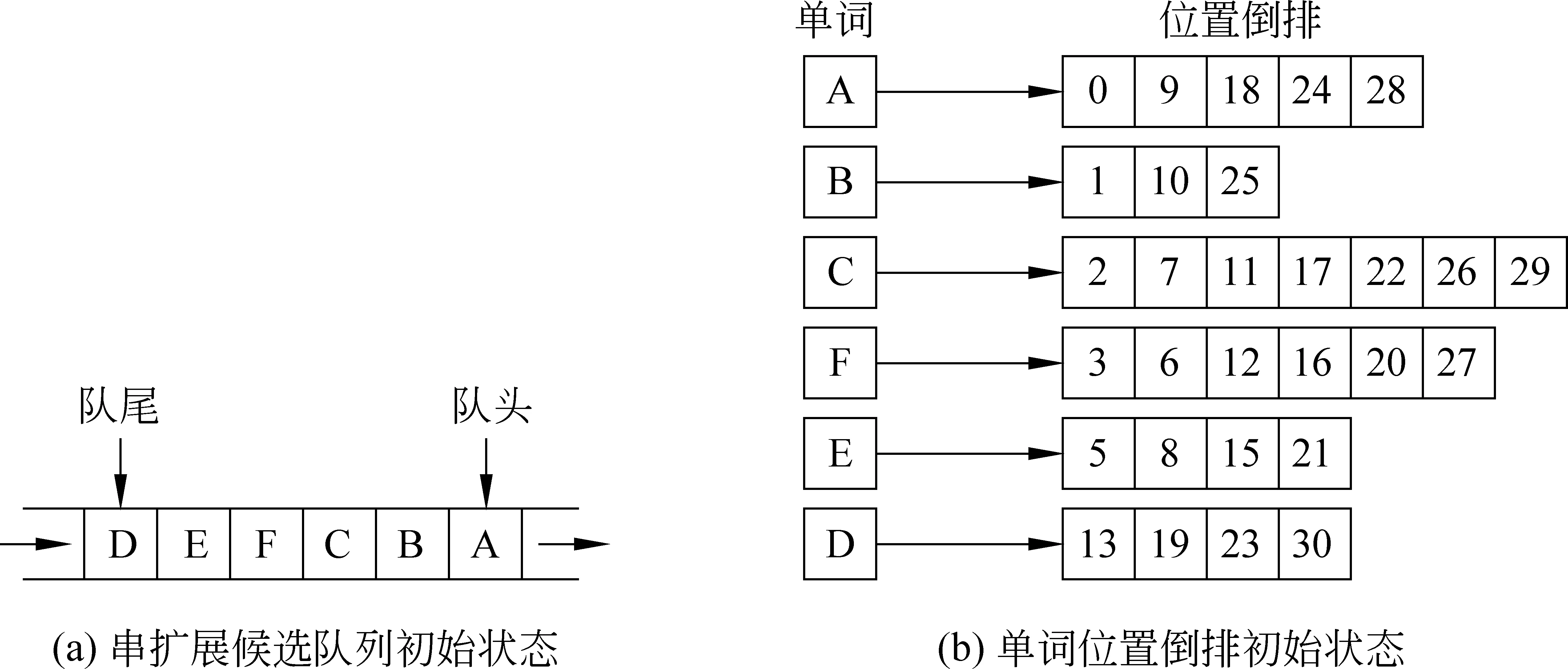
图3 串扩展初始状态示例
③Y不是停用词或形容词,即is_adj(Y)=0且is_stop(Y)=0;
④Y是频繁模式,即Freq(Y)≥2;
⑤XY是可信频繁模式,即Confidence(X→Y)>minconf且R-Confidence(X→Y)>minconf。
当队头单词A出队后,因为A具备条件①和②,因此从二级索引中读取A的左邻接列表,然后根据条件③④⑤依次判断A跟其每一个左邻接(下文)词构成新串的可能性。本例中,A的第一个左邻接B具备条件③和④,同时A与B构成的扩展串AB也具备条件⑤,因此将新产 生 的 串AB入 队,同
时将它的信息追加到索引中,然后判断A跟其下一个左邻接词C的关联强度,依次判断并进行从单词到二词扩展,直到A的所有左邻接词都被访问完为止(A与C和D都不能结合)。此时,扩展候选队列及索引变化情况如图4所示。
之后,让当前队头单词B出队,因为B已跟A结合,就不再进行扩展,然后是C出队。就这样,依次对每一个单词进行二词或三词扩展,同时将新产生的二词串或三词串作为可信频繁模式入队,等待继续被扩展。所有单词都被访问完之后,队列及索引变化情况如图5所示。
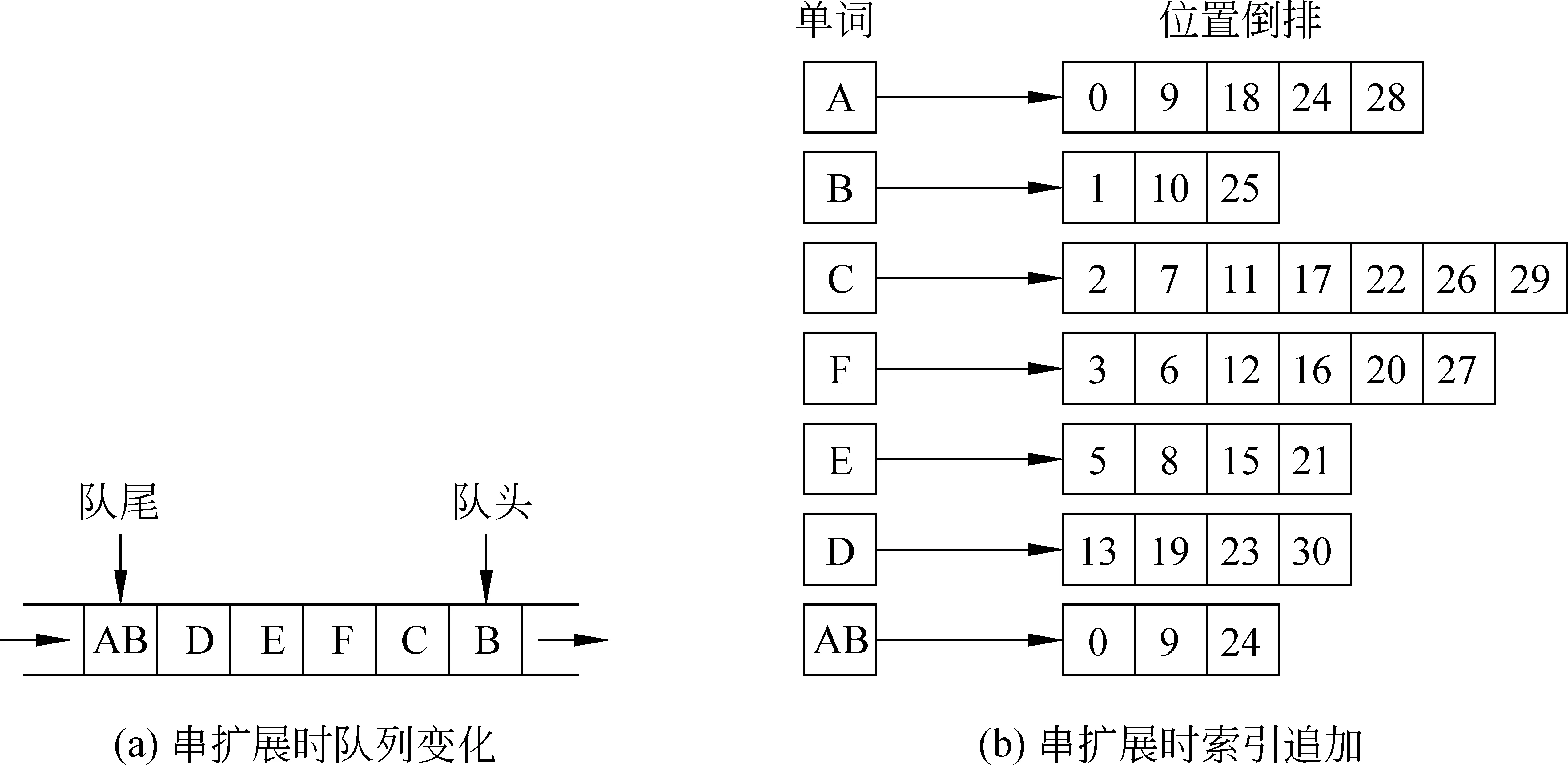
图4 串扩展(示例1)
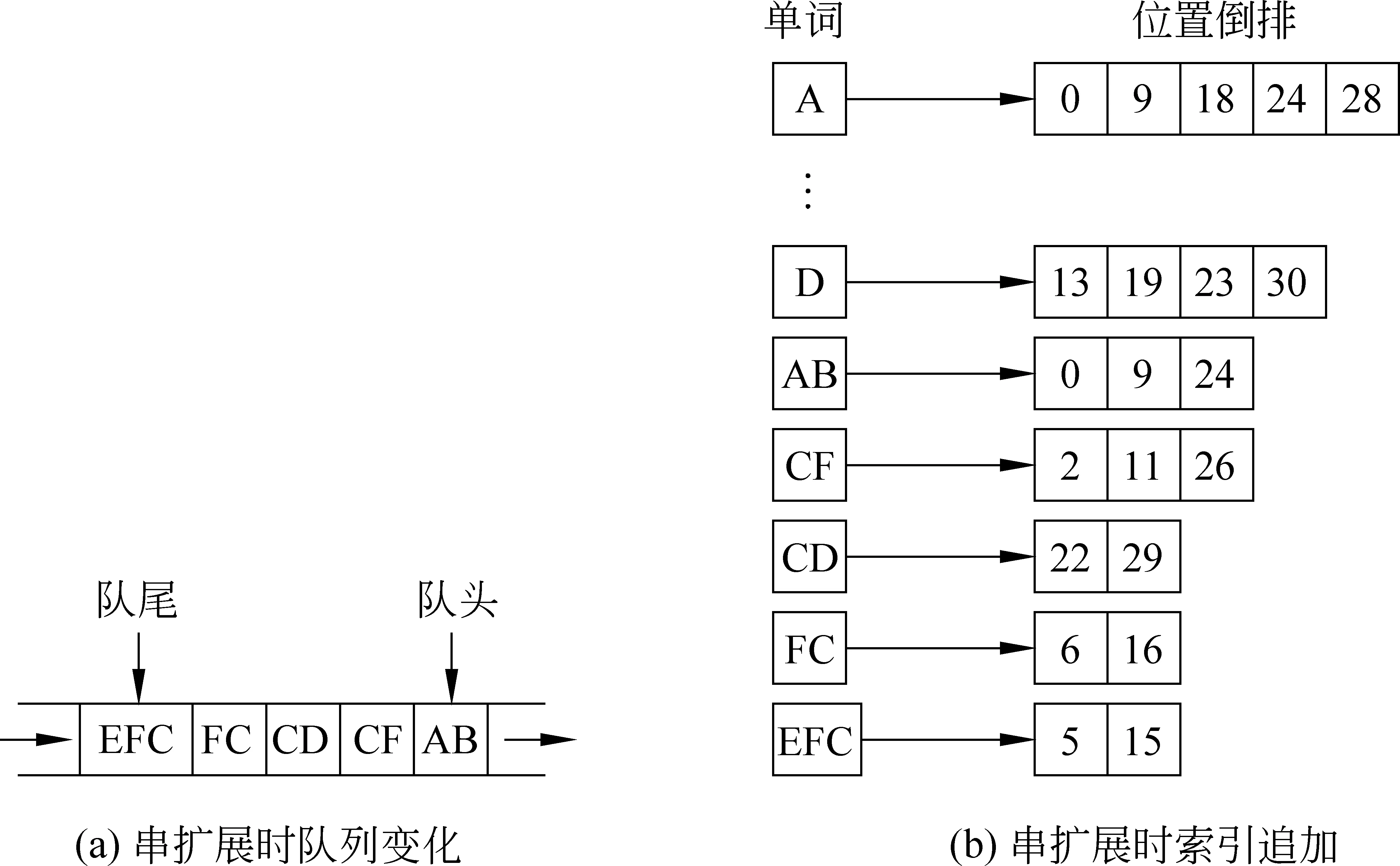
图5 串扩展(示例2)
等所有单词的二词串或三词串扩展进行完毕,就接着进入从候选串扩展更长串的过程,直到串扩展候选队列为空,此时频繁模式发现过程就结束。总体流程如图6所示。

图6 维吾尔文语义串发现流程
3.4 串完整性评价及语义串抽取
如果一个串能成为语义串,那么它在结构、语用、语义及统计上应该满足一定的特点。一般情况下,通过频繁模式发现得到的结果只能满足可统计性要求,称为语义串候选,这还需要采用上下文邻接分析或语言模型分析等方法进行进一步甄别和过滤[19]。本文研究中,判断语义串候选结构完整性,我们的方法与中文有所不同,主要原因如下。
(1) 中文常用功能字会跟其他汉字构成实词,如“的士”等。因此,对于串首(串尾)出现功能字的情况,就需要判断串首(串尾)字对双字耦合度和首字词首(词尾)成词概率。另外,不是所有的汉字都能作为词首或词尾,因此可以根据单字位置成词概率来判断串首和串尾,可以有效过滤垃圾串。但维吾尔文与中文不同,首先维吾尔文功能词不会跟其他词结合构成新词。另外,维吾尔文中的词本来就是一个独立运用的语言单位,词在串首、串尾位置用法没有特有规律(形容词除外)。
(2) 维吾尔文语义串抽取中,我们也可以用与中文类似的方法去判断串首和串尾“双词”耦合度,这对于垃圾串的过滤有一定帮助。但是,这就需要大量学习语料、人工标注并构建双词耦合度词典,而本文研究目的是无监督学习的语义串抽取方法。
(3) 关于语言模型的分析方法,本文算法是引入单词结合规则,并将它嵌入到频繁模式发现过程中,因而有效避免串尾出现形容词的垃圾串产生的情况,减轻了垃圾串过滤任务。
因此,本文主要是根据上下文邻接特征来判断每一个语义串候选的结构完整性。中文相关研究结果表明,采用邻接熵的结果比其他它三种邻接特征量(邻接种类,邻接对种类,邻接对熵)的结果好[20]。因此,我们用式(3)为每一个候选语义串赋权重。
AEweight(S)=min(LAE(S),RAE(S))
(3)
其中,AEweight(S)是串S的邻接熵(adjacency entropy,AE)权重,LAE(S)是串S的左邻接熵,RAE(S)是其右邻接熵。左(右)邻接熵计算公式为式(4)。
(4)
其中,m是串S的左邻接种类数,ni是串S的第i个左邻接的频次,所有左邻接频次总和为N,计算邻接特征量所需要的全部信息早在它们被发现时就已经记录好并存入索引中。最后,依次输出邻接特征量达到阈值的频繁模式,那就是最终要得到的语义串。语义串抽取流程如图7所示。
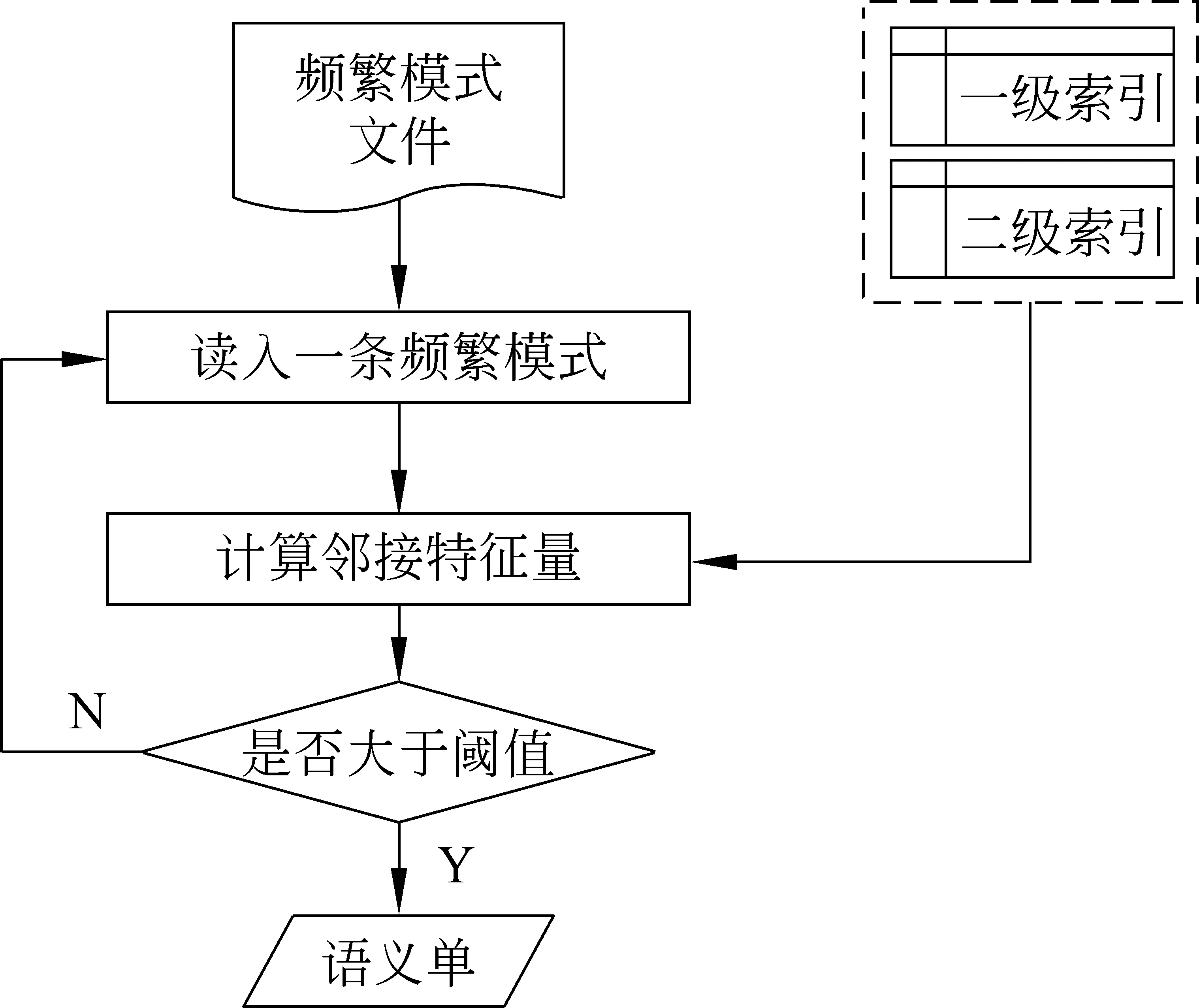
图7 从频繁模式集中抽取语义串流程
4 实验设计与结果分析
4.1 实验语料 本实验数据是新疆大学智能信息处理重点实验室提供的文本语料。根据不同实验目的准备如下实验语料。
(1) 单文档小语料(single document corpus,SDC): 2014年新疆维吾尔自治区两会政府工作报告(维吾尔文,144KB)。
(2) 小规模语料(small scale corpus,SSC): 从各类网站收集的3 000个文档,大小为23.2MB。
(3) 大规模语料(large scale corpus,LSC): 从国内维吾尔文网站采集(采集时间介于2013年9月23日到2014年8月18日之间)并格式化后的112 379个纯文本,大小为739MB。
4.2 评价标准
本文提出的维吾尔文语义串抽取方法是建立在频繁模式统计基础上的,因此我们设计的评价指标是以通过频次统计获取的频繁模式串为 基 准 的,这
样才能较准确地评价垃圾串过滤效率,同时还能减轻计算召回率的开销。
当然,频繁模式发现中的最小置信度minconf和最小频次minfreq也会影响最后语义串抽取效率。本文将minfreq取2,对minconf最佳取值下的实验结果进行评价,主要使用的评价指标有:
其中,P@N是用来评价大规模语料实验结果的指标,是拿前N个结果的准确率来评价实验正确率。
4.3 实验结果及分析
实验1 观察最小置信度阈值不同取值及可信频繁模式发现效率。
分别在语料SDC和SSC上观察minconf不同取值对频繁模式发现效率的影响,并根根Unit_count>1的频繁模式总数及其中的可作为语义串的可信频繁模式总数来计算各评价指标,从而为本文实验确定串扩展准确率最高时的minconf阈值。结果如图8所示。
从不同minconf阈值下的频繁模式发现准确率和召回率变化情况看出,当minconf=0.4时,得到了最好的识别效率。因此,我们确定minconf=0.4为阈值进行后续实验和分析。
实验2 对比使用不同策略情况下的识别效率。
上下文邻接分析、单词结合规律和独立词隔离是维吾尔文语义串识别过程中的三个不同策略。为了观察它们对语义串识别效率的影响,我们采用不同策略的组合在语料SSC上分别做实验,得到如表1所示结果。表1中,FPF指频繁模式发现(frequent pattern find),CA是上下文邻接分析(context analysis),WAR指单词结合规则(word association rule),IWI指独立词隔离(independent word isolation)。
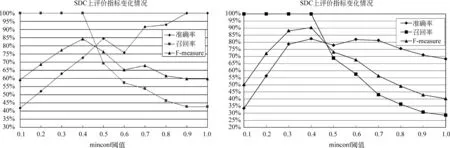
图8 minconf不同取值下评价指标变化情况
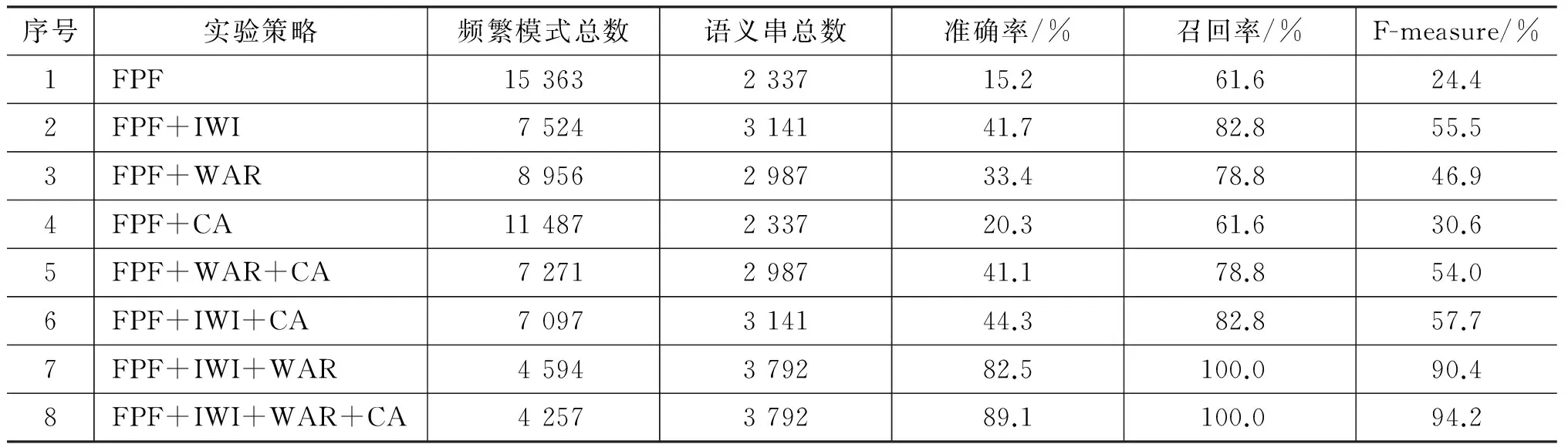
序号实验策略频繁模式总数语义串总数准确率/%召回率/%F-measure/%1FPF15363233715.261.624.42FPF+IWI7524314141.782.855.53FPF+WAR8956298733.478.846.94FPF+CA11487233720.361.630.65FPF+WAR+CA7271298741.178.854.06FPF+IWI+CA7097314144.382.857.77FPF+IWI+WAR4594379282.5100.090.48FPF+IWI+WAR+CA4257379289.1100.094.2
我们再把频繁模式(FPF)抽取结果作为实验基准,分析不同策略单独使用或组合使用情况下的实验结果,如图9所示。
从图9(a)中F-measure值来看,策略2是最有效的,这就表明我们在频繁模式发现过程中引入的独立词隔离策略起到了作用,有效避免了大量垃圾串的产生;单词结合规则比上下文邻接分析有效,因为使用单词结合规则同样避免了错误的串扩展而产生的垃圾串。
图9 不同策略实验结果图
从图9(b)中可以看出,在频繁模式发现阶段串扩展判断中使用的两种策略对语义串发现效率的影响最大,在此阶段就已经达到了相当高的识别准确率和召回率,这就表明这两种策略完全符合维吾尔语言文字特性。
我们还采用逐步增加策略的方式观察识别效率的变化情况,实验结果如图10所示。
可以看出,每一次增加策略、各个评价指标一直都是上升的趋势,说明每一种策略都在起作用。在频繁模式发现阶段引入独立词隔离策略,缩短处理时间的同时避免了大量垃圾串的产生,在此基础上使用单词结合规则进一步排除了以上情况的发生,最后使用上下文邻接分析策略再过滤少量垃圾串而得到了较高的准确率。
实验3 大规模语料上的实验。
在大规模语料LSC上做实验,得到Unit_count>1的语义串个数为166 334个,图11显示结果集N从100增大到1 500时,分别按邻接熵和频次排序时的P@N的变化情况。
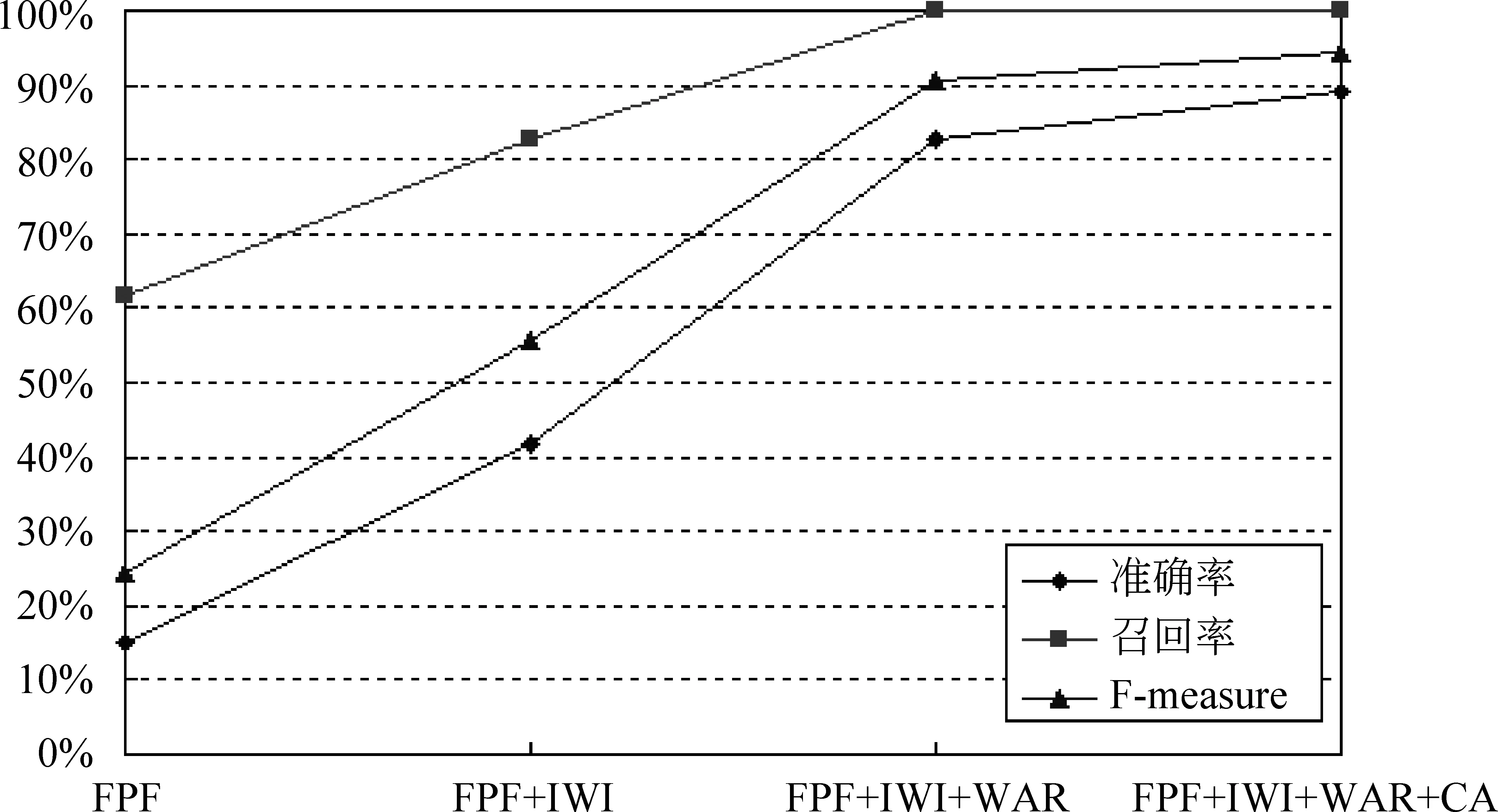
图10 逐步增加策略实验结果图
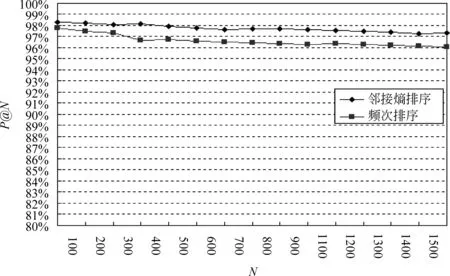
图11 大规模语料实验结果图
从图11发现,将邻接熵作为权重排序比按频次排序有效,这也说明上下文邻接变化多样性是语义串的固有属性。
从结果上看,N从100增加到1 500的过程中,准确率一直在97%以上,基本接近于实用化的水平,说明了本文提出的方法对于大规模语料是更有效的。从单条曲线变化情况来分析,呈现出了稳步下降的趋势,随着n的增加P@N逐渐降低,是因为排序越靠后的模式串成为语义串的可能性就越小,准确率也自然越低。
5 结语
浅层语言分析的方法能够抽取语言表层之下的特定关键信息,其时间效率、分析结果的准确性和系统的实用性均能满足海量文本处理需求。因此,本文研究一种基于浅层语言分析的维吾尔文语义串快速抽取方法。我们设计了一种多层动态索引结构,能满足大规模文本的表示及语义串抽取过程中的动态性和可扩展性需求;引入了维吾尔文独立词隔离及单词结合规则等语言特性,提出了一种基于n元递增算法的词串扩展及可信频繁模式发现算法、模式串结构完整性评价方法和权重计算方法等。最后几个实验分别验证了本文提出的方法在规模不同的语料上都是有效的,在单文档小语料上的实验准确率达到了76.3%,小规模语料上的实验准确率达到89.1%,在大规模语料上的实验P@N(N为1 500)结果超过98%。本文提出的语义串抽取方法不仅可以应用到维吾尔语文本挖掘中,还能应用到哈萨克文、柯尔克孜文等同语系语言文本挖掘中。
[1] L F Chien.PAT-tree-based keyword extraction for Chinese Information Retrieval[C]//Proceedings of the 20th annual international ACM SIGIR conference on research and development in information retrieval,1997: 50-58.
[2] J Zhang,J F Gao, M Zhou. Extraction of Chinese compound words -an experimental study on a very large corpus[C]//Proceedings of ACL2000 Second Chinese Language Processing Workshop, 2000: 132-139.
[3] Y S Lai, C H Wu. Meaningful term extraction and discriminative term selection in text categorization via unknown-word methodology [J]. ACM Transactions on Asian Language Information Processing, 2002, 1(1): 34-64.
[4] 胡吉祥.基于频繁模式的消息文本聚类研究[D]. 中国科学院研究生院硕士学位论文,2006.
[5] 贺敏.面向互联网的中文有意义串挖掘[D]. 中国科学院研究生院硕士学位论文,2007.
[6] 吴庆耀.无监督的中文语义词抽取技术研究[D]. 哈尔滨工业大学深圳研究生院硕士学位论文,2009.
[7] 贺敏,龚才春,张华平,等.一种基于大规模语料的新词识别方法[J].计算机工程与应用,2007.43(21): 157-159.
[8] N H Rais,M T Abdullah,R A Kadir. Multiword phrases indexing for Malay-English cross-language information retrieval [J]. Information Technology Journal, 2011,10(8): 1554-1562.
[9] Y F Zhang, F Long, L Bin. Identifying opinion sentences and opinion holders in Internet public opinion[C]//Proceedings of the 2012 International Conference on Industrial Control and Electronics Engineering, 2012: 1668-1671.
[10] H T Zheng, B Y Kang, H G Kim. Exploiting noun phrases and semantic relationships for text document clustering [J]. Information Sciences, 2009,179(13): 2249-2262.
[11] D Sreya, M M Narasimha. Using discriminative phrases for text categorization [C]//Proceedings of 20th International Conference on Neural Information Processing, 2013: 273-280.
[12] B Ibrahim, L Wiem, E Bile. Arabic domain terminology extraction: A literature review [J]. Lecture Notes in Computer Science, 2014,(8841): 792-799.
[13] Turdi Tohti, Winira Musajan, Askar Hamdulla.Unsupervised learning and linguistic rule based algorithm for Uyghur word segmentation[J]. Journal of Multimedia, 2014, 9(5): 627-634.
[14] J Atkinson, J Matamala.Evolutionary shallow natural language parsing [J].Computational Intelligence, 2012, 28(2): 156-175.
[15] 马乐,王力. 一种海量文本的动态索引方法[J]. 北京师范大学学报(自然科学版),2009,45(2): 134-137.
[16] W C Yang, J Liu, M Yu. Research of an improved algorithm for Chinese word segmentation dictionary based on double-array trie Tree[C]//Proceedings of 2nd CCF Conference on Natural Language Processing and Chinese Computing(NLPCC 2013),2013: 355-362.
[17] T Ahmad, M N Doja. Opinion mining using frequent pattern growth method from unstructured text [J].International Symposium on Computational and Business Intelligence, 2013: 92-95.
[18] S B Hazez. Linguistic pattern-matching with contextual constraint rules[C]//Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, 2001: 971-976.
[19] 张华平,高凯 ,黄河燕,等.大数据搜索与挖掘[M].北京: 科学出版社,2014.
[20] A Tiwari, R K Gupta, D P Agrawal. A survey on frequent pattern mining: current status and challenging issues [J]. Information Technology Journal, 2010, 9(7): 1278-1293.

吐尔地·托合提(1975—),博士,副教授,硕士生导师,主要研究领域为自然语言处理及文本挖掘。
E-mail: turdy@xju.edu.cn

维尼拉·木沙江(1960—),学士,教授,硕士生导师,主要研究领域为自然语言处理及信息检索。
E-mail: winira@xju.edu.cn

艾斯卡尔·艾木都拉(1972—),博士,教授,博士生导师,主要研究领域为智能信息处理。
E-mail: askar@xju.edu.cn
Uyghur Semantic String Extraction Based on Statistical Model and Shallow Linguistic Parsing
Turdi Tohti, Winira Musajan, Askar Hamdulla
(School of Information Science and Engineering, Xinjiang University, Urumqi, Xinjiang 830046,China)
1003-0077(2017)04-0070-10
TP391
A
