针对民生热线文本的热点挖掘系统设计
2017-10-11陶海军王加强
薛 彬,陶海军,王加强
(1.中国计量大学 信息工程学院,浙江 杭州 310018; 2. 北京市科学技术研究院 新技术应用研究所,北京 100089)
针对民生热线文本的热点挖掘系统设计
薛 彬1,陶海军1,王加强2
(1.中国计量大学 信息工程学院,浙江 杭州 310018;
2. 北京市科学技术研究院 新技术应用研究所,北京 100089)
随着城市智能化的发展,12345民生服务热线成为广大市民表达诉求的重要渠道之一.民生服务热线所收集的数据蕴含了丰富的当地社会热点,这些文本数据往往具有长度不一、信息量大等特点,而城市诉求管理需要一种高效的分类方法来处理这些热点问题. 在此首先阐述文本挖掘中的关键技术,在此基础上研究开发一个针对民生服务热线文本的民生热点挖掘系统,系统主要分为文本预处理、文本智能分类、民生热点挖掘三个功能模块,并借助可视化技术快速准确地分析出群众当前关心的热点,及时处理群众的诉求,使之有助于政府对社会民生建设的管理.
投诉文本;特征选择;文本分类;民生热点挖掘系统
Abstract: With the development of intelligent cities, "12345" people’s livelihood service hotline has become one of the important channel for citizens to express their demand. The collected data of people’s livelihood service hotline contains a wealth of hot issues of local society. The text data often have the characteristics of different length and of a large amount of information and so on. Therefore, the city demandsmanagement requires an efficient classification method to deal with these hot issues. A people’s livelihood hot issue mining system was developed in this paper. The system was divided into three functional modules: text preprocessing, text intelligent classification and people’s livelihood hot issue mining. By using visualization technology, it could analyze the current hot concern of the public rapidly and accurately, handle the demands of the citizens timely and help the government with the construction of social livelihood management.
Keywords: complaint text; feature selection; text classification; livelihood hot issue mining system
近年来,政府部门为了更好的了解民意,建立民生热线供市民表达诉求,成为政府部门了解当前社会热点的重要渠道之一.话务员将市民的诉求记录成文本信息,此类数据主要包含了上报的时间、地点和内容,以及人工记录的类别。由于数据量的不断增大,人工分类的分类标准不统一、分类效率较低等问题也随之暴露出来,这导致政府无法高效地发现当前社会热点信息.因此如何解决人工分类问题的弊端,快速、准确地把握群众当前关心的热点事件,及时处理群众的诉求,对于政府的管理有极大的帮助.
本系统引入文本挖掘的理念和方法,对比国内外的文本挖掘技术,通过分析民生热线文本的特点,将现有的文本挖掘技术运用于民生热线文本上,取代原始的人工分类方法,研究开发一个针对民生热线文本的热点挖掘系统,系统功能框架如图1.

图1 系统框架图Figure 1 Description of the system
本系统主要分为以下几个模块:在线文本预处理、文本智能分类、民生热点挖掘等.在线文本预处理模块主要是对新录入的文本进行分词、去除停止词以及词性标注等预处理;本系统利用大量文本数据通过不同算法训练分类器,然后对新录入文本采用精度高的分类器进行分类;民生热点模块可视化展示当前热点领域、群众关心的十大热点等文本挖掘得到的结果,并且与地理坐标相结合,了解各个区域的民生热点信息.
由于文本分类在文本挖掘领域的重要性,人们对其进行了广泛深入的研究.Salton等人于1997年提出向量空间模型(Vector Space Model,VSM)[1],这是一种简便、高效的文本表示模型.当前对于文本研究使用的技术主要分为两大类:一类是基于词典的方法;另一类是基于机器学习的方法[2]。1968年Cover等人提出K近邻(kNN,k-Nearest Neighbor)[3],是一个理论基础完善的机器学习算法,广泛地运用在文本分类中.朴素贝叶斯(Naive Bayes,NB)分类算法是来源于统计学中的贝叶斯公式的机器学习方法,Eyheramendy 等人将其用在文本分类发现也取得了不错的效果[4]. Vapnik等人于1995年提出的支持向量机(Support Vector Machine,SVM)[5],广泛地应用于数据挖掘中.
由于热线文本往往仅有几句话,这种形式的信息可以定义为短文本,其具有长度不一、内容丰富等共同特点.标签、微博、短信等都属于短文本的范畴[6].传统的文本挖掘算法都是基于长文本的基础上提出的,因此如何对这些短文本进行预处理以及进行后续的数据挖掘工作,都具有重要的意义[7].
1 文本挖掘技术
在文本分类之前需要先进行文本预处理,由于中文文本的特殊性,影响文本分类和文本聚类等精确度的关键因素之一就是文本预处理过程[8].在预处理过程中,需要对中文文本进行分词处理[9]、去除停用词[10],获得文本的关键词,这样才能提高文本分类、聚类等的精确度.
除了文本预处理之外,在进行文本分类等进一步文本挖掘之前还需要对文本进行特征选择,Yang等人提出用TF-IDF(Term Frequency-Inverse Document Frequency )方法在特征选择中计算各个特征词项的权重[11],除了TF-IDF之外,计算权重的方法还有信息增益、互信息[12]、等,在对预处理后的文本词集合进行特征选择后,进一步对词集合进行筛选,起到文本降维的作用.
1.1 文本分词
中文文本以汉字作为基本单位,词与词之间不像英语具有明显的形态界限,而且有很多标点符号,计算机难以识别词句之间的关系,所以在处理中文文本时首先必须要将词与词分开,即分词.目前主要分为基于词典的分词算法和无词典的分词算法两种,常用的有正向最大匹配法、最大概率法[13]、特征词库法[14]、语法分析法以及理解切分法.
1.1.1 正向最大匹配法
正向最大匹配法(Maximum Matching Method)[15]是基于词典的分词技术中最常用的方法之一,基本原理是:用Length表示词的最大长度,正向地依次取长度为Length的字符串,在词典中查找.如果匹配成功就将该字符串当作一个词语进行切分,然后再正向移动长度为Length的字符继续进行查找.如果查找失败则将Length=Length-1进行查找,如此进行下去,直至切分成功为止.
1.1.2 分词系统
中文文本技术已经有了深入的研究,学者们开发的一些成熟的分词系统有:清华大学SEG分词系统[16]、Microsoft Research 汉语句法分析器中的自动分词NLPWin等,每个分词包都具有自己的特点,本文将对目前较为流行的两种R分词工具:Rwordseg、JiebaR,针对民生服务热线数据进行分词结果比较,确定最优分词包.
选取100 000条民生服务热线数据,分别采用Rwordseg和JiebaR进行分词,通过system.time查看时间,可见JiebaR的分词时间消耗的更少.
表1分词方法耗时比较
Table 1 Time comparison of word segmentation method

方法用户系统总时间Rwordseg214.0688.97304.23JiebaR159.1784.90251.04
分词准确率才是文本分词最重要的指标,现选取两条民生服务热线数据,查看Rwordseg和JiebaR分词结果的差异.可见在对Test1的分词结果中,Rwordseg未将“西站”、“南站”识别成一个词,而在Test2的分词结果中,Rwordseg未将“七里河”识别成一个词,导致重要信息的丢失,在这两条数据中,JiebaR都很好的将句子分词识别,保持对句子的正确理解.

表2 分词方法结果比较
1.2 文本降维
1.2.1 处理停止词
在对文本进行分词之后,需要对分词结果进行进一步处理.比如对“某女士咨询西站到南站的班车信息,已告知.”进行分词,结果中含有“某”、“女士”、“到”、“的”等词,这些词对文本挖掘毫无意义,称之为停止词.该类词具有极其普遍、出现密度高等特点,在任何类别的文章中都经常出现,但是对于表征文本却没有意义.在特征提取过程中,停止词会导致结果出现误差,因此需要在文本预处理阶段将停止词去除.这样不仅能够消除干扰,而且还能降低文本维度.
停止词去除需要载入一个停止词表,停止词表中出现的词,都会从分词结果中滤除.比如对“某女士咨询西站到南站的班车信息,已告知.”进行分词及停止词处理后,得到的结果就只有“西站”、“南站”、“班车”,这就将无用信息滤除.在对民生数据进行停止词去除时,需要手动加入一些专有领域的词,完善停止词表.
1.2.2 词性标注
除了分词和处理停止词,词性标注也是文本预处理时重要的一部分[17],它有利于分词后关键词筛选.在对民生投诉文本进行处理时,由于是针对专有领域的文本挖掘,所以得根据投诉文本的特殊性对分词结果进一步的筛选. 投诉文本中的语气词、叹词等虚词对挖掘社会热点并没有实际意义,比较重要的是包括名词、动词、人名、地名等实词,所以在去除停止词后需要对分词结果进行词性标注,提取相关词性的词作为结果.
1.2.3 特征选择
数据集中每个类别5 000条共50 000条数据,其中部分数据在预处理后可能导致所有词语都被去除,另外有些数据由于长度过长,预处理后还有几十个词,这些情况对于分类器的训练会有很大的干扰,因此在预处理后,需要对数据进行进一步筛选,也就是特征选择.特征选择过程是对所有的特征词赋予权重,然后根据权重进行排列,选取一定数目的特征词,因此权重计算的准确性决定了特征选择的好坏.特征选择过程如下:
1)输入预处理后的词项集合
W={w1,w2…,wm};
2)计算W中每个的权重Weighti,并按从大到小排列;
3)选取Weighti最大的k个值对应的词项加入中;
4)输出特征词项集合为
Sc={cw1,cw2,…,cwk}.
常用的文本特征权重计算方式有:TF-IDF、信息增益等,TF-IDF不仅考虑某个特征项在该文本出现的频率,而且考虑在整个文本集的频率,是应用最广泛的权重计算方法.其中,TF称为词频,即给定词语在某一文本出现的频率.通常,词频越大则表明该词对本文越重要,类别区分能力越强;IDF代表逆文档频率,即数据集中文本总数与包含给定词语的文本数之商.在实际应用中,采用TF-IDF方法来计算特征项权重,如下所示:
(1)
其中,特征词j在文本i中的权重为WeightTFIDF(i,j),特征词j在文本i中出现的频率为 ,数据集的文本总数为N,数据集中包含特征词j的文本数为nj.如果对于某个词而言,在该文本出现的次数比较多,而在整体文本集中出现的次数较少,即WeightTFIDF(i,j)较大,则说明这个词语对于该文本具有较好的表征能力.
1.3 文本分类
传统的文本分类算法有K近邻分类、朴素贝叶斯分类、支持向量机等,由于支持向量机多采用于二分类,而本系统需要进行多分类,所以仅考虑朴素贝叶斯分类和K近邻分类算法来构建分类器.
1.3.1 K近邻分类
kNN算法是一种有监督学习的分类算法,该算法的基本思想是:在给定新样本之后,考虑新样本与训练样本集所有文本的距离,选取距离最近的k个样本的类别判定新样本所属的类别.具体的步骤如下:给定新样本,预处理后用特征词向量表示;
2)在训练样本集中选出与新样本距离最近的k个样本,距离计算如下:
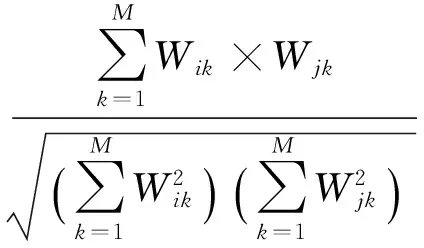
(3)
其中,k值一般是设定一个初始值,然后重复实验选取最优值.
3)在最相似的k个样本中,计算每类的权重,计算公式如下:
(4)
4) 比较类的权重,将新样本的类别判定为权重最大的那个.
kNN算法原理简单易实现,是现在最普遍使用的分类算法之一.
1.3.2 朴素贝叶斯分类
贝叶斯分类是以贝叶斯定理为基础的一类算法的总称.假设A、B两个事件,且P(A)>0,称P(B|A)=P(AB)/P(A)为事件A发生的条件下事件B发生的条件概率.贝叶斯定理如下:
试验表明,当样本数500~1 000较低时,CNN文本分类相对于其他文本分类算法准确率更高,虽然样本数在1 000~2 000之间,DBN算法以及RNN算法相对于CNN算法准确率有所提高,但是当样本数增大时,CNN 的准确率增长迅速。所以,实验表明,CNN算法在样本数低或者高的情况下都能较好地进行文本分类,准确率高于其他文本分类算法。
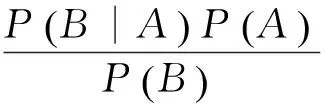
(5)
其中,P(A)称作A的先验概率或边缘概率,P(B)称作B的先验概率或边缘概率,P(A|B)称作已知B发生后A的条件概率,P(B|A)称作已知A发生后B的条件概率.
朴素贝叶斯是假设特征词间是相互独立的,并对每个样本计算出现在各个类别中的概率,概率最大的就判别成该文的类别.设定类别集合为C={c1,c2,…,cm},样本d={w1,w2,…,wm},n和m分别表示样本的特征词数和类别个数,则对于样本di,属于类别的条件概率如下:
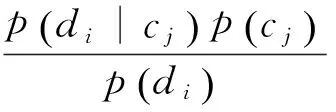
(6)
其中,p(cj|di) 是样本di属于cj的概率,p(cj)是类别的先验概率,p(di)是样本的概率.根据假设,各特征词项相互独立,p(di)可以表示如下:
p(di|cj)=p(wi1|cj)×…×p(win|cj).
(7)
其中,wik表示文档中di第k个特征项,所以P(ci|di)可以表示如下:
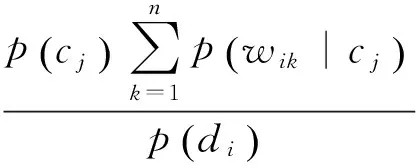
(8)
贝叶斯分类的优点是简单,易于理解,且性能较好,分类的过程效率高.并且相对于K近邻算法需要把新样本加入原有文本数据集进行重新训练,通过朴素贝叶斯算法训练的分类器可以直接用于新样本分类,在实时分类中效率较高.
2 实验与分析
2.1 实验环境
实验在如表3的软硬件环境下进行.

表3 实验环境
2.2 实验数据及结果评价指标
本系统采用的是来自北京新技术应用研究所的兰州市2016年12345民生服务热线文本数据,将其存在关系数据库MySQL中,语料库中共有178 948条数据,根据投诉内容可分类供暖供热、供水服务等十类,语料库文本类别分布情况如表4所列.
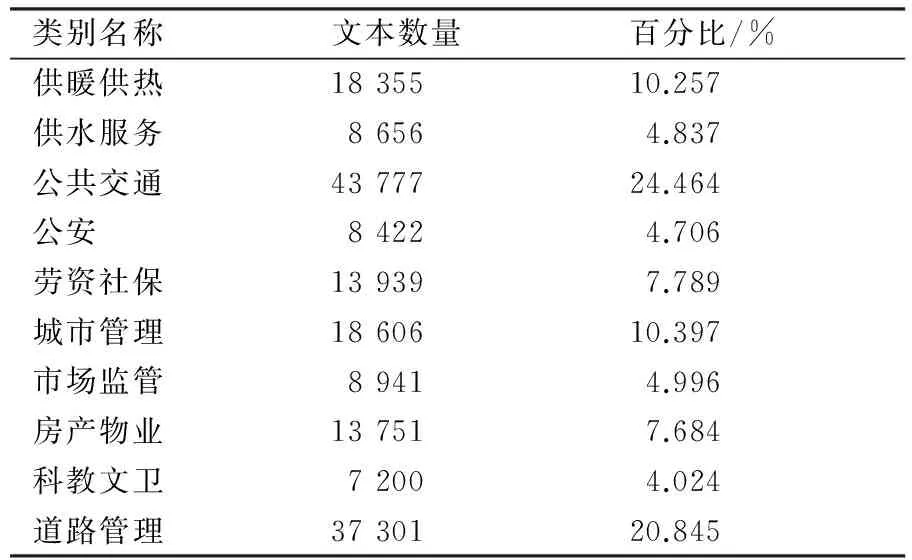
表4 实验数据集
由表4可知,各个类别的文本数目差异很大,其中最少的科教文卫类别的文本数目只有7 200条,而最多的公共交通类有43 777条,由于本系统的主要内容不是针对不均衡数据的研究,因此本系统拟通过随机选取,并经过过滤空数据与去重等处理后在每类中都筛选出5 000条文本,共50 000条文本作为实验数据语料.
分类实验结果可以从分类过程的复杂度、分类算法的简洁度以及分类效果几个方面来衡量[19],其中分类效果是最为重要的评价标准.
对于某个类别,准确率是指分类器正确分到该类别的文本数与被分到该类别所有文本数的比值;召回率是指分类器正确分到该类别的文本数与这个类别应该包含的文本数的比值.将准确率和召回率作为评价标准会出现如下情况:对于某个类别的5 000条数据全部都正确分到该类,但是还有大量不相关的文本被分类器分到该类,此时召回率是1,但准确率会比较低;若对于某个类别的5 000条数据只要少量正确分类,但是只有少量其它不相关文本被分到该类,此时准确率很高,但召回率比较低.因此使用准确率和召回率作为分类评价指标不能全面的衡量分类效果,本系统使用F1值作为评价指标.
由于本系统处理的是多分类,所以还需要衡量整个文本集的分类效果,通常使用所有被正确分类的文本数与总体文本数的比值作为整体分类效果的评价指标.

(9)

(10)
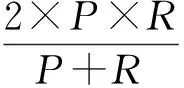
(11)
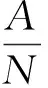
(12)
其中,P表示准确率,R表示召回率,N为总体文本个数,a表示正确分到该类别的文本个数,b表示错误分到该类别的文本个数,c表示被错分到其它类别的文本个数,A表示所有正确分类的文本,C表示对于总体的分类正确率.
2.3 不同特征词数的分类结果
为了评估朴素贝叶斯分类在民生服务热线数据中的性能,本系统对分类算法进行了实验分析与仿真.在对原始文本数据进行预处理之后,由于特征词数不一,为了避免不必要的误差,选取特征词数大于15个的数据作为构造分类器的实验数据集.
由于投诉文本的特殊性,采用不同的分词算法和分类算法在同一个数据集下进行四次实验,分别采用Rwordseg分词+kNN分类、Rwordseg分词+朴素贝叶斯分类、JiebaR分词+kNN分类、JiebaR分词+朴素贝叶斯分类.为了验证特征词数对分类精度的影响,本实验将实验数据集随机分为两部分:80%作为训练集,20%作为测试集,分别选取3~15个特征词进行实验,各个特征词数的分类精度如表5所示.为了更直观地表示精度随特征词数的变化也相应地变化,各个特征词数的分类精度如图2.
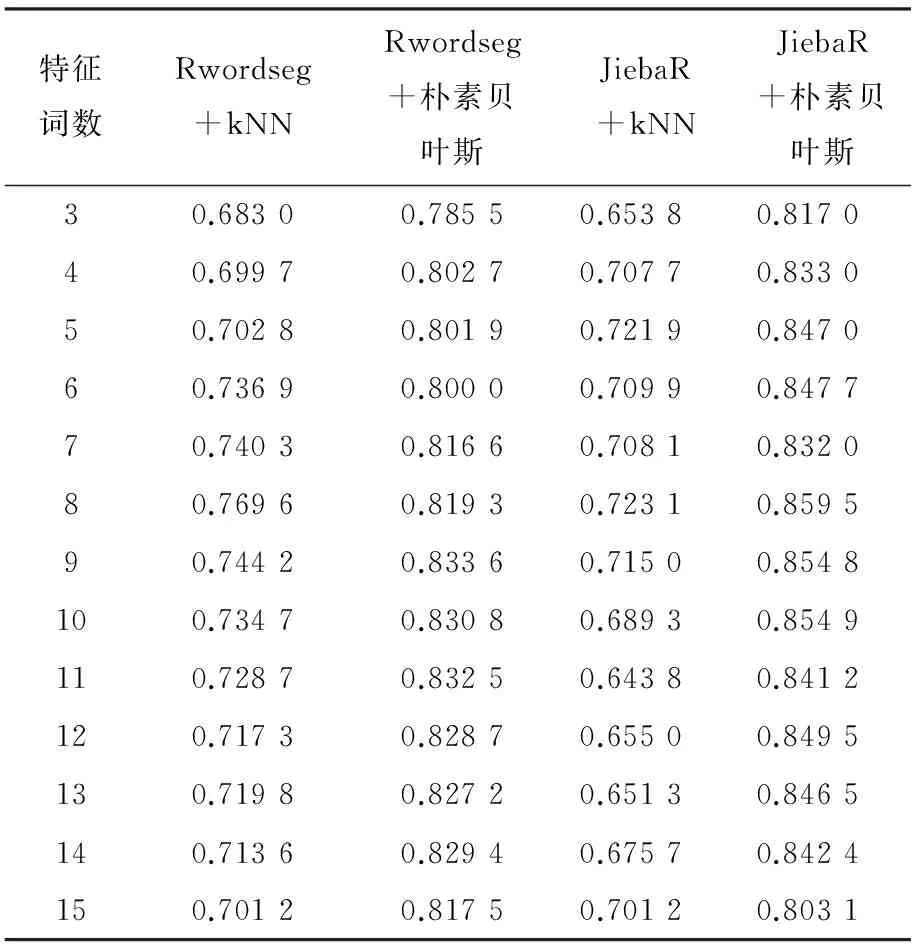
表5 四种方法的分类精度
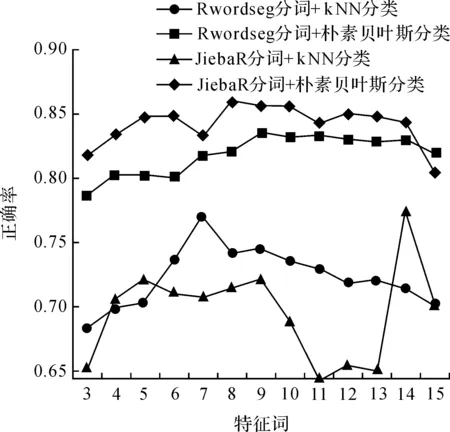
图2 四种方法的分类精度图Figure 2 Classification accuracy of four methods
由图2可以看出,在该数据集上朴素贝叶斯分类的效果明显比kNN分类好,同时也能看出,随着特征词数的递增波动不明显,因此可以认为朴素贝叶斯分类方法在此数据集上表现更为理想.并且由于kNN算法有以下缺点:第一,参数k不能根据样本规模动态改变;第二,由于kNN算法是惰性学习算法,必须得到新文本与整个训练文本集的所有相似度值,计算量较大导致时间耗费多,不适用于实时分类的情况.因此选取朴素贝叶斯分类作为后续实验的分类方法.
2.4 投诉文本各个主题分类效果
为了衡量投诉文本各类别的分类效果,采用整体分类精度最高的JiebaR分词+朴素贝叶斯分类来进行实验,分别计算各个类别的准确率、召回率以及F1值,实验结果如下:
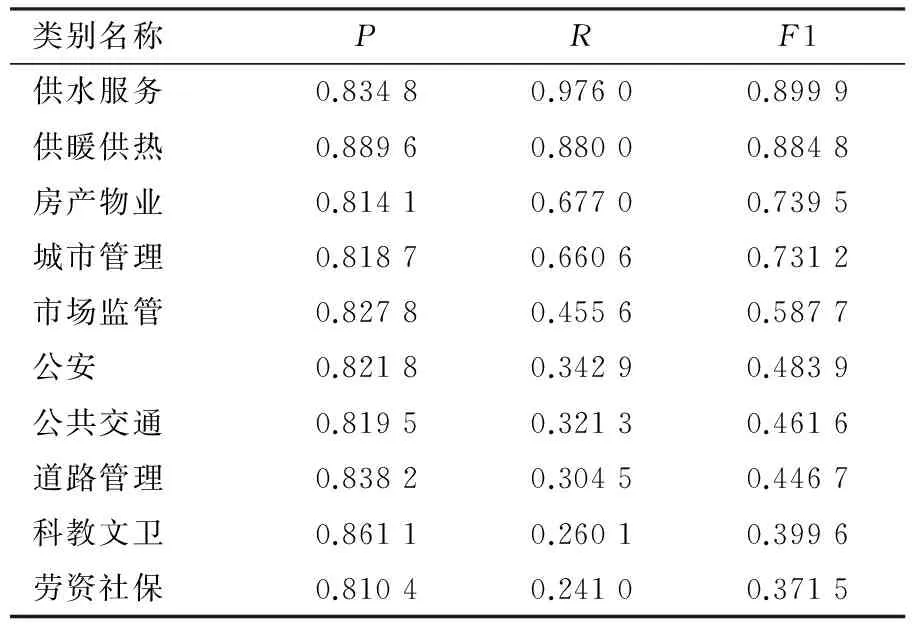
表6 分类结果
从结果可以看到,供水服务、供暖服务以及房产物业这三个类别的分类效果较好,而道路管理、科教文卫以及劳资社保这三个类别的分类效果较为不理想.通过观察原始数据集和特征选择后的关键词发现,分类效果好的类别往往文本长度较长,具有更多的关键特征词,比如供水服务类别中的“水费、停水”等词,而分类效果不理想的类别往往具有大量含糊不清的关键词,与其它类别有着较多的重叠词,比如劳资社保类别中的“部门,营业执照”等词就可能也是市场监管类别的关键词.
3 系统设计与实现
3.1 总体结构
本系统分为数据层、数据挖掘分析层、页面展示层.系统的总体结构如图3.

图3 系统整体架构Figure 3 Structure of the system
1) 数据层
本层由数据库构成,主要是进行数据存储、管理和维护.在数据处理阶段,对12345民生服务热线数据采集后对投诉文本数据进行数据清洗,完成数据的加工处理工作,生成投诉文本原始数据仓库,满足后继的数据分析与数据挖掘的需要.当服务端执行查询指令,数据库会执行相应的查询并返回数据到服务端;当服务端执行存储指令,数据库会将新的文本数据添加到原有数据表中.
2) 数据挖掘分析层
本系统的文本挖掘算法在本层由R语言实现,包括文本分词、特征选择、训练分类器以及新文本分类等.服务端接受浏览器的请求后,将浏览器端输入的文本传递到服务端,再将其作为RScript的输入执行R脚本进行分词、分类等.
3) 页面展示层
本层是用户层,即浏览器.根据不同的应用需求,本层被分解成多个主题,每个主题利用数据层和数据挖掘分析层进行数据挖掘以及可视化,包括文本预处理、文本智能分类、民生热点挖掘等模块.
4) 服务端
服务端即web服务器,采用Apache Tomcat服务器,负责处理来自浏览器的请求,比如向数据库请求数据、执行R脚本等.
3.2 可视化结果分析
系统通过分析电话反映的内容,将事件进行归类,提取出关键词进行热点挖掘.如图3所示该模块可以分为四个部分,围绕着“群众”进行热点挖掘,并与地理坐标相结合,发掘不同区域群众关心的领域以及热点,并用利用现有的可视化技术将数据挖掘结果展示出来,有利于政府决策者聚焦当前社会热点.系统实现总体情况分析、热点领域分析、区域热点分析以及热点动态分析功能,选取热点领域分析和热点动态分析加以说明.
3.2.1 热点领域分析
系统将所有事件按照性质归属为不同的大类和小类,从多个维度进行深入分析.通过这样对事件类型的具体分析,可以准确的把握事件热点.比如系统对2016年兰州市民生服务热线数据的事件类型进行分析,结果如图4.根据图中的矩形图分析,民生查询、公共交通、道路管理、咨询查询、供暖供热、城市管理占据了投诉事件的前五位.而道路管理这个大类中,出租车管理是接受投诉最多的子类事件,其后依次是:车辆管理、限行政策、黑车查处、交通管理和违章处罚,相关部门就可以得知群众对于出租车的管理存在较大的不满,需要在这方面进行改进.
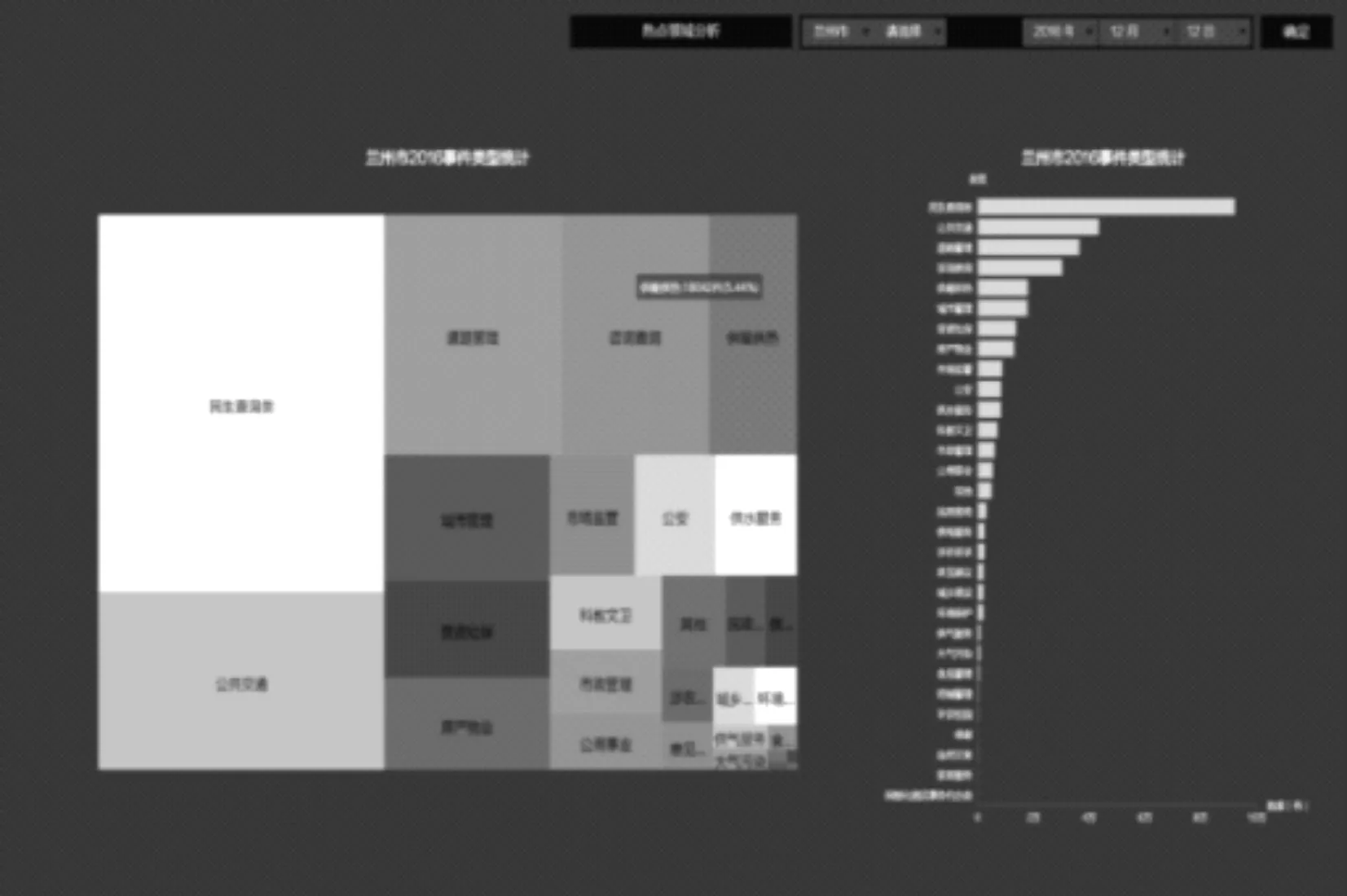
图4 热点领域分析可视化Figure 4 Visualization of hot field analysis
3.2.2 热点动态分析
事件的发生具有一定的规律性,把握投诉事件发生的规律对政府积极预防、集中整治、提升治理水平有重大意义.本部分从时间维度出发对民生服务热线事件进行分析,系统可以按照月份对投诉事件总数、各类型事件数量以及每月事件的投诉热词进行统计.如图5,每年的11月份开始,供暖供热类的事件数量逐渐增加,热词以“暖气”、“采暖”等词为主.这样基于时间维度的动态分析,相关部门的管理人员可以对热点的发展趋势有个宏观的分析,从而准确的把握民生服务热线事件中隐藏的规律,提升治理水平.
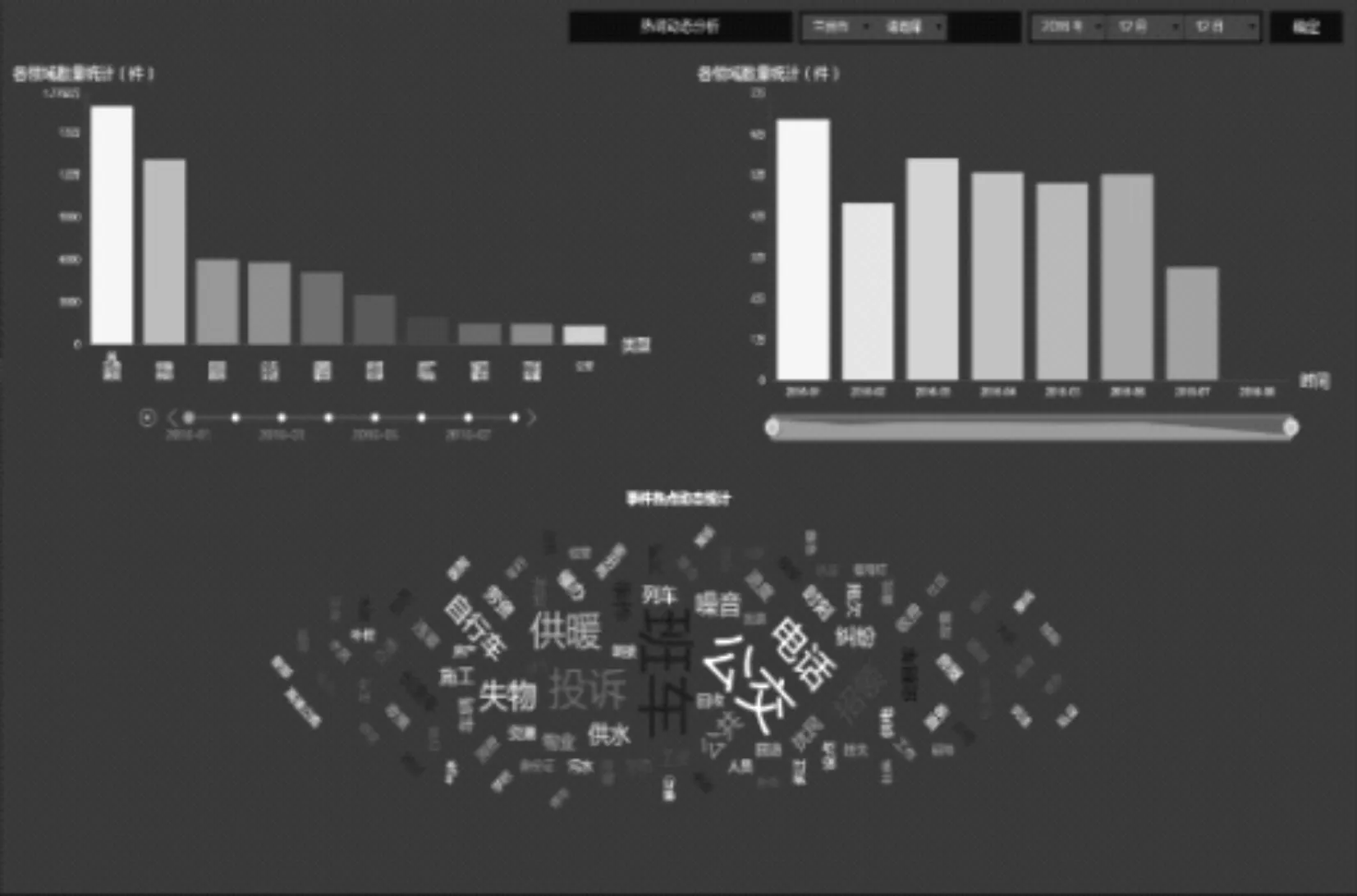
图5 热点动态分析可视化Figure 5 Visualization of hot spot dynamic analysis
4 结果与展望
本系统针对兰州市12345民生服务热线数据,对大规模民生服务热线信息进行基于时间尺度、空间尺度的数据分析与挖掘,同时构建针对特定主题、特定区域的地理实体识别算法,实现对热线文本的预处理和自动分类等功能,并对文本的分析与挖掘结果进行可视化,快速准确地把握住群众的关注焦点.在对投诉文本进行分析的时候,发现分类算法方面存在以下问题:1)原始数据的类别明显存在分类错误,这是由于人工分类时疏忽导致;2)原始数据的类别存在重复问题;3)各个类别的文本数目差异很大,出现语料严重偏斜的问题.针对海量文本,需要找到一种方法来解决语料不平衡问题,优化分类算法.系统方面,在未来还可以将投诉信息与人口信息相结合,比如发掘各个年龄段、各个学历的人群投诉信息的差异,这对于政府的管理和决策可提供很大的帮助.
[1] SALTON G, WONG A, YANG C S. A vector space model for automatic indexing[J].CommunicationsoftheAcm, 1975, 18(11):613-620.
[2] 叶佳骏, 冯俊, 任欢,等. IG-RS-SVM的电子商务产品质量舆情分析研究[J]. 中国计量大学学报, 2015, 26(3):285-290. YE J J, FENG J, REN H, et al. IG-RS-SVM’s analysis of public opinion on the quality of e-commerce products[J].JournalofChinaUniversityofMetrology, 2015, 26(3): 285-290.
[3] SLAPIN J B, PROKSCH S O. A scaling model for estimating time-series party positions from texts[J].AmericanJournalofPoliticalScience, 2008, 52(3): 705-722.
[4] ZHANG Y, LIU B, JI X, et al. Classification of EEG signals based on autoregressive model and wavelet packet decomposition[J].NeuralProcessingLetters, 2017, 45(2): 365-378.
[5] KANJ S, ADBALLAH F, DENDENOEUX T, et al. Editing training data for multi-label classification with the k-nearest neighbor rule[J].PatternAnalysisandApplications, 2016, 19(1):145-161.
[6] 曹彬, 顾怡立, 谢珍真,等. 一种基于大数据技术的舆情监控系统[J]. 信息网络安全, 2014(12):32-36. CAO B, GU Y, XIE G, et al. A public opinion monitoring system based on big data technology[J].InformationNetworkSecurity, 2014(12): 32-36.
[7] 崔春生, 吴祈宗, 王莹. 用于推荐系统聚类分析的用户兴趣度研究[J]. 计算机工程与应用, 2011, 47(7):226-228. CUI C S, WU Q, WANG Y. Research on user interest in clustering analysis of recommender systems[J].ComputerEngineeringandApplications, 2011, 47 (7): 226-228.
[8] 周姚. 基于云计算的文本挖掘技术研究[D]. 长沙:国防科学技术大学, 2011. ZHOU Y.ResearchonTextMiningTechnologyBasedonCloudComputing[D]. Changsha:University of Defense Technology, 2011.
[9] 丁琼. 基于向量空间模型的文本自动分类系统的研究与实现[D]. 上海:同济大学, 2007. DING Q.ResearchandImplementationofAutomaticTextCategorizationSystemBasedonVectorSpaceModel[D]. Shanghai: Tongji University, 2007.
[10] 王素格, 魏英杰. 停用词表对中文文本情感分类的影响[J]. 情报学报, 2008, 27(2):175-179. WANG S G, WEI Y J. The influence of the word list on the sentiment classification of Chinese text[J].JournalofInformationScience, 2008, 27(2): 175-179.
[11] JI S, TANG L, YU S, et al. A shared-subspace learning framework for multi-label classification[J].ACMTransactionsonKnowledgeDiscoveryfromData, 2010, 4(2):1-29.
[12] LI S, WU H, WAN D, et al. An effective feature selection method for hyperspectral image classification based on genetic algorithm and support vector machine[J].Knowledge-BasedSystems, 2011, 24(1): 40-48.
[13] 马玉春, 宋瀚涛. Web中文文本分词技术研究[J]. 计算机应用, 2004, 24(4):134-135. MA Y C, SONG H T. Web. Chinese text segmentation technology[J].Computerapplications, 2004, 24 (4): 134-135.
[14] 奉国和, 郑伟. 国内中文自动分词技术研究综述[J]. 图书情报工作, 2011, 55(2):41-45. FENG G H, ZHENG W. The domestic Chinese automatic segmentation technology research of[J].LibraryandInformationService, 2011, 55(2): 41-45.
[15] 常建秋, 沈炜. 基于字符串匹配的中文分词算法的研究[J]. 工业控制计算机, 2016, 29(2):115-116. CHANG J Q, SHEN W. Research on Chinese word segmentation algorithm based on string matching[J].IndustryControlComputer, 2016, 29(2): 115-116.
[16] 沈达阳, 孙茂松, 黄昌宁. 汉语分词系统中的信息集成和最佳路径搜索方法[J]. 中文信息学报, 1997(2):34-47. SHEN D Y, SUN M S, HUANG C N. Information integration and optimal path search method in Chinese word segmentation system[J].ChineseJournalofInformation, 1997(2): 34-47.
[17] 王敏, 郑家恒. 基于改进的隐马尔科夫模型的汉语词性标注[J]. 计算机应用, 2006, 26(增刊2)197-198. WANG M, ZHENG J H. On the attribution of Chinese part of speech based on improved Hidden Markov Model[J].ComputerApplications, 2006, 26(Suppl 2): 197-198.
[18] 于海燕, 陈丽如, 郑文斌. 基于核超限学习机的中文文本情感分类[J]. 中国计量大学学报, 2016, 27(2):228-233. YU H Y, CHEN L R, ZHENG W B. Sentiment classification of Chinese text based on kernel transfinite learning machine[J].JournalofChinaUniversityofMetrology, 2016, 27(2): 228-233.
[19] 宋枫溪, 高林. 文本分类器性能评估指标[J]. 计算机工程, 2004, 30(13):107-109. SONG F X, GAO L. Text classifier performance evaluation index[J].ComputerEngineering, 2004, 30(13): 107-109.
Designofhotissueminingsystemsbasedonlivelihoodservicehotlinetexts
XUE Bin1, TAO Haijun1, WANG Jiaqiang2
(1. College of Information Engineering, China Jiliang University, Hangzhou 310018, China; 2.Institute of New Technology Applications,Beijing Academy of Science and Technology, Beijing 100089, China)
2096-2835(2017)03-0371-09
10.3969/j.issn.2096-2835.2017.03.017
2017-04-09 《中国计量大学学报》网址zgjl.cbpt.cnki.net

TP391
A
