面向食品安全领域的个性化知识搜索系统研究
2017-09-22袁培森任吴北任守纲朱淑鑫徐焕良
袁培森,任吴北,任守纲,2,朱淑鑫,徐焕良,2
(1.南京农业大学信息科学技术学院,南京210095; 2.江苏省肉类生产与加工质量安全控制协同创新中心,南京210095)
面向食品安全领域的个性化知识搜索系统研究
袁培森1,任吴北1,任守纲1,2,朱淑鑫1,徐焕良1,2
(1.南京农业大学信息科学技术学院,南京210095; 2.江苏省肉类生产与加工质量安全控制协同创新中心,南京210095)
大数据时代,从海量的数据中发现对用户有用的知识成为研究领域重要的问题.通过集成多个搜索引擎的查询结果,实现食品安全领域中搜索信息的集成和个性化自适应排序.本文设计基于元搜索技术、知识本体和自适应的排序学习技术,实现多个搜索引擎相关查询结果集成,在对用户点击的标注和知识本体的基础上,利用基于监督学习的排序技术,实现对食品安全领域信息的个性化自适应排序.系统实现了集成多个搜索引擎的食品安全相关知识的提取和相关结果的重新排序.本研究不仅实现了多个搜索引擎食品安全信息查询相关的结果集成,而且能够根据用户的偏好实现结果的自适应排序.
食品安全搜索;个性化排序;搜索集成;领域本体
0 引言
随着信息技术的迅猛发展,各种信息查询在人们的生活中占据了重要地位,已经成为互联网在日常生活中的重要应用之一.中国互联网络信息中心第37次发布的调查报告显示,截至2016年6月,我国搜索引擎用户达7.10亿,年增长率约为3.1%[1],其中涉农的用户占比31.7%,规模达2.25亿,显示出农业搜索快速增长的势头.搜索引擎成为除即时通信应用之外使用率最高的互联网应用.近几年中,中国网民的规模持续扩大,而搜索引擎作为基础应用,其用户规模也持续增加,同时,搜索引擎的功能逐渐完善并各具特色,发展也更加多元化.
农业信息化是我国信息化的重要领域之一.信息作为现代农业发展的核心要素,贯穿农业生产全过程,在知识传播、技术咨询、决策支持等方面起着关键作用.目前,面向农业的信息服务资源建设得到突飞猛进的发展,农业搜索服务于农业专业需求的特定人群,其社区化特点明显,特定人群的价值决定了农业搜索的价值.目前,国内外在农业领域的搜索研究,主要集中在垂直搜索引擎[2-3],它具备“专、精、深”的特点[4],但是农业搜索不仅需要“专、精、深”,更需要“记忆模型”,记住用户的查询偏好,让用户更快捷地找到信息,直达全面、系统的结果.国外现有的农业搜索引擎主要有agnic(http://www.agnic.org/)、agrisearch (http://www.agrisearch.org/)、agriscape(http://agriscape.com/)等.当前,国内专注农业领域的搜索发展迅速,典型的系统有中国农业科学院农业信息研究所的“SDD农搜”[5],“搜农”(http://www.sounong.net/),cast(http://www.cast.net.cn/)等,但是这些搜索系统功能相对单一,缺少个性化查询功能,查询的结果缺少系统的知识水平的抽取.
食品安全是农业领域的重要问题之一,关系到国计民生,但是相关的信息和知识查询缺乏相关的专业查询系统.文献[6]提出了基于本体的农业信息服务个性化推荐框架,但是缺少系统实现;文献[7]研究了基于本体学习的食品安全网络舆情信息的构建技术,文献[8]介绍了本体学习的相关技术.
本文在食品安全智能化、知识化和个性化搜索需求背景下,以提供更加精确和更加贴近用户要求的搜索结果为目的,提供智能化、知识化和个性化农业综合信息查询.本文利用元搜索引擎和机器学习排序技术,设计了农业领域面向食品安全的个性化搜索排序系统(Personalized Re-ranking Of food Safety Knowledge system,简称PROSK),PROSK系统从多个搜索引擎获取基础的查询结果,根据用户的查询历史和日志,生成用户轮廓,结合用户轮廓和知识本体,对结果进行集成和自适应排序,满足不同用户查询结果的个性化和查询结果的知识化、系统化.个性化服务针对用户的不同提供的信息也是不相同的,它通过挖掘用户浏览行为,找到用户感兴趣的知识.
本文的第1节首先介绍基础知识和相关技术;第2节介绍了系统的排序原理和过程;第3节介绍了系统的实现及查询;最后,第4节对本文进行了总结和展望.
1 本体与元搜索集成
1.1 本体知识
本体是指一种“形式化的,对于共享概念体系的明确而又详细的说明”,是一种数据和知识集成的重要技术[8-10].本体提供特定领域中存在着的对象类型或概念及其属性和相互关系,它是对特定领域之中相关概念及其相互关系的形式化表达,用于描述对象类型、属性以及关系类型所构成的世界.
本体可以用五元组O=〈C,R,H,rel,A〉形式化表达,其中,C为概念集;R为关系集合; H表示概念层次,即概念之间的分类关系;rel为概念间的非分类关系,A表示本体公理[11].
本体的核心在于它能够对领域内的概念以及概念之间的关系进行定义,具有良好的概念层次、表达特点,能够在概念间建立丰富的语义联系,便于实现知识整合.本文使用本体进行食品安全领域的知识建模和搜索知识集成共享,属于领域本体[8,10].
食品安全本体集成框架(Food Safety Onlology Integration Framework)可以表示为三元组Fs=〈G,S,M〉,其中,G为全局本体,S为局部本体,M为G和S之间的映射.
1.2 元搜索集成
搜索引擎一般分为独立搜索和元搜素(Meta-search)[12].独立搜索引擎基于Robot技术,它使用Robot程序从网络中发现信息并且建立索引数据库.搜索时,它首先检索索引数据库,得到数据库中的相关内容,最后根据内容搜索到相应的信息或链接站点并提供给用户.
相对于独立搜索的元搜索技术,根据用户的搜索需求,将查询提交给多个独立型搜索引擎,从多个搜索引擎的搜索结果,并对多个引擎返回的结果集中处理,最后将处理后的搜索结果返回给用户[13-14].元搜索引擎(Meta Search Engine,MSE)从多个搜索引擎得到查询结果,由于不同搜索引擎结果不尽一致且排序标准不统一,因此如何根据用户的特点对结果重新排序成为一个重要的研究课题.元搜索引擎的关键是对查询结果的集成和排序.即指对其调用的多个成员搜索引擎所返回的结果集成、去重等,然后按照一定的准则排序,将排序结果按一定顺序展现给用户的过程[13].如何对元搜索引擎的结果进行个性化的排序对用户排序结果的满意度至关重要.
定义1元搜索查询(Meta Search Engine Query)是一个四元组,MSEQ=〈E,Q,T,C〉,其中,E是元搜索引擎集合,Q为查询集合,T是排序方法,C是查询结果的选择标准.
给定E={E1,E2,…,Em},对于查询q∈Q,搜索引擎Ei(1≤i≤m)产生的原始结果,为则MSEQ的查询结果集合为其中R(q)中的结果去除掉了多个搜索引擎不满足条件C的结果.
PROSK系统采用元搜索技术,从多个综合搜索引擎获取相关结果,并对结果集成和排序,原因在于一方面现有的独立搜索系统功能比较完善,具有互补优势,可以很好地利用现有的独立搜索引擎,避免系统从头做的巨大代价;另一方面,可以博采多个独立搜索引擎结果,并对多个独立搜索引擎结果进行高效集成和智能排序.PROSK系统如图1所示.
2 PROSK系统的个性化排序
2.1 个性化查询
个性化查询服务是一种有效的信息服务方式,这种服务方式的实现主要是根据用户的需求特征,通过对信息进行收集、整理、分类、分析,向用户提供最可能需要的信息,以满足用户对信息的需求[15-16].个性化查询服务也是未来搜索引擎发展的一个重要内容,它面向不同的用户查询,返回个性化的搜索信息并对结果的重要性根据个人偏好进行排序.PROSK系统的个性化查询主要体现在对查询结果的排序方面.
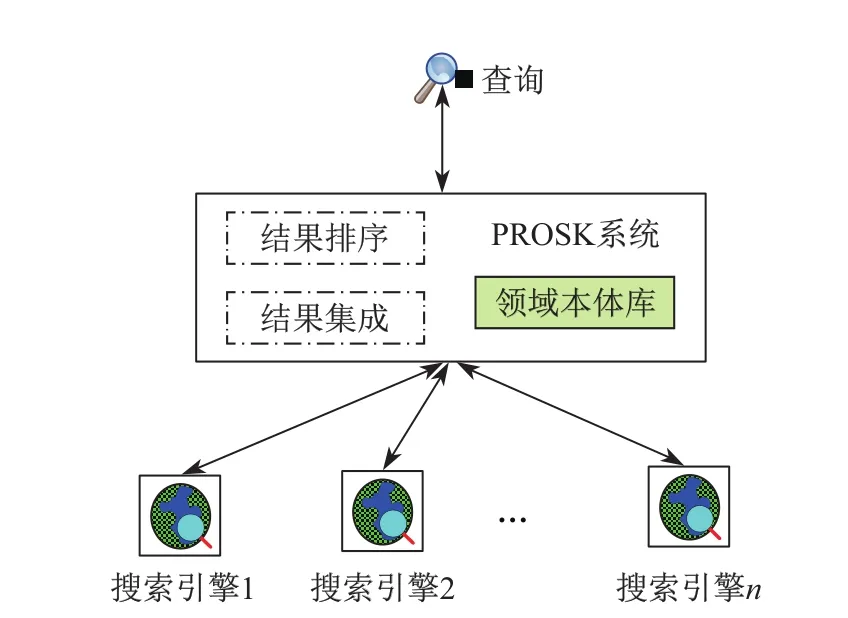
图1 PROSK系统示意图Fig.1 Illustration of query processing of PROSK
定义2基于元搜索的个性化查询可以表示为一个五元组:〈E,Q,T,C,P〉,其中E是元搜索引擎集合,Q为查询集合,T是排序方法,C是查询结果的选择标准,P为查询的用户轮廓.
2.2 排序学习及Ranking SVM原理
基于学习的排序技术运用了机器学习的概念,能够利用特征集合产生训练模型,并根据模型自动学习对结果进行自适应排序.排序学习算法数据由三部分构成:查询、与该查询相对应的文档特征序列,以及由人工标注的查询与文档之间的相关度[17].
现有的排序学习算法根据训练样例的不同分为三类:Pointwise、Listwise和Pairwise方法[18].Pointwise方法假设相关度是查询无关的(Query Independent),查询和样本对存在一个相关的排序分值,该方法将排序问题转化为多类分类问题或回归问题,例如McRank[19]. Listwise方法利用目标函数直接对文档的排序结果进行优化,利如ListNet[20].Pairwise方法利用有序数据之间的二元偏序关系将排序问题转化为二元分类学习问题,常见的有RankNet[21],RankBoost[22],Ranking SVM[23]等.
鉴于Pointwise方法的假设局限性和Listwise优化困难,以及Pairwise方法直观和高效,用户的点击选择反映了用户对查询结果的偏好,这些点击数据能很方便地形成成对的排序关系,因此,PROSK系统采用了基于Pairwise的排序技术.
Pairwise的排序可以用L(f(xq,x),yq)=I(f(xq,xi)≥f(xq,xj))表示.给定查询q,I为标识函数,如果对象xi比对象xj更接近,则为+1,否则为–1.Ranking SVM是由T.Joachims提出的基于支持向量机SVM的排序学习算法[23],该方法将排序问题转化为监督学习的分类问题,通过用对机器学习中的支持向量机进行训练[18]获得模型.Ranking SVM的基本原理是使用训练所得的分类模型对所有偏序对进行分类,得到数据集的一个偏序关系,根据偏序关系实现查询结果的排序.
定义3样本参考关系:给定样本的输入空间X⊆Rn,其中n为特征数量.Y= {r1,r2,…,rk}是由标签表示的rank值空间,其中k代表rank值个数.如果rank值之间存在一个偏序关系r1≺r2≺…≺rq,则存在一个函数f∈F,使得两个样本xi,xj之间的参考关系可以由公式(1)表示.

假设f是公式(2)形式表示的线性函数,Herbrich[24]将上述问题归结为对成对样本进行分类的问题.

其中,w表示权重向量,〈·,·〉表示内积.将公式(1)和公式(2)相减,得到以下公式.
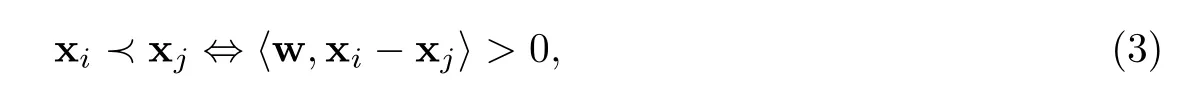
其中,xi,xj之间的关系xi≺xj可以表示成向量xi-xj的形式.据此,可以根据任意两个样本之间的关系构造出新的样本向量和新的标签,对数据集所有样本实现配对.给定两个样本x1和x2,则y1和y2分别表示两个样本相应的rank值,可得

其中
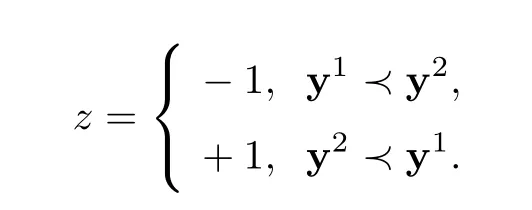
由给定训练数据集S,根据公式(4)创建新的数据集合S′,则S′包含l个标签向量,即把集合中z所对应的向量x1-x2作为类标记,如果两者是顺序对,则标号z为+1,若是逆序对,则标号z为-1.获得了标签数据S′之后,可以采用监督学习SVM模型.
给定查询q,因此上述排序问题转化为公式(5)的优化目标,可以形式化为QP问题[18]:
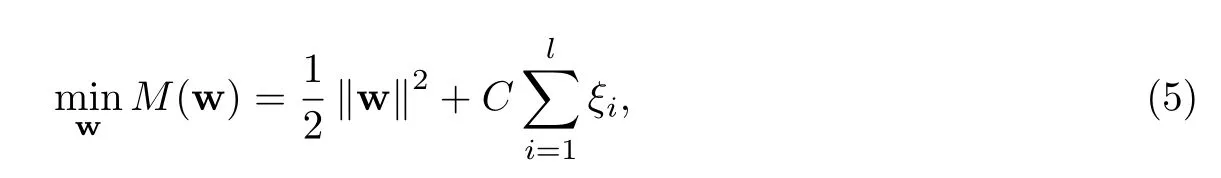
使得对任意(di,dj)∈r∗,满足w(q,di)≥w(q,dj)+1-ξi,j,其中r∗为查询q的目标排序结果,表示S中有序对的个数,ξ为松弛因子,C>0为惩罚参数.对同一训练集合,顺序对和逆序对是关于坐标原点对称的,因此S′上构造的偏序关系只需选取顺序对求解[23].
通过拉格朗日对偶和二次规划问题求解[18],可以计算出公式(5)中最优解α和最优权向量w.给定新样本q,Ranking SVM算法的排序函数的计算序列可以通过公式(6)进行[18].
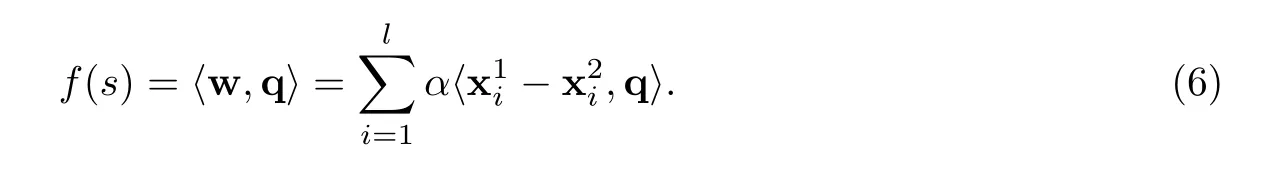
2.3 PROSK系统的结果集成
PROSK系统通过集成多个搜索引擎的结果,集成过程采用全局为中心的(Global Centric)领域本体来完成.由食品安全本体集成框架Fs=〈G,S,M〉,把各个搜索引擎结果映射到一致的语义空间,G采用E-R关系模型,S采用关系数据库存储.其中映射M是框架的核心,M通过形式为〈C,V,sound〉的一组对应关系表表示,其中,C为概念集合,V为查询, sound表示语义模型和局部模型之间语义的完备性[25].
2.4 PROSK系统的排序过程
对于用户的查询输入Q,PROSK系统首先返回多个搜索引擎的n个结果R= {r1,r2,…,rn},并记录查询和用户的点击序列,用于创建用户的轮廓(Prof i le).假设用户在查询结果上的点击序列T={ri,ri+1,…,ri+m}.用户对查询结果的点击,表明用户比较关注相关的内容,把相关的内容作为刻画用户特征的数据集.PROSK系统使用点击序列在结果集合R上构造偏序集合.对于任意r′∈T和r′′∈R-T,可以得出r′≻r′′,因此,对于集合T和R可以构造偏序集合P={r′≻r′′|r′∈T,r′′∈R-T}.
系统记录用户的点击序列,并构造偏序集P.根据偏序集合P,可以构造支持向量机的训练集,如果ri≻rj,则标号为+1,否则为–1.训练Ranking SVM模型M.PROSK系统对用户的相同查询结果的排序作为使用模型M的预测过程.对用户再次查询Q,使用学习到的模型M对查询结果R进行新的偏序关系预测,获得新的偏序P′,进而计算出新的查询结果的序列关系.
3 系统实现
3.1 查询处理流程
PROSK系统的查询处理流程分为在线计算和离线计算两个步骤,如图2所示.系统的离线数据采用MySQL数据库进行存储.
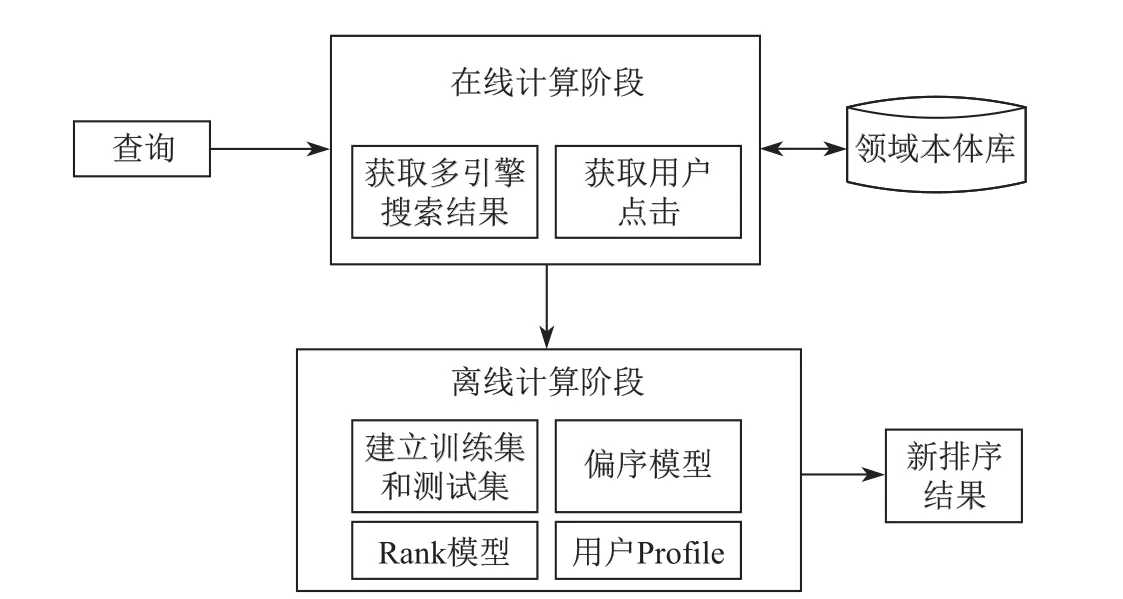
图2 PROSK系统处理流程Fig.2 Processing procedure of PROSK
在线计算步骤,主要完成了集成m个搜索引擎Ei(1≤i≤m)的查询结果,记录用户的点击记录情况,并从本体库中检索和查询相关的概念.离线计算步骤,主要完成两方面的工作:1.对查询结果的页面数据进行解析,提取页面的内容,对页面的中文分词,建立页面文档模型;2.使用获得的Ranking SVM模型,根据用户的点击数据,预测用户查询结果的顺序.
3.2 系统数据分析流程
PROSK系统通过多个搜索引擎返回结果的URL获取Web页面数据,对Web页面数据采用Gson和HtmlParser分别对URL、标题和网页内容作解析,获取基本的数据内容.对于中文页面数据,系统采用ICTCLAS 2016[26]系统完成中文分词、词性标注和命名实体识别等工作,ICTCLAS具有较高的正确率和速度.
由于ICTCLAS可以完成对词性标注,系统使用农业名词等具有明确意义的词进行建模,因此对于页面中词的权重,采用TF因子模型:其中,|Ct|为词t在页面中出现的次数,是文档中所有词出现次数的总和.
3.3 用户查询
目前,PROSK系统集成了百度(http://www.baidu.com/)、好搜(http://www.haosou. com/)和有道搜索(http://www.youdao.com/)三个典型的搜索引擎首页返回的相关查询结果,后台记录用户的点击情况,系统查询页面如图3所示.系统根据输入查询“安全溯源系统”,查询结果如图3(a)所示,根据用户的点击,系统对查询结果新的自适应排序结果如图3(b)所示.

图3 个性化查询结果对比示例Fig.3 Illustration of personalized query results comparison
3.4 查询性能
系统采用Java实现,测试的运行环境为Win7,CPU为i5-3210M,JVM内存512 MB, Ranking SVM实现采用SVMrank版本1.00[27],参数使用默认设置.
系统的查询性能分为在线计算和离线查询的响应时间.在线查询的响应时间主要是根据用户的偏好轮廓进行个性化的预测时间及排序开销;离线的响应时间包括从多个搜索引擎对查询结果集成、Ranking SVM训练及预测时间.离线的Web页面数20万条.表1是使用系统对5个典型查询进行5次查询的平均时间开销,时间单位为毫秒.
通过性能测试,可以看出系统的主要时间开销在离线计算阶段页面的解析和建模方面,平均为8~9 s左右,因为查询系统的查询需要在线获取多个引擎返回的结果,并对结果页面进行数据解析.后期的工作将在该方面进行性能优化,采用后台进程对页面进行分析,以缩短离线的查询时间.Ranking SVM的训练时间和预测时间都在毫秒级,能够满足查询的需求.

表1 PROSK查询性能Tab.1 Query performance of PROSK
4 结论
本文研究了农业信息领域中的食品安全领域的个性化搜索PROSK系统,该系统采用元搜索技术集成多个搜索引擎的相关结果,通过结合本体库和机器学习的排序算法,实现了查询食品安全领域相关知识的个性化自适应排序.鉴于系统的数据规模和离线处理时间较长的问题,未来的工作是把系统移植到分布式spark计算平台上,优化离线分析与处理,实现对海量食品安全数据的智能化查询和管理,对结果的质量评测将作为未来的主要工作.
[1]中国互联网络发展状况统计报告[R].中国互联网络信息中心,2016.
[2]彭玉容,杨捧,高媛.农业搜索引擎的发展现状及关键技术研究[J].安徽农业科学,2010,38(20):10971-10973.
[3]王超,李书琴,肖红.基于本体的旱区农业垂直搜索引擎研究[J].农机化研究,2013,35(8):184-187.
[4]李雷.基于Nutch的农业信息搜索引擎实现和优化[D].长春:吉林大学,2011.
[5]SDD农搜.[EB/OL].[2016-05-01].http://www.sdd.net.cn/.
[6]乔波,聂笑一,方逵.基于本体的农业信息服务个性化推送研究[J].安徽农业科学,2013,41(27):11213-11214.
[7]李宏伟,林萍,洪小娟.食品安全网络舆情本体学习研究[J].南京邮电大学学报(社会科学版),2013,15(4):72-77.
[8]杜小勇,李曼,王珊.本体学习研究综述[J].软件学报,2006,17(9):1837-1847.
[9]GRUBER T R.A translation approach to portable ontology specif i cations[J].Knowledge Acquisition.1993, 5(2):199-220.
[10]杨月华,杜军平,平源.基于本体的智能信息检索系统[J].软件学报,2015,26(7):1675-1687.
[11]NOY N F.Semantic integration:A survey of ontology-based approaches[J].ACM Sigmod Record,2004,33(4): 65-70.
[12]吴小兰,汪琪.元搜索引擎研究综述[J].图书情报工作,2009,53(9):46-49.
[13]曹林,韩立新,吴胜利.元搜索引擎排序技术综述[J].计算机应用研究,2009,26(2):411-414.
[14]阳小华,刘振宇,谭敏生,等.元搜索引擎系统合成算法的约束条件[J].软件学报,2002,13(7):1264-1270.
[15]胡宜敏.农业搜索个性化平台的研究与设计[D].合肥:中国科学技术大学,2009.
[16]曾春,邢春晓,周立柱.个性化服务技术综述[J].软件学报,2002,13(10):1952-1961.
[17]花贵春,张敏,邝达,等.面向排序学习的特征分析的研究[J].计算机工程与应用,2011,47(17):122-127.
[18]LI H.A short introduction to learning to rank[J].Ieice Transactions on Information&Systems,2011,94(10): 1854-1862.
[19]LI P,BURGES C J C,WU Q.McRank:Learning to rank using multiple classif i cation and gradient boosting[C]// International Conference on Neural Information Processing Systems.Curran Associates Inc,2007:897-904.
[20]CAO Z,QIN T,LIU T Y,et al.Learning to rank:From pairwise approach to listwise approach[C]//Proceedings of the 24th International Conference on Machine Learning.ACM,2007:129-136.
[21]BURGES C,SHAKED T,RENSHAW E,et al.Learning to rank using gradient descent[C]//Proceedings of the 22nd International Conference on Machine Learning.ACM,2005:89-96.
[22]FREUND Y,IYER R,SCHAPIRE R E,et al.An effi cient boosting algorithm for combining preferences[J]. Journal of Machine Learning Research,2003,4:933-969.
[23]JOACHIMS T.Optimizing search engines using clickthrough data[C]//Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.ACM,2002:133-142.
[24]HERBRICH R,GRAEPEL T,OBERMAYER K.Large margin rank boundaries for ordinal regression[J].Advances in Neural Information Processing Systems,2000,10(3):115-132.
[25]CALVANESE D,DE GIACOMO G,LENZERINI M.A framework for ontology integration[C]//Proceedings of the First International Conference on Semantic Web Working.2001:303-316.
[26]ICTCLAS.[EB/OL].[2017-02-01].http://ictclas.nlpir.org/.
[27]SVMrank.[EB/OL].[2016-09-01].https://www.cs.cornell.edu/people/tj/svm light/svm rank.html.
(责任编辑:林磊)
Research of personalized knowledge search for food safety system
YUAN Pei-sen1,REN Wu-bei1,REN Shou-gang1,2,ZHU Shu-xin1,XU Huan-liang1,2
(1.College of Information Science and Technology,Nanjing Agricultural University, Nanjing 210095,China; 2.Jiangsu Collaborative Innovation Center of Meat Production and Processing, Quality and Safety Control,Nanjing 210095,China)
In the era of big data,knowledge discovery from the mass of data is an important research problem,especially for the user’s customized knowledge.In this paper, an integrated search system aiming at personalized re-ranking of food safety knowledge system,PROSK for short,is designed and implemented.Firstly,using the existing search engines,the meta-search engine technique is employed for integrating the results of multiple search engines;then according to the results of the users’click through and the ontology of food safety domain,ranking-based learning algorithm is applied to sort search results adaptively according to the preference prof i les.The system integrates the agriculturalinformation from multi-engineers and ranks the query results adaptively and intelligently. This study proposes a feasible solution for ranking of information and knowledge of food safety from multi-engineers adaptively.
food safety search;personalized ranking;search engine integration; domain ontology
TP391
A
10.3969/j.issn.1000-5641.2017.05.011
1000-5641(2017)05-0117-08
2017-06-28
国家自然科学基金(61502236);中央高校基本科研业务费专项资金(KJQN201651, KYZ201752,KYZ201551);国家科技支撑计划(2015BA1105000);江苏省重点研发计划(BE2016803)
袁培森,男,博士,讲师,研究方向为智能计算与海量数据管理. E-mail:peiseny@njau.edu.cn.
朱淑鑫,女,硕士,副教授,研究方向为农业信息化.E-mail:zsx@njau.edu.cn.
