支持非等值连接的分布式数据流处理系统
2017-09-22陈明珠王晓桐房俊华张蓉
陈明珠,王晓桐,房俊华,张蓉
(华东师范大学计算机科学与软件工程学院上海高可信计算重点实验室,上海200062)
支持非等值连接的分布式数据流处理系统
陈明珠,王晓桐,房俊华,张蓉
(华东师范大学计算机科学与软件工程学院上海高可信计算重点实验室,上海200062)
实时处理的分布式数据流系统在当今大数据时代扮演着越来越重要的角色.其中,连接查询是大数据分析处理中最为重要且开销较大的操作之一.然而,由于现实应用产生的数据普遍存在倾斜分布现象,加之数据流本身的无界性与不可预知性,给在分布式数据流系统上进行连接查询处理提出了严峻的挑战.目前工业界较为主流的数据流系统处理连接查询的通用性较低,没有提供专门针对连接操作的接口;学术界推出的数据流连接查询原型系统虽然提供了接口,但大多面向等值连接,或仅能支持部分theta连接,且存在资源开销大、负载均衡性能低等问题.本文对比分析三种典型数据流系统,将基于Join-Matrix的连接处理技术与Storm系统相结合,设计并实现了通用的、可支持任意连接查询的数据流处理系统.实验展示了本文设计的系统具有更加良好的吞吐量与资源优化表现.
数据流处理系统;连接处理;分布式计算
0 引言
随着通信技术和硬件设备的不断发展,尤其是无线传感设备的广泛应用,数据采集越来越便捷,数据生成速度越来越快,这也决定了数据流入系统的速度增加.然而,由于内存资源有限,系统不可能对所有的数据进行存储,同时,流入的数据往往在流量与分布上存在动态性,这就决定了数据一旦流入系统便需要进行自适应的实时处理.21世纪之前,由于硬件条件的限制,人们对数据的实时处理往往局限于对数据流进行采样,以获取概要信息.近年来,随着分布式并行架构的相关技术日益成熟及在线实时分析连续数据流的需求日益增多,分布式数据流处理系统得到了快速发展,这使得其能够应对诸如金融交易管理、网络监控管理与实时推荐等应用成为可能.随着开放式处理平台的发展,工业界与学术界相继出现了大量的分布式数据流处理系统,典型的有Twitter的Storm[1],Yahoo!的S4[2]和伯克利大学的Spark Streaming[3].
在实时处理中,连接是最为重要的且开销较大的操作之一,其基础的要求是保证来自不同数据源的元组按照连接谓词聚集进行运算.在传统数据库领域中,连接技术的研究与发展颇为成熟.然而,在数据流环境下,日益增长的数据规模,有限的内存资源,流式数据的实时动态性以及数据的倾斜分布等给数据流系统的连接操作带来了严峻的挑战.以当下最为流行的共享单车为例,应用需要处理用户查找当前距离最近的单车停放点的频繁请求.在这个语义中,单车与用户为两条位置实时变化的数据流,系统需要根据位置与时间对两条数据流进行数据项匹配,输出连接结果,即向用户推送符合要求的单车位置.随着应用的推广,持续增长的用户与单车数量规模,经纬度定位数据的实时变化,以及上下班高峰期间用户人数的急剧增长等问题,无疑均会成为连接处理性能的限制因素.针对数据流的特性,研究人员设计并实现了诸多集中式数据流连接处理[4-8].近年来,随着大数据时代的到来以及分布式计算框架的普及,研究人员针对分布式数据流连接处理做了大量的工作[9-11].
尽管目前工业界推出的主流分布式数据流处理系统能够以高效的性能进行实时数据处理,但是大都没有提供用户有关连接处理的编程接口,均需用户根据具体的连接谓词构建不同的连接算子,不具备通用性与易用性.以Storm系统为例,需要根据具体的连接谓词选择适当的数据分组策略,将数据分发到对应的节点上进行连接处理.近年来,学术界也相继开发出改进的数据流原型系统.Squall[12]采用基于矩阵的连接模型,将连接语句翻译成由执行算子构成的有向无环图的查询计划,可支持任意谓词的连接操作,并提供了连接处理的编程接口,但连接矩阵的结构限制了系统扩展的灵活性,且带来较大的数据冗余存储,只能支持无窗口模式的连接处理.BiStream[13]采用基于二分图的连接模型,将集群分成两个部分,可根据连接操作的负载程度动态扩展处理单元的数量,较Squall中的矩阵模型大幅度降低了数据冗余度,提高了内存资源的利用率,但在数据分组时利用了内容敏感的混合路由策略,因此只能支持部分theta连接,且需要人工干预数据分组的参数设置.综上所述,目前在分布式数据流处理系统上进行连接操作主要存在以下2个问题.
(1)通用性低.多数系统不提供通用的连接编程接口,为了处理不同的应用需要,用户需要自己编写复杂的连接算子;
(2)theta连接处理限制性高.多数系统只能提供等值连接处理,或仅能支持部分简单的theta连接处理.
面对上述问题,本文从系统架构与编程模型的角度对3个典型数据流处理系统进行对比分析,基于Join-Matrix矩阵模型,制定均衡的数据分发策略与轻量级的数据迁移机制,与已用的系统相结合,设计并实现了通用的、可处理任意theta连接的数据流系统,并在Storm上实现了系统原型.通过大量实验证明本文设计的系统具有更加良好的性能.
本文后续组织安排如下.第1节阐述相关工作,包括数据流连接方法的介绍;第2节介绍了若干典型的数据流处理系统,并进行对比分析;第3节详细介绍系统架构设计、系统功能模块解析和连接处理的两项关键技术;第4节通过实验验证系统;最后,在第5节进行总结与未来工作展望.
1 相关工作
由于数据流的无界性与动态性等特点,且传统数据库领域的连接处理中包含阻塞行为,因此不能直接运用于数据流.近年来,研究人员对数据流连接处理投入了大量的研究工作.
对称哈希连接(SHJ)[4]是一个简单的、基于哈希的方法,假定所有的连接状态均需存储于内存中.XJoin[5]和DPHJ[6]对SHJ进行了扩展,允许将哈希表中的部分数据存储到磁盘中.后来许多流式连接处理均以XJoin为基础,RPJ[7]就是其中之一,它基于统计信息的刷新策略,选取最有可能被选中的元组存储在内存中.HMJ[8]总是同时刷新所有数据流的哈希表,用于平衡数据流的内存分配.以上均为集中式算法,因此不能直接应用于分布式的数据流连接处理.
Photon[9]是谷歌公司针对连接网络查询数据流和用户点击广告数据流而设计的,利用中心协调器实现容错和可扩展的多条数据流连接操作.由于采取非阻塞的方式进行键值匹配,不支持theta连接.D-Stream[10]是Spark Streaming定义的数据流操作对象,以阻塞的方式将数据流切分成一系列离散的微批次(mini-Batch),并利用世系机制实现快速容错,可支持theta连接,但是由于存在窗口大小的限制,只能获得近似查询结果.TimeStream[11]针对任意theta连接,提供了类似MapReduce的批量计算与流式计算两种处理方式,但是需要连接状态的依赖信息,通信代价较大.
2 分布式数据流处理系统
本章节介绍三种典型的分布式数据流系统进行连接的处理机制,包括Storm、Spark Streaming与Squall,并给出相应的对比分析.
Storm是可扩展的且具备容错能力的开源分布式数据流计算系统,在实时计算方面表现突出,但是在处理连接操作时,需要根据具体的连接谓词选择适当的数据分组策略,将数据分发到对应的节点上进行连接处理.Storm提供了八种数据分组策略,使用最为广泛的是随机分发(shuffl e grouping)与按字段分发(f i eld grouping).随机分发策略对数据进行洗牌,尽量均匀地随机分发到各处理节点;按字段分发策略,根据路由字段值(f i eld)对数据进行分组,相同字段的数据将被分发至同一个处理节点.随机分发策略由于不考虑数据的字段值,即其为内容不敏感的数据分发,因此在任意分布的数据负载下,都能保持处理节点间的绝对负载均衡.然而,在执行连接操作时,内容不敏感破坏了基于字段的操作语义,为了保证结果的完整性与正确性,需要付出额外的资源代价,譬如广播数据带来的网络通信负载相反,按字段分发策略根据连接谓词,将连接属性数值相同的数据分发到同一个处理节点,不存在额外的数据广播操作.但是,当数据呈现倾斜分布时,譬如上述共享单车的例子中,地铁站等人口流量较高的地点停放的单车数量远远高于其他区域,数据的分布不均将直接导致处理节点的负载不均衡.
Spark Streaming是对Spark核心API(Application Programming Interface)的扩展,用于可伸缩、高吞吐量、可容错地处理在线数据流.Spark Streaming接收在线数据流,将若干数据流元组以阻塞的方式构造成微批次,然后通过Spark引擎处理,并最终得到由一系列微批次的数据项构成的数据流.与Storm类似,利用Spark的RDD(Resilient Distributed Datasets)机制提供的基于字段与混洗的分区策略,进行连接处理.然后,由于微批次的数据结构,导致某些离散的微批次存在丢失连接元组对的现象,因此只能获得近似查询结果.
Squall是由洛桑联邦理工学院数据实验室基于Storm开发的分布式在线查询系统,可利用SQL(Structured Query Language)查询语句实现对数据流的实时连接处理.由于Storm处理连接操作的不便性,Squall将SQL查询语句翻译成由执行算子构成的有向无环图查询计划,对Storm的组件进行封装,实现连接查询的逻辑任务,最终通过构建Storm的拓扑结构来执行查询计划.尽管该系统提供了便捷的编程接口,但是,该系统不支持滑动窗口操作.此外,由于底层连接处理是基于不易扩展且结构限制的连接矩阵模型,因此系统扩展的灵活性较低,资源开销较大.
就数据流的连接处理,表1从连接类型、连接模型、可扩展性等方面,对上述三种数据流连接系统进行对比.

表1 Storm、Spark Streaming与Squall系统对比Tab.1 Comparison among Storm,Spark Streaming and Squall
表1中,Squall基于矩阵模型进行数据流的连接处理,尽管其可以精确地应对任意连接谓词的处理,然而这却以消耗更多的计算资源为代价.下文展示了基于优化的连接矩阵模型的系统实现.
3 系统实现
本章节主要从系统架构设计、系统功能模块解析和连接处理的关键技术这三个方面进行阐述.针对现有分布式数据流系统在处理连接时存在的问题,融合一种高效的数据流处理系统,它利用高吞吐量的分布式消息队列作为输入数据源的适配器,集成了主流的分布式数据流处理系统,配以开源的、基于内存的key-value数据库作为中间缓存,并使用目前主流的前端框架,实时动态地展示系统的运行状况.
3.1 系统架构设计
该系统共由四层组件构成,分别是数据源层,连接处理层,中间缓存层与应用展示层,如图1所示.
Kafka[14]是一个开源的消息发布与订阅系统,数据源层利用Kafka消息队列接收现实应用的用户行为数据或日志数据,作为系统的输入数据适配器.连接处理层是基于分布式数据流处理系统Storm进行连接操作的封装,将处理单元(bolt的task实例)组织成连接矩阵的形式.第三节将给出有关连接矩阵的设计与分析.中间缓存层利用内存数据库Redis[15]存放系统运行时需要使用的各类中间值与信号量,便于底层与上层的信息传递与交互.最上层为任务提交与运行状况显示的应用层,用户可自定义配置参数(Storm的bolt并行度等),提交连接查询任务,并利用Angular Js[16]前端架构动态展示系统运行的状况,比如处理架构的变换和数据迁移的方向与规模等.

图1 系统架构图Fig.1 The architecture of system
3.2 系统功能模块解析
为分析当前实时数据流连接处理的任务要求,系统包含三大功能模块:数据路由模块、数据连接模块与数据控制模块,如图2所示.

图2 数据流连接系统功能模块图Fig.2 Function block diagram of stream join processing system
数据路由模块实时接收输入数据适配,按照特定的路由策略,将数据分发至数据连接模块的对应连接计算单元.
数据连接模块接收上层应用提交的连接查询请求,并转为对已存储数据进行连接的逻辑计算任务,由具体的算子实施真实的连接计算.当前数据连接模块主要包括以下三部分业务:(1)查询分析:将连接查询请求翻译成由执行算子构成的有向无环图的连接查询计划,每个算子对应于Storm的一个组件,将算子的多个实例组织成矩阵的形式,并通过构建Storm的拓扑结构来执行连接查询计划.第3.3节将给出有关连接矩阵的关键技术.(2)连接计算:根据查询分析制定的连接查询计划,对Storm的组件(bolt)进行封装,实现具体的连接计算.多个连接算子计算,且互相独立,可实现相关工作中所述的任意集中式连接算法.(3)负载汇报:连接算子周期性地向数据控制模块汇报当前工作负载信息.
数据控制模块是系统的核心功能模型,负责处理架构的制定,主要包括以下三部分业务: (1)负载监控:接收数据连接模块定期汇报的负载,根据数据流的流量变化以及当前工作负载是否超出内存阈值,判断算子实例(处理单元)的组织形式是否需要调整.(2)矩阵制定:在负载监控的基础上,制定出资源消耗最小的矩阵结构,并更新数据路由模块中的路由策略.(3)迁移计划制定:为实现矩阵结构变换时数据迁移代价的最小化,利用局部敏感的机制制定数据迁移计划,指导连接模块中的连接计算单元进行相应的数据迁移操作.
3.3 平台关键技术
本文系统设计的关键在于有效应对数据倾斜与降低连接资源开销的平衡兼顾问题.本文使用Join-Matrix矩阵模型来解决数据倾斜问题,并制定局部敏感的数据迁移机制来解决连接操作的资源开销问题.由于篇幅的限制,有关上述两种技术的具体细节可参考文献[17-19].
3.3.1 Join-Matrix矩阵模型
Join-Matrix作为一种高性能的连接矩阵模型,方便部署于分布式环境下,支持任意连接谓词的数据流连接操作.由于采取随机分发元组作为路由策略,Join-Matrix可利用对元组内容的不敏感性来有效抵御数据倾斜.为了实现工作节点的负载均衡以及网络传输代价的最小化,本文在连接矩阵的模型基础上,利用等周定理引申的两条定理,即(1)在给定面积的所有矩形中,正方形的周长最小;(2)在给定周长的所有矩形中,正方形的面积最大.将系统中的计算资源抽象为上述定理中的面积与半周长,进而设计了一种代价高效的数据划分方案,使其占用的资源开销最小.
3.3.2 数据迁移机制
为了实现矩阵结构变换时数据迁移代价的最小化,本文设计了一种局部敏感的迁移机制,在进行矩阵变换之前,确定新旧矩阵中各个处理单元之间的映射关系,计算各处理单元之间的数据重叠程度,并将重叠程度最高的设置为最终配对单元.如图3所示,当数据流S的流量增大时,矩阵结构由2×2转变为2×3.为了实现数据迁移量的最小化,在原矩阵的中间增加一列新的处理单元,即第5和第6号单元,将1号和3号处理单元中存储的所有R流元组分别复制到5号与6号单元,同时将1号处理单元存储的S流元组与2号处理单元存储的S流元组复制到5号处理单元;将3号处理单元存储的S流元组与4号处理单元存储的S流元组复制到6号处理单元.

图3 矩阵变换(2×2转变为2×3)Fig.3 Matrix transformation(2×2 to 2×3)
4 实验与系统展示
本章节通过一系列对比实验对本文设计的数据流连接查询系统进行性能评估,并进行系统运行展示.实验部署在一组由22个物理主机的惠普刀片机服务器集群,单个机器拥有2个4核4线程的处理器,型号为Intel Xeon E5335,主频为250 GHz,并配有16 GB的RAM内存与2 TB的硬盘.所有的服务器主机运行Cent OS 65 Linux操作系统.通过控制元组处理的压力,使得分布式系统达到CPU资源的饱和点.实验结果是五次运行记录的平均值.
本文共使用了三种不同的系统来进行对比实验,MFM是本文设计的数据流连接查询系统; Squall是文献[12]中设计的基于连接矩阵模型的系统;Storm即原生态的分布式数据流系统,默认设置数据的分发策略为按字段分发.
实验中使用TPC-benchmark[20]的数据生成器dbgen生成具有Zipf分布的数据集,通过参数z调整数据的倾斜程度,默认值为1.实验基于全历史记录模型进行处理,将数据源源不断地载入系统,记录系统运行期间占用的处理单元数量,如图4(a)所示.随着数据的不断流入,由于矩阵形状的限制,Squall占用的处理单元数量急剧增加,相反,MFM根据当前系统的负载情况按需分配资源,消耗的处理单元最少.
此外,实验还使用了社交网络微博数据集Weibo,该数据集包含了微博服务五天的数据量,数据集中每一个元组的结构是以话题为key的字符串序列,数据总量为12 GB,涵盖10 000个话题.实验中基于窗口模型进行自连接操作,设置一个窗口内的工作负载为最近24小时内的所有元组,记录运行期间各系统的吞吐量,如图4(b)所示.由于Storm采用按字段分发,随着数据倾斜程度的增加,系统中某些处理单元的工作负载远远超过其他单元,成为系统中的straggler,进而降低了系统的吞吐量.Squall由于在矩阵变换时占用较多的处理单元,导致大量的数据迁移量,进而吞吐量低于本文的系统MFM.

图4 实验结果Fig.4 Experiment results
图5为系统运行的展示界面.用户选择连接查询任务,设置处理模式(窗口模式或全历史记录模式)并提交执行.图5(a)展示了系统运行期间处理单元组织结构的变换过程,即由2×2的矩阵转换为3×4的矩阵,并给出了数据迁移的具体细节.其中,绿色节点为旧矩阵的处理单元,黄色节点为新增的处理单元.图5(b)给出了系统运行期间各处理节点的工作负载,从图中可以看出,系统的负载均衡性能较高.
5 总结
分布式数据流连接操作在流式计算中占据举足轻重的地位.由于数据流的动态特性使得相关技术的研究面临严峻的挑战.本文以负载均衡与低资源开销为目标,基于连接矩阵模型,设计并实现了代价高效的数据流连接处理系统,可支持任意theta连接.但是,连接矩阵由于内容不敏感的特性,存在较为严重的数据冗余存储现象.因此,在未来的工作中,我们会进一步研究更优的方法,将内容敏感与连接矩阵相结合,将相关技术集成到Storm的底层源码,并在应用层做出改进.
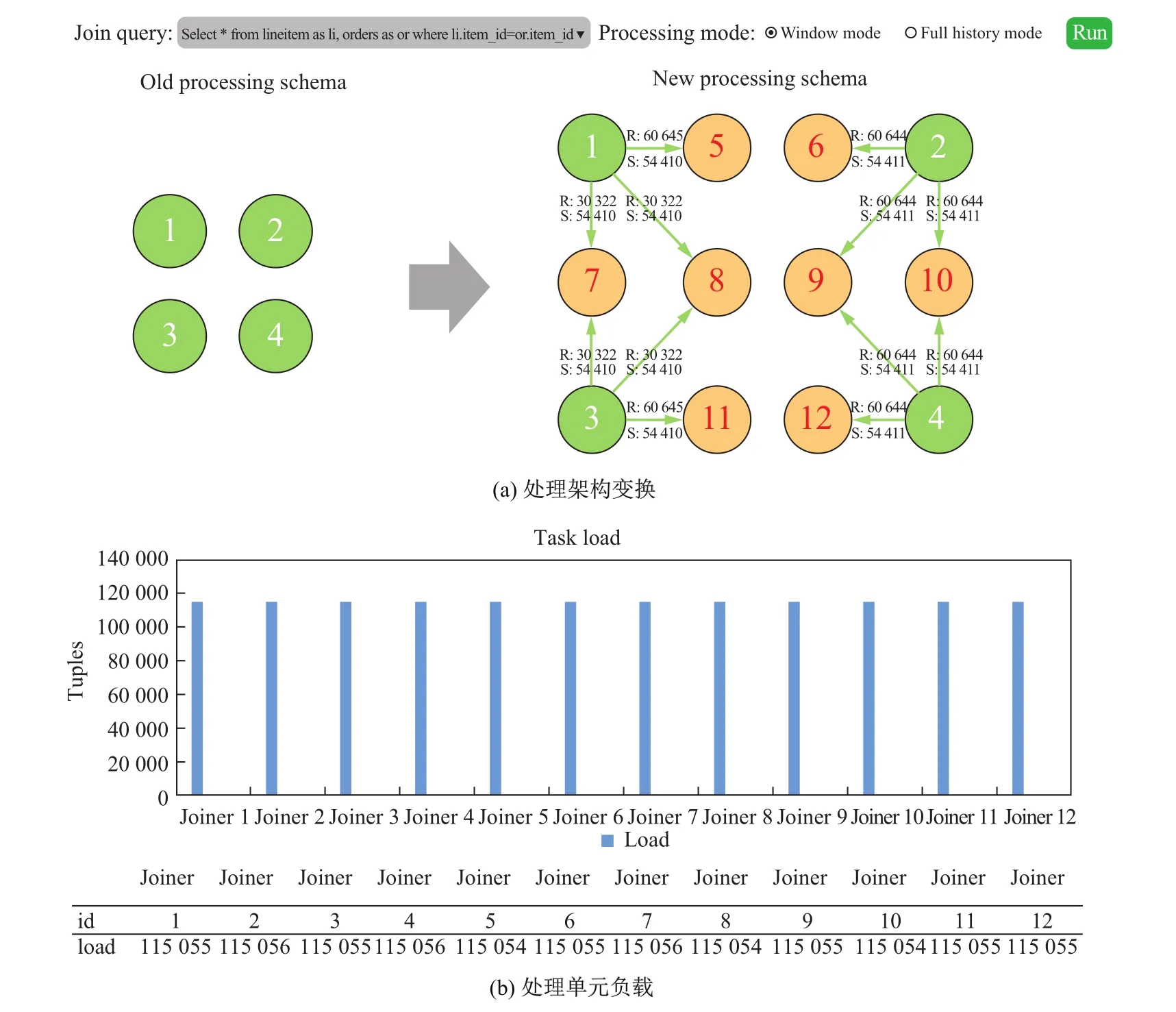
图5 系统展示Fig.5 System demo
[1]ANKIT T,SIDDARTH T,AMIT S,et al.Storm@Twitter[C]//Proceedings of SIGMOD International Conference on Management of Data.ACM,2014:147-156.
[2]LEONARDO N,BRUCE R,ANISH N,et al.S4:Distributed stream computing platform[C]//Proceedings of the International Conference on Data Mining Workshops,2010:170-177.
[3]CHEN G J,WIENER J L,IYER S,et al.Realtime data processing at Facebook[C]// Proceedings of SIGMOD International Conference on Management of Data.ACM,2016:1087-1098.
[4]WILSCHUT A N,APERS P M G.Dataf l ow query execution in a parallel main-memory environment[J].Distributed and Parallel Databases,1993(1):103-123.
[5]URHAN T,FRANKLINM J.Dynamic pipeline scheduling for improving interactive query performance[C]//Proceedings of International Conference on Very Large Data Bases.2001:501-510.
[6]IVES Z G,FLORESCU D,FRIEDMAN M,et al.An adaptive query execution system for data integration[C]//Proceedings of SIGMOD International Conference on Management of Data.ACM,1999:299-310.
[7]TAO Y F,YIU M L,PAPADIAS D,et al.RPJ:Producing fast join results on streams through rate-based optimization[C]//Proceedings of SIGMOD International Conference on Management of Data.ACM,2005:371-382.
[8]MOKBEL M F,LU M,AREF W G.Hash-merge join:A non-blocking join algorithm for producing fast and early join results[C]//Proceedings of the 20th International Conference on Data Engineering.2004:251-262.
[9]ANANTHANARAYANAN R,BASKER V,DAS S,et al.Photon:Fault-tolerant and scalable joining of continuous data streams[C]//Proceedings of SIGMOD International Conference on Management of Data.ACM,2013: 577-588.
[10]ZAHARIA M,DAS T,LI H Y,et al.Discretized streams:Fault-tolerant streaming computation at scale[C]// Proceedings of the 24th ACM Symposium on Operating Systems Principles.2013:423-438.
[11]QIAN Z P,HE Y,SU C Z,et al.TimeStream:Reliable stream computation in the cloud[C]//Proceedings of the 8th ACM European Conference on Computer Systems.ACM,2013:1-14.
[12]ELSEIDY M,ELGUINDY A,VITOROVIC A,et al.Scalable and adaptive online joins[C]//Proceedings of International Conference on Very Large Data Bases,2014(7):441-452.
[13]LIN Q,OOI B C,WANG Z K,et al.Scalable distributed stream join processing[C]//Proceedings of ACM SIGMOD International Conference on Management of Data.ACM,2015:811-825.
[14]GOODHOPE K,KOSHY J,KREPS J,et al.Building linkedin’s real-time activity data pipeline[J].IEEE Data Eng Bull,2012,35(2):33-45.
[15]REDIS.[DB/OL].[2017-06-01].https://redis.io/.
[16]ANGULAR JS.[EB/OL].[2017/06-01].https://angularjs.org/.
[17]FANG J H,ZHANG R,WANG X T,et al.Distributed stream join under workload variance[J].World Wide Web Journal,2017:1-22.
[18]FANG J H,WANG X T,ZHANG R,et al.Flexible and adaptive stream join algorithm[C]//Proceedings of International Conference on Asia-Pacif i c Web,2016:3-16.
[19]FANG J H,ZHANG R,WANG X T,et al.Cost-ef f ective stream join algorithm on cloud system[C]//Proceedings of CIKM International Conference on Information and Knowledge Management.ACM,2016:1773-1782.
[20]TPC-H BENCHMARK.[EB/OL].[2017-06-01].http://www.tpc.org/tpch.
(责任编辑:林磊)
Distributed stream processing system for join operations
CHEN Ming-zhu,WANG Xiao-tong,FANG Jun-hua,ZHANG Rong
(School of Computer Science and Software Engineering,Shanghai Key Laboratory of Trustworthy Computing,East China Normal University,Shanghai 200062,China)
Real-time stream processing system plays an increasingly important role in practical applications.Stream Join constitutes one of the most important and expensive operation in big data analysis.However,skewed data distribution in real-world applications and inherent features of streaming data,such as inf i nity and unpredictability,put great pressure on the join processing in distributed stream systems.Mainstream industrial stream systems have low versatility on join processing,providing no programming interface; though several academic stream prototype systems solve such a problem to a certain extent, they support equi-join processing only,or results in high resource utilization and severe load imbalance.In this paper,after analyzing three typical distributed stream systems,we integrate the techniques based on Join-Matrix into Storm,design and implement a general stream processing system which supports arbitrary theta joins.Experiments demonstratethat the system proposed in this paper outperforms the static-of-the-art strategies.
stream processing system;join processing;distributed computing
TP391
A
10.3969/j.issn.1000-5641.2017.05.002
1000-5641(2017)05-0011-09
2017-06-28
国家大学生创新创业训练计划(20160269127);国家自然科学基金(61232002);国家863计划(2015AA015307);国家自然基金委项目(61672233)
陈明珠,女,本科生,专业为计算机科学.E-mail:101521300140@stu.ecnu.edu.cn.
张蓉,女,教授,研究方向为分布式数据管理.E-mail:rzhang@sei.ecnu.edu.cn.
