研究生信息平台中运维系统的设计与实现
2017-09-22史兵夏帆宋树彬肖李敏董启文周傲英徐林昊
史兵,夏帆,宋树彬,肖李敏,董启文,周傲英,徐林昊
(1.华东师范大学数据科学与工程学院,上海200062;2.华东师范大学研究生院,上海200062; 3.印孚瑟斯技术中国有限公司,上海200135)
研究生信息平台中运维系统的设计与实现
史兵1,夏帆1,宋树彬2,肖李敏2,董启文1,周傲英1,徐林昊3
(1.华东师范大学数据科学与工程学院,上海200062;2.华东师范大学研究生院,上海200062; 3.印孚瑟斯技术中国有限公司,上海200135)
现代软件系统大多采用基于日志收集与分析的运维模式,帮助系统管理人员确保业务系统的安全性与稳定性.本文首先讨论了现有基于日志分析的运维方案.接下来,基于开源的ELK框架,设计了华东师范大学研究生院信息平台中的运维子系统.通过实时交互可视化的数据分析方式,有效地解决了研究生院业务人员在系统使用中遇到的性能与负载监控,用户行为分析以及服务异常调试等方面的问题.最后针对不同类型的业务运维场景,给出了基于交互式仪表盘的运维服务实现.
运维;日志;数据分析
0 引言
华东师范大学(简称华东师大)现有的研究生院信息系统从2005年开始分三期历时6年研发完成,具体包括招生、学籍、培养和学位四个子系统.从系统开发初期到2017年,研究生在校人数增长明显,同时专业学位的种类也更加丰富,使得系统的业务量不断扩大.并且,当全部系统最终交付的时候,很多研究生管理制度已经发生了较大的变化,使得目前的研究生院信息系统已经无法有效地对研究生信息进行管理,不能满足不断出现的新需求.
另一方面,由于系统开发时间较早,使用的技术框架比较落后,存在系统响应速度慢,浏览器兼容性差等问题.为了解决目前研究生院信息系统的不足之处,华东师大启动了新一代信息平台的开发.新的系统采用自主研发模式,与印孚瑟斯技术中国有限公司合作开发,旨在基于新的技术理念,满足新的业务需求,同时系统设计需要具有一定的灵活性以满足可能出现的业务流变更.在新信息平台的第一期项目研发过程中,研发团队以学籍业务为切入点,目标为利用成熟的主流开源软件框架打造信息平台的基础设施,为后续业务子系统的开发做充分的技术准备.
与传统的管理信息系统不同,基于现代互联网公司采用的开发运维理念,项目研发团队在下一代信息平台中引入了一个轻量级的运维子系统.主要原因如下:第一,伴随着大规模分布式计算技术的迅猛成长(如大型数据中心和软件即服务),基于日志采集和分析的运维框架与技术逐步发展成熟[1],被广泛地应用于如个性化推荐,计算广告以及反欺诈行为检测等业务领域.第二,随着在校研究生人数的大幅增长以及管理业务向基于移动端的技术方向发展,很多高校都在积极尝试如何将大数据技术中诸如服务动态水平扩展与用户行为分析[2]等技术应用于下一代管理信息系统中,旨在为学生与教职工提供更好的个性化服务[3].第三,高校的信息办虽然使用了商业运维工具,但主要用于管理高校信息化所使用的集群资源,并不针对某个特定的业务系统提供定制化的运维服务[4],如监控研究生院信息系统的负载状况.第四,通过收集与分析不同维度和业务场景的日志信息,不仅可以实现性能与负载实时监控,追踪用户访问服务的行为模式,发现服务异常并帮助研发团队快速准确地定位问题根源,而且还可以基于不同业务场景下的日志分析结果来不断地优化业务系统的设计与实现,从而确保新信息平台能够有效地支持面向移动端的业务需求和系统持续运行的稳定性.
本文主要贡献如下:
第一,不同于传统的管理信息系统,在华东师大下一代研究生院信息系统的设计中引入了基于日志采集与分析的运维理念和技术,不仅确保运维系统与业务系统之间的相互独立开发与部署,而且还能通过分析日志信息达到不断地优化系统设计与实现的长远目标.
第二,基于开源的ELK框架,针对不同维度与业务场景的运维需求[5],设计并实现了一种轻量级的运维子系统,通过定义日志抽取规则和交互可视化的仪表盘实现了信息平台所需的运维服务.
第三,实践证明,通过运维子系统提供的各种数据分析指标,研究生院的系统管理人员可以根据实际负载状况动态调整系统所需的各种资源,以及通过追踪用户访问行为并结合业务需求,达到不断改进完善业务系统的目标.
1 相关工作
日志收集与分析是运维系统中的重要组件之一,其中与日志处理的相关技术大体可以分为三类:①操作系统的命令工具;②开源软件或框架;③商业产品.表1列举了不同类型日志分析技术的特性对比.对于第一种日志分析方法,管理员需要通过终端登录远程服务器,随后执行查找统计命令或通过预先编写的脚本文件来对日志文件进行分析以完成特定运维任务.例如,Linux管理员可能需要执行如下命令来查看“某个IP在指定的时间里访问了哪些URL”:
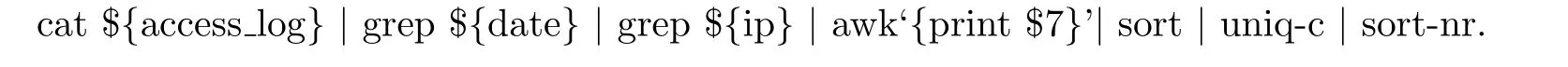
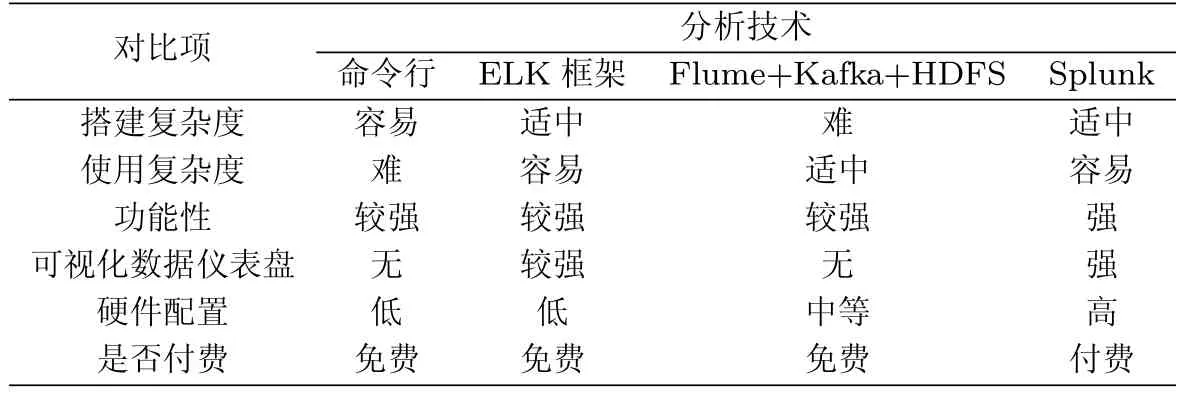
表1 日志分析技术对比Tab.1 Comparison of log analytic technology
使用操作系统命令来完成日志分析,基本上可以满足大部分运维需求.但是,这种方式对运维人员的技术要求高,同时操作较为繁琐,并且经常需要运维人员以登录远程服务器的方式进行操作,对系统的安全性会带来隐患,分析结果的展示也不直观.
对于开源系统而言,一类工作关注于如何提供简单且容易集成的组件(如日志收集组件Flume和消息总线组件Kafka),另一类工作则专注于如何构建完整的框架(如ELK框架).开源日志处理组件大多由一些著名的互联网公司或创业公司开发,用于构建公司内部的运维系统.随着开源软件的日益兴起,这些组件逐渐被贡献给开源社区,且大多围绕着Hadoop生态系统.此外,这些开源组件一般只针对日志收集与分析中的局部问题,如Flume仅解决了日志采集问题,并不关心如何分析日志与展示分析结果.
开源日志框架(如ELK框架和Solr+Hue)提供了完整的日志收集与分析的技术栈,文档齐全且易于安装部署.很多互联网公司往往会选择此类开源框架,用于构建公司内部的运维系统.例如,ELK主要由Elasticsearch,Logstash和Kibana三个开源工具[5]组成,其中Logstash用于采集多种日志源并统一传入Elasticsearch进行索引存储,Kibana则根据实际需求提供定制化的仪表盘来从Elasticsearch获取相关的日志分析统计数据.
商业日志收集与分析产品(如Splunk)具备海量日志数据采集与分析能力,会包含几十甚至上百种日志分析程序,提供类SQL的日志查询语言以及丰富的报表展示工具.然而,这类商业产品价格昂贵,仅会被一些业务复杂的互联网公司所采用(如IBM Cloudant采用了Splunk企业云服务,以应对全球24×7的运维服务).
2 运维需求分析
本节首先介绍研究生院信息平台的整体架构,然后讨论信息平台中的运维需求.
2.1 平台架构
研究生院信息平台包括三个子系统:持续集成与发布子系统,业务子系统,以及运维子系统.不同于传统的管理信息系统,研究生院信息平台之所以增加了持续集成与发布子系统和运维子系统,是为了应对不断发生变化的业务需求.基于这个原因,研发团队采用了敏捷开发模式,进而采用了与敏捷开发相关的持续集成与发布子系统和运维子系统,从而确保项目开发可以按照业务需求的变化进行相应的调整,并将这些设计与实现的调整通过持续集成与发布子系统体现出来,实现新版本的快速部署上线.图1展示了研究生院信息平台中三个子系统之间的相互关系.
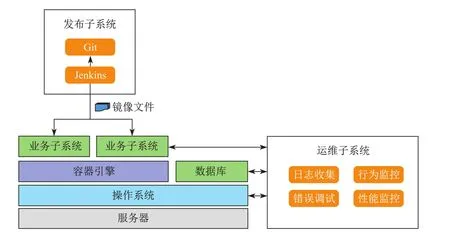
图1 研究生信息平台子系统关系Fig.1 Architecture of graduate student management system
研究生院信息平台中的业务子系统采用了基于浏览器/服务器(B/S)的三层架构,即Web前端展示-后端业务逻辑-数据库.在系统研发中,Web前端采用了谷歌AngularJS框架和Bootstrap风格样式,后端应用采用了Spring Boot框架来实现具体业务逻辑,而业务数据则存储在关系模型中.
在实际部署中,采用Nginx服务器作为整个业务子系统的访问入口,处理访问请求的负载均衡,并结合基于Docker的应用部署模式,有效地实现了系统处理能力的水平扩展.具体而言, Nginx首先会接受每个用户访问请求,并将该请求路由给当前工作负载最低的Web前端服务器; Web前端服务器分析并验证用户请求是否有效,然后调用业务逻辑的RESTful接口;基于安全性考虑,业务逻辑服务器会分析并再次验证从Web前端发过来的请求,调用相应的业务逻辑并将结果以JSON格式返回给Web前端;Nginx最后把Web前端的展示结果返回给用户.图2展示了业务子系统的功能架构,其中各部分产生的日志由ELK框架中的beats插件收集并转发到运维子系统中进行处理,具体参见设计与实现部分.
2.2 运维需求
在研究生院信息平台的使用过程中,需要从以下三方面提升整个系统的可靠性.
(1)性能与负载监控由于在部署中采用了基于Docker的虚拟化技术[6],研究生院信息平台的运维管理人员不仅需要及时地了解物理服务器的各项性能指标(CPU,磁盘I/O和网络I/O),还需要监控Docker、数据库以及应用逻辑的性能指标.对于物理服务器,Docker容器和数据库系统而言,只需要实时地采集这些系统提供的日志就可以获得监控所需的性能指标.然而,对于应用逻辑而言,则存在两种获取性能指标的方式:①通过Spring Boot提供的性能监控API,在一些关键的业务逻辑中增加相应的性能测量代码;②通过采集负载均衡器的系统日志来计算每个RESTful接口的性能指标.第一种方法的优点在于性能测量准确,但却会降低应用逻辑的处理效率(例如,CouchDB中的IOQ会因为增加性能测量代码而使得处理消息的吞吐率降低约70%),以及增加开发工作量.与之相反,第二种方法虽然提供了简便的性能测量方法,但却无法保证性能测量指标的精确性.研究生院信息平台采用了第二种方案,主要是因为信息平台的用户规模有限,无需非常精确的性能指标.

图2 业务子系统功能架构Fig.2 Architecture of business subsystem
通过实时地采集上述系统性能指标,运维管理人员不仅可以准确地把握当前系统的实际负载来解决实际出现的系统性能问题,而且还可以通过记录与分析历史运维问题来增加相应的解决预案(如通过增加Docker应用),达到未雨绸缪的运维目标.
(2)用户行为分析用户画像与行为分析是很多互联网应用的核心功能之一,旨在通过记录与分析用户行为的模式去了解用户[7],通过推荐等手段来增加直接或间接的商业收益.不同于这些互联网应用中的用户行为分析,研究生院信息平台不需要在很细粒度上进行用户行为的追踪(如记录用户的鼠标在页面里划过了哪些组件以及停留时长等),仅需要以页面访问为单位来进行行为分析即可(如用户在页面的停留时长和页面访问频次).另一方面,当某个用户在系统中执行了非法操作后,记录详细的用户访问请求可以确保数据安全方面的可追溯性.传统方式大多会建立相应的数据表并记录用户访问情况[8],然而这增加了系统的开发维护成本和数据库的访问负载.基于负载均衡器记录的用户访问日志,不仅可以达到保存用户访问请求的目标,而且还有效地避免了上述问题.因此,在系统实现中,无需在Web页面中植入获取用户行为的JavaScript代码和增加用户访问记录的数据表,而是采集负载均衡器的用户请求日志,这有效地降低了系统功能开发与维护的门槛与成本.
(3)服务异常调试对于Web前端与后端业务逻辑的实现而言,无法避免在实际使用过程中出现一些异常(由软件开发中的缺陷导致).为了提升系统的可靠性,需要系统研发团队能够快速定位到问题的根源,并依据异常提示进行缺陷修复.然而,如何准确定位并理解问题的根源是一个极具挑战的难题.为了解决这个问题,要求开发团队要能设计好异常提示.在研究生院信息平台的实现中,通过采集负载均衡器的日志与应用日志,将访问请求的详细信息与异常信息进行匹配,确保了研发团队准确理解并快速定位问题根源.
2.3 技术挑战
在设计研究生院信息平台的运维子系统时,主要面临以下三个技术挑战.
(1)实现业务子系统与运维子系统的松耦合.业务子系统的功能通常会发生较为频繁的改变,而运维子系统也会根据运维需求而逐渐变化.如果两个子系统之间存在较高的耦合,业务子系统的频繁变更将会导致运维子系统也相应地不断变化,而运维子系统的较大升级将可能导致所有业务系统的升级.因此,新的运维子系统与业务子系统在代码和运行部署上应该尽可能地独立.
(2)降低运维子系统的引入导致的性能损失.为了支撑运维子系统的运行,业务子系统中必然需要植入相关代码,输入运维子系统所需要的数据.而如何植入相关统计代码,统计信息的种类以及输入输出信息的过程都将对业务子系统的性能产生影响.如前文所述,CouchDB由于在代码中植入了性能测试代码,导致IOQ处理消息的吞吐率降低约70%.因此,从系统性能的角度出发,新版运维子系统需要避免对业务子系统的性能造成显著影响.
(3)运维子系统的灵活可扩展.业务子系统的功能变更较为频繁,老系统需要升级改造,新系统不断地构建部署.此外,运维业务本身的需求会不断地发生改变,从最基础的后台API运行状态监控,发展到主动地检测用户异常行为.因此,运维系统子系统需要具备一定的可扩展性,以便保证能够适应未来几年的需求变换.
3 设计与实现
研究生院信息平台的运维子系统采用了开源ELK框架,主要包括三个原因:第一,不同于互联网公司的内部系统,由于研究生院信息平台的数据规模和用户访问量有限,因此信息平台仅需要一个轻量级的运维子系统;第二,ELK提供了端到端的日志采集与分析工具,易于安装部署且规模可控;第三,基于ELK框架进行运维业务的开发,只需要解决如何抽取日志信息与设计仪表盘这两个问题,使得开发人员可以更专注于如何实现运维业务需求.基于上述原因,本文采用了开源的ELK框架来搭建运维子系统[9].
本节首先介绍ELK框架,然后分析了运维所需的统计信息,最后给出了日志抽取和仪表盘的设计与实现.
3.1 ELK简介
ELK由Elasticsearch,Logstash和Kibana三个开源工具[5]组成.Elasticsearch是一种基于Lucene的分布式搜索分析引擎,主要负责存储并索引由Logstash提供的各种日志,并提供日志搜索接口;Logstash是一个日志收集处理框架,解析从多种日志源中采集的日志数据,然后发送给Elasticsearch完成日志数据的存储与索引.Logstash通过建立事件处理管道来解析日志,包括三个核心配置插件:输入(Inputs),输出(Outputs)和过滤器(Filters).输入用于声明日志数据的输入来源,支持基于文件、端口或数据库等日志读取方式;过滤器用于处理日志数据,其中Grok插件负责从非结构化日志数据中提取出结构化信息;输出将过滤器解析的数据发送给Elasticsearch.Kibana则使用Elasticsearch提供的RESTful接口来查询日志数据,通过不同类型的图表帮助用户构建数据仪表盘,达到可视化日志分析的目的.
如果采用Logstash来解析并转发日志信息给Elasticsearch,那么就需要将Logstash部署在每一台系统服务器上.由于Logstash在处理日志的过程中需要消耗大量内存,会显著地降低应用服务器的性能.因此,系统实现将日志发送与解析进行了分离:使用Beats完成日志采集与传输,而Logstash则用于日志解析.Beats在ELK框架中被安装在应用服务端作为代理采集并转发数据,ELK提供的Beats组件主要包括:Filebeat,Metricbeat和Packetbeat.其中,Filebeat用于收集日志文件,Metricbeat用于采集系统信息,而Packetbeat则用于收集网络信息.
3.2 日志统计信息
系统首先需要收集并统计与Web访问相关的信息,包括访问量,访问IP,访问账号以及访问时间.通过统计前三类信息随时间变化的趋势可以让运维人员对系统有一个清晰的整体认识.此外,需要注意的是,访问IP和访问账号还可用于进行用户行为分析和记录与数据安全相关的用户操作(例如,可根据访问情况随时间的变化曲线找出行为异常的账号,以及哪个用户在什么时间通过哪个RESTful接口进行数据更新或删除操作).
其次,系统还需要统计每个请求访问的页面或后台服务,包括URL地址,响应时间,返回状态以及访问请求中的参数等信息.通过对这些信息的统计分析,运维人员可以了解哪些页面或后台服务的访问过于频繁、响应时间过长或者访问请求返回的状态码不正常,进而与开发团队一起有针对性地修正系统功能或优化系统性能.
最后,为了监控负载均衡服务器,数据库服务器,Web和应用服务器的资源消耗与负载状况,系统还需要收集并统计系统日志,包括CPU使用情况,内存使用情况,进程使用情况等信息.
基于以上讨论,表2给出了不同运维场景下需要统计的日志信息以及相应的日志来源.

表2 运维统计信息Tab.2 Statistical information of operation and maintenance
3.3 日志抽取
基于3.2节的统计信息,运维子系统需要从业务子系统中收集三类日志数据,而每种日志数据都通过Beats组件转发给Logstash进行日志解析.由于系统的访问请求入口都通过Nginx,因此我们可以很方便的从Nginx日志中获取大部分运维系统所需统计分析的日志信息.此外,由于Nginx支持对日志格式的定制化操作,结合3.2节列举的统计日志数据项,表3给出了运维子系统记录的Nginx日志字段.
表3中的日志信息通过Filebeat发送给Logstash,Logstash随后对接收到的日志文件进行解析,提取出运维所需存储的日志信息,以便于在Elasticsearch中进行查询和统计.对Nginx日志文件的解析主要由Logstash中的Grok插件完成,使用正则表达式对日志信息进行匹配和抽取,Grok插件提供了一些预定义的正则表达式可以直接使用.图3给出了运维系统实现的Nginx日志抽取规则,其中“%{WORD:http host}”用于对请求地址字段的信息抽取,WORD表示Grok中预定义的对字符进行匹配的正则表达式,http host表示对该字段的命名.对于Nginx记录的错误日志,运维子系统同样使用Filebeat将错误日志发送给Logstash,随后依据类似的抽取规则提取出错误发生的时间,错误级别和错误详细信息等字段,并转发给Elasticsearch用于存储与查询.
业务子系统在运行期间时会将用户行为记录在应用日志中,由于业务子系统在Docker容器中部署运行,为了获取业务子系统产生的日志文件,我们将Docker容器内的应用日志文件挂载到服务器磁盘上.这样,运维子系统就可以直接使用Filebeat将日志文件转发给Logstash来完成日志解析与抽取.由于应用日志文件的抽取规则与对Nginx日志的处理类似,这里就不再进行详细的描述.

表3 Nginx访问日志字段Tab.3 Nginx access log f i elds

图3 Log stash中的配置Fig.3 Conf i guration of Log stash
由于整个系统安装部署在Linux操作系统上,因此使用syslog作为系统日志并由Metricbeat完成日志收集(Docker虚拟机的日志也通过Metricbeat进行收集).此外,Metricbeat提供了预定义的仪表盘模板,以便于对所采集的系统日志进行统计展示.在系统实现中,我们直接采用了Metricbeat提供的仪表盘,并通过kibana展示.
3.4 仪表盘设计
运维子系统采用Kibana的仪表盘设计来完成日志分析结果的展示.在实现中,系统首先会呈现给用户一个总览仪表盘(如图4所示),主要包括六部分日志统计信息:①仪表盘目录,点击每个目录项可以获取更具体的日志统计信息,如系统负载统计,Docker容器运行状况,用户行为统计等;②在某个时间段内的系统访问吞吐量(时间段可以由用户任意指定);③在某个时间段内访问系统服务最多的用户统计信息;④在某个时间段内访问系统服务最多的IP统计信息;⑤用户访问情况的分时统计;⑥系统服务器资源使用情况的统计信息,如CPU,内存和硬盘的使用情况等.
通过上述总览仪表盘,运维人员每天都可以方便地了解研究生院信息平台各个功能模块的访问情况以及服务器的负载状况.例如,如果运维人员发现用户访问量增长地很快且Docker容器的性能显著下降,则可以增加一定数量的Docker容器并将应用服务逻辑部署在这些容器中,从而快速实现负载均衡.
在性能监控部分,系统日志的展示可以由Metricbeat导入的仪表盘实现,除此之外最重要的是应用中各API接口的响应时间,图5统计了各API响应时间中的最短时间,最长时间及平均时间,这可以帮助系统开发人员有效地发现系统性能瓶颈,根据访问参数来调试应用服务,通过代码优化等方法不断完善系统功能和性能.

图4 仪表盘总览图Fig.4 Overview of dashboard

图5 API响应时间统计图Fig.5 Statistical chart of API response time
对于用户行为分析需求,系统运维人员希望了解的典型场景是:哪些用户何时发送了哪些请求.在实现中,系统可以根据收集的日志信息从多个层面进行分析.例如,统计每个用户访问最多或最频繁的页面来反映用户使用系统的功能偏好,然后根据用户偏好为不同的用户进行系统功能的个性化布局与优化;或者统计在不同时段的系统访问情况来反映用户使用系统的时间偏好(图6展示了在不同时段的系统访问情况),从而达到依据时间段来动态调整系统资源的目标.
对于服务异常调试,系统需要收集应用逻辑抛出的异常,Docker的异常,MySQL的异常以及Nginx的负载异常.为了定位问题来源,可以分别对MySQL的错误日志,Nginx的错误日志和应用日志中的错误进行分时统计.当出现某种异常时,运维人员首先通过查看对应时间段内哪种日志类型中记录了错误信息来定位异常发生的位置.如果是应用逻辑抛出的异常,可以进一步在Kibana中搜索与该异常发生在同一段时间内的Nginx记录的访问请求,如哪个用户调用了哪个API并且RESTful的访问参数是什么.这样,开发人员就可以准确地了解所有与异常相关的信息,便于快速精确地定位与修正错误.

图6 API分时统计Fig.6 API time sharing accounting
4 性能分析
由于运维子系统需要定时从Nginx服务器和业务子系统的日志中抽取信息,这不可避免的会对业务子系统带来一些性能方面的影响.针对性能问题,本节测试并对比了在运行运维子系统和关闭运维子系统两种情况下业务子系统对用户请求的吞吐量.实验运行在一台安装了Centos7操作系统的服务器上,配备了8个主频为2.4 GHz的Intel Xeon CPU E5-2630芯片,内存为16 GB,磁盘容量为4TB,转速为7 200 r/s.
性能测试实验选择了学籍业务中具有代表性的用户请求,包括四种类型:角色激活,菜单获取,学籍查询和条件查询,其中角色激活指用户选择自己要进行操作的角色,菜单获取指获得可以操作的菜单页面,学籍查询指根据学生的学号返回学籍信息,条件查询指输入查询条件返回符合条件的学生信息.角色激活和菜单获取是用户登录时都需要进行的请求,基本覆盖了权限域表的操作;学籍查询和条件查询是学籍业务中的常用请求,且条件查询在请求数据时需要执行复杂的连接操作.在性能测试中,我们实现了一个用户请求模拟器,并在四台PC上安装运行了128个实例,不间断地向服务器发送请求.
图7展示了启用和关闭运维子系统时请求访问量的性能对比.从图中可以看出,在启用了运维子系统之后,业务子系统的性能相比于关闭运维子系统时略有下降,即业务子系统所处理的请求吞吐量仅降低了约5%.因此,实验结果证明了在几乎不降低业务子系统的请求吞吐量的情况下,运维子系统可以有效地实现对业务子系统的性能监控、基于用户行为分析的系统优化和服务异常调试的三个运维目标.

图7 访问量对比图Fig.7 Contrast of API views
5 结论
基于日志收集与分析的运维模式为现代大型软件系统提供了丰富的运维信息,从而有效地确保了大型业务系统运行期间的可靠性与稳定性.基于现代运维服务的理念,本文采用开源的ELK框架,设计并实现了华东师范大学研究生院信息系统中的运维子系统,解决了研究生院业务系统在实际使用中遇到的性能与负载监控、用户行为分析以及服务异常调试等问题.实践证明,本文实现的运维子系统不仅很好地满足了华东师范大学新一代研究生院信息系统的各种实际运维需求,而且还确保了业务系统与运维系统之间的相互独立性,这使得运维系统可以灵活地适应未来业务系统的升级改造.
[1]于长虹.智慧校园智慧服务和运维平台构建研究[J].中国电化教育,2015(8):16-20+28.
[2]岑荣伟,刘奕群,张敏,等.基于日志挖掘的搜索引擎用户行为分析[J].中文信息学报,2010(3):49-54.
[3]郭岩,白硕,杨志峰,等.网络日志规模分析和用户兴趣挖掘[J].计算机学报,2005(9):1483-1496.
[4]邢东山,沈钧毅,宋擒豹.从Web日志中挖掘用户浏览偏爱路径[J].计算机学报,2003(11):1518-1523.
[5]白俊,郭贺彬.基于ElasticSearch的大日志实时搜索的软件集成方案研究[J].吉林师范大学学报(自然科学版),2014(1): 85-87.
[6]刘庆磊,信师国,李晓林.虚拟技术在IT运维管理中的应用研究[J].信息技术与信息化,2010(1):43-45.
[7]王新,马万青,潘文林.基于Web日志的用户访问模式挖掘[J].计算机工程与应用,2006(21):156-158.
[8]鲍钰,黄国兴,张召.基于Web日志挖掘的网站结构优化方法[J].计算机工程,2003(12):82-84.
[9]周映,韩晓霞.ELK日志分析平台在电子商务系统监控服务中的应用[J].信息技术与标准化,2016(7):67-70.
(责任编辑:李万会)
Design and implementation of operation subsystem in graduate student management system
SHI Bing1,XIA Fan1,SONG Shu-bin2,XIAO Li-min2,DONG Qi-wen1, ZHOU Ao-ying1,XU Lin-hao3
(1.School of Data Science and Engineering,East China Normal University,Shanghai 200062,China; 2.Graduate School,East China Normal University,Shanghai 200062,China; 3.Infosys Technologies China Ltd.,Shanghai 200135,China)
Log collection and analysis based operation scheme is very important in the design of modern software systems,which helps system administrators to enhance data security and service stability.Firstly,this paper discusses the existing operation approaches based on log collection and analysis.Secondly,with the open source ELK framework,this paper gives a detailed design of the operation subsystem in graduate student information platform.The proposed design can ef f ectively fulf i ll the practical requirements of the graduate school,like performance and workload monitoring,user behavior tracking and error tracing,by using the real-time interactive data analysis on system and application logs.Finally,this paper demonstrates the interactive dashboard implementation of our operation subsystem under dif f erent business scenarios.
operation and management;log analysis;data analysis
TP315
A
10.3969/j.issn.1000-5641.2017.05.020
1000-5641(2017)05-0225-11
2017-05-01
国家重点研发计划(2016YFB1000905);国家自然科学基金广东省联合重点项目(U1401256);国家自然科学基金(61672234,61402177);华东师范大学信息化软课题
史兵,男,硕士研究生,研究方向为数据科学技术应用.
夏帆,男,博士后,研究方向为社交媒体分析.E-mail:fxia@sei.ecnu.edu.cn.
