异构Redis集群大规模评论数据存储负载均衡设计
2017-09-22张敬伟丁志均杨青张会兵张海涛周娅
张敬伟,丁志均,杨青,张会兵,张海涛,周娅
(1.桂林电子科技大学广西可信软件重点实验室,广西桂林541004; 2.桂林电子科技大学广西自动检测技术与仪器重点实验室,广西桂林541004)
异构Redis集群大规模评论数据存储负载均衡设计
张敬伟1,丁志均1,杨青2,张会兵1,张海涛1,周娅1
(1.桂林电子科技大学广西可信软件重点实验室,广西桂林541004; 2.桂林电子科技大学广西自动检测技术与仪器重点实验室,广西桂林541004)
大规模评论数据的存储与查询性能对构建于其上的各类应用的快速响应具有重要影响.同时,异构计算环境中各计算节点性能呈现差异,如何充分开采各节点的计算和存储性能,优化大规模评论数据的存储与查询性能,是一个关键挑战.基于Redis集群的数据管理优势,首先提出了一种同构环境下基于卡槽存储平衡的大规模评论数据存储模型;然后论证了卡槽数目与节点查询效率的关系,以“负载与访问性能相平衡”的原则分配卡槽,进一步设计了异构环境下的集群节点负载计算和存储分配方法,充分开采了异构Redis集群中不同节点的性能.实验结果表明,提出的存储模型具有很好的存储平衡效果,提升了集群的整体查询效率.
大规模评论数据;存储负载均衡;查询优化
0 引言
用户在电子商务网站、Web论坛等贡献了海量的评论数据,其蕴含了用户的兴趣偏好、主观观点、潮流取向等信息,对在线推荐、舆情监控、用户画像、公司商品服务决策等分析应用具有重要价值.上述分析应用通常要求以用户、评论对象、时间段等维度为查询约束开展高IO的数据获取操作,以有效支撑上层的计算与分析,这对大规模评论数据的管理带来了挑战.同时,快速发展的计算机硬件,例如多核CPU和大容量内存,使得应对大数据的分布式计算环境也不断更新变化,异构特征显著,硬件的革新给大规模数据的管理带来了新理念[1].如何利用大内存带来的存储性价比优势进行有效的负载均衡设计,充分开采异构集群中各计算节点的性能,是为基于大规模用户评论数据的分析应用及其快速响应提供数据访问优化的关键,具有重要的应用价值.
本文首先分析了基于评论数据分析应用的查询需求与特征,基于Redis的内存数据管理优势,设计了一种同构Redis集群下的评论数据平衡存储模型,保证了各卡槽数据的均匀分配;进而根据卡槽与键值的对应关系,测试配有不同卡槽数目的节点的查询效率,并基于测试结果、运用最小二乘法拟合出各节点卡槽数目与查询性能的关系,最后以“负载与访问性能相平衡”的原则分配卡槽,从而充分开采了异构Redis集群中不同性能节点的工作能力,提高了集群的整体查询效率.测试并不考虑其他因素,只根据当前的查询性能进行判断,避免了不可估计的参数影响,让建议的方案具有较强的实时性.
本文内容组织如下,第1节阐述了相关工作;第2节对具体问题需求进行了分析;第3节和第4节详细介绍了建议的评论数据存储模型,以及针对异构Redis集群的负载计算和存储分配的具体设计方案;第5节对提出的方法进行了实验验证;第6节对本文工作进行了总结.
1 相关工作
根据设计与实现方式的策略异同,现有的分布式存储系统架构主要分为两个派别:主从结构分布式存储系统和对等网络分布式存储系统.这两类系统的主要区别在于有无中心控制节点.
HBase、BigTable[2]、HDFS[3]是前者的典型代表,其通过管理节点master管理整个集群,监控各个存储节点slave并维护slave节点的信息,系统的写入与读取均需要与master进行交互.因此,主从结构分布式存储结构将系统角色划分为master和slave,让master节点负责slave节点系统负载、存储平衡、故障恢复等问题.这种管理模式简单,便于系统维护,但会造成master节点的压力过大,成为整个系统的瓶颈,以及master节点的系统故障导致系统可用性问题[4].
对等网络分布式存储系统主要通过分布式哈希算法建立逻辑映射的方式,将数据与存储节点关联.这种方式不需要设置中心管理节点,每个节点拥有并维护整个集群的信息,通过广播方式向其他节点报告自身信息.这种分布式存储架构具有很好的拓展性,但由于没有中心节点的控制,使得整个系统不能很好地根据当前状态进行负载的动态均衡.Redis即采用无中心节点的对等网络存储模式,建立有效的动态存储负载均衡策略对Redis集群整体性能提升具有重要意义.
具体到对等网络的存储负载均衡问题,当前的研究主要包含三个方面:1)构建动态平衡存储结构,维持整个集群的的平衡性.文献[5]将各集群中主机节点构建成一棵虚拟的平衡二叉树,同时给出了虚拟二叉树的路由方法以及节点的加入及删除方法,提高了对等网络的空间均衡和可用性.文献[6]通过累积延迟周期调整逻辑分区的大小,并基于一种有向无环图的方法实现逻辑分区的实时性分配.这种方式需要消耗大量时间来保证系统平衡,不适用于频繁更新的存储环境.2)设置数据的多个副本实现负载平衡.文献[7-8]通过副本备份,让集群中任意两点的存储内容都有存储交集,用户发出请求时,可以同时向多个节点获取内容.这种方式可增加系统的局部处理能力及可靠性,但随着副本数量的增加,维护多副本之间的一致性的开销变大,增加了系统的负担.3)采用数据迁移技术实现系统负载均衡.文献[9-10]通过权衡数据迁移获得的收益与消耗的代价,提出分布式数据迁移算法,并借助于存储位置优化节点间负载平衡,提高了系统运行效率.本文的工作主要聚焦于构建存储平衡模型和负载迁移技术,来解决异构Redis集群环境下的动态存储优化问题.
2 问题分析
在商品观点分析、用户画像等基于评论数据的分析应用中,通常需要以商品ID、时间范围或用户ID、时间范围为条件展开查询操作以获取数据.在采用key-value模式进行数据组织时,上述属性需要封装在key中,以建立与评论数据的一对一映射关系.多属性封装key影响数据存储key的数量以及key包含数据的规模.当较多数目的属性或分割粒度较大的属性被封装成key时,键值的数目相对较少,容易实现整个集群的存储平衡,但在进行部分属性查询时,需要以扫描的形式填充未给出属性,降低了查询效率;当较少数目的属性或分割粒度较小的属性被封装成key时,会使键值数目偏大,易造成存储和访问负载的不平衡.
在异构集群环境下,高性能的节点会比低性能的节点具有更快的响应速度,但并发访问效率通常受低性能节点制约.如图1(a)所示,在负载不均匀分配情况下,给予四个节点分配相同的负载量,虽然2~4节点的查询时间小于20 ms,但最终运行时间由1号节点决定;而相对于负载均衡的负载分配(图1(b)),所有节点返回的时间相近,从而提高了整个集群的查询性能.Redis采用无中心控制节点的对等网络分布式存储结构,支持手动或默认平均分配的方式分配卡槽实现数据存储,这种分配方式并没有考虑异构集群环境下的节点性能差异,需要面向节点性能差异建立动态的负载均衡方法.
针对上述问题,本文首先设计满足大规模评论数据查询需求的平衡存储模型,保证Redis中每个卡槽内的数据量相对均匀;进而以同构环境下存储平衡的存储模型为基础,针对Redis集群在异构环境下存储分配的不足,提出了动态负载计算和访问性能预判的存储分配方法,提高了异构Redis集群的并发访问效率.
3 基于Redis的大规模评论数据平衡存储模型设计
评论数据主要包含商品ID、评论用户、评论时间、评论内容4个属性.基于大规模评论数据的分析应用主要以商品ID、时间范围或评论用户、时间范围开展查询操作.同时,用户对商品的评论存在稀疏性,即一个用户只对少量的商品进行过评论,而商品ID属性对评论数据具有很好的聚合.依据查询方式的不同,将评论数据的商品ID属性与用户属性分别处理,商品ID属性作为评论数据的承载单元,用户属性作为辅助索引.

图1 不同存储负载的访问示例Fig.1 Accessing illustration on dif f erent storage loading
由于不同商品拥有的评论数目不同,导致基于商品ID存储的数据规模不同.如果商品拥有的评论数目过大,将造成集群存储不均衡.因此,本文提出以特定的评论数目(LineNum)为基准,对商品评论的时间属性进行分割,构建商品评论的二级索引.例如当LineNum为1 000时,即将评论数据以1 000个评论条目为单位进行分割,并记录每个分割单元的起始时间,使用Redis有序集合实现存储.具体索引结构如表1所示,其以“商品ID(ItemID)”为键值构建第一层索引,“起始时间戳(StartTime)”为排序值构建第二层索引,“商品ID:分割编号(ItemID:Number)”对应评论数据集合.表2描述评论数据的具体组织结构,也采用有序集合进行存储,其中具体值的内容为“用户ID:评论内容(UserID:comment)”,“评论时间的时间戳(Timestamp)”仍然作为排序值使用.

表1 评论数据二级索引结构Tab.1 Two-level index for comment data

表2 评论数据存储结构Tab.2 Storage structure for comment data
其次,使用“用户ID(UserID)”属性构建辅助索引,其中存储内容形式为“ItemID:Number: Timestamp”,并通过“,”加以区分.在进行评论数据查询时,只要涉及用户ID属性的查询,通过检索辅助索引的方式找到对应的信息,基于用户ID的辅助索引结构如表3所示.

表3 基于用户ID的辅助索引结构Tab.3 A secondary index on UserID
上述存储模型能满足大规模评论数据的存储与查询需求,同时以商品ID属性和Redis的卡槽数据组织模式为主要考虑因素让评论数据分布更加均衡,确保每个卡槽的存储数据量是相近的.
4 异构Redis集群下基于负载计算和访问性能预判的存储分配方法
在异构集群环境下,由于各节点的性能不一致,不合理的任务分配会降低整个集群的工作效率.鉴于Redis集群只提供了手动或默认均匀分配存储的方案,没有提供根据工作当前状态优化存储分配的方法,本文设计了面向异构Redis集群的负载计算和访问性能预判的存储分配方法,根据节点的实际查询性能实现均衡的存储分配.
设计的方法包含4个阶段.(1)建立卡槽节点映射表与卡槽测试键列表:根据键值与Redis的卡槽映射关系,为每个卡槽生成一个测试键值对,将全部的测试键值对存储在Redis集群中,并统计Redis集群信息,包括卡槽与节点关系、每个节点拥有的卡槽数目;(2)节点查询性能测试:根据卡槽节点映射表与卡槽测试键列表生成各个节点的卡槽测试键值表,并根据节点的卡槽数目将该节点的卡槽测试键值集合均匀地分成10等份,以份数为单位,对各个节点进行访问性能测试;(3)计算当前状态下的存储负载:运用最小二乘法拟合出各节点的卡槽数目与查询性能的关系,求得节点查询性能与查询负载相平衡的卡槽数目分配比例;(4)迁移卡槽数据实现存储均衡:根据新、旧的卡槽数目运用最大卡槽转出数目与最大卡槽移入数目相匹配的方式计算需要转移的卡槽,执行节点间卡槽转移.
4.1 建立卡槽测试键及卡槽节点映射表
该阶段的主要任务是生成卡槽测试键表以及卡槽机器映射表,记录各机器卡槽数目等.卡槽测试键是基于A~Z或a~z字符集合随机生成的4位字符串,将该字符串作为卡槽测试键值.鉴于Redis的最大卡槽数目是16 384个,将上述测试键值的CRC16码与16 384取余为测试键值,建立卡槽分配函数,基于获取的卡槽索引号将字符串存储在卡槽测试键列表(SlotString)中.以<key,index>键值对形式存储到Redis中,其中key为生成的4位字符串,index为卡槽测试键列表的索引值,即Redis卡槽编号,从而使得每个卡槽都存有一个卡槽测试键,卡槽测试键表如图2所示.

图2 16 384个卡槽测试键表Fig.2 Illustrating test key table for 16 384 slots
读取卡槽节点映射表信息,统计每个节点分配的卡槽数目,并存储在节点卡槽数目列表中.卡槽节点映射表(SlotToMachine)、节点卡槽数目列表(SlotNum)具体格式如下. SlotToMachine={1,2,1,…,n,…},集合内每个元素表示节点的索引号,一个卡槽对应一个节点,列表长度为16 384,列表的索引值表示卡槽编号.SlotNum={N1,N2,…,Nn},其中Nn表示编号为n的节点拥有的卡槽数目.
4.2 负载测试
上述预处理过程使得Redis集群中每个卡槽都具有唯一的一个测试键,同时设计的评论数据存储模型保证了各卡槽映射的数据相对均匀,这使得可以将对卡槽数目的负载测试转化为对键值数目的测试.每次查询操作可简化成基于测试键值计算卡槽,依据卡槽归属信息获得节点,再从节点中提出数据的过程.因此,对于特定节点测试是相对独立的,测试过程如图3所示,具体描述如下.
(1)遍历卡槽节点映射表,根据卡槽节点映射表的节点索引号n以及在表元素的索引值i,获取卡槽测试键列表中对应各卡槽的卡槽测试键集合SlotString[i],并进而建立各节点的卡槽测试键列表;
(2)将各节点的卡槽测试键列表均匀地分割10等份,当测试键值(或卡槽数目)无法满足被10整除时,将剩余的测试键值全部放入到最后一个等份中;
(3)以一份测试键集合为一个测试单位,对Redis集群进行查询性能测试,第一次查询第一份测试键集合中的所有测试键值,第二次查询第一份和第二份两个测试键集合中的所有测试键值,以此类推.每一次的测试运行5次,将查询测试的时间存储在测试时间列表中ResultList={t1,1,t1,2,t1,3,t1,4,t1,5,t2,1,…,tp,q,…,t10,5},其中p表示参加测试的份数,q表示当前的测试次数;
(4)将各节点的测试结果根据节点索引号排序,共产生n×50个测试结果,n为节点的数目.

图3 查询负载测试过程Fig.3 The test process for query performance
4.3 访问性能预测与存储分配
上节的查询性能测试中,影响查询效率的因素主要有节点本身的性能,已有负载和网络传输,鉴于节点的查询效率与测试键数目成正比例关系.由于键值数目可转化为卡槽数目,得如下方程(1).

其中,T表示卡槽集合查询所需要的时间,v表示测试机器在当前状态下的查询性能,N表示卡槽的数目.使用最小二乘法求得方程中v的值,即保证预测的结果与实际值的误差最小,给出最小误差平方和公式(2).

其中,t表示键值集合的查询时间,v表示节点的查询性能,n为当前测试键集合的键值数目(等于卡槽数目),p为当前参与测试键值集合的份数.该公式转换为矩阵表示,即(T-N v)T(T-N v),对v求导得到-2NT(T-N v),令其等于零,则有各个节点的卡槽数目与查询时间的关系如(3)所示.

根据各节点卡槽数目与查询时间的线性关系,保证查询负载与查询性能相平衡,即不同节点完成不同查询任务的时间应相同,有
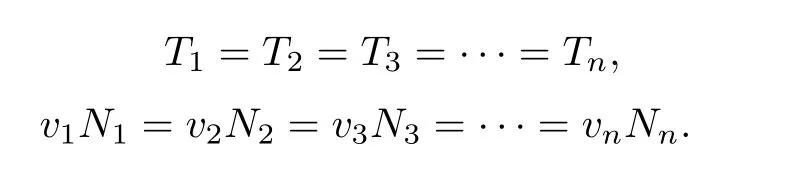
因此,得到不同节点卡槽数目的关系应为

且N1+N2+N3+…+Nn=16 384.在实际计算中,N若不能刚好被16 384整除,有如下约定,当<16 384时,将剩余的应分配卡槽分配到v值最小的节点上;当>16 384时,将多出的冗余卡槽数目从v值最大的节点中移除,从而得到节点查询负载平衡的新卡槽数目,将新得到的卡槽数目存储到NewSlotNum中,NewSlotNum={cN1,cN2,…,cNn},其中,cNn表示编号为n的节点存储的卡槽数目.
4.4 迁移数据卡槽
为保证数据转移效率,本文采用最大转出卡槽数目节点与最大移入卡槽数目节点相匹配的策略计算需要转移的卡槽,从而保证每一次匹配都可移除一个节点的卡槽转移计算.
首先以新卡槽数目为目标,求出各节点需要转移卡槽的数目,节点卡槽数目增多为正值,节点卡槽数目减少为负值,生成节点卡槽转移数目列表NodeSlotMigrateList= {M N1,M N2,M N3,…,M Nn},其中,MN为节点卡槽转移的数目,n为集群节点的数目;再从NodeSlotMigrateList中寻找节点卡槽增加的最大值P和节点卡槽减少的最大值Q,将两个卡槽节点的数目进行匹配,即将卡槽减少最多的节点转向卡槽增加最多的节点.扫描卡槽节点列表(SlotToMachine)提取转移的卡槽,并以<FromMachine,ToMachine,Index1, Index2,...,Indexi>形式存储转移卡槽记录,Index表示需要转移的卡槽编号,更新SlotToMachine列表,同时将NodeSlotMigrateList中的P与Q绝对值较小的值置为0,较大的值置为P+Q.重复上述操作,直至节点转移卡槽的值全部为0;最后,根据卡槽节点映射表SlotToMachine记录的卡槽转移记录执行卡槽转移.
5 实验
为了测试在异构条件下的Redis集群存储分配优化方案,本文在一台Dell PowerEdge R370服务器上基于VMware云平台搭建了Redis集群,服务器拥有20个CPU,128 G内存.实现的异构集群由3台虚拟机节点构成,节点的处理核心数分别为1、2、4,内存分别为4 G、4 G、8 G,操作系统为red hat linux 5.6.节点与测试机在同一个局域网内,网卡为千兆以太网卡,Redis集群版本为3.2.6.实验数据为真实的京东评论数据,大小为900 M,472件商品,共5 241 992条评论记录,评论数目最多的商品拥有45万多条评论,用户2 642 152人.
实验分为三个部分,第一部分为评论数据存储模型的分割跨度的设定,选出存储平衡性最好的存储跨度(即以特定数目LineNum对评论进行分割);第二部分测试在默认平均分配卡槽的Redis集群下,通过本文提出的算法进行存储负载的测试,验证负载与卡槽数目线性关系的正确性,并计算出符合负载的卡槽分配数量;第三部分为卡槽移动前后的Redis集群查询性能对比.
5.1 模型分割参数实验
以默认平均分配卡槽的方式构建Redis集群,3个节点拥有卡槽数目分别为5 462、5 461、 5 461,共16 384个卡槽.将上述评论数据集以10 000为跳步,依次按照本文提出的存储模型开展存储效果测试,测试结果如表4所示.表4的测试结果显示,2万条数目进行分割的存储平衡效果最好,随着分割参数的增大,平衡的效果逐渐弱化,最后平衡的效果趋近于不分割的存储平衡效果.由于Redis系统本身以及管理数据的结构所占用的空间,其总量约为数据本身大小的1.5倍左右.

表4 存储平衡分割参数(LineNum)的测试结果Tab.4 Experimental results for parameter(LineNum)of storage partition
5.2 存储负载测试
首先,基于默认值搭建Redis集群,则各节点分别被分配5 462、5 461、5 461个卡槽.使用存储负载管理器对Redis集群进行测试,测试结果显示卡槽数目与读取时间的回归曲线如图4所示.该图验证了卡槽读取的数目与读取时间的线性关系,在系统不稳定时,测试会稍现波动,例如,图4中配置有2核心CPU、4G内存的节点的性能有分散形状.
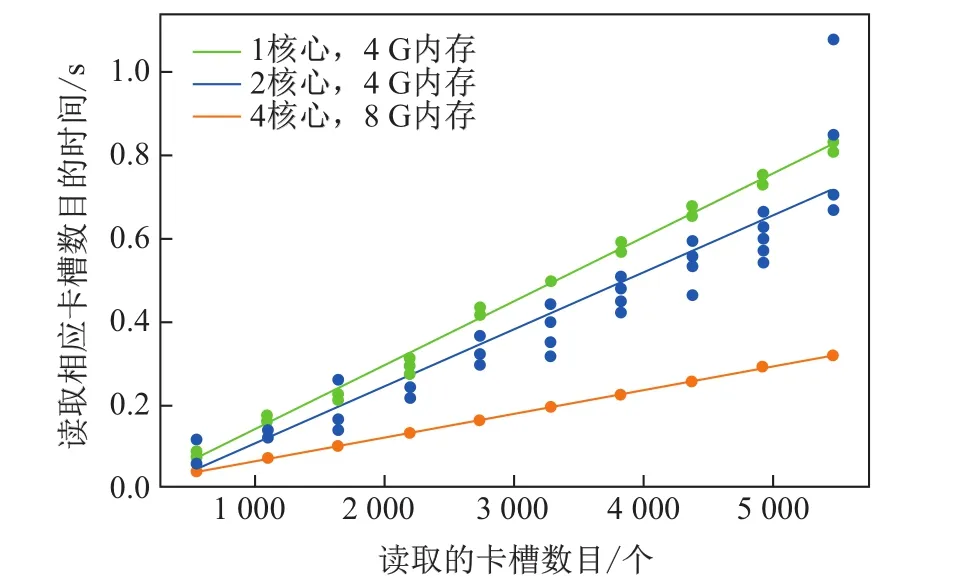
图4 节点查询性能测试Fig.4 Performance test for node query
图4显示1核、2核、4核节点的查询速度分别为v1=0.151 55毫秒/槽、v2= 0.130 67毫秒/槽、v3=0.058 305 2毫秒/槽.根据节点拥有卡槽数量与速度成反比的关系,得到新的卡槽数量应分别为3 449、4 000、8 935.卡槽转移前后Redis集群的数据存储如图5所示,卡槽移动后的存储比例如表5所示.
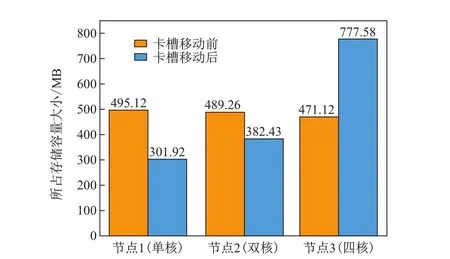
图5 迁移卡槽前后存储数据量对比Fig.5 Comparison of data volume before and after shifting slots

表5 卡槽转移后存储数据比例Tab.5 Ratios after shifting slots
5.3 查询性能对比
从数据集中随机选出10件商品,具体数据规模如表6所示.测试查询10件商品分别在1日、1月、半年、1年、1年半时间范围内的所有评论所需要的时间,测试结果如表7所示,结果显示查询效率有不同程度的提高,但并无明显的变化规律.这是由于评论数据本身随时间的密集程度不一以及单条评论内容大小是不确定的.从表6中可以发现商品4、5虽然数目比商品2多,数据的大小却小于商品2.数据的密集程度将影响查询结果的数目,单条评论内容大小同时影响查询结果,二者的不确定导致性能提高的不确定.

表6 查询数据表Tab.6 Data fact for testing queries

表7 范围查询测试结果Tab.7 The experimental results for queries
6 总结
本文主要针对异构Redis集群环境下评论数据存储的负载均衡问题,详细分析了大规模评论数据的查询需求,提出了一种同构环境下以商品ID为键值存储评论数据,以用户ID为键值建立辅助索引的存储模型,并以一定的分割阀值对存储数据进行分割,从而保证存储系统的平衡性.然后,根据建立的存储平衡,提出了异构环境下的集群节点负载计算和存储分配方法,通过对测试键的查询得到卡槽与节点查询效率的关系,以“负载与访问性能相平衡”的原则来分配卡槽,并进行了理论分析.建议的方法充分开采了异构Redis集群中不同性能节点的工作能力,提高了集群的整体查询效率.
[1]INTEL.A yearly product cadence moves the industry forward in a predictable fashion that can be planned in advance[EB/OL].[2017-05-10].https://www.intel.com/content/www/us/en/silicon-innovations/intel-tock-modelgeneral.html.
[2]CHANG F,DEAN J,GHEMAWAT S.et al.Bigtable:A distributed storage system for structured data[J].ACM Transactions on Computer Systems,2006,26(2):205-218.
[3]BORTHAKUR D.The Hadoop distributed fi le system:Achitecture and design[EB/OL].[2017-06-02]. http://hadoop.apache.org/common/docs/r0.180/hdfs design.pdf.
[4]申德荣,于戈,王习特,等.支持大数据管理的NoSQL系统研究综述[J].软件学报,2013(8):1786-1803.
[5]何亚农,宋玮,赵跃龙.基于平衡结构的对等网络存储系统研究[J].计算机工程与设计,2011,32(8):2611-2613.
[6]KALA K A,CHITHARANJAN K.Locality Sensitive Hashing based incremental clustering for creating affi nity groups in Hadoop-HDFS-An infrastructure extension[C]//International Conference on Circuits,Power and Computing Technologies.IEEE,2013:1243-1249.
[7]ROWSTRON A,DRUSCHEL P.Storage management and caching in PAST,a large-scale,persistent peer-topeer storage utility[C]//Proceedings of the 18th ACM Symposium on Operating Systems Principles.ACM, 2001:188-201.
[8]OKCAN A,RIEDEWALD M.Processing theta-joins using MapReduce[C]//Proceedings of SIGMOD International Conference on Management of Data.ACM,2011:949-960.
[9]WEI Q,VEERAVALLI B,GONG B,et al.CDRM:A cost-e ff ective dynamic replication management scheme for cloud storage cluster[C]//IEEE International Conference on CLUSTER Computing.2010:188-196.
[10]XIE C,CAI B.A decentralized storage cluster with high reliability and fl exibility[C]//Proceedings of 14th Euromicro International Conference on Parallel,Distributed,and Network-Based Processing.IEEE,2006:1-8.
(责任编辑:林磊)
Storage and load balancing for large-scale comment data on heterogeneous Redis cluster
ZHANG Jing-wei1,DING Zhi-jun1,YANG Qing2,ZHANG Hui-bing1, ZHANG Hai-tao1,ZHOU Ya1
(1.Guangxi Key Laboratory of Trusted Software,Guilin University of Electronic Technology,Guilin Guangxi 541004,China; 2.Guangxi Key Laboratory of Automatic Detection Technology and Instrument,Guilin University of Electronic Technology,Guilin Guangxi 541004,China)
The storage and query performance for large-scale comment data have a great inf l uence on those applications built on the above data.In a heterogeneous computing environment,each node has dif f erent performance on storage and computation,it presents a key challenge for optimizing the storage and query performance for large-scale comment data by taking full advantage of the performance of each node.Based on the ability of Redis cluster,we design a storage model for large-scale comment data in a homogeneous Redis cluster,which provides the storage balancing in Redis slots.And then,we discussthe relationship between the number of Redis slots and query effi ciency to design a method for allocating storage on the real load of each computing node for heterogeneous Redis clusters,which can make full use of the performance of each node and can guide to allocate slots to nodes by balancing the query performance and storage loading.Our experimental results show that the proposed model has a good ef f ect on storage loading and improve the query effi ciency of the heterogeneous Redis cluster.
large-scale comment data;storage and load balancing;query optimization
TP315
A
10.3969/j.issn.1000-5641.2017.05.003
1000-5641(2017)05-0020-10
2017-06-30
国家自然科学基金(61363005,61462017,U1501252);广西自然科学基金(2014GXNSFA A118353,2014GXNSFAA118390);广西自动检测技术与仪器重点实验室基金(YQ15110);广西高校中青年教师基础能力提升项目(ky2016YB156)
张敬伟,男,博士,副教授,研究方向为海量数据管理.E-mail:gtzjw@hotmail.com.
杨青,女,副教授,研究方向为智能信息处理.E-mail:gtyqing@hotmail.com.
