石脑油裂解产物分布支持向量机模型的建立
2017-09-18张利军王国清
张利军,王国清
(中国石化 北京化工研究院,北京 1 0 0 0 1 3)
石脑油裂解产物分布支持向量机模型的建立
张利军,王国清
(中国石化 北京化工研究院,北京 1 0 0 0 1 3)
选择工业上常用的石脑油物性参数和对裂解产物分布影响较大的裂解工艺参数等16个参数作为输入参数,以裂解产物分布中的24种产物收率作为输出结果,通过支持向量机(SVM)回归建立了石脑油裂解反应的经验模型。经过训练样本训练获得预测模型,比较模型的预测结果与预测样本,模型的预测结果与实验数据基本相符。采用SVM模型对工业裂解炉进行预测并与实际工业数据进行对比,模型预测结果与工业数据基本相符,偏差小于5%。模型能够用于裂解炉的优化控制。
石脑油;支持向量机;裂解反应;模型
在乙烯工业生产中,工艺流程的模拟及优化逐渐成为一种有效提高乙烯产量与企业效益的重要辅助手段,对裂解炉的模拟是整个流程模拟中最重要的部分,而裂解反应动力学模型则是整个裂解炉模拟的核心[1-2]。因此,裂解反应模型成为研究的重点。
经验模型是裂解反应模型的重要类型之一,经验模型发展初期,往往是以少数几种原料或工艺参数与乙烯、丙烯收率等关联,这种建立模型的方法简单实用但适应性较差。近年来,随着数学和计算机技术的发展,更多的研究者利用神经网络等新技术建立模型,能够关联更多的输入参数和输出参数,同时能够利用工业数据进行模型的学习和校正,使得这类模型在自动控制及优化等方面重现了生机。
随着以非线性大规模并行分布处理为主流的神经网络技术的发展和应用,越来越多的研究者利用神经网络[3]、支持向量机(SVM)[4]等技术对裂解反应模型进行研究和改进,王国清等[5]应用BP神经网络对石脑油裂解产物收率进行模拟,该模型以大量的实验数据为基础,通过模型的学习和训练,预测值与实验值的误差仅为5%。与通常的回归模型相比,该模型计算精度略高,但如果超出模型的学习和训练范围,模型的预测值与实验值差距较大。黄一俞等[6]同样应用神经网络将工业裂解炉的进料量、稀释比、入口温度、出口温度、燃料气流量、烟气横跨温度、烟气温度等与乙烯、丙烯收率进行关联,计算结果与工业实际基本符合。
随着统计学理论的发展,在小样本情况下建立经验模型成为可能。王清江等[7]在乙烯装置生产经营数据的基础上,采用SVM方法建立了模型,实现了生产计划、调度的优化,提高了生产经营计划的准确性。陈贵华等[8]采用最小二乘SVM(LSSVM)方法将裂解原料、工艺参数与裂解深度进行关联,得到了裂解深度的模型,与实际工业基本相符。刘佳等[9]采用PSO-LS-SVM(PSO为微粒群算法)方法对裂解炉乙烯收率进行了建模,得到了与实际相符的模型。上述模型均仅对裂解炉的某个参数或某几个参数进行建模,并非完整的裂解产物分布模型,
本文工作利用SVM方法建立裂解产物分布模型,通过有限的实验数据进行模型训练,并在工业试验中得到验证。
1 模型的建立
1.1 SVM方法介绍
SVM方法建立在统计学习的VC维理论和结构风险最小原理的基础上,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折衷,以期获得最好的推广能力。
SVM是Cortes和Vapnik于1995年首先提出的[10],它在解决小样本、非线性及高维模式识别中表现出许多特有的优势[11-14]。首先,它是专门针对有限样本情况的,目标是得到现有信息下的最优解而不仅仅是样本数趋于无穷大时的最优值;其次,算法最终将转化成为一个二次型寻优问题,从理论上,得到的将是全局最优点,解决了在神经网络方法中无法避免的局部极值问题;最后,算法将实际问题通过非线性变换转换到高维的特征空间,在高维空间中构造线性判别函数来实现原空间中的非线性判别函数,特殊性质能保证机器有较好的推广能力,同时巧妙地解决了维数问题,它的算法复杂度与样本维数无关。
目前,SVM算法在模式识别、回归估计、概率密度函数估计等方面都有应用。在裂解反应模型中采用SVM算法,主要是基于小样本情况下的训练模型能较好推广到更大的范围内应用而不至于失真。
1.2 模型参数分类
采用SVM方法建立石油烃热裂解反应模型首先需要对模型的输入输出进行定义和分类,通常模型的输入参数分为两类:裂解原料的物性参数和裂解炉的工艺参数,将工业上常用的这两类参数经过筛选和简化后可作为输入参数;输出参数则是希望通过模型得到的数据,通常裂解产物收率是最希望得到的,因此将24种裂解产物收率作为模型的输出参数。
目前工业上对石脑油日常分析的项目通常为石脑油密度(20 ℃)、ASTM馏程(初馏点(IBP)、10%馏点、30%馏点、50%馏点、70%馏点、90%馏点、终馏点(EP))、族组成(正构烷烃含量(NP)、异构烷烃含量(IP)、烯烃含量(O)、环烷烃含量(N)、芳烃含量(A))。为了便于裂解反应动力学模型的工业应用,按照烯烃厂日常分析项目的内容重新组建了石脑油样本,即石脑油物性为密度(20 ℃)、ASTM馏程(IBP、10%、30%、50%、70%、90%、EP)、族组成(NP、IP、N、A),族组成中O一般低于1%(w),且与NP、IP、N、A归一,因此舍弃O这一物性参数,因此,模型共选原料物性参数12个。工业上,一般对裂解产物产生影响显著又能够调节控制的工艺条件包括辐射段出口温度(COT)、辐射段出口压力(COP)、水油比、停留时间,因此,选用这4个工艺参数作为输入参数。综上所述,模型共选用16个输入参数,包括12个物性参数和4个工艺参数。
有了输入和输出参数后,建立完整的SVM模型还需要有适量的样本数据,样本数据可分为两部分:大部分作为训练样本,剩余部分则作为预测样本。将训练样本数据输入SVM程序数据库中,然后调用训练程序,待训练结束后自动生成石脑油热裂解反应动力学模型;将预测样本的石脑油物性和工艺条件输入预测程序中,可以计算出该石脑油在此工艺条件下的裂解产物收率。将预测样本的计算结果与实验值进行比较分析,可以对预测模块的性能进行测试。
1.3 模型训练
基于SVM的回归分析原理编制了模型程序,包括三个部分:数据库、训练程序、预测程序。数据库里保存训练样本的数据,为训练程序提供基础数据;训练程序将自动读取数据库提供的数据进行学习训练,对训练样本的规律进行模式识别,最终将其归纳进模型并将该模型信息保存在相应的文件中;预测程序是将石脑油物性和工艺条件变量输入模型中,根据输入的变量进行计算并输出计算结果。将石脑油训练样本输入SVM程序的数据库中,然后调用训练程序对其进行训练,训练完毕后调用预测程序对预测样本数据进行预测。SVM回归的基本原理如下:
对于输入参数向量x(在此为16维的油品物性及工艺参数),寻找一个线性的超平面,对训练数据进行最佳预测:

训练求解的目标函数及约束如下:
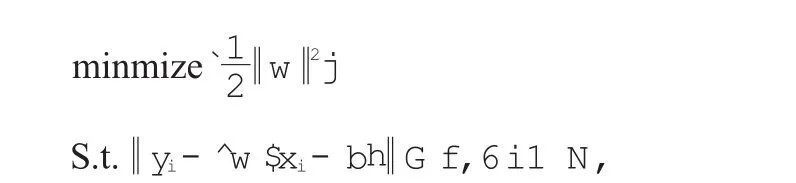
式中,w是法向量;b是超平面截矩;yi是训练中的输出结果向量;i是训练样本标号;N表示训练样本个数。在求解后,w以l个支撑向量xj的线性组合表示,组合因子为αj,式(1)改写为:
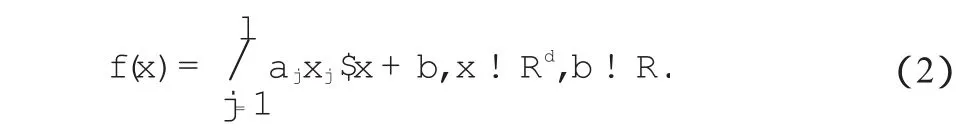
对于非线性的数据,SVM采用核函数的方法将其在高维空间内线性化,然后进行预测,公式如下:
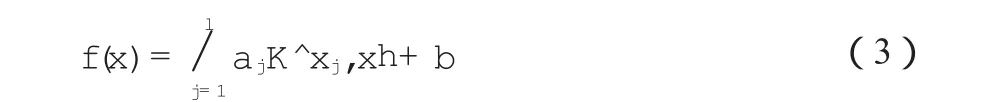
式中,K(·)表示核函数,可以选择线性、多项式、径向基等多种形式。由于径向基核函数能够较好地将非线性数据映射为线性数据,本工作选择了径向基核函数:

训练获得SVM回归模型后,预测程序在CPU为2.8 G、内存为2 G的计算机上运行时,能够在1.0 s的时间内给出模型的预测结果,计算速度快,符合裂解炉控制模型计算速度的要求。
2 实验部分
2.1 实验装置
根据建立反应模型的需要,搭建了裂解反应实验装置,如图1所示。油品经天平称重后由泵打入预热炉进行预热,蒸汽经天平称重后由泵打入经过预热的油品中,混合后进入裂解反应的核心区——炉膛。裂解反应炉膛采用电加热双面辐射,多程耐高温的Cr25Ni20炉管垂直悬挂于炉膛中央。油品经裂解反应后进入急冷器迅速降温,而后依次通过水冷罐和冰冷罐,裂解液相产品冷却下来,裂解气相产品则经过缓冲瓶和取样后由湿式流量计计量进入后处理系统。
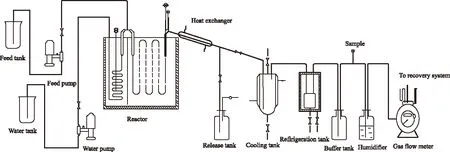
图1 裂解反应实验装置Fig.1 The flowchart of the experimental furnace.
2.2 实验方案
样本采集了16种石脑油热裂解的试验数据。石脑油试样中,密度(20 ℃)最大的为0.74 g/cm3,最小的为0.66 g/cm3。根据所选工艺参数和物性参数,对较宽范围内的各参数进行实验,利采用正交设计,共进行了16种石脑油的342次裂解实验。模型部分输入参数的实验范围见表1。
2.3 实验数据
经多次试验后,得到了三百余条实验数据作为模型建立的样本数据。部分数据见表2。
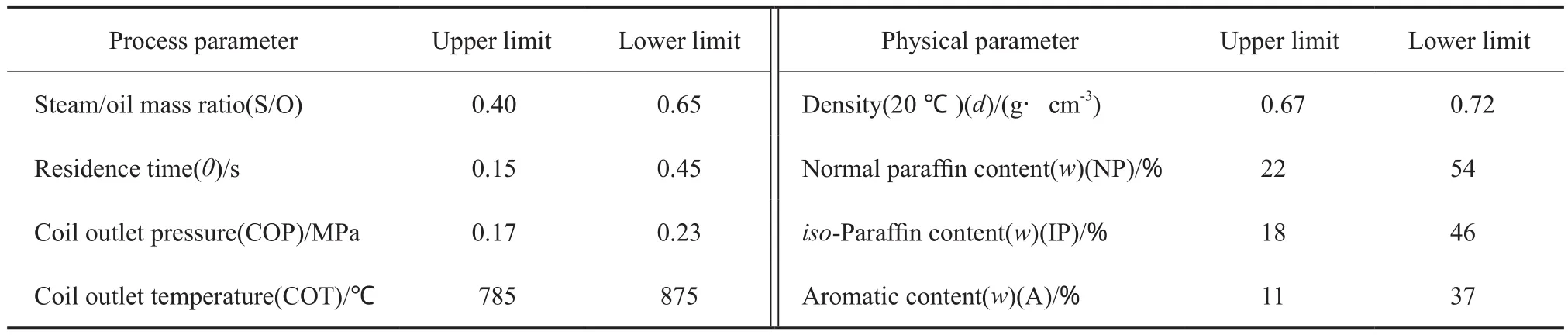
表1 模型部分输入参数的实验范围Table 1 The range of input data of the model
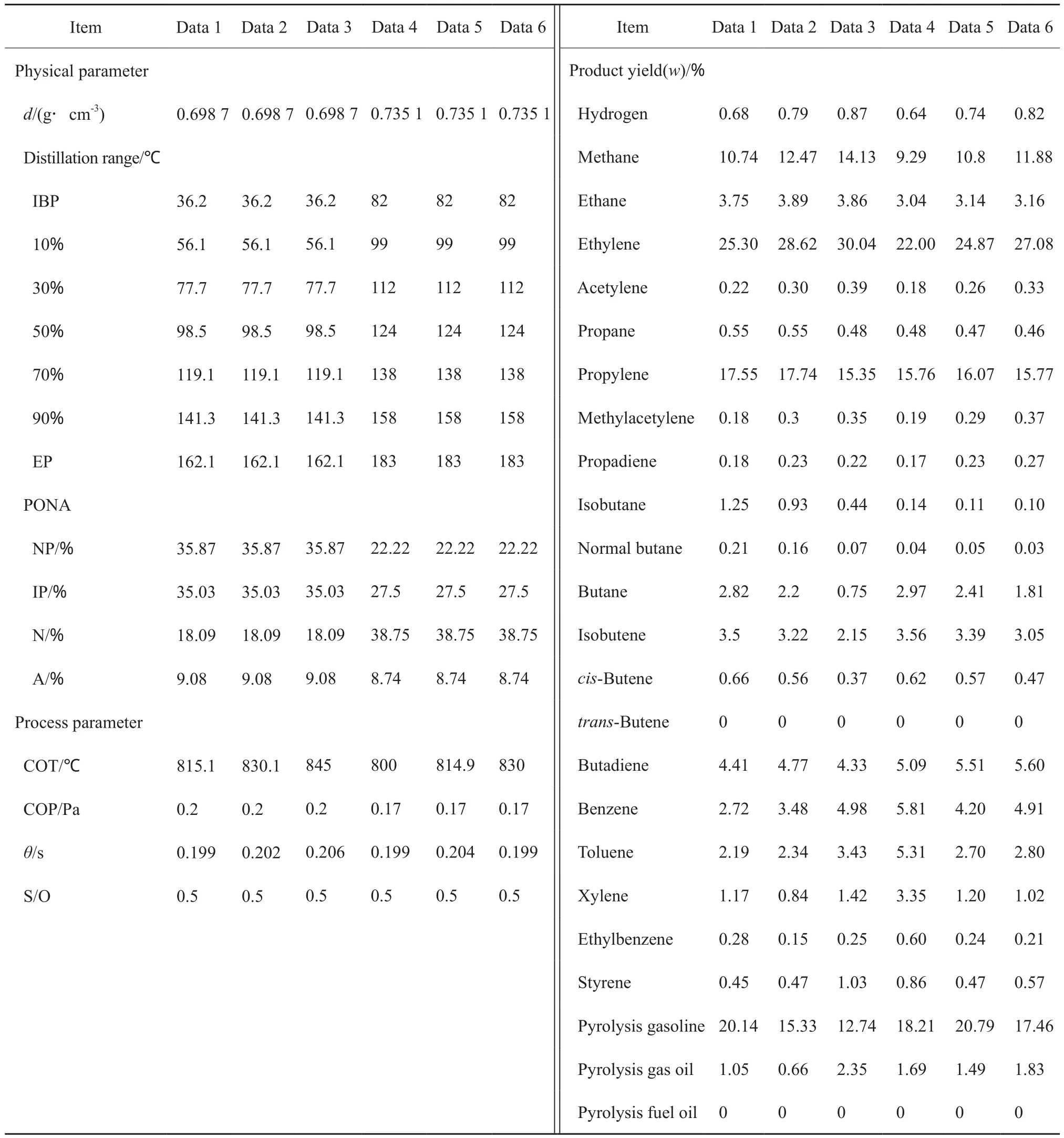
表2 部分石脑油裂解的实验数据Table 2 Partial data of naphtha cracking in lab
3 结果与讨论
3.1 模型评估
模型建立完成后,利用SVM模型按照预测样本的输入参数进行预测,结果如表3和图2所示,预测结果给出了24种裂解产物中较重要的5种,分别是氢气、甲烷、乙烯、丙烯及丁二烯。从表3可看出,预测结果与样本数据基本相符,相对误差基本在5%以下。从图2可看出,样本数据与预测数据的数据点基本落在对角线附近,表明SVM模型预测的结果是可靠的,与实际数据相符。
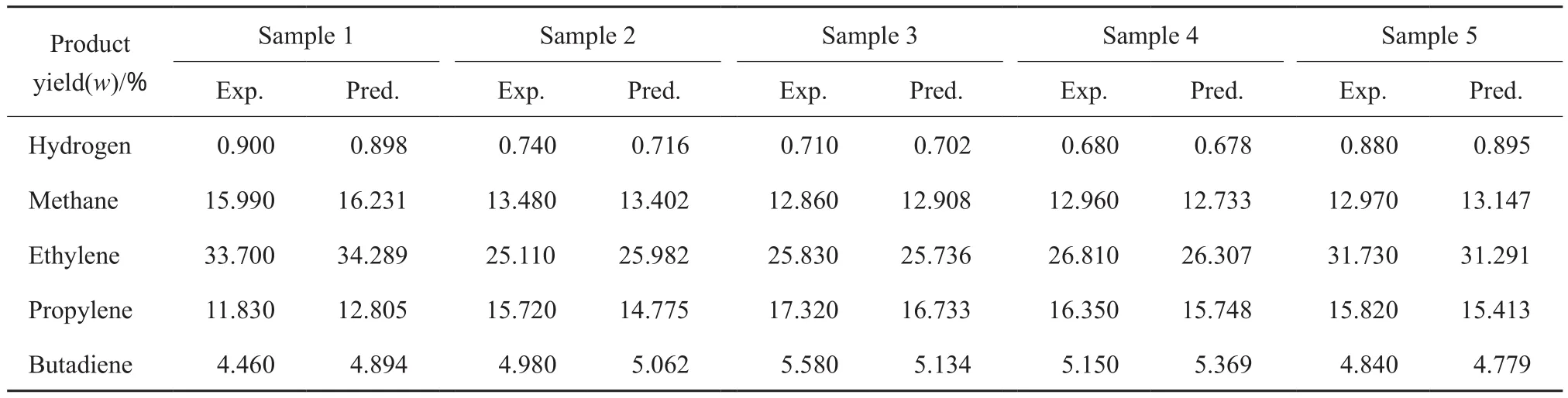
表3 样本数据和SVM模型的预测数据Table 3 Experimental data and predicted data of SVM model
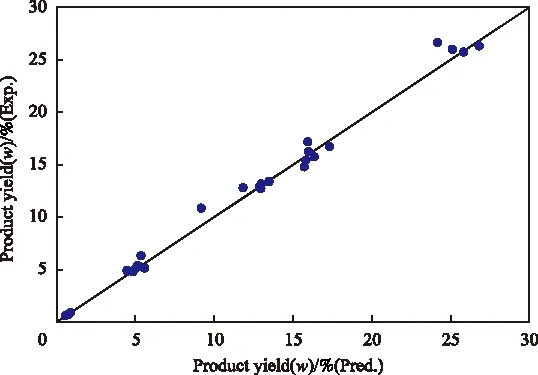
图2 样本数据与SVM预测数据的比较Fig.2 Correlation between the predicted data of SVM model and experimental data.
3.2 模型应用
SVM裂解反应模型建立完成后,对其进行了实际应用,对工业裂解炉进行预测并与实际工业数据进行了对比,结果见表4和图3。图3中的数据点几乎在对角线附近,可以看出SVM模型的预测结果能够与工业数据很好地吻合,偏差小于5%,能够用于工业裂解炉的模拟。
图4为SVM模型的预测数据和工业数据随裂解温度的变化趋势。从图4可看出,模型预测数据随COT的变化趋势与工业实际结果基本一致,表明模型能够用于工业实际过程的优化控制。

表4 SVM预测数据与工业数据的比较Table 4 Comparison between predicted data and industrial data
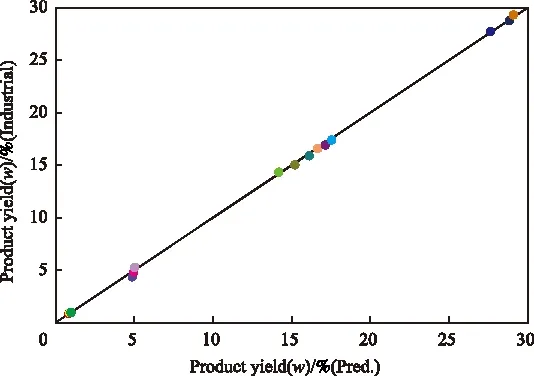
图3 工业数据与SVM预测数据的比较Fig.3 Comparison between the predicted data and industrial data.
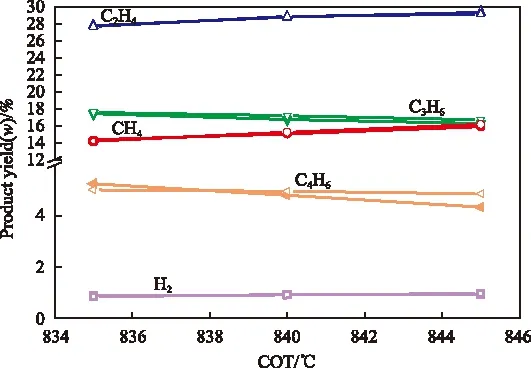
图4 裂解产物分布随COT的变化Fig.4 Effect of COT on the product profile.
4 结论
1)利用实验室样本数据建立了石脑油的SVM预测模型,模型的输入参数包括石脑油的物性参数和裂解工艺参数共16个,输出结果为24种裂解产物收率。从预测样本与预测结果的比较可看出,经过样本训练的模型的预测结果与实验数据基本相符。
2)模型的预测结果与工业数据基本相符,偏差小于5%;模型预测的裂解产物分布随工艺参数的变化趋势与工业数据基本相符,建立的SVM预测模型能用于裂解产物收率的预测、裂解炉优化控制等实际问题中。
符 号 说 明


[1] 赵岩,何小荣,邱彤,等. 乙烯热裂解炉模拟平台的开发及应用[J].计算机与应用化学,2006,23(11):1065-1068.
[2] 张利军,张永刚,王国清. 石脑油裂解反应模型研究及应用进展[J].化工进展,2010,29(8):1411-1417.
[3] 段向军,朱跃,陈乾伟. 新型神经模糊系统及其在乙烯裂解炉建模中的应用[J].石油化工自动化,2007,36(7):699-704.
[4] 王艳芳. 探究支持向量机算法在化学化工中的应用[J].当代化工,2014,43(9):1850-1855.
[5] 王国清,杜志国,张利军,等. 应用BP神经网络预测石脑油热裂解产物收率[J].石油化工,2007,36(1):39-41.
[6] 黄一俞. 乙烯裂解炉过程建模与操作优化[D].北京:北京化工大学,2005.
[7] 王清江,凌泽济,雷向欣. 采用支持向量机实现烯烃裂解料优化选择[J].上海化工,2012,37(11):13-17.
[8] 陈贵华,王昕,王振雷,等. 基于模糊核聚类的乙烯裂解深度DE-LSSVM多模型建模[J].化工学报,2012,63(6):1790-1796.
[9] 刘佳,邵诚,朱理. 基于迁移学习工况划分的裂解炉收率PSO-LS-SVM建模[J].化工学报,2016,67(5):1982-1988.
[10] Vapnik V. The nature of statistical learning theory[M].New York:Springer,1995:244-257.
[11] David V,Sanchez A. Advanced support vector machines and kernel method[J].Neurocomputing,2003,55(1):5-20.
[12] 田盛丰,黄厚宽. 回归型支持向量机的简化算法[J].软件学报,2002,13(6):1169-1172.
[13] 刘江华,程君实,陈佳品. 支持向量机训练算法综述[J].信息与控制,2002,31(1):45-50.
[14] 陶卿,曹进得,孙德敏. 基于支持向量机分类的回归方法[J].软件学报,2002,13(5):1024-1028.
(编辑 王 萍)
Modeling of steam cracking of naphtha by SVM
Zhang Lijun,Wang Guoqing
(Sinopec Beijing Research Institute of Chemical Industry,Beijing 100013,China)
Selection of commonly used industrial naphtha properties and process parameters as 16 input parameters,with 24 kinds of pyrolysis product yields as results,the support vector machine(SVM) model of regression was established for naphtha thermal cracking. The training samples are trained to obtain the prediction model;the prediction results and prediction samples of the model are compared. The prediction results of the model are roughly consistent with the experimental data. The industrial cracking furnace is predicted by SVM model and compared with the actual industrial data. The model predictions are roughly consistent with the industrial data,and the deviation is less than 5%. The model can be used for optimization control of cracking furnace.
naphtha;support vector machine;thermal cracking;model
10.3969/j.issn.1000-8144.2017.08.011
1000-8144(2017)08-1022-06
TQ 221.2
A
2017-04-07;[修改稿日期]2017-06-22。
张利军(1976—),男,河南省济源市人,博士,高级工程师,电话 010-59202725,电邮 zhanglj.bjhy@sinopec.com。
