基于Scrapy的分布式爬虫系统的设计与实现
2017-09-12李代祎谢丽艳钱慎一吴怀广
李代祎,谢丽艳,钱慎一,吴怀广*
(1.郑州轻工业学院 计算机与通信工程学院,河南 郑州 450002; 2.河南省工商行政管理学校,河南 郑州 450002)
基于Scrapy的分布式爬虫系统的设计与实现
李代祎1,谢丽艳2,钱慎一1,吴怀广1*
(1.郑州轻工业学院 计算机与通信工程学院,河南 郑州 450002; 2.河南省工商行政管理学校,河南 郑州 450002)
随着互联网的快速发展,其信息量和相关服务也随之快速增长.如何从海量的信息中快速、准确地抓取所需要的信息变得越来越重要,因此负责互联网信息收集工作的网络爬虫将面临着巨大的机遇和挑战.目前国内外一些大型搜索引擎只给用户提供不可制定的搜索服务,而单机的网络爬虫又难当重任,因此可定制性强、信息采集速度快和规模大的分布式网络爬虫便应运而生.通过对原有Scrapy框架的学习和研究,将Scrapy和Redis结合改进原有的爬虫框架,设计并实现了一个基于Scrapy框架下的分布式网络爬虫系统,然后将从安居客、58同城、搜房等网站抓取的二手房信息存入MongoDB中,便于对数据进行进一步的处理和分析.结果表明基于Scrapy框架下的分布式网络爬虫系统同单机网络爬虫系统相比效率更高且更稳定.
Scrapy;分布式;Scrapy-Reids;网络爬虫;MongoDB;数据存储
互联网中的信息量随着互联网的迅速发展而越来越多,在2008年Google公司宣布他们检索到的网页已经超过了1万亿,然而其检索到的网页仅仅是互联网上的一部分而已[1],如何从大量的信息中挖掘出有用的信息就成了当今的热门问题,搜索引擎也正是在这种需求下而诞生的技术.搜索引擎是通过网络爬虫从互联网中挖掘大量需求信息,然后网络爬虫将这些信息存储在数据库中,以便将来根据用户需求对其进行处理,它用到人工智能、信息检索、计算机网络、数据库、分布式处理、数据挖掘、机器学习和自然语言处理等多领域的理论技术,具有很强的综合性和挑战性[2-3].
目前国内外在网络爬虫领域已经有了很多研究,例如,爬行策略、海量数据存储、海量数据索引、网页评级等.但是较为成熟的大型网络爬虫只能为用户提供不可定制的搜索服务,且很多网络爬虫的技术都被列为商业机密,不对外开放.在开源爬虫方面,例如,Larbin、Nutch、heritrix等已经是比较成熟的网络爬虫项目,但是它们大多为单一网络爬虫,并且存在着性能不稳定、用户亲和性较低、对中文支持不足和配置复杂等问题[4-5].因此,部署方便、可定制性高的中小规模分布式网络爬虫取代传统的网络爬虫势不可挡.
1 分布式网络爬虫技术基础
1.1 网络爬虫
网络爬虫(Web Crawler)是一种按照一定规则在互联网上自动获取处理网页的计算机程序,其广泛地应用于互联网搜索引擎或网页缓存管理中[6].简单来讲,URL资源存放在一个队列中,此队列负责URL资源的优先级管理.首先网络爬虫从队列中获取一个 URL资源 并下载此网页,然后提取该网页中的其它URL 资源并放入队列中.重复上述过程,直到爬虫将其关闭[7-8].通用的网络爬虫结构如图1所示.
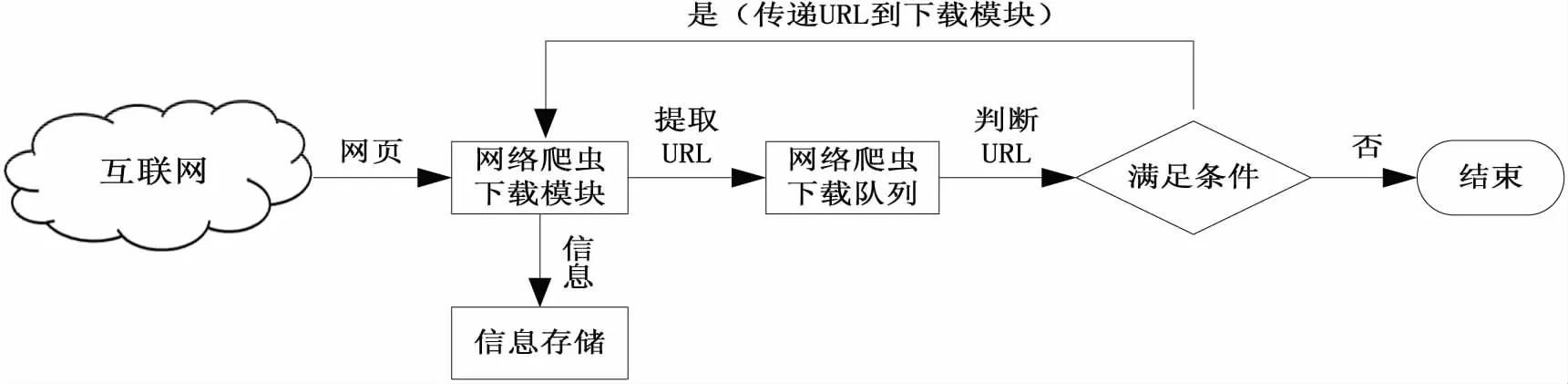
图1 通用的网络爬虫结构Fig.1 General web crawler architecture
网络爬虫通过不同爬行策略递归的访问页面、保存页面,最终获取所需信息.目前网络爬虫遵守以下4种爬行策略规则[9]:
1)选择爬行规则:使用广度优先的爬行策略.一个网络爬虫的目的是抓取互联网中最相关的网页,而不是随机的获取互联网的某些样本网页.
2)回访规则:互联网是动态的,互联网中网页的建立、修改和删除等活动在不断进行.然而一个爬虫活动可能持续和长时间,所以爬虫要制定回访规则来访问更新的网页.
3)礼貌规则:如果网络爬虫不断抓取同一台服务器上的网页,当请求过多时会造成服务器瘫痪.因此网络爬虫在正常运行的同时也要兼顾服务器的正常运行.
4)并行规则:网络爬虫可以通过多线程并发地运行多个爬行进程,通过这样可以极大的降低开销和提高下载效率.
1.2 Scrapy-Redis
Scrapy-Redis[10]是基于Redis的Scrapy分布式组件,其将任务和数据信息的存取放到redis queue中,使多台服务器可以同时执行crawl和items process,从而大大提高了数据爬取和处理的效率.其功能为:①多个爬虫共享一个redis queue 队列,适合大范围、多域名的爬虫集群.②爬取的items存放到items redis queue队列,可以开启多个items process来处理爬取的数据.Scrapy-Redis各个组件之间的关系如图2所示.

图2 Scrapy框架图Fig.2 Scrapy frame diagram
1.3 数据存储NoSQL
由于网络爬虫爬取的数据大多为半结构化或非结构化的数据,并且传统的关系型数据库并不擅长存储和处理此类数据.因此选择非关系型数据库 NoSQL 存储爬取到的数据.
NoSQL 数据库大致分为4类[11]:
1)键值(Key-Value)存储数据库:Key-Value模型对于IT系统来说的优势在于简单、易部署.例如:Tokyo Cabinet/Tyrant,Redis,Voldemort,Oracle BDB.
2)列存储数据库:此类数据库通常是针对海量的数据实施分布式存储.键仍然存在且指向了多个列.如:Cassandra,HBase,Riak.
3)文档型数据库:此类型的数据模型使版本化和半结构化的文档以特定的格式存储,例如,JSON.文档型数据库的查询效率比较高,如:CouchDB,MongoDb,SequoiaDB.
4)图形(Graph)数据库:图形结构的数据库是使用灵活的图形模型,并且该模型能够扩展到多个服务器上.如:Neo4J,InfoGrid,Infinite Graph.
2 分布式网络爬虫的研究与设计
2.1 Scrapy框架研究
2.1.1 Scrapy框架 如图2所示,Scrapy 框架的模块组成有[12-14]:
1)Scrapy引擎(Scrapy Engine):负责调控数据在系统中各个模块间传递,以及调用相应的函数响应特定的事件.
2)调度器模块(Scheduler):负责对所有待爬取的 URL资源进行统一管理.例如,将接收 Scrapy 引擎提交的URL资源插入到请求队列中;将URL从队列中取出并发送给Scrapy引擎以响应Scrapy引擎发出的URL 请求.
3)下载器中间件模块(Downloader Middlewares):负责传递Scrapy引擎发送给下载器模块的URL请求和下载器模块发送给 Scrapy 引擎的HTTP 响应.
a)下载器模块(Downloader):负责下载Web 页面上的数据,并最终通过Scrapy 引擎将其发送给爬虫模块.
b)爬虫模块(Spider):分析从下载器模块获取到的数据,然后提取出Item 或得到相关的URL资源.
c)爬虫中间件模块(Spider Middlewares):负责处理爬虫模块的输入和输出.
d)数据流水线模块(Item Pipeline):通过数据清理、数据验证、数据持久化等操作来处理由爬虫模块提取和发送过来的Item.
2.1.2 Scrapy框架扩展 Scrapy框架简单、高效,且被广泛应用于数据的挖掘、监测和自动测试.但是Scrapy框架也存在不足,例如,Scrapy框架下的爬虫不支持分布式、单线程执行、内存消耗过大等.因此深入理解Scrapy框架的扩展机制,通过编程来替换或增加框架中的一些模块来弥补其不足是十分必要的.本文对Scrapy框架做了如下补充:
1)本文利用Scrapy-Redis通过redis对爬取的请求进行存储和调度,并对爬取产生的项目(items)存储以供后续处理使用.Scrapy-Redis的组件如下[15-16].
a)Connection.py:对settings进行配置,实现通过Python访问redis数据库,被dupefilter和scheduler调用,涉及到redis存取的都要使用到这个模块.
b)dupefilter.py:使用redis的set数据结构对reqeust进行去重处理.
c)queue.py:将request存入到queue中,调度时再将其弹出.目前队列的调度有三种方式:FIFO(先入先出)的SpaiderQueue,SpiderPriorityQueue和LIFO(后入先出)的SpiderStack.本文用的是第二种方式.
d)pipelines.py:将Item存储在redis中以实现分布式处理.

图3 Scrapy-Redis组件之间的关系Fig.3 Relationship between Scrapy-Redis components
e)scheduler.py:重写scrapy中的调度模块,实现crawler的分布式调度.
f)spider.py:重写scrapy中的爬虫模块,从redis数据库的队列中读取要爬取的url,然后执行爬取.若爬取过程中有其它的url返回,继续执行爬虫直到所有的request完成后,再从队列中读取url,循环上述过程.
通过分析可得,Scrapy-Redis各个组件之间的关系如图3所示.
2)单机硬盘与内存容量有限、数据的频繁查询是造成了CPU性能的严重下降的主要原因,因此数据库的选择显的尤为重要.由于网络爬虫爬取的数据大多数为非结构化的数据,因此本文选取擅长存取非结构化数据的数据库MongoDB[17-18].经过扩展后的Scrapy框架如图4所示.
2.2 反爬虫技术应对策略
目前很多网站禁止爬虫爬取数据,网站通过用户请求的Headers、用户行为、网站目录和数据加载等方式来进行反爬虫,从而增大爬取的难度.本爬虫主要采取了以下应对策略:
1)设置download_delay参数. 如果下载等待时间过长,则短时间大规模抓取数据的任务将不能完成,而太短则会增加被禁止爬取数据的概率.因此在settings.py中设置:DOWNLOAD_DELAY = 2.
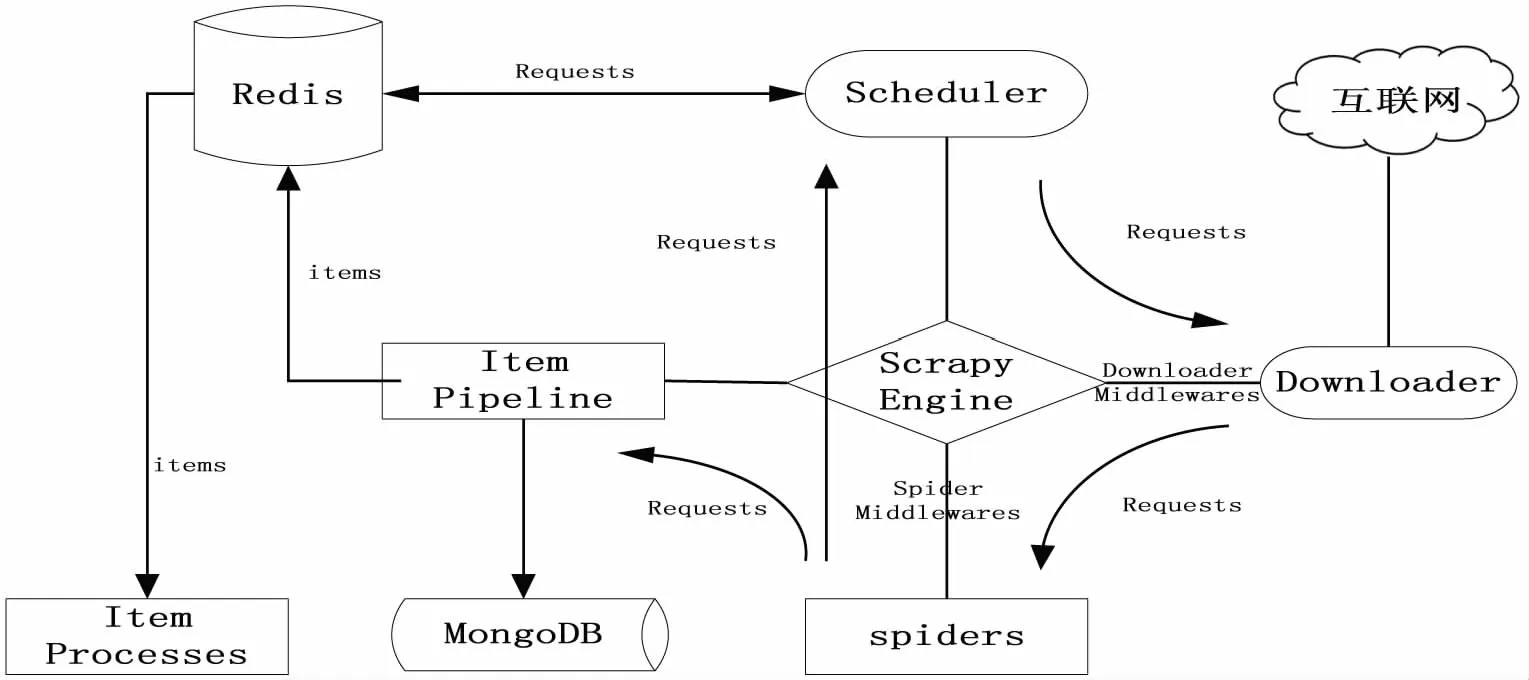
图4 扩展后的Scrapy框架Fig.4 The extended Scrapy framework
2)禁用cookies,可以防止爬虫行为被使用cookies识别爬虫轨迹的网站所察觉,因此需要在settings.py 中设置:
COOKIES_ENABLES=False.
3)伪装user agent,防止被服务器识别,将user agent 写入rotate_useragent.py文件里形成user-agent池,在发送请求时会从user-agent池中随机选取一个使用.因此需要在settings.py中设置:
DOWNLOADER_MIDDLEWARES={′scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware′ :None,′
HouseInfoSpider.spiders.rotate_useragent.RotateUserAgentMiddleware′ :400,}
2.3 数据爬取与存储
2.3.1 网页结构和数据分析 通过对网页HTML结构进行分析,从而完成爬虫模块的编写.本爬虫的URL队列中有3种类型的URL,以安居客的网页结构为例进行分析.该网页中所包含数据的节点是class=”houselist-mod”的
- 节点,该节点下的
- 节点有50个,每个
- 节点中包含有需要提取的目标数据,即index类型的URL.Scrapy提取数据使用特定的 XPath 表达式来提取 HTML 网页中的数据,伪代码如下所示:
def parse_detail(self,response):
item = HouseInfoItem()
selector = scrapy.Selector(response)
item[′url′] = response.url
item[′village_title′]= #标题
list_first_item(selector.xpath(′//h3[@class ="long-title"][1]/text()′).extract()).strip() }
(……)
item[′village_describe′]= #描述
list_first_item(selector.xpath(′//div[@class="houseInfoV2-item-descjs-house-explain"]/text()′).extract()).replace(" ","").replace(" ","").replace("","").strip()
yield item
从网站上获得数据followers、fullname等在Item中统一建模.相应代码在items.py中:
import scrapy
class HouseInfoItem(scrapy.Item):
url=scrapy.Field() #当前网页的url
village_name=scrapy.Field() #小区名
village_location=scrapy.Field() #位置
village_area=scrapy.Field() #面积
(……)
2.3.2 数据库连接和参数设置 在settings.py文件中设置MongoDB的相应参数:服务器、端口号、数据库,然后在指定的位置添加数据库设置:
#MongoDB
MONGO_URI=′mongodb://127.0.0.1:27017′
MONGO_DATABASE = ′HouseInfo′
#改变默认PIPELNES
ITEM_PIPELINES={′HouseInfoSpider.pipelines.MongoPipeline′:300,′scrapy_redis.pipelines.RedisPipeline′:400,}
在pipelines.py文件中定义一个函数连接数据库:
#数据库初始化
Class MongoDBPipeline(object):
hp_collection_name = ′house_info′
def_inir_(sef,mongo_uri,mongo_db)
(……)
#数据库连接
def open_spider(self,spider):
self.client=pymongo.MongoClient
(self.mongo_uri)
self.db = self.client[self.mongo_db]
#将数据存入到数据库中
def process_item(self,item,spider):
if isinstance(item,HouseInfoItem):
key_index = item[′url′]
if not self.db[self.hp_collection_name] .find({′url′:key_index}).count():
self.db[self.hp_collection_name].insert(dict(item))
return item
3 实验结果分析
3.1 实验结果
Ipush.py文件中将要爬取的原始网站url存入redis数据库的队列中,然后通过scrapy crawlall命令执行爬虫,最后将爬取的数据存入MongoDB中.爬取结果显示如图5所示.

图5 MongoDB中的数据Fig.5 Data in MongoDB
3.2 结果分析
整个系统的部署:1台安装有redis和MongoDB数据库的服务器作为爬虫的主节点;1台安装有MongoDB数据库的服务器作为爬虫从节点;1台安装有MongoDB数据库的单独服务器.硬件配置如表1所示.

表1 硬件配置
实验测试中,为了防止爬虫行为被禁止,将最高爬取频率设置为2秒/网页,系统运行5个小时(单机爬取和分布式爬取选在同一时段),其爬取结果如表2所示.
通过分析表2中的数据可知,每个节点每小时爬取的网页数量在1 700左右.为了防止爬虫被禁止,爬虫的最高频率设置为2秒/网页.由于受网络延迟、I/O延迟等的限制,每小时爬取的网页数量略低于理论上最高值1 800(60*60/2=1 800).另外,2个爬虫节点每小时爬取url的数量几乎接近1∶1,这也证明了系统中各个爬虫节点的负载均衡.同时运行结果也表明,经过扩展的Scrapy框架使得爬取速度大大提高了.

表2 爬取结果
根据表2中数据,利用Matlab可得到图6的线形图.

图6 分布式网络爬虫测试Fig.6 Distributed web crawler testing
图6中每条线的斜率就代表其爬虫的爬取效率.从图6中可以看出一个节点进行爬取时的效率要远远低于两个节点同时爬取时的效率.综上所述分布式爬虫爬取的效率远高于单机爬虫.
4 结束语
本文通过对开源网络爬虫Scrapy框架的深入研究和扩展,利用Scrapy-redis组件之间的相互作用,设计和实现了一个分布式的网络爬虫系统;通过与数据库的连接,将爬取的数据存入MongoDB中,便于对数据进行查询、统计和分析;同时在技术上也为数据研究人员提供了方便的数据获取方法. 但是本文只对URL进行了去重处理,并没有考虑节点爬取的负载均衡问题,同时爬取过程中网页被重置问题目前也没有好的解决办法,这些问题需要进一步的探索研究.
[1] VLADISLAV Shkapenyuk,TORSTEN Suel.Desigen and Imlementation of a High-Performance Distributed Web Crawler.Technical Report,In Proceedings of the 18th International conference on Data Engineering(ICDE)[C]∥IEEE CS Press,2001:357-368.
[2] 薛丽敏,吴琦,李骏.面向专用信息获取的用户定制主题网络爬虫技术研究[J].信息网络安全,2017(2):28-31.
[3] 王素华.基于网络爬虫技术的学生信息收集方法[J].电脑迷,2016(3):89-92.
[4] HANS Bjerkander,ERIK Karlsson.Distributed Web-Crawler[D].Master Thesis Chalmers University of Technology,2013:1-2.
[5] 郭涛,黄铭钧.社区网络爬虫的设计与实现[J].智能计算机与应用,2012(4):78-92.
[6] 董日壮,郭曙超.网络爬虫的设计与实现[J].电脑知识与技术,2014(17):201-205.
[7] JUNGHOO Cho,HECTOR Garcia-Molina.Parallel crawlers[C]∥Of the 11th International World-Wide Web Conference,2002:32-35.
[8] 李勇,韩亮.主题搜索引擎中网络爬虫的搜索策略研究[J].计算机工程与科学,2008(3):42-45.
[9] 黄聪,李格人,罗楚.大数据时代下爬虫技术的兴起 [J].计算机光盘软件与应用,2013(17):79-80.
[10] 赵鹏程.分布式书籍网络爬虫系统的设计与现[D].成都:西南交通大学,2014.
[11] MOHR G,STACK M,RNITOVIC I,et al.Introduction to heritrix [C]∥4th International Web Archiving Workshop,2004:109-115.
[12] CATTELL R.Scalable SQL and NoSQL data store [J].ACM SIGMOD Record,2011(2):12-27.
[13] 刘学.分布式多媒体网络爬行系统的设计与实现 [D].武汉:华中科技大学,2012:10-25.
[14] 李贤芳.面向作战系统应用的数据分发中间的研究与设计[D].南京:南京理工大学,2013.
[15] THELWALl M.A web crawler design for data mining[J].Journal of Information Science,2001,27(5):319-325.
[16] 徐亦璐.基于多线程的网络爬虫设计与实现[J].计算机光盘软件与应用,2011(2):152-152.
[17] 王劲东.基于高级数据加密标准 AES 的数据库加密技术研究与实现[D].西安:西安电子科技大学,2011.
[18] 雷德龙,郭殿升,陈崇成,等.基于MongoDB的矢量空间数据云存储与处理系统[J].地球信息科学学报,2014(4):65-67.
责任编辑:时 凌
Design and Implementation of Distributed Crawler System Based on Scrapy
LI Daiyi1,XIE Liyan2,QIAN Shenyi1,WU Huaiguang1*
(1.School of Computer and Communication Engineerring,Zhengzhou University of Light Industry,Zhengzhou 450002,China; 2.Henan School of Administration of Industry and Commerce,Zhengzhou 450002,China)
With the rapid growth of the Internet,the amount of information and related services are growing rapidly.How to capture the information from massive information quickly and accurately is becoming more and more important,so the network crawler is also facing great challenges and opportunities.At present,domestic and foreign large search engines can only provide non-customizable search services for users,and a single-machine web crawler cannot assume the difficult task.Therefore,the distributed web crawler with flexible customization,high information acquisition speed and large scale has come into being.In this paper,through the study of the original Scrapy framework,the original crawler framework is improved by combining Scrapy and Redis,and a distributed crawler system based on Web information Scrapy framework is designed and implemented.The second-hand housing information captured from www.anjuke.com,www.58.com and www.fang.com is stored in MongoDB,so that the data can be processed and analyzed.The results show that the distributed crawler system based on Scrapy framework is more efficient and stable than the single-machine web crawler system.
Scrapy;distributed;Scrapy-Reids;Web crawler;MongoDB;data storage
2017-05-24.
国家自然科学基金项目(61672470);河南省科技攻关项目(162102410076);河南省重大科技专项(161100110900).
李代祎(1988-),男,硕士生,主要从事计算机技术,数据挖掘,机器学习等的研究;*
吴怀广(1976-),男,博士,副教授,主要从事大数据、软件工程、形式化方法、空间移动计算等的研究.
1008-8423(2017)03-0317-06
10.13501/j.cnki.42-1569/n.2017.09.016
TP3
A
