一种路网环境中的轨迹隐私保护技术
2017-08-12霍峥王腾
霍 峥 王 腾
1(河北经贸大学信息技术学院 河北 石家庄 050061)2(中国电子科技集团第54研究所卫星导航系统与装备技术国家重点实验室 河北 石家庄 050000)
一种路网环境中的轨迹隐私保护技术
霍 峥1王 腾2
1(河北经贸大学信息技术学院 河北 石家庄 050061)2(中国电子科技集团第54研究所卫星导航系统与装备技术国家重点实验室 河北 石家庄 050000)
不经过隐私处理直接发布轨迹数据会导致移动对象的个人隐私泄露,传统的轨迹隐私保护技术用聚类的方法产生轨迹k-匿名集,只适用在自由空间环境,并不适用于道路网络环境中。针对上述问题设计了一种路网环境中的轨迹隐私保护方法,将路网环境中的轨迹模拟到无向图上,并将轨迹k-匿名问题归结到无向图的k-node划分问题上。证明了图的k-node划分是NP-完全问题,并提出贪心算法解决此问题。通过实验验证了该算法的匿名成功率平均接近60%,最高可达80%以上。
路网 轨迹 隐私保护 数据发布
0 引 言
随着移动定位技术的迅速发展,出现了大量的带有移动定位功能的设备,同时也产生了大量的位置数据,位置数据按采样时间排序形成了轨迹数据。针对轨迹数据的分析和挖掘可以支持多种与移动相关的应用[1-2]。然而,轨迹数据含有丰富的时空信息,针对轨迹数据的分析和挖掘可能导致轨迹数据中包含的个人私密信息泄露。随着各行各业对轨迹数据应用需求的增长,轨迹隐私保护技术已成为国内外的研究热点之一[3-5]。研究者们对自由空间中的轨迹隐私保护技术进行了研究,提出了多种基于聚类的轨迹k-匿名技术[6-8]。基于聚类的k-匿名技术不适用在路网空间中,且不能合理地分配匿名不成功的轨迹,从而增大了信息丢失。本文针对路网空间的特性,提出一种路网环境中的轨迹隐私保护技术,将轨迹及轨迹之间的关系模拟到无向图上,将轨迹k-匿名问题转化为轨迹图上的k-node划分问题。本文证明了k-node划分问题是NP-完全问题,设计了一个贪心算法实现了轨迹图的k-node划分,进而实现了轨迹k-匿名。与现有的轨迹隐私保护技术相比,该方法可以解决路网环境中的轨迹隐私保护问题,且该方法能够系统地解决轨迹k-匿名中删除的轨迹数量等问题,因此匿名成功率和数据可用性较高,本文通过实验对算法的可用性和算法效率进行了验证。
1 问题定义
1.1 预备知识
下面对轨迹等概念进行形式化定义。
定义1 (轨迹) 某个移动对象Op的轨迹是采样位置按照采样时间排序的序列,即T={(x1,y1,t1),(x2,y2,t2),…,(xn,yn,tn)},其中,(xi,yi)表示移动对象Op在ti时刻所处位置的坐标。
定义2 (同步轨迹) 两条轨迹Tp和Tq是同步轨迹,当且仅当这两条轨迹在同一采样时间都有采样位置。一组轨迹是同步的,则这组轨迹中的每两条轨迹都是同步的。若两条轨迹是同步轨迹,同一采样时间的采样位置称为“对应位置”。采用欧几里德距离来衡量轨迹之间的距离。
定义3 (轨迹距离) 给定两条同步轨迹Tp和Tq,其轨迹距离是其对应位置的欧几里德距离的平均值,计算如下:
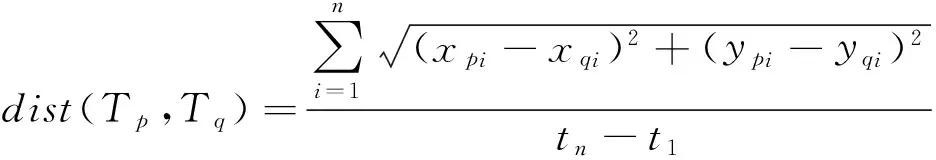
(1)
其中(xpi,ypi,ti)和(xqi,yqi,ti)分别表示轨迹Tp和Tq在ti时刻的采样位置。两条轨迹的采样位置从t1时刻开始,至tn时刻为止。
用(xs,ys,ts)和(xe,ye,te)分别表示一条轨迹的起始采样位置和终止采样位置。起始位置和终止位置在x坐标方向和y坐标方向上可分别表示为两个位置对(xs,xe)和(ys,ye)。如果两条轨迹在“时空上没有任何重叠”,没有必要计算这两条轨迹之间的距离,因为这样的两条轨迹几乎不可能被匿名在同一个匿名集中。所谓“时间重叠”是指这两条轨迹所跨越的时间有交叠,即轨迹T1的结束时间t1e晚于轨迹T2的开始时间t2s。而空间上的重叠用下述定义来描述。
定义4 (s-空间重叠) 给定两条同步轨迹Tp={(xp1,yp1,t1), (xp2,yp2,tp2), … , (xpn,ypn,tn)} 和Tq={(xq1,yq1,t1), (xq2,yq2,t2), … , (xqn,yqn,tn)} ,若Tp上至少存在一个采样位置(xi,yi) (i=1, 2, …,n), 满足xi∈ [xqs,xqe] 或yi∈ [yqs,yqe], 则称Tp和Tq之间有s-空间重叠, 其中,s(s>0)是Tp和Tq的重叠比例,由重叠采样位置数与整条轨迹的采样位置数的比值计算得出。
1.2 问题定义
在定义问题之前,先介绍在路网环境中可能遭遇的两种攻击模式。
• 背景知识攻击:移动对象通过背景知识暴露其所处的位置。比如,两个移动用户关于工作地点的谈话可能会暴露其中一个用户日常轨迹的终点或起点。假定攻击者通过背景知识知晓用户Op可能会在时刻ti时出现在位置Li,恰好ti是发布的轨迹数据库D*中,用户Op的轨迹上的某个采样位置,这时攻击者就可以根据这个信息从D*中识别出Op的整条轨迹。这种攻击模式称为背景知识攻击。
• 观察攻击:假定攻击者静止或者按预定策略运行进行观察攻击,假设观察过程中没有噪音数据。当攻击者发现Op出现后,观察Op至少一个采样周期以获得Op在采样时间时的确切位置。在最坏的情况下,如果Op是该时间段内唯一出现的移动对象,攻击者可以100%的在发布数据库D*中识别出Op的整条轨迹。如果同时有N个移动对象出现,且攻击者没有其他背景知识,那么识别出Op轨迹的概率下降为1/N,这种攻击模式称为观察攻击。当然,观察攻击者不仅仅指个人,还可能是各种各样的数据采集器,如商场中的摄像头、道路上的监控设备等。
轨迹k-匿名技术可以抵御上述两种攻击类型,轨迹-匿名是指将k条轨迹匿名在同一个匿名集中,最终发布的匿名集是各个采样时刻由k个用户共享的匿名区域。对于背景知识攻击来说,由于轨迹k-匿名将各个时刻的采样位置匿名为包含k个用户位置的匿名区域,攻击者没有办法将背景知识与一个区域中的多个位置连接起来。轨迹k-匿名对观察攻击同样有效:假定攻击者观察到Op在某个时刻出现在某个位置,攻击者还是无法从发布的k个用户的匿名轨迹中直接识别出Op的轨迹。
然而,把k条轨迹匿名会造成严重的信息丢失。因此,轨迹隐私保护技术的关键问题是:如何在保护轨迹隐私的前提下将信息丢失降到最低。本文提出一种方法将轨迹隐私保护问题归结到一个图的k-node划分问题上,该问题是一个NP-完全问题,本文提出一种贪心算法来构造轨迹k-匿名集。
定义5 (轨迹k-匿名) 给定移动对象数据库D,发布的轨迹数据库D*是D的匿名版本,需满足以下两个条件:
• 发布数据库D*中每条轨迹的采样位置都至少和其它k-1条轨迹匿名在同一个匿名集中。
• 发布数据库D*相对于原始数据库D的信息丢失最小。
轨迹k-匿名可以抵御上述两种攻击模式:对于发布数据库D*来说,即使攻击者知晓多少条轨迹匿名在同一个匿名集中以,其识别一条轨迹的概率小于1/k。
2 隐私保护算法
2.1 数据预处理
数据预处理阶段需要完成下述两个任务:轨迹起始及终止点识别、构建轨迹等价类。
轨迹起始及终止点识别:移动对象的一条完整的轨迹中可能包含多个长时间的停留。轨迹起始及终止点识别就是要识别哪些采样位置属于长时间停留,哪些采样位置是轨迹的终止位置。如果移动对象Op在某个采样位置的停留时间超过事先设定的阈值tht,就认为Op的轨迹在这个停留位置终止了,下一个采样位置成为Op的新轨迹的起始位置。
构建轨迹等价类:由于轨迹k-匿名仅仅能够将出现在相同时间段的轨迹匿名在同一个匿名集中。为了能够扩大同一个时间段内轨迹等价类中所含轨迹的数量,需要把起始时间在[tds1,tds2]范围内,及终止时间在[tde1,tde2]范围内的轨迹放入同一个等价类中。轨迹等价类的定义如下。
定义6 (轨迹等价类) 轨迹等价类由起始及终止时间在相近时间段的轨迹构成。两条轨迹Tp和Tq在同一个等价类中,当且仅当Tp.ts,Tq.ts∈[tds1,tds2]且Tp.te,Tq.te∈[tde1,tde2]。
2.2 轨迹图构建
本节首先介绍轨迹图的定义,然后介绍轨迹图的构建过程。
定义7 (轨迹图) 轨迹图TG=(V,E)是一个带权无向图,其中,顶点集V表示轨迹,两个顶点之间有边,当且仅当两条轨迹Tp和Tq之间有s-重叠。边(Tp,Tq)的权值是轨迹Tp和Tq之间的距离。
对轨迹等价类EC构造轨迹图TG=(V,E)的过程如下所述:初始时轨迹图的边集为空,顶点集为轨迹等价类中任意一条轨迹T1,未被加入到轨迹图中的轨迹放入集合Vleft中。然后,检查Vleft中的每条轨迹是否和V中的轨迹有s-重叠。如果两条轨迹Ti和Tj之间有s-重叠,则计算两条轨迹之间的距离作为这两条轨迹之间的边的权值,并将这条轨迹从Vleft移动到V中。如果没有s-重叠,仅把这条轨迹移动到V中,不需要计算轨迹距离。由于多数轨迹之间并不存在s-重叠关系,因此轨迹图极可能是由多个连通分量构成的非连通图。如果两条轨迹之间没有s-重叠,也不需要计算轨迹距离,节省了计算资源。
2.3 轨迹匿名
为了控制每个轨迹匿名集中的轨迹数量,系统的对匿名失败的轨迹进行分配,文章把轨迹k-匿名问题归结到图划分问题上。通过对图中顶点的划分来构建轨迹匿名集。最理想的情况是:划分后的每个子图是一个包含k个顶点的连通分量,并且耗费最少。
2.3.1k-node划分
轨迹k-匿名所用到的k-node划分和k-way划分不同,其形式化定义如下:
定义8 (k-node划分) 关于轨迹图TG的一个k-node划分是指:将图TG划分为若干个连通分量V1,V2,…,Vi及D1,D2,…,Dh,满足如下条件:
•V1∪V2∪…Vi∪D1∪D2∪…∪Dh=TG;
• 对任意i,k≤|Vi|≤2k-1且|Di| •Vi∩Vj=φ;Di∩Dj=φ且Di∩Vj=φ; •Wi表示子图Ti的权值之和,且Wi的值最小,h尽可能小。 在k-node划分中,V1,V2,…,Vi构成了轨迹k-匿名集,每个轨迹k-匿名集中包含至少k个顶点,D1,D2,…,Dh表示要被删除的子图,因为上述子图中包含的顶点数都不够k个,达不到隐私保护参数k的需求。第4个条件表示匿名集中的权值之和应尽可能小,且被删除的子图数量应尽可能小。被删除子图可能是由下述三个原因产生的:第一种情况:TG是一个由几个连通分量构成的非连通图,如果某个连通分量的顶点数小于k,就无法被划分到其它子图中,因此被删除。第二种情况:TG中的连通分量包含的顶点数大于k,但是由于构成k-匿名集后删除一些顶点,连通分量中剩余的顶点数不足k;第三种情况:整个轨迹图TG是连通分量,若其顶点数n满足nmodk≠0,则构成几个轨迹k-匿名集后,剩下的轨迹就是多余的。 为了达到降低信息丢失的目的,需要对k-node划分做出如下两个限制:第一,对于每个划分好的子图,其权值之和ICost最小,称子图的权值之和为“内部信息丢失”;第二,删除的子图越少越好。 下面证明k-node划分是一个NP-完全问题。 定理1 k-node划分问题是一个NP-完全问题。 2.3.2 贪心算法 已经证明了k-node划分是NP-完全问题,本节就采用一种贪心方法找到轨迹图的一个k-node划分。 TG是一个有n个顶点的图,通过下述GreedyFindC算法可以将图TG进行k-node划分。对于TG中的每个连通分量,调用算法GreedyFindC,直到TG中没有任何连通分量的顶点数大于或等于k。算法中有两个子图集合,子图集合RS保存了所有可能构成轨迹k-匿名集的子图;子图DS保存了不足k个顶点的子图,需要被删除。在算法GreedyFindC中,采用一种贪心策略来划分TG。基本思想就是找到边权最小的边,将它作为子图的边,除非删除这条边会造成一个新的顶点数小于k的连通分量。算法从图中权值最小的边出发,这条边关联的两个顶点构成连通分量C,顶点入栈SC,和连通分量C相邻接的所有顶点放入集合X中。当连通分量C中的顶点数小于k时,每次找到和C相关联的,且边权最小的那条边加入新的连通分量,顶点放入C。当连通分量C中的顶点数达到k时,试着将C从连通分量Gi中删除。在删除之前,首先检查删除掉C之后是不是会构成新的顶点数小于k的连通分量,如果是,就尝试换一条边加入连通分量C,再次检查。检查完毕之后发现无论怎样都会产生新的顶点数小于k的连通分量,那么还是回到最初的那条边,然后从Gi中将C删除。GreedyFindC算法如下: 算法1 GreedyFindC(Gi, k) 输入:连通分量Gi=(V, E); 每个子图中含有顶点数k; 输出:含有k个顶点的子图C; 1: Token=0; X←∅; 2: 找到权值最小的边e=(vs, ve),将vs,ve放入C; 3: Push(SC, vs); Push(SC, ve);//SC是初始化为空的栈; 4: X←和子图C中的顶点相邻接的边x; 5: while |C| 6: if (X=∅) then 7: X←和子图C中的顶点相邻接的边x; 8: end if 9: 找到X中权值最小的边e=(vi, vj); Push(SC, vj); 10: X←和C中结点相邻接但不包含在C中的边; 11: if |C| =k and token =0 then 12: Gi←delete-detection (Gi, C); 13: if存在GSi∈Gi且|GSi| 14: C←SC中元素出栈后的剩余元素; 15: if X中仅包含(vs, ve) then 16: token=1; C← (vs, ve); 17: end if 18: else 19: Gi←Gi-C; return C; 20: end if 21: else if |C|>=k 且token=1 then 22: Gi←Gi-C; return C; 23: end if 24: end while 2.3.3 信息丢失衡量 (2) 信息丢失由两部分构成,一是将一个采样位置匿名为一个区域,导致数据可用性的下降;二是被删除的轨迹导致数据完全丢失。在上述公式中,Area(xj,yj,tj)表示采样位置(xj,yj,tj)对应的匿名区域面积大小,MaxArea表示整个地图的面积。如果轨迹Ti被删除,则其所有信息都丢失了,即所有采样位置都被丢失了。 3.1 实验设置 实验选取了合成数据和真实数据来衡量算法的可用性和效率。真实数据集名为TRUCKS,它包含了50个卡车33天时间里在希腊雅典周边建筑地区运输混凝土的轨迹。另外一个数据集OLDEN是由著名的Brinkhoff Generator生成的,该数据集表示为OLDEN。生成器使用的是Oldenburg的路网数据,整个城市区域的面积为23.57 km×26.92 km,它包含了6 105个节点和7 035条边。实验生成了10 000个移动对象在150个时刻的位置数据。 表1展示了两个数据集在预处理之后的特征。|D|表示在预处理之后的轨迹数目;|Dec|表示每个数据集中的等价类的数目;MaxNo和MinNo分别表示等价类中最多轨迹数目和最小轨迹数目;Ratio表示在每个等价类中轨迹s-重叠的平均比例。可以看出,TRUCKS数据集比OLDENBURG数据集稀疏,也就是说TRUCKS轨迹集的轨迹数目少,且分布空间更大。 表1 数据集特性 3.2 数据可用性 数据可用性主要用信息丢失来衡量。本文在TRUCKS和OLDENBURG数据集上分别衡量了信息丢失。图1展示了在两个数据集上的信息丢失的结果。由于TRUCKS比OLDENBURG稀疏,所以设置了不同的k值。从图1中可以看出,信息丢失随着k的增长逐渐增大,这是因为k值越大,匿名区域面积越大,因此信息丢失越大。从另一方面来说,随着k的增大,匿名失败率也会增大,删除的轨迹数目增多,信息丢失也会增大。然而,信息丢失的增长是比较稳定的,也就是说k值的增大不会造成信息丢失的急剧增长。 图1 信息丢失衡量 匿名成功率是指成功匿名的轨迹数目占所有轨迹数目的比例。实验分别在TRUCKS和OLDENBURG数据集上测试了匿名成功率,实验结果展示在图2中。从图中可以看出,在OLCENBURG数据集上,尽管匿名成功率随k的增大而降低,但匿名成功率仍大于65%,最高可达80%。 图2 匿名成功率 3.3 算法效率 贪心k-node划分算法是由Java实现的,实验运行的CPU是1.4 GB Intel Core i5,内存为4 GB,操作系统是Windows 7。 算法耗费13 897 ms预处了OLDENBURG数据集,花费194 732 ms构建了132个轨迹图。算法预处理TRUCKS数据集耗费了10 072 ms,花费了5 455 ms构建了154个轨迹图。图3展示了贪心k-node划分算法的运行时间。 图3 算法运行时间 数据集TRUCKS比OLDENBURG数据集小,因此,贪心k-node划分算法在TRUCKS上比在OLDENBURG上的运行的更快。在两个数据集上,运行时间随着k的增大而增加,这是由于k的增大会导致划分时,尝试删除一个k个顶点的子图将花费更多时间。 本文提出了一种路网环境中基于图划分的轨迹隐私保护技术,通过将轨迹数据模拟到无向图中,利用图的k-node划分实现轨迹k-匿名,实验验证了算法的有效性。 [1] Pan X, Wu L, Hu Z, et al. Voronoi-based spatial cloaking algorithm over road network [C]// 25th DEXA Conference and workshops, September 1-4, 2014, Munich, Germany, Springer, 2014: 273-280. [2] Pan X, Chen W, Wu L, et al. Protecting personalized privacy against sensitivity homogeneity attacks over road networks in mobile services[J]. Frontiers of Computer Science, 2016, 10(2):370-386. [3] Chen R, Fung B C M, Desai B C, et al. Differentially private transit data publication: a case study on the Montreal transportation system[C]// 18th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, August 12-16, 2012, Beijing, China, ACM, 2012: 213-221. [4] Hay M, Rastogi V, Miklau G, et al. Boosting the accuracy of differentially private histograms through consistency[J]. Proceedings of VLDB Endowment,2010,3(1):1021-1032. [5] Sui P, Wo T, Wen Z, et al. Privacy-preserving trajectory publication against parking point attacks[C]// 2013 IEEE 10th International Conference on Ubiquitous Intelligence and Computing and 2013 IEEE 10th International Conference on Autonomic and Trusted Computing, December 18-21, 2013, Vietri sul Mare, Sorrento Peninsula, Italy, IEEE Computer Society, 2013: 569-574. [6] Seidl E D, Jankowski P, Tsou M-H. Privacy and spatial pattern preservation in masked GPS trajectory data[J]. International Journal of Geographical Information Science,2016,30(4):785-800. [7] Cao Y, Yoshikawa M. Differentially Private Real-Time Data Publishing over Infinite Trajectory Streams[J]. Ieice Transactions on Information & Systems, 2016, 99(1):68-73. [8] Abul O, Bonchi F, Giannotti F. Hiding sequential and spatiotemporal patterns [J]. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(12): 1709-1723. A TRAJECTORY PRIVACY PROTECTION TECHNOLOGY IN ROAD NETWORK ENVIRONMENT Huo Zheng1Wang Teng2 1(SchoolofInformationTechnology,HebeiUniversityofEconomicsandBusiness,Shijiazhuang050061,Hebei,China)2(StateKeyLaboratoryofSatelliteNavigationSystemandEquipmentTechnology,No.54Institution,ChinaElectronicsTechnologyGroupCorporation,Shijiazhuang050000,Hebei,China) Directly publishing trajectory data without privacy processing can result in the disclosure of personal privacy of the moving object. Traditional trajectory privacy protection technology uses the method of clustering to generate trajectory k-anonymous set, which only applies to free space environment and does not apply to road network environment. A trajectory privacy protection method in road network environment was designed to simulate the trajectory in the road network environment to an undirected graph, and the k-anonymity problem was reduced to the k-node partition problem of undirected graphs. It was proved that the k-node partition of the graph is an NP-complete problem and a greedy algorithm was proposed to solve this problem. The anonymous success rate of the algorithm was verified to be close to 60% on average, and the maximum is over 80%. Road-network Trajectory Privacy protection Data publication 2016-06-02。国家自然科学基金项目(61303017);河北省自然科学基金项目(F2015207009);河北省高等学校科学研究项目(BJ2016019)。霍峥,讲师,主研领域:移动对象数据库,隐私保护技术。王腾,高工。 TP3 A 10.3969/j.issn.1000-386x.2017.07.057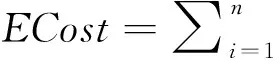
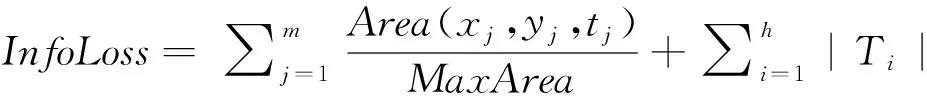
3 实验分析
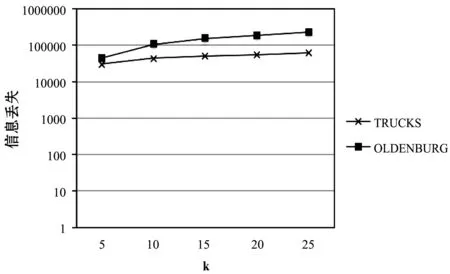
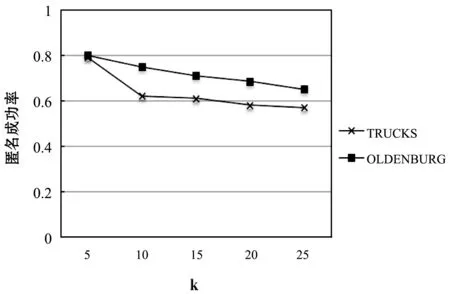
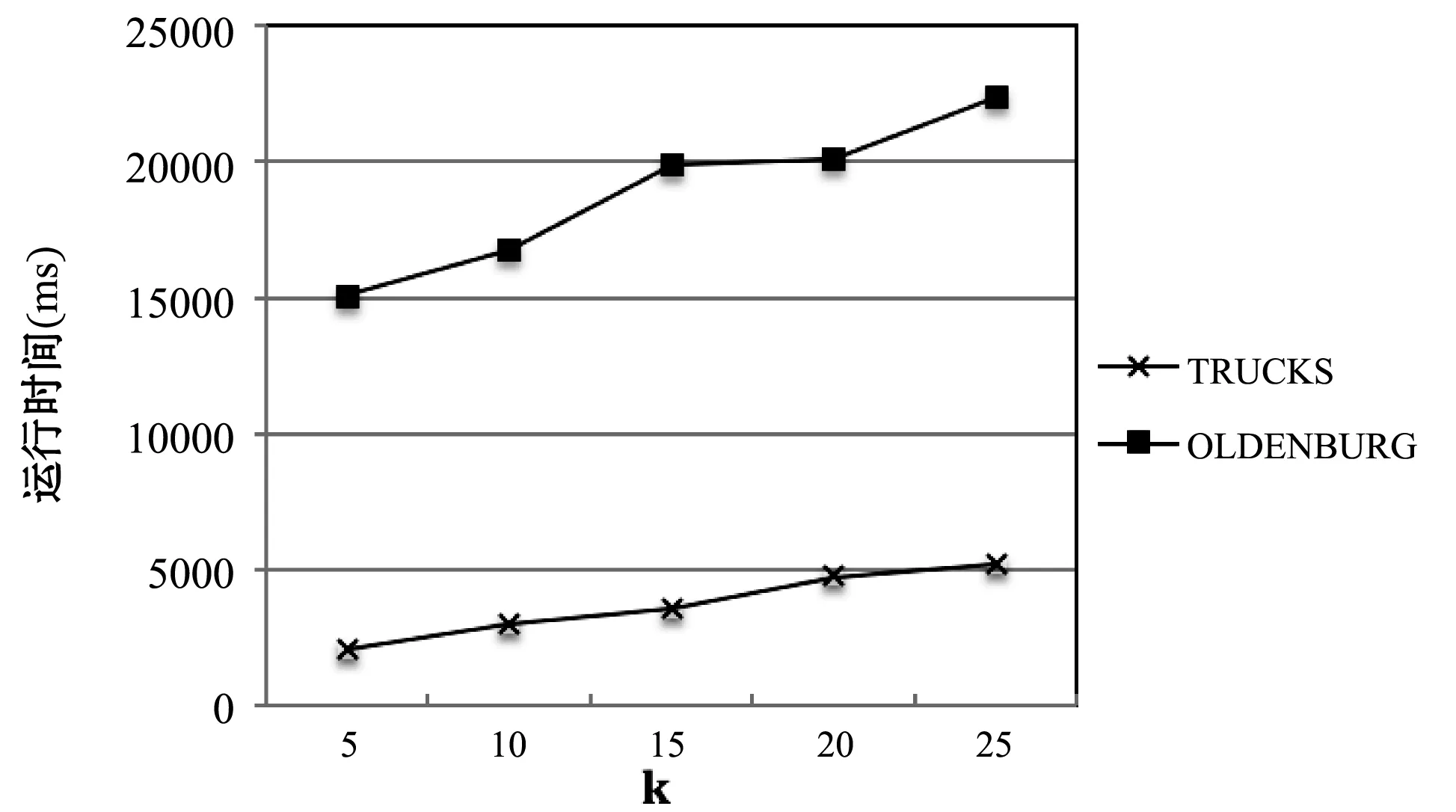
4 结 语
