基于语义依存分析的句子相似性度量算法及应用研究
2017-08-12何聚厚
李 玲 何聚厚
1(陕西师范大学计算机科学学院 陕西 西安 710119)2(陕西师范大学现代教学技术教育部重点实验室 陕西 西安 710062)
基于语义依存分析的句子相似性度量算法及应用研究
李 玲1何聚厚2*
1(陕西师范大学计算机科学学院 陕西 西安 710119)2(陕西师范大学现代教学技术教育部重点实验室 陕西 西安 710062)
问答系统在MOOC(Massive Open Online Course)学习平台中占有很重要的地位,但由于MOOC课程学习中用户多、问题多的特点,快速准确地找到某一问题的答案,成为提升MOOC平台用户体验的一个挑战。为此,构建了面向常问问题集的问答系统,通过计算问句的相似性实现系统的自动问答。在现有的句子相似性度量方法基础上,设计了基于语义依存关系的度量方法,并结合了句长、词形、词义等多种特征度量句子之间的相似性。实验结果表明,该方法能够较好地反映句子之间的语义差别,是一种可行有效的方法,且提高了系统的响应准确率。该系统具有较高应答准确率,具有较强使用价值和广阔的应用前景。
MOOC 自动响应 问答 句子相似度 语义依存分析
0 引 言
大规模在线开放课程MOOC是基于网络和移动智能技术的新型在线学习课程形式。自2012年MOOC元年以来,它作为一种全新的学习方式,不仅推动了现代远程教育,更是给传统教育,尤其是给高等教育带来了巨大变革[1]。但是,由于地理上的分离,基于网络的MOOC学习中,师生之间缺乏直接的互动。而答疑工作,作为教学活动过程中的一项必不可少的环节,开展效果将直接影响到教学质量的高低。在现代MOOC教学中,大多数MOOC课程利用在讨论区提问的方式进行答疑,如edX、学堂在线、中国大学MOOC等平台,教师可根据学习者的反馈予以定期答疑,哈佛大学曾在edX上开设《China》课程[2],每周两位主讲教师会收集上周学习参与者们提出来的具有代表性的问题,专门制作一个答疑视频(Office Hours),帮助师生的互动交流。一些MOOC课程会根据需要通过QQ、Facebook等社交、通信平台进行交互,但要获得及时答疑的前提是双方同时在线,例如在爱丁堡大学的EDC MOOC[3]中,教师利用Google Hangout进行定期视频答疑,要求学习者必须在规定的时间登录到Google Hangout。也有少数教学平台带有自己的问答平台,如网络课程联盟Coursera、中国的慕课网等,学生可以提出问题让其他学生回答,据统计,Coursera的回答时间中间值为22分钟[4]。就目前存在的答疑方式来看,学习者碰到的问题无法在第一时间得到教师的辅导,学习者缺乏及时的指导,难以达到好的学习效果。同时,MOOC课程最主要的特征是大规模和开放性[5],为数众多的学习者导致教师没有足够的时间和精力回答每一个提问。如何快速准确地找到某一问题的答案,成为提升MOOC平台用户体验的一个挑战。
自动问答(Question Answering Track)系统的作用和搜索引擎相似,能够为用户提供相关问题的答案。不同的是,它既能够让学习者用自然语言提问,不需要将问句分解为关键字,又能够返回一个简洁、准确的答案,而不是一些相关的网页,能够比搜索引擎更准确地找出用户所需要的答案,满足用户的检索需求[7]。将自动问答技术应用于MOOC学习平台,在一定范围内自动回答学习者提出的问题,使学习者能够及时解决疑难问题,以便后续学习,不仅提高了时效性和资源复用率,而且能够帮助教师进行分析、统计,发现学习者的薄弱之处,改善教学中的不足,提高教学效果。为此,本文设计了面向常问问题集FAQ(Frequently Asked Question)的问答系统,常问问题集中保存了用户经常问的问题及答案,当用户提问时,系统首先在常用问题集中查找是否有相同或相似问题存在,如果有,那么直接给用户提供该问题的答案,完成自动响应,方便快捷地解答了学习者学习过程中遇到的疑惑,具有较强的实用价值。
1 常见的句子相似性度量方法
在FAQ问答系统中,系统能否高效地完成自动响应的核心是问句与问句之间的相似性度量是否合理,其中,计算方法的时间复杂度和结果的准确率对问答系统的效率有直接影响。目前,常用的句子间相似性度量方法有以下几种。
1.1 基于相同词的句子相似性度量方法
基于相同词的句子相似性度量,也叫做词形相似度,反映的是两个句子包含的词语在形态和结构上的相似程度,一般使用两个句子含有的相同词的个数作为衡量标准。这种方法计算简单且效率高,但是由于没有利用到句子的语义和语法信息,结果不是很准确。
1.2 基于语义词典的句子相似性度量方法
基于语义词典的相似性度量方法是以语义词典作为语义分类体系得到词语间相似度,在此基础上进行句子相似性度量。语义词典是词语语义相似性度量的基础,目前常用的英文语义词典有WordNet、MindNet等,中文语义词典有《知网》(HowNet)[8]、《同义词词林》等。利用语义词典度量词语相似性的主要思想是:首先利用语义词典中概念间的多种语义关系(上下位、反义和同义等)计算得到概念与概念间的语义距离,再根据概念之间的语义距离计算得到概念之间的语义相似度,最后由概念之间的语义相似性计算得到词语间的语义相似度。但是由于这一方法没有考虑到句子的句法结构和词与词的相互作用关系,结果并不是很准确。
1.3 基于编辑距离的句子相似性度量方法
编辑距离是指从句子A变化成为句子B所需要的最少编辑操作次数。编辑操作指的是对句子进行的插入、删除和替换操作,一般指定位置的单个字符操作被称为一次编辑操作。编辑距离应用的成果较少,主要被用于句子的快速模糊匹配领域,文献[21]将其应用到了句子检索系统中,不仅使用了编辑距离算法进行句子检索,同时利用语义词典来弥补编辑距离在语义信息方面的缺失,并用实验证明了方法的有效性。
1.4 基于依存句法的句子相似性度量方法
依存句法是1959年法国语言学家L.Tesniere最先提出的概念。它将句子分析成一颗依存句法树,描述出各个语言单位之间的依存关系,指出了各个句子成分之间在句法上的搭配关系,这种搭配关系是和语义密切联系的。依存句法分析能够反映出句子当中各语义成分之间的相互修饰关系,与各成分在句中的物理位置无关,因此可以长距离搭配。如何找出句子中各成分的依存关系是使用依存结构度量句子相似性的核心问题。在利用句法结构进行相似性度量时,一般只考虑那些构成有效搭配对的相似程度,也就是整个句子的中心词和直接和中心词依存的有效词(名词、动词和形容词)组成的搭配对。文献[25]获取句子中的词语搭配和构成特征时利用了依存句法理论,并进行了实验对比,证明了该方法能够可行有效地反应句子之间的语义差别。
1.5 基于角色标注的句子相似性度量方法
通常的句子相似性度量方法都很少包含语义信息,而基于语义角色标注的句子相似性度量不仅考虑了语法信息,同时将语义信息融入其中。语义角色标注作为句子深层语义分析的一个过度阶段,将其应用到句子相似性度量中有很重要的作用。文献[26]利用了语义角色来度量句子的相似性,将语义角色标注结构相似性引入到句子相似性度量中。本文在此基础上将语义角色改为语义依存分析的结果,不仅包含语义角色,还包含句法结构和二级语义关系,后文用实验证明了此算法的有效性。
2 本文中的句子相似性度量方法
2.1 基于语义依存分析的句子相似度
语义角色标注结构中包含着丰富的语义信息。文献[19]和文献[26]都提出了利用语义角色来度量句子的相似性,但语义角色只关注句子主要谓词的论元及谓词与论元之间的关系,而语义依存不仅关注谓词与论元的关系,还关注谓词与谓词之间、论元与论元之间、论元内部的语义关系。语义依存分析对句子语义信息的刻画更加完整全面,是句法和语义的进一步深化。因此本文在此基础上提出一种基于语义依存分析的句子相似性度量方法,计算过程中使用哈工大社会计算与信息检索研究中心研发的 “语言技术平台(LTP)”[11]进行句法分析,利用分析结果进行计算。
语义依存关系包括:主要语义角色,每一种语义角色对应存在一个嵌套关系和反关系;事件关系,描述两个事件间的关系;语义依附标记,标记说话者语气等依附性信息[11]。正是由于语义依存分析包含如此丰富的信息,所以如何利用这些有用信息来计算句子的相似度就成为我们研究工作中的研究重点。衡量整个句子的语义时,通常情况下标点、语气、连词、介词等因素对语义的影响较小,在计算时将这类标记忽略,只计算有实际含义的语义依存角色。计算过程如下:
(1) 相同语义依存角色的个数
(1)
SameRole(S1,S2)表示句子S1与句子S2中所包含的相同的语义依存角色数目,Role(S1)和Role(S2)表示句子S1和S2各自包含的语义依存角色数目。
(2) 相同语义依存角色在句子中的位置
(2)
(3)
其中,r1i与r2i表示句子S1与S2中第i个相同的语义角色,dis(r1i)和dis(r2i)表示该角色距离语义依存句法树根结点的距离,距离越接近,句子越相似。
(3) 基于语义依存分析的句子相似度SdpSim(S1,S2)=αSdpSim1(S1,S2)+βSdpSim2(S1,S2)
(4)
经过实验,α=0.2,β=0.8时,计算结果最为有效。
2.2 多因素的句子相似性度量
句子之间的相似性受到很多因素的影响,例如词形、句长、词序、词语含义、句法结构等。两个句子的相似程度不仅和句子的语义信息相关,也和句子的句法信息相关,要想取得理想的效果就不能单纯考虑其中的单一方面。因此,我们在处理过程中把上面提到的这些因素分别看成句子的不同特征项,综合利用这些特征项,根据重要性来配给不同的权重,得到句子的最终相似度。计算过程如下:
(1) 词形相似度
根据两句话中出现的相同词语来衡量句子的相似性。句子S1和S2 的词形相似度为:
(5)
其中,Len(S1)和Len(S2)分别表示两个句子的词数,SameWord是两个句子包含的相同词的个数。
(2) 句长相似度
句子长度在一定程度上也反映了句子之间的相似程度,长度越接近的两个句子相似程度越大。设S1、S2为两个句子,则S1和S2 的句长相似度为:
(6)
其中,和Len(S2)分别表示两个句子的词数。
(3) 语义相似度
本文采用《知网》作为语义词典来度量句子之间的相似性。设S1、S2为两个句子,S1包含的词为A1,A2, …,Am,S2包含的词为B1,B2, …,Bn,利用文献[9]的方法计算出词Ai(1≤i≤m)和Bj(1≤j≤n)之间的相似度为S(Ai,Bj),则句子S1与S2之间的语义相似度为:
(7)
其中:
ai=max(S(Ai,B1),S(Ai,B2),…,S(Ai,Bn))
(8)
bi=max(S(A1,Bj),S(A2,Bj),…,S(Am,Bj))
(9)
(4) 句子相似度
基于多因素的句子相似性度量模型的计算公式如下:
SenSim(S1,S2) =γ1WordSim(S1,S2)+
γ2LenSim(S1,S2)+
γ3SematicSim(S1,S2)+
γ4SdpSim(S1,S2)
(10)
其中:
γ1+γ2+γ3+γ4=1
3 句子相似度在中文问答系统中的应用
3.1 系统处理流程
该问答系统数据库包含了一个常用问题库,为加快查找和计算效率,问题经过预处理,标注了分词结果、词性和语义依存关系。当用户输入问题时,系统首先判断是否合法,如果不是,则提示用户提问非法,用户重新提问。
系统判断是合法问句后,首先利用哈工大的 “语言技术平台(LTP)” 为基础对用户问句进行词法分析、命名实体识别、依存句法分析、语义角色标注,得到词语信息的集合;查找计算之前,首先进行停用词过滤处理,去除那些对句子整体意思影响不大的词汇(如介词、语气词等),提高相似性度量的准确性,降低向量空间模型的维度,提高查找效率。然后在数据库中查找备选问题。将用户输入的问题和备选问题进行句子相似性度量,选择计算结果相似性最大的问题,判断是否大于阈值。大于则返回常问问题库中对应问题的答案,小于则将问题提交给对应的教师或者管理员。MOOC学习平台下的中文自动问答系统的处理流程如图1所示。
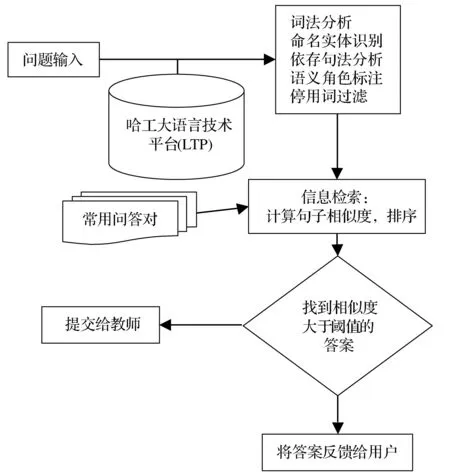
图1 问答系统处理流程
3.2 系统界面
图2 问答系统聊天界面
3.3 对比实验
结合本文应用场景为MOOC网络学习平台,实验数据采用与《论语》课程相关的语料构造的问答库,语料来源于互联网综合数据交易和服务网站“数据堂”。
(1) 计算结果对比
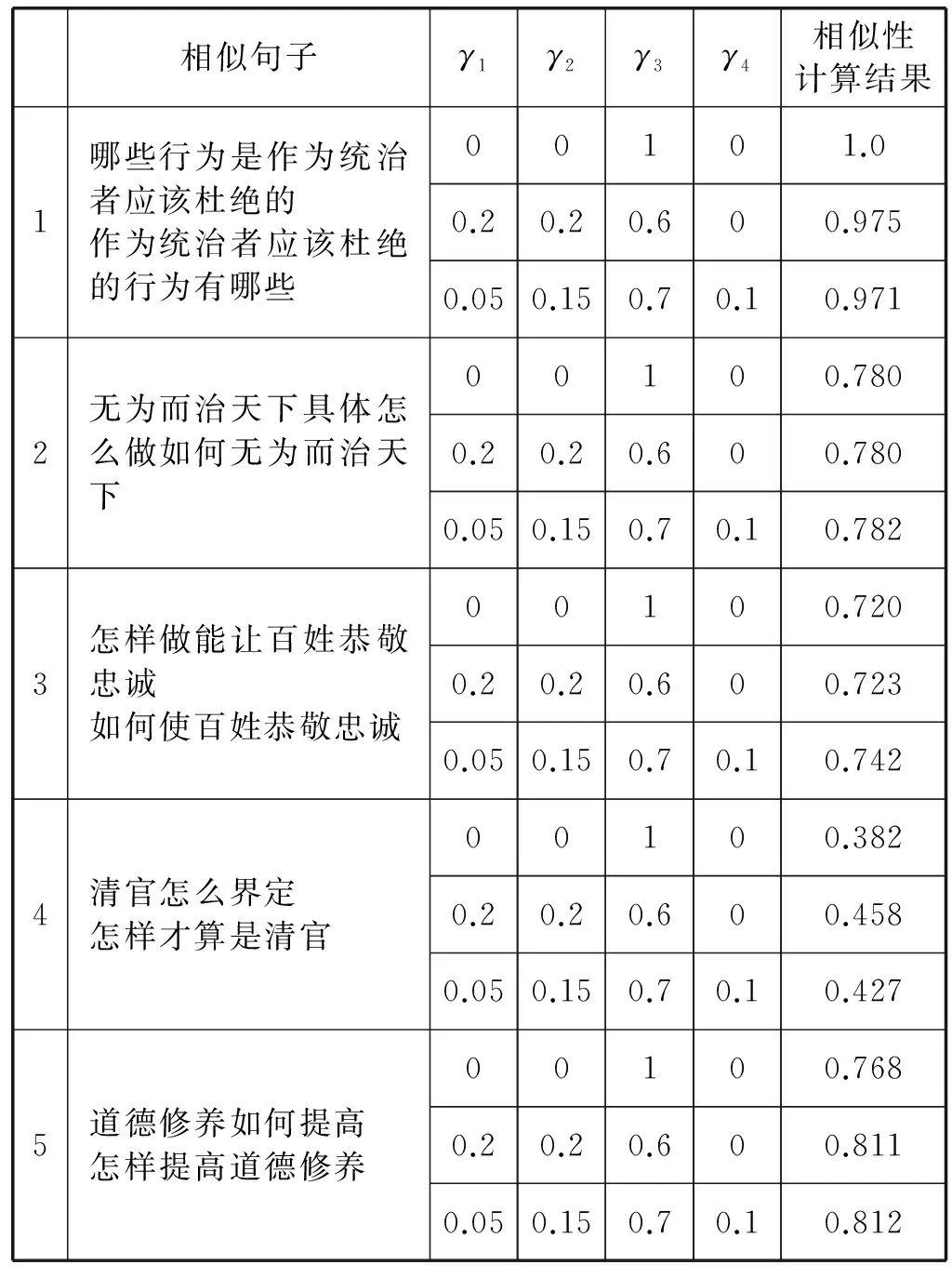
表1 加入语义依存分析前后对比实验
从表1可以看出,基于词形、句长、词义和语义依存分析多重因素考虑句子之间的相似度,比单纯基于语义词典的相似性度量结果更为准确。
(2) 系统响应正确率
测试问题数为100条,其中20条在问题库中有相应的问题和答案,60条是经过问句的变形提问并在问题库中都有答案,剩余20条在问题库中没有对应提问和答案。经过实验对比,查找问句时,设置阈值为0.7。选择相似度最大的问句,若相似度大于等于0.7,将该问题对应的答案返回;若小于0.7,那么认为该问题集中没有用户所提问题的答案。实验结果对比如表2所示。

表2 各因素不同权重的实验对比
如表2所示,实验组(1)中句子相似性度量只考虑基于语义词典的词义相似度;实验组(2)和(3)在(1)的基础上加入了词形和句长的计算,句子查找的正确率有一定提高,但是效果不明显;实验组(4)、(5)、(6)在(2)、(3)的基础上考虑了语义角色和句法结构,将基于语义依存分析的句子相似性度量结合进去,查找正确率明显提高。从上图的实验结果来看,计算句子相似度时,词形、句长、词义和语义依存分析分别占权重为0.05、0.20、0.70、0.05时,系统的准确率最高。
4 结 语
MOOC作为全新的学习方式,在现代教育中应用越来越广泛,但由于MOOC课程学习中用户量大、问题多,快速准确地找到某一问题的答案,成为提升MOOC平台用户体验的一个挑战。自动问答技术是自然语言处理领域的研究热点,被称为“第二代搜索引擎”,拥有广阔的应用前景。将自动问答技术应用在MOOC平台中,可以有效解决师生交流的不及时和问答资源不能重复利用的问题。本文设计了基于依存句法分析的句子相似性度量方法,并结合词形、句长、词义多重因素度量句子之间的相似性,在此基础上实现了原型系统并进行了实验。实验结果实验证明,将语义依存分析应用到问答系统句子相似性度量中,能够更加精确地反映问答数据的特征,使系统性能得到改善,有很高的研究和应用价值。今后的工作将继续研究句子相似性度量的方法和效率,不断提高问答系统的性能。
[1] 王文礼. MOOC的发展及其对高等教育的影响[J]. 江苏高教,2013(2):53-57.
[2] 李青,王涛. MOOC:一种基于连通主义的巨型开放课程模式[J]. 中国远程教育,2012(3):30-36.
[3] 马武林,张晓鹏. 大规模开放课程(MOOCs)对我国大学英语课程设置的启示研究——以英国爱丁堡大学EDC MOOC为例[J]. 电化教育研究,2014(1):52-57.
[4] 科勒.我们能从在线教育中学到什么?[OL].http://www.ted.com/talks/daphne_koller_what_we_re_learning_from_online_education.html.
[5] 陈肖庚,王顶明. MOOC的发展历程与主要特征分析[J]. 现代教育技术,2013(11):5-10.
[6] 郑实福, 刘挺, 秦兵. 中文自动问答系统综述[J]. 中文信息学报, 2002, 6(16): 46-52.
[7] 毛先领, 李晓明. 问答系统研究综述[J] . 计算机科学与探索, 2012,6(3):193-207.
[8] 董强,董振东. 知网简介[EB/OL]. [2013-01-29]. http://www. keenage. com/.
[9] 刘群, 李素建. 基于《知网》的词汇语义相似度计算[C]// 第三届中文词汇语义学研讨会. 中国台北, 2002.
[10] Huang Gaitai, Yao Hsiuhsen. Chinese question answering system[J].Journal of Computer Scienceand Technology, 2008, 19(4):479-488.
[11] Che Wanxiang, Li Zhenghua, Liu Ting. LTP: A Chinese Language Technology Platform[C]// COLING 2010, International Conference on Computational Linguistics, Demonstrations Volume, 23-27 August 2010, Beijing, China. DBLP, 2010:13-16.
[12] Zhu Z Y, Dong S J, Yu C L, et al. A text hybrid clustering algorithm based on HowNet semantics[C]// ICAMCS 2011: 2011 International Conference on Advanced Materials and Computer Science. Zurich: Trans Tech Publications Ltd, 2011:474-476.
[13] 张亮. 面向开放域的中文问答系统问句处理相关技术研究[D]. 南京:南京理工大学, 2006.
[14] 李欢. 问答系统中的文本信息抽取研究与应用[D].北京: 中国科学技术大学, 2009.
[15] 刘朝涛. 中文问答系统中的句型理论及其应用研究 [D]. 重庆:重庆大学, 2010.
[16] 吴全娥. 汉语句子相似度计算及其在自动问答系统中的应用[D]. 西南大学,2011.
[17] 王肖磊. 自动问答系统的研究与应用[D] . 北京: 北京邮电大学,2015.
[18] 邢超. 智能问答系统的设计与实现[D]. 北京: 北京交通大学,2015.
[19] 张祎挺. 语义角色标注及其在句子相似度计算上的应用[D]. 北京: 北京邮电大学,2008.
[20] 裴婧, 包宏. 汉语句子相似度计算在FAQ中的应用[J]. 计算机工程, 2009,35(17):46-48.
[21] 车万翔, 刘挺, 秦兵, 等. 基于改进编辑距离的中文相似句子检索[J]. 高技术通讯, 2004, 14(7):15-19.
[22] 刘宝艳, 林鸿飞, 赵晶. 基于改进编辑距离和依存文法的汉语句子相似度计算[J]. 计算机应用与软件, 2008,25(7):33-34, 47.
[23] 薛慧芳. 句子相似度计算理论及应用研究[D]. 西安: 西北大学,2011.
[24] 李茹, 王智强, 李双红, 等. 基于框架语义分析的汉语句子相似度计算[J]. 计算机研究与发展, 2013, 50(8): 1728-1736.
[25] 吴佐衍, 王宇. 基于HNC理论和依存句法的句子相似度计算[J]. 计算机工程与应用, 2014,50(3):97-102.
[26] 王志青. 基于语义角色标注的句子相似度计算[D]. 北京: 北京邮电大学,2014.
[27] 郑诚,李清,刘福君. 改进的VSM算法及其在FAQ中的应用[J]. 计算机工程,2012,38(17):201-204.
[28] 李春梅,徐庆生. 基于多特征的汉语句子相似度计算模型的研究[J]. 计算机技术与发展, 2014(6):136-139, 144.
[29] 张培颖,房龙云. 多特征结合的词语相似度计算模型[J]. 计算机技术与发展, 2014(12):37-40.
CHINESE SENTENCE SIMILARITY COMPUTATION AND APPLICATION BASED ON SEMANTIC DEPENDENCY PARSING
Li Ling1He Juhou2*
1(SchoolofComputerScience,ShaanxiNormalUniversity,Xi’an710119,Shaanxi,China)2(KeyLaboratoryofModernTeachingTechnology,MinistryofEducation,ShaanxiNormalUniversity,Xi’an710062,Shaanxi,China)
Question answering system makes a big difference on MOOC learning platform, but since number of users and questions is so large that how to find the certain answer to a question quickly and accurately is a challenge to enhance user experience. So a frequently asked question system was designed to response question automatically. Based on the existing similarity calculation methods, this paper proposed a similarity calculation method according to semantic dependency parsing and multiple characteristics between sentences such as same words, sentence-length, and semantic of words. Test result shows that this method can reveal sentence difference better improve the accuracy of the response. This system has high response accuracy, has high practical value and wide application prospects.
MOOC Auto respond Question and answer Sentence similarity Semantic dependency parsing
2016-07-26。教育部-中国移动科研基金项目(MCM20150604)。李玲,硕士生,主研领域:网络与远程教育。何聚厚,副教授。
TP311
A
10.3969/j.issn.1000-386x.2017.07.045
