基于变精度双论域粗糙集的个性化推荐方法
2017-07-10阎瑞霞
林 群 阎瑞霞
(上海工程技术大学管理学院 上海 201620)
基于变精度双论域粗糙集的个性化推荐方法
林 群 阎瑞霞
(上海工程技术大学管理学院 上海 201620)
针对用户不确定性决策问题,提出基于变精度双论域粗糙集的个性化推荐方法。首先,基于置信度的含义提出一种新的知识库构建方法,并利用SQL语言实现。在此基础上构建基于变精度双论域粗糙集的个性化推荐模型,并将该模型应用到男士衬衫的个性化推荐中。最后通过推荐方法比较分析,实验结果说明了基于变精度双论域粗糙集的个性化推荐模型的有效性。
变精度粗糙集 双论域 个性化推荐 关联规则 非确定性决策
0 引 言
“互联网+”行动计划不断加快电子商务企业发展,越来越多的商家进入电子商务行业。据统计,截至2015年12月,中国网民增长率为6.1%,网民规模达6.88亿[1],在线销售变得纷繁复杂。尽管推荐系统早已产生,但面对海量的不确定性用户信息,商家往往只根据热度高的商品或者用户以往买过的相似商品覆盖率进行推荐,商家推荐商品的精准性大幅度下降。同时,随着用户生活节奏逐渐增强,用户购物时间紧迫,用户要求商家在短时间内做出精准推荐。商家在不确定性用户信息与实时性决策环境下推荐的商品,往往会使用户对实际货物与购物心理预期形成落差,大大提高了网购退换货率,退换货必然会影响购物体验,降低用户忠诚度。为了提高商家推荐准确性与实时性,提高用户回头率,准确性高的个性化推荐系统对商家而言尤为重要。
个性化推荐系统[2-4]是建立在海量数据挖掘基础上的智能推荐平台,以帮助电子商务网站为用户提供个性化购买决策支持与信息服务。商家针对不同的用户,根据偏好与个性化需求给出更加精确的推荐。近年来,电子商务个性化推荐受到了国内外诸多学者的密切关注,产生许多研究成果。个性化推荐算法主要分为3种:基于内容、协同过滤与混合推荐。文献[5] 在计算微博用户与微话题的相似性的基础上,提出了基于内容的热门微话题推荐方法,该方法可解释性强,用户易理解,也不存在冷启动问题,但是在推荐多样性上存在不足,难以发掘用户的潜在偏好。文献[6] 根据用户的发帖、回帖和阅读等记录,计算用户帖子的评分矩阵,认为对于任意帖子评分相同的用户具有相同的偏好,提出基于协同过滤的网络论坛个性化推荐算法,该方法很好应用于复杂推荐对象,但存在冷启动问题。文献[8] 提出基于商品属性与用户聚类的个性化服装混合推荐方法,通过用户个人信息与对商品的评价,计算用户之间的相似性,进行聚类分析,通过计算商品相似性,得到top-N相似列表,并结合两者的权重值,实现用户个性化推荐。文献[9] 改进传统基于内容推荐得到的用户现有兴趣,通过协同过滤得到用户潜在兴趣,并加以结合,构建基于内容与协同过滤的混合推荐方法下的用户兴趣模型。混合推荐方法兼顾推荐多样性和个性化需求的同时,有效避免推荐时间上的滞后性,但存在冷启动问题,并未考虑推荐环境的不确定性。
用户属性特征的不确定性决定了网络购物环境的不确定性,用户购物行为复杂多变,比如,用户年龄是不断增长的,过去购买行为并不能说明现状;用户身份为销售人员时其工资发放性质决定其收入的不稳定性和购物行为不定性等。粗糙集是一种处理不确定性知识的数学工具,是人工智能中的一种重要推理技术。针对以往推荐系统并不能很好地解决推荐环境不确定性问题,本文提出基于变精度双论域粗糙集的个性化推荐方法,其主要思想是在粗糙集的基础上,将粗糙集模型推广到两个不同但相关的论域,同时在模型中引入分类精度,使模型具有一定的容错性,增强模型抗噪声能力。目前关于变精度双论域粗糙集的研究主要集中在模型的构建、属性约简和规则提取等方面[10-12],很少有学者研究知识库的构建。本文结合关联规则的原理,将置信度引入到知识库的构建中,并利用SQL语言实现;在此基础上构建基于变精度双论域粗糙集的个性化推荐模型;最后,本文将该模型应用到服装的个性化推荐中,并通过比较说明了模型的有效性。
1 基础理论
1.1 变精度双论域粗糙集
经典Pawlak粗糙集研究的是在同一个论域上的对象,同时要求所处理对象完全已知的且分类是完全精确的,得到的规则也只适用于该对象。然而在许多实际管理决策问题中,常常涉及两个不同论域,往往只是将所求的样本结论推测总体对象,数据具有不精确性。因此,相对于经典粗糙集而言,变精度双论域粗糙集的理论思想和模型是解决实际管理决策问题的有效工具。
1.1.1 分类正确率与参数的确定
基于上述问题,变精度双论域粗糙集在引入双论域的基础上,还引入分类正确率与参数α、β,加强定义双论域粗糙集上、下近似算子,放松粗糙集严格的边界定义,使模型更适用于现实数据的不精确性问题,同时,双参数的设定使模型对数据不一致性有一定的容忍度,提高数据分析的适应能力。
定义1 (分类正确率) 设X、Y分别是有限论域U、V的子集,令:
(1)
其中,|R(x)∩Y|表示集合X关于Y的相对分类正确率,即集合Y基于X的条件概率。
在双参数变精度双论域粗糙集模型中,正确确定参数α和β的范围能减少数据噪声,增强分析的准确性。Y的双论域近似区域与阈值α和β取值紧密相关,并随α和β的取值变化而变化,因此,α和β取值能够体现双论域近似空间的精确度,决策者对参数确定也显得尤为重要。本文研究主要利用Aijun提出的0.5<β≤α≤1的分类正确率来研究电子商务服装个性化推荐模型[ 13]。
1.1.2 双参数变精度双论域粗糙上、下近似计算
定义2 (双论域上、下近似) 在信息系统(U,V,R),U={x1,x2,…,xm},V={y1,y2,…,yn},∀Y⊆V,0.5<β≤α≤1,Y在关系R下的α双论域下近似集和双论域β上近似集定义如下:
(2)
(3)
分别表示Y的双论域α下近似和β双论域上近似[14]。
1.1.3 决策规则提取
在信息系统(U,V,R)中,U={x1,x2,…,xm},V={y1,y2,…,yn},∀Y⊆V,规定:
由此可以提取规则:两条确定性规则,分别根据双论域正域和负域提取;以及两条可能性规则,分别根据双论域可能域和边界域提取,为商家个性化推荐提供有力的依据。
1.2 关联规则
定义3 (关联规则) 关联规则是数据挖掘的核心技术之一,可描述如下:设I={i1,i2,…,im}是个不同项目组成的集合,其中的元素i称为项目(item)。记D={t1,t2,…,tn}为事务数据库,T为D的事务集,每个事务ti(i=1,2,…,n)都对应I上的一个子集。我们用关联规则分析形如X→Y的蕴涵式,X⊆I,Y⊆I,且X∩Y=∅。X是关联规则的前件,Y是关联规则的后件,关联规则挖掘就是要找到所有满足给定的最低支持度和最低置信度的蕴含式。
因此,关联规则分析的基本算法步骤:
(1) 选出满足支持度最小阈值的频繁项集;
(2) 从频繁项集中找出满足最小置信度的所有规则。
2 知识库的构建
变精度双论域粗糙集是在知识库基础上进行推理判断的。传统知识库的建立主要有三种方法:(1)简单使用SPSS软件分析各属性之间的相关性并构建关系矩阵;(2)将关系数据库中的多值属性进行布尔转换,再利用布尔型关联规则建立关系矩阵。在属性较多的情况下,这两种方法在实现上较复杂且消耗大量时间,甚至会丢失部分有用信息;(3)利用关系数据库系统中的SQL语句来执行。该方法目前只是对经典关联规则算法进行扩展,影响了挖掘效率。
同时,关系数据库往往是由成千上万不同类型和值域空间的属性组成的,这决定了获取的关联规则具有明显的特点:(1)离散化的多值型关联规则。关系数据库往往含有大量的数值属性和类别属性,在关联规则分析之前需要对其进行数值属性或多值属性的离散化;(2)多属性型关联规则,包括两个及以上不同属性之间关系的关联规则。
因此,针对上述问题,本文主要是在关联规则分析关系数据库的基础上,通过执行SQL语句提出数据库中多值、多属性型关联规则算法[15-19]。该方法操作简单快速且高效,适用于各种数据类型。挖掘算法描述如下[20]:
输入:挖掘数据源(db)、最小支持度阈值(minsup)、最小可信度阈值(minconf)
k=1
ACk=generate-attribute-combination(k)
// 产生db中所有1组合属性集
Lk=generate-frequent-attribute-value-sets (ACk)
// 产生db中频繁1项集
DowhileLk≠∅andk≤AttributeCount
//AttributeCount为db中属性的个数
k=k+1
ACk=generate-attribute-combination(k)
// 产生db中可能具有频繁值集的所有k组合属性集
Lk=generate-frequent-attribute-value-sets(ACk)
// 产生db中频繁k项集
End do
AR=generate-association-rules(Lk)
// 产生db中所有强关联规则。
例如,在收集的数据表(db)中计算年龄(A)、收入(C)、档次(I)这三个属性满足的最小支持度(minsup)的频繁属性值集,可用“selectA,C,I,count(*)fromdbgroupbyA,C,Ihavingcount(*)≥minsup”执行。通过借鉴Apriori算法“连接”与“剪枝”的思想产生属性组合集,减少SQL执行次数。

3 基于变精度双论域粗糙集的个性化推荐模型
根据上述分析研究,针对目前电子商务个性化推荐中存在的问题,提出基于双参数变精度双论域粗糙集的方法。商家通过提取影响用户购物行为的商品属性特征以及用户本身属性特征,运用关联规则建立知识库,在此基础上构建变精度双论域粗糙集的个性化推荐模型[10-13],计算并提取决策规则。根据变精度双论域粗糙集特点,提取到两条确定性规则(基于α正域、基于β负域)和两条可能性规则(基于α可能域、基于α、β边界域),并依据上述四条规则对用户进行个性化推荐。
基于双参数变精度双论域粗糙集推荐模型步骤如图1所示。
(1) 将SQL语句引入到关联规则中,建立关系知识库,从而构建双参数变精度双论域粗糙集关系矩阵MR;

(3) 计算双参数变精度双论域粗糙集的正域、负域、边界域和可能域;
(4) 提取决策规则。
4 基于双参数变精度双论域粗糙集的服装个性化推荐
为了方便分析,以男士衬衫个性化推荐为例,利用双论域变精度双论域粗糙集方法,针对用户对男士衬衫的个性化需求,商家对男士衬衫进行个性化推荐,缩短用户消耗时间,提高用户信赖与忠诚度,减少退换货率。
4.1 数据来源
本文主要通过设计调查问卷,从受访者的年龄、身高、收入、购买时间、穿着习惯等基本信息,以及受访者对衬衫的尺码、颜色、材质、档次、风格、版型、厚薄等个性化要求进行调查,将收集到的数据进行预处理,进而对问题进行研究。此次共发放问卷350份,扣去未收回和缺失值过多的无效问卷,最后得有效问卷310份,有效率达到88.6%。
4.2 用户和男士衬衫属性类型
根据结合天猫网站用户和男士衬衫属性划分方法,本文主要利用用户5种属性(年龄、身高、收入、购买时间、穿着习惯)以及男士衬衫7种特征(尺码、颜色、材质、档次、风格、版型、厚薄)来分析男士衬衫的个性化推荐情况,但是从问卷调查中收集到的数据都是连续性的,因此,需要先对收集到的数据进行离散化。本文采用自然划分分段的方法,将连续的属性值划分成若干个范围,并在每个范围中给出一个标准值,这样就使连续的属性值达到了离散化。具体分类及离散化后的决策如表1和表2所示。
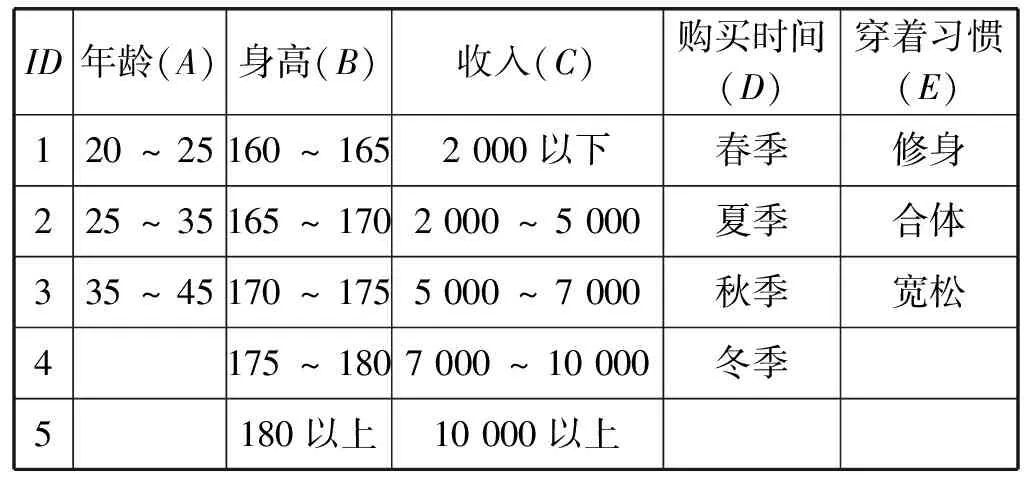
表1 用户特征属性值

表2 男士衬衫属性值
由上述表1可以得到离散的数据如表3所示。

表3 离散的数据表

续表3
4.3 关系矩阵
根据信息系统(U,V,R)中,U={x1,x2,…,xm},V={y1,y2,…,yn},∀Y⊆V。其中U={x1,x2,…,x23}表示男士衬衫的属性特征,V={y1,y2,…,y21}表示用户属性特征。


图2 相关分析图

4.4 结果分析
假设下近似阈值为α=0.6,上近似阈值为β=0.55,并且上述的知识库为完备知识库。为了充分验证双参数变精度双论域粗糙集推荐方法能很好地处理冷启动问题,假设新用户属性集合为Y={y2,y6,y11,y16,y19},可以得到:

由此可以看出,如果新的用户属性为年龄:25~35,身高:170~175,收入:5 000~7 000,购买时间:秋季,穿着习惯:合体,可以得到:
(1) 两条确定性规则
①y2∩y6∩y11∩y16∩y19⟹x3∩x12∩x17∩x21,则必须向其推荐的男士衬衫应该同时具有:尺码:L,档次:中档,版型:直筒,厚薄:厚。
②y2∩y6∩y11∩y16∩y19⟹(x1∩x2∩x4∩x5∩x7∩x8∩x10∩x11∩x13∩x14∩x16∩x18∩x19∩x20∩x22),则不要向其推荐的男士衬衫具有 :尺码:S,尺码:M,尺码:XL,尺码:2XL,颜色:深色系,档次:低档,档次:高档,风格:休闲,版型:修身,版型:宽松,厚薄:常规,厚薄:薄,厚薄:加厚。
(2) 两条可能性规则
①y2∩y6∩y11∩y16∩y19⟹x3∩x6∩x9∩x12∩x15∩x17∩x21,则可以考虑向其推荐的男士衬衫具有:尺码:L,颜色:浅颜色,材质:棉质,档次:中档,风格:正式,版型:直筒,厚薄:厚中任意特征的男士衬衫。
②y2∩y6∩y11∩y16∩y19⟹x6∩x9∩x15,则可以考虑向其推荐的男士衬衫具有:颜色:浅颜色,材质:棉质,风格:正式中任意特征的男士衬衫。
4.5 评 估
由于每个推荐系统的评估标准不一样,本文主要采用综合指标F-Measure和整体多样性来评估推荐系统的好坏,其中综合指标F-Measure是由分类准确率中准确率(precision)与召回率(recall)两个评估指标调和加权平均所得[7-10]。推荐结果统计如表4所示。

表4 推荐结果统计表


通过设置不同的推荐服装数N,得到不同推荐方法在不同推荐服装数下的F1的值,N-F1曲线如图3所示。

图3 推荐服装数N-F1曲线
由图3可以看出,基于变精度双论域粗糙集随着推荐服装数N的变动,综合评价指标F1的值在排除偶然因素的情况下,一直稳定在0.4~0.6之间,具有良好的稳定性与持久性。同时,变精度双论域粗糙集方法在性能上与混合算法相比虽然只有稍微提高,但与协同过滤和基于内容的推荐方法相比有了明显提高。
设s(i,j)ε[0,1]表示服装属性i和j的余弦相似度,单用户u推荐列表R(u)的多样性计算公式为:
(4)
推荐系统整体多样性计算如下式所示:
(5)
如图4所示,不同推荐服装数N下的Diversity值,可以看出变精度双论域粗糙集方法在多样性上,与混合方法、协同过滤推荐算法基本相当,但比基于内容的推荐方法有了明显提高。

图4 不同推荐算法Diversity比较
图3、图4表明双论域粗糙集在性能上与混合推荐方法差别不大,但由于混合推荐方法易产生冷启动的问题,而变精度双论域粗糙集能很好的针对新用户进行推荐,不存在冷启动问题,因此双论域粗糙集方法优于其他方法。
5 结 语
基于变精度双论域粗糙集的个性化推荐系统,将双论域粗糙集应用到电子商务多对多双边匹配的多属性决策问题中去,是解决实际管理决策问题的有效工具。将SQL语句引入到关联规则中,用于构建关系矩阵,高效且方便的数据关系挖掘方法大大缩短系统的推荐时间,节约了用户时间成本。同时,在保证性能良好与整体多样性的基础上,基于变精度双论域粗糙集不依赖于用户以往行为,不仅能够很好地解决目前推荐系统中存在的冷启动问题,更能实现用户不确定性环境下的个性化需求,提高了推荐的准确性以及用户的购物体验与忠诚度,减少退换货率。
[1]CNNIC报告. 移动互联网或引领文化发展新布局[J].计算机与网络, 2016, 42(5):6.
[2]WengSS,LinBS,ChenWJ.Usingcontextualinformationandmultidimensionalapproachforrecommendation[J].ExpertSystemwithApplications, 2009,36(2):1268-1279.
[3]ZuoY,GongMG,ZengJL,etal.PersonalizedRecommendationBasedonEvolutionaryMulti-ObjectiveOptimization[J].IEEEcomputationalintelligencemagazine, 2016,10(1):52-62.
[4] 王国霞, 刘贺平.个性化推荐系统综述[J].计算机工程与应用, 2012,48(7):66-76.
[5] 安悦,李兵,杨瑞泰,等. 基于内容的热门微话题个性化推荐研究[J].情报杂志,2014,33(2):155-160.
[6] 张新猛,蒋盛益. 基于协同过滤的网络论坛个性化推荐算法[J]. 计算机工程,2012,38(5):67-69.
[7]MarcoDegemmis,PasqualeLops,GiovanniSemeraro.Acontent-collaborativerecommenderthatexploitsWordNet-baseduserprofilesforneighborhoodformation[J].UserModelingandUser-AdaptedInteraction, 2007, 17(3):217-255.
[8] 艾黎. 基于商品属性与用户聚类的个性化服装推荐研究[J]. 现代情报,2015,35(9):165-170.
[9] 杨武,唐瑞,卢玲. 基于内容的推荐与协同过滤融合的新闻推荐方法[J].计算机应用,2016,36(2):414-418.
[10]WuZhong,YanRuixia.Variableprecisionroughsetoverdual-universesingeneralincompleteinformationsystem[J].InternationalJournalofAdvancementsinComputingTechnology, 2012, 4(19):299-306.
[11] 庾慧英,刘尚. 双论域上的变精度粗糙集模型[J].科学技术与工程,2007,7(1):4-7.
[12] 张海东. 基于一般关系下的双论域变精度粗糙集模型[J]. 宁夏师范学院学报,2011,32(6):18-21.
[13] 赵焕焕,刘勇,刘思峰,等. 基于灰色相似关联关系的灰色变精度粗糙集模型及应用[J]. 系统工程,2015,33(2):146-151.
[14] 阎瑞霞,郑建国,翟育明. 双论域粗糙集的不确定性度量[J]. 上海交通大学学报,2011,45(12):1841-1845.
[15] 李少阳,李巧艳,宋卫妮. 粗糙集上下近似的矩阵刻画及应用[J]. 计算机工程与应用,2015, 51(20):107-110,152.
[16]ChunguangBai,JosephSarkis.Evaluatingsupplierdevelopmentprogramswithagreybasedroughsetmethodology[J].ExpertSystemswithApplications, 2011, 38(11):13505-13517.
[17] 肖辉辉,段艳明. 关系数据库SQL语句的设计优化研究[J]. 软件导刊,2010,9(12):177-179.
[18] 李杰,徐勇,王云峰,等. 面向个性化推荐的强关联规则挖掘[J]. 系统工程理论与实践,2009,29(8):144-152.
[19] 钱慎一,王欢欢,杨铁松. 改进关联规则算法在烟草物流销售规律中的应用[J]. 计算机系统应用,2016,25(3):204-208.
[20] 王芳,王万森. 关系数据库中关联规则挖掘的一种高效算法[J].微机发展,2004,(14)9:20-22.
A PERSONALIZED RECOMMENDATION METHOD BASED ON VARIABLE PRECISION DUAL-UNIVERSE ROUGH SET
Lin Qun Yan Ruixia
(SchoolofManagement,ShanghaiUniversityofEngineeringScience,Shanghai201620,China)
Aiming at the problem of user uncertainty decision, a personalized recommendation method based on variable precision dual-universe rough set is proposed. First, a new knowledge base construction method is proposed based on the meaning of confidence, and implemented by SQL language. Based on this, a personalized recommendation model based on variable-precision dual-domain rough set is proposed, and the model is applied to the personalized recommendation of men’s shirts. Finally, the effectiveness of the personalized recommendation model based on variable precision dual-universe rough sets is illustrated by the comparative analysis of experimental results.
Variable precision rough set Dual-universe Personalized recommendation Association rule Uncertainty decision-making
2016-04-28。国家自然科学基金项目(71301100);上海市教委科研创新项目(14YZ140);上海市教委青年教师计划项目(ZZGJD12036);上海市自然科学基金项目(16ZR1414000);上海工程技术大学研究生科研创新项目(15KY0354)。林群,硕士生,主研领域:个性化推荐技术。阎瑞霞,副教授。
TP713
A
10.3969/j.issn.1000-386x.2017.06.045
