基于分布式消息队列的企业级全文检索模型研究
2017-07-10李政武彤
李 政 武 彤
(贵州大学计算机科学与技术学院 贵州 贵阳 550025)
基于分布式消息队列的企业级全文检索模型研究
李 政 武 彤
(贵州大学计算机科学与技术学院 贵州 贵阳 550025)
针对传统集中式全文检索系统的查询性能不足的问题,提出基于分布式消息队列构建的企业级分布式全文检索模型。该模型充分利用分布式消息队列将查询集群中的各个节点去耦合,以异步方式对查询请求进行处理,提高整个集群的查询吞吐量。从该模型的总体结构、分布式全文检索算法过程设计、算法验证三个方面进行了阐述,验证了该模型的可行性,并且验证结果表明具有良好的查询性能。
分布式消息队列 企业级全文检索 分布式全文检索
0 引 言
随着信息化技术的不断发展,大、中型企业对信息化应用的规模也在不断扩大,应用的需求也越来越复杂。其中企业对各类文档、报表数据的检索需求从传统的检索方式发展为全文检索的方式。而传统的企业信息化平台中只提供传统的搜索功能甚至并没有搜索功能,对全文检索的应用较少。
企业级全文检索对检索信息的整合性、安全性、准确性都有较高的要求[1],文档来源多,虽然单一应用系统中的文档数量通常较少,但是对于整个企业的信息化平台建设的全文检索系统需要处理的文档数量较多。若依据集中式方法建立全文检索引擎,则在查询效率上可能会不尽如人意。分布式技术是当前处理大批量数据、复杂计算的流行方式,分布式全文检索提出可以解决企业级全文检索的索引建立和查询的效率问题。
分布式全文检索技术的引入提高了全文检索系统在应对大数据量查询的性能以及全文检索系统结构的可扩展性。分布式全文检索的常用方式包括一种基于P2P的分布式搜索技术以及基于MapReduce的分布式搜索技术等[2]。P2P搜索技术中整个网络中不存在中心节点,每一个节点都同时具有信息消费者、信息提供者和信息通信三个方面的功能。基于MapReduce的分布式搜索技术的应用就是传统的集中式网络服务,基于此技术的搜索引擎系统,拥有多个单搜索引擎,这些引擎分布在不同的地方,中心搜索引擎利用这些分布的、单个的搜索引擎的结果进行整合得到完整的结果。元搜索引擎技术是一种基于搜索引擎的搜索引擎[3],通过整合多个独立的搜索引擎结果向用户提供查询结果。
分布式消息队列作为一种重要的分布式系统通信方式已被当前很多分布式系统的设计所采用。在文献[4]中所提出的一种基于分布式消息队列的通信方法的数据传输速率证实明显优于Socket方法。并且得益于消息队列对消息生产者和消息消费者之间的解耦,使得分布式系统的灵活性和容错性大大提高,相应地,整个系统所能承受的负载也会有所提升。同样,消息队列把分布式集群中各个节点的关系耦合度降低,使得这样的结构可以易于扩展。那么如何将分布式消息队列技术应用在企业级分布式全文检索中就成为了一个值得研究的问题。
本文在前述企业级全文检索和相关分布式全文检索方法的基础上,结合分布式消息队列技术,提出一种满足企业级分布式全文检索的模型。
1 总体结构
由于企业级全文检索对权限控制严格要求,结合元搜索引擎的思想,分布式全文检索系统可以分为多个主题,这个主题一般是由人工设定的,例如财务、人事、生产、科研等。这里所述的主题与面向主题的搜索引擎[5]中的概念类似,整个系统可以人为设定或通过聚类算法对文档进行分主题管理,将数据量较大的文档集合拆分为若干个不同主题的文档集。系统针对每个主题都可以进行权限控制,结合其他权限控制方式则可以实现企业级全文检索严格的文档资源访问控制功能。
从逻辑结构上来看,每个主题作为一个相对独立的搜索接口分布在工作节点上,由至少一个工作节点来负责这个主题内文档的处理工作。各个工作节点之间的通信和事务处理分别通过分布式消息队列和分布式协调器来实现。每一个工作节点同时具有处理用户的查询请求、响应其他节点所提交的查询、进行文档索引建立的功能,每个工作节点存储有该节点对应主题的索引分片数据。在查询时不同索引节点上会产生不同的查询结果,然后统一对这些结果集进行合并得到最终查询结果。
由上述结构可以看出,整个系统以一种具有多入口的计算集群的方式提供服务,而通过负载均衡方式对外展示统一的接口。客户机通过这个接口发送查询请求经过负载均衡均匀分布在集群内各个工作节点上以提高系统效率。企业级全文检索系统的总体结构如图1所示。

图1 总体架构图
1.1 分布式消息队列
分布式消息队列是运行在一组通过网络连接的计算机集群上的软件实体,其维护着一个或多个存储消息的队列,并且提供了对消息的发布或订阅操作。使用消息队列进行通信的程序有时又称为消息生产者或消息消费者。分布式消息队列将传统用于进程间通信的方式发展到了集群环境中。当前分布式消息队列的一个主要协议为高级消息队列协议(AMQP),其统一了消息模式,如发布/订阅、队列、事务以及流数据。该协议定义了通过网络发送的字节流数据格式,所以任何实现了该协议的程序都可以进行交互,做到跨语言、跨平台[6]。AMQP中定义了消息的生产者、消息交换器、消息消费者,消息交换器在中间起到了消息的路由以及消息存储的功能,通过消息路由机制可以方便地控制不同主题消息的分发。
在该系统结构中分布式消息队列充当集群中所有节点之间对等通信的桥梁,各个节点通过消息队列发布查询请求、查询结果以及接收查询请求。一般分布式消息队列的消息发布分为同步消息和异步消息两种方式。同步消息方式情况下,消息生产者发布消息后需要等待消息消费者的响应才能完成一次消息通信过程,异步消息方式情况下消息生产者只负责把消息推送至分布式消息队列中,而不需要等待消息消费者的响应。在分布式全文检索的查询过程中使用异步消息模式,各索引节点可以同时进行某一查询请求的处理,这样对于整个系统的吞吐量有更大提高。
1.2 分布式协调器
分布式系统需要一个主控制节点管理集群内各个工作节点的事务处理,保证集群内数据的一致性。分布式协调器可以在一个所有节点对等的集群上实现:① 各节点数据一致性,提供分布式锁服务;② 在部分节点失效的情况下提供服务的能力;③ 实时监测节点情况,处理节点失效、连接超时、链接失效等异常。在分布式系统中保证以上三点非常重要,同时不能由于协调器的性能问题对分布式集群的性能有过大影响。Zookeeper是Google的Chubby的一个开源实现,其为分布式系统提供了一个高效的数据一致性解决方法,并且基于Zookeeper可以实现分布式系统锁功能[7],在此基础上实现分布式事务等功能。
分布式协调器管理着整个集群的元数据,并且保证其一致性,可以在数据变化时通知相关节点。分布式全文检索中的各个工作节点需要在协调器中注册一个对应自己的临时数据节点。利用协调器在客户端会话中断时自动删除临时数据节点的特性来实时监控处理工作节点的失效问题。在某一节点失效的情况下,该节点在协调器中的元数据中一个临时节点会被删除,协调器会立即通知正在等待响应的节点,已发送的查询请求可以实时取消,新来的查询请求不再包含失效的节点。若是在索引建立的时刻某节点失效,可以依据两种策略进行处理,一种是取消该次索引建立,另一种是在消息队列中保存索引建立的消息,待失效节点恢复工作后还可以从之前的消息队列位置开始处理数据。
1.3 工作节点
工作节点是整个系统中用于处理查询请求以及接收用户端请求的计算单元,每个节点对应着一个或多个上述检索主题。也就是说,一个节点通常只处理一个或若干个主题的文档,当建立索引时每个文档根据不同的主题分发到相应节点上进行处理。在同一主题具有多个节点的情况下通过哈希算法将文档均匀地分发给不同节点处理。同理查询时根据用户的权限不同,分发的查询任务不会每个工作节点都进行接收处理。
工作节点中可以采用Lucene作为处理全文检索索引以及查询的基础组件,Lucene具有索引查询效率高,功能强大等特点,并且支持全文检索的查询模型,例如布尔表达式查询。Lucene的主要组成部分包括分词模块(Analysis)、索引模块(Index)和检索模块(Search)[8]。分词模块作为文档数据的预处理组件,具有良好的扩展性,可以方便地使用不同的分词引擎,实现分词结果的优化。索引模块提供了增量索引和批量索引的功能,并且支持近实时搜索,在索引真正写入文件之前即可提供查询功能。检索模块是真正提供查询功能的部分,其不局限于文本查询,还支持复杂的表达式查询功能,可以根据用户构建的检索模型表达式树进行快速的查询。
2 分布式全文检索过程设计
全文检索系统主要包括两个过程:一是索引建立过程,二是查询过程。企业级全文检索系统中文档来源于企业中的各个业务应用系统,各个业务系统中包含数据库数据、文本数据、半结构化表格数据等,文档类型繁多,所以需要考虑文档索引的存储,设计出高效的索引建立以及查询方法。
传统集中式全文检索的索引建立方式比较单一,一般是通过单个接口进行文档的获取和索引建立工作,在效率上会有性能瓶颈。且随着文档数量的增多,集中式的方式扩展性上也会出现很大问题。而分布式全文检索中可以采用更加灵活的调度方式对文档数据进行分发处理,也很容易通过增加节点的方式进行系统的横向扩展。
2.1 全文索引的建立
本文所述分布式全文索引的结构是根据主题进行分片,来源于企业各个应用系统的文档资源通常自然地对应了相应主题。这样的索引分片方法其实属于基于文档的分割方法,每个工作节点上的索引分片相对独立,通过哈希算法将文档分布在对应主题的多个索引节点中。全文索引的建立主要包括的组件有:
1) 文档数据队列:用于存放待索引的文档信息,队列以主题划分,通过消息路由分发不同主题的文档数据,负责不同主题的工作节点在文档工作队列中获取文档信息进行索引建立;
2) 文档数据网关:按时从业务系统中根据需要抽取各类型文档数据放入文档数据队列中;
3) 文档索引引擎:分布在各个工作节点上运行的进程,监听文档数据队列,在有新的文档操作消息到来时进行相应的索引建立、索引更新、索引删除操作,在索引节点中采用Lucene实现基本索引功能,将文档进行文本分词后建立索引文件进行存储。
全文索引建立结构如图2所示,根据这一索引建立结构,可以有效地管理文档索引建立的过程,异步化的方式减小了发生故障的影响。在节点索引建立方面目前最流行的办法是以文档分词后的词语作为索引项进行倒排索引,查询时通过词向量相似度计算算法来获取以相关程度排序的查询结果。如一种基于Lucene实现的采用正相最大匹配分词算法的索引技术[9],可以快速对文档进行分词并建立索引。索引建立后的文件持久化存储在工作节点上提供查询请求。
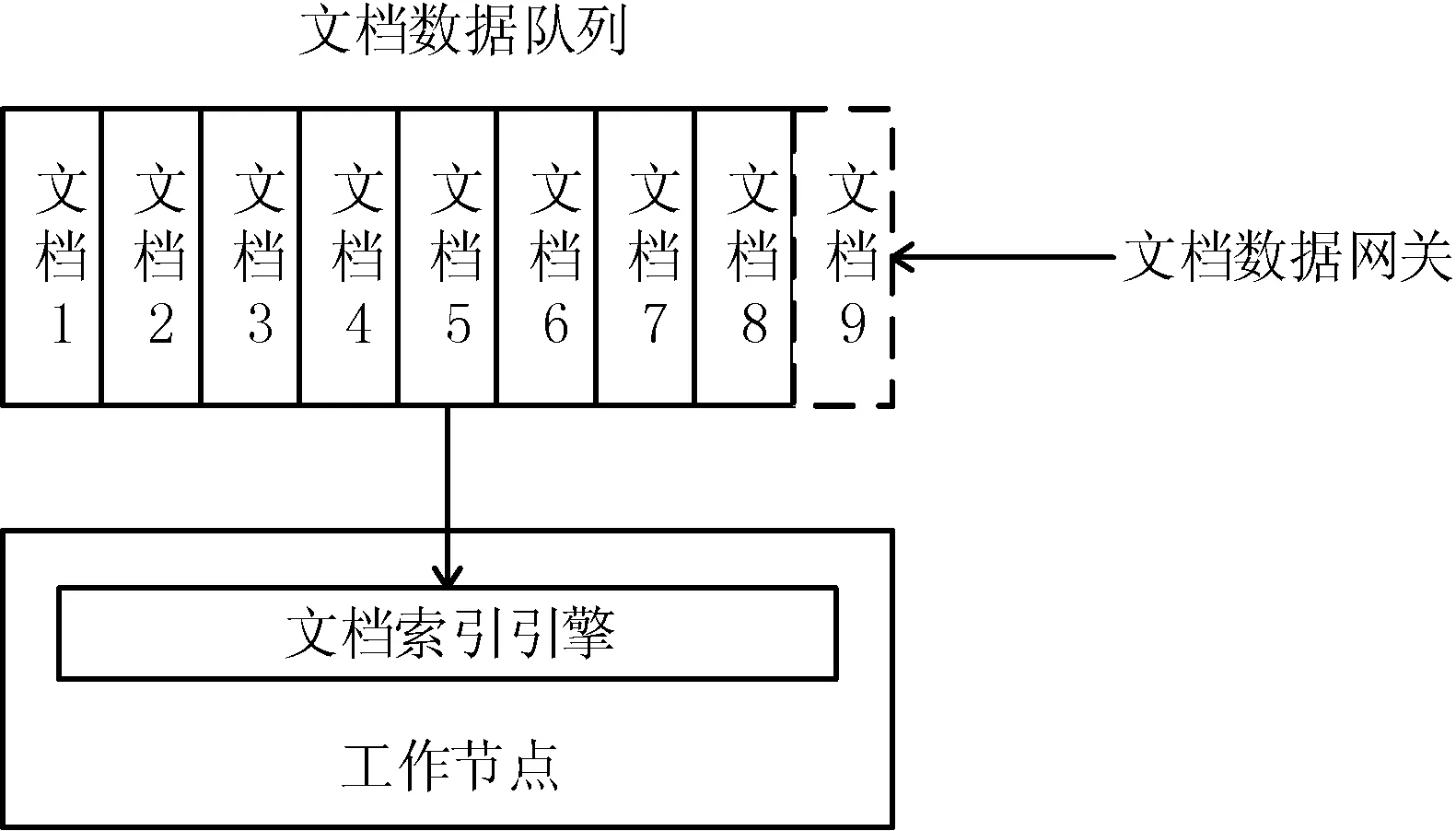
图2 全文索引过程
2.2 全文检索的查询算法
根据索引的分片结构,系统在响应用户查询的时候会根据权限方面的区别向不同的索引服务器发送查询请求,最后根据各个服务器的响应结果集综合排序后返回结果给用户。
在响应用户查询的方式上传统的分布式全文检索需要一个主节点去进行处理,这样的结构会导致主节点的负载过高,不利于分布式集群的扩展,在本文所述的结构中每一个工作节点都可以响应查询。
具体的全文检索查询算法流程如下:
1) 用户向系统发起查询请求,经过负载均衡后用户的请求转发给某一台工作节点,此节点作为临时主节点。
2) 临时主节点接收到查询请求,对此次查询生成一个全局唯一的查询Id,在分布式消息队列中新建以此查询Id为Key的消息队列。
3) 临时主节点验证查询请求中用户的权限信息,向满足权限的查询主题消息队列中添加含有查询Id以及查询请求内容的消息。
4) 临时主节点在分布式协调器中注册以查询Id为名称的数据节点,并在该数据节点下添加各主题对应名字的数据节点用于标识某个主题的查询是否已经成功响应,然后监听各个主题对应数据节点的修改事件。
5) 索引节点通过监听自己所负责的主题队列可以及时获取到临时主节点添加的查询请求,索引节点立即根据线程池的情况分配或新建一个线程对这个查询进行处理。
6) 索引节点的一个线程通过索引引擎获取满足查询的结果列表,然后将该结果列表序列化后发送到与查询Id相对应的消息队列中,形成多个结果集R1,R2,…,RN。最后在分布式协调器中将查询Id对应的数据节点下的主题数据节点标识设置为已完成。
7) 临时主节点在所有节点查询完成或者响应超时的情况下将查询Id相对应的消息队列中结果集合并后发送给用户,完成一次查询请求。
3 算法验证
3.1 验证环境
对于本文研究算法的验证,采用的验证环境是基于虚拟化平台的3台虚拟化集群,其中宿主机和虚拟机的配置分别如下表1、表2所示。

表1 宿主机硬件配置
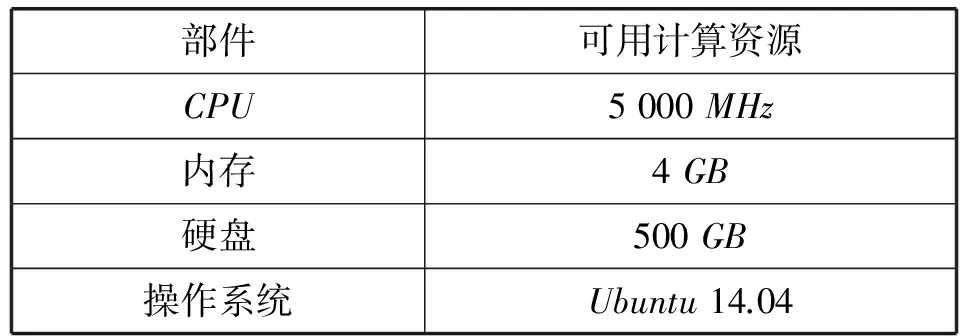
表2 虚拟机计算资源
3.2 算法实现
根据本文所述的分布式全文检索模型以及全文检索查询算法流程,算法实现阶段包括以下工作:
1) 使用RabbitMQ部署分布式消息队列集群,提供分布式消息队列服务;
2) 使用Zookeeper部署了分布式协调器,提供分布式元数据管理以及分布式锁功能;
3) 使用Lucene实现了分布式文档索引引擎,对100GB的企业文档数据进行索引;
4) 结合全文检索算法流程,使用Lucene提供基础索引操作功能以及RabbitMQ客户端和Zookeeper客户端实现了工作节点的功能。
通过算法的实现验证了所提出模型的可行性。
为了与本文所提出的模型进行对比,采用Lucene实现了一个集中式全文检索服务,以单服务器形式部署,同样对100GB的文档进行了索引。
在此基础上进行了集群的性能测试,主要测试分布式全文检索的并发查询性能,分别测试了500至10 000并发请求量下的响应时间。图3为该模型在不同查询并发数下与集中式全文检索的平均响应时间对比。通过性能测试可以看出分布式全文检索在并发请求数上升的情况下也可以保持较为平缓的响应时间增长。
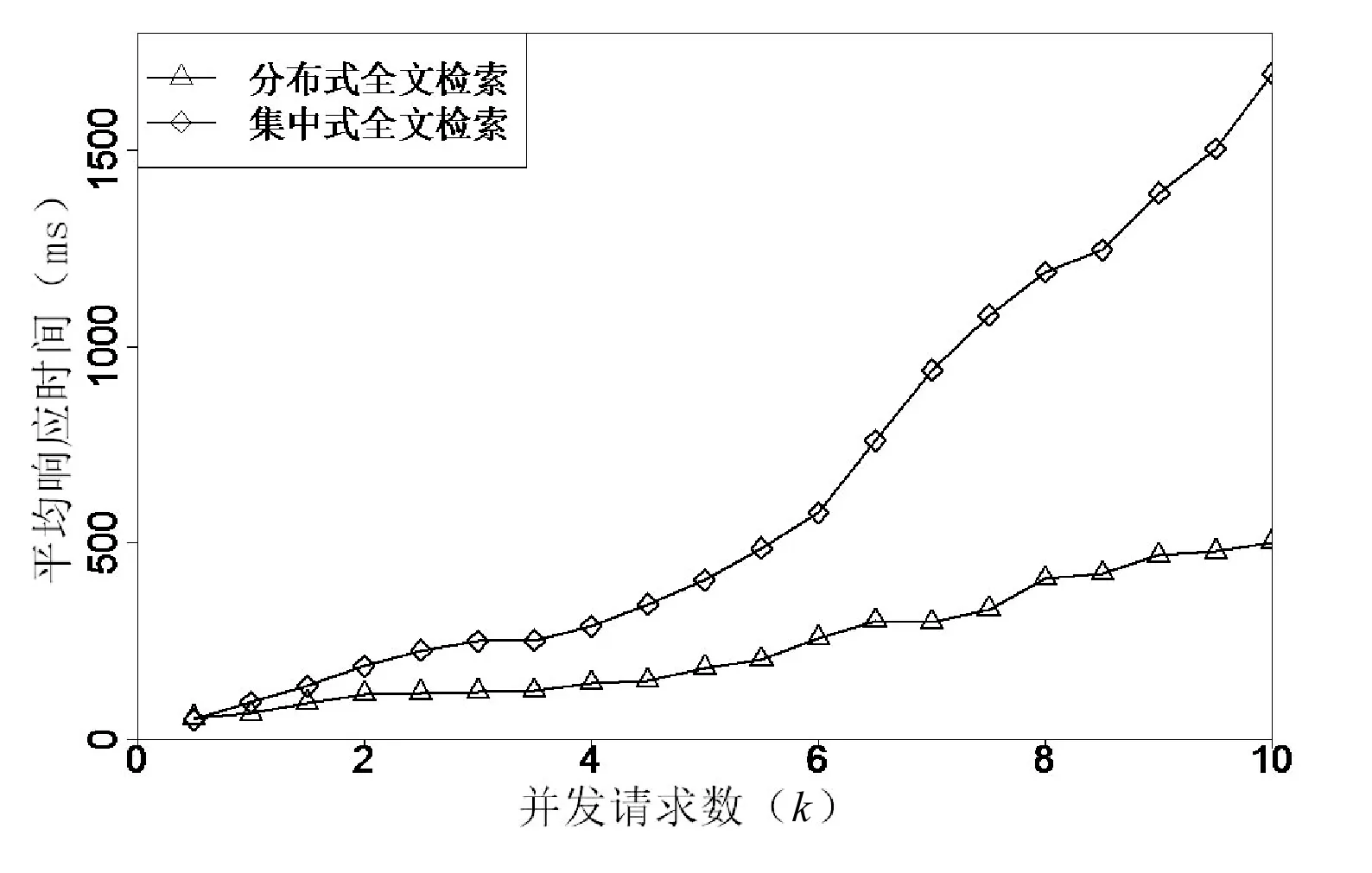
图3 并发性能测试
4 结 语
当前全文检索技术在企业信息化平台中的应用相对较少,并且企业信息化平台中的大量文档数据来源以及企业级全文检索对整合性、安全性、准确性以及查询性能的要求,促使企业级全文检索向分布式方向发展。分布式全文检索系统相较于集中式全文检索系统具有吞吐量大、易扩展等特点,本文提出了基于分布式消息队列构建的企业级分布式全文检索模型。该模型利用分布式消息队列将查询集群中的各个工作节点之间的关系松耦合化,以异步处理的方式对查询请求进行处理,通过验证,该模型可以提高整个集群的查询吞吐量。
[1] 武骏,王雅娜,赵刚,等.企业级搜索的技术特征分析[C]//第二十一届全国计算机信息管理学术研讨会,2007.银川:中国科学技术情报学会,2007:79-83.
[2] 蒋建洪.主要分布式搜索引擎技术的研究[J].科学技术与工程,2007,7(10):2418-2424.
[3] 李广建,黄崑.元搜索引擎及其主要技术[J].情报科学,2002,20(2):175-179.
[4] 薛鹏飞,胡荣贵,胡劲松.基于ZeroMQ的分布式系统通信方法[J].计算机应用,2015,35(S2):34-37.
[5] 姜华.基于Lucene面向主题搜索引擎的研究与设计[D].上海:华东师范大学,2007.
[6] 吴炜鑫,王宇,王兴伟,等.基于AMQP的校园消息总线系统的设计与实现[J].通信学报,2013,34(Z2):180-183.
[7] 刘芬,王芳,田昊.基于Zookeeper的分布式锁服务及性能优化[J].计算机研究与发展,2014(S1):229-234.
[8] 李永春,丁华福.Lucene的全文检索的研究与应用[J].计算机技术与发展,2010,20(2):12-15.
[9] 郑榕增,林世平.基于Lucene的中文倒排索引技术的研究[J].计算机技术与发展,2010,20(3):80-83.
RESEARCH ON ENTERPRISE FULL-TEXT RETRIEVAL MODEL BASED ON DISTRIBUTED MESSAGE QUEUE
Li Zheng Wu Tong
(SchoolofComputerScienceandTechnology,GuizhouUniversity,Guiyang550025,Guizhou,China)
Aiming at the problem of insufficient query performance of traditional centralized full-text retrieval system, this paper proposes a distributed enterprise full-text retrieval model based on distributed message queue construction. The model makes full use of the distributed message queue to couple each node in the query cluster to process the query request in an asynchronous way, and to improve the throughput of the whole cluster. We elaborate the feasibility of the model from three aspects: the overall structure, distributed full-text retrieval algorithm design process, algorithm verification, and the validation results show that it has a good query performance.
Distributed message queue Enterprise full-text retrieval Distributed full-text retrieval
2016-08-17。李政,硕士生,主研领域:数据库技术,数据挖掘技术。武彤,教授。
TP311.133.1
A
10.3969/j.issn.1000-386x.2017.06.052
