基于Bootstrapping的新闻事件型实体关系抽取方法
2017-07-05宋卿戚成琳杨越
宋卿,戚成琳,杨越
(1.中国传媒大学 新媒体研究院,北京 100024;2.中国传媒大学 理工学部,北京 100024)
基于Bootstrapping的新闻事件型实体关系抽取方法
宋卿1,戚成琳1,杨越2
(1.中国传媒大学 新媒体研究院,北京 100024;2.中国传媒大学 理工学部,北京 100024)
新闻所包含核心内容是事件,现有的中文实体关系抽取方法都针对属性型关系,忽略了事件型关系的抽取;新闻内容涉及领域广,要求关系抽取方法具有良好的领域扩展能力;同时,开放域人工标注训练语料库的难度较大。针对上述问题,本文提出Bootstrapping的关系种子集自动生成方法,并在迭代过程中加入扩展和过滤规则,最终得到准确度和复用性较高的实体关系提取模式。通过实验测试,本文提出的方法在事件型实体关系的提取中能够取得良好效果。
关系抽取;事件型关系;Bootstrapping;开放模板
随着媒体行业信息化程度不断加深,互联网已成为媒体机构最重要的宣传阵地,中文新闻网页总量也早已过亿。面对海量的新闻内容,传统的搜索引擎基于关键字匹配和网页重要度排序等方法,虽然在一定程度上能够解决用户查询新闻信息的需求,但仅能提供符合条件的新闻文本,用户仍需要通读全文来获取新闻所包含的事件内容。此外,新闻记者进行新闻报道时,要花费大量的时间从以往相关报道中获取相关知识作为素材。因此,如何帮助用户快速准确的获取新闻文本中所包含的核心内容就成为近几年新闻领域的一个研究热点。
信息抽取(Information Extraction,IE)技术的主要目的是从非结构化自然语言文本中抽取实体、实体关系和事件信息。其中实体关系抽取(Entity Relation Extraction)用于识别实体间的语义关系。例如 “国家主席习近平在中南海会见到访的美国总统奥巴马”一句中,“习近平”和“奥巴马”是其中包含的两个命名实体,而“会见”是两个实体间的语义关系词。我们可以看到:如果信息抽取是将非结构化的自然语言文本表述为结构化的表格数据,而实体识别确定了表格中各个元素的话,那么实体关系抽取则是确定这些元素在表格中的相对位置[1]。总之,实体关系抽取是在实体识别的基础上,将无结构的自然语言文本中包含的实体间的语义关系提取出来,然后以三元组(实体 1、关系、实体 2)的形式存储在数据库中,供用户查询或其他软件系统复用。本文针对中文新闻的特点,提出了一种面向开放领域的中文新闻事件型实体关系抽取方法。
1 研究现状
关系抽取任务最早由MUC[2]会议提出,在后续ACE[3]、TAC[4]测评会议的推动下取得了显著的发展。早期主要采用基于规则的方法,一般针对特定关系类型,由语言专家或领域专家人工编写关系抽取规则集合。如:抽取层次关系,专家通过制定规则集合(Y such as X,such Y as X,such Y as X,X,and other Y,Y including X,Y especially X等)来抽取不同表述形式的层次关系[5]。上述方法非常依赖人工制定规则的质量。优点在于匹配精准,但即便是某一种关系类别,人工也很难穷举所有可能规则。如果有新的关系类型抽取需求,则要重新制定规则,因此基于规则的方法领域移植性较差。
监督学习方法在自然语言处理领域的广泛应用极大的促进了实体关系抽取方法的革新。监督学习类方法又分为两类:1)基于特征向量的方法和基于核函数的方法。基于特征向量方法将关系抽取任务转化成分类问题,根据训练语料库的特点选取有效特征,并构造特征向量,使用条件随机场[6]、最大熵[7]、SVM[8]等不同方法训练关系分类器用于关系预测。该方法性能好坏的关键在于特征选取,不同的领域不同的语料特征选取差别很大,所以移植性较差,但计算复杂度较低;2)基于核函数[9-11]的方法,引入核函数对样例关系和待识别关系之间的相似度进行计算,不需要定义特征集合,通过一个隐含的高维特征空间计算相似度,一方面可以得到更加全面的特征信息,同时也解决了特征方法在特征选取方面存在的问题,但核函数方法的计算复杂较高。监督学习方法相比人工规则的方法有了很大提升,但是还是需要人工进行算法训练语料的标注,往往只针对特定的关系或者特定的领域,难以适应开放领域关系的抽取的要求。
面向开放域的关系抽取,Banko[12]等人最早提出了开放式关系抽取的概念,利用启发式规则和简单的句法特征训练分类器的TextRunner系统,Hasegawa[13]等人在ACL2004提出利用无监督的方法,在假设相同实体关系具有相同的上下文语境的前提下,使用聚类算法对关系进行聚类,但这种方法过于依赖语料的好坏,而且假设也存在问题。哈工大刘安安[14]等人提出无监督开放式的中文实体关系抽取方法主要研究人、机构、地点之间的属性型实体关系开放式描述。Wu F[15]等人提出的WOE系统,使用维基百科中的信息框来标注关系抽取语料,该类方法主要依靠已有知识库,在假设两个实体对应的句子均表示同一种关系的基础上,通过将知识库中已有的关系实例和待标注训练语料进行对齐自动构建训练语料库,后续和监督学习方法一样进行关系抽取分类器的训练和关系的抽取。方法不需要人工过多干预,但是现阶段没有完备可供使用的中文知识库,同时,目前所有的知识库只有属性型关系,缺少新闻需要的事件型关系,无法构建训练语料满足新闻文本中抽取事件型实体关系的要求。因此,我们考虑采用自动的方式生成种子关系集,然后通过自举的方法不断进行新的关系的学习,结合规则的思想,自动生成关系抽取模式,用于新的关系发现与抽取。
2 开放式中文新闻事件型实体关系抽取
面向开放领域的实体关系抽取目前普遍采用弱/远监督的方法,需要借助已有的知识库,OLLIE系统[16]是抽取结果最好的系统,但其仅支持英文,初始种子集依靠ReVerb系统[17]产生。本文针对中文新闻提出自动构建种子集的方法,能够解决中文领域无现成可用的知识库和关系抽取系统的问题。通过多次迭代学习关系抽取模式,以简单的模式为起点,生成更多复杂模式,从而匹配更多的关系,获得比较好的实体关系抽取结果。方法主要分为下面两个部分:新闻文本预处理和新闻事件型关系抽取。

图1 开放式中文新闻事件型关系抽取方法流程
2.1 文本预处理
新闻文本以非结构化形式存在,为了便于后续处理,我们需要进行文本预处理,主要包括以下步骤:
(1)句子分词与命名实体识别。综合考虑分词速度和准确率指标,我们选择Ansj中文分词包(分词速度30万字/秒,准确率大于96%)。输出结果(有词性标注、命名实体标注并且完成分词的句子)将作为句子划分和依存句法分析的基础输入。通过对结果分析发现,命名实体识别存在一定误差,例如“中国传媒大学 食堂 最 受 欢迎 的 菜品 是 广院肉饼”的命名实体识别结果是“中国传媒大学”为机构,但紧邻的“食堂”并没有与紧邻的名词共同识别为一个组织机构,我们期望得到的是“中国传媒大学食堂”作为组织机构名,同时“广院”和“肉饼”也存在类似的情况,因此,我们对ansj的命名实体识别结果进行如下处理:在识别出一个命名实体E1后,如果紧邻这个实体的前后词语是名词N或者命名实体E2,我们就对其标记,在后续得到依存句法分析结果后,如两个词语之间的依存关系满足“ATT关系”,我们则将词语组合的整体为一个命名实体E3(E1E2/E1N)。
(2)复杂句切分。考虑到依存句法分析对复杂长句的分析准确率很低,因此我们考虑对复杂句进行切分,通过对新闻语料的分析,我们选用逗号作为分句的标点符号,遵循以下规则进行复杂句切分:对由一个或多个逗号分隔的复杂长句进行切分,如果任意一个切分结果中的按照前一步进行合并后的名词或命名实体的总数少于2个,则不做切分。
(3)依存句法分析。依存句法分析选用哈工大的语言技术平台云[18],以完成分词、命名实体识别和复杂句切分处理后的文本作为输入,进行依存句法分析,输出依存句法分析结果。
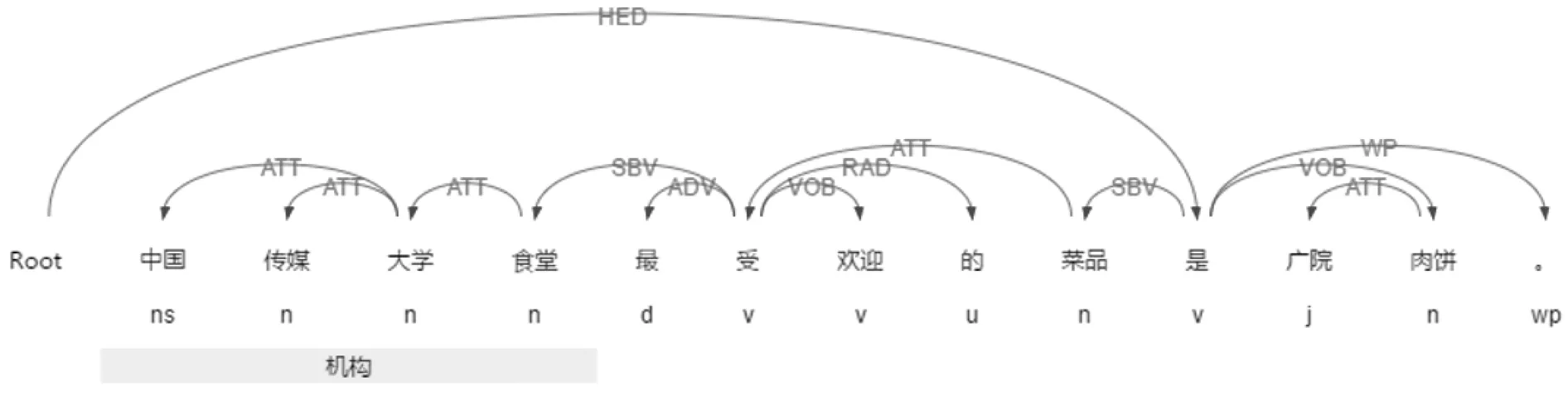
图2 依存句法分析结果
2.2 事件型关系抽取
(1)关系抽取种子集自动生成。对于事件型关系来说,命名实体/名词短语对之间的关系主要是施动和受动的关系,为了保证关系抽取种子集的质量,我们选用最基本的关系抽取规则:依据依存句法分析的输出结果,从依存树中提取主语、谓语、宾语,其中主语和宾语是命名实体/名词短语对,谓语则是与实体对主谓关系的动词/动词短语,进而得到候选的实体关系三元组。考虑到种子集质量对整个关系抽取的重要影响,我们定义以下规则对三元组进行筛选过滤:
•基于停用词表过滤关系无实际意义的关系指示词和名词;
•关系指示词为动补结构时,排除该三元组;
•通过定中关系(ATT)将实体对象补充完整;
基于以上过滤和补充规则,我们可以将满足这些条件的句子中的实体三元组从候选集合中删除或者补充完整,作为后面实体关系提取的种子集。
(2)基于Bootstrapping的事件型关系提取。将种子集中的三元组作为Bootstrapping算法的初始三元组在新闻语料库进行软匹配(句子中包含两个以上三元组元素就匹配成功),对匹配成功的句子抽取实体关系模式,存入模式库,然后选择模式库中频率高的前N项(本实验中N取10)对语料库进行模式匹配,匹配成功则抽取实体关系三元组。Bootstrapping方法的核心在于不断迭代,每次迭代输出的数据作为下次迭代的输入数据,误差会不断被放大,因此对每一次迭代的输入准确性要求较高,通过上一步中三元组过滤规则对迭代结果进行过滤。过滤新获得的实体关系三元组再作为软匹配的种子,不断重复上述过程,直到没有新的实体关系三元组产生为止。

Bootstrapping算法伪代码
3 实验结果与分析
(1)测试集获取:目前没有公开的面向开放领域的中文新闻关系抽取语料库,我们在新华社新闻库中选取1000篇新闻文章(国内政治领域300篇,国际政治领域200篇,体育领域100篇,科技领域50篇,历史领域100篇,财经领域50篇,军事领域100篇,社会领域100篇),采用交叉标注的方式对新闻中所包含的事件句进行人工标注。
(2)实验设计与实现:利用已构建种子集中实体关系三元组作为输入,采用Bootstrapping方法进行开放模版的学习,表1中我们列举了出现频率最高的三个开放模版,模版符合下列条件:
•依存树路径中没有空节点;
•关系表示节点位于实体之间;
•如果模版的介词需要和关系中的介词匹配;
•依存树路径中不能存在名词组合或形容词修饰的关系边。
最后,就可以使用开放模版从待抽取关系的新闻文本中识别实体关系三元组。
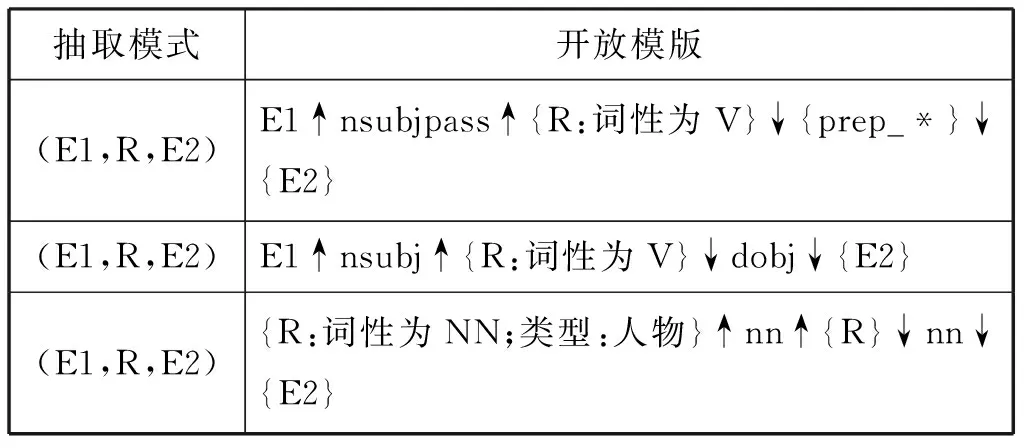
表1 开放模板示例
(3)实验结果与分析
从测试集中随机抽取100个句子进行实验,实验结果如下:
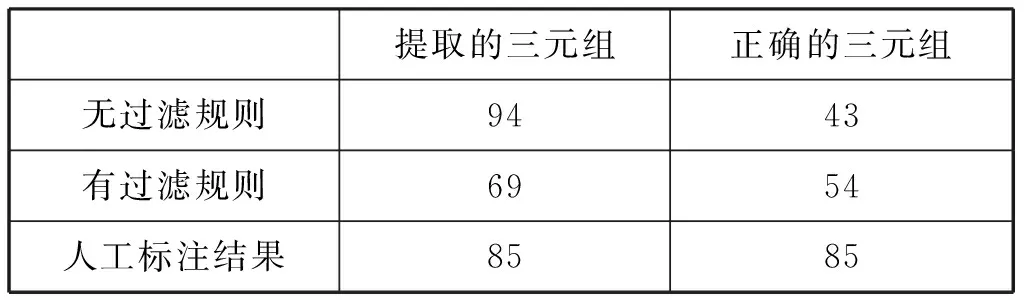
表2 实验关系三元组抽取结果

表3 实验的召回率、准确率、F值
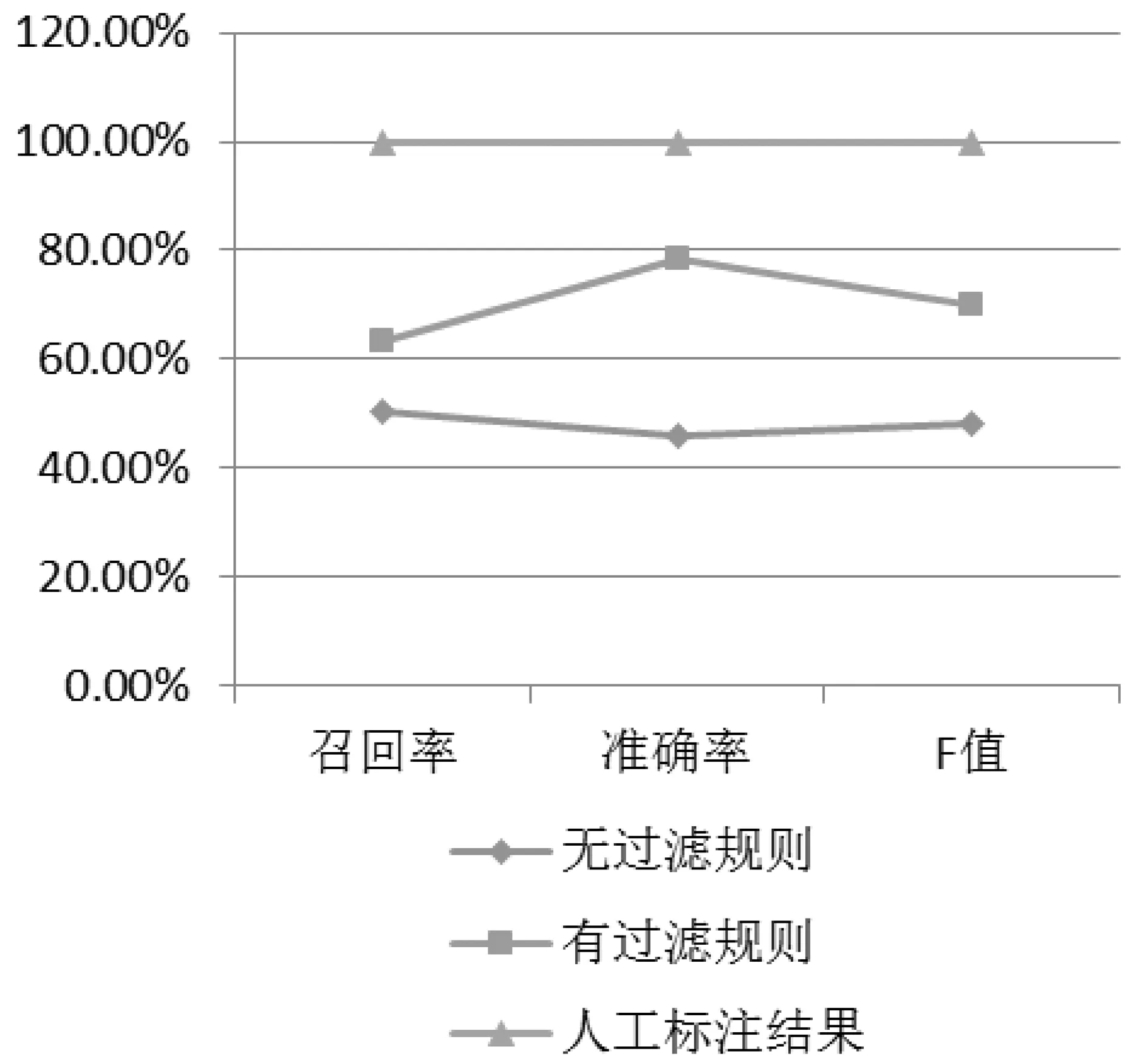
图3 召回率、准确率、F值
从实验结果中可以看出,引入了过滤规则后,算法的准确率得到大幅提高。
4 总结
本文自动从中文新闻文本中抽取实体关系的算法是在OLLIE系统方法的基础之上进行改进的。本文自动构建初始种子集,并通过过滤规则的设定控制了自举算法每次迭代的误差,对最终结果准确率的提高切实有效。接下来将会对方法进行优化,在实体关系抽取基础之上,进一步研究对时间、地点等关系属性值的抽取。
[1]车万翔,刘挺,李生.实体关系自动抽取[J].中文信息学报,2005,19(2):1-6.
[2]Chinchor N.Overview of MUC-7[J].Seventh Message Understanding Conference(MUC-7):Proceedings of a Conference held in Fairfax,VA,1998.
[3]ACE[EB/OL].http://www.nist.gov/speech/tests/ace.
[4]TAC[EB/OL].http://www.nist.gov.tac/203/KBP.
[5]M A Hearst.Automatic acquisition of hyponyms from large text corpora[J].Proceedings of the 14th conference on Computational linguistics-Volume 2,539-545,Association for Computational Linguistics,1992.
[6]Culotta,Aron,Andrew McCallum,Jonathan Betz.Integrating probabilistic extraction models and data mining to discover relations and patterns in text[J].Proceedings of HLT-NAACL,2006.
[7]Kambhatla N.Combining Lexical,Syntactic,Semantic Features with Maximum Entropy Models for Extracting Relations[C].ACL,2004.
[8]Mooney R J,Bunescu R C.Subsequence kernels for relation extraction[C].advances in neural information processing systems,2005,171-178.
[9]Zelenko D,Aone C,Richardella A.Kernel methods for relation extraction[J].The Journal od Machine Learning Research,2003(3):1083-1106.
[10]Zhao S,Grishman R.Extracting relations with integrated information using kernel methods[C].Proceedings of 43rd annual Meeting on Association for Computational Linguistics,2005,419-426.
[11]Qian L,Zhou G,Kong F.Tree Kernel-Based Semantic Relation Extraction using Unified Dynamic Relation Tree[C].Advanced Language Processing and Web Information Technology,ALPIT’08 International Conference,2008,64-69
[12]M Banko,M Cafarella,S Soderland,M Broadhead,O Etzioni.Open information extraction from the Web[J].Procs of IJCAI.
[13]Hasegawa T,Sekine S,Grishman R.Discovering Relations among Named Entities form Large Corpora[C].Proc of ACL-2004,2004,415-422.
[14]刘安安.无指导的开放式中文实体关系抽取[D].哈尔滨工业大学,2013.
[15]Wu F,Weld D S.Open information extraction using Wikpedia[J].ACL ’10 Proceedings of the 48th Annual Meeting of the Association for Cimputational Linguistics,2010,118-127.
[16]Mausam,Michael Schmitz.Open Language Learning for Information Extraction[J].
[17]Oren Etzioni,Anthony Fader,Janara Christensen,Stephen Soderland,Mausam.Open information extraction:the second generation[J].Proceedings of the International Joint Conference on Artificial Intelligence,2011.
[18]Che W,Li Z,Liu T.LTP:A Chinese Language Technology Platform[J].Proceedings of the Coling 2010,8,13-16.
(责任编辑:宋金宝)
News Event Relation Extraction Approaches Based on Bootstrapping
SONG Qing1,QI Cheng-Lin1,YANG Yue2
(1.New Media Institute,Communication University of China,Beijing 100024,China2.Faculty of Science and Technology,Communication University of China,Beijing 100024,China)
Event is the core content of the news.The entity relation extraction methods,which have been obtained,can only be used for extracting property relations.And the work on event relation extraction is neglected;News contents involving a wide range of fields,require the relation extraction method has domain expansion capability;and it is difficult to annotate the training corpus.To solve the above problems,we proposed an automatic seed set generation method of bootstrapping,and add the extension and filtering rules throughout the iteration,finally get entity relation extraction template with accuracy and reusability.The experimental results show that the method proposed in this paper can achieve good results in the extraction of event entity relation.
relation extraction;event relation;Bootstrapping;open template
2017-04-15
北京市科委项目(Z161100000216141);中国传媒大学工科规划项目(3132016XNG1605)
宋卿(1982-),男(汉族),贵州人,中国传媒大学博士研究生、讲师.E-mail:songqing@cuc.edu.cn
TP391.1
A
1673-4793(2017)04-0046-05
