基于MFCC的混响效果识别研究
2017-07-05马赛谢茜刘嘉胤
马赛,谢茜,刘嘉胤
(1.中国传媒大学 媒介音视频教育部重点实验室,北京 100024;2.山东省烟草公司信息中心,济南 250101)
基于MFCC的混响效果识别研究
马赛1,谢茜1,刘嘉胤2
(1.中国传媒大学 媒介音视频教育部重点实验室,北京 100024;2.山东省烟草公司信息中心,济南 250101)
直达声/混响声能量比(Direct-to-Reverberant Ratio,DRR)和混响时间(Reverberation Time,RT)是判断混响效果的两个重要参数。针对合成有声语音及元音EH,在给定的混响时间下,提取不同直达声/混响声能量比的混响语音信号的MFCC(Me-Frequency Cepstral Coefficients)特征,分别对其进行混响效果识别的10折交叉验证。利用高斯混合模型对训练集进行聚类分析,得到其概率分布函数,通过马氏距离(Mahalanobis Distance,MD)计算测试集的每个样本的混响效果概率,进而判断其混响效果等级。实验结果证明,合成有声语音基于MFCC的混响效果识别准确率可以达到90%以上,元音EH可以达到80%以上。
混响;MFCC;交叉验证;高斯混合模型
1 引言
语音通过声道产生,声道可以看作改变声带振动频谱形状的滤波器。当声带处于发声状态时生成有声语音,发声状态指声带绷紧并周期振动,声道滤波器被周期脉冲激励,产生的语音波形具有准周期性;当声带处于无声状态时生成无声语音,无声状态指声带不振动,声道滤波器被噪声源激励,产生的语音波形无规则[1][2]。语音信号生成的源-滤波器模型(Source-Filter Model,SFM)[3]如图1所示,声带的两种状态通过切换开关实现,声道通过时不变滤波器模拟,滤波器参数可以对语音信号进行线性预测分析获得[4]。本文只关注有声语音信号。
混响存在于任何封闭环境中。当语音信号在房间等封闭环境中传播时,房间的声学属性使语音信号产生失真,这些属性包括房间的尺寸,声音的反射路径和墙壁的吸声系数等,这种失真的语音信号称之为混响语音信号。混响不仅能够影响语音信号的质量和清晰度[5][6],其作用还涉及到很多其他的实际应用方面,比如降低自动语音识别(Automatic Speech Recognition,ASR)系统的性能[7],干扰学生的课堂学习质量[8],妨碍耳蜗佩戴者的听觉感知[9]等等。因此,混响效果的判断对于语音应用的各个领域具有重要意义。
声像源模型(Image-Source Model,ISM)[10]是一种常用的混响语音信号处理模型,很多声学相关领域的研究工作都是基于ISM进行的,例如盲源分离[11],信道识别与均衡[12],声源定位与追踪[13],语音增强[14],语音识别[15]。通过ISM生成的房间脉冲响应(Room Impulse Response,RIR)函数代表声源与麦克风之间的系统传递函数,许多混响参数可以通过RIR预测获得,其中直达声/混响声能量比(Direct-to-Reverberant energy Ratio,DRR)[16]和混响时间(Reverberation Time,RT)[17]是房间混响特性的两个重要指标。DRR是声源直接到达麦克风的声音能量与经各种反射到达的声音能量之比,是对声源距离感知的主要线索;RT指声源停止发声以后声压级衰减60dB所用的时间,是声学环境的基本属性。
本文提出了一种基于MFCC特征的混响效果识别算法。在给定的RT下,以DRR代表不同混响效果等级,提取混响语音信号的MFCC特征,以高斯混合模型对其进行聚类分析,通过10折交叉验证检验基于MFCC的混响效果识别的有效性。本文结构如下:第二部分介绍合成有声语音和元音EH的混响语料库;第三部分介绍混响效果识别算法结构;第四部分介绍混响效果识别实验结果;第五部分为本文结论。

图1 语音信号源-滤波器模型
2 混响语料库
2.1 房间脉冲响应函数
通过ISM生成不同的房间脉冲响应函数。混响时间是房间尺寸的近似函数(常系数反射时),选择三组不同的混响时间,如RT=300ms,RT=600ms,RT=1000ms,改变声源与麦克风距离(Source-Microphone Distance,SMD)使得DRR的范围从15dB到0dB(3dB步阶),如表1所示。模拟房间尺寸为长×宽×高=9×4×6m3,共得到18个房间脉冲响应函数。
2.2 合成有声语音信号
利用线性预测模型分析一段纯净语音信号,为了获得更好的谐波结构以描绘声道的谐振特性,选择基频在100Hz左右的短时语音信号。为了不失一般性,选择3种线性预测分析阶数,分别为=12,20,28。通过3组线性预测分析系数构成的全极点滤波器模拟声道响应函数,即获得3个声道模型。根据人类基频范围[18],我们选择基频为150到350Hz(50Hz步阶,共5个基频)对应周期的脉冲序列作为有声语音激励信号作用于声道模型,合成语音信号的持续时间控制在5秒,期间没有停顿或者静音,一共可以获得3×5=15个合成有声语音信号。全极点滤波器是零状态滤波器,为了排除滤波器起始与终止响应的影响,我们从50ms开始采集,在4.55s停止采集,即最后所得到的合成语音信号长度控制在4.5秒。

表1 SMD及相应DRR
2.3 合成元音EH
因为女性元音EH的频谱结构与所获得的声道模型较为接近,选择其作为含有语义的研究实例,通过共振峰级联滤波器的方法进行合成,其中女性元音EH的参数如表2所示。

表2 女性元音EH参数
从共振峰的频率到带宽有三套经验公式[19][20],本文选择对前三个共振峰频率最准确的一组
B1=15*(500/F1)2+20*(F1/500)1/2
+5*(F1/500)2
(1)
B2=22+16*(F1/500)2
+12000/(F3-F2)
(2)
B3=25*(F1/500)2+4*(F2/500)2
+10*F3/(Fa-F3)
(3)
其中,女性Fa=3700。
通过纯净语音信号与房间脉冲响应函数的卷积获得混响语音信号,对于有声语音信号,共有15*18=270个混响语音;对于女性元音EH,共有18个混响语音。使用前3s的有声混响语音,混响元音EH的长度控制在2.5~3s之间。至此,本文所需混响语料库构造完成。
3 混响效果识别算法设计
在给定的混响时间下,根据不同的DRR为混响语音信号添加混响效果等级标签,分帧(帧长25ms)提取混响语音信号的MFCC(12阶)特征,与对应标签共同构成数据集。将该数据分为训练集(training dataset)与测试集(test dataset),利用高斯混合模型对训练集进行训练,得到训练集在不同混响效果等级下的概率分布函数。计算测试集与不同混响效果等级概率分布函数的距离得到测试集属于某混响效果等级的最大似然概率,对测试集数据所属混响效果等级进行判断,通过与测试集混响效果等级标签的对比,得到混响效果识别的准确率,算法流程如图2所示。

图2 混响效果识别算法流程
假设有种混响效果等级,分别对其用模型数为M=(M=16)的高斯混合模型[21]进行训练,得到第n种等级的高斯混合模型中每个聚类的概率密度函数为
gn(xn|μni,∑ni),λn={ωni,μni,∑ni},i∈M
(4)
马氏距离(MahalanobisDistance)[22]用来测量一个离散点与一个分布的距离,测试集为Y={y1,…,yl},其中第l个测试样本到第n种高斯混合分布中第i个聚类的马氏距离为
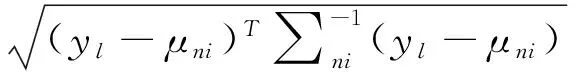
(5)
则测试样本属于该聚类的概率定义为
Plni=e-MDlni
(6)
测试样本yl属于第n种高斯混合分布的概率即为属于各聚类概率的加权和
(7)
该测试样本的混响效果等级判断为
Levell=argmax{Pl1,…,Pln}
(8)
由此完成对所有测试样本所属混响效果等级的识别,并与测试集标签作对比,得到识别准确率。
交叉验证一种模型验证方法[23],将对统计过程的判断引用到独立数据集。本实验采取10折交叉验证的方法,将混响语音特征矢量随机划分成10个大小相等的子样本,其中9个样本作为训练集,1个样本作为测试集。交叉验证过程重复10次,保证每个样本都遍历一次测试集,将10次验证结果取平均值,作为混响效果识别的最终结果。
4 混响效果识别实验结果
实验环境:MATLAB2011b,DellVostro220s台式计算机,2.6GHzPentium(R)Dual-CoreE5300处理器,2GB内存。迭代时间定义为完成一次10折交叉验证的运算时间。
4.1 有声语音信号混响效果识别
将合成的有声混响语音信号根据混响时间分为三组:RT=300ms,RT=600ms,RT=1000,为了获得更好的统计效果,我们将10折交叉验证实验重复100次。以MFCC为特征的混响效果识别准确率和迭代时间的100次交叉验证结果如表3所示。
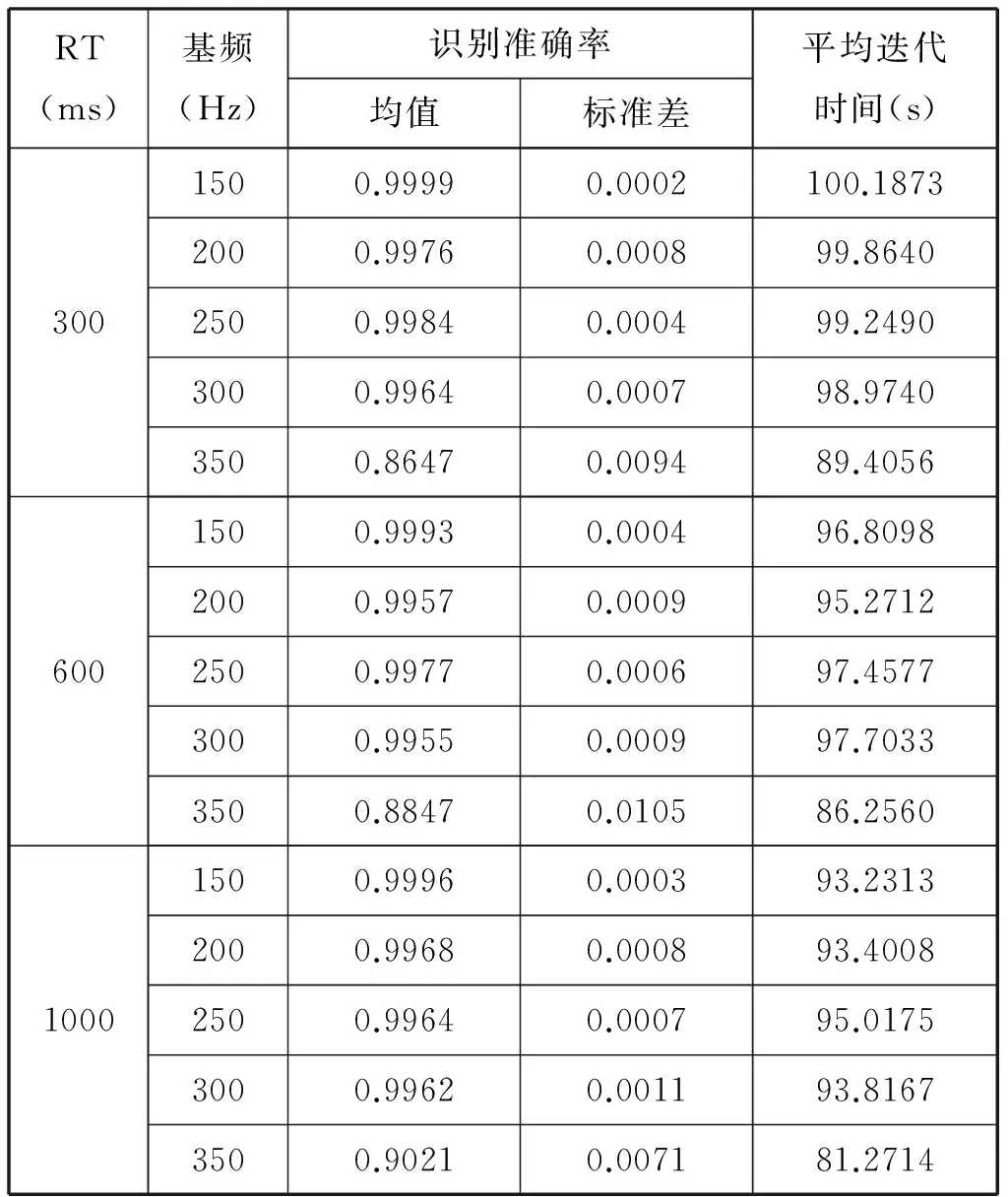
表3 有声语音MFCC混响效果识别准确率与迭代时间
4.2 元音EH混响效果识别
同样按照混响时间分为三组,分别为RT=300ms,RT=600ms,RT=1000ms。与有声语音的验证过程相同,分别将10折交叉验证重复100次以获得更好的统计结果。将混响效果识别的100次交叉验证的准确率作为参量,可以得到识别准确率的概率分布如图3所示。
可以明显看出其服从自由度是99的t分布,置信度是90%的置信区间与100次交叉验证的平均迭代时间如表4所示。
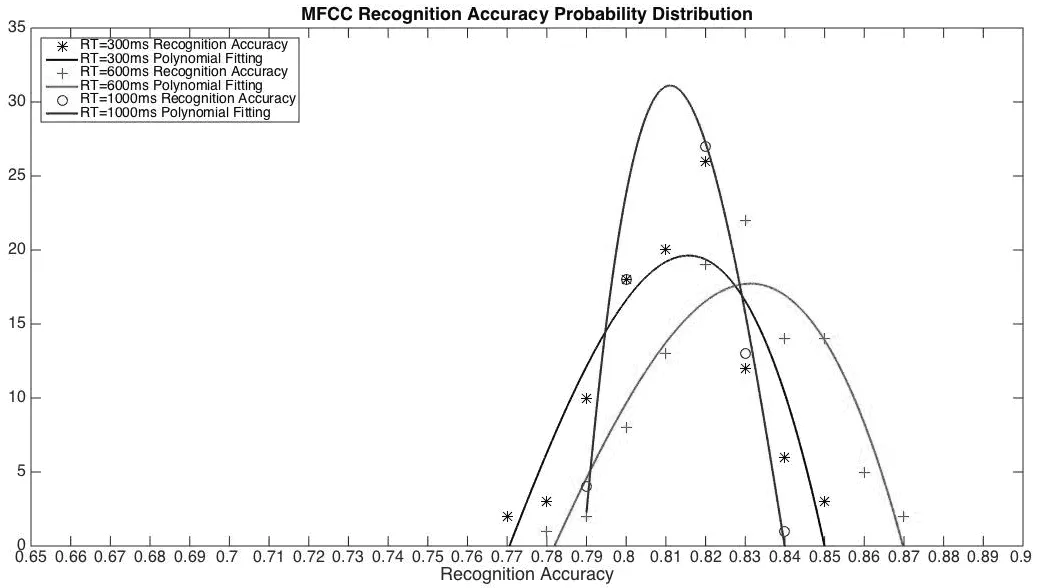
图3 MFCC混响效果识别准确率概率分布
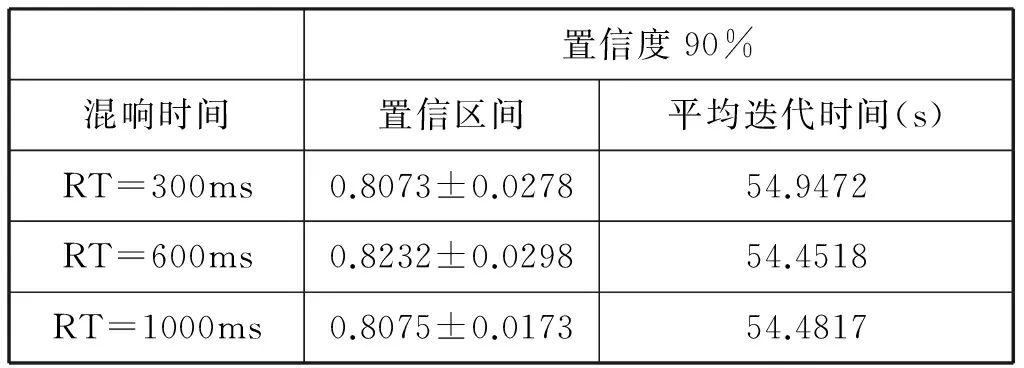
表4 元音EH混响效果识别准确率与迭代时间
5 结论
MFCC可以有效的用于混响效果识别,对合成有声语音其识别准确率在90%以上,对合成元音EH其识别准确率在80%以上,本文算法可以与语音信号去混响以及语音质量/清晰度客观评价等方面的研究进一步结合。但是,对于有声语音信号,当基频提高至350Hz时,MFCC的识别准确率有一个明显衰减,其对于高基频的语音信号表现不够稳定。另外,由实验结果可以看出MFCC的识别迭代时间较高。如何在保证识别准确率的情况下获得更稳定的表现,以及降低识别过程的运算成本是下一步研究工作的重点。
[1]Dimitar D D.Acoustic Model and Evaluation of Pathological Voice Production [C].3rd Conference on Speech Communication and Technology EUROSPEECH,Berlin,Germany,1993:1969-1972.
[2]Abberton E R M,Howard D M,Fourcin A J.Laryngographic assessment of normal voice:A tutorial [J].Clinical Linguistics & Phonetics,1989,3(3):281-296.
[3]Fant G.The source filter concept in voice production [J].STL-QPSR,KTH,1981,22(1):21-37.
[4]Vaidyanathan P.The theory of linear prediction [J].Synthesis Lectures on Signal Processing,2007,2(1):1-184.
[5]Nábělek A K,Letowski T R,Tucker F M.Reverberant overlap and self‐masking in consonant identification[J].Journal of the Acoustical Society of America,1989,86(4):1259-65.
[6]Kokkinakis K,Loizou P C.The impact of reverberant self-masking and overlap-masking effects on speech intelligibility by cochlear implant listeners(L)[J].Journal of the Acoustical Society of America,2011,130(3):1099-1102.
[7]Kinoshita K,Delcroix M,Yoshioka T,et al.The reverb challenge:A common evaluation framework for dereverberation and recognition of reverberant speech[C].Applications of Signal Processing to Audio and Acoustics,IEEE,2014:1-4.
[8]Crandell C C,Smaldino J J.Classroom Acoustics for Children With Normal Hearing and With Hearing Impairment[J].Lang Speech Hear Serv Sch,2000,31(31):362-370.
[9]Hazrati O,Loizou P C.The combined effects of reverberation and noise on speech intelligibility by cochlear implant listeners[J].International Journal of Audiology,2012,51(6):437-443.
[10]Allen J B,Berkley D A.Image method for efficiently simulating small‐room acoustics [J].Journal of the Acoustical Society of America,1979,65(4):943-950.
[11]Ikram M Z,Morgan D R.A multiresolution approach to blind separation of speech signals in a reverberant environment[C].2001 IEEE International Conference on Acoustics,Speech,and Signal Processing,2001,5:2757-2760.
[12]Radlovic B D,Williamson R C,Kennedy R A.Equalization in an acoustic reverberant environment:robustness results [J].IEEE Transactions on Speech & Audio Processing,2000,8(3):311-319.
[13]Lehmann E A,Johansson A M.Particle Filter with Integrated Voice Activity Detection for Acoustic Source Tracking [J].EURASIP Journal on Advances in Signal Processing,2007,Article ID 50870,11pages.
[14]Aarabi P,Shi G.Phase-based dual-microphone robust speech enhancement [J].IEEE Transactions on Systems Man & Cybernetics-Part B:Cybernetics,2004,34(4):1763-1773.
[15]Kalle J.Palomäki,Brown G J,et al.A binaural processor for missing data speech recognition in the presence of noise and small-room reverberation[J].Speech Communication,2004,43(4):361-378.
[16]Jeub M,Nelke C,Beaugeant C,et al.Blind estimation of the coherent-to-diffuse energy ratio from noisy speech signals[C].2011 European Signal Processing Conference,IEEE,2011:1347-1351.
[17]Lehmann E A,Johansson A M,Nordholm S.Reverberation-Time Prediction Method for Room Impulse Responses Simulated with the Image-Source Model[C].2007 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics,2007:159-162.
[18]Peterson G E,Barney H L.Control Methods Used in a Study of the Vowels [J].Journal of the Acoustical Society of America,1952,24(1):175-184.
[19]Fant G.Vocal Tract Wall Effects,Losses,and Resonance Bandwidths [J].STL-QPSR,1972,13(2-3):28-52.
[20]Fant G.the Vocal Tract in Your Pocket Calculator [J].STL-QPSR,1985,1:001-019.
[21]Dr D R.Gaussian Mixture Models [J].Encyclopedia of Biometrics,2008,03(4):93-105.
[22]Xiang S,Nie F,Zhang C.Learning a Mahalanobis distance metric for data clustering and classification [J].Pattern Recognition,2008,41(12):3600-3612.
[23]Kohavi R.A study of cross-validation and bootstrap for accuracy estimation and model selection[C].IJCAI’95 Proceedings of the 14th international joint conference on Artificial intelligence,1995,2:1137-1143.
(责任编辑:王谦)
Reverberation Level Recognition Based on MFCC
MA Sai1,XIE Xi1,LIU Jia-yin2
(1.Key Laboratory of Media Audio & Video,Ministry of Education,Communication University of China,Beijing 100024,China;2.Information Center of Shandong Tobacco Company,Jinan 250101,China)
Direct-to-Reverberant energy Ratio(DRR)and Reverberation Time(RT)are the primary parameters for reverberation strength judgement.Given some selected RT,cluster reverberant synthesized voiced speech and vowel EH at different DRR based on MFCC,and use 10-fold cross validation for reverberation level recognition,respectively.Train the training dataset by Gaussian Mixture Model to obtain the probability distribution,and calculate the test dataset probability via Mahalanobis Distance in order to achieve the recognition purpose.Experiments show that reverberant voiced speech recognition accuracy is higher than 90%,and reverberant vowel EH is higher than 80%.
reverberation;MFCC;cross validation;gaussian mixture model
2017-04-13
马赛(1980-),男(汉族),山东寿光人,中国传媒大学助理研究员.E-mail:saima@cuc.edu.cn
TN912.3
A
1673-4793(2017)04-0018-06
