一种基于朴素贝叶斯的内容选择方法
2017-07-05龚隽鹏曹娟
龚隽鹏,曹娟
(1.中国传媒大学理工学部,北京 100024;2.中国传媒大学新媒体研究院,北京 100024)
一种基于朴素贝叶斯的内容选择方法
龚隽鹏1,曹娟2
(1.中国传媒大学理工学部,北京 100024;2.中国传媒大学新媒体研究院,北京 100024)
主要研究通过语料库自动学习特定领域的内容选择方法。我们基于语料库提出了选择的内容特征,通过朴素贝叶斯方法训练出一个内容选择模型。实验标明,该方法在特定领域的内容选择任务中可以取得较好的效果。
内容选择模型;朴素贝叶斯;内容特征
1 引言
内容选择是自然语言生成中的一个重要任务。在自然语言生成系统中,我们通常将特定某一次内容生成的上下文称为场景Scenarios。不同的场景,生成的文本也相应不同。在某场景下,提供的信息通常和领域、用户等不同的内容相关,我们将选择恰当的信息提供给用户的过程叫做内容选择。
表1是一个内容选择的实例,对于出现的概念实体包括天空遮蔽情况、降雨概率、降雪概率和风向,每个概念对应了1到多个实例;表格第一列标明概念是否选中;表格第二列标明所属概念;表格第三列标明实例的属性及其取值。其输入可看作是一个概念的名-值对的集合Set〈topic,propertySet〉,输出是一个被选中的概念名-值对的子集Setselected〈topic,propertySet〉,从集合Set〈topic,propertySet〉到集合Setselected〈topic,propertySet〉的过程就是一个内容选择过程。其中子集Setselected〈topic,propertySet〉就是包含了最终向用户需要交付的信息,决定了最终生成的文本。
因此,我们可以将内容选择的过程看作是一个分类的问题或者是一个序列标注的过程。
如果将内容选择的过程单纯考虑成一个分类的过程,我们的任务就是对输入的名-值对集合Set〈topic,propertySet〉中的每一条记录进行简单的{selected,unselected}二分类的标注。内容选择的问题也由此转换为分类问题,对于每个概念实体实例的二分类标注。但事实上,对于某些受限领域的内容选择,也可以考虑成对一般文档的多标签标注[1],在本节中,我们主要考虑二分类的标注问题。
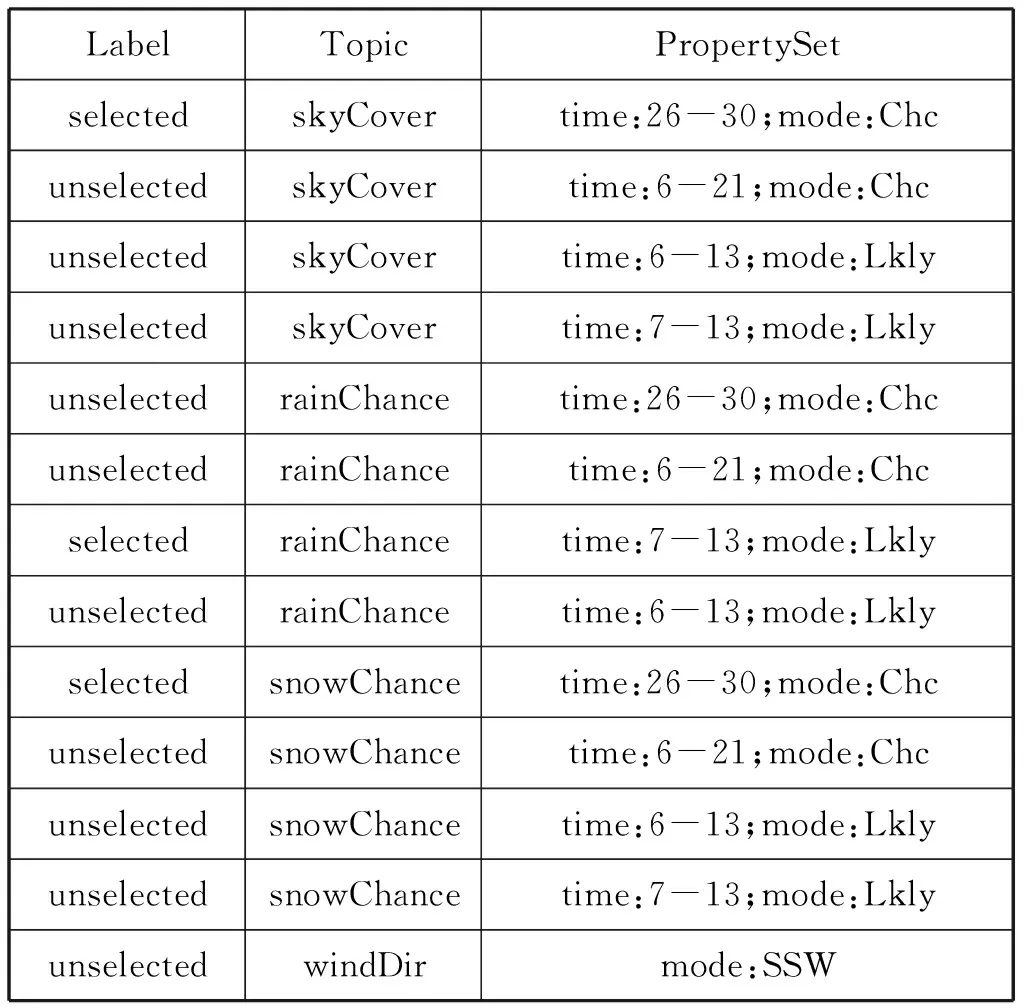
表1 内容选择实例
2 相关工作
与人类在用自然语言交流时总是先想好说什么类似,内容选择在自然语言生成的系统中总是作为第一个模块出现。Sripada[2]的工作指出,相较于文字拼写等其他错误,文本中信息的不恰当是用户更不能接受的。
在早期经典的内容选择方法中,内容选择的问题通常被考虑成真正内容索要陈述的内容和描述内容的结构两个方面。Moore[3]的工作将内容选择的算法和文档结构的算法集成在一起进行考虑。文献[2,4,5]将内容选择和文档结构的工作看作一个流水线工作的两个阶段。
近些年来,出现了很多使用机器学习的方法,直接研究端到端的工作。Konstas[6]的工作研究了一个直接从语料库训练文本生成模型,直接完成内容选择和文本生成的工作。Shang[7]研究定义了一个深度学习网络,通过语料训练了一个语义编码器,自动生成自然语言。
是否将内容选择的问题作为一个独立问题解决,需要根据不同的场景单独思考。在ILEX的工作中,内容选择的查询一次性的给出了用户、物品和文章结构的相关信息。但是,如果要将机器学习的技术应用到相应的场景下,这也要求算法中要预置例如RST等更多的信息,这意味着大量的标注工作,也为算法在不同领域的迁移使用带来了问题。因此,我们将内容选择和用户模型等内容进行分解,单独考虑内容选择。
3 内容选择算法
本文提出的内容选择算法框架如图 1 所示。主要思想如下:在首先根据数据集进行结构特征的计算,并训练相应的分类器。最后,对于特定场景,可通过分类器得到最终结果。

图1 算法框架示意图
3.1 朴素贝叶斯模型
朴素贝叶斯算法基于贝叶斯定理[8],是利用统计学的分类方法,我们假设topic的特征项之间是相互独立的,利用概率求topic的类别。topic的最终类别是由概率的最大值所在的类别指定。
我们假设话题d={w1,w2,...,wm},使用该算法实现对文本d的分类,转化成对P(Ck|d),其中1≤j≤n的求解,如果
P(ck|d)=max{P(c1|d)P(c2|d),…,
P(cn|d)}
(1)
则d属于ck。
计算公式如下:
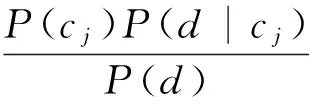
(2)

3.2 特征选择
在传统的内容选择的工作中,内容选择的方法是通过定义一个内容选择的规则集合RuleSet。如果从监督学习系统的角度考虑,系统通过语料库学习到相应的内容选择规则RuleSet,特别的,在监督学习系统中,我们可以将这些RuleSet看作样本的某种特征。
对于所有的内容选择规则Rule,我们可以认为是一个关于结构数据的函数f,函数f将话题映射到至取值为{True,False}的二值空间。是否包含某一知识节点的决策过程,不考虑外部的领域知识库DomainKnowledge和用户知识库Userknowledge,仅由输入的语料数据决定。规则通常是对实例节点本身的取值进行判定,例如:一个异常的温度通常是值得报道的。但有的时候规则也受其相关的节点的内容影响,例如:如果报道了降雨,通常也会报道降雨的数量。
通过对语料库进行分析和验证后,使用如表2的限定规则。

表2 内容选择特征
与话题节点间关系相关的规则。
Topic规则主要获取宏观层面的内容选择特征。对于每一个话题选择,
f2主要获取话题结构方面的内容选择信息。例如,我们可以学习到在描述风向后,通常会紧接着秒速风速。
f1主要捕获话题的共现情况,例如,降水概率可能和雨夹雪共同出现的概率可能很低。
与话题节点相关的规则。
f3主要体现当前话题类型出现的概率情况,例如,降水出现的概率很大,通常是会被提到的。
与话题节点属性相关的规则
f4主要体现不同取值情况下,话题被选择的情况。
4 试验及分析
4.1 实验数据
WeatherGov数据集包含了地区天气预报的详细气象信息,其文本是天气预报的短文本。数据集收集了2009年2月7日-2009年2月9日期间,人口超过1000人的美国城市天气预报,共计3753个城市,文字和相应的数据来源均为www.weather.gov。数据集每天为每个城市创建2个记录,共计22000条,一个场景是日间天气预报,一个场景是夜间天气预报,其内容主要由气温,风速,降雨概率等构成。
4.2 实验设置
我们分别使用特征f1,f1+f2,f1+f2+f3,f1+f2+f3+f4的特征集进行测试,考查不同特征对结果的影响。
构建的数据集被分为两部分。第一部分20000条被作为训练集(development set),第二部分2000条作为测试集(test set)。
4.3 评价
评价标准使用精确率(precision)、召回率(recall)和F1值(F1-measure)。
4.4 实验结果
实验结果如表3所示。
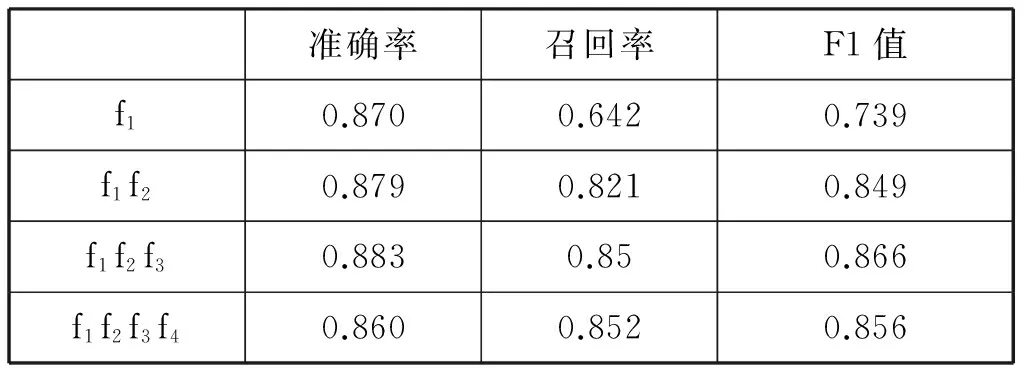
表3 实验结果
可以看出,朴素贝叶斯模型在受限领域的内容选择任务上可以达到较好的效果,从图3中可以看出,在使用f1+f2+f3时的效果最好,f1值可以达到0.86。受到朴素贝叶斯其独立性假设影响,使用所有的特征f1+f2+f3+f4效果相比反而有所下降。
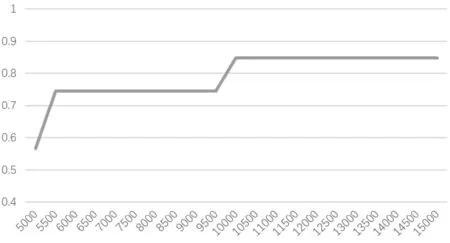
图2 样本数与F1值间的关系
此外,图2描述了训练样本数和F1值间的关系,样本数量在10000左右到达最优。
5 小结
本文提出了一种基于朴素贝叶斯的内容选择方法。实验表明,模型可以较好的在天气数据集上完成内容选择的任务。在未来的工作中,我们将研究独立于领域的内容选择特征,研究通用领域的内容选择模型。
[1]Gkatzia D.Data-driven approaches to content selection for data-to-text generation[D].Edinburgh,UK:Heriot-Watt University,2015.
[2]Sripada S G,Reiter E,Hunter J,et al.A two-
stage model for content determination[C].Proceedings of the 8th European workshop on Natural Language Generation,Association for Computational Linguistics,2001,8:1-8.
[3]Moore J D,Swartout W R.A reactive approach to explanation:taking the user’s feedback into account[C].Natural language generation in artificial intelligence and computational linguistics,Springer,US,1991:3-48.
[4]Lester J C,Porter B W.Developing and empirically evaluating robust explanation generators:The KNIGHT experiments[J].Computational Linguistics,1997,23(1):65-101.
[5]Bontcheva K,Wilks Y.Dealing with dependencies between content planning and surface realisation in a pipeline generation architecture[C].International Joint Conference on Artificial Intelligence,Lawrence Erlbaum Associates Ltd,2001,17(1):1235-1240.
[6]Konstas I,Lapata M.A Global Model for Concept-to-Text Generation[J].J Artif Intell Res(JAIR),2013,48:305-346.
[7]Shang L,Lu Z,Li H.Neural responding machine for short-text conversation[C].arXiv preprint arXiv:1503.02364,2015.
[8]Lewis D D.Naive(Bayes)at forty:The independence assumption in information retrieval[C].European Conference on Machine Learning,Springer,Berlin Heidelberg,1998:4-15.
(责任编辑:王谦)
A Naïve Bayes-based Content Selection Model
GONG Jun-peng1,CAO Juan2
(1.Faulty of Science and Technology,Communication University of China,Beijing 100024,China;2. New Media Institute,Communication University of China,Beijing 100024,China)
This article proposes a new method for learning content selection rules.Central to this approach is the content select feature.The algorithm introduced in the article automatically train a naïve bayes model from a set of concept features.The results indicate model suits the task well in specific domain.
content selection;naïve bayes;content feature
2017-04-25
北京市科委项目(Z161100000216141);中国传媒大学工科规划项目(3132016XNG1605)
龚隽鹏(1982-),男(汉族),重庆市人,中国传媒大学副教授.E-mail:JPGONG@cuc.edu.cn
TP
A
1673-4793(2017)04-0014-04
