Linked Data数据集的主题模型建立方法
2017-06-13刘海池唐晋韬魏登萍刘培磊
刘海池,王 挺,唐晋韬,宁 洪,魏登萍,刘培磊
(国防科技大学计算机学院,湖南 长沙 410073)
Linked Data数据集的主题模型建立方法
刘海池,王 挺,唐晋韬,宁 洪,魏登萍,刘培磊
(国防科技大学计算机学院,湖南 长沙 410073)
提出了建立Linked Data数据集主题模型的方法.首先,将数据集中的RDF陈述三元组转换成主谓宾结构的语句,从而将Linked Data数据集转化为文本文档;然后,使用LDA算法对所有数据集的文本文档进行主题建模,即可得到每个数据集的主题向量,该向量就是描述数据集内容主题的特征.在Linked Data数据集链接目标推荐问题上,引入数据集的主题特征进行实验.使用数据集主题向量的余弦相似度替换基于记忆的协同过滤推荐算法中的相似度计算模块.结果表明,推荐效果比原始的协同过滤算法有很大提升.
Linked Data;数据集;主题模型;LDA;推荐系统;协同过滤
0 引言
经过10多年的努力,语义网的理论基础已经奠定,W3C有关语义网的技术规范也逐步得到了完善.[1]同时,链接数据(Linked Data)指导原则[2]已经成为在万维网上发布RDF数据的基本准则,一个基于RDF数据模型的数据之网(Web of Data)正在快速增长.链接开放数据(Linking Open Data)项目的成立,极大地促进了链接数据的发展.截至2014年4月,已经发布1 014个数据集,包含8 038 396个资源.[3]然而数据之网上的数据集缺乏关于其内容的描述信息,例如Linked Data数据集注册中心Datahub上,仅有一些简单的标签和关于数据集大小、发布者、发布时间等结构化元数据可用,关于数据集内容或主题的描述通常是缺失的,这给使用者选择数据集带来了困难.主题模型作为一种统计方法,它通过分析非结构化文本中的词语以发现蕴藏于其中的主题.[4]如果能够有一种方法对Linked Data数据集建立主题模型,然后利用获得的主题向量,就可以更好地支持数据集的检索、分类、聚类、摘要提取以及数据集间相似性、相关性判断等一系列应用.
主题模型起源是隐性语义索引(Latent Semantic Indexing,LSI)[5].LSI 并不是概率模型,因此也算不上一个主题模型,但是其基本思想为主题模型的发展奠定了基础.T.Hofmann[6]提出了概率隐性语义索引(Probabilistic Latent Semantic Indexing,pLSI),pLSI模型被看成是第一个真正意义上的主题模型.而此后D.M.Blei等人[7]提出的隐性狄里克雷分配(Latent Dirichlet Allocation,LDA)又在pLSI的基础上进行扩展,得到了一个更为完全的概率生成模型.LDA是一种生成式贝叶斯概率模型,将文档集中的文档建模为“词项-主题-文档”3层结构.LDA 基于“词袋”假设,不考虑词项之间的相互关系,将文档看做词项的独立出现的集合.在此基础上,LDA认为在文档的背后隐藏着由词项分布表示的话题,因此每篇文档可以看做是若干话题的分布.LDA假设文档中话题的分布服从Dirichlet分布,而话题中词项的分布服从多项式分布,从而简化了模型参数的推导过程.
但Linked Data数据集由RDF三元组的结构化数据组成,不能够直接应用主题模型算法.为此,本文提出了Linked Data数据集的主题模型建立方法.首先,按照实体的类型,对数据集进行分割,将描述同一类型实体的三元组聚集在一起形成子数据集.然后,对子数据集中的RDF陈述三元组,去除URI中的命名空间信息,从而将RDF陈述转换为句子.这样,就可以将数据集转换成本文文档.在文本文档集合上,应用各种主题模型算法计算主题向量.最后,以分割后数据集的三元组数量为权重,综合得到原始数据集的主题向量.在Linked Data数据集链接目标推荐问题上应用学习到的数据集主题模型进行实验.协同过滤是经典的推荐系统算法,在基于记忆的协同过滤算法中,通常使用评分历史记录计算用户或者物品的相似度[8].使用数据集的主题向量的余弦值来计算相似度,从而形成新的推荐算法.在LOD Cloud 2014[3]上,利用数据集间的链接关系构造 “用户-物品”评分矩阵,并在该实验数据上评价了多个协同过滤推荐算法的性能.实验表明,利用数据集的主题向量计算相似度的推荐算法,无论在评分的准确性还是推荐列表的准确性上都表现更好.
1 Linked Data数据集的主题模型建立方法
Linked Data数据集的主题模型建立过程可以形式化描述:给定Linked Data数据集的集合{d1,d2,…,dn},并指定主题的数量m,使用特定算法进行训练学习,得到每个数据集的内容在m个主题上的概率分布,并用向量(t1,t2,…,tm)表示.由于Linked Data数据集定义为RDF三元组的集合[1],并不是文本文档,不能够直接应用主题模型算法进行计算,因此需要经过一定的处理,如图1所示.
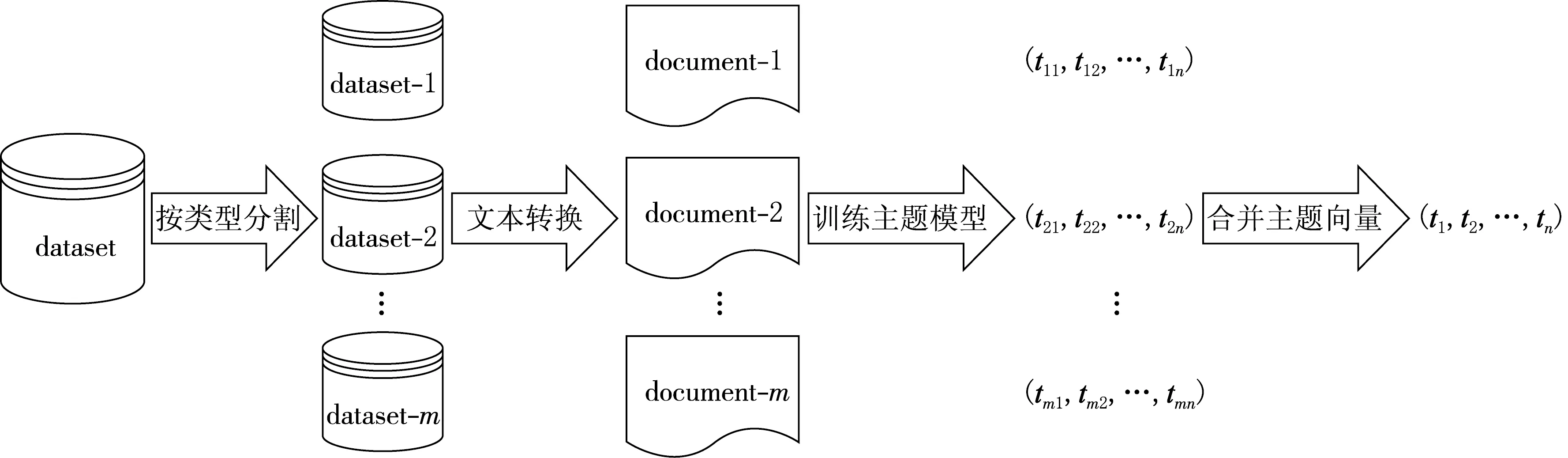
图1 Linked Data数据集主题模型建模方法流程
1.1 按照实体类型分割数据集
Linked Data数据集通常会包含多种类型的实体,每种类型的实体都由一系列三元组描述.根据类型的不同,这些三元组通常会描述实体的名称以及其他不同属性的取值.同一类型实体的三元组描述内容,主题上应该相对集中,因此,可以对数据集内的三元组按照类型分割,把描述某种类型的实体的三元组看做一个整体.rdf:type属性表示实体的类型信息,(subject rdf:type class_uri)三元组模式指明了实体所属的类型.对数据集按照类型分割时可以采用如下方法:首先找到数据集内所有的类型,使用SPARQL语句select distinct ?class_uri where {?s a ?class_uri.}.然后用查询到的所有类型URI,构造SPARQL语句select ?s ?p ?o where {?s a <" + class_uri + ">.?s ?p ?o.},该语句的查询结果就是描述某种类型实体的所有三元组集合.数据集内也可能存在不包含显式的类型信息的实体,这些实体类型为owl:Thing.使用语句select ?s ?p ?o where {?s ?p ?o.FILTER NOT EXISTS {?s a ?class.}}查询,可以得到这些实体的三元组.
1.2 对按类型分割的数据集进行转换
这一步主要是把数据集内的三元组转换为句子.数据集所包含的RDF陈述用于描述资源所具有的属性.一个陈述是一个“对象-属性-值”三元组,由一个资源、一个属性和一个值组成,值可以是资源,也可以是字面量(literal),字面量是原子值(字符串).一个陈述是一个“主语-谓语-宾语”结构的三元组,除字面量外,由一个统一资源标志符(Uniform Resource Identifier,或URI)表示.字面量本身是文本,不需要处理,而URI是一个用于标志某一互联网资源名称的字符串,包含命名空间(namespace)和本地名称(localname)2个部分,其中命名空间部分属于模式信息.把URI的命名空间部分去掉,只留下本体名称部分,就可以把RDF陈述三元组变成句子.例如,3个陈述三元组:

经过处理,就变成3个句子:

处理之后,按类型分割的数据集,都变成了包含该类型实体陈述句子的文本文档了,所有分割后的数据集经转换得到的文本文档作为文档集合.
1.3 在文档集合上训练主体模型
利用上节的方法,把数据集分割、转换成本文文档后,能够应用主题模型算法,计算文档的主题向量.本文中的文档集合是LOD Cloud 2014[3]的所有数据集经处理所形成的文档集合.使用Mallet工具包[9]中的LDA算法,训练主题模型.在训练之前,首先对转换得到的文本文档进行一系列预处理,主要包括特殊符号、分词、停用词的除却及大写变小写等.实验中,主题数设定为150,训练周期数设定为2 000.最终每个按类型分割的数据集得到一个表示其内容的150维的主题向量.
1.4 形成原始数据集主题向量
经过上述步骤,得到了按类型分割的数据集内容的主题向量.为了得到分割前数据集的主题向量,我们需要进行综合.可以根据分割后数据集三元组的数量,按照权重求和方法,得到分割前数据集的主题向量.计算公式为
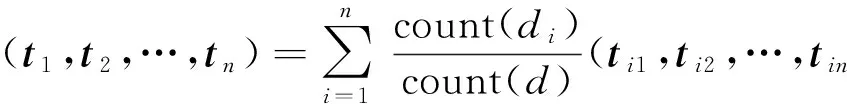
其中:count(x)为数据集x包含的三元组数量,di为按类型分割后的数据集中第i个类的子数据集,d为分割之前的原始数据集,(ti1,ti2,…,tin)为数据集di的主题向量,(t1,t2,…,tn)为综合后数据集d的主题向量.
2 推荐系统实验
使用上述方法,可以得到数据集表示数据集内容的主题向量.为了验证主题向量的建模效果,我们在数据集链接关系推荐[10]问题上进行了实验.根据Linked Data的基本原则,数据集之间要建立尽可能多的链接.但随着Web of Data上发布的数据集越来越多,对于数据集发布者来说,寻找可以建立链接关系的目标数据集是一个具有挑战性的问题.之前的工作[10]把这一问题转换为推荐系统问题,取得了较好的效果.在推荐过程中,发现数据集内容特征的描述对发现目标数据集是至关重要的.因此,本文探索了使用LDA算法对Linked Data数据集进行主题建模的方法.利用主题建模得到的主题向量计算数据集间的相似度,并取代传统推荐算法的相似度计算模块,通过实验来说明本文提出的主题建模方法的有效性.实验中,原始算法和评价指标的计算都是利用Mahout[11]实现的.
2.1 推荐系统实验框架
在推荐系统实验中,数据集同时类比表示为用户和物品,数据集间的链接关系类比为用户对物品的购买或评分,建立相互链接关系的“用户-物品”矩阵,然后用推荐算法作为数据集推荐可链接的目标数据集.协同过滤是推荐系统领域的经典算法,可以分为基于记忆的算法和基于模型的算法.基于记忆的算法又可以分为基于用户的和基于物品的算法,[8]在基于记忆的推荐算法中,一个重要步骤是通过评分历史计算用户或者物品的相似度.例如,2个用户相似度就是他们评过分的物品列表的相似度,而2个物品相似度就是对它们评过分的用户列表的相似度,列表相似度使用向量夹角的余弦值计算.
可以利用数据集的主题向量的余弦值,来计算数据集的相似度,并作为基于记忆的推荐算法中的相似度计算模块,并把得到的推荐算法分别记为Item-Topic和User-Topic.为了对比推荐实验的效果,选择了一些基础算法和原始协同过滤算法作为baseline.Random推荐算法产生随机的评分和推荐列表,ItemAverage推荐算法总是把所有评分的平均值作为对物品的评分预测.ItemUserAverage算法跟ItemAverage类似,但是把待推荐用户的所有评分的平均值作为该用户对未知物品的评分.Item-based是原始的基于物品的协同过滤算法.对于基于用户的算法User-based有2种选择邻居的方法,分别是基于固定的邻居数和基于相似度阈值.实验中尝试了一系列可能的参数取值,对于固定的邻居数n,取值1~10,对于相似度阈值t,以0.1为步长,取值0.1~0.9.选择取得最佳的结果作为实验结果,参数设置标记在算法名称后面.RatingSGD是基于模型的推荐算法,它有3个参数可设置,分别是因子数f、学习率γ和周期数i,同样,本文给出了最优参数取得的结果.
2.2 实验数据构造
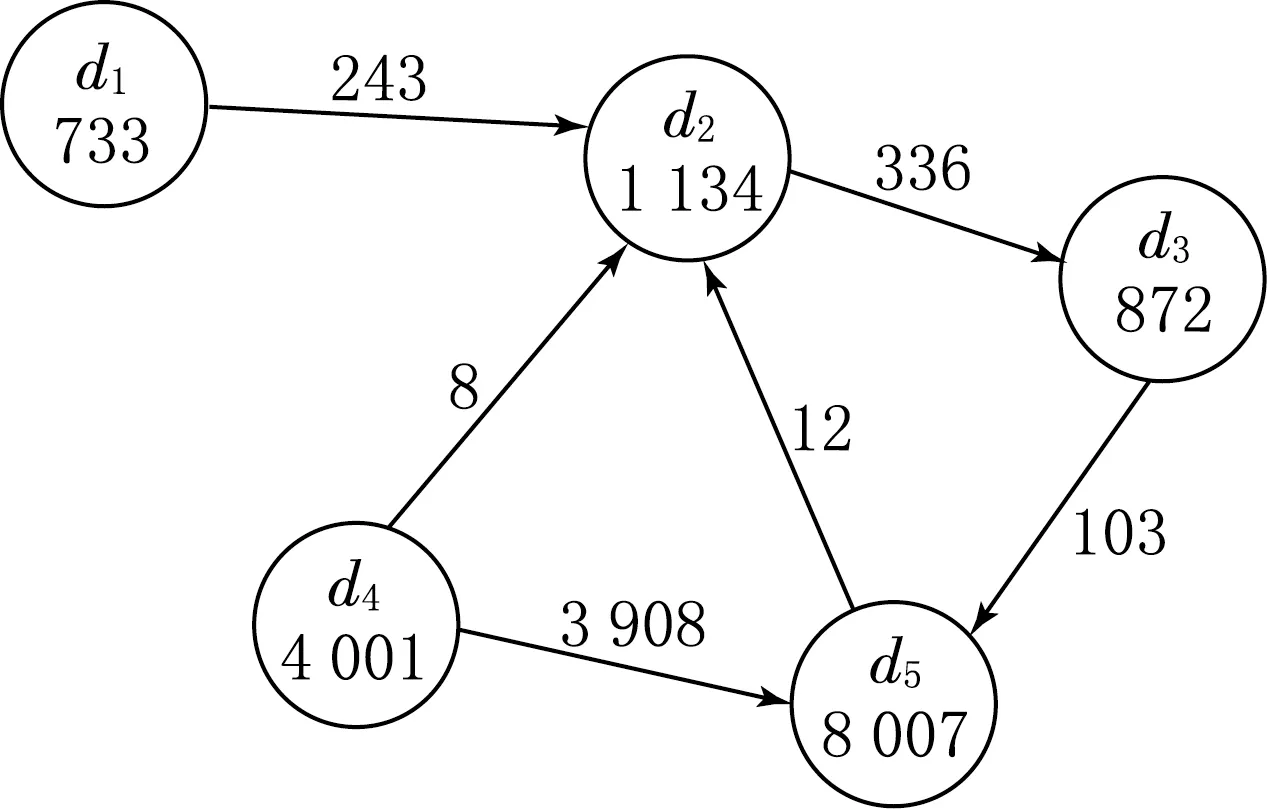
为了进行数据集推荐实验,首先需要构造“用户-评分”矩阵.我们把数据集之间的链接关系看做是数据集之间的评分,也就是说,如果2个数据集d1到d2之间有RDF链接,那么就认为数据集d1对d2有评分关系.评分值的定义方法是数据集之间的RDF链接三元组数量的数字位数,这一过程见图2.图2(a)表示的是5个数据集间的链接关系,圆圈中的数字表示数据集所包含的实体的个数,箭头表示2个数据集之间的RDF链接,箭头的方向由RDF链接三元组主语所在的数据集指向宾语所在的数据集,箭头上的数字表示RDF链接三元组的数量.图2(b)表示从图2(a)中构造的“用户-物品”的二部图.图2(c)是最终所生成的5行5列“用户-物品”矩阵.数据集d1到d2有243个RDF链接,那么对应的用户评分矩阵中r1,2值为3.
使用文献[3]中提供的LOD Cloud 2014数据集构造推荐系统的实验数据,这些数据是我们在2014年4月从900 129个文档中爬取的.爬取到的数据提供N-Quad格式的文件下载,文件大小约为50 GB,共包含来自1 014个数据集的1.88×108个三元组.根据图2 的方法,最终得到的推荐系统数据集有1 014 个“用户”、1 014个“物品”、4 993个评分值.
(a)数据集间的链接关系
2.3 实验结果
在评价推荐结果的评分准确度时,选择了平均绝对误差(MAE)和均方根误差(RMSE)2个评价指标,它们用于评价推荐算法给出的打分同真实打分之间的差别大小,取值越小说明预测评分越准确.对于每个用户,取出一部分打分作为训练数据来计算推荐结果,剩余的评分作为标准答案.因为数据是随机分割的,因此对于每个推荐算法,进行10次测试然后取平均值.不同推荐算法的MAE和RMSE值对比见表1和2.由表1和2可以看到用主题向量计算数据集相似度,无论MAE还是RMSE都比原来的算法效果要好,MAE值降低了12%到46%,RMSE值降低了3%到39%.所有算法中,效果最好的是基于主题向量相似度的带阈值的基于用户的推荐算法(见表1和2黑体字).
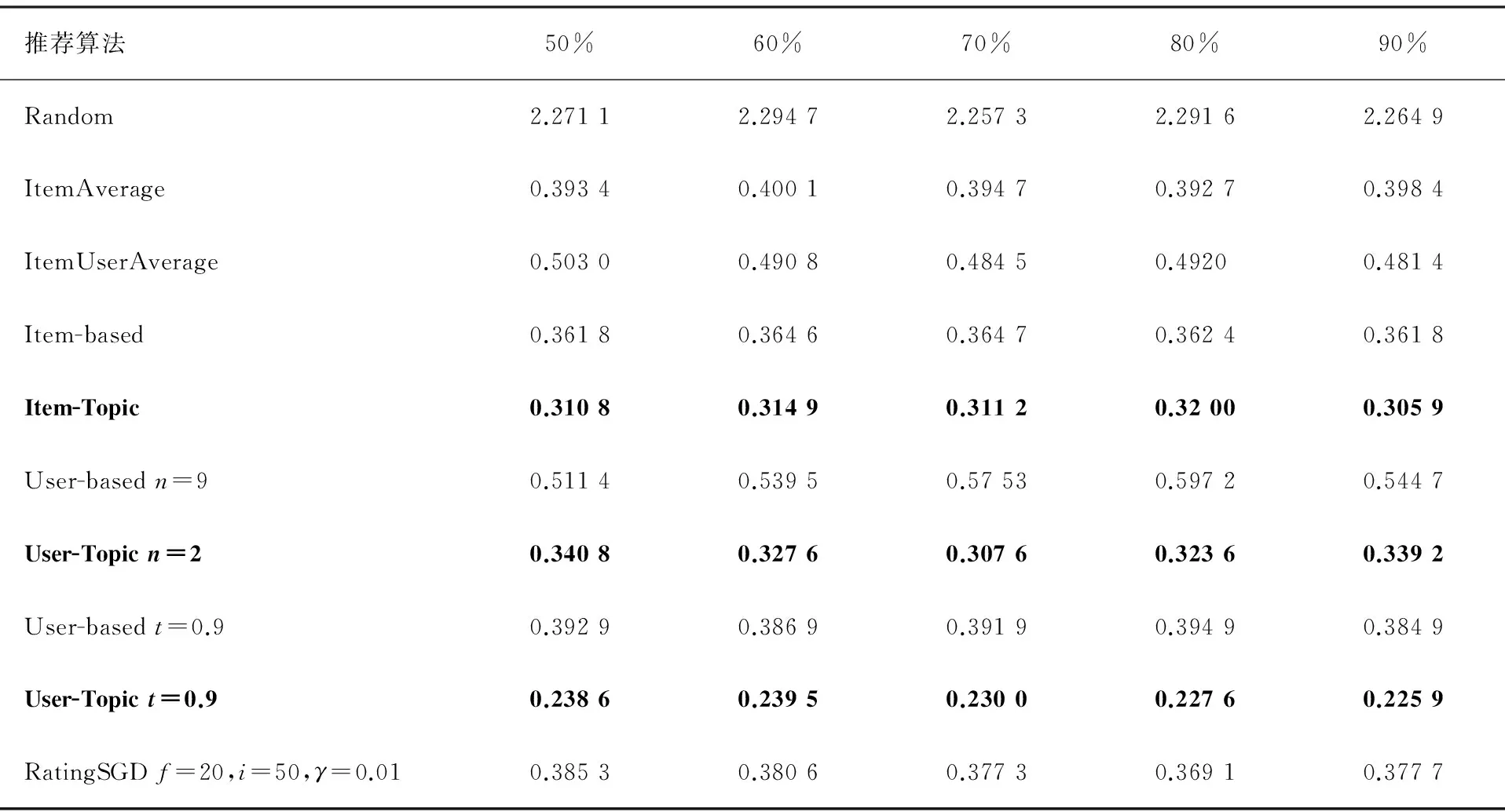
表1 不同推荐算法的MAE值对比

表2 不同推荐算法的RMSE值对比
有时,比起评分值,用户更关心推荐系统给出的推荐列表是否准确,因此我们还对TopN推荐进行了评价.使用了F1值和NDCG(Normalized Discounted Cumulative Gain)这2个指标.用于评价推荐列表的排序质量,取值越大越好.我们采用“留一法”进行实验,对于每个用户,去掉TopN个评分,然后用该用户剩下的评分和其他所有用户的所有评分作为训练数据,所有用户的平均结果作为最终结果.因为训练数据是按照评分降序选择的,因此对于基于记忆的推荐算法不需要多次重复实验.对于矩阵因子分解算法,由于最初的向量是随机初始化的,因此我们进行了10次测试后,取平均值.不同推荐算法的F1值和NDCG对比见表3和4.从表3和4可以看出,在基于物品的推荐算法中,使用主题向量计算数据集相似度较原始算法效果差.但在基于用户的推荐算法中,使用主题向量计算相似度,效果较好,F1值提升了13%到177%,NDCG值提升了19%到246%.
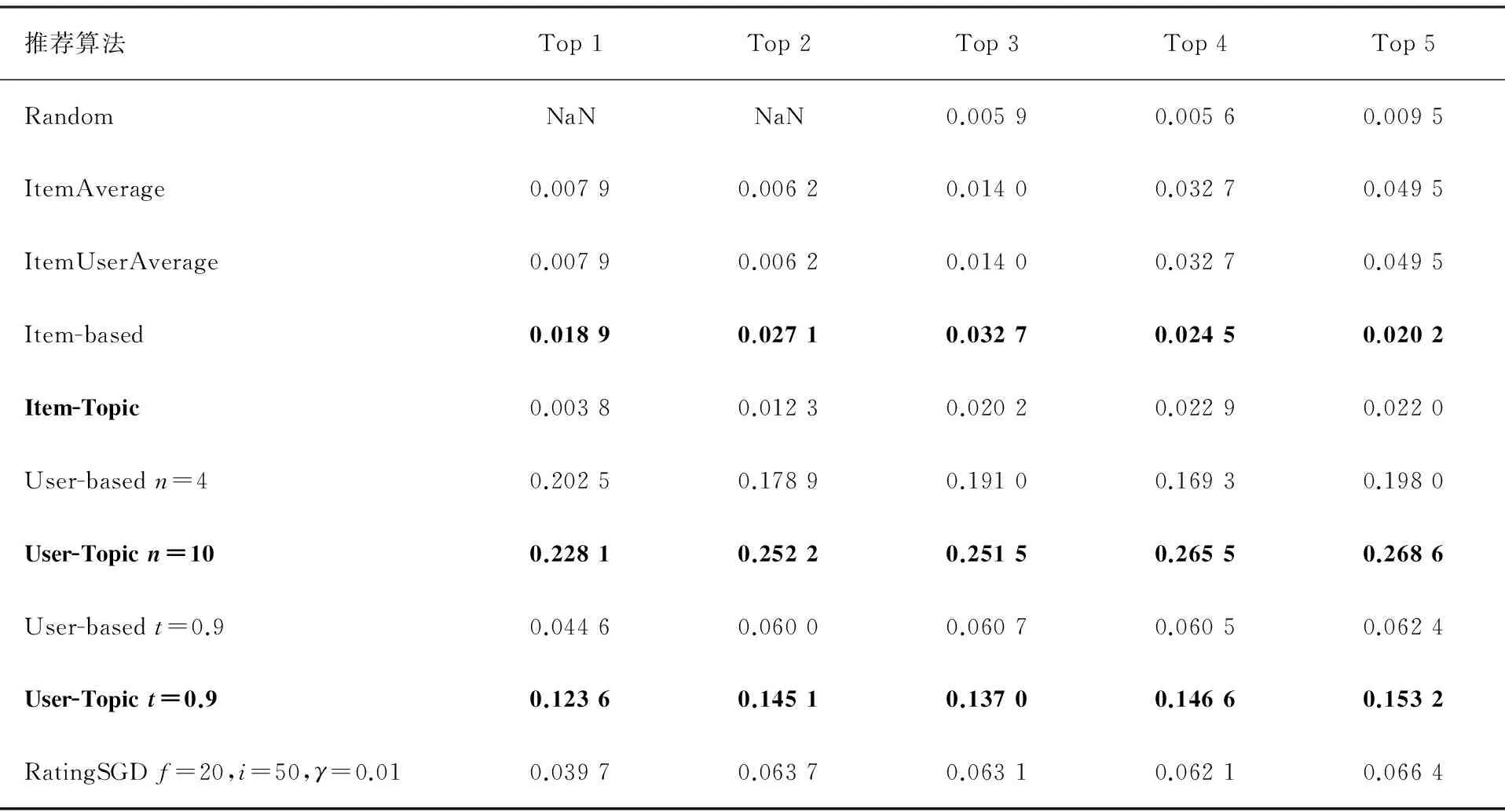
表3 不同推荐算法Top N推荐的F1值对比
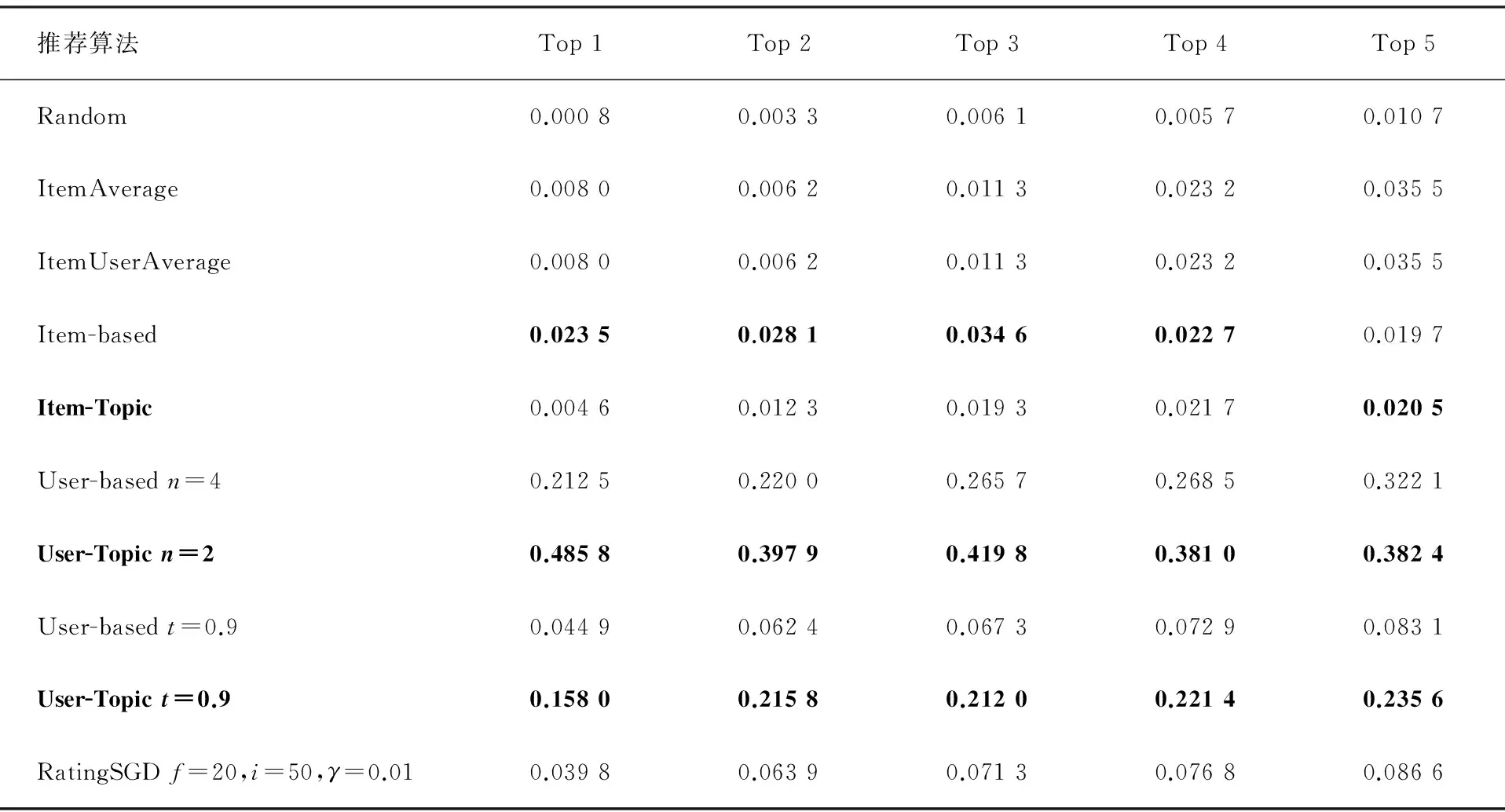
表4 不同推荐算法Top N推荐的NDCG值对比
通过2个实验对比表明,使用数据集的主题向量计算数据集相似度是可行的,而且得到的相似度较准确.在绝大多数情况下,比基于记忆的协同过滤推荐算法中使用评分历史计算相似度效果好(见表3和4黑体字).
3 结束语
本文提出了Linked Data数据集主题模型的建立方法.该方法把RDF陈述转换为本文句子,从而把数据集转换为文本文档.在文本文档上使用任意主题模型算法进行建模,能够表示数据集内容的主题向量.本文在Linked Data数据集链接目标推荐问题上使用数据集的主题模型进行了实验.利用数据集的主题向量计算余弦相似度,并将该相似度作为基于记忆的协同过滤算法中的相似度模块.在2014年LOD Cloud数据集上的实验表明,在绝大多数情况下,利用数据集的主题向量计算相似度比使用评分历史计算相似度效果好,得到的推荐算法性能好于原始的协同过滤算法.
[1] HEATH T,BIZER C.Linked data:evolving the web into a global data space[J].Synthesis Lectures on the Semantic Web Theory and Technology,2011,1(1):1-136.
[2] TIM BERNERS-LEE.Linked data[EB/OL].[2016-04-03].http://www.w3.org/DesignIssues/LinkedData.html.
[3] SCHMACHTENBERG M,BIZER C,PAULHEIM H.Adoption of the linked data best practices in different topical domains[M]//The Semantic Web-ISWC 2014,Berlin:Springer International Publishing,2014:245-260.
[4] 徐戈,王厚峰.自然语言处理中主题模型的发展[J].计算机学报,2011,34(8):1423-1436.
[5] DEERWESTER S,DUMAIS S T,FURNAS G W,et al.Indexing by latent semantic analysis[J].Journal of the American Society for Information Science,1990,41(6):391.
[6] HOFMANN T.Probabilistic latent semantic indexing[C]//Proceedings of The 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,Newyork:ACM,1999:50-57.
[7] BLEI D M,NG A Y,JORDAN M I.Latent dirichlet allocation[J].The Journal of Machine Learning Research,2003,3:993-1022.
[8] 冷亚军,陆青,梁昌勇.协同过滤推荐技术综述[J].模式识别与人工智能,2014,27(8):720-734.
[9] MCCALLUM,ANDREW KACHITES.Mallet:a machine learning for language toolkit[DB].[2016-12-05].http://mallet.cs.umass.edu.2002.
[10] LIU H,WANG T,TANG J,et al.Identifying linked data datasets for sameas interlinking using recommendation techniques[C]//Proceedings of The 17th International Conference on Web-Age Information Management,Belin:Springer,2016:298-309.
[11] ANIL R,DUNNING T,FRIEDMAN E.Mahout in action[M].Shelter Island:Manning,2011:29-51.
Topic modeling for Linked Data datasets
LIU Hai-chi,WANG Ting,TANG Jin-tao,NING Hong,WEI Deng-ping,LIU Pei-lei
(School of Computer Science,National University of Defense Technology,Changsha 410073,China)
The increasing adoption of Linked Data principles has led to an abundance of datasets on the Web.However,take-up and reuse is hindered by the lack of descriptive information about the content of the datasets,such as their topic coverage.To address this issue,an approach for creating Linked Data dataset topic profiles was proposed.Topic modeling has quickly become a popular method for modeling large document collections for a variety of natural language processing tasks.While their use for semi-structured graph data,such as Linked Data datasets,has been less explored.A framework for applying topic modeling to Linked Data datasets was presented.The RDF statement triples were transformed to natural language sentences.In this way the datasets which contains RDF structured data is transformed into text documents,this paper can apply topic modeling algorithms to get topic vector for each dataset.This paper describes how this topic profile of datasets can be used in a recommendation task of target Linked Data datasets for interlinking.The cosine similarity of topic vector of datasets generated by LDA topic modeling algorithm was calculated and the cosine similarity was made as the similarity component of memory-based collaborative filtering recommendation algorithms.Experiments to evaluate the accuracy of both the predicted ratings and recommended datasets lists of the resulting recommenders were conducted.The experiments demonstrated that our customized recommenders out-performed the original ones with a great deal,and achieved much better metrics in both evaluations.
Linked Data;dataset;topic model;LDA;recommender systems;collaborative filtering
1000-1832(2017)02-0077-07
10.16163/j.cnki.22-1123/n.2017.02.015
2016-10-20
国家自然科学基金资助项目(61472436).
刘海池(1985—),男,博士研究生,主要从事语义网Semantic Web、关联数据Linked Data研究;王挺(1970—),男,博士,教授,主要从事自然语言处理研究;宁洪(1963—),女,教授,主要从事数据库技术Database Technology研究.
TP 391 [学科代码] 520·2070
A
