基于改进Single-Pass算法的话题发现技术研究
2017-05-12陈美英周安民
陈美英,周安民
(四川大学电子信息学院,成都 610065)
基于改进Single-Pass算法的话题发现技术研究
陈美英,周安民
(四川大学电子信息学院,成都 610065)
为了在海量的移动互联网数据中自动识别出新闻话题,分析经典Single-Pass聚类算法及其不足,提出针对性改进方法完成新闻话题发现。改进算法继承Single-Pass聚类算法的原理,通过对关键信息加权和引入时间因子提高算法的聚类精度;通过设置话题中心与待聚类文本比较来降低算法的计算开销。实验表明,改进后的算法相比于经典算法在准确率、召回率和F值三个指标上有所提高。
Single-Pass 聚类算法;TF-IDF;时间因子;话题中心
0 引言
随着互联网的飞速发展和普及,网络成为人们获取新闻资讯的重要渠道之一。根据第38次《中国互联网络发展状况统计报告》的数据显示,截至 2016年 6月,中国网民规模达 7.10亿,半年共计新增网民 2132万人;手机网民规模达 6.56亿,较 2015年底增加3656万人[1]。随着手机流量资费的下降、手机终端大屏化等应用体验的提升,以手机作为主要上网终端会成为更多人的选择。网络新闻作为基础的互联网应用,用户规模保持稳健增长,使用率在80%以上。网络新闻客户端是人们在日常生活中关心国家大事和社会热点的最简单直接的工具,大量繁杂甚至无用的网络信息也通过新闻客户端输送给用户。那么,如何在海量互联网信息中检测和提取当今社会大众较为关注的新闻事件话题变得尤为重要。
1 话题发现研究现状
话题检测与跟踪 (Topic Detection and Tracking,TDT)是一项在日益膨胀的互联网新闻信息中对新话题进行自动识别和对已知话题保持持续跟踪的信息处理技术,最早由美国国防高级研究计划署(DARPA)于1996年发起[2]。
从1998年开始,美国国家标准技术研究所(NIST)在DARPA的支持下举办话题检测与追踪国际会议,并进行相应的测评[3]。此后国外很多机构和学者开始研究此类技术。Martijin等人很对语言模型采用话题发现和相似度计算的方法[4]。NewsInEssence多源新闻文摘系统使用聚类和多文档自动文摘技术来发现话题[5]。IBM公司采用了两层聚类策略,使用对称的Okapi公式来对比两篇新闻报道的相似性[6]。
国内在TDT方面的研究起步较晚,但在学者的努力下至今也取得了丰硕的成果。2004年贾自艳等提出一种动态进化模型的事件探测和追踪算法[7]。2005年于满泉等针对新闻事件的特点提出了单粒度话题识别方法,并将基于多层聚类的MLCS算法应用在话题组织上[8]。2009年何婷婷等人提出基于两层聚类的算法和热度计算公式来发现热点话题[9]。
TDT中话题发现主要针对于传统聚类算法的选择试验和改进,其中常用的聚类算法是Single-Pass聚类算法。该算法是一种简单的增量聚类算法,对比依次输入的新闻数据和已有类的匹配度,将数据归为已有类或创建新的类,实现增量和动态聚类。
2 算法描述
2.1 Single-Pass聚类算法
Single-Pass聚类算法按文本出现的顺序依次处理文本集合D={d1,d2,…,dn},如果是第一个文本d1,则将该文本作为种子创建一个新的话题;后续出现的文本di与已有话题比较,并计算相似度θ。如果最大相似度没有达到系统预设的阈值ε,则判定该文本di是一个新的话题;否则将文本归到相似度最高的话题中。该算法的流程如图1所示。了运算开销。另外,为了确保聚类结果的准确,需要不断调整聚类中心,不断获取最优的聚类中心。
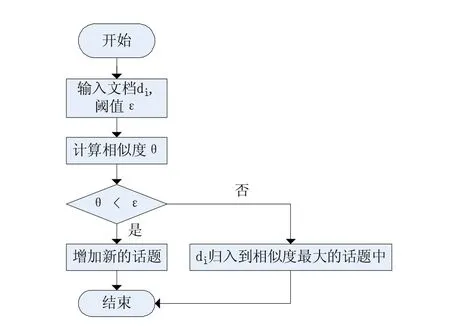
图 1 Single-Pass算法流程图
(3)经过对新闻报道文本特征的深入分析,标题、人名、地名机构名等对新闻文本有着很高的区分度;而且新闻的第一段大多是对整片新闻的总结性概括,也很好地将自身区别于其他不同报道。因此要对相关特征词和文本第一段内容赋予更高的权重,才能更准确地表示文档,以此提高聚类的精度。现在比较普遍的权重计算方法是TF-IDF权重表示法。
(4)因为新闻文本具有时效性特点,也许是同一个事件但是发生的时间不同,如果在聚类是不考虑时间跨度,很容易将不同时期的同一事件归为一类。因此需要引入时间因子来更好地判断待聚类文本是否属于已有聚类话题。
经典的Single-Pass聚类算法直观又易于理解,但是仍有不足之处:
(1)对输入次序的依赖性很高。针对相同的文本集合,因为输入的次序不同会有不同的聚类结果。
(2)计算开销大,系统效率低。新的需要聚类的文本要与已聚类的每一个文本做相似度计算,随着后期文本增多,计算量会逐步增大,使得系统的效率低下。
(3)聚类精度不高。由于没有考虑新闻报道的特殊性,例如新闻时效性特点以及一些特征词(标题、人名、地名、机构名等)的权重,导致聚类结果的不理想。
2.2 改进的Single-Pass算法
对于上述提出的Single-Pass聚类算法的不足,我们可以做以下的改进:
(1)在预处理要聚类的文本时,可以根据新闻报道发布的时间对文本进行排序,减小话题在演变过程中新闻报道的不同对话题聚类结果的影响。
(2)为了避免待聚类文本与已聚类的每一文本比较并计算相似度,首先在已聚类的话题中设定聚类中心,代表该聚类中所有文本的共有话题[10]。新的待聚类文本只需要和聚类中心比较并计算相似度,大大缩减
3 基于改进的Single-Pass新闻话题发现
话题发现的流程包括数据采集和预处理、文本向量化、文本聚类等基本步骤。
3.1 数据采集与预处理
数据采集是指利用网络爬虫技术在网络上自动获取并存储Web网页的信息。网络爬虫从初始的URL出发,根据网络之间的链接关系和指定的条件,不断扩展并获取整个网络的页面信息。一个网页的信息可以分为两类,给用户浏览的信息和给浏览器识别的标记信息。将采集到的HTML源文件内容进行解析处理,去掉标记信息HTML标签和用户浏览信息中链接、导航和广告等对于文本聚类无用的噪声信息,提取出我们需要的新闻报道标题、时间和正文等,最终得到纯文本文档。
为了将新闻报道字词特征的集合又尽量保持报道本身的内容不受影响,本文采用空间向量模型这一种简单高效的文档表示模型来规范地表示新闻报道,词作为特征项。而汉语中词和词之间没有明确的分隔标识,因此要对本文分词。中文分词最常用的方法是基于统计的分词方法和基于字符串匹配的分词方法。中科院经过多年研究开发出汉语词法分析系统ICTCLAS(Institute of Computing Technology, Chinese Lexical Analysis System),主要包括中文分词、此行标注、命名实体识别等功能,分词精度可以达到98.5%。本文即采用该方法对文本进行分词,随后去掉不涉及报道内容的停用词。
3.2 文本的向量表示
经预处理后的数据仍包含大量无用或重复的词,给后续文本处理带了难度。特征抽取的目的是在不改变文本原本传达的核心信息的情况下识别出能够标识文本原有内容、区别于其他文本的特征项,方便计算,提高处理效率。文档频率法是特征抽取最简单有效的方法,特征分量高于预定阈值的特征量保留。不同特征项对文本内容的贡献度不同。针对新闻报道,人名、地名、机构名、标题和第一段内容往往更重要,将被分配更高的权重。
为了将文本表示为计算机可以处理的数字化信息及进行特征抽取和加权处理,本文采用空间向量模型(Vector Space Model,VSM)和TF-IDF算法对文本进行处理。
设每个文档d表示为一个特征向量公式(1):
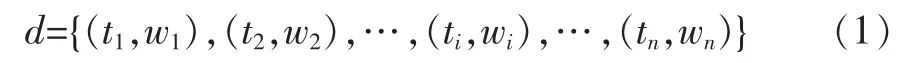
其中ti是该文本的特征项,wi为该特征项的权值。接下来,我们利用TF-IDF算法来计算特征项的权值。
TF-IDF(Term Frequency-Inverse Document Frequency)即词频-反文档频率,其思想是词频TF表示词在文档中出现的频率,反文档频率IDF表示词在整个文档集合里出现的频率。当一个词在该文档中出现的频率高而在其他文档中出现的频率低,表示它对该文本的独特性贡献更大,该词的权重也应更大。TF、IDF的计算公式分别为公式(2)、(3):

其中fij表示该词在文档dj中出现的次数,Nj表示文档dj中词的总数;N为文档合集中文档的总数,Ni表示包含词i的文档的个数。权值是TF和IDF的乘积并进行归一化。为了调整人名、地名、机构名、标题和第一段内容的权重值,引入加权因子Fm={f1,f2,f3,f4,f5},分别表示以上五项的权重。即文档dj中第i个词的权重wij表示为公式(4):

3.3 文本相似度计算
待聚类的文本d和话题T之间的相似度通过计算两向量之间的夹角余弦值来衡量,用公式(5)表示:

其中,w表示文本或话题的特征项权重,n是文本或话题不同特征项的总数。从公式可以看出,向量d和T之间的夹角越小,余弦值就越大,两者之间的相似度就越大,反之成立。
为了区分不同时间段的新闻报道而使聚类结果更精确,我们引入时间距离函数T(公式6)来计算文本和话题之间的时间距离。

其中,td表示文档d的发布时间,tTs是话题T中第一篇新闻报道的时间,tTe是话题T中最新一篇新闻报道的时间。加入时间距离函数之后的相似度计算公式(7)如下:

基于以上公式,本文既考虑了文本和话题的内容相似度,也从时间上判断两者是否应该归为一类。其中α+β=1,经过大量试验,α=0.8时聚类效果最好,这也印证了文本内容相似度在聚类中更为重要的作用。
3.4 文本聚类
将第一篇新闻文本作为初始的话题中心,然后处理下一篇报道d,根据以上的流程和方法,将文本表示为空间向量模型。根据相似度公式可以计算出文本d与全部已有话题的话题中心之间的相似度,通过比较可以找到相似度最大的话题Tm,此时的相似度为Sm。系统在开始时已经设定好阈值ε,如果Sm大于阈值,将文本归于该话题Tm。反之,d作为新的话题中心设置新的话题,并参与之后的文本处理。在输入文本d确定自身所属聚类话题之后,需要比较新文本d与聚类中心的特征项数量,如果新文本d特征项数量大于原聚类中心,那么将新文本d作为新的聚类中心进行接下来的聚类。重复以上过程直到文本处理完毕,聚类完成。
4 实验结果分析
4.1 实验数据
本文的实验语料来自手机App腾讯新闻的数据。实验主要爬取了腾讯新闻2016年下半年数据,包括以下10个新闻话题:中国女排夺冠、三星note7爆炸、杭州G20、阿里月饼门、网约车新政、美国大选、朴槿惠闺蜜门、林丹出轨、卡斯特罗去世、罗一笑事件。其中每个话题的报道100篇,并加入作为干扰的报道100篇,共计1100篇报道。
4.2 实验评价指标
评价实验方法性能的常用指标有准确率P、召回率R和F值。准确率是指系统正确识别的报道占文档总数的比例,也就是查准率;召回率是指系统正确识别的话题的报道数占语料库中该话题实际的报道数的比例,也就是查全率;可以看出准确率和召回率是一对矛盾的值。F值是准确率P和召回率R的调和平均,如公式8所示:

4.3 实验结果及分析
基于以上实验方法、数据及评价方法,应用经典的Single-Pass算法对实验数据进行聚类的结果如表1所示,准确率、召回率和F值分别为79.1%、80.1%和79.5%。
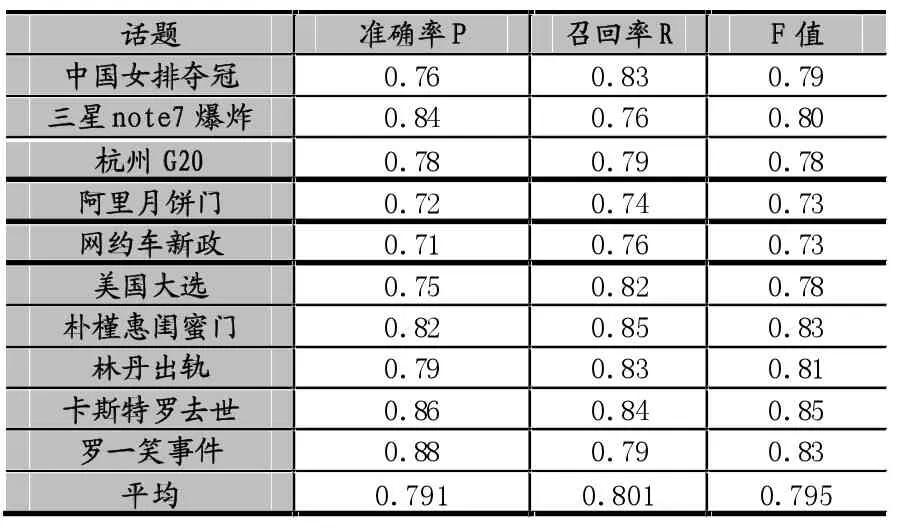
表 1经典Single-Pass算法实验结果
经过改进的Single-Pass算法的实验结果如表2所示,准确率、召回率和F值分别为82.6%、83.6%和83.1%。
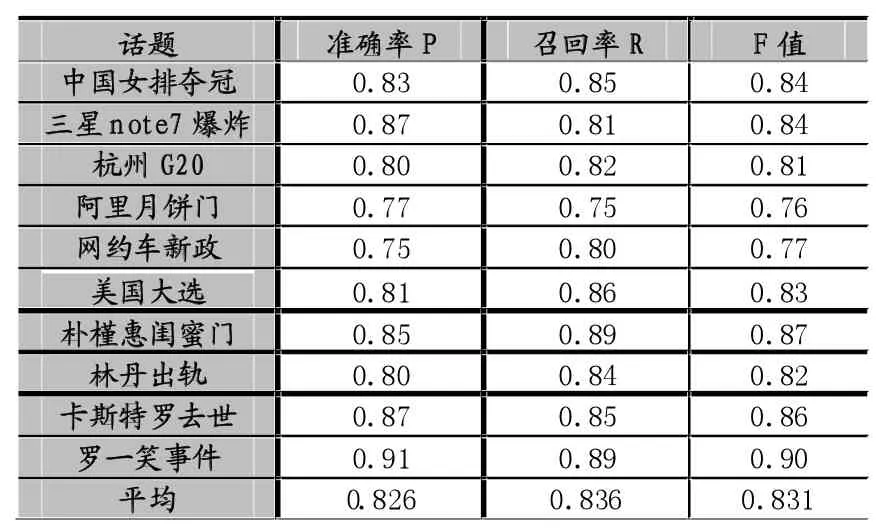
表 2改进Single-Pass算法实验结果
图2用柱状图清晰地表示出改进方法相比于经典方法在各项评价指标上的优势。

图2 两种方法实验指标对比
以上实验结果对比可知,由于在数据处理时运用特征项加权和引入时间因子的文本向量更好地表征了文本报道要表达的语义,为文本聚类提供了更优的条件,改进Single-Pass算法的准确率、召回率和F值均高于经典的Single-Pass算法。
5 结语
本文以经典的Single-Pass聚类方法为基础,针对2016年腾讯新闻数据进行话题发现研究。话题发现方法的一般流程是数据采集和预处理、文本向量化、文本聚类等。经典的Single-Pass聚类方法虽然简单直观,但是仍然存在聚类精度不高的问题,本文在文本向量表示时加权各个对文本思想表达重要的特征项,并加入时间影响因子,来提高新闻聚类的精度;针对计算开销大的问题,本文将已有话题归纳话题中心并不断更新,文本向量与话题中心的对比取代与每个文本的对比,减小计算开销。经过对数据的实验验证,改进的Single-Pass方法在准确率、召回率、F值方面有了较好的改善,肯定了文本研究的价值。
参考文献:
[1]中国互联网络信息中心 、新华网等综合汇编.CNNIC发布第38次《中国互联网络发展状况统计报告》[J].中国教育网络,2016,09:16.
[2]洪宇,张宇,刘挺,李生.话题检测与跟踪的评测及研究综述[J].中文信息学报,2007,06:71-87.
[3]Allan J,Lavrenko V,Connell M E.A Month to Topic Detection and Tracking in Hindi[J].ACM Transactions on Asian Language Information Processing(TALIP),2003,2(2):85-100.
[4]Spitters M,Kraaij W.TNO at TDT2001:Language Model-Based Topic Detection[J],2001.
[5]Fung G P C,Yu J X,Yu P S,et al.Parameter Free Bursty Events Detection in Text Streams[C].Proceedings of the 31st International Conference on Very Large Data Bases.VLDB Endowment,2005:181-192.
[6]Allan J.Introduction to Topic Detection and Tracking[M].Topic Detection and Tracking.Springer US,2002:1-16.
[7]贾自艳,何清,张海俊,李嘉佑 ,史忠植.一种基于动态进化模型的事件探测和追踪算法[J].计算机研究与发展,2004,07:1273-1280.
[8]于满泉,骆卫华,许洪波,白硕.话题识别与跟踪中的层次化话题识别技术研究[J].计算机研究与发展,2006,03:489-495.
[9]刘星星,何婷婷,龚海军,陈龙.网络热点事件发现系统的设计[J].中文信息学报,2008,06:80-85.
[10]马国栋,李慧.基于改进Single-Pass算法的BBS热点话题发现[J].首都师范大学学报(自然科学版),2014,06:13-17.
Research on Topic Discovery Based on Improved Single-Pass Algorithm
CHEN Mei-ying,ZHOU An-min
(College of Electronics and Information Engineering,Sichuan University,Chengdu 610065)
Aiming at the automatic identification of news topic in massive mobile internet data,analyzes the classical single-pass clustering algorithm and its disadvantages,and puts forward the pertinent improvement method to finish the news topic detection.The improved algorithm inherits the principle of Single-Pass clustering algorithm,and improves the clustering accuracy by weighting the key information and adds the time factor,reduces the computational cost of the algorithm by setting the center of the topic to compare with the text to be clustered.Experiment results show that the improved algorithm has higher accuracy,recall and F value than the classical algorithm.
Single-Pass Clustering Algorithm;TF-IDF;Time Factor;Topic Center
1007-1423(2017)09-0018-05
10.3969/j.issn.1007-1423.2017.09.005
陈美英(1992-),女,甘肃嘉峪关人,硕士,研究方向为数据处理和Web开发
2017-01-17
2017-03-10
