基于时序数据的top-k时间区间对比序列模式挖掘算法
2017-05-12晏力
晏力
(四川大学计算机学院,成都 610065)
YAN Li
(College of Computer Science,Sichuan University,Chengdu 610065)
基于时序数据的top-k时间区间对比序列模式挖掘算法
晏力
(四川大学计算机学院,成都 610065)
随着物联网技术的发展,现在越来越多的传感器被应用于人们的生活中,由此产生大量的时间序列数据。正是因为数据的爆炸式增长,人们迫切地希望从大量时间序列数据中发现有用的模式。目前已经有大量的序列模式分析算法应用到时序数据上。设计并实现一个应用到时序数据的top-k时间区间对比挖掘算法。
时间序列;对比挖掘;top-k
0 引言
序列数据是一种重要的数据类型,这种数据类型常常出现在很多领域,如科学、医学、商业、安全和其他应用领域。而序列模式是序列数据挖掘中必不可少的任务,而序列模式中的对比序列模式[1]是一种比较热门的模式,近年来引起了学术界的广泛关注。对比序列模式(又称为显著序列模式)是指在一个序列数据集中频繁出现,而在另外一个序列数据集中不频繁出现的模式。对比序列模式主要是反映了两个或多个序列数据集的差异性,可以用来理解和识别这些数据集的信息特征,因此可以用于个性化推荐、基因数据分类和异常探测等。目前,对比序列模式被应用到了聚类、分类、预测等数据挖掘任务中。
在时间序列数据集上的对比序列模式挖掘正被越来越多的学者所关注。同时在这些算法与实际生产相结合的时候,用户往往希望自定义一些时间区间,并希望能得到在这些时间区间上的模式的显著度。本文正是基于上述用户实际需求,开发了一个基于固定时间区间的top-k对比挖掘算法。
1 问题定义
那么现在我们从基础的定义开始。时间序列就是在字符序列数据的基础上多了一个时间属性,这种数据主要由传感器接收到的事件组成,所以我们可以定义时间序列的基本元素为一个事件event,定义为一个二元组(e,t),e代表一个事件类型,t代表时间戳(时间戳可以是绝对时间和相对时间,为了方便,本文时间戳为非负整数)。我们定义表示数据集中所有事件类型的总表,T代表数据集的最大时间戳。一个时间序列S是一系列按照时间戳升序排列的事件列表,

其中ei∈E,ti∈[0,T],且ti≤tj(1≤i〈j≤n)。对于事件时间序列S我们定义它的长度为它所包含的事件个数,记为|S|。我们指定S[i](1≤i≤|S|)表示在事件时间序列S中的第i个事件元素。对于S[i],我们使用S[i].e来表示事件类型,S[i].t来表示与事件类型相关联的时间戳。 例如:给定S=〈(e1,0),(e2,10),(e3,30),(e4,40)〉,可知|S|=4,S[2]=(e2,10),S[2].e=e2,S[2].t=10。
事件类型序列E是一个事件类型的有序序列,格式为E=〈e1,e2,…,en〉,其中ei(1≤i≤n);如果存在着整数1≤k1〈k2〈…〈k|E′|≤|E|,使得E′=〈E[k1],E[k2],…,E [kn]〉,那么我们称E是E′的超序,记为E′⊂E。例如〈e1,e2,e3,e4〉是〈e2,e4〉的超序。

时间延迟约束r被规定为两个非负整数,形式为r =[rmin,rmax],满足条件0≤rmin≤rmax≤T。
给定一个时间序列S、事件类型序列E、时间窗口W和时间延迟约束r,如果存在着整数1≤k1〈k2〈…〈k|E|≤|S|,使得他们之间满足如下两个条件:(1)1≤i≤ |E|,满足S[ki].e=E[i],W.ts≤S[ki].t≤W.te;(2)1≤j≤|E|-1,满足S[kj+1].t-S[kj].t∈[rmin,rmax]。那么我们说这是一个匹配,记为例如:给定 S=〈(e1,0),(e2,10),(e3,30),(e4,40)〉,E=〈e2,e3〉,r=[0,20]和W=[0,30],其中 S[2].e=E[1]=e2,S[3].e=E[2]=e3,且 S[2].t≥0,S[3].t≤30,S[2].t-S[3].t∈r。有此可见,对于事件类型序列E,我们可以得到这样一个匹配
有了上面的匹配的定义,我们可以给出类似于传统序列数据挖掘频繁模式支持度的概念。这里我们注意到,因为我们使用了固定时间区间的定义,那么我们的模式定义为一个二元组(E,W),其中E为事件类型序列,W为一个时间窗口。那么在数据集D上,给定一个事件类型序列E在时间窗口W中,满足时间延迟约束r的支持度记为Sup(D,(E,W))。具体公式如下:
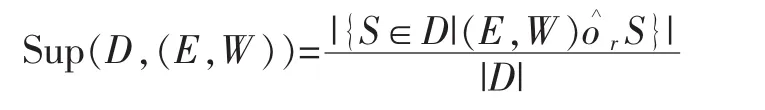
也就是(E,W)在数据集D中的匹配的数量与数据集的大小的比值。这样我们可以给出对比度的定义:CR(E,W)=Sup(D+,(E,W))-Sup(D-,(E,W))。那么,我们可以给出本文模式的准确定义。
定义1(时间区间对比模式WCTP)。在给定两个时序数据集D+/D-,事件类型序列E,时间窗口W,在时间延迟约束r下,一个模式(E,W)是一个时间区间对比模式,那么该模式满足条件:(1)CR(E,W)〉0;(2)不存在W′使得(E,W′)满足条件一,且a.CR(E,W′)〉CR(E,W)或CR(E,W′)=CR(E,W),且||W′||〈||W||。
本文的目的就是要在两组时序数据集D+/D-中挖掘出对比度最高的top-k个WCTP模式。
2 算法实现
本文提出的算法WCTP-Miner主要用来在正负列数据集D+/D-中,找出给定的时间窗口W下满足时间延迟约束r的top-k WCTP。其中WCTP是一个二元组(E,W),相对于之前的对比序列挖掘,本算法不仅要枚举出所有的候选事件类型E,而且需要找到使得E的对比度最高的时间窗口W。所以WCTP算法的主要分为三个步骤a.生成候选事件类型E,b.选出候选时间窗口W,使得CR(E,W)最大,c.更新结果集R。算法1给出了本文的算法框架。
算法1:WCTP-Miner算法框架
输入:D+:正例数据集,D–:负例数据集,k:top-k,r:时间延迟约束,Ω:用户指定相邻的时间区间集合
输出:R:top-k WCTP结果集
1:for从事件类型序列候选集中选取一个E do
3: 根据Ω,选择使得对比度最高的W
4: if(E,W)的优先级属于最高的top-k个then
5: 更新R;
6: end if
7:end for
8:return R;
对于步骤一,为了能系统且无缺失的选出所有的事件类型序列候选集,本算法采用了在对比序列挖掘常用的集合枚举树[2]。在枚举树上,我们提出了如下剪枝条件:
剪枝条件1 给定事件类型序列E,如果Sup(D+,(E,[0,T]))〈CRk(CRk表示当结果集中最小的第k个的对比度),那么在枚举树上,以该E为根的枚举树都会被剪掉。
对于步骤二,因为我们的候选时间窗口以根据用户给定的Ω根据组合直接得到,那么本文的任务就是在候选集中找出使得对比度最高的W。通过研究我们给出了如下剪枝。
剪枝条件2 如果时间窗口W满足Sup(D+,(E,W))〈CRk,那么对于∀W′⊂W,我们都可以直接减去这个时间窗口W′。
3 算法实验
本文采用了在UCI机器学习库中的在线零售数据集[3]作为实验数据集,该数据集记录了一个网上零售商店的交易记录,我们采用该商店2011/02的交易数据作为正列数据集D+,2011/01的交易数据作为负列数据集D-,且Ω为每个时间作为元素,r以10分钟作为跨度。表1展示了使用本算法挖掘出的top-5 WCTPs。
4 结语
本文在以往的对比时序挖掘的基础上提出了在用户指定时间区间上的对比序列模式挖掘。从表1可以看出,在挖掘出的对比模式中,带有用户规定的时间区间。如模式E2的语义为在时间12点到16点之间,交易事件〈粉色茶杯茶托〉的2月与1月的对比中对比度为0.875。这在一定的程度上增加了对比模式的语义,同时用户自定义的时间区间也更能符合用户的需要,具有一定的实际意义。挖掘出的模式,也有助于用户解释模式所蕴含的意义。

表1
[1]Dong,G.,Bailey,J.(eds.):Contrast Data Mining:Concepts,Algorithms,and Applications.CRC Press,Boca Raton(2013)
[2]Rymon,R.:Search Through Systematic Set Enumeration.In:Proceedings of the 3rd International Conference on Principles of Knowledge Representation and Reasoning,KR,pp.539-550,(1992)
[3]Dr Daqing Chen,Director:UCI Machine Learning Repository,(2015)
Mining Top-k Contrast Time Interval Sequential Patterns from Time Sequences
Nowadays,with the development of Internet of Thing technology,more and more sensors have been applied in people′s life,so a lot of time sequences data has been produced.Because the explosion of time sequences data,people want to find useful pattern from time sequences data urgently.There are a lot of sequential patterns analysis algorithms are applied to the time sequences data.Designs and implements an algorithm of mining top-k contrast time interval sequential patterns from time sequences.
Time Sequence;Contrast Mining;Top-k
1007-1423(2017)09-0028-03
10.3969/j.issn.1007-1423.2017.09.007
晏力(1988-),男,四川大学计算学院研究生
2017-03-16
2017-03-20
YAN Li
(College of Computer Science,Sichuan University,Chengdu 610065)
