差额奖惩机制的WSNs节点信任演化模型*
2017-05-10曲蔚贤毛剑琳付丽霞王昌征
曲蔚贤, 毛剑琳, 付丽霞, 郭 宁, 王昌征
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
差额奖惩机制的WSNs节点信任演化模型*
曲蔚贤, 毛剑琳, 付丽霞, 郭 宁, 王昌征
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
针对目前无线传感器网络(WSNs)节点间信任决策导致网络不稳定的问题,引入了差额奖惩机制。在实际中,网络存在不可靠因素,加入丢包率,构建基于奖惩机制的信任演化模型。通过信任演化模型,推导出节点交互时的状态。通过实验分析了节点在选择策略时的各种变化以及差额奖惩机制对演化收敛时间起到的作用,通过实验验证了差额奖惩机制对WSNs中的善意节点最终收敛到信任策略所需节点初始信任策略比例数的要求所起到的作用。差额奖惩机制弥补了在无差额奖惩机制模型中演化收敛速度慢的问题,并且降低初始节点选择信任策略比例数的要求,为WSNs信任机制的设计提供了理论基础。
无线传感器网络; 丢包率; 信任; 演化博弈; 差额奖惩机制
0 引 言
无线传感器网络(WSNs)作为传感器、微机电系统和无线传感器三项技术相结合的产物,是一种新的信息获取和处理技术,已经引起了学术界和工业界的高度重视[1]。文献[2]系统将WSNs研究领域分为环境监测、军事应用和其他的商业应用等方面。其中安全问题又是WSNs研究的重点。1996年,文献[3]首次提出了信任管理的概念,最初信任是用于解决“陌生人”授权的问题。文献[4]提出了一种适应WSNs的动态激励机制,使网络进一步达到信任合作状态,并更快地达到稳定。文献[5]引入了信任合作激励机制,解决了大规模MANET节点不合作的问题。文献[6]针对Ad Hoc网络中节点不合作的问题,提出了非合作博弈的信任模型。文献[7]利用演化博弈论研究了P 2P网络激励机制的动态演化问题,最终实现网络的“软安全”。
1972年,Smith首次提出了演化稳定策略(evolutionary stable strategy,ESS)的概念[8]。于1978年,Taylor和Jonker共同提出了复制子动态(replicator dynamics,RD)的概念[9],使得演化博弈论获得了进一步发展。
本文在信任演化[10]的基础上引入了差额奖惩机制,分析了WSNs节点如何快速达到信任稳定状态,这些研究成果将为WSNs节点信任机制提供理论基础。
1 演化博弈论与WSNs节点信任
1.1 演化博弈论
演化博弈论的过程是在一个大的种群中不断地重复进行匹配博弈的过程。演化博弈论系统含有两个重要的概念,即演化稳定策略(ESS)和复制子动态(RD),分别强调了变异和选择的作用。
1.2 演化稳定策略
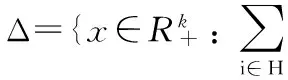
u[x,εy+(1-ε)x]>u[y,εy+(1-ε)x]
(1)
1.3 复制子动态
种群中的每个个体采取的策略都来自Δ。在时间t,采用策略i∈H的个体占总体的比例为xi(t),则种群的当前状态可由向量x(t)=(xi(t),…,xk(t))定义。复制子动态方程[10]可由式(2)给出
(2)
式中 u(si,x)为在种群处于x状态时,采用纯策略i的个体获得的平均收益;u(x,x)为总体平均收益,即
(3)
2 基于差额奖惩机制的WSNs节点信任演化模型
2.1 模型的建立
本文在文献[9]基础上引入了惩罚机制,且奖励与惩罚机制均采用差额的形式。在展示该模型之前,首先对模型的假设作出如下说明:
记L为节点发送的数据包没有到达目的节点而引起的损失;C为节点进行数据包的发送与转发的成本;G1为节点因转发数据包而获得的收益;G2为节点发送的数据包被其他节点转发而带来的收益;A为攻击成本;D为防御成本;a为奖励因子;b为惩罚因子;P为丢包概率;T为信任度。
由于每次节点发送的数据包和转发的数据包并不一定能够到达预定节点,因此导致了不同策略的交互,节点之间的收益不尽相同。以下分情况进行讨论。
1)交互节点双方均选择信任策略
AB节点两两交互时,两个节点均选择信任策略,两个节点均有发包转包行为,每种行为成功与失败对应的结果如表1所示,其中‘1’表示成功,‘0’表示失败。

表1 两个节点均选择信任的收益表
由表1可知:双方选择信任策略的收益均为P2G1+P2G2+P2L+aT-PC-C-L
2)善意节点选择信任策略,自私节点选择不信任策略
AB节点两两交互时,善意节点选择信任策略,自私节点选择不信任策略,每种行为成功与失败对应的结果如表2所示。

表2 善意节点选择信任策略,自私节点选择不信任策略的收益表
由表2可知:善意节点的收益为P2G1+aT-PC-C-L,自私节点的收益为P2G2+P2L-C-L-bT。
3)善意节点选择防御策略,自私节点选择信任策略
AB节点两两交互时,善意节点选择防御策略,自私节点选择信任策略,每种行为成功与失败对应的结果如表3所示。
由表3可知:善意节点的收益为P2G1+P2G2+P2L+aT-PD-D-L。
4)善意节点选择防御策略,自私节点选择不信任策略
AB节点两两交互时,善意节点选择信任策略,自私节点选择不信任策略,每种行为成功与失败对应的结果如表4所示。

表3 善意节点选择防御策略,自私节点选择信任策略的收益表

表4 善意节点选择防御策略,自私节点选择不信任策略的收益表
由表4可知:善意节点的收益为P2G1+aT-PD-D-L,自私节点的收益为P2G2+P2L-C-L-bT。
5)善意节点选择信任策略,自私节点选择攻击策略
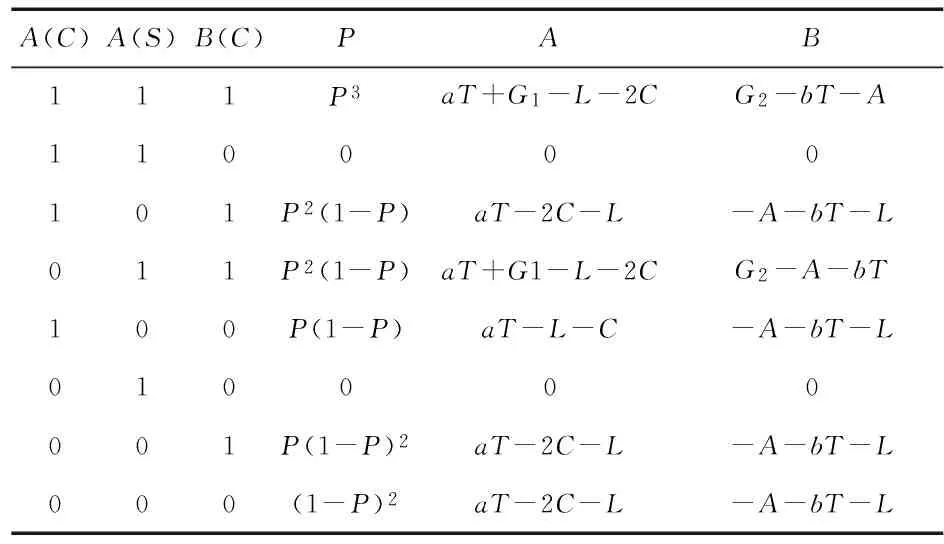
表5 善意节点选择信任策略,自私节点选择攻击策略的收益表
由表5可知:善意节点的收益为P2G1+aT-PC-C-L,自私节点的收益为P2G2+P2L-A-L-bT。
6)善意节点选择不信任策略,自私节点选择攻击策略
双方都只有发包行为,善意节点的收益为-C-L-bT,自私节点的收益为:-A-L-bT。
7)善意节点选择防御策略,自私节点选择攻击策略
善意节点要多付出一部分防御代价,而自私节点要付出攻击代价,所以,善意节点的收益为-D-L+aT,自私节点的收益为-A-L-bT。
8)善意节点选择不信任策略,自私节点选择不策略
双方都选择不信任策略,则双方就只有发包行为,因此,双方的收益为-C-L-bT。
2.2 信任演化稳定策略和演化分析
善意节点和自私节点的收益矩阵可由表6给出。
假设WSNs中理性节点采取信任、不信任及防御策略的比例分别为x1,x2,x3,自私节点采取信任、不信任和攻击策略的比例为y1,y2,y3,其中,x1+x2+x3=1,y1+y2+y3=1。理性节点和自私节点的收益矩阵分别记为A,B,可分别得出

表6 博弈双方的收益矩阵表
根据演化博弈的复制动态方程理论,可以得到两总体复制子动态方程
(4)
(5)
x1x3(y1+y2)PD
(6)
x2x3(y1+y2)PD+x2x3D+x1x3PC-(x1x2+x2x3)
(7)
x2x3bT+(x1x3+x2x3)C+x2x3aT
(8)
(9)
y1y2bT-y1y2aT+y1y2PC+y2y3A
(10)
(y1+y2)y3C-y1y3bT-y1y3aT
(11)
3 实验分析
本文通过Matlab进行仿真,通过设置G1,G2,P,T,C,a,b,L,A,D,T不同的取值来验证博弈过程中的演化稳定。
1)假定G1=10,G2=8,L=2,a=0,b=0,T=10,C=10,D=12,A=8,P=0.8。
当(X,Y)=(x1,x2,x3,y1,y2,y3)=(1/2,1/2,0,1/3,1/3,1/3)时,WSNs的状态如图1。
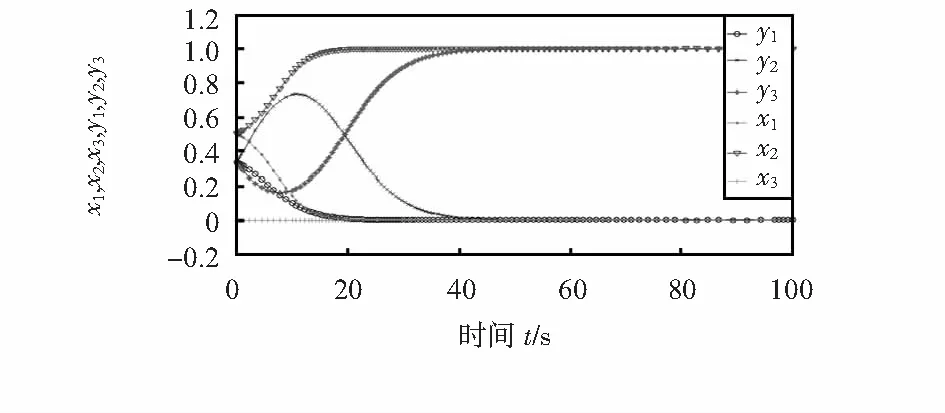
图1 无防御机制下的演化模型
图1仿真结果表明,在无奖惩机制下,理性节点都没有采取防御策略时,自私节点选择攻击策略,理性节点为了减少损失而选择不信任策略,自私节点最终选择了不信任策略,网络最终收敛到双方都不合作的状态,这样将导致网络不能正常地提供服务。
(X,Y)=(x1,x2,x3,y1,y2,y3)=(1/3,1/3,1/3,1/3,1/3,1/3)时,WSNs的状态如图2。
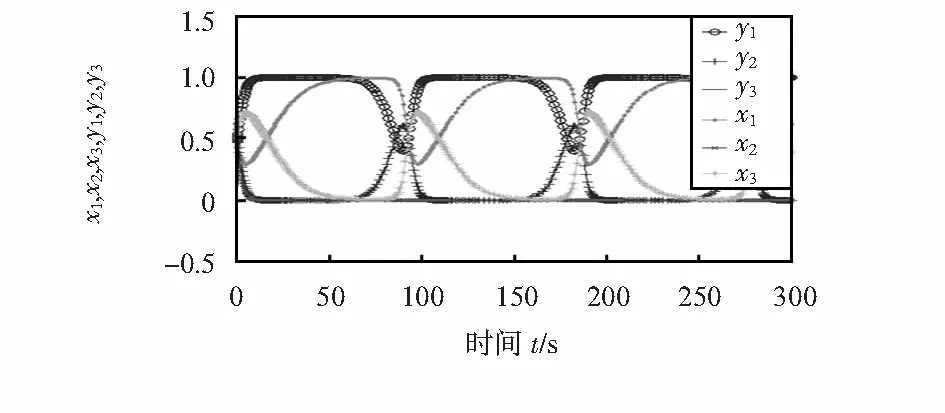
图2 引入防御机制下的演化模型
图2仿真结果表明,在无奖惩机制下,当WSNs有部分理性节点采取防御策略时,自私节点观察到理性节点有采取防御策略,为了使自己的利益最大化而选择信任策略。理性节点发现自私节点都采取信任策略后,也为了自己的利益最大化放弃防御策略去选择信任策略。自私节点又选择了攻击策略,理性节点观察到自私节点的行为后又选择了防御策略,最终使得网络处于一种策略不断交替变换的循环中。
2)假定G1=10,G2=8,L=2,a1=0.1,a2=0.2,b1=0.1,b2=0.2,T=10,C=10,D=12,A=8,P=0.8。
(X,Y)=(x1,x2,x3,y1,y2,y3)=(1/3,1/3,1/3,1/3,1/3,1/3)时,WSNs的状态见图3。
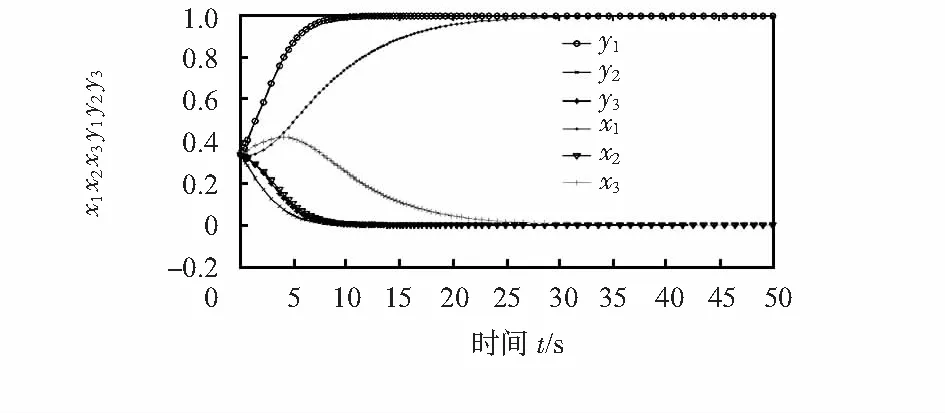
图3 引入差额奖惩机制后的演化模型图
从图3仿真结果表明,WSNs引入差额奖惩机制后,当善意节点与自私节点在采用信任合作策略时,都会得到相应的奖励,因此,所有的节点为了能够使得自己的收益最大化,进而全部采用信任合作策略,整个网络可以有效地避免自私节点的攻击,减少网络能耗,使得整个网络可以给用户提供正常的服务。
4 结束语
WSNs的信任机制是研究WSNs安全的重要方面。本文利用演化博弈对节点的决策过程所建立的模型反映了节点在选择不同策略时的收益。与信任度绑定的差额奖惩机制有效降低了WSNs对节点初始选择信任策略比例数的要求,使得WSNs能够更快地达到合作状态。本文的研究内容揭示了WSNs演化稳定的规律,为WSNs信任机制的设计提供了理论基础。
[1] 陈 英,舒 坚,陈宇斌,等.无线传感器网络技术研究[J].传感器与微系统,2007,26(10):1-5.
[2] Aykildiz I F,Su W,Sankarasubramaniam Y,et al.Wireless sensor networks:A survey[J].Comuter Networks,2002,38(4):393-422.
[3] Blaze M,Feigenbaum J,Lacy J.Decentralized trust manage-ment[C]∥Proc of the 17th Symposium on Security and Privacy,Washington DC:IEEE Computer Society,1996:164-173.
[4] Chen Zhide,Qiu Yihui,Liu Jingjing.Incentive mechanism for selfish nodes in wireless sensor networks based on evolutionary game[J].Computers & Mathematics with Applications,2011,62(9):3378-3388.
[5] 李紫川,沈士根,曹奇英.基于反思机制的WSNs节点信任演化模型[J].计算机应用研究,2014,31(5):1528-1531.
[6] Mejia M,Pena N,Munoz J l,et al.A game theoretic trust model for on-line distributed evolution of cooperation in MANETs[J].J of Networks and Computer Applications,2011,34(1):39-51.
[7] Wang Y F,Nakao A,Vasilakos A V,et al.P2P soft security:On evolutionary dynamics of P2P incentive mechanism[J].Computer Communications,2011,34(3):634-646.
[8] Smith J M,Price G R.The logic of animal conflict[J].Nature,1973,246(5427):15-18.
[9] Taylor P,Jonker L.Evolutionary satble strategies and game dynamics[J].Math Biosci,1978,16:76-83.
[10] 李紫川,沈士根,曹奇英,等.基于反思机制的WSNs节点信任演化模型[J].计算机应用研究,2014,31(5):1528-1531.
[11] 威布尔.演化博弈论[M].王永钦,译.上海:上海人民出版社,2006:188-197.
Evolutionary trust model of WSNs nodes based on graded rewards and penalties mechanism*
QU Wei-xian, MAO Jian-lin, FU Li-xia, GUO Ning, WANG Chang-zheng
(Faculty of Information Engineering and Automation,Kunming University of Science and Technology,Kunming 650500,China)
Aiming at issue of trust decisions among WSNs nodes which can affect WSNs instability,introduce an imbalance rewards and penalties mechanism.The unreliable factors exist in the real networks,introduce rate of the package loss,built on evolutionary trust model of WSNs nodes based on imbalance rewards and penalties mechanism.By the evolutionary trust model,deduce the nodes state of interaction.In the end,through the experimental analysis on various changes of nodes in the selection strategy,effect of the imbalance rewards and penalties mechanism on the evolution of the convergence time.Through the experiment,the effect of the imbalance rewards and penalties mechanism is verified by the results of WSNs,which is a kind of node's initial trust strategy.The imbalance rewards and penalties mechanism for the evolution of the slow convergence in the model mechanism, and can reduce the initial nodes selection strategy trust ratio,which provides the theory basis for the design WSNs trust mechanism.
wireless sensor networks(WSNs); rate of package loss; trust; evolutionary game; graded rewards and penalties mechanism
10.13873/J.1000—9787(2017)05—0011—05
2016—05—31
国家自然科学基金资助项目(61163051); 云南省应用基础研究基金资助项目(2009ZC050M)
TP 393
A
1000—9787(2017)05—0011—05
曲蔚贤(1991-),男,硕士研究生,主要研究方向为无线传感器网络。
毛剑琳(1976-),女,通讯作者,博士,教授,从事无线传感器网络,MAC 层资源分配和优化以及控制网络方面的研究工作,E-mail:km_mjl@aliyun.com。
