基于前导码挖掘的未知协议帧切分算法
2017-04-20王晓晗马云飞
雷 东,王 韬,王晓晗,马云飞
(军械工程学院 信息工程系,石家庄 050003)
(*通信作者电子邮箱ldd_lw@163.com)
基于前导码挖掘的未知协议帧切分算法
雷 东*,王 韬,王晓晗,马云飞
(军械工程学院 信息工程系,石家庄 050003)
(*通信作者电子邮箱ldd_lw@163.com)
针对未知协议帧切分技术存在的效率较低的问题,提出基于前导码挖掘的未知协议帧切分技术。首先介绍前导码作为标识链路帧起始位置的原理,分析候选序列选取问题是现有频繁序列挖掘方法无法对长度较长的前导码进行挖掘的原因,并针对该原因以及前导码挖掘的特点提出从目标比特流中发现候选序列、基于候选序列集合大小变化特征的候选序列选取等改进方法;然后提出未知前导码长度的判定与挖掘方法,从挖掘的众多频繁序列中找出前导码序列,进而对帧进行切分;最后通过采集的真实数据对所提方法的有效性进行了验证。实验结果表明,所提方法能够快速准确地挖掘未知协议比特流中的前导码序列,相比现有方法降低了空间与时间复杂度。
前导码挖掘;频繁序列;帧切分;未知协议;比特流
0 引言
随着网络技术的发展和应用,通信双方为保证通信内容的安全性,开始使用私有的未知协议进行传输,这给网络的安全运行以及监管带来挑战。在电子对抗环境中,监听者通过截获目标通信的物理信号,再解调得到协议未知的链路层比特流数据。如何对未知协议进行识别与分析,并对其有用信息进行提取,是现有研究的一个重要课题[1]。而未知协议的帧切分技术,即从截获的比特流中切分出一个个完整的帧,是该研究的首要工作[2]。
通常,在链路协议已知的情况下,通信双方可通过帧同步功能从比特流中提取出帧数据。但是对于监听方而言,无法准确地得知所捕获数据的链路协议,需要通过数据挖掘等手段,从大量的协议比特流数据中找出标志帧起始的特征序列前导码,然后对帧进行切分。
目前,已有相关文献对该技术进行了研究。文献[3]利用相关滤波区分信息码和帧同步码,使用哈达玛变换(Hadamard Transform)[4]压缩数据识别出帧长,进一步识别出帧同步码的起始位;但是该识别方法仅适用于少量数据的处理,对于大量的比特流数据效率不高。大部分的研究多是采用基于AC(Aho-Corasick)算法的频繁序列挖掘方法,统计获得比特流数据中频繁出现的前导码序列;但由于AC算法的空间复杂度随着频繁序列长度的增加呈指数增长,导致其无法直接挖掘长度较长的频繁序列,金陵[5]通过实验验证其方法仅对长度为3~8 bit的频繁序列有较好的效果。文献[6-7]中通过拼接短频繁序列挖掘长频繁序列,然后识别提取出标志帧起始的特征序列及关联规则序列,给出可能的切分建议,但大量的短频繁序列拼接过程会产生组合爆炸问题,且拼接结果的准确性依赖于短频繁序列的准确性。文献[8]同样基于频繁序列与关联规则挖掘,提取出数据特征序列,寻找其最小位置差对帧进行定界,定界方法只能估算帧的最小长度,并不能进行准确帧切分。文献[9]在将未知混合多协议分离为单协议的基础上,通过研究找到协议的地址信息,最后将单协议的数据帧按地址分为点对点数据帧,为研究数据的获取打下了基础。
针对现有研究存在的问题,本文提出一种快速挖掘标识协议数据帧起始的频繁序列挖掘算法,能够高效准确地挖掘出未知协议链路帧的前导码,并完成帧的切分。
1 链路层帧切分原理
无论是OSI的七层协议体系结构,还是得到广泛应用的TCP/IP体系结构,数据链路层作为其中的底层结构,都发挥着不可替代的作用。除了检错纠错外,其另一主要功能是将比特流拆分成多个离散的帧,为每个帧计算校验和,并将该校验和放入帧中一起传输[10]。本文研究的主要内容便是模仿数据链路层,对捕获到的未知协议比特流数据进行准确帧切分,以便对协议数据进行更进一步的分析与利用。
1.1 研究对象
目标数据的来源一般捕获自某一特定环境下、某一段时间内的协议交互数据,这使得其具有以下特点[11]:
1)大量的数据帧前后相接,组成一个长的比特流,因此需要对其进行帧切分;
2)获得的目标比特流中,链路帧格式是相同的,因为同一条链路上采用的链路协议是固定的。
当具有相同链路帧格式的未知协议比特流数据大量汇聚时,寻找其中的规律便成为可能。
1.2 基于前导码的帧切分原理
为了高效安全地传输,许多数据链路层协议综合使用了字节计数法、字节填充的标志字节法以及比特填充的标志比特法[12]等成帧方法。分析现有已知协议,发现多数通信协议都采用相同的分界模式,即用一个定义良好的比特模式来标识一个帧的开始,该比特模式即为前导码(preamble)。这种定界的模式一般较长,是为了提醒接收方准备接收数据。
前导码由一段伪随机序列构成,具有一定的特性,比如连续的比特“1”或“0”,或者交替出现。对经典的以太网和802.11帧格式及其前导码分析如下:
以太网帧格式如图1所示,其前导码由8 Byte组成,其中前7 Byte为同步码,每个字节均为比特序列“10101010”,最后一个字节为“10101011”,该字节被称为帧起始定界符(Start Of Frame, SOF),表示帧头从其后开始。因此以太网帧的前导码十六进制表示为:AAAAAAAAAAAAAAAB。
802.11帧格式如图2所示,其前导码长度较长,达18 Byte。其中,同步码长度为16 Byte,由128位的全“1”比特组成,SOF长2 Byte,比特序列为“0000 0101 1100 1111 (0x50CF)”。因此802.11帧的前导码用十六进制表示为:
FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF05CF
通过以上分析可知,大多数链路帧都存在一段长度较长的前导码作为帧的起始单元,以保证帧的同步并进行准确切分,那么如何在协议未知,即前导码未知的情况下从大量比特流数据中挖掘出未知帧的前导码是本文研究的重点。

图1 以太网帧格式
Fig.1 Format of Ethernet frame

图2 802.11数据帧格式
Fig.2 Format of 802.11 data frame
2 基于前导码挖掘的帧切分技术
前导码的挖掘,是基于模式匹配算法的频繁序列挖掘。首先对模式匹配算法进行简单介绍。
2.1 模式匹配算法
要从大量协议比特流数据中挖掘出频繁出现的前导码序列,基本方法是模式匹配算法,即从目标比特流S中统计出指定模式P的出现频数与位置的算法,根据查找的候选模式的数量可分为单模式匹配与多模式匹配。
单模式匹配是指在S中只查找一个特定的模式串P的过程,经典的算法有BF(BruceForce)算法[13]、KMP(KnuthMorrisPratt)算法[14]和BM(BoyerMoore)[15]算法等。文献[16]中详细分析对比了这几种算法的效率。由于单模式匹配算法只能查找一个模式串,对于捕获到的未知协议的比特流数据,链路帧的前导码是未知的,因此该方法并不适用。
多模式匹配则是指在目标比特流S中同时查找候选模式集合P中所有的候选模式串的过程,多模式匹配并不是单模式匹配的简单重复,其效率更高。多模式匹配算法有AC算法[17]、AC-BM算法[18]、WM(WuandManber)算法[19]等。
由于AC算法在多模式匹配算法研究中的奠基作用,被视为经典算法,多数面向比特流的频繁模式挖掘方法均基于AC多模式匹配算法进行研究。
2.2 基于AC算法的频繁序列挖掘
AC算法兼具有限状态自动机和字典树的优点,使得其匹配的时间复杂度仅为O(n)。由于其匹配时间不取决于候选序列数量,使其非常适合于候选序列数量巨大的比特流频繁序列挖掘;而且AC算法可以在一次扫描过程中匹配不同长度的候选序列。
2.2.1 候选序列的选取
假设从目标比特流S中挖掘长度为mbit的候选序列,由于目标序列未知,所以枚举出所有可能的2m个模式串作为候选序列,并以完全二叉树的方式表示出来,即字典树,如图3所示。图中是一个长度仅为3bit的候选序列字典树,每一个从根节点到叶子节点的路径都表示一个候选模式串,如000、001、111等。

图3 1~3 bit候选序列字典树
2.2.2 候选序列频数统计
建立好字典树后,便是对目标比特流S进行扫描并统计其中候选序列出现的频数,即字典树中的候选序列与比特流S进行匹配的过程。匹配过程从字典树的根节点开始,遇到叶子节点时,表明从根节点到该叶子节点的路径所代表的候选序列在S中出现一次,对其进行计数。匹配到叶子节点后,并不是直接返回根节点重新匹配,而是按照计算好的fail表(如图3中虚线所示)找到一个最佳的匹配位置,这也是AC算法的精髓所在,减少匹配过程中重复匹配的现象,大大提高匹配效率。
现有文献大多数都是采用该方法进行频繁序列的挖掘,但是都无法回避其存在的缺陷。
2.3 基于AC算法的频繁序列挖掘缺陷
2.3.1 无法直接挖掘长频繁序列
该算法生成的字典树是一个完全二叉树,挖掘长度为m的频繁序列,所需的节点个数为2m+1-1,所需空间着随着m的增加呈指数增长。当候选序列的长度m较大时,其所需的节点个数是无法想象的。AC算法是一个典型的用空间换取时间的算法。以挖掘以太网帧前导码为例,前导码长度为8Byte(64bit),用字典树表示出所有的候选序列,需要265-1(约3.69×1019)个节点空间,所需空间极大。
现有方法采用了剪枝的策略以减少字典树对空间复杂度的需求,即在挖掘统计过程中,根据实时统计的结果,剪掉一些出现频数明显较低的节点。但是该方法是在字典树建立之后,并没有从源头上降低字典树的空间复杂度,如果字典树因为空间复杂度太大而无法建立,此方法将失效。
2.3.2 短频繁序列挖掘结果易受用户数据影响
协议交互比特流数据主要包括协议头部字段和协议用户数据部分。频繁出现的序列是来自协议头部字段中类似于前导码的一些固定字段,相比头部字段中的固定字段,用户数据部分的比特序列则可视为随机序列。而大多数协议数据(如TCP、UDP等)中,用户数据部分占有极大比例。如果候选序列P的长度m较短,那么P很有可能同时出现在头部字段与用户数据部分,导致挖掘的结果偏大。
若目标比特流S是一个完全随机的比特序列,那么其中长度为m的候选序列出现的概率是相同的,均为1/2m。对于用户数据部分,当m每减小1 bit,候选序列P出现在其中的概率就将增加一倍,对挖掘结果的影响将增大;同理,m每增加1 bit,候选序列P出现在用户数据部分的概率将减半。
本文要挖掘的链路帧前导码长度都较长,因此在挖掘过程中受到的影响较小。
2.4 基于AC算法的未知帧前导码挖掘
针对上述分析的现有基于AC算法的频繁序列挖掘方法无法直接挖掘长频繁序列的问题,结合前导码长度较长且长度未知特点,对其进行改进。
2.4.1 候选序列集合的选取
现有方法在构建字典树时,将所有可能的候选序列枚举出来,构成一个完全二叉树。但在实际挖掘的过程中,对于长度较长的候选序列,大部分序列在目标比特流S中出现次数极少,甚至部分序列在S中不出现,浪费了存储空间,可见这种枚举的方法过于盲目。
改进1 从目标比特流S中发现候选序列。
候选序列的选取不再盲目枚举,而是从目标比特流S中选取。对于长频繁序列的挖掘,采用边发现边统计的策略对S进行扫描,每发现一个新的序列,便将其加入字典树并进行计数,直到S扫描完毕。如此,构建的是一个非完全二叉树,将大大减少字典树所需空间。但是该方法使用具有很大的局限性:1)对于短频繁序列挖掘空间复杂度的减小没有帮助,反而增加挖掘时间;2)对于较长的频繁序列挖掘,空间复杂度降低程度不够,发现的候选序列仍然过多。实验1将对该方法进行实验分析。
无论是直接枚举所有候选序列的方法,还是改进方法1,都可以统计出目标比特流S中存在的所有的候选序列出现的频数,而本文只需要挖掘前导码这一项,因此只需要确保候选序列集合中存在前导码这一项。由于前导码在目标比特流S中的每个帧头都会出现,因此,候选序列集合的选取在改进方法1的基础上,再进行改进。
改进2 基于候选序列集合大小变化特征的候选序列选取。
同样是从目标比特流S中选取候选序列集合,从S的头部(或任意位置)开始扫描,由于数据捕获时机的随机性,S的头部不一定从前导码开始,扫描至少一个帧的最大长度(例如以太网帧的最大传输单元(MaximumTransmissionUnit,MTU)为1 500Byte),以确保选取的候选序列中包含前导码,才可对其出现频数进行统计并挖掘。但是,由于目标数据协议未知的特性,帧的最大长度也是未知的。可以根据候选序列选取过程中候选序列集合大小的变化特点快速发现前导码是否已经被加入候选集合。具体思路如下:
1)从目标比特流S的任意部位开始对其进行扫描,每发现一个序列,将其加入候选序列集合T,并且集合的大小Tn加1。
2)如果扫描发现的新序列在T中已经存在,则集合T的大小Tn保持不变。
3)由于最初集合T为空,因此刚开始阶段Tn一直呈线性增长,在该过程中包括前导码在内的某个帧头中的频繁序列也被加入,当在S中发现下一个帧头时,包括前导码等频繁序列已被加入T中,Tn的大小将保持不变。当该帧头扫描过后,Tn又将继续增长。整个过程中,Tn随着对S的扫描,呈阶梯形增长,而Tn在阶梯形中的拐点就是候选序列集合最合适的大小。实验2将展示候选序列选取过程中集合大小的变化特征,而实验3将验证改进方法2的有效性。
一个好的候选序列集合的选取应能在保证挖掘结果准确性的基础上,大幅降低算法的空间复杂度,提高挖掘效率。实验4将对基础的枚举方法,以及提出的改进方法1、2进行对比分析。
2.4.2 前导码长度的判定及挖掘
由于捕获数据协议未知,其帧前导码也未知,前导码长度的判断就显得尤为重要,可以使前导码的挖掘更具有方向性,如已知前导码的长度为m,则只需要在目标比特流S中直接挖掘长度为m的频繁序列即可。
方法原理:对于某一长度为m的前导码K,其在目标比特流S中频繁出现,其子序列(K中包含的长度小于m的序列)必然频繁出现[18],但当长度增加时,其出现的概率与频数都将大大降低,通过这一变化,可以判定前导码的长度。
结合上述有效的候选序列结合方法,提出前导码长度的判别方法:
1)利用改进方法2从S中选取长度为MByte的候选序列,并统计其中出现频数较多的序列KMi及其频数NMi,结果记为RM。
2)候选序列长度M增加1 Byte,再次统计其中出现频数最多的序列及其频数,记为RM+1,对比RM+1与RM中序列频数的变化,随着M的增加,部分序列的频数在减少,而部分序列的频数则保持不变。
3)当频数保持不变的序列在RM+i中是唯一的频数最高的序列,且在RM+i+1中不再出现,则该序列即为前导码,M+i即为前导码的长度;否则跳转到步骤2继续挖掘。
在挖掘得到前导码之后,便可通过前导码对目标比特流S进行准确的帧切分。实验5将对该方法进行验证。
3 实验结果与分析
3.1 实验数据
实验所用数据来自以太网,捕获某一主机在一段时间内使用同种协议的交互数据包,并经过处理使其转换成为带帧头的连续比特流数据,其中S2数据量足够大,如表1所示。

表1 实验所用数据
3.2 从目标比特流S中发现候选序列
实验1以数据量较小的S1为研究对象,采用从目标比特流S中发现候选序列并构建字典树的方法,分别查找其中8、16、32以及48bit长度的候选序列集合,统计该过程中扫描长度(在S1中扫描多少比特即可发现所有候选序列)、发现个数(扫描完S1发现的候选序列个数)以及该过程的耗时,结果如表2所示。
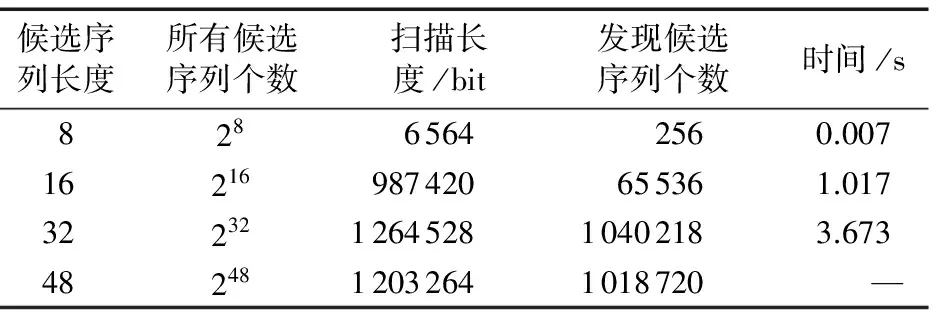
表2 从目标比特流中发现候选序列的结果
由表2可知,在发现8、16bit长度较短的候选序列时,未扫描完S1便已发现所有可能的候选序列,并没有减少候选序列的个数,与枚举法结果相同,反而会在扫描S1上消耗时间,说明该方法对于短频繁序列挖掘空间复杂度的减小没有帮助。在发现32bit长度的候选序列时,扫描完整个S1从中找出约100万个候选序列,相比枚举法的232个,减少为原来的约1/4 000。但是,在对48bit的候选序列发现过程中,对S1扫描到约95%位置时,由于构建字典树深度更大,导致内存空间不足,此时发现约100万候选序列。
综上所述,该方法不适用于长度较短的候选序列发现(可直接用枚举法),而对于长度较长的候选序列的发现,虽然已经大幅减小了候选序列的数量,但是减少后的候选序列个数依旧太多,无法构建字典树,仍需新的方法大力削减。
3.3 基于候选序列集合大小变化特征的候选序列选取
实验2首先验证候选序列集合大小的变化特征。以比特流S2为研究对象,从其任意位置开始(本实验从2 000bit位开始)扫描发现长度为16、32、48、64bit的候选序列,统计候选序列集合大小随扫描比特数增加的变化特点,如图4所示(图中四条曲线由下至上分别是16、32、48以及64bit长度的候选序列集合大小)。由图4可知:扫描初期,随着扫描比特数的增加,候选序列集合的大小(记作K)线性增长,直到虚线a所标识的位置(895bit)时,K不再变化,扫描到虚线b所标识的位置(1 050bit)之后K又开始增长,在a~b区域内停止增长,说明该区域内的序列在之前0~b的范围内已经出现并加入到候选序列集合,根据协议数据帧头中有包含前导码在内的序列频繁且连续性出现,说明在0~b范围内至少有一个包含前导码的帧头出现。因此,从2 000bit位开始,0~b范围内进行候选序列的查找即可发现包含前导码的帧头。
对4个不同长度的候选序列发现结果进行对比可知,候选序列长度较短,易受协议用户数据的影响,导致候选序列集合大小变化特征不明显,而对于长度较长的32、48以及64bit的候选序列集合,其受协议用户数据的影响较小,能更加清晰地显示候选序列集合大小的变化特征。
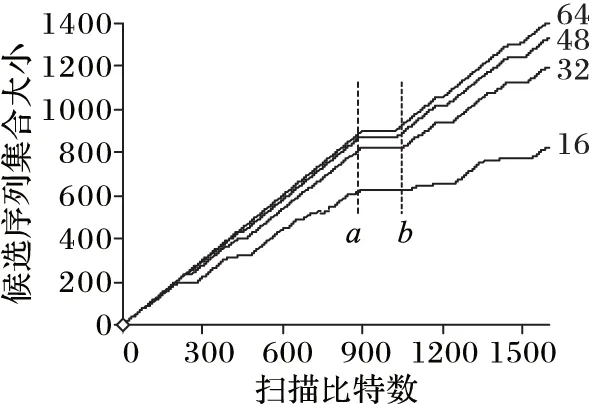
图4 候选序列集合大小变化特征
为了验证上述方法的准确性与高效性,进行实验3。分别从S2数据的0、2 000以及20 000bit位置出发,按照实验2所提方法发现长度为64bit的候选序列,所得结果如表3所示。由表3可知,从S2的不同位置开始选取候选序列,选取的候选序列的个数平均值在1 000左右,相比枚举法以及改进方法1有了显著减少,很好地控制了构造字典树所需的存储空间;并且保证该方法能够发现至少一个包含前导码的帧头。分别使用三个不同起始位置选取的候选序列对S2中的频繁序列进行挖掘,得到的出现频数最高的序列相同,均为:AAAAAAAAAAAAAAAB,频数均为1 000,与已知以太网帧的前导码一致,保证了该方法的准确性。

表3 改进方法2的候选序列选取
实验4以比特流S1为研究对象,挖掘其中长度为32bit的候选序列,将三种候选序列选取方法:枚举法、改进方法1以及改进方法2进行对比,结果如表4所示。由表4可知,枚举法并不从S中选取候选序列,其枚举所有的候选序列,当候选序列长度较长时,其候选序列数量太大,构建的字典树节点空间更大,难以实现;改进方法1与2都是从S中选取,改进方法1扫描完整个S发现其中所有的长度为32bit的候选序列有106个,字典树节点有1.3×107个,相比枚举法,分别缩减为原来的约1/4 000和1/600,但是该方法并没有遗漏任何一个候选序列,可见枚举法对空间的巨大浪费;改进方法2在改进法1的基础上继续改进,仅扫描包含一个前导码的小范围,大大缩减了字典树空间,并且达到挖掘前导码的要求。

表4 候选序列选取方法对比
3.4 前导码长度的判定及挖掘
实验4中为了验证选取候选序列的准确性,使用了已知条件,即以太网前导码的长度为64bit,仅挖掘了长度为64bit的频繁序列,而实际情况是捕获到的数据协议未知,实验5以包含1 000个数据帧的S3数据为研究对象,对提出的前导码长度的判定及挖掘方法进行了验证。
实验初始参数候选序列长度M设置为6Byte,即48bit,因为前导码在设计时为了避免其与协议用户数据的冲突,其长度设计一般大于帧头中最长的固定字段的长度,即MAC地址的长度(6Byte),因此本实验从6Byte开始挖掘前导码,挖掘得到的出现频数最高的序列(十六进制表示)及其频数如表5所示。由表5可以看出,挖掘得到的频数较高的频繁序列主要包括以下三种:全为5的十六进制序列,用“555”表示;全为A的十六进制序列,用“AAA”表示;以及除了最后一位为B其余全为A的十六进制序列,用“AAB”表示。图5清晰地显示了候选序列频数随长度的变化特点。

表5 不同长度频繁序列挖掘结果
由图5可知,随着候选序列长度的增加,序列“555”与“AAA”的频数急速下降到0;而序列“AAB”的频数一直固定为1 000,长度增长为8Byte时,“AAB”成为唯一的频数最高的序列,且其在9Byte的频繁序列挖掘结果中消失,可以得出要挖掘的前导码的长度即为8Byte,前导码为序列“AAB”即AAAAAAAAAAAAAAAB,与已知以太网帧前导码相同。此外,前导码的出现频数1 000即为比特流中包含的链路层帧的个数。

图5 候选序列频数随长度的变化
本文方法通过扫描仅包含一个前导码的小范围选取候选序列,大大减小了构建字典树所需的节点空间,因此可以直接对长度较长的前导码进行挖掘。与现有的先挖掘短频繁序列再拼接得到长频繁序列的方法相比,具有以下优点:1)效率更高。短频繁序列挖掘两两拼接后得到的长频繁序列不一定频繁,需要重新扫描一次目标比特流判断其是否频繁,而大量的短频繁序列两两拼接,再与拼接而成的长频繁序列继续拼接,会产生大量的组合结果,需要对目标比特流进行大量扫描以判断新得到的长频繁序列是否频繁,且该过程前导码的长度很难判断。2)准确率更高。本文分析得知短频繁序列的挖掘结果易受协议用户数据的影响,导致其挖掘的短频繁序列准确率不高,那么由短频繁序列拼接的长频繁序列也会受其影响,而本文方法直接对长频繁序列进行挖掘,不存在该问题。
4 结语
本文分析了链路层基于前导码进行帧切分的原理,面对现有的频繁序列挖掘方法存在的无法对长度较长的频繁序列进行挖掘的问题,针对前导码挖掘的特点,提出了高效的挖掘未知协议前导码的方法,并通过实验验证了该方法的准确性与高效性。最后,通过挖掘得到的前导码完成对未知协议链路帧的切分。本文的研究为未知协议的识别与分析打下了良好的基础,下一步研究重心将放在未知协议格式的推断方面,通过频繁序列挖掘以及关联规则挖掘等方法,推断出未知协议的大致格式,以及其格式中不同字段所代表的语义,进而对捕获到的数据内容进行猜测、利用等探索性研究。
)
[1]EDWARDW.信息战原理与实战[M].吴汉平,译.北京:电子工业出版社,2003:1-20.(EDWARDW.InformationWarfare:PrinciplesandOperations[M].WUHP,translated.Beijing:PublishingHouseofElectronicsIndustry, 2003: 1-20.)
[2]LIF,LIT,ZHANGC-R,etal.Lengthidentificationofunknowndataframe[C]//ICCIS2012:ProceedingsoftheEighthInternationalConferenceonComputationalIntelligenceandSecurity.Washington,DC:IEEEComputerSociety, 2012: 674-677.
[3]BAIY,YANGXJ,ZHANGY.Arecognitionmethodofm-sequencesynchronizationcodesusinghigher-orderstatisticalprocessing[J].JournalofElectronicsandInformationTechnology, 2012, 34(1): 33-37.
[4]MATSUZAWAA,HIGUCHIM,JONAHG,etal.Thejudgmentofdocumentsimilaritiesorthogonaltransformationsandimprovementoftheproperty[J].InternationalJournalofCircuits,SystemsandSignalProcessing, 2012, 6(1): 65-74.
[5] 金陵.面向比特流的未知帧头识别技术研究[D].上海:上海交通大学,2011:29-39.(JINL.Studyonbitstreamorientedunknownframeheadidentification[J].Shanghai:ShanghaiJiaoTongUniversity, 2011: 29-39.)
[6] 王和洲,薛开平,洪佩琳,等.基于频繁统计和关联规则的未知链路协议比特流切割算法[J].中国科技大学学报,2013,43(7):554-560.(WANGHZ,XUEKP,HONGPL,etal.Anunknownlinkprotocolbitstreamsegmentationalgorithmbasedonfrequentstatisticsandassociationrules[J].JournalofUniversityofScienceandTechnologyofChina, 2013, 43(7): 554-560.)
[7] 温爱霞.比特流数据未知协议特征发现技术研究[D].成都:电子科技大学,2016:33-45.(WENAX.Thetechnologyresearchoffeatureselectionforunknownprotocolintheformofbitstream[D].Chengdu:UniversityofElectronicScienceandTechnology, 2015: 33-45.)
[8] 琚玉建,谢绍斌,张薇.基于自适应权值的数据报指纹特征识别与发现[J].计算机测量与控制,2014,22(7):2288-2290.(JUYJ,XIESB,ZHANGW.Identificationofdatafingerprintcharacteristicsbasedonself-adaptiveweights[J].ComputerMeasurement&Control, 2014, 22(7): 2288-2290.)
[9] 郑洁,朱强.未知单协议数据帧的地址分析与研究[J].计算机科学,2015,42(11):184-187.(ZHENGJ,ZHUQ.Analysisandresearchonaddressmessageofunknownsingleprotocoldataframe[J].ComputerScience, 2015, 42(11): 184-187.)[10] RICHARD S W.TCP/IP详解卷1:协议[M].范建华,胥光辉,张涛,等译.北京: 机械工业出版社,2008:1-13.(RICHARD S W.TCP/IP Illustrated Volume 1: The Protocols [M].FAN J H, XU G H, ZHANG T, et al, translated.Beijing: China Machine Press, 2008: 1-13.)
[11] 吴艳梅.无线环境下比特流协议帧定位与特征分析[D].成都: 电子科技大学, 2014: 10-11.(WU Y M.The frame location and protocol feature analysis from the bit-stream in the wireless network [D].Chengdu: University of Electronic Science and Technology, 2014: 10-11.)
[12] TANENBAUM A S, WETHERALL D J.计算机网络[M].严伟,潘爱民,译.5版.北京: 清华大学出版社, 2012: 153-156.(TANENBAUM A S, WETHERALL D J.Computer Networks[M].YAN W, PAN A M, translated.5th ed.Beijing: Tsinghua University Press, 2012: 153-156.)
[13] 鲍震.高速网络入侵监测系统模式匹配算法的研究与实现[D].长沙:国防科学技术大学,2007:10-20.(BAO Z.Research and implementation of pattern matching algorithms based high-speed network intrusion detection system [D].Changsha: National University of Defense Technology, 2007: 10-20.)
[14] KNUTH D E, MORRIS J H, Jr, PRATT V R.Fast pattern matching in strings [J].SIAM Journal on Computing 1977, 6(2): 323-350.
[15] BOYER R S, MOORE J S.A fast string searching algorithm [J].Communications of the ACM, 1977, 20(10): 762-772.
[16] 王和洲.面向比特流的链路协议识别与分析技术[D].合肥:中国科学技术大学,2014:16-17.(WANG H Z.Research on bit-stream oriented link protocol identification and analysis techniques [D].Hefei: University of Science and Technology of China, 2014: 16-17.)
[17] 蔡晓妍,戴冠中,杨黎斌.改进的多模式字符串匹配算法[J].计算机应用,2007,27(6):1415-1418.(CAI X Y, DAI G Z, YANG L B.Improved multiple patterns string matching algorithm [J].Journal of Computer Applications, 2007, 27(6): 1415-1418.)
[18] 万国根,秦志光.改进的AC-BM字符串匹配算法[J].电子科技大学学报,2006,35(4):531-534.(WAN G G, QIN Z G.Improved AC-BM algorithm for matching multiple strings [J].Journal of University of Electronic Science and Technology of China, 2006, 35(4): 531-534.)
[19] 张鑫,谭建龙,程学旗.一种改进的Wu-Manber多关键词匹配算法[J].计算机应用,2003,23(7):29-32.(ZHANG X,TAN J L,CHEGN X Q.An improved Wu-Manber multiple patterns match algorithm [J].Journal of Computer Applications,2003,23(7):29-32.)
This work is partially supported by the National Natural Science Foundation of China (61272491, 61309021).
LEI Dong, born in 1992, M.S.candidate.His research interest include network protocol identification.
WANG Tao, born in 1964, Ph.D., professor.His research interests include information security, side-channel analysis in cryptography.
WANG Xiaohan, born in 1992, Ph.D.candidate.His research interest include network protocol identification.
MA Yunfei, born in 1992, M.S.candidate.His research interest include cube attack on block ciphers.
Unknown protocol frame segmentation algorithm based on preamble mining
LEI Dong*, WANG Tao, WANG Xiaohan, MA Yunfei
(DepartmentofInformationEngineering,OrdnanceEngineeringCollege,ShijiazhuangHebei050003,China)
Concerning the poor efficiency in unknown protocol frame segmentation, an unknown protocol frame segmentation algorithm based on preamble mining was proposed.Firstly, the principle of the preamble being used as the start of frame was introduced.As the cause that the existing frequent sequence mining algorithm cannot mine long preamble directly, the problems in candidate sequence selection were analyzed.Combining with the characteristics of preamble, two methods for selecting candidate sequences from the target bit streams and selecting candidate sequence based on the variation of the size of candidate sequence set were given.Secondly, an algorithm inferring the length of preamble and mining the preamble was put forward for unknown protocol frame segmentation.Finally, experiments were conducted with real bit streams captured from the Ethernet.The experimental results show that the proposed algorithm can rapidly and accurately mine the preamble sequence in the bit stream of the unknown protocol with lower space and time complexity.
preamble mining; frequent sequence; frame segmentation; unknown protocol; bit stream
2016- 07- 22;
2016- 08- 28。 基金项目:国家自然科学基金资助项目(61272491,61309021)。
雷东(1992—),男,陕西咸阳人,硕士研究生,主要研究方向:网络协议识别; 王韬(1964—),男,河北石家庄人,教授,博士,主要研究方向:信息安全、密码旁路分析; 王晓晗(1992—),男,河北衡水人,博士研究生,主要研究方向:网络协议识别; 马云飞(1992—),男,吉林德惠人,硕士研究生,主要研究方向:分组密码立方攻击。
1001- 9081(2017)02- 0440- 05
10.11772/j.issn.1001- 9081.2017.02.0440
TN915.04
A
