基于deepwalk方法的适应有限文本信息的DWLTI算法
2017-04-07江东灿陈维政闫宏飞
江东灿, 陈维政, 闫宏飞
(北京大学 计算机科学与技术系 北京 100871)
基于deepwalk方法的适应有限文本信息的DWLTI算法
江东灿, 陈维政, 闫宏飞
(北京大学 计算机科学与技术系 北京 100871)
提出一种新的网络表示学习算法DWLTI,它是可以同时考虑网络的结构信息和节点的文本属性信息的低维向量表示.DWLTI模型是一种基于deepwalk方法的能够适应有限文本信息的新模型.它通过采用合适的数据融合形式,同时最大化随机游走获得的节点序列和文本内容的词语序列的共现概率.通过应用两棵哈夫曼子树,使得即使只有少量部分节点拥有自身的文本信息,这些稀疏信息也能被充分利用.最后在真实网络数据集上进行节点分类实验,评估学习到的节点表示的质量.实验结果表明,利用有限文本信息的DWLTI优于多种经典基线模型.
deepwalk; 层次Softmax; 有限文本信息; 网络表示学习; 深度学习
0 引言
准确地表达大规模网络节点之间的关系是数据挖掘机器学习领域中一个充满挑战的重要研究目标,也是其他诸多任务不可或缺的前提.近年来,将离散节点映射(embedding)到一个新的低维连续空间中以向量形式表示是网络表示学习(network representation)一个热点方向.
然而在现有的网络表示学习算法中,多数仅仅纯粹考虑网络结构关系,而忽略了节点本身拥有的文本信息内容.比如谱向量(spectral embedding)[1]、MDS[2]、IsoMap[3]等时间复杂度很高的经典学习算法,以及近年来运用神经网络模型通过随机游走序列学习向量表示的deepwalk算法[4], 具有运用节点之间直接邻居关系的一阶模型和运用节点邻居结构相似度的二阶模型的line算法[5]等.同时也存在一些不是为网络设计的算法,它们主要解决如何将文本信息映射成向量的问题,比如传统的词袋模型[6], 基于矩阵分解的潜在语义分析LSA(latent semantic analysis)[7], 主题模型[8-9],基于神经网络的学习方法Word2Vec[10-11], PV-DBOW[12],多向量话题表示方法[13]等,但它们同样仅考虑了节点文本单方面的的信息,而不考虑节点之间的网络结构关系.因此,目前大部分的算法都是仅基于网络结构或是节点文本信息某一方面的内容,鲜有算法将两者结合在一起,通过综合利用网络中共存的各类有效信息,将节点映射表示成能够充分反映网络特征的向量.同时我们也注意到,在很多网络中,除了网络结构关系之外只有部分节点拥有文本信息,如何在文本信息稀疏有限的情况下,还能在向量表示中学习到相关内容,也是一个值得关注的问题.
本文提出一种新的网络表示学习算法,在优化目标中同时考虑网络结构信息和节点自身的文本内容,基于deepwalk对网络中节点与节点之间的结构关系进行建模,基于PV-DBOW对节点自身包含的文本信息建模,并采用正确的融合形式,同时最大化随机游走获得的节点序列的出现概率和文本内容的共现概率,并通过在模型中应用两棵哈夫曼树,使得即使只有少量部分节点拥有自身的文本信息,这些稀疏信息也能在学习中充分发挥作用而不会被稀释忽略,并进一步利用层次Softmax建立二叉树神经网络结构优化模型,采用深度学习的方法训练学习模型参数.最后我们通过线性SVM分类器在数据集上进行分类任务测试向量表示的效果.实验结果表明,我们的算法能够充分利用网络中并存的多类信息,即使在节点信息与文本信息规模不一致的情况下,在训练数据从10%~90%的各种占比的情况下,分类准确率都能优于一些经典的算法.
1 模型设计及求解
带有文本信息的网络可以表示成G=(V,E,D),其中:vi∈V是网络中的节点;ei,j=(vi,vj)∈E是网络中节点直接的连接关系;di∈D是节点i中文本信息中的单位信息.网络表示学习方法的目标是为每个点vi学习它在低维空间中的向量表示,使得在网络结构连接中相近的点,或者在文本内容上具有相似性的点,在映射后的低维空间中向量之间的距离也会更接近.
我们将网络中的节点分为两类:一类是自己具有文本信息的节点;另一类是自己没有文本信息的节点.对网络中的所有节点,我们的模型中采用deepwalk方法对它们之间的网络结构关系进行建模学习; 对于自己具有文本信息的节点,我们的模型中另外对其采用PV-DBOW方法对节点自带的文本信息进行建模学习,最后将两者结合在一起,两类信息共同对节点的向量表示产生影响.由于我们的融合过程里文本信息学习过程和节点关系的学习过程没有混杂在一起,而是分别对节点向量产生影响,所以即使只有有限的节点具有文本信息,也能充分发挥这些文本信息的作用,不会由于这类节点在网络整体中占比太小而导致这些稀疏信息在学习过程中被忽略.
1.1 采用deepwalk方法学习网络结构信息
deepwalk中发现一个无标度网络图中节点出现的频率也是符合幂律分布的,这和自然语言中词频是符合幂律分布具有相同的特征,所以deepwalk提出了引入自然语言领域中发展成熟的神经网络模型来处理网络中的结构信息,他选择使用Word2Vec模型[10-11].
在网络结构信息的模型中,我们通过在网络中构造随机游走的序列来学习网络中节点的向量表示.任意选取一个起始节点vi,从这个节点开始,随机选择一个它的邻居节点作为序列中的下一个节点,再从这个被选中的节点开始继续这个随机过程,直到产生预设数量的序列节点个数.通过这种随机游走产生的序列,我们获得了网络结构信息.这种将序列控制在一定长度内的随机游走有两个优点:一是方便并行,多个局部可以同时探索;另一方面是一旦局部信息发生了变化,我们不用在全局中重新计算.
将网络中的所有节点看作词汇表,随机游走生成的序列即为一种特殊语言中的句子.采用Word2Vec 中的SkipGram算法作为语言模型,其思想是给定句子中的某个词(某个节点),最大化一个句子(序列)中在其左右一定窗口范围(i-w,i+w)中出现的词(序列中周围的节点)的出现概率,所以优化目标为
(1)
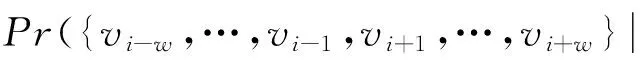
(2)
其中:N是节点的总数量;S是随机游走获得的序列集合.逐次迭代更新向量表示,实现对这个优化目标的求解,最后,在图结构中相互连接或者连接关系临近的点在低维向量空间中的向量也会更加靠近.
具体算法如下:
输入:图G和相关参数(窗口大小,序列抽样个数,序列长度等)
输出:映射表示矩阵Φ
随机初始化表示矩阵
进行γ次随机游走
对所有节点乱序排列
所有节点依次作为初始节点,作以下循环处理:
从这个节点开始随机游走,产生预设长度的序列
对每个序列用SkipGram模型进行处理,对随机游走得到的序列中的每个点vi
用窗口大小w获得向左和向右的2w个节点
用这个窗口中的每个节点uk,更新
1.2 采用PV_DBOW学习部分节点的文本信息
将文本信息表示成向量的最原始的模型是词袋模型BOW(bag-of-words)[6], 但是词袋模型具有一些不可忽略的缺点,比如它忽略了词汇之间的语义关系,近义词在词袋模型中的表示往往依然是不同的,以及向量表示的空间维度可能太高并存在高维引起的稀疏问题等.PV-DBOW(paragraph vector without word ordering: distributed bag of words)[12]方法是另一种运用神经网络将文本信息映射成低维空间向量的方法,它是一个非监督的学习框架,能够从长度不定的文本信息中学习定长的向量表示.相同语义的词语在新的低维空间中的位置也是相近的,并且它们之间的距离也是具有意义的,比如“国王”的向量,减去“男性”的向量,加上“女性”的向量,将会在“王后”的向量附近.
根据PV-DBOW算法,对于给定的文本序列,我们设定一定的窗口长度,随机设定窗口位置,并从这个窗口范围内随机抽取单词来进行预测,这个方法和Word2Vec中的SkipGram算法的思想实际上是相似的,但是PV-DBOW能够对任意长度的文本信息比如句子、段落、文章等都进行学习.
1.3 DWLTI模型
针对网络中同时具有网络结构信息和仅有部分节点自身的文本信息的特点,我们设计了新的能够适应有限文本信息的deepwalk方法,我们称其为DWLTI模型(deepwalk with limited text information),它综合运用deepwalk学习网络结构信息和PV-DBOW学习文本信息的思想,使得映射到低维空间中的向量表示同时充分具有这两类信息中的特征.
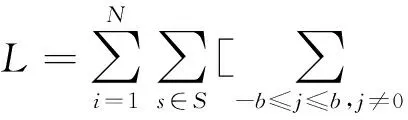
在上述算法的迭代更新中,当规模变大时,直接对P计算的计算量将变得非常大,所以需要进一步采用层次Softmax[14-15]来估计这个概率.将每个点都作为一个二叉树的叶子节点,从而将上述概率转化成对从树的根节点到达某个叶子节点的路径的概率,假设从根节点到叶节点uk的路径中经过的树节点为b0,b1, …,b, 上述概率即为Prvj),其中Pvj)可以用一个二分类器Pr)来计算选择左子树或是右子树的概率,σ是一个sigmoid函数.
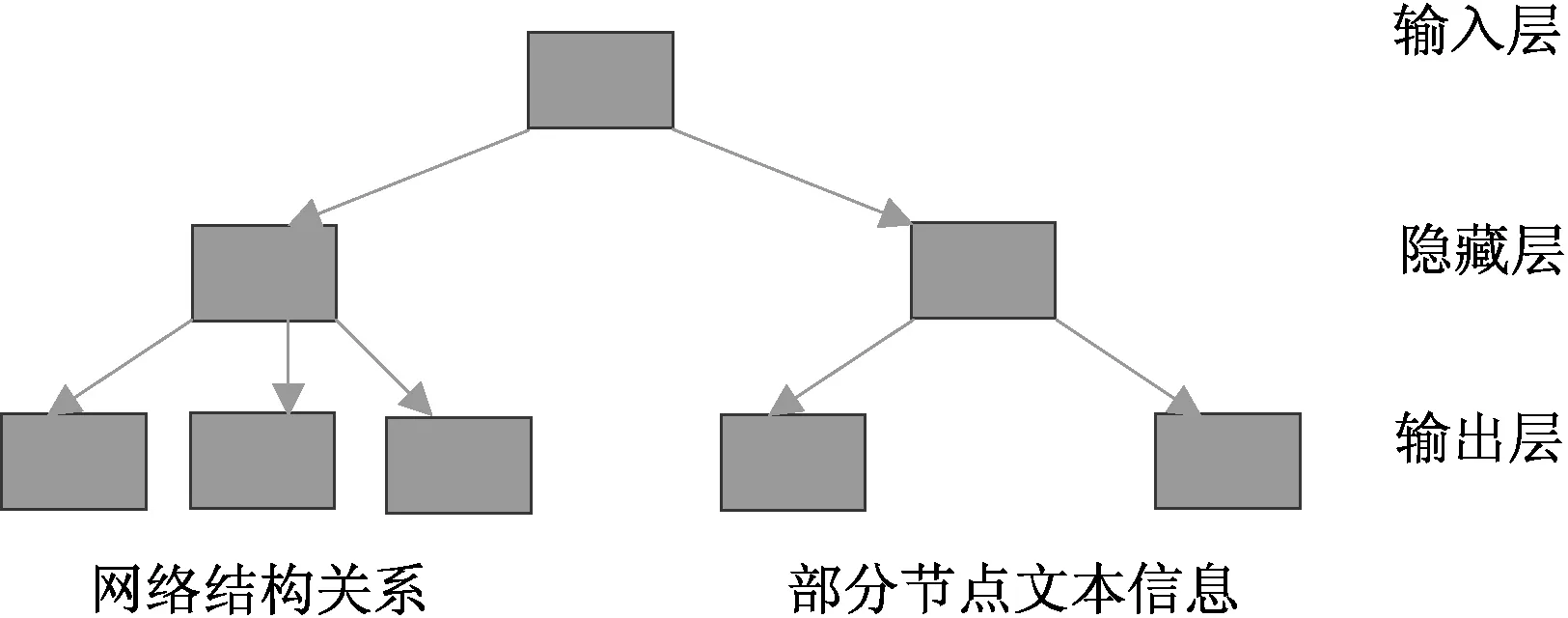
图1 DWLTI哈夫曼树Fig.1 DWLTI Huffman tree

由于我们的优化函数中同时存在网络结构和文本信息两部分的内容,并且这两部分信息的规模大小可能并不一致,所以在DWLTI模型中通过两棵哈夫曼树来进行迭代更新,和将两种信息混杂在一棵哈夫曼树中相比,即使拥有文本信息的节点数量较少,这些信息也能全部通过单独的哈夫曼树发挥作用,而不会被大量的网络结构信息节点稀释忽略,示意图如图1所示.
2 实验
2.1 实验数据集及参数设置
为了检验向量表示的结果,我们选择了两个数据集Cora和Citeseer,先通过我们的DWLTI模型学习出节点对应的低维空间向量,再用线性SVM利用获得的低维空间向量进行分类任务.
Cora数据集中有2 708篇机器学习相关的论文,其中包含7个具体的子类和5 429条连接.连接定义为论文之间的引用关系,同时文档自身的内容信息用一个1 433维的0-1向量表示.
Citeseer数据集中有3 312篇著作,其中包含了6个具体的子类和4 732条连接.和Cora数据集相似,连接是论文之间的引用关系,同时文档自身的内容信息可以用一个3 703维的0-1向量表示.
在实验中,我们设置DWLTI模型的向量长度d=200,窗口大小等于10.每个节点选择80个随机游走序列,每个随机游走序列的长度等于40,并将文档的内容信息转换成序列进行学习.最终用线性SVM在模型学习出的向量表示上进行分类任务,采用准确率作为度量标准.
2.2 实验结果
我们选用经典的deepwalk和line算法作为实验结果对比.对deepwalk对应参数设置与DWLTI相同的值,对line算法采样个数为1 000万.在实验结果表1和表2中,line(1st)表示line的一阶模型,line(2nd)表示line的二阶模型, DWLTI(0.2)表示网络中只有20%的节点自身具有文本信息,DWLT(0.5)表示网络中只有50%的节点自身具有文本信息.

表1 Cora数据集上的节点分类准确率

表2 Citeseer数据集上的节点分类准确率
实验结果表明,我们的DWLTI算法几乎在所有情况下的分类准确率都优于几种经典算法.即使是文本信息节点稀疏的情况下都能充分利用有限的信息,在我们的实验中,即使只有20%或50%的节点具有文本信息,也能达到比deepwalk和line算法更优的结果.因此,在DWLTI模型中学习得到的向量表示具有更高的分类准确率.DWLTI算法是一种适应有限文本信息的网络表示新模型,在网络表示学习研究中具有一定的意义.
[1] TANG L, LIU H. Leveraging social media networks for classification[J]. Data mining and knowledge discovery, 2011, 23(3):447-478.
[2] COX T F, COX M A A. Multidimensional scaling[M].2nd Edition.Florida: CRC Press, 2000.
[3] TENENBAUM J B, DE S V, LANGFORD J C. A global geometric framework for nonlinear dimensionality reduction[J]. Science, 2000, 290(5500):2319-23.
[4] PEROZZI B, AL-RFOU R, SKIENA S. Deepwalk: online learning of social representations[C]//Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, 2014:701-710.
[5] TANG J, QU M, WANG M Z, et al. Line: large-scale information network embedding[C]//Proceedings of the 24th International Conference on World Wide Web. Florence, 2015: 1067-1077.
[6] MANNING C D, RAGHAVAN P, SCHÜTZE H. Introduction to information retrieval[M].Cambridge: Cambridge University Press, 2008:824-825.
[7] LANDAUER T K, FOLTZ P W, LAHAM D. An introduction to latent semantic analysis[J]. Discourse processes, 1998, 25(2):259-284.
[8] HOFMANN T. Probabilistic latent semantic indexing[C]//Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. Sheffied, 2004:56-73.
[9] BLEI D M, NG A Y, JORDAN M I. Latent dirichlet allocation[J]. Journal of machine learning research, 2003,3(1):993-1022.
[10]MIKOLOV T, CORRADO G, CHEN K, et al. Efficient estimation of word representations in vector space[C]//Proceedings of Workshop at ICLR.Florida,2013:1-12.
[11]MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality[C]//Advances in Neural Information Processing Systems 26.Lake Tahoe,2013:3111-3119.
[12]LE Q V, MIKOLOV T. Distributed representations of sentences and documents[J]. Computer science, 2014, 4:1188-1196.
[13]李欣雨,袁方,刘宇,等.面向中文新闻话题检测的多向量文本聚类方法[J].郑州大学学报(理学版),2016,48(2):47-52.
[14]MORIN F, BENGIO Y. Hierarchical probabilistic neural network language model[C]//Proceedings of the International Workshop on Artificial Intelligence and Statistics. Cambridge, 2005: 246-252.
[15]MNIH A, HINTON G E. A scalable hierarchical distributed language model[C]//Conference on Neural Information Processing Systems. Vancouver, 2008:1081-1088.
(责任编辑:王海科)
DWLTI Method Based on Deepwalk with Limited Text Information
JIANG Dongcan, CHEN Weizheng, YAN Hongfei
(DepartmentofComputerScienceandTechnology,PekingUniversity,Beijing100871,China)
A new network representation method was proposed.It could simultaneously consider both the network link structure information and the text information on some nodes in the optimization goal. It had created a correct format to merge those parts to maximize the co-occurrence probability of the nodes sequence gotten by random walk and the word sequence in text. The new model used two Huffman sub-trees to make all text information useful even with small amount of nodes. It used Hierarchical Softmax to optimize the model by building binary tree and learned model parameters using deep learning.Linear SVM was chosed to test the quality of vector representation in the new low-dimension embedding space. The experimental result showed that the new method DWLTI was useful in the network with limited text information on part nodes. The results of DWLTI were better than some other classical models in this field.
deepwalk; hierarchical Softmax; limited text information; network representation; deep learning
2016-11-15
973项目(2014CB340400);国家自然科学基金项目(U1536201,61272340).
江东灿(1992—),女,福建南平人,硕士研究生,主要从事搜索引擎与数据挖掘研究,E-mail:dongcan.jiang@gmail.com; 通讯作者:闫宏飞(1973—),男,吉林扶余人,副教授,主要从事搜索引擎与数据挖掘研究,E-mail:yhf1029@gmail.com.
TP301.6
A
1671-6841(2017)01-0029-05
10.13705/j.issn.1671-6841.2016312
