基于多图像组信息的人脸识别研究
2017-02-15段晓东王存睿李泽东
逯 波,段晓东,王存睿,李泽东
( 大连民族大学 a.大连市民族文化数字技术重点实验室 b.计算机科学与工程学院,辽宁 大连 116605)
基于多图像组信息的人脸识别研究
逯 波a,b,段晓东a,b,王存睿a,b,李泽东a,b
( 大连民族大学 a.大连市民族文化数字技术重点实验室 b.计算机科学与工程学院,辽宁 大连 116605)
提出利用多图像组信息构建二部学习框架进行人脸识别。首先,利用两种不同的多图像组信息源分别学习两个相应的度量空间模型;其次,将得到的模型合并为一个统一的判别距离度量空间;最后,对所构建的二部学习框架进行范化,使得框架中的多图像组信息能够用来进行子空间学习和距离度量学习。通过在多个标准通用数据集上得到实验结果验证了所提出方法的有效性。
人脸识别;多图像组信息;距离度量学习
在人脸识别领域,每一个被试都对应多张人脸图像,以此改进人脸分类器及学习模型的性能表现,并将每个被试所对应的多张图像称之为多图像组信息。本文针对多图像组信息主要考虑两类问题:首先,在已知测试集中获取具有相同信息的人脸图像数据,例如,在视频追踪检测过程中进行人脸识别,通常很难在视频序列中推断相同的人脸图像信息;其次,在人脸图像组信息是已知的前提下,如何找到哪些图像数据构成了这些组信息的问题,例如,在一个家庭相册中进行人脸识别时,每个未知家庭成员都对应于一组人脸图像,但无法确定哪些未知成员的人脸图像信息构成了组信息。
为了解决上述难题,同时提高在以上两种场景中人脸识别的性能表现,本文提出利用多图像组信息构建了一个统一的二部框架,在框架中能够独立的在训练集和测试集中进行距离度量学习,并将结果合并到一个判别距离度量空间中。同时,提出的二部框架具有良好的扩展性,能够合并任意两种不同的度量方法,比如子空间学习技术[1-2]和距离度量学习方法[3-4],此外,这些度量方法在框架中能够使用有监督和半监督两种学习方法。
在利用有监督学习模式时,二部框架能够直接在测试数据集使用组信息来形成约束条件。在利用半监督学习模式时,二部框架能够使用已知的组信息源代替某些不可用组别信息,这些信息均以无监督的方式进行推断。基于有监督学习和半监督学习的二部框架可视化描述如图1,其中分别使用A、B、C、D以及实心圆圈、三角形等图案代表训练集和测试集中的数据。在整个二部框架中,可以进行有监督学习和半监督学习,在训练集和测试集上同时学习两种距离度量模式。当测试数据集上具有已知的组信息时,距离度量就可以通过组别标签来进行学习,即保证有监督学习二部度量。当训练和测试数据集上具有部分未知组信息时,距离度量可以通过无监督模式进行学习,即保证半监督学习二部度量。

图1 基于有监督学习和半监督学习的二部框架
1 二部学习框架
1.1 二部框架基本理论与方法
文中提出的二部框架,分别使用了两种不同的距离度量,一种从训练集学习得到,另一种从测试集学习得到。
给定数据集中任意两张图像xi和xj,则距离度量A的形式如下:
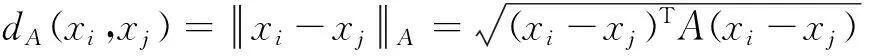
(1)
式中,A是半正定距离度量函数,可看作是马氏距离参数化形式的一种。在式(1)中利用乔里斯基分解WWT替代A,可以得到:

(2)
由于二部框架方法通过使用W代替W1W2的方式,融合了两种距离度量。因此,二部距离度量可定义为:
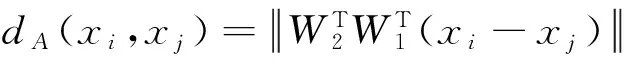
(3)
式中,W1和W2分别对应于从训练集和测试集学习得到的距离度量。通过式(3)可以看出,利用W1将原始的人脸图片映射到Rd1空间,利用W2映射到Rd2空间。其中由于W2保留了之前的映射信息,所以W2起到更重要的作用。
为了说明在式(3)中W1和W2是如何学习的,文中将在接下来的部分讨论W1的学习过程,而W2的学习过程具有相似的步骤。

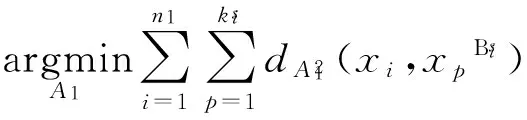
(4)
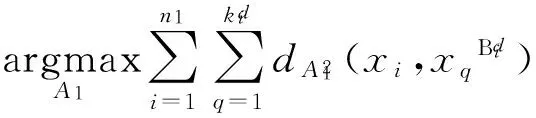
(5)
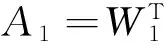
通过式(4)和(5)结合形成目标函数:
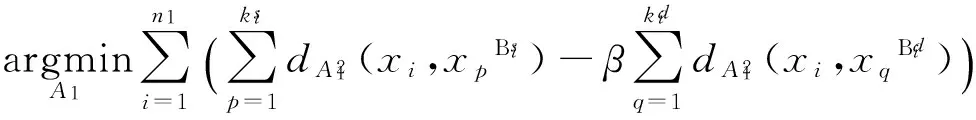
(6)
式中,β用来量化两种类型约束的相关重要性,距离度量A1和W1可以由式(6)得到。对于A1,任意两个样例之间的距离可以看作是使用映射矩阵W1所得到的欧氏距离[5],而W2可以从训练集中学习得到。因此,通过W1和W2,可以由式(3)得到最终的距离度量A。
1.2 二部框架构建
本节主要介绍二部框架的构建过程,二部框架的主要作用是能够成为子空间学习和距离度量学习桥接纽带。在式(3)中,我们可以使用映射矩阵W作为子空间学习,同时,在式(4)中,A1可以被任意的度量用A所取代,从而作为距离度量学习。
针对线性子空间学习算法,其目标可以转换为以下形式:
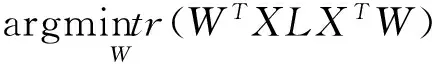
(7)
例如,局部保留映射算法(LocalityPreservingProjections,LPP)在式(7)上可增加的约束条件为Id=WTXLTW,而主成分分析(PrincipalComponentAnalysis,PCA),线性判别分析(LinearDiscriminantanalysis,LDA)等算法在式(7)上可增加约束条件为WTW=Id。
另一方面,针对距离度量方法可以用下面公式表示:


(8)

1.3 二部框架的应用性能
为了整合和改善子空间学习和距离度量学习方法,本文所提出的方法可以用来提供有监督学习或半监督学习的框架。
针对有监督学习的二部框架模式,可以用来处理已知多图像组信息的人脸识别任务。在这种模式下,测试集中的组信息是已知的,并用来训练和学习距离度量。通过W1和W2可以分别从测试集或训练集进行学习,同时W1能够从数据集中学习更多的信息。在本文实验中,我们从测试集学习W1,因为有更多的测试图像。当W1和W2学习完成后,使用二部方法合并这两种距离度量,同时这种顺序映射能够得到一个单一映射结果,其中包含了来自训练集和测试集的有用信息。
文献[6]中也定义了一种合并两个度量学习的相类似方法,其作法是将局部保留投影和线性判别分析方法进行合并和优化,最终形成一个目标函数。然而,文献[6]中仅适用了来自于训练集中的信息,忽略了测试集中的有用信息的利用。此外,本文中的二部方法不需要求解拉普拉斯矩阵,因此,所提出的二部方法具有更好的扩展性,适用于合并和优化大多数方法,并最终归纳为式(7)和(8)。
在性能方面,二部度量W1W2的性能并不弱于W1或W2,当W2为满秩时,由于没有对W2进行降维,所以W1W2的性能和W1一样。如果W2不影响整体性能,则可将W2设置为单位矩阵。此外,二部框架方法可以通过将W1和W2置换为任意的映射矩阵来泛化为一个有监督学习框架,其中的映射矩阵可以通过子空间学习或距离度量学习方法进行学习,如在式(7)和(8)中所提到的。
2 实验与分析
2.1 数据集
在实验过程中,我们使用了四个人脸识别数据集,其中包括从Yale人脸数据库中选取了15名被试,每人对应11张人脸图片并包含不同的人脸表情;从UMIST人脸数据库中选取20个人的564张人脸图像并包括不同的姿势;从ChokePoint监控录像数据集[8]中选取80个人的共560张的人脸图像,包括不同的光照,姿势,锐度和校准变化;从FG-NET数据集中选取66个被试,每人11张人脸图像。实验中所采纳的被试者年龄范围从新生儿到69岁。这些数据集中部分人脸样例如图2,其中从第一行到最后一行的图像分别来自于YALE,UMIST,ChokePoint和FG-NET。
此外,YALE,UMIST和ChokePoint数据集中的图像已经进行了对齐处理,并且根据眼睛位置进行了裁剪,尺寸为40×40大小,并归一化灰度值为0255之间。在FG-NET数据集中,每个图像包括68个标记点,用来描述形状特征,这些点是通过主动外观模型(ActiveAppearanceModel,AAM)来进行特征提取的,同时利用主动外观模型提取458个模型参数来表示每个单独的个体。
图2 数据集中的部分图像样例
2.2 对比方法
为了验证本文提出方法的有效性,在实验过程中,将二部框架方法与下列方法进行了对比。
(1)标准子空间学习方法线性判别分析LDA和局部保留映射LPP;(2)半监督判别分析(Semi-supervisedDiscriminantAnalysis,SDA)[7];(3)基于图像集合距离的线性一体式方法(LinearAffineHullBasedImageSetDistance,L-AHISD)[9],(4)大间隔最近邻方法(LargeMarginNearest-Neighbour,LMNN)[4]。

2.3 实验设计
在实验过程中,每个被试都提供一组人脸图片。在训练集中,所有的组信息都带有被试标签,在测试集中则不设置此类标签。实验的目标是能够正确识别这些没有标签的多图像组信息。
这些多图像组信息被直接使用到有监督学习的二部框架以及基于图像集合距离的线性一体式方法L-AHISD中,在其他的方法中,使用投票方法来识别测试集中无标签的组图像信息。
在对测试集中的组信息识别实验过程中,每个被试被假设有多个图像相对应。同时,测试集没有相对应的存在被试的多图像组信息。我们使用基于半监督学习的二部框架方法解决这类问题,在测试集中使用k近邻方法构建组信息。而基于图像集合距离的线性一体式方法L-AHISD并不使用此设置。半监督判别分析SDA和基于半监督学习的二部框架方法同时使用训练集和测试集;其它所有的方法只使用训练集进行学习。在训练过程中,设置t=2,每个被试对应4个样本进行训练,t为每个被试对应的训练样本数量;剩余的样本用于测试。
2.4 实验结果
各个方法进行对比时的平均识别率和标准差见表1-2。其中,表1对应于未知多图像组信息的人脸识别,表2对应于已知多图像组信息的人脸识别。为了便于阐述实验结果,将使用的数据集分别表示为YALE、UMIST、ChokePoint、FG-NET。将本文提出的方法和对比方法分别表示为有监督二部度量(半监督二部度量)、LMNN、L-AHISD、LDA、SDA和LPP。此外,在表1和表2中,t是每个被试对应的训练样本数量,括号中的数字是最终映射空间中的维度。
在未知多图像组信息的人脸识别的实验中,根据表1可观察到,半监督二部度量的结果最好,然后是LMNN,如公式(8),这两种方法有着相似的目标函数。然而,对于不相似的人脸图像,半监督二部度量有着更强的约束,同时在测试集中也利用了判别信息。而LDA,SDA和LPP在低维子空间也可得到相似的结果,但是识别率不准确。
在已知多图像组信息的人脸识别实验中,根据表2可观察到,只使用多图组识别信息进行投票,有监督二部度量和L-AHISD比其他方法取得更好的性能。同时,有监督二部度量通过使用训练集和测试集信息,在大多数数据集上的准确率要优于L-AHISD。
当有更多训练集时,所有方法的性能都有所提高,例如,表1和表2中t=4时。然而,在我们实验设计中,如果有更多的训练集则意味着有更少的测试集。因此,当训练集稀缺时,二部框架使用测试集来增强学习到的映射,而二部框架方法和其他方法则期望于使用更高的t取值来缩小两者之间的性能差距。
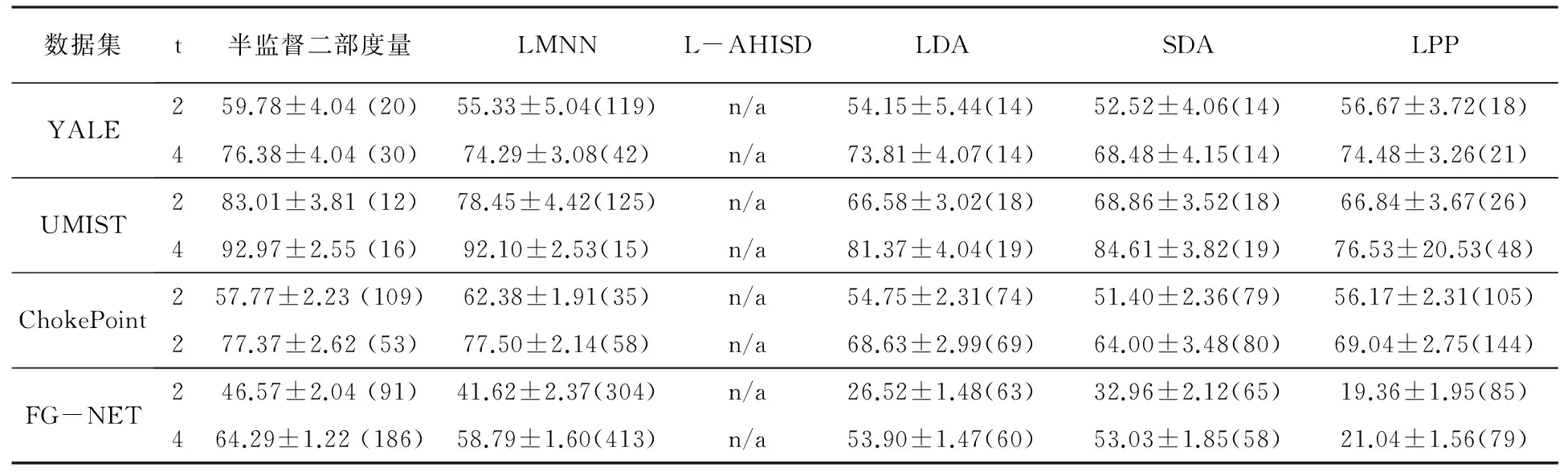
表1 未知多图像组信息的人脸识别
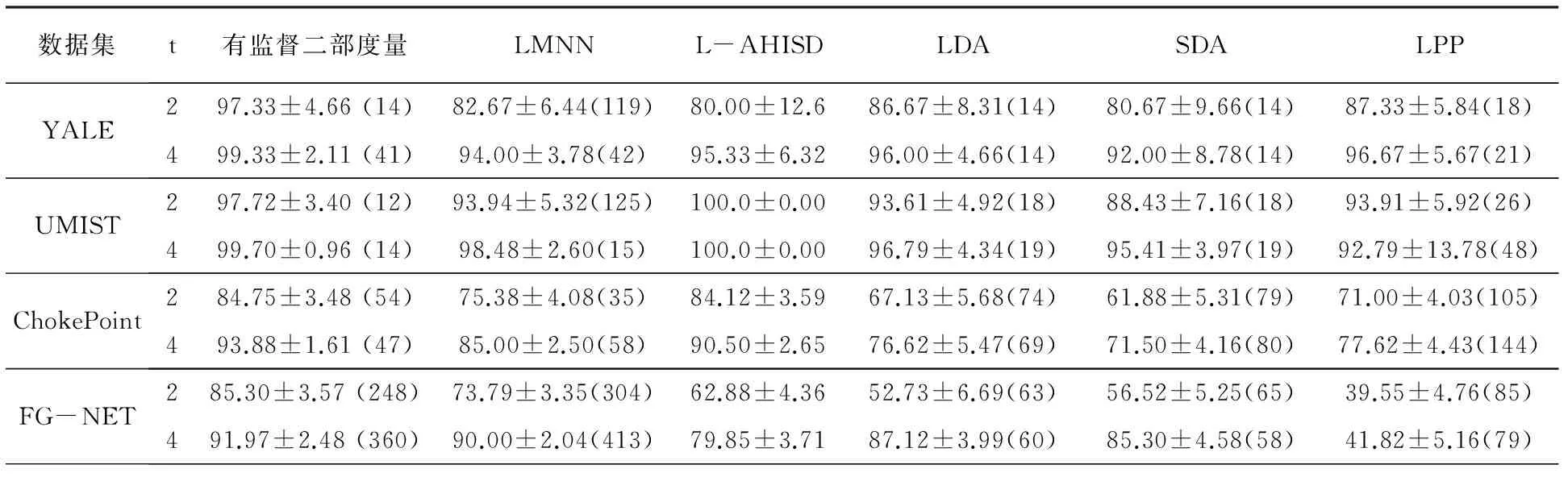
表2 已知多图像组信息的人脸识别
3 结 论
本文针对使用多图像组信息的两类常见问题,提出了利用多图像组信息构建二部学习框架进行人脸识别任务。在构建二部学习框架过程中,利用两种不同的多图像组信息源分别学习两个相应的度量空间模型,将得到的模型合并为一个统一的判别距离度量空间。对所构建的二部学习框架进行统一规范化,使得框架中的多图像组信息能够用来同时进行子空间学习和距离度量学习。通过在多个数据集上与其他方法进行比较,验证了本文所提出的方法在进行人脸识别时具有更好的性能表现。
[1]HEX,NIYOGIP.Localitypreservingprojections[C].ProceedingsofNIPS,Canada, 2003:153-160 .
[2]ZHANGT,TAOD,YANGJ.Discriminativelocalityalignment[C].ProceedingsofECCV,France, 2008:725-738.
[3]XINGE,AN,etal.Distancemetriclearningwithapplicationtoclusteringwithside-information[C].ProceedingsofNIPS,Canada, 2002:505-512.
[4]WEINBERGERK,SAULL.Distancemetriclearningforlargemarginnearestneighborclassification[J].JournalofMachineLearningResearch, 2009(10):207-244.
[5]ROWEISST,SAULLK.Nonlineardimensionalityreductionbylocallylinearembedding[J].Science, 2000,290(5500):2323-2326.
[6]SUGIYAMAM.Dimensionalityreductionofmultimodallabeleddatabylocalfisherdiscriminantanalysis[J].JournalofMachineLearningResearch, 2007(8):1027-1061.
[7]CAID,HEX,JHan.Semi-superviseddiscriminantanalysis[C].ProceedingsofICCV,Brazil, 2007:1-7.[8]WONGY,SC,etal.Patch-basedprobabilisticimagequalityassessmentforfaceselectionandimprovedvideo-basedfacerecognition[C].ProceedingsofCVPRWorkshop,USA, 2011:74-81.
[9]CEVIKALPH,TRIGGSB.Facerecognitionbasedonimagesets[C].ProceedingsofCVPR,USA, 2010:2567-2573.
(责任编辑 邹永红)
Face Recognition based on Group Information of Multiple Images
LU Bo, DUAN Xiao-dong, WANG Cun-rui, LI Ze-dong
(Key Lab of Dalian Nationalities Culture and Digital Technology,School of Computer Science and Engineering, Dalian Minzu University, Dalian Liaoning 116605, China)
In this paper, we propose a bipart framework to take advantage of group information of multiple images of each subject in the testing set as well as in the training set. Two different sources of group information of multiple images which are utilized to learn two metric space models independently are combined to form a unified discriminative distance space. Furthermore, the bipart framework is generalized to allow both subspace learning and distance metric learning methods to take advantage of this group information. The proposed framework is evaluated on the face recognition problem using several benchmark datasets, which demonstrates the validity.
face recognition; group information of multiple images; distance metric learning
2016-11-21;最后
2016-12-21
国家自然科学基金项目(61672132,61602085,61370146);辽宁省科技计划项目(2013405003);中央高校基本科研业务费专项资金资助项目(201501030401, 201502030203)。
逯波(1982-),男,内蒙古赤峰人,讲师,博士,主要从事多媒体检索领域研究。
段晓东(1963-),男,吉林辽源人,教授,博士,主要从事民族人脸识别领域研究,E-mail:duanxd@dlnu.edu.cn
2096-1383(2017)01-0071-04
TP391
A
