制造业上市公司财务预警模型构建
2016-12-07李海玲
李海玲
制造业上市公司财务预警模型构建
李海玲
针对制造业短期财务预警模型缺乏的现状,本文以2014年数据为模型样本,尝试以Logistic和Fisher构建短期财务预警模型。在此基础上,以2016年公布的2015年1867家制造业上市公司数据为检验样本,对模型预警能力进行检验。旨在为对企业管理、短期投资、或相关利益者有效辨别财务困境提供有效模型。
Logistic回归;Fisher判别;财务预警;制造业
一、研究背景
(一)国内外文献综述
国外,最早是Fitzpatrick进行财务危机单变量预警,后期研究从单变量突破到多变量。关于多变量的研究,主要有多元线性、多元逻辑、多元概率三大类模型。还有其他研究,即尝试着对基本模型加入现金流量、审计意见、股权治理等新因素,期望提高财务困境预警模型准确率。
国内研究始于上世纪八十年代,相对于国外起步较晚,可以借鉴的国外研究很多,所以国内研究轨迹基本和国外是一致的。在此基础上,以我国企业数据为样本,国内学者也尝试着进行了一些有益的探索。首先,分行业进行研究。最新的文献主要有王洪艳(2015)生物制药业、梁飞媛(2014)机械制造业、张国政(2015)农业、定鹏(2012)高校、邢有洪(2011)航空公司等。其次,分模型进行研究。相对于国外三大类模型,国内偏向于研究三大类模型中的这些具体模型:Ahmna的Z值模型、Fisher判别模型、Logistic模型、网络神经模型。
(二)研究目的
纵观国内研究,虽然取得了重大进展,但是,还存在一定的研究空间。首先,行业方面。随着《中国制造2025》规划的推出,制造业备受关注。但是,对于制造业,近三年有关制造业财务预警文献并不多。其次,模型方面。虽然有些财经类网站提供上市公司Z值预警,但与公布的ST真实结果相差较大。当然,国内许多研究表明,Logistic模型准确率相对较高。但是,对此模型,绝大部分学者选择以年度数据进行检验。针对短期财务困境的预警模型还十分匮乏,不能满足短期投资需求,故本文尝试构建短期财务预警模型,旨在为相关利益者有效辨别短期财务困境提供参考。
二、Logistic模型构建
(一)样本及指标选取
1.样本选取
首先,样本行业选取制造业。根据国内外学者研究发现,样本所处行业不同,财务指标呈现较大的差异性,因此,ST预警结合行业更加精确合理。根据我国证监会行业统计,共有18个行业。纵观各行业上市公司的数量、各行业被ST的公司数量,制造业在这两方面都位居首位,故本文选取了2014年制造业上市公司作为模型样本,以其2012年至2014年数据为样本数据。其次,样本容量大、数据新。最后,样本配比比例多次测算。国内外对于ST和非ST公司的配比有1:1、1:2、1:3,本文通过对1:1到1:4的几种比例进行测算对比,发现1:2建模是最佳的,而且过高的配比比例会影响模型的稳健性。对于本文选取的样本见表1:

表1 制造业上市公司ST预警样本选取情况 单位:家
2.指标选取
在选取指标时,考虑到以下几个特点:(1)获取性。本文主要是为了构建简易模型,能够通过财务指标快速地预测被ST的可能性。所以,在选取指标时,要考虑指标容易获取。本文的指标通过新浪、同花顺等财经类网站均可获取,便于决策者快速预测。(2)全面性。单项财务指标反映的能力有限,本文从6个方面选取指标作为自变量,旨在提高预警效力。(3)稳定性。选取每种财务能力的核心指标,过多的指标进行组合建模会影响模型的稳定性。综上,构成自变量的指标具体如表2所示:

表2 预警指标选取情况
(二)Logistic模型构建
1.正态性检验
本文首先对所选取的12项财务指标进行正态性检验,这主要通过SPSS软件中的K-S检验来实现。从检验结果可知,在a=0.05的显著水平下,只有X10的双侧显著性0.2>0.05,服从正态分布,其他指标均不服从正态分布。
2.显著性检验
针对正态性检验的不同结果,选用不同的显著性检验。首先,对服从正态分布的X10采用独立样本T检验,从检验结果可知,方差方程的Levene检验结果为sig.=0.001<0.05,并且F=11.452,说明两组方差不相等。当方差不相等时,X10双侧显著性0.000<0.05,说明X10在是否ST上存在显著性差异。其次,对其他指标采用两个独立样本非参数检验中的Mann-Whitney U检验,从检验可知,在a=0.05的显著性水平下,只有X7的双侧显著性0.213>0.05,说明X7在是否ST上不存在显著性差异。综上,对于所有指标,只有X7没有通过显著性检验。
3.拟合度检验

表3 Logistic模型分类表
表3反映利用回归模型对原始值的预测情况。整体预测正确率为79.44%。根据国内外相关文献,有相当一部分研究以最低误判率来寻找分割点。本文的分割点为0.5,如果调整分割点为0.42,则整体预测正确率为80.7%。参照现有的国内外文献,模型正确率接近80%,拟合方程的整体拟合效果是比较高的。其中,对非ST公司预测的正确为91.6%,说明模型对这个单项预测效果很好。但是,对ST公司预测的正确率为55.1%,预测正确率偏低,这主要是由于模型通过ST近三年的数据建立的,2/3的样本距离ST(财务困境)发生的时间超过一年。较早的财务指标还不能充分反映ST公司财务困境的特点。因为财务困境是一个随着时间逐步恶化,是一个渐进的过程。当然,本文也尝试以年度作为控制变量建立模型,消除时间因素,但其结果与本模型准确率基本一样,故不调整模型。
4.Logistic回归模型构建
根据回归结果中方程式中的变量,通过显著性为0.05 Wald检验的自变量有:X2、X3、X8,说明这3个变量对是否ST具有显著影响,其他变量没有通过显著性水平。根据统计结果,3个变量的系数均为负,说明这3个自变量每增加一个单位,发生ST的可能性只是小于一个单位的75.4%、88.9%、47%。根据表中的相关系数,进一步得出Logistic拟合回归方程为:

(三)Logistic模型预测
本文前面第二部分,已通过2014年ST和非ST公司为样本建立了财务预警模型,整体准确率比较高。在此基础上,为了检验模型预测能力,本文再运用此模型对制造业上市公司1867家2015年的ST与非ST情况进行预测,并与证监会2016年公告的2015年ST结果进行对比。由于本文基于短期财务预警模型缺乏的现状,预检验模型的短期预测能力,所以检验期间选取2015年的4个期间进行短期预测,即2015年第一季、中期、第三季和年度,这四个期间分别对应2015年被ST前9个月,6个月、3个月和0个月。列示ST前各个期间,有利于考察模型在各期间的预警准确率和变化趋势。当然,财务报告对外公告的时间一般都比其所属期间晚,所以,在运用此模型进行预测时,要注意ST预测期间所涵盖的时间范畴。具体预测效果见表4。
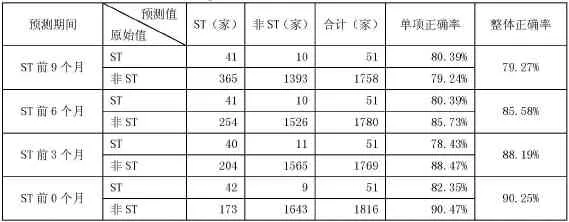
表4 Logistic模型2015年预测能力检验
从表4可以看出:首先,在预测期间准确率方面,各期间的单项和整体准确率几乎都在80%以上,说明该模型具有很高的预测能力。有利于快速准确地把握制造业上市公司短期财务预警状况。其次,在准确率变化趋势方面,距离ST发生的时间越近,ST预警模型的单项与整体准确度都越高,模型预测能力更强,说明自变量可以有效地解释及预测因变量。
三、Fisher模型构建
对于制造业财务预警,本文也尝试着运用Fisher判别构建模型。运用同样的数据,通过SPSS软件进行分析,根据Fisher判别函数系数,构建的ST的判别表达式表示如下:
非ST=-0.53X1+0.947X2+0.182X3-0.009X4-0.001X 6+3.284X8+1.881X9+0.235X10+0.001X11+0.164X12 -11.929
ST=-0.351X1+0.684X2+0.101X3-0.01X4+0.002X5-0.004X6+2.597X8+1.861X9+0.237X10-0.008X11-0.48X12-11.094
在此基础上,再运用此表达式对2015年制造业上市公司进行预测,判断其是否被ST,从而检验模型的预测能力。对2015年制造业上市公司1867家的4个期间进行预测,其中,各个期间数据存在披露不全的公司。剔除这些公司,对预测结果进行整理如表5所示:
从表5可以看出:首先,在预测期间准确率方面,各期间准确率都比较高,但每个期间单项和整体准确率都比Logistic模型低。其次,在准确率变化趋势方面,距离ST发生的时间越近,ST预警模型的单项与整体准确率就越高,这与Logistic模型的预测变化趋势是一致的。
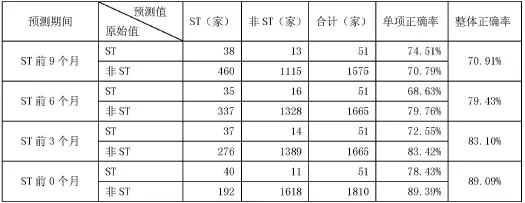
表5 Fisher模型2015年预测效果检验
四、结论
本文以2014年制造业上市公司为样本,利用其近三年数据为样本,以反映财务6大核心能力的12项财务指标作为预警指标,建立财务预警模型。本文运用Logistic回归、Fisher判别两种模型建立财务预警,并以最新的2015年数据为检验样本对模型预警效果进行检验。检验结果显示:两种模型单项和整体准确率都比较高。而且距离ST发生的时间越近,ST预警模型的单项与整体准确度都越高。但是,相比较而言,不管是单项还是整体,Logistic模型比Fisher模型准确率更高。总之,对于短期财务预警模型比较缺乏的现状,本文通过模型进行实证检验,旨在为对企业管理、短期投资、或相关利益者有效辨别财务困境提供有效模型。
盐城师范学院校级品牌专业建设工程支柱项目。
[1]王宗胜.我国制造业上市公司财务困境预警分析[J].统计与决策,2015(3):174-177.
[2]王洪艳.生物制药行业上市公司财务预警模型构建[J].财会通讯,2015(19):33-36.
(作者单位:盐城师范学院商学院)
