基于Hadoop的云平台的实现与基准测试
2016-11-30王研,张岩
王 研, 张 岩
(1. 沈阳师范大学 教育技术学院, 沈阳 110034; 2. 中国医科大学 生物医学工程系, 沈阳 110013;3. 沈阳师范大学 计算机与数学基础教学部, 沈阳 110034)
基于Hadoop的云平台的实现与基准测试
王 研1,2, 张 岩3
(1. 沈阳师范大学 教育技术学院, 沈阳 110034; 2. 中国医科大学 生物医学工程系, 沈阳 110013;3. 沈阳师范大学 计算机与数学基础教学部, 沈阳 110034)
Hadoop 是google云计算理论的开源实现,作为软件系统中间件的软件框架,它可以对大量数据进行分布式处理。通过Haddop,用户可以在不了解分布式底层细节的情况下开发分布式程序,充分利用集群的威力进行高速运算和存储。通过使用VMware虚拟机技术实现在单机上配置多个虚拟计算机节点,从而进行集群测试;在虚拟节点上安装Ubuntu操作系统作为Hadoop的操作系统支持;同时,利用Xmanager软件,以及配置局域网中宿主机与虚拟机、远程控制机的网络参数,实现对虚拟节点的远程控制;在已经安装好Ubuntu操作系统的各个虚拟节点上安装Hadoop、java-JDK等软件,并进行相关的参数设置,实现在虚拟机上各个虚拟节点的Hadoop完全分布式平台。最后在Hadoop平台上,使用Hadoop软件自带的基准测试程序包对平台进行4个Hadoop的经典基准测试。同时,每个测试都会加载不同的数据量及负载进行多次实验,通过比较在不同的负载下Hadoop的基准测试结果,测试Hadoop平台的相关性能,并分析负载及数据量的变化对Hadoop平台性能的影响。
云计算; Hadoop; 基准测试; 虚拟机
0 引 言
云计算的核心思想是将分布在网络上的若干计算机组成一个集群,将大量用网络连接的计算机资源统一管理和调度,构成一个计算资源池向用户提供所需的服务。而底层的技术对于上层用户完全透明,对于用户来说,就好像使用一台服务器来提供服务一样。随着网络技术的发展与大数据的应用越来越普及,云计算技术在更多更广泛的领域受到了人们的重视。Hadoop作为云计算技术的一种实现方法,具有成本低,安全性高等优点。同时,Hadoop框架作为一种开源的中间件技术,允许用户在Hadoop框架之上实现自己的应用逻辑,具有可扩展,开源性,普及性等优点。因此研究Hadoop平台的实现方法以及测试平台性能有着现实意义。本文将研究Hadoop平台在虚拟机上的实现,同时进行Hadoop平台的基准测试,并对测试结果进行分析。
1 Hadoop完全分布式平台的实现
1.1 实验软硬件配置
联想电脑2台,1台作为linux虚拟系统的宿主机,1台作为远程控制终端机。软硬件配置见表1。

表1 实验平台软硬件配置
1.2 虚拟机设置

表2 各节点IP地址
在宿主机上安装VMware软件,由VMware虚拟出4个计算机节点。计算机节点操作系统采用Ubuntu12.04 server。本实验采用1个Master节点和3个Slave节点,可以先安装一个Master节点,并配置相关参数。再使用VMware的克隆功能克隆出3个Slave节点。同时对虚拟机的网络进行相应的配置使得虚拟节点之间能够进行网络通信。将VMware的虚拟网络适配器设置为Bridge(桥接)方式,这样可以给虚拟机分配一个与宿主机以及远程终端机相同网段的IP地址,实现多台主机连接,本实验使用网段为192.168.52.X。具体IP地址如表2所示。
1.3 在终端机上实现远程控制虚拟机
在终端机上安装Xmanager软件。Xmanager是一款小巧、便捷的浏览远端窗口系统的工具,通过对Xmanager进行简单的配置,即可实现将网络中的某台计算机作为远程控制终端,进行远程控制虚拟机里的各个节点的功能,同时还可以利用Xmanager自带的ftp工具实现虚拟节点与控制终端之间的文件传输。通过Xmanager,建立对4个虚拟机节点的连接,连接协议选择SSH,在主机名称里分别输入4台虚拟节点对应的IP地址,并配置帐号与密码。连接后即可通过终端远程控制虚拟节点。接下来的操作均在远程终端输入。
1.4 安装配置Hadoop与JDK
1.4.1 JDK参数配置
安装好JDK后在/etc/profile中配置环境变量。
export JAVA_HOME=/usr/java/JDK1.7.0_45
export HADOOP_HOME=/usr/Hadoop/Hadoop-1.2.1
export JAVA_BIN=/usr/java/JDK1.7.0_45/bin
export PATH=$PATH:$JAVA_HOME/bin: $HADOOP_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
1.4.2 Hadoop参数配置
在Hadoop安装目录下的conf里,根据系统情况修改6个配置文件:Hadoop-env.sh,core-site.xml,hdfs-site.xml,mapred-site.xml,Masters,Slaves。其中在hdfs-site.xml文件里将数据副本数设置为2。
〈configuration〉
〈roperty〉
〈ame〉fs.replication〈name〉〈-dfs里数据的片段份数,即有无副本--〉
〈alue〉〈value〉property〉
〈configuration〉
同时,在/etc/network/interfaces文件中配置主机的IP地址并在/etc/hosts文件中配置DNS。配置好Master节点后,对Slave各节点也进行相应的配置。
1.5 配置各节点的SSH协议
SSH为Secure Shell的缩写,是建立在应用层和传输层基础上的安全协议,专为远程登录会话和其他网络服务提供安全性保障。利用 SSH 协议可以有效防止远程管理过程中的信息泄露问题。在本实验中中的使用SSH协议可以使得节点之间可以免密码登录。
首先对4个节点分别产生公私密钥,设置本地无密码登录。然后让4个节点里的authorized_keys都包含4个节点的公钥。为了实现这个功能,可以先将Slave1、Slave2、Slave3中的id_dsa.pub分别复制到Master下,再追加到Master的authorized_keys里,最后把这个authorized_keys复制回Slave1,Slave2、Slave3替换原来的authorized_keys。配置完成后,即可实现免密码连接其他节点。
1.6 查看集群运行情况
在Master节点输入命令start-all.sh启动Hadoop集群守护进程。
在各个节点输入命令jps可以查看各节点守护进程情况(见图1、图2)。
root@master: ~# jps
10894 SeconaryNameNode
10712 NameNode
10976 JobTracker
11099 Jps
图1 Master节点守护进程
root@slavel: ~# jps
13136 Jps
12956 DataNode
13043 TaskTracker
图2 各Slave节点守护进程
在Master节点运行hadoop dfsadmin-report可以查看集群情况。
在Master节点运行hadoop fsck加上相关参数,可以查看HDFS文件系统情况。
2 Hadoop平台的基准测试
为了深入研究Hadoop平台性能,需要对完成的Hadoop平台进行相关的测试。本文采用Hadoop最常用的几个基准测试程序进行测试,并对测试结果进行分析。
2.1 TestDFSIO测试
TestDFSIO用于测试HDFS的IO性能,使用一个MapReduce作业来并发地执行读写操作,每个map任务用于读或写一个文件,Map的输出用于收集与处理文件相关的统计信息,Reduce用于累积统计信息,并产生Summary。本实验分别在文件数量相同(单个文件)但数据大小不同,以及数据总量相同但文件数量不同的情况下进行了测试。
2.1.1 对5个文件(1 G~20 G)执行TestDFSIO测试
测试结果(见表3、表4)表明,在集群较小的情况下,对单个文件测试时,IO读写时间随数据量增加而呈曲线增加,并且读时间要低于写时间;同时读写吞吐量随数据量增加而减少(见图4)。

表3 单个文件写测试

表4 单个文件读测试

图3 单个文件TestDFSIO测试结果
2.1.2 对数据总量相同(10 G)但文件数量不同(1~20)的数据执行5次TestDFSIO测试
测试结果表明,在集群较小的情况下,虽然数据总量保持不变(10 G),但随着文件数量、并发map数量的增加,平台执行性能逐渐降低,其中当文件数由2个增加到5个时,写测试的执行时间增加明显,当文件数再次增加时,执行时间趋于稳定;而读测试的执行时间随文件数量增加显著增长。

表5 总数据10G文件数量不同的写测试

表6 总数据10G文件数量不同的读测试

图4 总数据10G、文件数量不同时的TestDFSIO测试结果
2.2 mrbench测试
mrbench会多次重复执行一个小作业,用于检查在集群上小作业的运行是否可重复以及运行是否高效。本实验使用mrbench程序分别进行重复执行小作业测试,结果如表7所示。

表7 mrbench测试结果
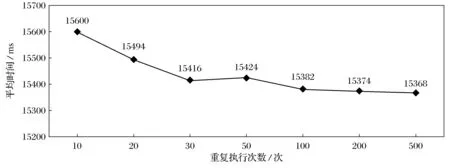
图5 mrbench测试结果
从测试结果可以看出,随着小作业从数量的增加,作业执行的平均时间逐渐趋于稳定并缓慢下降。
2.3 WordCount
WordCount主要完成功能是统计一系列文本文件中每个单词出现的次数。本实验使用WordCount程序分别对100M、200M、500M、1G、2G大小的文件进行测试。

表8 WordCount测试结果
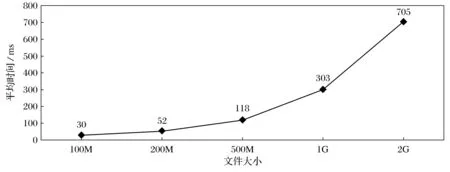
图6 WordCount测试结果
测试结果表明,随着数据量的增加, WordCount程序执行时间呈曲线增加。
2.4 TeraSort
TeraSort程序通过对文本文件里的字符进行排序来测试Hadoop平台的性能。实验分别对100M,200M,500M,1G,2G的文件进行排序测试。

表9 TeraSort测试结果
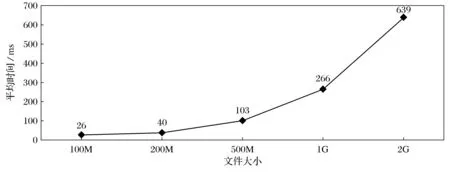
图7 Terasort测试结果
测试结果表明,随着数据量的增加,Terasort程序执行时间呈曲线增加。
3 结 语
本文在介绍了虚拟机上实现Hadoop完全分布平台的全部过程,同时在实现的Hadoop平台上进行了一系列的基准测试,并对测试得到的数据结果进行了分析。从测试中可以看到,随着测试数据量的增大,Hadoop平台的优势开始慢慢显现出来。当然,实验只是在虚拟机上进行了平台实现与测试,数据量与真实情况仍有一定差距。在实际生产应用中,Hadoop平台的集群网络规模与服务器性能都非常强大,处理的都是TB甚至PB级别的数据。本实验起到了对Hadoop平台实现与测试分析的研究作用,后续还需要在实际的计算机集群网络甚至服务器上进行进一步的测试与研究。在此基础上,还可以对Hadoop软件架构的参数配置文件、实现算法等方面做进一步的优化研究。
[ 1 ]WHITE T. Hadoop权威指南[M]. 3版. 北京:清华大学出版社, 2014.
[ 2 ]ARUN C M, VAVILAPALLI V K, EADLINE D, et al. Hadoop YARN权威指南[M]. 北京:机械工业出版社, 2015.
[ 3 ]HOLMES A. Hadoop硬实战[M]. 北京:电子工业出版社, 2015.
[ 4 ]崔文斌,牟少敏,王云诚,等. Hadoop大数据平台的搭建与测试[J]. 山东农业大学学报(自然科学版), 2013,44(4):550-555.
[ 5 ]张新玲. Hadoop平台基准性能测试研究[J]. 软件导刊, 2015,14(1):30-32.
[ 6 ]张岩,郭松,赵国海. 基于Hadoop的云计算试验平台搭建研究[J]. 沈阳师范大学学报(自然科学版), 2013,31(1):85-89.
[ 7 ]李三淼,李龙澍. Hadoop中处理小文件的四种方法的性能分析[EB/OL].[2015-11-13]. http:∥www.cnki.net/kcms/detail/11.2127.TP.20141230.1656.014.html.
[ 8 ]管莹,李佳音. 基于Hadoop的实验室数据管理系统的实现[J]. 电脑编程技巧与维护, 2014(4):39-40.
[ 9 ]潘慧,朱信忠,赵建民,等. 基于Hadoop云测试体系架构的设计[J]. 计算机工程与科学, 2013,35(10):73-78.
[10]徐东. 基于Hadoop的云教学资源平台设计与实现[D]. 北京:北京交通大学, 2014.
[11]张洪磊. 基于Hadoop的医院数据中心系统设计与实现[D]. 杭州:浙江大学, 2014.
[12]刘源. 基于Hadoop的海量数据分析系统设计与实现[D]. 大连:大连理工大学, 2013.
[13]张朋,常静,范福玲. 云计算与高等院校教育信息化变革研究[J]. 科教文汇(上旬刊), 2012(9):24-25.
[14]李丹. 校园分布式系统集成管理平台的设计与实现[J].电子测试, 2013(13):3-4.
[15]潘丹,甘宏. 基于异构集群环境下Hadoop作业调度优化的研究[J]. 科技广场, 2015(9):16-19.
[16]尹颖,林庆,林涵阳. HDFS中高效存储小文件的方法[J]. 计算机工程与设计, 2015(2):406-409.
Implementation and benchmarking of cloud platform based on Hadoop
WANGYan1,2,ZHANGYan3
(1. School of Educational Technology, Shenyang Normal University, Shenyang 110034, China; 2. Department of Biomedical Engineering, China Medical University, Shenyang 110013, China; 3. Computer and Basic Mathematics Education Department, Shenyang Normal University, Shenyang 110034, China)
Hadoop is an open source implementation of Google cloud computing theory. Hadoop, as a software framework, can process a large amount with distributed processing. By using Hadoop, users can develop a distributed program, and make full use of the cluster to carry out high-speed computing and storage, even without knowing the details of the distributed layer. In this paper, we use VMware virtual machine technology to realize the configuration of multiple virtual computer nodes on a single machine, and then use it to carry out the cluster test. As the Hadoop's operating system, Ubuntu operating system is installed on virtual nodes; meanwhile, with the help of Xmanager software, host computer and virtual machine, as well as referring to network parameters from the remote controller, the remote control of virtual nodes is realized. In the Ubuntu operating system, Hadoop, java-JDK, and other software are installed on each virtual node. The relevant parameter configuration is set up to realize the complete distributed platform of Hadoop in the virtual machine. Finally, the benchmark program package, included with the Hadoop software, do 4 Hadoop benchmark tests were carried out on the platform. In the same time, each test will load a number of different data and load for many experiments. By comparing the results of the benchmark test from different load Hadoop, performance of Hadoop platform was tested, and the impact of load and data on the Hadoop platform also is analyzed.
cloud computing; Hadoop; Benchmark test; Virtual machine
2015-12-03。
辽宁省科技厅自然科学基金资助项目(201202197)。
王 研(1981-),男,辽宁沈阳人,沈阳师范大学硕士研究生,中国医科大学讲师; 通信作者: 张 岩(1968-),女,辽宁沈阳人,沈阳师范大学教授,硕士。
1673-5862(2016)02-0240-06
TP311
A
10.3969/ j.issn.1673-5862.2016.02.023
