基于Hadoop的SQL查询引擎性能研究
2016-11-29吴黎兵叶璐瑶王晓栋
吴黎兵, 邱 鑫, 叶璐瑶, 王晓栋, 聂 雷
(1.武汉大学 计算机学院, 武汉 430072; 2.英特尔 英特尔亚太研发中心, 上海 201100)
基于Hadoop的SQL查询引擎性能研究
吴黎兵1*, 邱 鑫1,2, 叶璐瑶1, 王晓栋2, 聂 雷1
(1.武汉大学 计算机学院, 武汉 430072; 2.英特尔 英特尔亚太研发中心, 上海 201100)
Apache Hadoop处理超大规模数据集有非常出色的表现,相比较于传统的数据仓库和关系型数据库有不少优势.为了让原有业务能够充分利用Hadoop的优势,SQL-on-Hadoop系统越来越受到工业界和学术界的关注.基于Hadoop的SQL查询引擎种类繁多,各有优势,其运算引擎主要包括三种:①传统的Map/Reduce引擎;②新兴的Spark引擎;③基于shared-nothing架构的MPP引擎.本文选取了其中最有代表性的三种SQL查询引擎—Hive、Spark SQL、Impala,并使用了一种类TPC-H的测试基准对它们的决策支持能力进行测试及评估.从实验结果来看,Impala和Spark SQL相对于传统的Hive都有较大的提高,其中Impala的部分查询比Hive快了10倍以上,并且Impala在完成查询所占用的集群资源也是最少的.然而若从稳定性、易用性、兼容性和性能等多个方面进行对比,并不存在各方面均最优的查询引擎,因此在构建基于Hadoop的数据仓库系统时,推荐采用Hive+Impala或者Hive+Spark SQL的混合架构.
大数据; SQL-on-Hadoop; 数据仓库; Spark SQL; Impala; Hive
随着数据量的急剧增长,传统的数据仓库应用已经难以满足联机分析处理 (On-line Analytical Processing, OLAP)对数据仓库提出的新需求,特别是大数据4V特性中,大规模(Volume)、高复杂度(Variety)两座大山让扩展性不足的传统数据仓库不堪重负,寻求新型的高可扩展性数据仓库成为了当务之急.
搭建在廉价商用机器之上的Hadoop[1],在处理超大数据集的优秀表现无疑是解决大数据问题的一大良方.其低成本、高性能、高可靠和高可扩展的特性已经逐渐得到业界的认可,国内外已有大量的应用案例.
Facebook公司[2-3]在面临大数据的压力后,对多套系统进行了深入的评估,最终选择了Hadoop作为其商业数据库的替代产品;中国农业银行也已经将其历史交易数据的存储和查询系统迁移到了x86服务器搭建的Hadoop集群之上,并从2013年开始对外提供长达10年的历史交易数据查询.
Hadoop平台经过数年的发展,现已能完美满足中国人民大学王珊教授在2011年对新型数据仓库系统提出的8个重要特性[4].Hadoop的分布式文件系统(Hadoop Distributed File System, HDFS)虽然搭建在廉价的x86服务器上,但是其稳定性和可靠性已经达到了生产系统的要求,并且拥有极高的可扩展性,可以提供PB甚至ZB级别的存储空间,不会出现传统数据仓库存储空间耗尽后陷入扩容难的窘境.同时Hadoop平台上的数据处理工具也十分丰富,不仅支持对结构化数据的处理,更可以处理半结构化甚至是非结构化的数据;支持的计算类型也不再是单一的Map/Reduce[5]所代表的批处理,也有了新兴的流式处理框架——Storm、Spark Streaming.几乎所有的数据处理工作都可以在Hadoop平台上完成,而传统的架构经常需要将数据在多个不同功能的平台之间导入导出,造成了数据的冗余和大量时间、带宽的浪费.
数据仓库最重要的功能是进行OLAP并为用户提供决策支持,因此SQL查询的性能十分重要.本文关注于Hadoop平台上的SQL执行引擎,也就是SQL-on-Hadoop系统.IBM的研究人员将SQL-on-Hadoop系统分为两大类,Database-Hadoop hybrids和Native Hadoop-based systems[6].第一类仅利用了Hadoop的容错性和调度方法,使用关系型数据库执行查询,其中的代表有Microsoft PolyBase、Pivotal HAWQ[7]、Hadapt以及IBM Big SQL;第二类系统与Hadoop集成度较高,充分利用了Hadoop高可扩展性的优势,其中有3个大类:①基于Map/Reduce的Hive;②内存计算框架Apache Spark的子项目Spark SQL;③基于shared-nothing架构的大规模并行处理(Massively Parallel Processing, MPP)引擎,如Cloudera Impala、Apache Drill、LinkedIn Tajo和Facebook Presto.
本文选取了最具代表性的、架构各不相同的3种查询引擎Spark SQL、Impala、Hive进行对比分析.
1 SQL-on-Hadoop系统
Hive是Hadoop生态系统中第一个SQL查询引擎,也是目前应用最广泛的一个.它在处理超大规模数据集时十分的稳定,但是在处理较小的数据集时受Map/Reduce高启动延时的影响较为明显.而新兴的查询引擎如Impala、Spark SQL主要是为了解决Hive进行ad-hoc查询和交互式查询时延时较高的问题.
如表1所示,Hive、Impala、Spark SQL的架构、运行环境和使用编程语言完全不同,Hive依赖于Map/Reduce,Spark SQL依赖于Spark,Map/Reduce和Spark都运行在Java虚拟机(Java Virtual Machine,JVM)上.而Impala则采用了无共享结构的(shared-nothing)架构,并使用了C/C++编写,运行环境不同于Map/Reduce和Spark.3种查询引擎均支持Hive查询语句(Hive Query Language,HiveQL)和绝大部分的SQL92语法,同时Spark还拥有一种对弹性分布式数据集(Resilient Distributed Datasets,RDDs)进行查询的本地语言(Domain Specific Language,DSL),可以很方便地嵌入到Spark应用程序中使用.3种查询引擎均支持从HDFS上读取多种格式的数据,Hive和Impala可以从基于Hadoop的NoSQL数据库HBase中读取数据,而Spark SQL支持读取JSON格式的数据,这为分析网络应用的数据提供了较大的便利.

表1 Hive、Spark SQL、Impala对比
1.1 Hive
Facebook公司将大量的数据转移到HDFS上面以后,发现Map/Reduce在性能上已经满足了需求,但是Hadoop的Map/Reduce编程模型较为底层,对于用户来说并不友好,特别是对数据分析师们来说,他们熟知SQL却对Java和Map/Reduce框架并不熟悉.虽然直接使用Map/Reduce开发应用的程序执行效率高,但是研发周期长、成本高并且代码难以复用和维护.因此,简单易用、高效率的SQL查询系统更有用武之地,Hive就在这种环境下应运而生的.
Hive是构建在Hadoop之上的、开源的、通用的、可伸缩的SQL引擎,它使用一种类SQL语句—HiveQL对数据进行处理.如图1中Hive的架构部分所示,Hive主要由元数据仓库(MetaStore)和驱动(Driver)两大组件构成.Hive的元数据仓库中存储Hive表的元数据信息,现在已经成为众多SQL-on-Hadoop系统的共享元数据仓库.驱动中又包括了编译器(Compiler)、优化器(Optimizer)、执行器(Executor)3个模块.用户可以通过Hive Shell、JDBC/ODBC连接和Hadoop web界面程序Hue提交HiveQL语句,驱动在接收HiveQL语句后,先由编译器根据存储在Hive元数据仓库中的元数据信息对该语句进行类型检查和语义分析,其后生成对应的逻辑计划(Logic Plan),逻辑计划会被传递给优化器进行优化后生成一个由Map/Reduce作业和HDFS作业所组成的无回路有向图(Directed Acycli Graph,DAG)执行计划—优化的逻辑计划(Optimized Logic Plan),执行器最后按照最优计划中描述的依赖关系将Map/Reduce作业依次提交给Hadoop集群,所有任务完成后再将执行结果返回给用户.
Hive是Hadoop生态系统中第一个SQL执行引擎,也是目前最为稳定的SQL引擎,但是由于Hive所依赖的Map/Reduce存在如下两点不足影响了Hive的性能:
1) 重量级的执行单元.每个Map和Reduce作业都需要启动一个JVM来执行,虽然可以对JVM进行重用,但是花费在作业启动上的时间依然不少;
2) I/O读写.较为复杂的SQL语句会被解释成多个Map/Reduce作业运行,每个Map/Reduce作业执行结束后的中间结果需要暂存在HDFS上,这导致会在I/O上额外花费大量的时间.
1.2 Spark SQL
为解决Map/Reduce框架的不足,加州大学伯克利分校的AmpLab提出了内存计算框架Spark[8],Spark使用了较为轻量的线程作为执行器,从而大大减少了作业启动的开销,降低了通信成本,提高了调度的响应速度;并且Spark支持通用计算有向图(general computation DAGs),不再是只由Map和Reduce操作所组成的两级拓扑结构,从而减少了大量不必要的Map任务.Spark提供了一种高效的、可靠的、分布式的共享内存抽象—RDDs,RDDs使得Spark上的应用程序可以以特定的抽象格式将数据缓存到Spark集群的内存中,可以对RDDs使用map、filter、flatMap、reduceByKey等操作构建出新的RDDs[9].如Spark SQL中所使用Schema RDDs是一个由Row对象组成的、拥有结构信息的特殊RDDs,除了可以对它使用普通RDDs同样的操作以外,还可以使用HiveQL、DSL对Schema RDDs进行查询.

图1 Hadoop、Hive、Impala与Spark架构图Fig.1 Architecture of Hadoop, Hive, Impala and Spark
Spark SQL中驱动(Driver)的架构与其前身Shark[10]类似,但是与Shark依赖Hive来生成查询计划不同,Spark SQL仅依赖Hive的HiveQL解释器(HiveQL Parser)来生成HiveQL的抽象语法树(Abstract Syntax Tree, AST),并拥有自己的查询优化器Catalyst,不再依赖于Hive进行查询优化.如图2所示,Catalyst接受来自HiveQL解释器生成的AST后,将会依次进行逻辑计划、优化的逻辑计划、物理计划(Physical Plans)的生成,最终有一个或多个物理计划产生.Catalyst会根据它的运算代价模型(Cost Model)对所有物理计划进行评估,然后根据最优的物理计划生成其关联执行操作(Relation Execution Operators).与Hive类似,驱动会通过Spark Context将Spark操作依次提交给Spark集群,在所有任务执行完成后将最终结果提交给用户.
1.3 Impala
Impala[11]使用了与Spark完全不同的方法解决Hive查询高延时的问题,它是由Cloudera公司主导开发的类MPP的SQL引擎.虽然架构在Hadoop之上,却并不依赖Map/Reduce处理数据,而是使用本地的MPP执行引擎.Impala的设计思想起源于Google在2011年发表的Dremel[12],将MPP数据仓库的shared-nothing思想与Hadoop的高可扩展性、高可靠性融合在了一起.
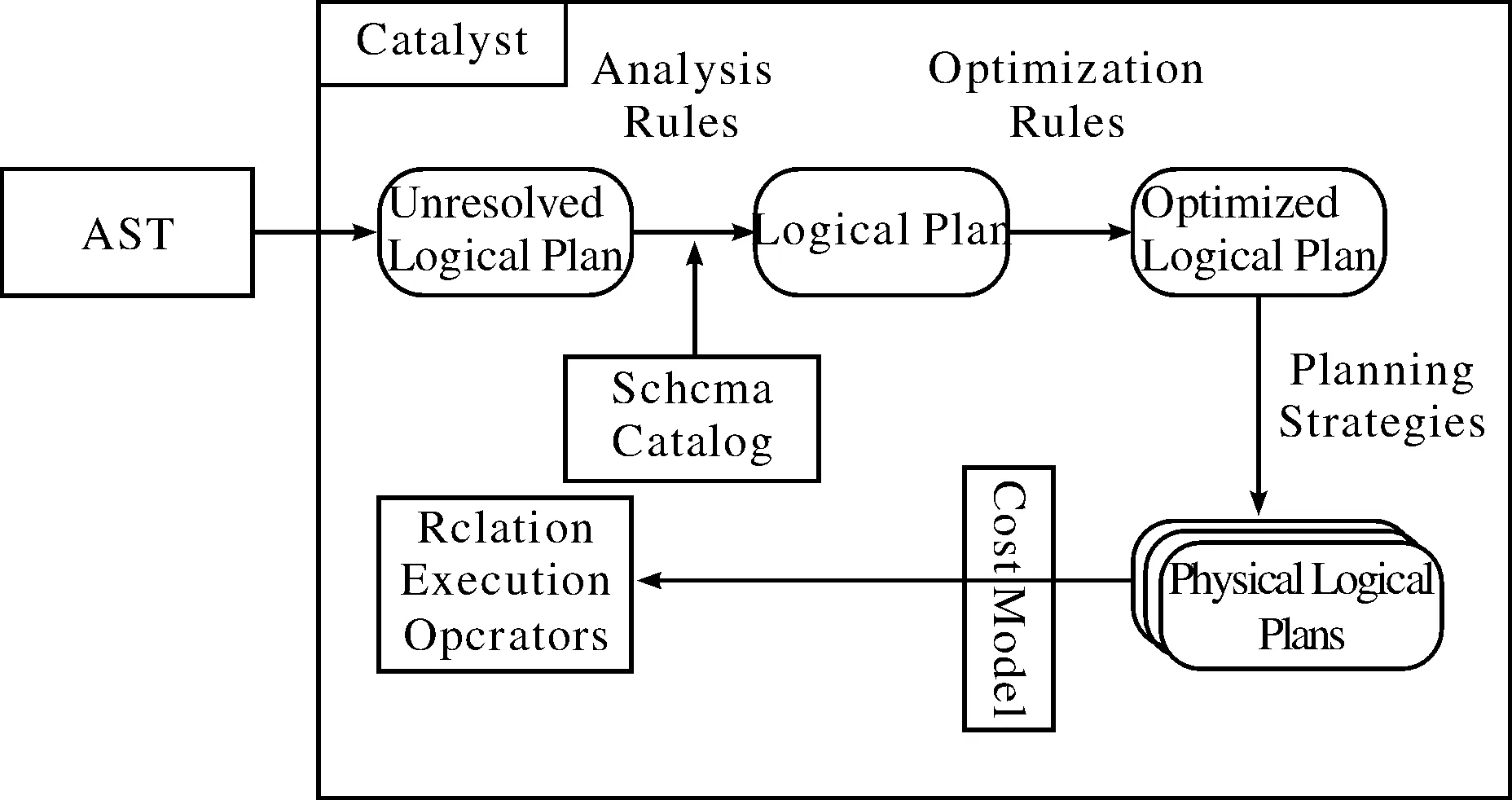
图2 Catalyst执行流程Fig.2 Catalyst Executing Process
如图1中Impala的架构部分所示,与Hive、Spark SQL架构有很大的不同,Impala使用的是经典的shared-nothing架构,在每个工组节点上均运行着一个名为impalad的守护进程,每个impalad都由计划器(Planner)、协调器(Coordinator)和执行引擎(Exection Engine)3个模块组成,用户可以连接到任意一个impalad后提交自己的SQL语句,接收到SQL语句的impalad就会成为这次查询的协调节点(Coordinate Node).协调节点的计划器将根据Catalog Server中缓存的元数据信息和NameNode中数据块的信息来生成执行计划,然后协调器将任务分发给其他impalad,其他impalad任务执行完成后将结果返回,协调节点对收到的所有数据进行汇总后,再将最终结果返回给用户.
2 实验与分析
本文实验采用了一套类TPC-H的测试基准,对Hive、Spark SQL、Impala的决策支持能力进行测试.TPC-H测试基准由英特尔和数家知名厂商共同制定,是一套评估数据仓库决策支持能力的基准程序(Benchmark),它由一系列模拟真实业务的ad-hoc查询和并发数据修改语句组成,SQL语句和数据集的具体描述参见说明文档(http://www.tpc.org/tpc-documents-current-versions/pdf/tpch2.17.1.pdf).测试所用SQL语句是改写后的HiveQL语句,由于TPC-H所用的SQL92语法在HiveQL中并不完全兼容,因此TPC-H的22个SQL语句中Q11和Q22无法执行.
2.1 测试环境
测试集群为8台物理服务器,操作系统为RadHat6.4,每台机器配备双路二十核Intel Xeon CPU E5-2660 v2 @ 2.20GHz CPU,内存64GB,4块7200转2TB SATA硬盘:其中一块系统盘,3块为数据盘.由于磁盘阵列(Redundant Arrays of Independent Disks, RAID)会对Hadoop的性能有影响,故数据盘未做RAID,网络环境为千兆网.其中一台机器作为主节点,剩余7台为工作节点,集群拓扑如图3所示.所使用的软件版本:Hadoop 2.5.0-cdh5,Hive 0.13.1-cdh5,Apache Spark 1.1.0,Impala 2.0.0-cdh5.
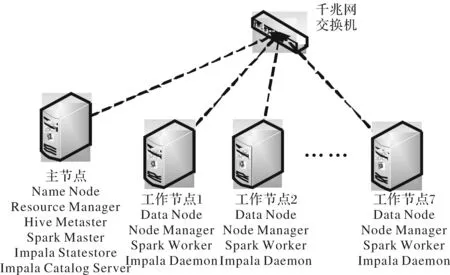
图3 集群拓扑图Fig.3 Cluster topology
2.2 数据及数据格式
Hive、Impala、Spark SQL共用同一份存储在HDFS上的数据集,由TPC-H提供的DBGen程序生成,并存储在HDFS上.如表2所示,共有8个表,原始文本文件共215.1GB,使用了3种不同的文件格式进行测试.
Parquet是Hadoop上的一种通用的、高效的列式存储格式,相对于纯文本文件有一定的压缩率,能够节省HDFS的存储空间.Parquet文件可以使用Snappy或gzip压缩算法进行进一步的压缩.使用压缩文件可以节省磁盘空间,并减小磁盘I/O压力,但是需要消耗一部分计算资源进行解压缩,所以可能会对性能有一定影响.综合考虑,本文对Parquet文件的压缩方法选用了压缩比和解压速度较为均衡的Snappy.
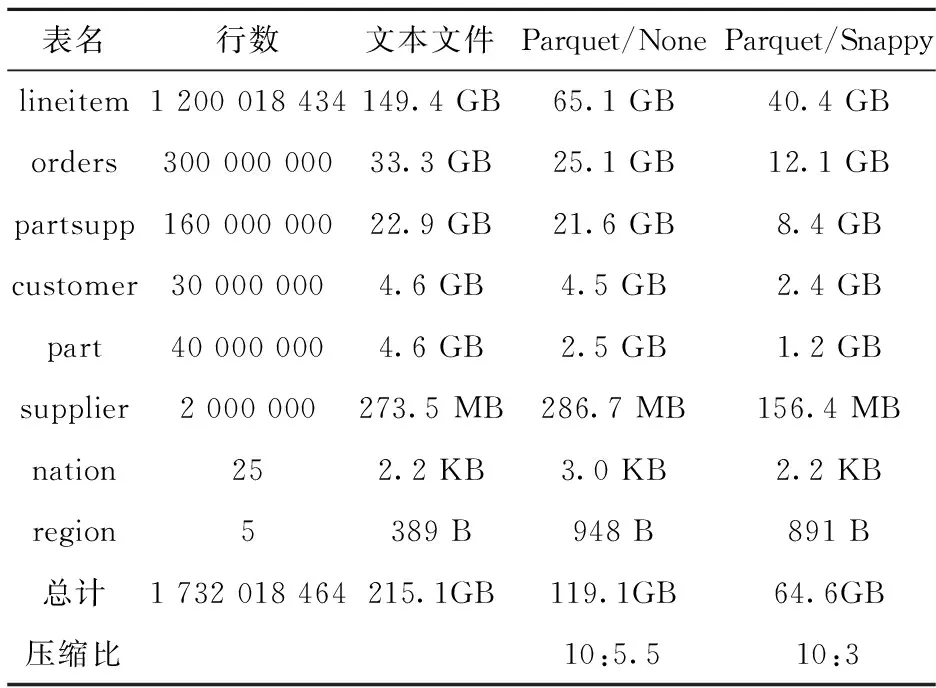
表2 实验数据集
2.3 统计信息
统计信息分为表的统计信息和列的统计信息,表的统计信息包括表的行数、表的文件数以及表的所有数据文件的总字节数,列的统计信息包括该列的最大值、最小值、数值类型的绝对值之和、空行数等信息.查询引擎的优化器可以根据统计信息使用基于损耗的优化方法,计算不同执行计划所需的损耗,从而选出最优的执行计划.如果在用户提交的查询恰好是统计信息中已有的信息时,可以不执行查询,直接将结果返回给用户.
Hive使用了“ANALYZE TABLE [table-name] COMPUTE STATISTICS FOR COLUMNS”计算每个表和所有列的统计信息,Spark SQL使用Hive收集到的统计信息,Impala使用了“compute stats [table-name]”计算每个表的统计信息.
2.4 实验结果

表3 查询运行时间
实验采用20个SQL依次运行的方式,执行结果如表3所示.从总运行时间来看,Impala与Spark SQL的查询速度与Hive相比都有较大的提高,Impala比Hive快了1.5倍,Spark SQL比Hive快了0.5倍.Impala有部分查询的速度比Hive快了10倍甚至更多,如Q6、Q12和Q15.Spark SQL表现并没有Impala出色,它是Spark在2014年9月发布的1.0.0版本中才推出的,在实验中所用的Spark 1.1.0中还属于测试组件,因此并不太稳定.同时因为其对Parquet格式的查询存在一些问题,并没能得到正确的结果.Impala处理Parquet格式时的效率显著提高,特别是针对Parquet的单表统计查询,如Q1的查询速度提高了5倍之多,Q6的查询速度也有6.5倍的提高.以Q1为例,Q1的查询语句如下:
Q1: SELECT L-RETURNFLAG, L-LINESTATUS,
SUM(L-QUANTITY), SUM(L-EXTENDEDPRICE),
SUM(L-EXTENDEDPRICE*(1-L-DISCOUNT)),
SUM(L-EXTENDEDPRICE*(1-L-DISCOUNT)*(1+L-TAX)), AVG(L-QUANTITY),
AVG(L-EXTENDEDPRICE), AVG(L-DISCOUNT),
COUNT(1)
FROM lineitem
WHERE L-SHIPDATE<='1998-09-02'
GROUP BY L-RETURNFLAG, L-LINESTATUS
ORDER BY L-RETURNFLAG, L-LINESTATUS;
Q1对lineitem表中L-SHIPDATE字段小于等于“1998-09-02”的数据进行了聚集操作,并根据L-RETURNFLAG和L-LINESTATUS两个字段进行排序.通过查看查询运行时的详细信息,对文本文件的查询需要遍历整个lineitem表的149.4GB数据,对Parquet文件的查询得益于Parquet列式存储的优势,只需要读取查询中需要处理的列,因此大大降低了I/O成本.Impala仅读取了Parquet/None格式20.12%的数据,即13.1GB,Parquet/Snappy仅需要读取10.6GB,但是Snappy解压需要消耗时间,Parquet/None与Parquet/Snappy最终的查询时间相差不大.
Impala拥有一个非常强大的自动缓存功能,对同一张表进行多次查询时表现得更加明显.Q1和Q6都是针对lineitem表的统计分析型语句,在运行完Q1语句后,Impala会将lineitem表的数据都缓存到内存中,再执行Q6语句.其执行时间大大减少,对文本文件的查询从110.93 s降低到了12 s,对Parquet的查询从14 s降低到3 s左右.
得益于Spark提供的强大接口和Shark在SQL处理上的积累,还处于测试版本的Spark SQL顺利地完成了所有语句的执行,并且执行速度比Hive要快.但是Spark SQL使用过程中遇到了一些问题,例如默认使用的Broadcast Hash Join在执行部分Query时会返回大量的中间结果给Spark驱动,导致驱动(运行在Master节点上,分配内存20GB)由于内存不足而运行失败,最后改用了Shuffle Hash Join的方式才解决问题.
2.5 Q21资源消耗情况
如图4所示,Q21中的作业由3个子查询组成,子查询S1和S2是两个对lineitem表中数据进行的聚集操作,S3是依次与lineitem、supplier、nation、orders、AGG1和AGG2进行关联操作后进行的一次聚集操作后得到AGG3,再对AGG3进行一次排序.在实验过程中,收集了3种引擎在运行Q21时集群CPU、内存、网络、磁盘的使用情况,如图5所示.可以发现Impala在完成查询的同时对集群资源的占用是最少的,Hive其次,Spark SQL占用资源最多,特别是在内存占用方面和磁盘读取上更为明显.

图4 Query 21Fig.4 Query 21

图5 Q21集群资源消耗图Fig.5 Cluster resource usage of Q21
Impala与Hive和Spark SQL的最大不同是它使用C/C++编写,可以更加方便地在底层进行大量的优化;而Hive和Spark SQL均运行在JVM之上,相对来说对CPU和内存的控制并没有Impala做得精细.如图5a所示,Impala占用的CPU时间要明显少于Hive和Spark SQL,这得益于Impala专门针对CPU层进行了大量的优化,Impala的查询在每个节点上仅占用一个CPU线程,在相当低的CPU使用率下查询结果与另外两个引擎不相上下.而Hive和Spark SQL的运行环境为JVM,他们在CPU层的优化完全依赖于JVM,因此优化没有Impala细致.图5b中,Impala与Hive所占用的内存相差不大,而Spark SQL由于Spark的关系长时间占用了大量的内存空间,Spark并不像Map/Reduce那样使用进程作为执行单元,而在占用资源较多的Executor Backend进程中使用线程来执行任务,因此实验中为Executor Backend分配的50GB内存会在任务结束前被一直占用.
在磁盘使用方面,Impala和Hive比Spark SQL表现要好一些.S1和S2都是对lineitem表进行聚集操作,从图5c对磁盘读取速率来看,Spark SQL在执行S1和S2时分别从磁盘中读取了一次lineitem表.Hive和Impala在执行S1的时候均从磁盘读取了大量的数据,但是在S2执行的过程中,Impala对磁盘的使用率最低,而Hive对磁盘的读操作要远少于Spark SQL.出现这样的情况是因为HDFS Datanode会使用操作系统缓存对已读文件块进行缓存,但是由于Spark在执行的过程中占用了大量的系统内存,留给Datanode可用的缓存空间并不多,因此Spark从Datanode的系统缓存中读取的数据相对较少.
从图5d对磁盘的写入速率中可以发现,Impala在S1和S2执行结束后将结果写入HDFS时,集群磁盘才有一个比较大的写入,也就是说Impala在聚合操作的过程中仅有少量的数据重分布(shuffle),所有的中间结果都暂存在内存中,而Hive和Spark SQL在执行S1和S2的过程中有一些中间数据shuffle到磁盘中.
从图5e所展示的网络流量上看,Impala在执行S3的时候网络I/O非常高.因为Impala采用了Broadcast Join的方式进行表连接操作,会将较小的表缓存到每个impalad的内存中,impalad在各自的聚集操作结束后将计算出的结果AGG3通过网络传输给协调节点进行最后的排序,因此Impala在执行的过程中会出现一个较大的网络流量.
2.6 结论
从实验过程和结果中来看,3个查询引擎都有各自的优点,现阶段并不存在一个各方面都最优的查询引擎.Impala是其中最快的一个,它的查询速度比Hive要快1.5倍,运行较为稳定,但是Impala在查询总大小超过内存大小的数据时还存在一些问题:在尝试执行1TB数据规模的TPC-H测试语句时,Impala会因为内存不足导致查询终止,即使启用了中间结果缓存磁盘的功能,查询也会在持续运行数小时后异常退出.而Hive运行十分稳定,对超大规模数据的查询能得正确的结果,但是受到Map/Reduce启动过慢等问题的影响,在本文实验中性能是最弱的.Spark SQL目前还处于测试版本,虽然在实验中性能比Hive要好,但是目前还不成熟,如果能在后续的版本中解决好稳定性以及资源占用过多的问题,将会成为一个非常优秀的查询引擎.
结合本次实验以及英特尔在Hadoop上的使用经验来看,在构建基于Hadoop的数据仓库系统时,推荐SQL引擎部分采用稳定的Hive搭配高性能的Impala或Spark SQL的混合架构.3个查询引擎互相兼容,共享了同一个元数据库,同时使用并不需要在不同的引擎中多次建表.在实际使用中,得益于Hadoop集群强大的计算和存储能力,可以将原始数据的ETL(Extract Transform Load)工作中的转换操作T转移到Hadoop上交给Hive执行.在ETL完成后,对较大规模的原始数据的统计分析工作可以交给Hive完成,而在对经过统计分析后得到的小规模数据集进行查询时可以使用速度更快的Impala或者Spark SQL,在对数据集缓存以后,绝大部分的查询在秒级即可完成.
3 结束语
Hadoop是新一代数据仓库的有力竞争者,基于Hadoop的多种SQL查询引擎各有优势,但从稳定性、易用性、兼容性和性能多个方面对比分析,目前并不存在各方面均最优的SQL引擎,因此推荐使用Hive+Impala或者Hive+Spark SQL的混合架构,规模较大的查询和分析工作由Hive完成,小规模的数据集则可以使用速度更快的Impala或者Spark SQL.这种混合架构既得到了Hive的高稳定性和易用性的优点,还可以享受Impala和Spark SQL的高性能带来的快速查询.
[1] SHVACHKO K, KUANG H, RADIA S, et al. The hadoop distributed file system[C]//2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST). IEEE, 2010:1-10.
[2] THUSOO A, SARMA J S, JAIN N, et al. Hive: a warehousing solution over a map-reduce framework[J]. Proceedings of the VLDB Endowment, 2009, 2(2):1626-1629.
[3] THUSOO A, SARMA J S, JAIN N, et al. Hive-a petabyte scale data warehouse using hadoop[J]//2010 IEEE 26th International Conference on Data Engineering (ICDE). IEEE, 2010, 41(3):996-1005.
[4] 王 珊, 王会举, 覃雄派, 等. 架构大数据: 挑战, 现状与展望[J]. 计算机学报, 2011, 34(10):1741-1752.
[5] DEAN J, GHEMAWAT S. MapReduce: simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1):107-113.
[6] FLORATOU A, MINHAS U F, OZCAN F. SQL-on-Hadoop: Full circle back to shared-nothing database architectures[J]. Proceedings of the VLDB Endowment, 2014, 7(12):1-12.
[7] CHANG L, WANG Z, MA T, et al. HAWQ: a massively parallel processing SQL engine in hadoop[C]//Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data. ACM, 2014:1223-1234
[8] ZAHARIA M, CHOWDHURY M, FRANKLIN M J, et al. Spark: cluster computing with working sets[J]. Book of Extremes, 2010, 15(1):1765-1773.
[9] ZAHARIA M, CHOWDHURY M, DAS T, et al. Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing[C]//Procegs of the 9th USENIX conference on Networked Systems Design and Implementation. USENIX Association, 2012:141-146.
[10] XIN R S, ROSEN J, ZAHARIA M, et al. Shark: SQL and rich analytics at scale[C]//Proceedings of the 2013 International Conference on Management of Data. ACM, 2013:13-24.
[11] BITTORF M K A B V, BOBROVYTSKY T, ERICKSON C C A C J, et al. Impala: A modern, open-source SQL engine for Hadoop[J]. The biennial Conference on Innovative Data Systems Research (CIDR), 2015:1-10.
[12] MELNIK S, GUBAREV A, LONG J J, et al. Dremel: interactive analysis of web-scale datasets[J]. Communications of the ACM, 2011, 54(6):114-123.
Research on SQL-on-Hadoop systems
WU Libing1, QIU Xin1,2, YE Luyao1, WANG Xiaodong2, NIE Lei1
(1.Computer School, Wuhan University, Wuhan 430072; 2.Intel Asia-Pacific R&D Center, Intel Corporation, Shanghai 201100)
Hadoop has huge advantage over traditional data warehouse and RDBMs on storing and processing large amount of data. In order to be compatible with existing business logic, SQL-on-Hadoop systems are getting more and more attentions from both industry and academia. There are variable kinds of SQL-on-Hadoop systems with different architectures and different execution engines. Those systems are generally divided into three categories: traditional engines based on Map/Reduce, newborn engines based on Spark, and MPP engines based on shared-nothing architecture. In this paper, three SQL-on-Hadoop systems, Hive, Spark SQL and Impala, are chosen to represent each category, respectively. A TPC-H like workload is used to benchmark the efficiency and resource usage for each system. Through detailed analysis of the experimental result, both Impala and Spark SQL are faster than Hive. In some particular queries, Impala is 10X faster than Hive with minimum CPU / RAM usage among the three SQL systems. However, when compared in terms of stability, usability, compatibility and performance, no one can beat others at all aspects. So while building the data warehouse system based on Hadoop, it is recommended to use a hybrid architecture using Hive+Impala or Hive+Spark SQL.
big data; SQL-on-Hadoop; data warehouse; Spark SQL; Impala; Hive
2015-09-06.
国家自然科学基金项目(61272112,61472287);湖北省自然科学基金重点项目(2015CFA068).
1000-1190(2016)02-0174-09
TP311
A
*E-mail: wu@whu.edu.cn.
