Hadoop云计算平台的参数优化算法
2016-11-29王春梅胡玉平易叶青
王春梅, 胡玉平, 易叶青
(1.广东金融学院 互联网金融与信息工程系, 广州 510521; 2.广东财经大学 信息学院, 广州 510320; 3.湖南人文科技学院 信息科学与工程系, 湖南 娄底 417000)
Hadoop云计算平台的参数优化算法
王春梅1*, 胡玉平2, 易叶青3
(1.广东金融学院 互联网金融与信息工程系, 广州 510521; 2.广东财经大学 信息学院, 广州 510320; 3.湖南人文科技学院 信息科学与工程系, 湖南 娄底 417000)
为提高Hadoop云计算平台的性能,该文提出了一种跨层的参数优化模型.首先分析了云计算平台的工作流程,将系统参数与流程对应,并加入基础设施即服务与平台即服务层的参数,找出对Hadoop集群效率作用显著的参数,并把这些参数值作为性能参数,构建成性能参数模型,再用启发式蚁群算法搜寻性能较优的可行参数,并不断修正,找出最佳参数组合,最后整合跨层的参数来提高Hadoop云计算平台的性能.实验表明,该算法可行,性能优良.
Hadoop云计算; 参数最优化; 蚁群优化算法; 虚拟机
Hadoop是Apache基金组织下的一个开源的可运行于大规模集群上的分布式并行编程框架,搭建Hadoop云计算平台进行海量数据存储是目前最为广泛应用的开源云计算软件平台[1-2].Hadoop云计算平台的系统参数配置,直接关系到系统资源的利用情况,性能参数值的合理设定对Hadoop云计算平台的工作性能具有重要的作用[3].但现在多数Hadoop集群系统对参数的设置都过于简单,通常在集群安装配置时,采用默认配置或手动修改部分配置的方式.由于Hadoop集群工作系统提供200多个可调的参数,这些参数直接影响集群的工作效率,但并不是所有的参数对Hadoop集群效率作用显著[3-5].调整对效率有显著作用的参数,可缩短作业执行时间,提高吞吐量,减少I/O或网络传输成本,因此合理配置这些参数是集群工作性能提升的重要保障.
Hadoop集群系统的参数影响是复杂且联动,改变某个参数的值可减少某部分的成本,但也可能增加其它部分的成本.因此很多学者一直不断研究.代栋等[6]利用模糊逻辑规则对集群参数进行自动配置,该方法主要考虑集群中节点的异构,并没有对集群任务做出明确的分析.Herodotou等[7]先建立一个参数空间,然后使用搜寻算法来找出最佳化参数配置来满足目标函数,由于挑选出整体最佳化参数配置是相当消耗时间,而且没有明确目标函数来寻找参数空间,导致搜寻效果不佳.Lin等[8]结合参数调整的经验和登山算法来配置,但效果不是非常理想.
本文提出一种跨基础设施即服务(Infrastructure as a Service,IaaS)层、平台即服务(Platform as a Service,PaaS)层和软件即服务(Software as a Service,SaaS)层的跨层式参数优化模型,并使用蚁群算法串接IaaS层、PaaS层、SaaS层的优化方法,来提高Hadoop云计算的系统性能.实验表明本算法可行,性能优越.
1 跨层式参数优化模型
跨层式参数优化模型的结构如图1.先通过收集到的性能参数建立性能模型,再利用模型所产生的值,通过蚁群优化(Ant Colony Optimization,ACO)算法[9]搜寻最佳参数组合,最后使用跨层蚁群算法(C-ACS)整合跨层的参数,来改善Hadoop云计算平台的性能.

图1 跨层参数优化模型流程图
Fig.1 Flow chart of cross-layer parameter optimization mode
1.1 跨层效率参数
本文主要是搜寻那些参数会直接或间接对工作效率有影响,因Hadoop集群工作系统有200多种可调的配置参数,经过一些学者研究,其中大约有20多个对Hadoop集群效率作用显著[1],以这些参数为依据建立性能模型,并加入跨层的性能参数,让启发式蚁群算法(ACS)在搜寻参数最佳组合时,可以有更好的参数选择来提升云计算平台的性能.Hadoop集群工作系统的运行架构如图2.
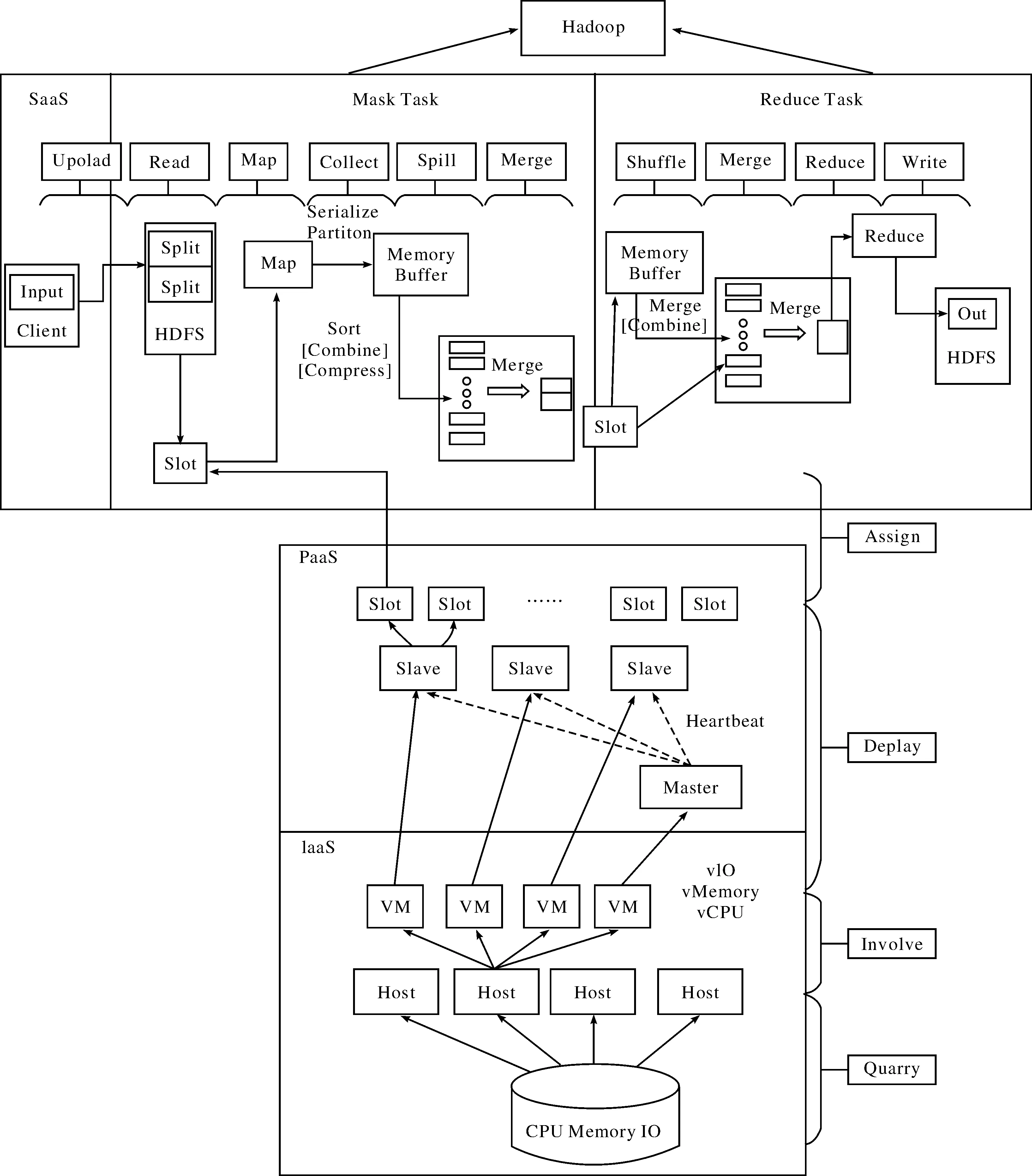
图2 Hadoop集群工作系统运行架构示意图Fig.2 Diagram of Hadoop cluster operating system
(I) SaaS层
Hadoop云计算平台的SaaS层运行MapReduce的应用程序,一开始从Client端将需要运算的输入数据上传到HDFS分布式文件系统,HDFS将上传的数据分割成Block.然后Block按照键值对存储在HDFS上,并将键值对的映射存到内存中.MapReduce框架主要包括Map和Reduce两个阶段,每个阶段都会有各自的任务(MapTask、ReduceTask),在Map阶段,每个MapTask读取一个block,并调用map()函数进行处理,将结果写到本地磁盘上;在Reduce阶段,每个ReduceTask从MapTask所在节点上读取数据,调用reduce()函数进行数据处理,并将最终结果写到HDFS.
SaaS层的性能参数主要是改善MapReduce执行Job时的参数,可分为三大类:Job整体性能参数、MapTask性能参数、ReduceTask性能参数.这三大类参数可能直接影响系统的效率,可以通过修改/etc/Hadoop/conf文档来调整系统性能.SaaS层Job整体性能参数如表1.
SaaS层中MapReduce的参数归纳为两部分,一个是Map端的性能参数,另一个是Reduce端的性能参数.由于这两部分没明确的定义,所以需通过搜寻参数的方式,来找出最佳参数的组合.

表1 SaaS层Job整体性能参数
(II) PaaS层
除考虑SaaS层的性能参数外,还得考虑到PaaS层的参数,Hadoop云计算平台的PaaS层有Master节点和Slave节点,Master节点是主要控制节点,用来指派工作任务给工作节点Slave,Slave节点通过不断的心跳汇报(HeartBeat)来和Master通信,可以让Master节点知道那些Slave节点可以使用,那些已经失效,这样可以避免将工作任务指派给失效的节点上,导致任务失败.PaaS层性能参数如表2.

表2 PaaS层性能参数
(III) Iaas层
Hadoop云计算平台的基础设在Iaas层上,将硬件资源分配给虚拟机(VM),每一台VM就会得到虚拟的硬件资源(vCPU、vIO、vMemory).IaaS层性能参数(Host参数)有:nHostr(Host的数量)、hCPU(Host的CPU能力)、hMemory(Host的内存大小)、hIO(Host的IO能力),IaaS层性能参数(VM参数)有nVM(VM的数量)、vCPU(VM的CPU能力)、vmemory(VM的内存大小)、vIO(VM的IO能力).
有了这些性能参数之后,就可以将这些参数建立性能参数模型,找出相对应的关系.
1.2 性能参数模型
通过找出的性能参数与Hadoop的流程作结合,得出性能模型如公式(1).
T=TSetup+TMap+TReduce+TCleanup,
(1)
其中,TSetup为程序启动基本作业时间,TMap为Map阶段作业执行时间,TReduce为Reduce阶段作业执行时间,TCleanup为结束程序的基本作业执行时间.
性能模型找出性能参数之间的关系,通过这样的关系,找出3层参数对CPU、Memory、IO之间的性能模型:
1) 运算能力CPU
每个VM的运算能力vCPUN不一定会一样,将这些vCPUN加总,就得到Host的运算能力hCPU,如公式(2).
(2)
其中,k为VM的个数.vCPU为VM的CPU能力.
而Slot的运算能力sCPUN是由VM的运算能力vCPUN除以Slot的数量nSlot,如公式(3).

(3)
2) 内存大小Memory
Host的内存大小计算如公式(4).
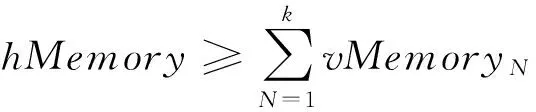
(4)
VM的内存大小vMemoryN如公式(5).
vMemoryN≥mapred.child.java.opts*
(nMapSlot+nReduceSlot)+io.sort.mb+
mDataNode+mTracker+mOS,
(5)
其中,mapred.child.java.opts为JVM的大小,nMapSlot和nReduceSlot分别是Map和Reduce所使用的Slot数量,io.sort.mb为缓冲区的大小,mDataNode为启动DataNode的基本内存开销,mTracker为启动TaskTracker的基本内存开销,mOS为操作系统的基本开销.
3) 磁盘IO
磁盘IO的计算如公式(6).
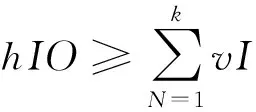
(6)
IO的模型主要是减轻IO的压力,计算如公式(7).
vION=MapOutput+Intermediate+
ReduceOutput.
(7)
通过定义出来的参数性能模型,让蚁群算法搜寻满足上述各层的性能需求的参数解.
1.3 参数优化模型的ACS

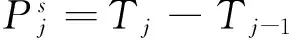
(8)
其中,Tj为调整参数后的执行时间成本,Tj-1为调整参数前的执行时间成本.
然后确定Hadoop参数配置,假设给定n个候选参数值i∈I,要选m个最佳参数值j∈J,可使用一个变量xij(变量xij表示最佳参数j是否选取候选参数值i),目标是使执行时间最小化,如公式(9).
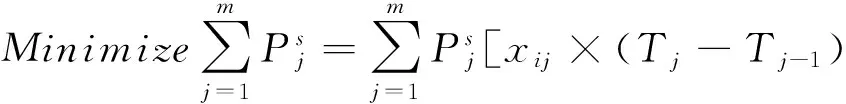
(9)
期望值ηi,j的计算如公式(10),如果F的值越大,期望值就越小,反之F值越小,就会对蚁群的吸引力越大,也就是说当执行时间越少,蚁群越容易找到这个参数组合.
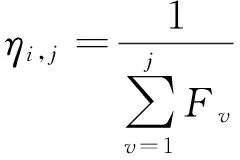
(10)
依照公式(11)和公式(12)可以判断蚁群是否要选取这个参数.
i=
(11)
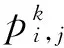
(12)
AS在进行整体信息素更新时,是以每只蚂蚁的表现进行更新的,ACS的更新方式如下:
整体信息素计算公式如公式(13).
τi,j(t)=(1-ρg)τi,j(t-1)+ρΔτi,j,
(13)
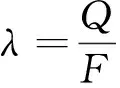
ACS在每一只蚂蚁寻找一个可行解(可能参数值)的过程中,每经过一个边(i,j),即对该边做一次信息素更新,以避免其它蚂蚁收敛在局部解,并增加路径寻找的多样性,其更新方式如公式(14).
τi,j(t)=(1-ρl)τi,j(t-1)+ρl·τ0.
(14)
1.4 参数优化模型的C-ACS
在跨层的参数优化模型中将PaaS与IaaS的影响也考虑进来,SaaS层采用ACS的方法,而Paas层的影响则采用跨层的方法C-ACS.跨层参数优化模型的架构图如图3.

图3 跨层参数优化模型的架构图Fig.3 Structure diagram of cross-layer parameter optimization model
跨层参数优化模型的运作流程:1)SaaS层优化:执行Hadoop的Job的调教,一开始执行能被调整的参数,取得每个参数对应的执行时间,将需要调整的参数的执行时间作为路径,执行时间越短的几率越高,越会被蚁群寻找到,从而搜寻到该时刻最佳的参数组合.2)Paas层优化:在运行中遇到VM繁忙时,本优化模型会依照那个VM具有空闲的能力,将他暂时加入;遇到Host都很忙碌时,可以将VM从别的Host取得.3)IaaS层优化:一开始本模型会去建立一个VM,并跑一个Job,得到执行时间,通过这个执行时间,评估出在一台Host上需建立多少个VM.4)通过一开始IaaS层优化,到PaaS层优化,以及最后的SaaS层优化,来构建本参数优化模型.
1.4.1 跨层优化的目标函数
1) SaaS层优化的目标函数
SaaS层优化的目标函数如公式(15).
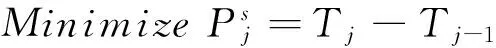
(15)
2) PaaS层优化的目标函数
执行过程中当遇到节点突然坏死的情况,如果节点心跳一直没有回传回来,就会被加到这一次的Job的黑名单,这时需动态启动一个节点来支援运算,对于实体机可能无法那么快的新增节点,但对于虚拟机可以快速启动节点,并加入到集群中.本模型利用跨层的ACS执行搜寻实体机上是否还有空闲的资源可以利用,能利用的资源越多,对跨层的ACS吸引力就越大,如果要启动节点的话,会在信息素最多的实体机上建立虚拟机,来加入到集群中.
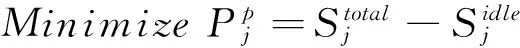
(16)
3) IaaS层优化的目标函数
现在的研究大部分注重在应用层的参数调整上,所以一开始建立集群环境时,就没特别最优化.本优化模型通过跨层ACS来进行搜寻最佳的虚拟机搭配实体机的方式.一开始通过建立虚拟机并执行Job得到执行效率,建立蚁群初始值,让蚁群寻找出最佳的实体机与虚拟机的搭配方式,最后产生出环境最佳组合,来组成虚拟机集群.
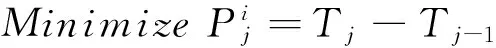
(17)
其中,Tj为调整虚拟机数量后的执行时间成本,Tj-1为调整虚拟机数量前的执行时间成本.
1.4.2 跨层目标函数F(x) 跨层的目标函数如公式(18).
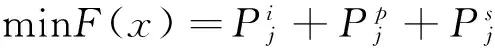
(18)
让ACS通过搜寻方式,可以找到最小的目标函数F(x),从而达到跨层优化目标,相对单一层的目标函数,跨层的目标函数给定更多的参数选择.
2 仿真实验结果与分析
建立一个虚拟Hadoop集群,服务器配置:CPU为Intel Xeon E5-2690W,内存32GB,硬盘2TB 7.2K RPM;软件配置是:OS为Linux CentOS6.5-64bit,Hadoop版本为Hadoop2.2.0,Java版本为Sun JDK 6u45.6个虚拟节点的参数如表3.
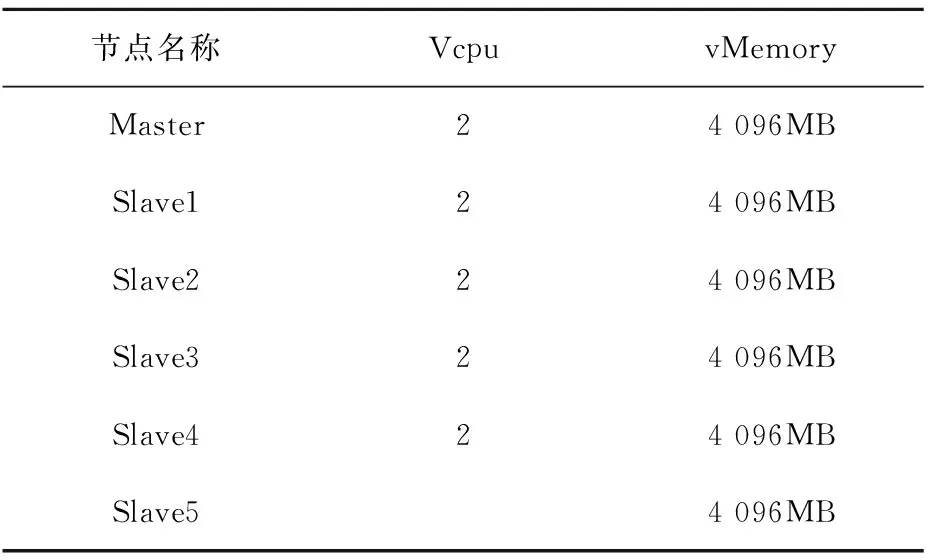
表3 6个虚拟节点的参数情况
选一台虚拟机同时作为Namenode和JobTracker,称为主节点,其余虚拟机同时充当DataNode和TaskTracker,称为从属节点.本文使用WordCount和Terasort来模拟实际的负载情况,WordCount主要测试CPU,Terasort主要测试IO.使用TeraGen这个测试工具,产生1G的文本文件,作为输入的数据集.
2.1 参数最佳化组合结果
在执行蚁群算法时,使用刘彦鹏[10]的方法先初始化,把初始值τ0设为0.006 944,信息素衰落参数(ρ)设为0.9,蚁群数量(S)设为3,α=1,β=2,执行时间T=3,Q=100.实验得到的最优化参数如表4.

表4 实验得到算法的最优化参数
执行效率比较如图4.从图中可看出,其模型比登山算法和系统默认的都要好,这是由于登山算法被限制在所设定的范围内进行搜索,所以当范围设置不当时,只能找到设定范围内较佳参数解.而本文的方法通过探索的方式,找到设定范围外的可用解.
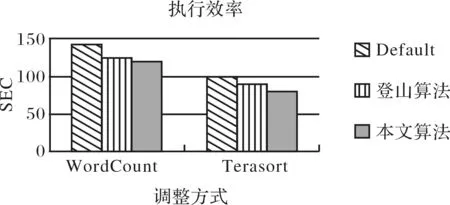
图4 执行时间比较Fig.4 Comparison of executive time
2.2 节点失效情况
节点突然失效时的实验结果如图5.从实验结果可看出,Default在节点失效时时间花费较多,这是由于节点失效时,Default的状态是用剩余的节点去完成运算,但它还会尝试失效的节点,这时将去做加入一个节点动作,当新的节点进入Hadoop集群时,会遇到要将数据传输到这个节点上做运算,所以会多花费一些传输的时间.
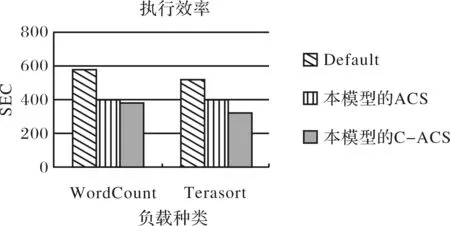
图5 节点失效情况下执行的效率对比Fig.5 Efficiency comparison of the execution in the case of node failure
2.3 与Starfish方法比较
本实验使用Herodotou[7]的方法进行比较,两种方法最佳化参数组合比较如表5.
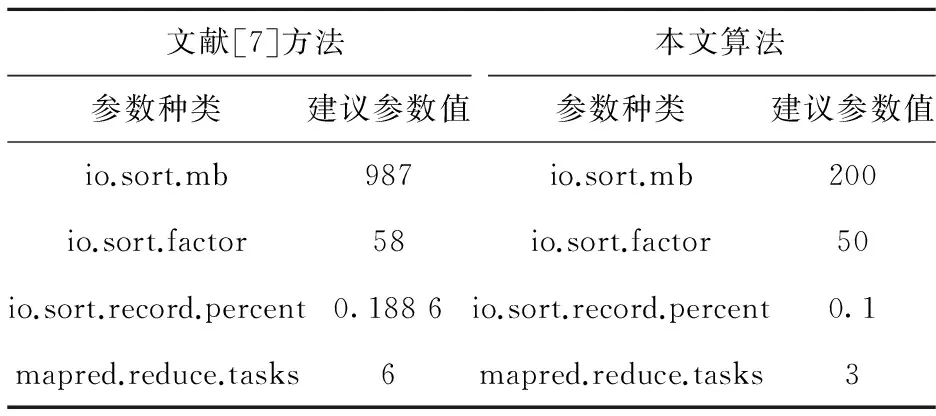
表5 最佳化参数组合比较
与Herodotou[7]的方法进行比较,Wordcount与Terasort执行的效率差异如图6.从图可以看出本文的算法效果明显.这主要是Herodotou的方法主要根据经验来配置部分参数.
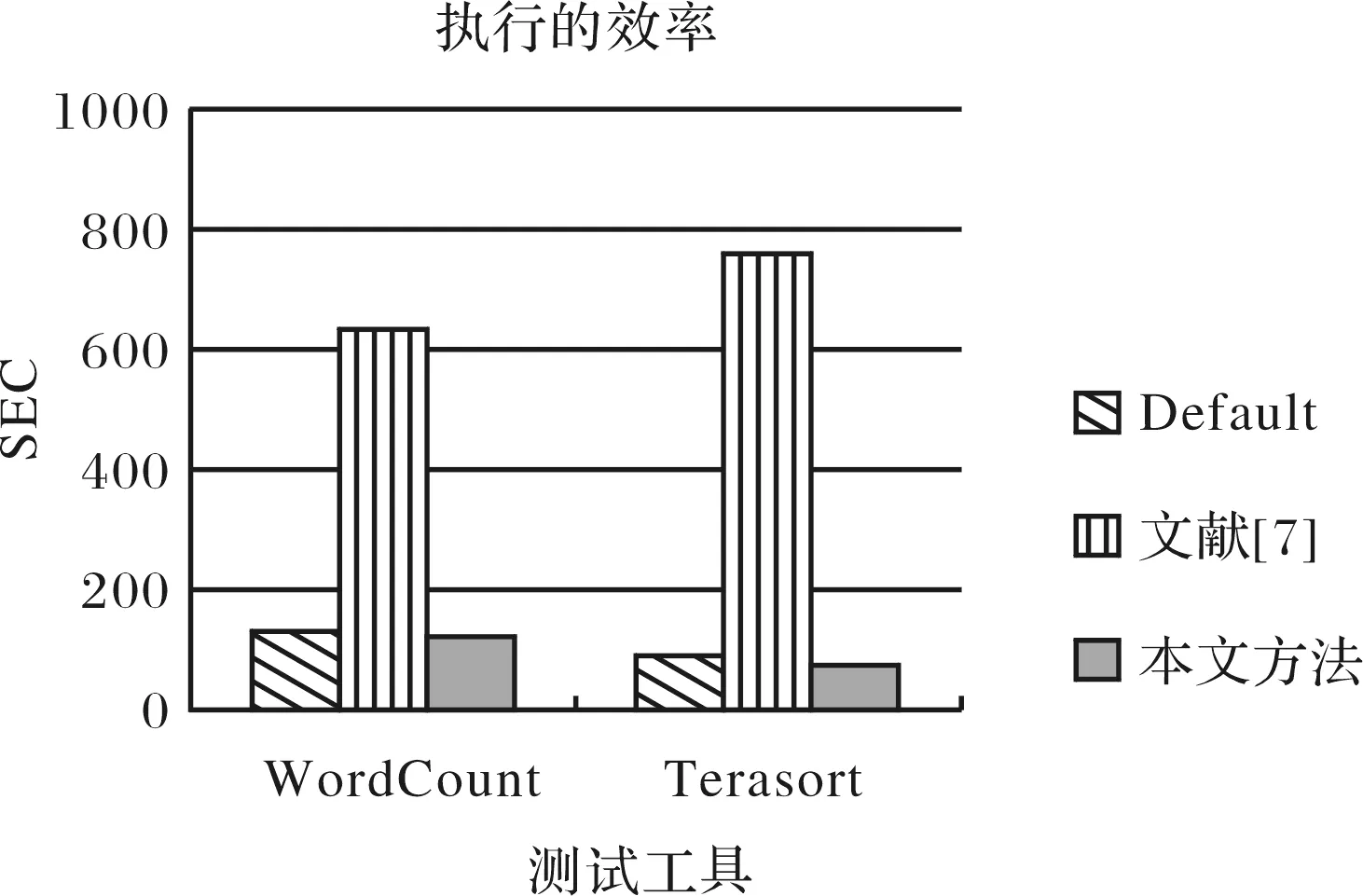
图6 执行的效率差异Fig.6 Difference of the execution efficiency
3 结束语
本文研究目标是希望提高Hadoop云计算平台的性能,首先将Hadoop集群系统中使用到的参数归纳出来,分析云计算的工作流程中的参数,将参数与流程一一对应,并加入IaaS层和PaaS层参数,来找出那些参数值可以作为性能参数,并把性能参数建立性能模型,用启发式蚁群算法搜寻出执行时间中最佳可行参数,并不断修正,找出最佳参数组合.仿真实验表明跨层改善的方式比单一Hadoop层的改善,更具有弹性,性能的改善更好.未来的研究希望可以通过自动化的过程让虚拟机通过跨层优化的方式,建立虚拟集群,让蚁群找到最佳参数组合,来改善Hadoop集群性能,同时还可以使用数据挖掘的算法来分析Job的特征,建立分类模型,当Job要最佳化时,可以有特征值来进行比对,这样能使整个系统性能更优越.
[1] 林 利, 石文昌. 构建云计算平台的开源软件综述[J].计算机科学, 2012, 39(11):1-7.
[2] DEAN J,GHEMAWAT S. Map reduce:a flexible data processingtool[J].Communications of the ACM, 2010, 53(1): 72-77.
[3] 项 明. Hadoop集群系统性能优化的研究[D].大连:辽宁师范大学,2013.
[4] LEE G,CHUNB G, KATZ R H. Embracing heterogeneity in scheduling mapReduce [EB/OL].[2012-03-26].http://www.cs.berkeley.edu/~agearh/cs267.sp10/files/cs267-gunho.pdf.
[5] MURTHY A C. Speeding up Hadoop[EB/OL]. [2012-03-26].http://developer.yahoo.com/blogs/ydn/posts/2009/09/hadoop-summit-speeding-up-hadoop/.
[6] 代 栋, 周学海, 杨 峰. 一种基于模糊推理的Hadoop异构机群自动配置工具[J].中国科学院研究生院学报, 2011, 28(6):793-798.
[7] HERODOTOU H, HAROLD L, GANG L, et al. Starfish: a self-tuning system for big data analytic[C]//Proc. 5th Biennial Conference on Innovative Data Systems Research. USA:CIDR, 2011: 261-272.
[8] LIN X, TANG W, WANG K. Predator—an experience guided configuration optimizer for HadoopMapReduce[C]//In Proceedings of the 2012IEEE 4th International Conference on Cloud Computing Technology and Science. Taiwan: IEEE Press, 2012:419-426.
[9] DORIGO M, GAMBARDELLA L M. Ant colony system: a cooperative learning approach to the traveling salesman problem[J]. IEEE Transactions on Evolutionary Computation, 1997, 1(1):53-66.
[10] 刘彦鹏. 蚁群优化算法的理论研究及其应用[D].杭州:浙江大学,2007.
Cross-layer parameter optimization algorithm for Hadoop cloud computing platform
WANG Chunmei1, HU Yuping2, YI Yeqing3
(1.Department of Internet Finance & Information Engineering, Guangdong University of Finance, Guangzhou 510521; 2.School of Information, Guangdong University of Finance & Economics Guangdong, Guangzhou 510320; 3.Department of Information Science and Engineer, Hunan University of Humanities Science and Technology, Loudi, Hunan 417000)
In order to improve the performance of the Hadoop cloud computing platform, a parameter optimization model is presented for across layer of IaaS, PaaS and SaaS. Firstly, the work flow of cloud computing platform is analyzed, to make the system parameters correspond to the flow. The parameters of IaaS and PaaS layer are added and parameters which significant impact on Hadoop execution time are found. Performance parameter model is formed based on the above parameters and optimized by Heuristic ant colony algorithm. Finally, cross layer parameters are integrated to improve the performance of Hadoop cloud computing platform. Experiments show that the algorithm is feasible and perform well.
Hadoop cloud computing; parameter optimization; ant colony system; virtual machine
2015-12-30.
国家自然科学基金项目(61472135));广东省科技计划项目(2014B010102007).
1000-1190(2016)02-0183-07
TP393
A
*E-mail: mei_wangchun@163.com.
