基于决策树分类算法的研究与应用
2016-11-25杨永春
路 翀,徐 辉,杨永春
(1.新疆交通职业技术学院 新疆 乌鲁木齐 831401;2.伊犁师范学院 电子与信息工程学院,新疆 伊宁 835000)
基于决策树分类算法的研究与应用
路 翀1,徐 辉2,杨永春1
(1.新疆交通职业技术学院 新疆 乌鲁木齐 831401;2.伊犁师范学院 电子与信息工程学院,新疆 伊宁 835000)
首先采用企业的客户数据作为样本数据进行客户的稳定性分析,然后,提出了一种基于ID3算法的改进分类算法,该分类新的算法是在经典ID3算法基础上引入粗糙组合属性的思想,使得期望非叶节点到各叶节点的平均路径最短,从而提升分类的速度和准确率。通过实例对改进算法生成决策树产生的结果分析,表明了该算法生成的决策树结构更简单,时间复杂度更优,算法更有效。
决策树;ID3算法;分裂属性;粗糙集理论
决策树(Decision Tree,DT)是一种用于分类,聚类和预测的建模方法。决策树采用“分而治之”的方法将问题的搜索空间分为若干子集,这些子集由决策树的根节点和内部节点表示。每个节点引出的弧代表了该节点相关联的问题的可能答案。每个叶节点代表对问题解决方案的一个预测输出[1]。
决策树分类算法的关键问题在于选择一个恰当的分类属性规则,利用恰当的规则产生的分支可加快决策树的生长以及产生较优化结构的决策树,从而获得较准确的知识。随着训练样本的规模不断扩大,尤其训练样本的属性空间不断扩大。训练样本独立分散在主存中不仅费时,而且影响算法效率。同时,分析数据的算法往往由于数据的多构化不规则性,且需要跨学科跨领域的研究。因此,优化算法使其有效地处理各种大规模的数据已经成为决策树分类算法的重要研究方向[2-3],也是目前国内对决策树分类算法研究的热点。
1 决策树的分类算法
决策树分类方法将搜索空间划分为一些矩形区域,然后根据元组(或对象,实例)落入的区域对元组进行分类。给定一个数据库
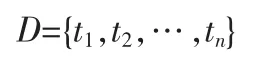
其中元组
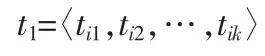
其属性空间为

其中ai为每个内部节点。同时,给定类别集合
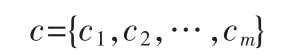
其中cj被标记为每个叶节点,且记cj中的样本数为tl。每个弧都被标记一个谓词,这个谓词可应用于相应父节点的属性。
1984年,Quinlan在《Introduction of decision trees》中提出了著名的ID3算法[4],其关键思想是利用信息熵原理,选择信息增益(Gain)最大的属性作为分类属性,递归地构造决策树的分枝,最大限度地减少正确分类所需要的信息。之后,Quinlan提出ID3优化算法C4.5[5],在几个方面的不足上进行了改进,提出信息增益率(GainRatio)的概念,其定义如下,给定概率:
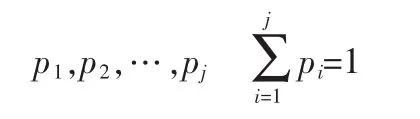
其中则熵的定义为:
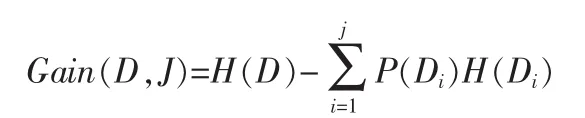
若给定一个数据状态D,以及该状态被分裂为j个新状态

则分裂属性的信息增益定义
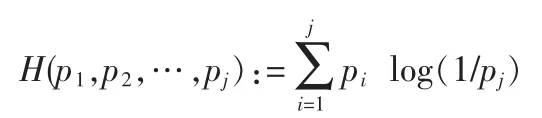
其增益比率定义[1]
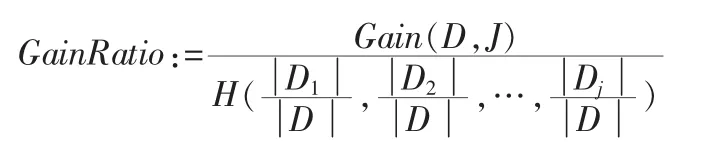
则分裂属性的信息增益定义其增益比率定义[1]。
本文对客户的稳定性分析所提出的分类算法在经典ID3算法基础上引入粗糙组合属性的思想[6],期望非叶节点到各叶节点的平均路径最短,提升分类的速度和准确率。
假设在给定数据库D中,属性au∈A(1≤u≤h)是分类决策树中决定分裂属性的Gain的值较大的,称为强分裂属性。属性av∈A(1≤u≤h,u≠v),相应地,每次递归计算中Gain值较小的,称为弱分裂属性。若对象的非空有限集合U中任意的子集V,不能够将非空有限集U中的某些对象区分开,则记作Dim(V)。若删除属性,

则定义弱分裂属性集AV:=Uav;同样地,

则定义强分裂属性集
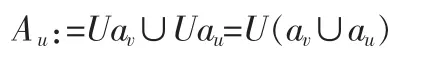
其中
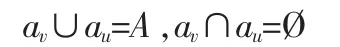
2 粗糙集理论
粗糙集理论[7-9]的核心就是将知识和分类结合在一起,并用等价类关系形式化构造商集合U/R={X1,X2,…,Xm},其中Xi就是U/R的一个等价类。
由于不可分关系计算的时间复杂度直接影响到算法的复杂度,Rough集理论中利用求等价类划分的算法。基于基数排序的思想可以将求等价类划分的时间复杂度降低到O(|P|| U|),其中P位属性子集中属性的数量,U为论域[10-13]。所以这就解释了结合粗糙集理论的分类算法在速度和准确性上会有一定程度的提升。
3 本文提出的分类算法
经典ID3算法是选取Gain值最大的属性作为优先分裂属性。本文提出的结合粗糙集理论的分类算法首先是组合强分裂属性,然后生成决策树,具体优化后的算法如下:

4 基于客户流失实例分析
下文采用某企业的客户数据(共计600条记录),作为样本数据进行分析,如表1所示。
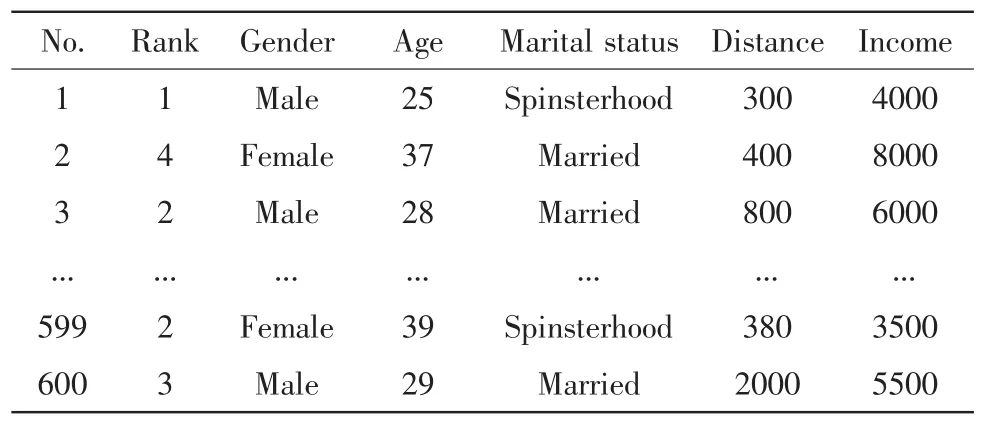
表1 原始样本数据
4.1 数据预处理
由于样本数据存在结构差异,故需要对原始数据作定义处理。属性:

结构化后数据样本如表2所示。
4.2 生成决策树
首先由经典ID3算法,根据结构化数据样本建立客户流失分析的决策树模型,如图1所示。为了改进算法的时间复杂性与准确性,将训练样本也采用结合粗糙集组合属性的算法建立决策树,如图2所示。

表2 结构化样本数据
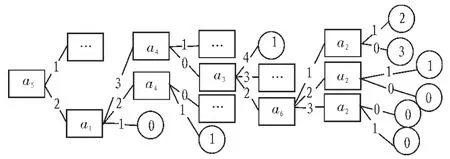
图1 ID3算法模型图
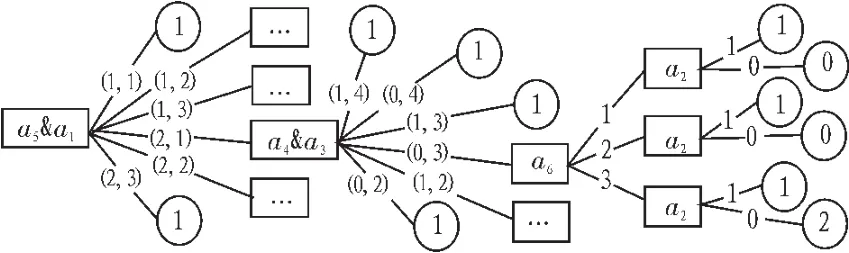
图2 ID3改进算法模型图
4.3 分 析
结果中叶节点0表示常驻客户,1表示非常驻客户,2表示极有可能流失客户。从时间复杂度方向的评价,粗糙集组合属性构建的决策树拥有更简洁的树结构,所花费的时间优于经典ID3算法,有利于决策者做出决策,尤其在遇到较多维属性的样本时,采用粗糙集组合属性的思想结合分类算法对数据进行处理时十分有必要的。另一方面,解决了ID3算法常见的问题,即在整个搜索过程中出现的局部最优而非全局最优。
5 结束语
文中提出的优化算法与ID3算法的分析比较,得出此方法生成的决策树结构更简单,时间复杂度更优。尽管如此,改进后的算法仍有待完善,主要体现在以下的几方面:1)简单的优化目前之限于多维的数据库,对高维的数据库,比如上万维的生物基因信息数据库,需要更多的优化;2)由于本文的数据与结果存在着一定的相关性,所以在很多情况下,需要对属性进行删减,其目的与算法剪枝类似,防止决策树过拟合;3)其准确性在不同的样本中表现不一样,若追求既快速又准确地算法有待更进一步完善[14-19]。
[1]Margaret H.Dunham Data Mining Introductory and Advanced Topics[D].Arrangement with the original publisher,Pearson Education,Inc,2003:51-102.
[2]刘小虎,李生.决策树的优化算法[J].软件学报,1998,9(10):797-800.
[3]冯少荣.决策树算法的研究与改进[J].厦门大学学报:自然科学版,2007,7(46):496-500.
[4]Ouinlan JR.Induction of decision trees[J].Machine Learning,1998(1):81-106.
[5]Ouinlan JR.C4.5:Programsformachine learning[M].California:Morgan Kaufmann Publishers Inc.,1993.
[6]于海平,朱玉金,陈耿.一种基于粗糙集理论的决策树构造方法[J].计算机应用与软件,2011,28(2):80-84.
[7]王国胤,姚一豫,于洪.粗糙集理论与应用研究综述[J].计算机学报,2011,7(32):1229-1246.
[8]马文萍,黄媛媛,李豪,等.基于粗糙集与差分免疫模糊聚类算法的图像分割[J].软件学报,2014,11(25):2675-2689.
[9]李华雄,刘盾,周献中.决策粗糙集模型研究综述[J].重庆邮电大学学报:自然科学版,2010,5(22):624-630.
[10]唐瑞春,张肖南,郭双乐.一种基于粗糙集和欧式距离的手机故障案例匹配算法[J].中国海洋大学学报:自然科学版,2015,12(45):125-130.
[11]张琼.基于粗糙集的改进Leader聚类算法[J].江苏师范大学学报:自然科学版,2015,4(33):50-53.
[12]鲍新中,张建斌,刘澄.基于粗糙集条件信息熵的权重确定方法[J].中国管理科学,2009,3(17):131-135.
[13]张清华,王国胤,肖雨.粗糙集的近似集[J].软件学报,2012,7(23):1745-1759.
[14]张明,程科,杨习贝,等.基于加权粒度的多粒度粗糙集[J].控制与决策,2015,2(30):222-228.
[15]罗彬,邵培基,罗尽尧,等.基于粗糙集理论-神经网络-蜂群算法集成的客户流失研究[J].管理学报,2011,2(8):265-272.
[16]徐岩,陈昕.基于贝叶斯决策树的电网报警信息去噪方法研究[J].陕西电力,2014(6):38-41.
[17]吴恩英,吕佳.基于二叉树支持向量机多类分类算法的研究[J].重庆师范大学学报:自然科学版,2016(3):102-106.
[18]徐国浪,魏延.基于二叉树结构双优化的SVM多分类算法研究[J].重庆师范大学学报:自然科学版,2013(6):109-113.
[19]王江荣,罗资琴,文晖,等.基于粗糙集的多项logistic回归模型在油层识别中的应用[J].工业仪表与自动化装置,2015(3):28-32.
The research and application of classification algorithm based on decision tree
LU Chong1,XU Hui2,YANG Yong-chun1
(1.Xinjiang Vocational and Technical College of Communication,Wulumuqi,831401,China;2.Electronics and Information Engineering College,Yili Normal College,Yining 835000,China)
In this paper,we analysed the stability by enterprise customer data as the sample data,and then,we proposed an improved algorithm based on the ID3 algorithm via combining with rough set theory.The new classification algorithm is based on the classical ID3 algorithm to introduce the concept of rough combination attribute,which makes the average path of the expected non leaf nodes to the nodes of the shortest path,so as to improve the speed and accuracy of classification.The structure of decision trees which are constructed by the improved algorithm becomes very exact and simple,the time complexity is betterthantheID3algorithm.Experimentalresultsonthedecisiontreealsoshow theimprovedalgorithm iseffective.
decision tree;ID3 algorithm;splitting attribute;rough set theory
TP301
A
1674-6236(2016)18-0001-03
2016-01-22 稿件编号:201601207
国家自然科学基金项目(61363066);新疆高校项目(XJEDU2014I043)
路 翀(1966—),男,江苏江都人,教授。研究方向:模式识别。
