基于决策树算法的石油基础数据挖掘系统应用研究
2016-11-25杨涛
杨涛
(中海石油(中国)有限公司 北京 100010)
基于决策树算法的石油基础数据挖掘系统应用研究
杨涛
(中海石油(中国)有限公司 北京 100010)
针对石油基础数据量急剧增长,数据之间不能达成共享,管理不能保持统一等问题,研究并设计了石油基础数据挖掘系统分析系统。通过构建石油基础数据数据仓库模型,用于完成数据清理、数据变换和数据集成等数据预处理操作。应用决策树算法实现油基础数据的数据挖掘与分析,并借助数据挖掘插件直观地向用户展现了数据挖掘算法的分析结果,辅助业务管理人员对油气生产做出指导和决策,促进了中国石油勘探与生产分公司生产管理水平的提高。
石油基础数据;数据挖掘;数据仓库;决策树法
石油基础数据正伴随石油行业信息化的迅速发展而不断攀升,加强管理,并科学合理分析这些数据,对于中国石油勘探与生产分公司来说意义重大[1]。目前管理系统查询数据的主要形式为报表或者表格,缺点在于不能直观显示图表数据,所以,对石油基础数据挖掘系统的构建势在必行[2]。
文中基于中国石油经济研究院提供的基础数据,该数据服务于中石油勘探与生产分公司,分析角度确定为石油基础数据分析,对数据仓库体系结构以及多维数据分析模型进行构建,对数据仓库的多维分析主题进行合理确定,完成石油基础数据挖掘系统分析系统的设计与实际验证,选择数据挖掘技术归纳总结石油基础数据,寻找有用信息,直观显示分析结果,提升中国石油企业业务管理人员的管理能力与决策能力[3]。
1 石油基础数据的数据挖掘概述
数据挖掘被称为数据库的知识发现(Knowledge Discov-ery in Databases),石油基础数据的数据主要目标为大量石油基础数据,主要任务是对这些业务数据进行清洗、抽取、转换以及加载,筛选有利于决策的重要数据[4]。图1表示该系统结构。
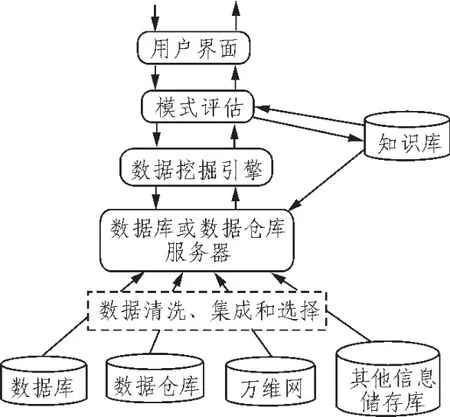
图1 石油基础数据挖掘系统的结构
石油基础数据挖掘属于人机交互过程,该过程具有完整以及多次反复等特征[5]。数据挖掘基于多个步骤,并且不同步骤会随着石油数据来源与研究领域的差异而改变,该过程见图2。
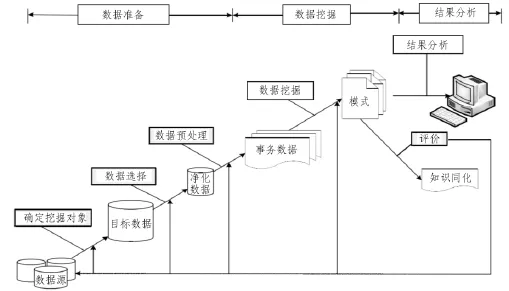
图2 石油基础数据挖掘过程示意
2 石油基础数据的数据仓库设计
数据仓库属于分析型处理数据库,数据来源为数据集合,该数据集合具有多个异构、完整、稳定等特征,并对上述数据集合进行有效集成,根据各自主题的差异重新组合,寻找数据间的联系与规律,为业务管理人员的决策提供关键信息[7]。
2.1 数据仓库体系结构设计
石油基础数据数据仓库的体系结构由3部分组成,分别为:1)数据源;2)数据存储;3)数据管理。图3表示具体结构[8]。数据源作为数据仓库的基础,其来源包括4方面:①世界石油工业基础数据库;②石油基础数据要览;③世界油气资源查询系统数据库;④其他外部数据源。

图3 石油基础数据数据仓库体系结构
石油基础数据仓库的数据组织方式可以完整清晰地描述分析对象,寻找与分析对象相关企业不同数据间的内在关联。具有高效率、高准确率的特征,提升管理人员的决策能力[9]。
1)数据仓库的数据综合:数据仓库中的数据组织方法为分级组织,对应级别包括:①早期细节级;②当前细节级;③轻度综合级;④高度综合级;⑤元数据。其中第3种和第4种级别的数据适当进行归纳总结,因此,适合这两种级别数据的模型为星型或者是雪花片模型,从而增加数据访问速度[10]。数据仓库的数据组织结构见图4。

图4 数据仓库的数据组织结构
2)数据仓库元数据模型:元数据(Meta Data)是关于数据的数据。元数据可大幅度提高寻找所需数据速度。石油基础数据数据仓库的核心为元数据,其对不同对象进行描述。元数据指明数据仓库信息的内容与位置,对数据的抽取与转换规则进行详细描述,对数据仓库主题相关的所有信息进行储存[11]。详见图5所示。
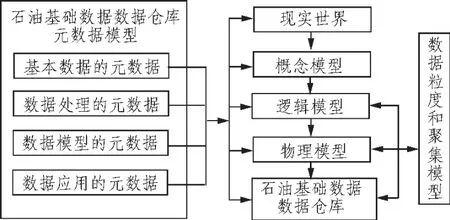
图5 元数据关系示意图
3)数据仓库的粒度设计:数据粒度指的是数据仓库中保存数据的细化或者是综合程度的级别。数据粒度越小,则数据细化程度越高,数据综合级别越低,提供细节数据的查询能力越强,反之亦然。
2.2 数据仓库ETL设计
对源数据以及目标数据结构进行扫描,在元数据库中进行相应储存,对源表以及目标表进行确认之后,建立字段映射,检验字段映射能否成功,系统依据抽取规则,对数据进行抽取。确定源字段与转换函数,对数据进行转换;最后按照ETL自定义的数据抽取规则、转换规则,自动生成 ETL信息,将数据加载至目标数据库中。
3 基于决策树法的数据挖掘
1)在数据集中,该方法选择信息增益作为属性选择的标准,确定最有影响力的属性;2)分解数据集,形成多个子集,确定不同子集最有影响力的属性,继续分解,直到每个子集只包含同一类型的样本为止。由此形成一棵决策树,详见图 6所示。
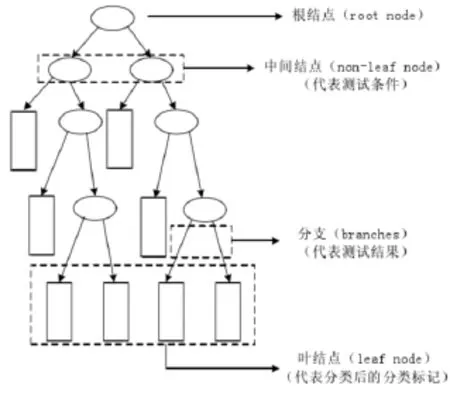
图6 决策树的构成
假设石油基础数据集S中有s个样本,类别属性有m个不同取值,定义m个不同的类Ci,i∈{1,2,3,…m}。设si为类别Ci的样本个数,该数据集分类所需要的期望信息如下:

其中pi是任意一个样本属性类别的Ci的概率,参照si/S进行计算。
设属性A可取v个不同的值{a1,a2,a3…av},可以用属性A将S划分v个子集{s1,s2,s3…sv},其中,Si包含S属性A中取值aj为1的样本。若属性A为测试属性,设sij为子集Sj中属于Ci类别的样本数。则利用属性A划分当前集合所需的期望信息计算为:
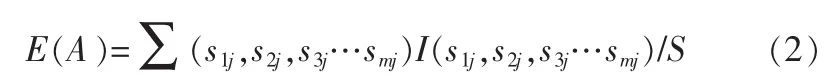
其中,(s1j,s2j,s3j…smj)/S称为第j个子集的权值。E(A)越小,即子集划分结果越优。作为给定子集Sj,期望信息如(1)所示。其中pij=sij/|Sj|为子集中任一个样本属于类别Ci的概率。
由此利用属性A对当前分支节点进行划分所获得的信息增益是:

Grain(A)是根据属性A进行集合划分所获得的信息熵的减少量。
挖掘过程如图7所示。

图7 决策树算法的数据挖掘过程
石油基础数据挖掘分析系统由4个功能模块构成,分别为:1)能源数据查询;2)能源数据三维柱状图以及饼状图显示;3)能源数据分析;4)数据挖掘。其中,第3功能模块涵盖3方面内容:①OLAP分析;②多维透视表分析;③多维透视图分析。具体详见图 8。
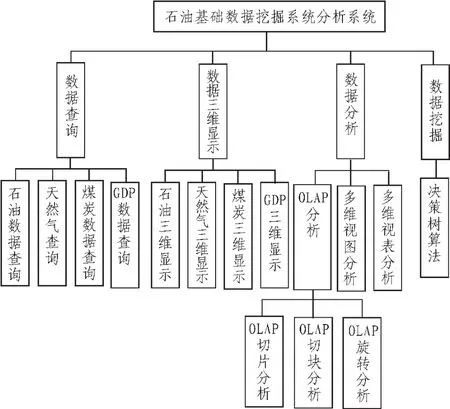
图8 决策树算法的数据挖掘过程
4结 论
文章基于石油基础数据的特征,对石油基础数据仓库模型进行构建,对数据挖掘模型进行创建,达到挖掘分析石油基础数据的目标。所设计的挖掘系统可直观展示三维或多维报表与数据查询结果的图表形式。这对于提高业务管理人员的决策能力,加强中国石油企业的生产管理水平至关重要。
[1]崔立芳.浅析石油数据管理[J].计算机工程应用技术,2011,7(30):7514-7515.
[2]杨凯.数据挖掘技术在中石油 ERP中的应用研究[J].中国管理信息,2010,13(17):57-59.
[3]郑继刚,王边疆.数据挖掘研究的现状与发展趋势[J].红河学院学报,2010,8(2):45-48.[4]谭锋奇,李洪奇,孟照旭,郭海峰,李雄炎.数据挖掘方法在石油勘探开发中的应用研究[J].石油地球物理勘探,2010,45(1):85-91.
[5]郑岩.数据仓库与数据挖掘原理及应用[M].北京:清华大学出版社,2011.
[6]徐玉鹏.数据仓库、OLAP和数据挖掘在商业智能中的应用研究[D].南京:南京航空航天大学,2010.
[7]HU Hong-tao,ZHANG Jing-na,LI Zhou-li.A distortion correction method of lateral multi-lens video logging image[C]//2012 IEEE InternationalConference on Computer Science and Automation Engineering,2012:141-144.
[8]张俊泽.数据挖掘在石油行业资金管理中的应用[D].天津:天津大学,2008.
[9]商琳,骆斌.一种基于数据仓库的数据挖掘系统的结构框架[J].计算机应用研究.2000(9):63-65.
[10]王晓莲,顾娟,王颖,等.大庆油田测井数据库系统设计[J].油气田地面工程,2007,26(2):46-47.
[11]汪忠德,王新海,瞿建华,等.数据挖掘技术在石油勘探与开发中的研究及应用[J].石油工业计算机应用,2007,15(1):17-20.
[12]肖基毅,胡蓉,王以群.油网格数据挖掘新技术研究[J].西南石油大学学报,2008,30(3):152-154.
[13]冯宗祥.油气勘探生产信息平台建设的目标及方法[J].中国石油勘探,2005,10(3):53-56.
[14]Hirsh H.Data mining research:current status and future opportunities.Statistical Analysis and Data Mining,2008,1(2):104-107.
[15]李立平.基于数据挖掘的勘探随钻分析系统[D].上海:上海交通大学,2010.
Oil based data mining system based on decision tree algorithm applied research
YANG Tao
(China National Offshore Oil Corporation,Beijing 100010,China)
For oil based data volume increase sharply,unable to reach a Shared between data,couldn't keep his unified management,research and design of the world's oil and gas resources query analysis system.By building oil based data warehouse model,oil based data warehouse multidimensional analysis method is given.Using decision tree algorithm to realize oil based data mining and analysis of the data,and with the help of data mining plug-in intuitively to show the user the analysis results of data mining algorithm and auxiliary business managers make guidance to the oil and gas production and decision-making,promote the production management level,the branch of China petroleum exploration and production.
oil based data;data mining;data warehouse;decision tree method
TN98
A
1674-6236(2016)18-0016-03
2016-02-25 稿件编号:201602133
国家级重点专项基金课题(2011ZX05026-001-06);北京市科技局课题(TX-78901W2015)
杨 涛(1978—),男,河北徐水人,中级工程师。研究方向:设备设施完整性管理。
