基于随机方法和优化的DPLL算法的测试用例自动生成技术研究
2016-11-22查敬芳胡立生
查敬芳 白 涛 胡立生
(1.上海交通大学电子信息与电气工程学院,上海 200240;2.深圳中广核工程设计有限公司,广东 深圳 518172)
基于随机方法和优化的DPLL算法的测试用例自动生成技术研究
查敬芳1白 涛2胡立生1
(1.上海交通大学电子信息与电气工程学院,上海 200240;2.深圳中广核工程设计有限公司,广东 深圳 518172)
提出一种基于随机方法和优化的DPLL算法的测试用例自动生成技术,并以基于FPGA的核电仪控系统为对象进行了验证。该方法能验证HDL描述符合设计规范的要求,代码覆盖率较好,所提方法在解决大规模问题时效率有所提升,尤其是对于可满足性问题,效率提升非常显著。
测试用例 SAT问题 DPLL算法 核电仪控系统
核电作为一种清洁低碳能源,其经济性好、持续供应能力强,代表着能源优质化的发展方向,但是2011年日本福岛核电站爆炸事故给人类和环境造成的破坏也是极其严重的。因此,进一步提高核电的安全标准和技术水平已成为全世界的共识。数字仪控系统是核电实现可靠性、多样化设计的重要手段。而基于FPGA的仪控系统因其开发和验证过程的简便性、系统架构的灵活多变性及容错性等特点,在核电安全重要领域的应用比重日益加大,成为实现仪控系统多样化设计、定制性设计的重要手段。而功能验证的完备性为系统的可靠性提供最直接的保证,为了达到功能验证的完备性,需要针对测试空间高效率地生成大量的测试用例,尽可能多地覆盖测试空间中的功能点。
功能验证中测试用例生成的基本方法有直接测试和随机测试[1]。直接测试用例击中的是测试空间中某个特定的功能点,具有单一性和明确的目的性,没有太多的精简余地;而随机测试可以随机击中测试空间中的任何一个点。因此,随机测试是当前功能验证中测试用例生成的主要方法,和直接测试相比,随机生成的测试用例可覆盖到测试空间的任一功能点,有可能覆盖到验证人员都未想到的功能角落。但也因为这种随机性,随机测试有可能导致功能点的重复覆盖,这种无谓的重复就延长了验证时间,降低了验证效率。所以,当前功能验证的主要研究热点是在保证覆盖率的前提下设定约束,有效提高验证效率。这些研究包括:
a. 采用演化计算方法,通过不断进化,选择最佳的测试向量[2~4]。
b. 通过分析覆盖率模型和输入测试向量之间的关系建立模型,用优化的测试向量验证收敛过程,如基于贝叶斯网络模型的测试方法[5,6]。
c. 研究其他覆盖率和功能覆盖率关系的方法,如通过代码覆盖率分析来提高功能覆盖率[7]。
d. 结合直接方法和随机方法生成测试向量,并用路径覆盖率衡量验证工作是否收敛。对于前两种方法不能覆盖的边界情况,将目标测试路径转化为合取范式的可满足(SAT)问题,用DPLL算法进行求解,以进一步提高路径覆盖率[8]。
文献[8]所提方法很好地解决了在边界情况下采用随机方法,覆盖率提高效率极低的问题,但该方法无法用于解决大规模问题,这是由传统的DPLL算法在解决该问题时决策策略部分不足所导致的,因为传统的DPLL算法的决策策略是每次做决策时重新计算评估函数,对每个变量的赋值所带来的影响做出效率评估,非常耗时。基于此,笔者提出基于随机方法和优化的DPLL算法的测试用例生成技术。优化的DPLL算法在进行决策时仅针对因空间裁剪引起变化的子句进行局部统计,且根据变量对整个空间的贡献情况,动态调整变量的权值,从而显著提高求解效率。
1 基本知识
1.1SAT问题
给定合取范式F,问是否存在变量的某种赋值,使得F的值为真。如果变量存在这样的赋值,则称F是可满足的;如果变量的任意赋值F都为永假式,则称F是不可满足的。在人类为大规模计算问题寻求高效率算法的努力过程中,可满足问题扮演了重要角色,例如可用于规划调度、对光纤的布线、寻找蛋白质的折叠态以及对计算机芯片进行验证等[9]。
可满足问题一般用合取范式来表示,合取范式一般是子句合取的形式,子句则是文字的析取形式,而文字是布尔变量的肯定或者否定形式。其数学描述如下:
a. 合取范式F是子句合取的形式,即F=C1∧C2∧…∧Cs,当存在变量X使得F=1时,则说明该范式是可满足的;否则,是不可满足的;
b. 子句C1,C2,…,CN,其中每个子句是文字析取的形式,即Ci=l1∨l2∨…∨lt,实际上每个子句是一个约束条件;
c. 文字l∈{x1,┑x1,x2,┑x2,…,xN,┑xN},即每个文字是布尔变量的肯定或者否定形式;
d. 布尔变量x∈{x1,x2,…,xN},它的取值域为{1,0},即每个变量。
1.2决策策略
决策赋值是指每次分支选择时选择一个变量进行赋值,决策的过程是在未赋值的变量中选择一个变量进行“0”或“1”的赋值。在DPLL搜索过程中,当遇到下面情形之一时,需要在未赋值的变量空间中选择一个变量进行赋值:无任一单位子句出现,能对变量进行蕴含赋值;而此时又无子句冲突发生;并且仍有大量子句在当前赋值下无法满足。在遇到上面这3种情形之一时,都需要进行决策赋值。
为了更好地说明笔者提出的决策策略的优势,首先介绍一下已有的常用策略。
最简单的决策方法是在未赋值的所有变量中随机选择一个变量进行赋值。另外一种策略采用启发式方法,求当前变量状态和子句数据库构成的复杂函数的最大值。在决策时,通过定义评估函数,对每个变量的赋值所带来的影响做出效率评估,目前算法所采取的策略可分为两大类:一类是静态的,即在初始情况下,通过为每一个变量赋值,计算它对搜索空间的压缩程度,然后采用贪心算法,每次选取压缩效率最高的变量进行随机赋值。另一类是动态的,即在每次进行决策时,都利用当前的信息重新评估该变量对搜索空间压缩程度的影响。第1类方法比较快速,一次计算,整个过程都有效,但由于在决策剪枝之后整个空间会发生变化,每个变量相对于该空间的比值会发生变化,所以初始的评估不一定有效。第2类方法能解决这个问题,但第2类方法由于每次决策都需要进行重新计算,比较耗时。目前优化的算法都采用动态决策方法,在众多变量决策策略中,文献[10]提出的优先选取最短子句中出现频率最大的变量和文献[11]提出的优先选择最短的正子句这两种方法比较常用。然而动态方法在变量数比较多的情况下,效率很差。
综上可知,要实现高效率的决策,需要考虑3方面的要求:一是决策算法本身的花费,如果决策算法本身开销过大,会导致整个算法失去实际意义;二是通过决策分支,能否对整个搜索空间进行优化;三是在解决一个问题时所做的决策次数,决策次数越少,说明所做的决策越智能。
2 优化的DPLL算法
2.1算法概述
笔者所提出的测试用例生成方法结合了随机方法和DPLL算法,重点对DPLL算法的决策部分进行优化。DPLL算法是解决布尔可满足性问题的完全算法,该算法是在二叉树搜索空间中进行深度优先的分支搜索。在基本DPLL算法中,核心的4部分是布尔约束传播、冲突分析、回溯和决策,其中布尔约束传播、冲突分析和回溯用来裁剪搜索空间,使搜索空间不断收缩,加快搜索速度。该算法中的另一个重要部分是决策,决策是否智能直接影响总的决策次数、布尔约束传播次数和冲突发生的次数,从而影响搜索空间的压缩程度和搜索效率。笔者所提出的优化的DPLL算法流程如图1所示。
2.2空间裁剪
在笔者所提算法中,选用布尔约束传播和冲突分析来对搜索空间进行裁剪。
布尔约束传播是利用单位子句规则。单位子句是指在当前赋值下,除了一个“字”以外,其他文字都已被赋值,且赋值为“0”,称该子句中未被赋值的这个“字”为单位字。这样,为了使得单位子句的值为“1”,则该“字”必须赋值为“1”。这样在搜索中,就不必去搜索值为“0”的分支路径,就达到了裁剪空间的目的。为了满足某个单位子句值为“1”而迫使单位字为“1”的过程称为蕴含,单位字被蕴含赋值后,往往有更多的单位子句出现,于是新的蕴含过程发生,这种链式的蕴含过程就称为布尔约束传播。

图1 优化的DPLL算法流程
冲突分析是利用冲突子句的启发信息。冲突子句是指在当前的赋值下,所有字的值都为“0”的情况下,当遇到冲突子句时,就无需在该路径上继续下去,需要进行回朔,取消部分变量的赋值,回溯到某个层级上,从另外的路径上重新进行搜索。
2.3决策
优化算法的基本思想可用图2来表示,将整个搜索空间(图中的大圆形)分成两部分,未被搜索的不确定空间和已被标记的不可满足空间(图中的小圆形),算法的工作就是通过决策选择被赋值的变量,使得图中已被标记的不可满足空间变得越来越大,也就是说使得冲突可能发生的情况提早,在冲突发生后,经过对冲突的分析,将引起冲突发生的赋值集合加上约束,即对这组赋值集合加上不可满足的标记,使它在之后的搜索过程中不会再出现相同的赋值组合而引起同样的冲突。那么,随着已被证明的不可满足空间越来越大,后续搜索中未被搜索的空间则相应减小,即整个搜索空间的不确定性部分逐渐减小,后续搜索的工作量相应下降,从而使得搜索效率提升。

图2 搜索空间分布
在该算法中,如何设定评估函数选择优先赋值的变量使得不可满足空间逐渐增大至关重要。现有的决策策略思路有:随机选择;考虑到文字在最短子句中的信息增益较大,所以优先在最短子句中进行选择;选择出现频率最高的文字进行赋值。在前人工作的基础上,考虑以下两点选择评估函数:出现频率最高的文字对所有子句的信息增益最大;正负文字出现频率都高的变量发生冲突的可能性更大。基于这两点,笔者提出一种新的选择方法,核心思想是:比较所有变量x的正负文字计数器值h(x)、h(┒x)的大小,选择二者计数器值较小的文字为优先级构建优先级队列,每次选择队首的文字对它赋假值。
优化的DPLL算法详细描述如下:
a. 初始情况下,为每个变量x的正、负文字x、┒x各绑定一个计数器,计数器值h(x)和h(┒x)都初始化为0。
b. 然后依次将所有子句加入到数据库中,每加一个子句,该子句中相关文字的计数器值h(x)或h(┒x)就加1。
c. 比较所有变量x正、负文字计数器值h(x)、h(┒x)的大小,然后选择h(x)、h(┒x)中较小的为优先级,构建优先级队列。
d. 在冲突分析后将学习获得的子句加入数据库时,该子句中相关文字的计数器值也加1,同时更新优先级队列。此时再做局部更新,动态调整变量对空间的压缩效率。
e. 决策时,选择优先级队列队首的文字,使该文字赋值为“0”。这种赋值方法可使冲突问题更早出现,因为此时选择的变量是正反文字出现频率都高的变量,引起冲突的可能性更大。因而可以以此来裁剪空间,使搜索空间逐渐减小,搜索空间中的不确定部分逐渐减少。
f. 在算法的搜索过程中,每个变量的计数器值会定期用一个正数值取模,这样可动态调整每个变量对空间贡献的权值,使后续因学习子句而产生影响的变量权值较高,同时防止某些变量长期得不到赋值的情况。
如以下实例:
l1:(┒m∨n∨p)
l2:(m∨p∨q)
l3:(m∨p∨┑q)
l4:(m∨┑p∨q)
l5:(m∨┑p∨┑q)
l6:(┑n∨┑p∨q)
l7:(┑m∨n∨┑p)
l8:(┑m∨┑n∨p)
采用所述的决策策略,该实例表示的优先级队列如图3所示。

图3 优先级队列
初始情况下,为每个变量的正、负文字各绑定一个计数器,即{文字x,计数器值h(x)},h(x)初始化为0。如上例,则有{┑m,0}、{m,0}、{n,0}、{p,0}、{q,0}、{┑q,0}、{┑p,0}、{┒n,0},然后依次读取子句l1~l8,并更新计数器值。读完子句之后,比较变量x相应文字的计数器值h(x)、h(┑x),选择计数器值较小的文字为优先级构建优先级队列(图3)。然后在需要做变量决策时,选择优先级队列队首的文字,对该文字赋“0”值。在空间裁剪过程中遇到冲突子句时,在冲突分析和添加学习子句之后,动态更新上述计数器值,并根据新的计数器值调整优先级队列。
所提决策策略递归地生成决策树,直到判定该问题为可满足性问题或者总搜索空间都被标记为不可满足的空间为止。原有的方法在生成决策树的过程中易出现过拟合现象,即在生成决策树的过程中因为剪枝不充分或者生成决策树的算法计算“精度”过高,导致生成的决策树非常复杂。但优化的算法在决策时选择导致冲突发生可能性最大的变量进行赋值,逐渐扩大不可满足空间,使总搜索空间中不确定部分逐渐缩小。
3 实例应用
笔者关注的是基于FPGA的核电仪控系统开发实现阶段之后的功能验证部分。在根据要求规范开发设计完基于FPGA的核电仪控系统各个模块的HDL程序后,就对该系统的各个模块进行功能验证。选取其中一个模块进行示例,该模块的输入变量个数为2 424。首先用随机方法生成测试用例,将它输入到系统的该模块中,然后通过EDA软件收集覆盖率。某一时刻,发现覆盖率已较高,并且此时输入随机方法生成的测试用例,并不能明显提高覆盖率,此时将未覆盖路径构建为布尔可满足性问题,并化为标准形式,标准形式的子句个数为14 812,其合取范式的标准表达式列举如下:
(x450∨┑x1813)
∧(┑x1005∨┑x2160)
∧(┑x481∨┑x495∨x584)
∧(x263∨x1820)
∧(┑x799∨┑x1223)
∧(x701∨x2226)
∧(x801∨┑x1709)
∧(┑x636∨┑x1534)
∧(┑x685∨┑x868)
∧(┑x967∨┑x2396)
∧(┑x1087∨┑x2311)
∧(x1969∨x2218)
∧(┑x1183∨┑x2419)
∧(┑x100∨x1830)
∧(x715∨x1493)
∧(x821∨x1249∨┑x1747∨x2040∨┑x1269∨x2096)
∧(x815∨x825∨x2144∨x1088∨┑x998∨x1841)
⋮
∧(┑x700∨┑x1389)
∧(x1118∨x1422)
然后用所提算法求解,图4给出了求解的详细过程记录,图5给出了求解结果。

图4 可满足的大数据量测试数据的计算过程

图5 可满足的大数据量测试数据的计算结果
选取表1中的测试数据,分别用文献[8]算法和笔者所提的优化算法进行求解,求解所用时间见表1。由表1的对比结果可知,笔者所提方法可用于解决大规模问题,并且在解决大规模问题时效率有所提升。对于可满足性问题,提升效果非常显著。更重要的是,当所解决的问题是不可满足性问题时,效率提升也很明显。文献[8]算法用于解决不可满足性问题时,需要遍历所有空间,时间消耗非常大,并且时间消耗大多数都是在不可接受的范围内。而笔者所提方法,每次决策都排除了一些已知的不可满足空间,从而使需要搜索的空间逐渐减小。对于这类问题,笔者所提算法体现出相当大的优势。
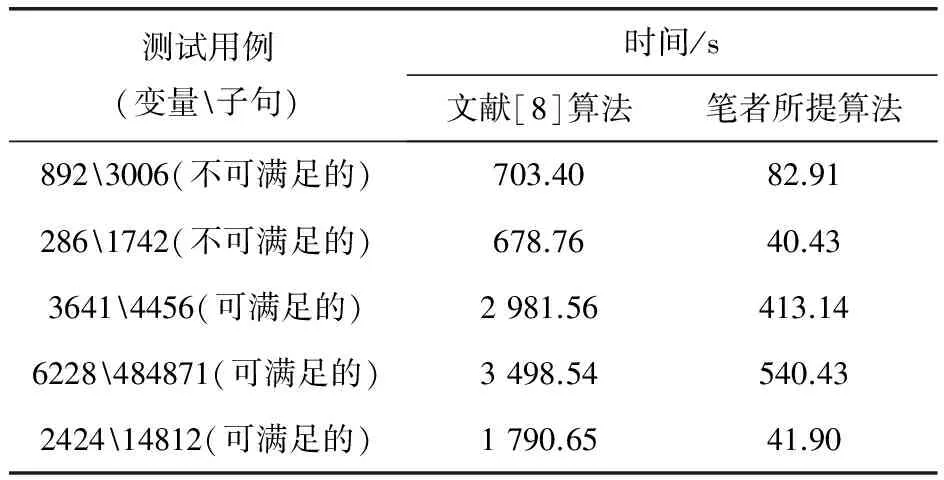
表1 文献[8]算法和笔者所提算法的结果比较
4 结束语
对于核电这种高安全性重要领域的功能验证,笔者所提方法能验证HDL描述符合设计规范的要求,代码覆盖率较好,且相对于文献[8]算法,该方法在解决大规模问题时的效率有所提升,对可满足性问题提升效果非常显著,并且当所解决的问题是不可满足性问题时,效率提升也很明显。
[1] 钟文枫.SystemVerilog与功能验证[M].北京:机械工业出版社,2010.
[2] 罗春,杨军,凌明.基于遗传算法和覆盖率驱动的功能验证向量自动生成算法[J].应用科学学报,2005,23(4):375~379.
[3] Samarah A,Habibi A,Tahar S,et a1.Automated Coverage Directed Test Generation Using a Cell-Based Genetic Algorithm[C].Proceedings of IEEE International High Level Design and Test Workshop.Monterey:IEEE,2006:19~26.
[4] 范小勤,汪小红,尹洁.约束优化问题的改进混合遗传算法[J].化工自动化及仪表,2010,37(7):13~16.
[5] Fine S,Ziv A.Coverage Directed Test Generation for Functional Verification Using Bayesian Networks[C].Proceedings of the 40th Design Automation Conference.Anaheim:IEEE,2003:286~291.
[6] 王豪,郑恩让.概率神经网络在点击故障诊断中的应用[J].化工自动化及仪表,2010,37(8):59~62.
[7] 傅亮,卢鼎,张志敏,等.通过分析代码覆盖提高功能覆盖率的验证输入自动生成方法[J].计算机辅助设计与图形学学报,2009,21(4):454~460.
[8] 陈可.核级FPGA软件验证方法研究[D].上海:上海交通大学,2014.
[9] Gomes C P,Selman B.Satisfied with Physics[J].Com-puter Science,2002,297(5582):784~785.
[10] Jeroslow R G,Wang J C.Solving Propositional Satisfiability Problem[J].Annals of Mathematics and Artificial Intelligence, 1990,1(1):167~187.
[11] Jing M E, Zhou D, Tang P S.Solving SAT Problem by Heuristic Polarity Decision-making Algorithm[J].Science in China Series F: Information Sciences,2007,50(6):915~925.
ResearchofAuto-generationTechnologyofTestCasesBasedonRandomMethodsandOptimizedDPLLAlgorithm
ZHA Jing-fang1, BAI Tao2, HU Li-sheng1
(1.SchoolofElectronicInformationandElectricalEngineering,ShanghaiJiaotongUniversity,Shanghai200240,China;2.ChinaNuclearPowerEngineeringDesignCo.,Ltd.,Shenzhen518172,China)
The random methods and optimized DPLL algorithm-based auto-generation technology for the test cases was proposed. Taking FPGA-based instrument and control system in the nuclear power generation as the object of test to show that this HDL specifications can meet design requirements along with better code coverage; and the efficiency of the proposed method is improved in solving large-scale issues; and regarding the satisfiability, the efficiency promotion is significant.
test cases, SAT issue, DPLL algorithm, instrument and control system in nuclear power generation
TP206
A
1000-3932(2016)09-0927-06
2016-07-12(修改稿)
